


近日DeepMind發布VQ-VAE-2算法,也就是之前VQ-VAE算法2代,這個算法從感觀效果上來看比生成對抗神經網絡(GAN)的來得更加真實,堪稱AI換臉界的大殺器,如果我不說,相信讀者也很難想象到上面幾幅人臉圖像都是AI自動生成出來的。
不過如此重要的論文,筆者還沒看到專業性很強的解讀,那么筆者就將VQ-VAE-2算法分為VQ,VAE,VQVAE2三部分來介紹原理,權當拋磚引玉。
什么是VQ
VQ是vector quantisationk(一般譯作矢量量化)的縮寫,他的主要思想是通過k-means算法進行聚類,將相近的點全部近似點簇的重心,從而在不損失太多信息的情況下對輸入進行壓縮。
k-means聚類算法:我在之前博客《終于把軟微BING搜索-SPTAG算法的原理搞清了(https://blog.csdn.net/BEYONDMA/article/details/90578111)
也曾經介紹過k-means算法。算法先隨機指定選取K個點做為初始聚集的簇心,分別計算每個樣本點到 K個簇核心的余弦距離,找到距離最近的核心點,將它歸屬到對應的簇,所有點都歸屬到簇之后, M個點就分為了 K個簇。之后重新計算每個簇的重心,將其定為新的“核心”,重復上述步驟直到新核心不再改變為止或者改變距離達到一定值后中止。那么最終的K個簇就是最終的聚類結果。
k-means算法試圖最小化失真,其定義為每個觀測向量與其主質心之間距離的平方之和。通過迭代地將觀測結果重新分類為星系團,并重新計算中心體,直到得到一個中心體穩定的構型,從而達到最小值。
那么VQ實際就是先把輸入的圖像進行-means聚類,完成后只保留最終留下的K個簇質心,簇上的其它點全部近似化為質心來進行存儲,用這樣的方式來進行壓縮。
什么是VAE
VAE是variational auto encoding(一般譯作變分自動編碼),不過筆者感覺譯為隱變更自動編碼可能更貼切。VAE的主要思想是他認為圖像、聲音等信息是由多個隱變量(latent arrtibute),比如對于人的面部圖像來說就由笑容,膚色、發色、發型等變量決定,那么VAE網絡就先把圖像中的笑容,膚色、發色、發型等變量識別出來,然后將這些變量傳遞給解碼器生成圖像。具體工作原理圖如下:
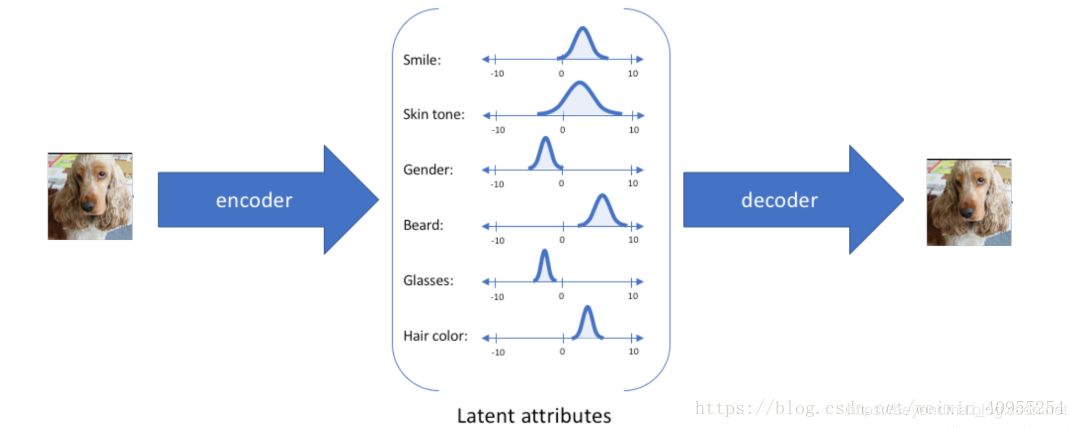
VQ-VAE1代算法整體的工作方式
簡單來講VQ-VAE1代算法,在Encoder層計算latent arrtibute(隱向量)的向量族z,然后傳遞給隱層,在隱層按照剛剛所述的VQ算法進行壓縮,然后輸出給Decoder進行生成,其具體原理見下圖。
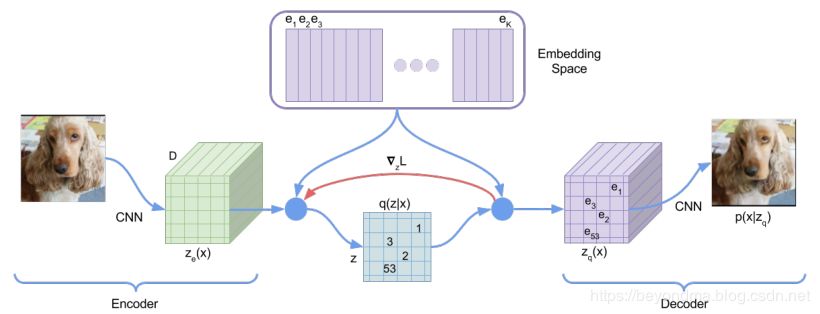
如果要進行換臉,那么只要將人臉A的Encoder進行編碼計算latent arrtibute(隱向量),然后輸出給FaceB的Decoder進行生成即可完成。
VQ-VAE2代算法的更新
VQ-VAE2代其實總體和1代差別不大,主要將latent arrtibute(隱向量)分為top和bottom兩層,其中top層記錄整體細節主要是明亮度、色調等信息,而bottom層主要記錄細節信息,從實際效果上看甚至包括了發絲、瞳孔等超級細微的層面。具體原理圖如下:
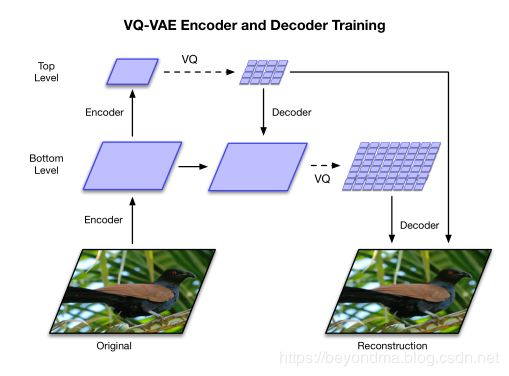
VQ-VAE-2將AI換臉的技術提升到了真假難辯的高度
我在之前的博客《終于把AI換臉的原理搞清了》(https://blog.csdn.net/BEYONDMA/article/details/88365203)曾經介紹過deepfakes等項目的原理,不過之前那些換臉算法對于細節的把握程度遠遠達不到VQ-VAE-2的程度,從DeepMind的論文中可以看到,其生成效果之好、分辨率之高已經到達了刷新了筆者的認知極限。所以筆者最后也再次呼吁,不要將AI換臉技術用在歪路上。
-
AI
+關注
關注
88文章
35041瀏覽量
279019 -
DeepMind
+關注
關注
0文章
131瀏覽量
11552
原文標題:AI換臉技術再創新高度,DeepMind發布的VQ-VAE二代算法有多厲害?
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
AlphaEvolve有望革新AI玩具芯片設計,算法進化驅動能效與成本雙突破
DevEco Studio AI輔助開發工具兩大升級功能 鴻蒙應用開發效率再提升
《DNESP32S3使用指南-IDF版_V1.6》第六十章 貓臉檢測實驗
Banana Pi 發布 BPI-AI2N & BPI-AI2N Carrier,助力 AI 計算與嵌入式開發
在英特爾酷睿Ultra AI PC上用NPU部署YOLOv11與YOLOv12

FPGA+AI王炸組合如何重塑未來世界:看看DeepSeek東方神秘力量如何預測......
農村污水處理站遠程監控智慧運維系統方案





 工商網監
工商網監

評論