 一種AI算法,可以根據說話聲音來預測說話人將作出怎樣的肢體動作
一種AI算法,可以根據說話聲音來預測說話人將作出怎樣的肢體動作
來自UC Berkeley和MIT的研究人員開發了一種AI算法,可以根據說話聲音來預測說話人將作出怎樣的肢體動作。所預測的動作十分自然、流暢,本文帶來技術解讀。
人在說話的時候,常常伴隨著身體動作,不管是像睜大眼睛這樣細微的動作,還是像手舞足蹈這樣夸張的動作。
最近,來自UC Berkeley和MIT的研究人員開發了一種AI算法,可以根據說話聲音來預測說話人將作出怎樣的肢體動作。
研究人員稱,只需要音頻語音輸入,AI就能生成與聲音一致的手勢。具體來說,他們進行的是人的獨白到手勢和手臂動作的“跨模態轉換”(cross-modal translation)。相關論文發表在CVPR 2019上。
研究人員收集了10個人144小時的演講視頻,其中包括一名修女、一名化學教師和5名電視節目主持人(Conan O’Brien, Ellen DeGeneres, John Oliver, Jon Stewart, 以及Seth Meyers)。
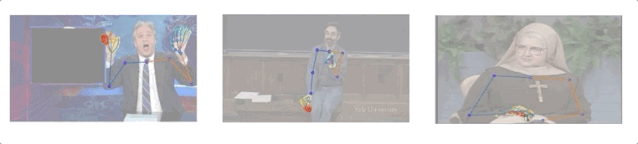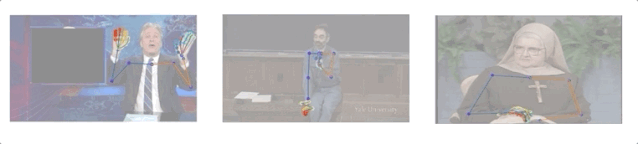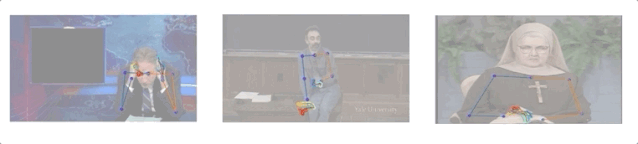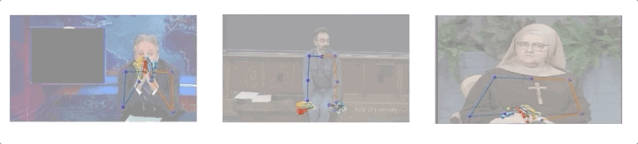
演講視頻數據集
他們使用現有的算法生成代表說話者手臂和手位置的骨架圖形。然后他們用這些數據訓練了自己的算法,這樣AI就可以根據說話者的新音頻來預測手勢。

圖1:從語音到手勢的轉換的示例結果。由下往上:輸入音頻、由我們的模型預測的手臂和手的姿態,以及由Caroline Chan等人在“Everybody Dance Now”論文中提出的方法合成的視頻片段。
研究人員表示,在定量比較中,生成的手勢比從同一說話者者隨機選擇的手勢更接近現實,也比從一種不同類型的算法預測的手勢更接近現實。
圖2:特定于說話者的手勢數據集
說話者的手勢也是獨特的,對一個人進行訓練并預測另一個人的手勢并不奏效。將預測到的手勢輸入到現有的圖像生成算法中,可以生成半真實的視頻。
研究團隊表示,他們的下一步是不僅根據聲音,還根據文字稿來預測手勢。該研究潛在的應用包括創建動畫角色、動作自如的機器人,或者識別假視頻中人的動作。
為了支持對手勢和語音之間關系的計算理解的研究,他們還發布了一個大型的個人特定手勢視頻數據集。
方法詳解:兩階段從語音預測視頻
給定原始語音,我們的目標是生成說話者相應的手臂和手勢動作。
我們分兩個階段來完成這項任務——首先,由于我們用于訓練的唯一信號是相應的音頻和姿勢檢測序列,因此我們使用L1回歸到2D關鍵點的序列堆棧來學習從語音到手勢的映射。
其次,為了避免回歸到所有可能的手勢模式的平均值,我們使用了一個對抗性鑒別器,以確保產生的動作相對于說話者的典型動作是可信的。
任何逼真的手勢動作都必須在時間上連貫流暢。我們通過學習表示整個話語的音頻編碼來實現流暢性,該編碼考慮了輸入語音的完整時間范圍s,并一次性(而不是遞歸地)預測相應姿勢的整個時間序列p。
我們的完全卷積網絡由一個音頻編碼器和一個1D UNet轉換架構組成的,如圖3所示。
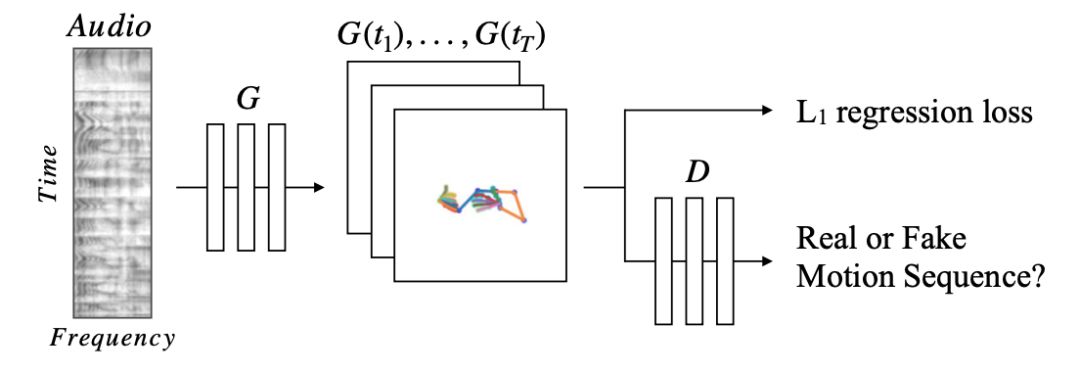
圖3:語音到手勢的翻譯模型。
一個 convolutional audio encoder對2D譜圖進行采樣并將其轉換為1D信號。然后,平移模型G預測相應的2D姿勢序列堆棧。對真實數據姿勢的L1回歸提供了一個訓練信號,而一個對抗性辨別器D則確保預測的動作既具有時間一致性,又符合說話者的風格。
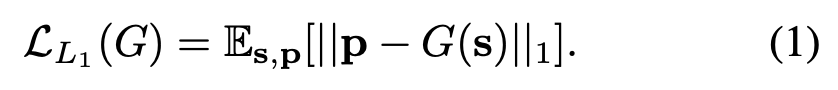
我們使用UNet架構進行轉換,因為它的bottleneck為網絡提供了過去和未來的時間上下文,而skip connections允許高頻時間信息通過,從而能夠預測快速移動。
定量和定性結果
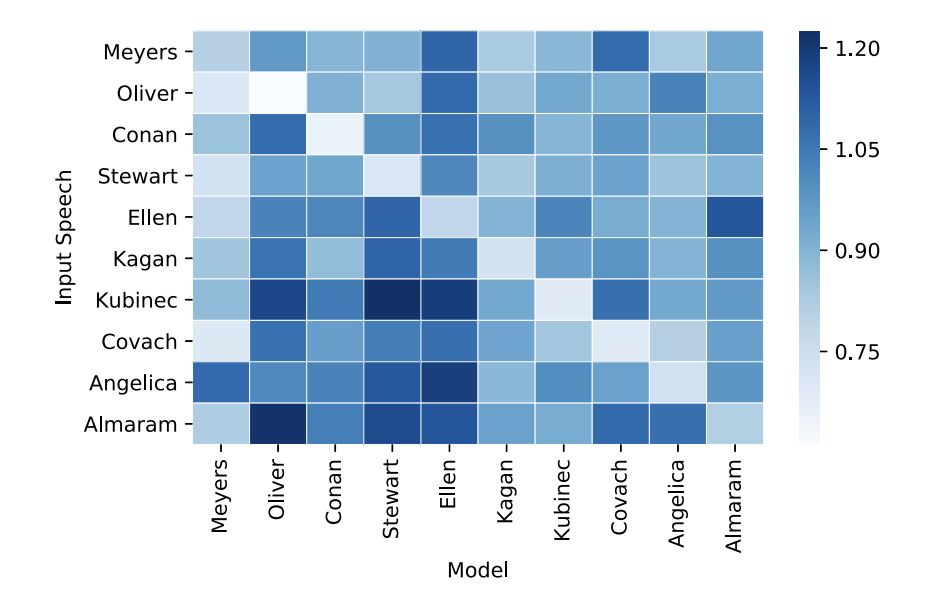
圖4:我們訓練過的模型是特定于人的。對于每個說話者的音頻輸入(行),我們應用所有其他單獨訓練的說話者模型(列)。顏色飽和度對應于待測集上的L1損耗值(越低越好)。對于每一行,對角線上的項都是顏色最淺的,因為模型使用訓練對象的輸入語音效果最好。
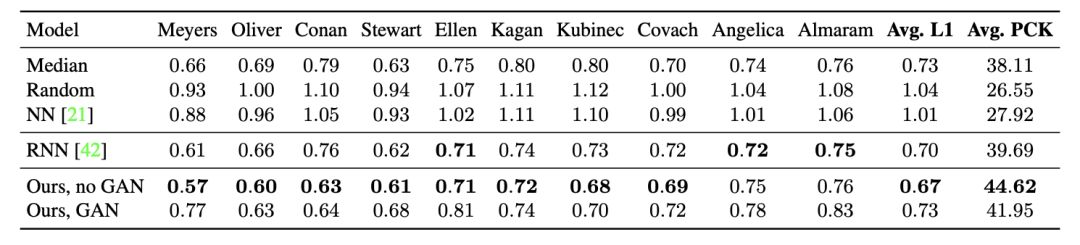
表1:在測試集上使用L1損失的語音到手勢轉換任務的定量結果(越低越好)

圖5:語音到手勢轉換的定性結果。我們展示了Dr. Kubinec(講師)和Conan O’Brien(節目主持人)的輸入音頻頻譜圖和預測手勢。
-
語音
+關注
關注
3文章
385瀏覽量
38062 -
鑒別器
+關注
關注
0文章
8瀏覽量
8772 -
AI算法
+關注
關注
0文章
251瀏覽量
12278
原文標題:你說話時的肢體動作,AI僅憑聲音就能預測 | CVPR 2019
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
中國移動與南京大學合作研發高保真2D數字人說話系統
將AIC33的DIN和DOUT腳用短路的方式實現自環時,說話的聲音稍微大點的時候,會在聲音上疊加一個“噼啪”聲,為什么?
將TPA31102D2板的音頻輸入與SPEAKER芯片連接時,說話聲很小失真很厲害,為什么?
可以將一個TLV320AIC3101的輸入與輸出端口的左右聲道分開使用嗎?
BitEnergy AI公司開發出一種新AI處理方法
云知聲說話人識別引擎獲得HUAWEI COMPATIBLE證書及認證徽標的使用權







 工商網監
工商網監
評論