


生成模型通常使用人工評估來確定和證明進展。不幸的是,現有的人類評估方法目前還沒有標準化,李飛飛等人ICLR2019論文構建人類眼睛感知評估(HYPE),帶給你新的認知。
HYPE是一種人類眼睛感知評估,它具有四大特點:
(1)以感知的心理物理學研究為基礎,
(2)在一個模型的不同隨機抽樣輸出集合中是可靠的,
(3)能夠產生可分離的模型性能,
(4)在成本和時間上是有效的。
我們引入了兩種變體:一種是在自適應時間約束下測量視覺感知,以確定模型輸出顯示為真實的閾值(例如250毫秒),另一種是在無時間約束的假圖像和真實圖像上測量人為錯誤率的較便宜變體。
我們測試了六種最先進的生成對抗網絡和兩種采樣技術,利用四種數據集(CelebA, FFHQ, CIFAR-10和ImageNet)生成有條件和無條件圖像。我們發現HYPE可以跟蹤模型之間的相對改進,并通過引導抽樣確認這些測量是一致且可復制的。
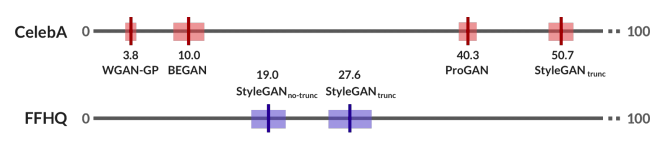
圖1:我們的人的評估指標,HYPE,可以一直區分彼此模型:這里,我們比較不同的生成模型在FFHQ上的表現。50%的分數代表取自真實的不可區分的結果,而50%以上的分數代表超現實。
我們進行了兩次大規模實驗。首先,在CelebA-64,我們通過四個生成對抗網絡(GANs)展示了HYPE在無條件人臉生成上的表現。我們還在FFHQ-1024上評估了的兩個較新的GANs。HYPE表明,GANs之間有明顯的、可測量的知覺差異;這種排名在HYPE和HYPE∞上都是相同的。表現最好的模型StyleGAN在FFHQ上接受了訓練,并使用截尾技巧(截斷技巧)進行了采樣,HYPE∞表現27.6%,這表明改進的機會很大。我們可以以60美元的價格用30名人工評估人員用10分鐘的時間重現這些結果,以95%的置信區間。
我們在ImageNet的和CIFAR-10數據集上對HYPE的性能進行了測試。當產生CIFAR-10時,像BEGAN這樣的早期GANs在HYPE∞中是不可分離的:它們沒有一個能產生令人信服的結果,證明這是一項比面部生成更困難的任務。較新的StyleGAN顯示出可分離的改進,這表明它比以前的模型有了進步。有了ImageNet-5,GANs已經改進了被認為“更容易”生成的類(例如檸檬),但在所有較難生成類(例如法國號)的模型中,它的分數始終較低。
對于研究人員來說,HYPE是一種快速的解決方案,可以測量他們的生成模型,只需點擊一下就可以得出可靠的分數并測量進展。
HYPE:人眼感知評價的基準
HYPE在Amazon Mechanical Turk上向眾包評估人員逐個顯示一系列圖像,并要求評估人員評估每個圖像是真是假。一半的圖像是真實圖像,從模型的訓練集(例如,FFHQ, CelebA, ImageNet或CIFAR-10)中繪制。另一半來自模型的輸出。我們使用現代眾包培訓和質量控制技術來確保高質量的標簽。模型創建者可以選擇執行兩種不同的評估:HYPEtime,它收集時間限制的感知閾值來測量心理測量功能并報告人們進行準確分類所需的最短時間;HYPE∞,一種簡單的方法,它在無時間限制的情況下評估人們的錯誤率。
圖2:使用在FFHQ上訓練的StyleGAN的截斷技巧采樣的示例圖像。右邊的圖像顯示出最高的HYPE∞分數,最高的人類感知。
HYPEtime:基于心理物理學的知覺保真度
我們的第一種方法,HYPEtime,測量時間限制的知覺閾值。它屬于心理學文獻,一個專門研究人類如何感知刺激的領域,在感知圖像時評估人類時間閾值。我們的評估方案遵循所謂的自適應階梯法(圖3)程序。圖像在有限的時間內被閃爍,之后評估者被要求判斷它是真是假。如果評估者一直回答正確,樓梯會下降并以更少的時間閃爍下一個圖像。如果評估者不正確,樓梯會上升并提供更多的時間。
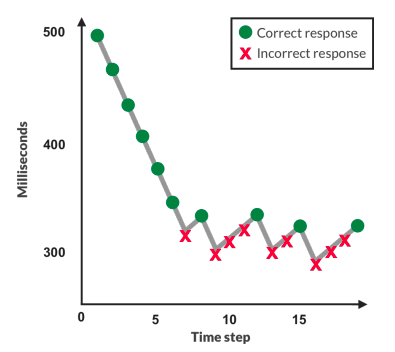
圖3:自適應階梯法向評估者顯示不同時間曝光的圖像。正確時減少,錯誤時增加。模態暴露測量他們的感知閾值。
這個過程需要足夠的迭代來收斂到評估者的感知閾值:他們能夠保持有效性能的最短曝光時間。這個過程產生了所謂的心理測量功能,即時間刺激暴露與準確性的關系。例如,對于一組易于識別的生成圖像,人類評估人員將立即降低到最低毫秒曝光。HYPEtime為每個評估者顯示三個樓梯塊。圖像評估從3-2-1倒計時時鐘開始,每個數字顯示500毫秒。然后顯示當前曝光時間的采樣圖像。每幅圖像后立即快速顯示四幅感知掩模圖像各30毫秒。這些噪聲面罩被扭曲,以防止圖像消失后的視網膜后像和進一步的感官處理。我們使用現有的紋理合成算法生成遮罩。每次提交報告時,HYPE都會向評估者揭示報告是否正確。圖像曝光范圍[100毫秒,1000毫秒],來源于感知文獻。所有塊從500毫秒開始,持續150個圖像(50%生成,50%真實),根據之前的工作經驗調整值。在3向上/1向下自適應階梯方法之后,曝光時間以10毫秒的增量增加,并以30毫秒的降幅減少,理論上這會導致接近人類感知閾值的75%精度閾值。每個評估人員在不同的圖像集上完成多個稱為塊的樓梯。因此,我們觀察到模型的多個度量。我們采用三個區塊,以平衡評估人員的疲勞。我們對各模塊的模態暴露時間進行平均,以計算每個評估者的最終值。分數越高表明模型越好,其輸出需要更長的時間曝光才能從真實圖像中辨別出來。
HYPE∞:成本效益近似
在前面的方法的基礎上,我們引入了HYPE∞:一種簡單、快速、廉價的方法,在除去HYPEtime后優化速度、成本和解釋的方便性。HYPE∞在給定的無限評估時間內,從感知時間的測量值轉變為人類欺騙率的測量值。HYPE∞分數測量任務的總誤差,使測量能夠捕獲假圖像和真實圖像上的誤差,以及假圖像看起來比真實圖像更逼真時超現實生成的效果。HYPE∞比HYPEtime需要更少的圖像才能找到穩定的值,經驗上可以減少6倍的時間和成本(每個評估者10分鐘,而不是60分鐘,同樣的速度是每小時12美元)。分數越高越好:10%的HYPE∞表示只有10%的圖像欺騙了人,而50%的人則表示人們偶然會誤認為真實和虛假圖像,從而使虛假圖像與真實圖像無法區分。超過50%的分數表明是超現實的圖像,因為評估者錯誤的圖像的概率大于偶然性。HYPE∞向每個評估者顯示總共100張圖像:50張真實圖像和50張假圖像。我們計算錯誤判斷的圖像比例,并將K圖像上n個評價者的判斷匯總,得出給定模型的最終得分。
設計一致可靠
為了確保我們報告的分數是一致和可靠的,我們需要從模型中充分抽樣,并雇用、鑒定和適當支付足夠的評估人員。
采樣足夠的模型輸出。從特定模型中選擇要評估的K圖像是公平和有用評估的關鍵組成部分。我們必須對足夠多的圖像進行采樣,以充分捕捉模型的生成多樣性,同時在評估中平衡這一點與可跟蹤成本。我們遵循現有的工作,通過從每個模型中抽取k=5000個生成圖像和從訓練集中抽取k=5000個真實圖像來評估生成輸出。從這些樣本中,我們隨機選擇要給每個評價者的圖像。
評估人員的質量。為了獲得一個高質量的評估人員庫,每個人都需要通過一個資格鑒定任務。這種任務前過濾方法,有時被稱為面向人的策略,其性能優于執行任務后數據過濾或處理的面向過程的策略。我們的鑒定任務顯示100個圖像(50個真實圖像和50個假圖像),沒有時間限制。評估人員必須正確分類65%的真實和虛假圖像。該閾值應被視為一個超參數,并可能根據教程中使用的GANs和所選評估者的期望識別能力而改變。我們根據100個答案中65個二項選擇答案的累積二項式概率選擇65%:只有千分之一的概率評價者有資格通過隨機猜測。
與任務本身不同的是,虛假的資格圖像是從多個不同的GANs抽取出的,以確保所有主體都具有公平的主體資格。資格鑒定是偶爾進行的,這樣一批評估人員就可以根據需要評估新的模型。
付款。評估人員的基本工資為1美元,用于完成資格鑒定任務。為了激勵評估人員在整個任務中保持參與,資格認證后的所有進一步薪酬都來自每幅正確標記的圖像0.02美元的獎金,通常總計工資為12美元/小時。
實驗1:人臉的HYPEtime和HYPE∞
我們報告了HYPEtime的結果,并證明HYPE∞的結果與HYPEtime的結果接近,只是成本和時間的一小部分。
HYPEtime
CelebA-64。我們發現StyleGANtrunc的HYPE得分最高(模式曝光時間),平均為439.3毫秒,這表明評估者需要近半秒的曝光來準確分類StyleGANtrunc圖像(表??)StyleGANtrunc之后是ProGAN,速度為363.7毫秒,時間下降17%。BEGAN 和WGAN-GP都很容易被識別為假的,因此它們在可用的最小曝光時間100毫秒左右排在第三位。BEGAN 和WGAN-GP都表現出一種觸底效應——快速一致地達到最小曝光時間100毫秒。
為了證明模型之間的可分性,我們報告了單向方差分析(ANOVA)測試的結果,其中每個模型的輸入是每個模型的30個評估者的模式列表。ANOVA結果證實存在統計學上顯著的綜合差異(F(3,29)=83.5,P<0.0001)。使用Tukey測試進行的成對事后分析證實,除了BEGAN 和?WGAN-GP (n.s.).之外,所有模型對都是可分離的(所有p<0.05)。
FFHQ-1024.我們發現,StyleGANtrunc的曝光時間比StyleGANno-trunc高,分別為363.2 毫秒和240.7 毫秒(表1)。雖然95%的置信區間代表2.7 毫秒的保守重疊,但未配對的t-test證實兩種模型之間的差異是顯著的(t(58)=2.3,p=0.02)。
HYPE常數
CelebA-64。表2是CelebA-64的HYPE∞結果。我們發現StyleGANtrunc使得HYPE∞得分最高,50.7%會欺騙評估者。StyleGANtrunc之后是ProGAN,為40.3%,開始于10.0%,WGAN-GP為3.8%。無重疊的置信區間,方差分析檢驗顯著(F(3,29)=404.4,P<0.001)。成對的事后Tukey檢驗表明,所有的模型對都是可分離的(p<0.05)。值得注意的是,HYPE∞導致了BEGAN 和?WGAN-GP的可分離結果,而在HYPEtime中,由于自下而上的影響,它們不可分離。

表2:在CelebA-64上訓練的四個GANs上的HYPE∞。與直覺相反,真實誤差隨著假圖像上的誤差而增加,因為評價者變得更加困惑,兩種分布之間的區分因素變得更加難以辨別。
FFHQ-1024.我們觀察到StyleGANtrunc和StyleGANno-trunc之間的一致可分離性差異,以及模型之間的清晰輪廓(表3)。HYPE∞將StyleGANtrunc(27.6%)排在StyleGANtrunc(19.0%)之上,沒有重疊的CIs。可分離性通過未配對t檢驗(t(58)=8.3,p<0.001)得到確認。

表3:FFHQ-1024培訓的StyleGANtrunc和StyleGANno-trunc上的HYPE∞。評價者經常被StyleGANtrunc欺騙。
準確度和時間的成本權衡
HYPE的目標之一是節約成本和時間。當運行HYPE時,在準確性和時間以及準確性和成本之間有一個內在的權衡。這是由大量法律驅動的:在眾包任務中招聘額外的評估人員通常會產生更一致的結果,但成本更高(因為每個評估人員的工作都是付費的),而且完成的時間更長(因為必須招聘更多的評估人員,并且必須完成他們的工作)。
為了處理這種權衡,我們在StyleGANtrunc上運行了一個HYPE∞實驗。我們用60個評估者完成了一個額外的評估,并計算了95%的自舉置信區間,從10到120個評估者中進行選擇(圖4)。我們看到CI開始聚集大約30名評估人員,這是我們推薦的要招聘的評估人員數量。
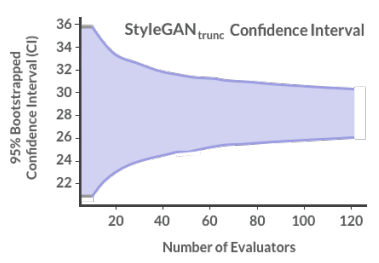
圖4:更多評估者對CI的影響
對評估人員的付款按照“方法”一節中的描述進行計算。在30個評估者中,在一個模型上運行HYPEtime的成本約為360美元,而在同一個模型上運行HYPE∞的成本約為60美元。兩項任務的每個評估人員的報酬約為12美元/小時,評估人員平均花在一項HYPE任務上的時間為一小時,在HYPE∞任務上花費的時間為10分鐘。因此,HYPE∞的目標是在保持一致性的同時,運行起來要比HYPEtime便宜得多。
與自動化指標的比較
由于FID是最常用的無條件圖像生成評估方法之一,因此有必要在相同的模型上將HYPE與FID進行比較。我們還比較了兩個新的自動化指標:KID,一個獨立于樣本大小的無偏估計量,以及F1/8(精度),它獨立的捕獲保真度。我們通過Spearman秩次相關系數表明,HYPE分數與FID不相關(ρ=-0.029,p=0.96),其中-1.0的Spearman相關性是理想的,因為較低的FID和較高的HYPE分數表示更強的模型。因此,我們發現,FID與人類的判斷并不高度相關。同時,HYPE時間和HYPE∞之間具有很強的相關性(ρ=1.0,p=0.0),其中1.0是理想的,因為它們是直接相關的。我們通過評估CelebA-64和FFHQ-1024的50K生成和50K真實圖像的標準協議計算FID,重現StyleGANno-trunc的分數。Kid(ρ=?0.609,p=0.20)和精度(ρ=0.657,p=0.16)均顯示出與人類的統計上不顯著但中等水平的相關性。
模型訓練時的HYPE∞
HYPE也可以用來評估模型培訓的進展。我們發現隨著StyleGAN訓練的進展,HYPE∞分數從4k時的29.5%上升到9k時的45.9%,到25k時的50.3%(f(2,29)=63.3,p<0.001)。
實驗2:人臉以外的HYPE∞
現在我們轉到另一個流行的圖像生成任務:對象。實驗1表明,HYPE∞是HYPEtime的一個有效且具有成本效益的變體,這里我們只關注HYPE∞。
ImageNet-5
我們評估了五個ImageNet類上的條件圖像生成(表4)。我們還報告了FID、KID和F1/8(精度分數。為了評估每個對象類中三個GAN的相對有效性,我們計算了五個單向方差分析,每個對象類一個方差分析。我們發現,對于來自三個簡單類的圖像,HYPE∞分數是可分離的:薩摩耶(狗)(F(2,29)=15.0,p<0.001),檸檬(F(2,29)=4.2,p=0.017),和圖書館(F(2,29)=4.9,p=0.009)。配對后驗表明,這一差異僅在SN-GAN和兩個BigGAN變體之間有顯著性。我們還觀察到,模型具有不同的優勢,例如SN-GAN更適合生成圖書館而不是薩摩耶。
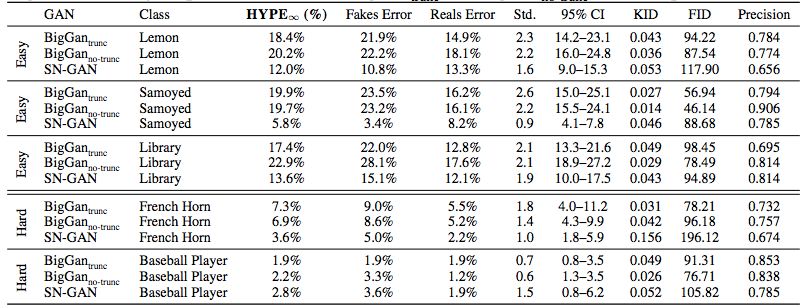
表4:在ImageNet上訓練的三個模型上的HYPE∞和在五種類別里有條件抽樣。BigGAN的表現通常優于SN-GAN。BigGANtrunc和BigGANno-trunc不可分離。
與自動化指標的比較。所有三個GANs的Spearman秩次相關系數在所有五個分類中均顯示,HYPE∞分數與KID(ρ=-0.377,p=0.02)、FID(ρ=-0.282,p=0.01)之間存在一個低到中等的相關性,與精度的相關性可忽略不計(ρ=-0.067,p=0.81)。我們的ImageNet-5任務需要一些相關性,因為這些度量使用預訓練的ImageNet嵌入來測量生成數據和實際數據之間的差異。
有趣的是,我們發現這種相關性依賴于GAN:僅考慮SN-GAN,我們發現KID(ρ=?0.500,p=0.39)、FID(ρ=?0.300,p=0.62)和精度(ρ=?0.205,p=0.74)的系數更強。當只考慮BigGAN時,我們發現FID(ρ=?0.151,p=0.68)、FID(ρ=?0.067,p=0.85)和精度(ρ=?0.164,p=0.65)的系數要弱得多。這說明了這些自動度量的一個重要缺陷:它們與人類關聯的能力取決于度量正在評估的生成模型,根據模型和任務而變化。
CIFAR-10
針對CIFAR-10上無條件生成的困難任務,我們在實驗1中使用了相同的四種模型體系結構:CelebA-64。表5顯示HYPE∞能夠將StyleGANtrunc與早期的BEGAN, WGAN-GP, 和ProGAN分離,這表明StyleGAN是其中第一個在CIFAR-10無條件對象生成方面取得人類可感知進展的。

表5:CIFAR-10上的四種型號。StyleGANtrunc可以從CIFAR-10生成逼真的圖像。
與自動化指標的比較。所有四個GAN的Spearman秩次相關系數均為中等,但統計學上不顯著,與KID(ρ=-0.600,p=0.40)和FID(ρ=0.600,p=0.40)和精度(ρ=-800,p=0.20)的相關性。
討論與結論
預期用途。我們創造了一個HYPE作為解決方案,人類對生成模型的評估。研究人員可以上傳他們的模型,獲得分數,并通過我們的在線部署比較進展。在高使用率期間(如比賽),retainer模式允許在10分鐘內使用HYPE∞進行評估,而不是默認的30分鐘。
局限性:HYPE的擴展可能需要不同的任務設計。在文本生成(翻譯、標題生成)的情況下,HYPE需要對感知時間閾值進行更長、更大范圍的調整。除了測量真實性之外,其他指標,如多樣性、過度擬合、糾纏度、訓練穩定性、計算和樣本效率,都是可以納入但不在本文范圍內的額外基準。有些可能更適合全自動評估。
結論:HYPE為生成模型提供了兩個人類評估基準:
(1)以心理物理學為基礎,
(2)提供產生可靠結果的任務設計,
(3)單獨的模型性能,
(4)具有成本和時間效率。
我們引入兩個基準:使用時間感知閾值的HYPEtime和報告無時間限制的錯誤率的HYPE∞。我們展示了我們的方法在六種模型中的圖像生成效果:StyleGAN、Sn-GAN、BigGAN、ProGAN、Begin、WGAN-gp、四種圖像數據集Celeba-64、FFHQ-1024、CIFAR-10、ImageNet-5,以及兩種采樣方法。{有、無截斷技巧}。
-
圖像
+關注
關注
2文章
1094瀏覽量
41340 -
數據集
+關注
關注
4文章
1224瀏覽量
25478 -
李飛飛
+關注
關注
0文章
20瀏覽量
3700
原文標題:李飛飛等ICLR2019論文:構建人類眼睛感知評估
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
人類視覺感知方式對VR的挑戰
認知無線電頻譜感知與分配技術
谷歌AI中國中心落地北京 李飛飛、李佳率領
李開復對話李飛飛:人工智能帶來的改變很大但還不能理解復雜的知識
人工智能首席科學家李飛飛代表谷歌發布新API產品
李飛飛卸任斯坦福AI負責人 “以人為本”新項目啟動
李飛飛又多了一個新的身份——斯坦福以人為本人工智能研究院的聯合主任
ICLR 2019在官網公布了最佳論文獎!

ICLR 2019最佳論文日前揭曉 微軟與麻省等獲最佳論文獎項
Chip Huyen總結ICLR 2019年的8大趨勢 RNN正在失去研究的光芒
CVPR 2019最佳論文公布了:來自CMU的辛書冕等人合作的論文獲得最佳論文獎
近日,李飛飛接受CNBC專訪:認為智能和價值觀都可以由人類灌輸給機器
系統從感知到認知的意義

李飛飛最新解碼空間智能,DePIN破局最后一米,AIoT即將綻放異彩






 工商網監
工商網監

評論