") 碾壓Bert?“屠榜”的XLnet對NLP任務意味著什么
碾壓Bert?“屠榜”的XLnet對NLP任務意味著什么
這兩天,XLNet貌似也引起了NLP圈的極大關注,從實驗數(shù)據(jù)看,在某些場景下,確實XLNet相對Bert有很大幅度的提升。就像我們之前說的,感覺Bert打開兩階段模式的魔法盒開關后,在這條路上,會有越來越多的同行者,而XLNet就是其中比較引人注目的一位。當然,我估計很快我們會看到更多的這個模式下的新工作。
未來兩年,在兩階段新模式(預訓練+Finetuning)下,應該會有更多的好工作涌現(xiàn)出來。根本原因在于:這個模式的潛力還沒有被充分挖掘,貌似還有很大的提升空間。當然,這也意味著NLP在未來兩年會有各種技術或者應用的突破,現(xiàn)在其實是進入NLP領域非常好的時機。原因有兩個,一個是NLP正面臨一個技術棧大的改朝換代的時刻,有很多空白等著你去填補,容易出成績;另外一點,貌似Bert+Transformer有統(tǒng)一NLP各個應用領域的趨向,這意味著此時進入NLP領域,具備學習成本非常低的好處,和之前相比,投入產(chǎn)出比非常合算。
當然,即使如此,想要學好NLP,持續(xù)的精力投入是必不可少的。有句老話說得好:“永恒的愛大約持續(xù)三個月”,這句話其實對于很多對NLP感興趣的同學也成立:“對NLP的永恒的熱情大約能夠持續(xù)3到5天”,希望真的有興趣的同學能堅持一下,起碼持續(xù)7到8天,湊夠一個星期…..
那么XLNet和Bert比,有什么異同?有什么模型方面的改進?在哪些場景下特別有效?原因又是什么?本文通過論文思想解讀及實驗結果分析,試圖回答上述問題。
首先,XLNet引入了自回歸語言模型以及自編碼語言模型的提法,這個思維框架我覺得挺好的,可以先簡單說明下。
自回歸語言模型(Autoregressive LM)
在ELMO/BERT出來之前,大家通常講的語言模型其實是根據(jù)上文內容預測下一個可能跟隨的單詞,就是常說的自左向右的語言模型任務,或者反過來也行,就是根據(jù)下文預測前面的單詞,這種類型的LM被稱為自回歸語言模型。GPT 就是典型的自回歸語言模型。ELMO盡管看上去利用了上文,也利用了下文,但是本質上仍然是自回歸LM,這個跟模型具體怎么實現(xiàn)有關系。ELMO是做了兩個方向(從左到右以及從右到左兩個方向的語言模型),但是是分別有兩個方向的自回歸LM,然后把LSTM的兩個方向的隱節(jié)點狀態(tài)拼接到一起,來體現(xiàn)雙向語言模型這個事情的。所以其實是兩個自回歸語言模型的拼接,本質上仍然是自回歸語言模型。
自回歸語言模型有優(yōu)點有缺點,缺點是只能利用上文或者下文的信息,不能同時利用上文和下文的信息,當然,貌似ELMO這種雙向都做,然后拼接看上去能夠解決這個問題,因為融合模式過于簡單,所以效果其實并不是太好。它的優(yōu)點,其實跟下游NLP任務有關,比如生成類NLP任務,比如文本摘要,機器翻譯等,在實際生成內容的時候,就是從左向右的,自回歸語言模型天然匹配這個過程。而Bert這種DAE模式,在生成類NLP任務中,就面臨訓練過程和應用過程不一致的問題,導致生成類的NLP任務到目前為止都做不太好。
自編碼語言模型(Autoencoder LM)
自回歸語言模型只能根據(jù)上文預測下一個單詞,或者反過來,只能根據(jù)下文預測前面一個單詞。相比而言,Bert通過在輸入X中隨機Mask掉一部分單詞,然后預訓練過程的主要任務之一是根據(jù)上下文單詞來預測這些被Mask掉的單詞,如果你對Denoising Autoencoder比較熟悉的話,會看出,這確實是典型的DAE的思路。那些被Mask掉的單詞就是在輸入側加入的所謂噪音。類似Bert這種預訓練模式,被稱為DAE LM。
這種DAE LM的優(yōu)缺點正好和自回歸LM反過來,它能比較自然地融入雙向語言模型,同時看到被預測單詞的上文和下文,這是好處。缺點是啥呢?主要在輸入側引入[Mask]標記,導致預訓練階段和Fine-tuning階段不一致的問題,因為Fine-tuning階段是看不到[Mask]標記的。DAE嗎,就要引入噪音,[Mask] 標記就是引入噪音的手段,這個正常。
XLNet的出發(fā)點就是:能否融合自回歸LM和DAE LM兩者的優(yōu)點。就是說如果站在自回歸LM的角度,如何引入和雙向語言模型等價的效果;如果站在DAE LM的角度看,它本身是融入雙向語言模型的,如何拋掉表面的那個[Mask]標記,讓預訓練和Fine-tuning保持一致。當然,XLNet還講到了一個Bert被Mask單詞之間相互獨立的問題,我相信這個不太重要,原因后面會說。當然,我認為這點不重要的事情,純粹是個人觀點,出錯難免,看看就完了,不用較真。
XLNet做了些什么
上文說過,Bert這種自編碼語言模型的好處是:能夠同時利用上文和下文,所以信息利用充分。對于很多NLP任務而言,典型的比如閱讀理解,在解決問題的時候,是能夠同時看到上文和下文的,所以當然應該把下文利用起來。
在Bert原始論文中,與GPT1.0的實驗對比分析也可以看出來,BERT相對GPT 1.0的性能提升,主要來自于雙向語言模型與單向語言模型的差異。這是Bert的好處,很明顯,Bert之后的改進模型,如果不能把雙向語言模型用起來,那明顯是很吃虧的。
當然,GPT 2.0的作者不信這個邪,堅持沿用GPT 1.0 單向語言模型的舊瓶,裝進去了更高質量更大規(guī)模預訓練數(shù)據(jù)的新酒,而它的實驗結果也說明了,如果想改善預訓練語言模型,走這條擴充預序列模型訓練數(shù)據(jù)的路子,是個多快好但是不省錢的方向。這也進一步說明了,預訓練LM這條路,還遠遠沒有走完,還有很大的提升空間,比如最簡單的提升方法就是加大數(shù)據(jù)規(guī)模,提升數(shù)據(jù)質量。
但是Bert的自編碼語言模型也有對應的缺點,就是XLNet在文中指出的,第一個預訓練階段因為采取引入[Mask]標記來Mask掉部分單詞的訓練模式,而Fine-tuning階段是看不到這種被強行加入的Mask標記的,所以兩個階段存在使用模式不一致的情形,這可能會帶來一定的性能損失;另外一個是,Bert在第一個預訓練階段,假設句子中多個單詞被Mask掉,這些被Mask掉的單詞之間沒有任何關系,是條件獨立的,而有時候這些單詞之間是有關系的,XLNet則考慮了這種關系(關于這點原因是否可靠,后面會專門分析)。
上面兩點是XLNet在第一個預訓練階段,相對Bert來說要解決的兩個問題。
其實從另外一個角度更好理解XLNet的初衷和做法,我覺得這個估計是XLNet作者真正的思考出發(fā)點,是啥呢?就是說自回歸語言模型有個缺點,要么從左到右,要么從右到左,盡管可以類似ELMO兩個都做,然后再拼接的方式。但是跟Bert比,效果明顯不足夠好(這里面有RNN弱于Transformer的因素,也有雙向語言模型怎么做的因素)。
那么,能不能類似Bert那樣,比較充分地在自回歸語言模型中,引入雙向語言模型呢?因為Bert已經(jīng)證明了這是非常關鍵的一點。這一點,想法簡單,但是看上去貌似不太好做,因為從左向右的語言模型,如果我們當前根據(jù)上文,要預測某個單詞Ti,那么看上去它沒法看到下文的內容。具體怎么做才能讓這個模型:看上去仍然是從左向右的輸入和預測模式,但是其實內部已經(jīng)引入了當前單詞的下文信息呢?XLNet在模型方面的主要貢獻其實是在這里。
那么XLNet是怎么做到這一點的呢?其實思路也比較簡潔,可以這么思考:XLNet仍然遵循兩階段的過程,第一個階段是語言模型預訓練階段;第二階段是任務數(shù)據(jù)Fine-tuning階段。它主要希望改動第一個階段,就是說不像Bert那種帶Mask符號的Denoising-autoencoder的模式,而是采用自回歸LM的模式。
就是說,看上去輸入句子X仍然是自左向右的輸入,看到Ti單詞的上文Context_before,來預測Ti這個單詞。但是又希望在Context_before里,不僅僅看到上文單詞,也能看到Ti單詞后面的下文Context_after里的下文單詞,這樣的話,Bert里面預訓練階段引入的Mask符號就不需要了,于是在預訓練階段,看上去是個標準的從左向右過程,F(xiàn)ine-tuning當然也是這個過程,于是兩個環(huán)節(jié)就統(tǒng)一起來。當然,這是目標。剩下是怎么做到這一點的問題。

那么,怎么能夠在單詞Ti的上文中Contenxt_before中揉入下文Context_after的內容呢?你可以想想。XLNet是這么做的,在預訓練階段,引入Permutation Language Model的訓練目標。什么意思呢?
就是說,比如包含單詞Ti的當前輸入的句子X,由順序的幾個單詞構成,比如x1,x2,x3,x4四個單詞順序構成。我們假設,其中,要預測的單詞Ti是x3,位置在Position 3,要想讓它能夠在上文Context_before中,也就是Position 1或者Position 2的位置看到Position 4的單詞x4。可以這么做:假設我們固定住x3所在位置,就是它仍然在Position 3,之后隨機排列組合句子中的4個單詞,在隨機排列組合后的各種可能里,再選擇一部分作為模型預訓練的輸入X。比如隨機排列組合后,抽取出x4,x2,x3,x1這一個排列組合作為模型的輸入X。于是,x3就能同時看到上文x2,以及下文x4的內容了。
這就是XLNet的基本思想,所以說,看了這個就可以理解上面講的它的初衷了吧:看上去仍然是個自回歸的從左到右的語言模型,但是其實通過對句子中單詞排列組合,把一部分Ti下文的單詞排到Ti的上文位置中,于是,就看到了上文和下文,但是形式上看上去仍然是從左到右在預測后一個單詞。

當然,上面講的仍然是基本思想。難點其實在于具體怎么做才能實現(xiàn)上述思想。首先,需要強調一點,盡管上面講的是把句子X的單詞排列組合后,再隨機抽取例子作為輸入,但是,實際上你是不能這么做的,因為Fine-tuning階段你不可能也去排列組合原始輸入。所以,就必須讓預訓練階段的輸入部分,看上去仍然是x1,x2,x3,x4這個輸入順序,但是可以在Transformer部分做些工作,來達成我們希望的目標。
具體而言,XLNet采取了Attention掩碼的機制,你可以理解為,當前的輸入句子是X,要預測的單詞Ti是第i個單詞,前面1到i-1個單詞,在輸入部分觀察,并沒發(fā)生變化,該是誰還是誰。但是在Transformer內部,通過Attention掩碼,從X的輸入單詞里面,也就是Ti的上文和下文單詞中,隨機選擇i-1個,放到Ti的上文位置中,把其它單詞的輸入通過Attention掩碼隱藏掉,于是就能夠達成我們期望的目標(當然這個所謂放到Ti的上文位置,只是一種形象的說法,其實在內部,就是通過Attention Mask,把其它沒有被選到的單詞Mask掉,不讓它們在預測單詞Ti的時候發(fā)生作用,如此而已。看著就類似于把這些被選中的單詞放到了上文Context_before的位置了)。
具體實現(xiàn)的時候,XLNet是用“雙流自注意力模型”實現(xiàn)的,細節(jié)可以參考論文,但是基本思想就如上所述,雙流自注意力機制只是實現(xiàn)這個思想的具體方式,理論上,你可以想出其它具體實現(xiàn)方式來實現(xiàn)這個基本思想,也能達成讓Ti看到下文單詞的目標。
這里簡單說下“雙流自注意力機制”,一個是內容流自注意力,其實就是標準的Transformer的計算過程;主要是引入了Query流自注意力,這個是干嘛的呢?
其實就是用來代替Bert的那個[Mask]標記的,因為XLNet希望拋掉[Mask]標記符號,但是比如知道上文單詞x1,x2,要預測單詞x3,此時在x3對應位置的Transformer最高層去預測這個單詞,但是輸入側不能看到要預測的單詞x3,Bert其實是直接引入[Mask]標記來覆蓋掉單詞x3的內容的,等于說[Mask]是個通用的占位符號。
而XLNet因為要拋掉[Mask]標記,但是又不能看到x3的輸入,于是Query流,就直接忽略掉x3輸入了,只保留這個位置信息,用參數(shù)w來代表位置的embedding編碼。其實XLNet只是扔了表面的[Mask]占位符號,內部還是引入Query流來忽略掉被Mask的這個單詞。和Bert比,只是實現(xiàn)方式不同而已。
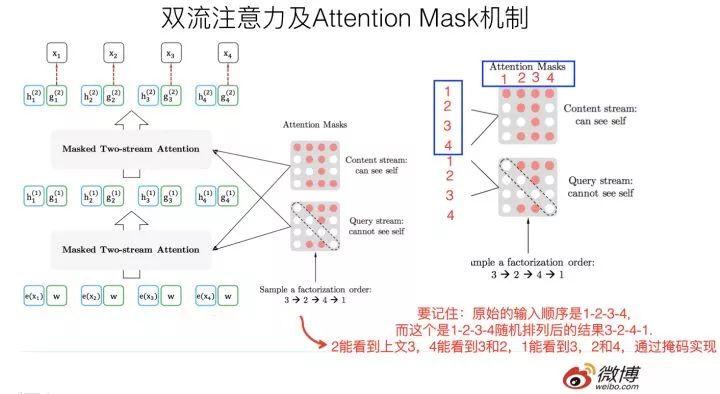
上面說的Attention掩碼,我估計你還是沒了解它的意思,我再用例子解釋一下。Attention Mask的機制,核心就是說,盡管當前輸入看上去仍然是x1->x2->x3->x4,但是我們已經(jīng)改成隨機排列組合的另外一個順序x3->x2->x4->x1了,如果用這個例子用來從左到右訓練LM,意味著當預測x2的時候,它只能看到上文x3;當預測x4的時候,只能看到上文x3和x2,以此類推……這樣,比如對于x2來說,就看到了下文x3了。
這種在輸入側維持表面的X句子單詞順序,但是其實在Transformer內部,看到的已經(jīng)是被重新排列組合后的順序,是通過Attention掩碼來實現(xiàn)的。如上圖所示,輸入看上去仍然是x1,x2,x3,x4,可以通過不同的掩碼矩陣,讓當前單詞Xi只能看到被排列組合后的順序x3->x2->x4->x1中自己前面的單詞。這樣就在內部改成了被預測單詞同時看到上下文單詞,但是輸入側看上去仍然維持原先的單詞順序了。
關鍵要看明白上圖右側那個掩碼矩陣,我相信很多人剛開始沒看明白,因為我剛開始也沒看明白,因為沒有標出掩碼矩陣的單詞坐標,它的坐標是1-2-3-4,就是表面那個X的單詞順序,通過掩碼矩陣,就能改成你想要的排列組合,并讓當前單詞看到它該看到的所謂上文,其實是摻雜了上文和下文的內容。這是attention mask來實現(xiàn)排列組合的背后的意思。
上面講的Permutation Language Model是XLNet的主要理論創(chuàng)新,所以介紹的比較多,從模型角度講,這個創(chuàng)新還是挺有意思的,因為它開啟了自回歸語言模型如何引入下文的一個思路,相信對于后續(xù)工作會有啟發(fā)。當然,XLNet不僅僅做了這些,它還引入了其它的因素,也算是一個當前有效技術的集成體。
感覺XLNet就是Bert、GPT 2.0和Transformer XL的綜合體變身,首先,它通過PLM預訓練目標,吸收了Bert的雙向語言模型;然后,GPT2.0的核心其實是更多更高質量的預訓練數(shù)據(jù),這個明顯也被XLNet吸收進來了;再然后,Transformer XL的主要思想也被吸收進來,它的主要目標是解決Transformer對于長文檔NLP應用不夠友好的問題。
以上是XLNet的幾個主要改進點,有模型創(chuàng)新方面的,有其它模型引入方面的,也有數(shù)據(jù)擴充方面的。那么,這些因素各自起到了什么作用呢?在后面我們會談。在談不同因素各自作用之前,我們先分析下XLNet和Bert的異同問題。
與 Bert 的預訓練過程的異同問題
盡管看上去,XLNet在預訓練機制引入的Permutation Language Model這種新的預訓練目標,和Bert采用Mask標記這種方式,有很大不同。其實你深入思考一下,會發(fā)現(xiàn),兩者本質是類似的。區(qū)別主要在于:Bert是直接在輸入端顯示地通過引入Mask標記,在輸入側隱藏掉一部分單詞,讓這些單詞在預測的時候不發(fā)揮作用,要求利用上下文中其它單詞去預測某個被Mask掉的單詞;而XLNet則拋棄掉輸入側的Mask標記,通過Attention Mask機制,在Transformer內部隨機Mask掉一部分單詞(這個被Mask掉的單詞比例跟當前單詞在句子中的位置有關系,位置越靠前,被Mask掉的比例越高,位置越靠后,被Mask掉的比例越低),讓這些被Mask掉的單詞在預測某個單詞的時候不發(fā)生作用。
所以,本質上兩者并沒什么太大的不同,只是Mask的位置,Bert更表面化一些,XLNet則把這個過程隱藏在了Transformer內部而已。這樣,就可以拋掉表面的[Mask]標記,解決它所說的預訓練里帶有[Mask]標記導致的和Fine-tuning過程不一致的問題。至于說XLNet說的,Bert里面被Mask掉單詞的相互獨立問題,也就是說,在預測某個被Mask單詞的時候,其它被Mask單詞不起作用,這個問題,你深入思考一下,其實是不重要的,因為XLNet在內部Attention Mask的時候,也會Mask掉一定比例的上下文單詞,只要有一部分被Mask掉的單詞,其實就面臨這個問題。
而如果訓練數(shù)據(jù)足夠大,其實不靠當前這個例子,靠其它例子,也能彌補被Mask單詞直接的相互關系問題,因為總有其它例子能夠學會這些單詞的相互依賴關系。
我相信,通過改造Bert的預訓練過程,其實是可以模擬XLNet的Permutation Language Model過程的:Bert目前的做法是,給定輸入句子X,隨機Mask掉15%的單詞,然后要求利用剩下的85%的單詞去預測任意一個被Mask掉的單詞,被Mask掉的單詞在這個過程中相互之間沒有發(fā)揮作用。
如果我們把Bert的預訓練過程改造成:對于輸入句子,隨機選擇其中任意一個單詞Ti,只把這個單詞改成Mask標記,假設Ti在句子中是第i個單詞,那么此時隨機選擇X中的任意i個單詞,只用這i個單詞去預測被Mask掉的單詞。
當然,這個過程理論上也可以在Transformer內采用attention mask來實現(xiàn)。如果是這樣,其實Bert的預訓練模式就和XLNet是基本等價的了。
或者換個角度思考,假設仍然利用Bert目前的Mask機制,但是把Mask掉15%這個條件極端化,改成,每次一個句子只Mask掉一個單詞,利用剩下的單詞來預測被Mask掉的單詞。那么,這個過程其實跟XLNet的PLM也是比較相像的,區(qū)別主要在于每次預測被Mask掉的單詞的時候,利用的上下文更多一些(XLNet在實現(xiàn)的時候,為了提升效率,其實也是選擇每個句子最后末尾的1/K單詞被預測,假設K=7,意味著一個句子X,只有末尾的1/7的單詞會被預測,這意味著什么呢?意味著至少保留了6/7的Context單詞去預測某個單詞,對于最末尾的單詞,意味著保留了所有的句子中X的其它單詞,這其實和上面提到的Bert只保留一個被Mask單詞是一樣的)。
或者我們站在Bert預訓練的角度來考慮XLNet,如果XLNet改成對于句子X,只需要預測句子中最后一個單詞,而不是最后的1/K(就是假設K特別大的情況),那么其實和Bert每個輸入句子只Mask掉一個單詞,兩者基本是等價的。
當然,XLNet這種改造,維持了表面看上去的自回歸語言模型的從左向右的模式,這個Bert做不到,這個有明顯的好處,就是對于生成類的任務,能夠在維持表面從左向右的生成過程前提下,模型里隱含了上下文的信息。
所以看上去,XLNet貌似應該對于生成類型的NLP任務,會比Bert有明顯優(yōu)勢。另外,因為XLNet還引入了Transformer XL的機制,所以對于長文檔輸入類型的NLP任務,也會比Bert有明顯優(yōu)勢。
哪些因素在起作用?
如上分析,XLNet有個好處,但是感覺同時也是個問題,那就是:XLNet其實同時引入了很多因素在模型里。說是好處,因為實驗證明了這樣效果確實好,即使是跟Bert_Large這種非常強的基準模型比也是,尤其是長文檔任務,這個效果提升比較明顯;說是問題,是因為其實應該在實驗部分充分說明,如果模型起了作用,這些因素各自發(fā)揮了多大作用,尤其是在跟Bert進行對比的時候,感覺應該把數(shù)據(jù)規(guī)模這個變量磨平進行比較,因為這才是單純的模型差異導致的性能差異,而不是訓練數(shù)據(jù)量引發(fā)的差異。
當然,XLNet最后一組實驗是把這個預訓練數(shù)據(jù)規(guī)模差異磨平后,和Bert比較的,所以信息含量更大些。而前面的幾組實驗,因為天然存在預訓練數(shù)據(jù)量的差異,所以模型導致的差異到底有多大,看得不太明顯。
我們上文提到過,XLNet起作用的,如果宏觀歸納一下,共有三個因素;
1. 與Bert采取De-noising Autoencoder方式不同的新的預訓練目標:Permutation Language Model(簡稱PLM);這個可以理解為在自回歸LM模式下,如何采取具體手段,來融入雙向語言模型。這個是XLNet在模型角度比較大的貢獻,確實也打開了NLP中兩階段模式潮流的一個新思路。
2. 引入了Transformer-XL的主要思路:相對位置編碼以及分段RNN機制。實踐已經(jīng)證明這兩點對于長文檔任務是很有幫助的;
3. 加大增加了預訓練階段使用的數(shù)據(jù)規(guī)模;Bert使用的預訓練數(shù)據(jù)是BooksCorpus和英文Wiki數(shù)據(jù),大小13G。XLNet除了使用這些數(shù)據(jù)外,另外引入了Giga5,ClueWeb以及Common Crawl數(shù)據(jù),并排掉了其中的一些低質量數(shù)據(jù),大小分別是16G,19G和78G。可以看出,在預訓練階段極大擴充了數(shù)據(jù)規(guī)模,并對質量進行了篩選過濾。這個明顯走的是GPT2.0的路線。
所以實驗部分需要仔細分析,提升到底是上述哪個因素或者是哪幾個因素導致的性能提升?
我們把實驗分成幾個部分來分析。
首先,給人最大的印象是:XLNet對于閱讀理解類任務,相對Bert,性能有極大幅度地提升。下面是論文報道的實驗結果:


其中,RACE和SQuAD 2.0是文檔長度較長的閱讀理解任務,任務難度也相對高。可以看出,在這兩個任務中,XLNet相對 Bert_Large,確實有大幅性能提升(Race提升13.5%,SQuAD 2.0 F1指標提升8.6)。在Squad1.1上提升盡管稍微小些,F(xiàn)1提升3.9%,但是因為基準高,所以提升也比較明顯。
說XLNet在閱讀理解,尤其是長文檔的閱讀理解中,性能大幅超過Bert,這個是沒疑問的。但是,因為XLNet融入了上文說的三個因素,所以不確定每個因素在其中起的作用有多大,而對于長文檔,Transformer XL的引入肯定起了比較大的作用,Bert天然在這種類型任務中有缺點,其它兩類因素的作用不清楚。
感覺這里應該增加一個基準,就是Bert用與XLNet相同大小的預訓練數(shù)據(jù)做,這樣抹平數(shù)據(jù)量差異,更好比較模型差異帶來的效果差異。當然,我覺得即使是這樣,XLNet應該仍然是比Bert效果好的,只是可能不會差距這么大,因為XLNet的長文檔優(yōu)勢肯定會起作用。
下面我們看下其它類型的NLP任務。

GLUE是個綜合的NLP任務集合,包含各種類型的任務,因為ensemble模式里面包含了各種花式的trick,所以重點看上面一組實驗,這里比較單純。從實驗數(shù)據(jù)看,XLNet相對Bert也有性能提升,當然不像閱讀理解提升那么大,而且性能提升比較大的集中在RTE,MNLI和COLA數(shù)據(jù)集合,其它任務提升效果還好。
而我一直覺得,RTE在GLUE里,是個神奇的存在,如果沒有它,很多論文的效果可能沒法看,這個是閑話,先不講了,后面我會單說。
當然,仍然不確定這種性能提升主要來自于XLNet的哪個因素,或者哪幾個因素各自的貢獻,尤其是如果Bert加大預訓練數(shù)據(jù)規(guī)模后,兩者性能差異有多大。感覺這里Transformer XL的因素可能發(fā)揮的作用不會太大,其它兩個因素在起作用,但是作用未知,這里感覺應該補充其它實驗。
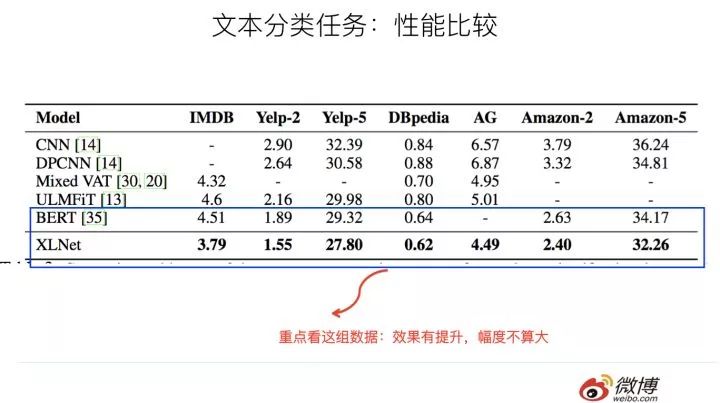
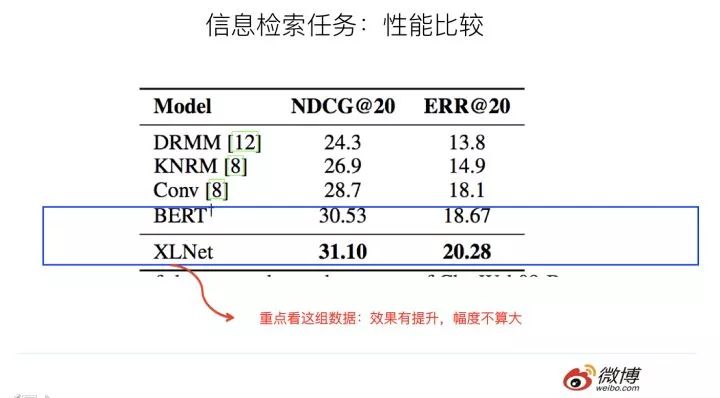
上面是文本分類任務和信息檢索任務,可以看出,相對Bert,XLNet效果有提升,但是幅度不算大。仍然是上面的考慮,起作用的三個因素,到底哪個發(fā)揮多大作用,從數(shù)據(jù)方面看不太出來。
下面一組實驗可以仔細分析一下,這組實驗是排除掉上述第三個數(shù)據(jù)規(guī)模因素的實驗的對比,就是說XLNet用的是和Bert相同規(guī)模的預訓練數(shù)據(jù),所以與Bert對比更具備模型方面的可比較性,而沒有數(shù)據(jù)規(guī)模的影響。實驗結果如下:

如果仔細分析實驗數(shù)據(jù),實驗結果說明:
因為和Bert比較,XLNet使用相同的預訓練數(shù)據(jù)。所以兩者的性能差異來自于:Permutation Language Model預訓練目標以及Transformer XL的長文檔因素。
而從中可以看出,DAE+Transformer XL體現(xiàn)的是長文檔因素的差異,和Bert比,Race提升1個點,SQuAD F1提升3個點,MNLI提升0.5個點,SST-2性能稍微下降。這是Transformer XL因素解決長文檔因素帶來的收益,很明顯,長文檔閱讀理解任務提升比較明顯,其它任務提升不太明顯。
而通過XLNet進一步和DAE+Transformer XL及Bert比,這一點應該拆解出Permutation Language Model和Mask的方式差異。可以看出:XLNet相對DAE+Transformer XL來說,Race進一步提升1個點左右;SQuAD進一步提升1.8個點左右,NMLI提升1個點左右,SST-B提升不到1個點。
雖然不精準,但是大致是能說明問題的,這個應該大致是PLM帶來的模型收益。可以看出,PLM還是普遍有效的,但是提升幅度并非特別巨大。
如果我們結合前面Race和SQuAD的實驗結果看(上面兩組實驗是三個因素的作用,后面是排除掉數(shù)據(jù)量差異的結果,所以兩者的差距,很可能就是第三個因素:數(shù)據(jù)規(guī)模導致的差異,當然,因為一個是Bert_base,一個是Bert_Large,所以不具備完全可比性,但是大致估計不會偏離真實結論太遠),Race數(shù)據(jù)集合三因素同時具備的XLNet,超過Bert絕對值大約9個多百分點,Transformer因素+PLM因素估計貢獻大約在2到4個點之間,那么意味著預訓練數(shù)據(jù)量導致的差異大概在4到5個點左右;類似的,可以看出,SQuAD 2.0中,預訓練數(shù)據(jù)量導致的差異大約在2到3個點左右,也就是說,估計訓練數(shù)據(jù)量帶來的提升,在閱讀理解任務中大約占比30%到40%左右。
如果從實驗結果歸納一下的話,可以看出:XLNet綜合而言,效果是優(yōu)于Bert的,尤其是在長文檔類型任務,效果提升明顯。如果進一步拆解的話,因為對比實驗不足,只能做個粗略的結論:預訓練數(shù)據(jù)量的提升,大概帶來30%左右的性能提升,其它兩個模型因素帶來剩余的大約70%的性能提升。
當然,這個主要指的是XLNet性能提升比較明顯的閱讀理解類任務而言。對于其它類型任務,感覺Transformer XL的因素貢獻估計不會太大,主要應該是其它兩個因素在起作用。
對NLP應用任務的影響
XLNet其實本質上還是ELMO/GPT/Bert這一系列兩階段模型的進一步延伸。在將自回歸LM方向引入雙向語言模型方面,感覺打開了一個新思路,這點還是非常對人有啟發(fā)的。當然,如果深入思考,其實和Bert并沒有太大的不同。
如果讓我推論下XLNet的出現(xiàn),對后續(xù)NLP工作的影響,我覺得跟Bert比,最直接的影響應該有兩個,一個是對于Bert長文檔的應用,因為Transformer天然對長文檔任務處理有弱點,所以XLNet對于長文檔NLP任務相比Bert應該有直接且比較明顯的性能提升作用,它在論文中也證明了這點。所以,以后長文檔類型的NLP應用,XLNet明顯跟Bert比占優(yōu)勢。當然,你說我把Transformer XL的因素引入Bert,然后繼續(xù)在Bert上做改進,明顯這也是可以的。
第二點,對于生成類的NLP任務,到目前為止,盡管出了一些改進模型,但是從效果看,Bert仍然不能很好地處理。而因為XLNet的預訓練模式天然符合下游任務序列生成結果,所以按理說能夠直接通過引入XLNet來改進生成類NLP任務的效果。所以,這點估計是XLNet會明顯占優(yōu)勢的一個領域。
可以預計的是,很快我們就會看到XLNet在文本摘要,機器翻譯,信息檢索…..等符合上述XLNet應用領域特點和優(yōu)勢領域的應用結果,以及在這些任務上的進一步改進模型。
-
nlp
+關注
關注
1文章
489瀏覽量
22053
原文標題:碾壓Bert?“屠榜”的XLnet對NLP任務意味著什么
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
ADS7230有兩個電源和兩個地,是不是意味著芯片內部模擬部分和數(shù)字部分是隔離的?
ADS1274沒有DRDY信號輸出,是否意味著芯片已經(jīng)損壞?
ADS8671 datasheet里寫的是小信號輸入-3db帶寬為15KHz,是不是意味著正常信號超過10K衰減已經(jīng)很厲害了?
在ADS8320的規(guī)格書里,Tcsd最大為0ns,請問這是不是意味著Dclock極性只能是空閑為低?
ADC的數(shù)據(jù)表給出了±VREF的輸入范圍,是否意味著可以測量相對于接地的負電壓?
ADS1262浮空測量波動大,是否意味著連接上信號實測波動也會很大?
超級電容的出現(xiàn)意味著儲能技術的突破






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論