 賽靈思AI方案三大重點
賽靈思AI方案三大重點
低時延,低時延,低時延
加速整體應用,而非單項加速
匹配創新的速度,手慢無
01 最低時延的 AI 推斷
在數據中心 AI 平臺上,對于低時延 AI 推斷,賽靈思能以最低時延的條件下提供最高吞吐量,在 GoogleNet V1 上進行的標準基準測試當中,賽靈思 Alveo U250 可為實時推斷提供比現有最快的 GPU 多出 4 倍的吞吐量。
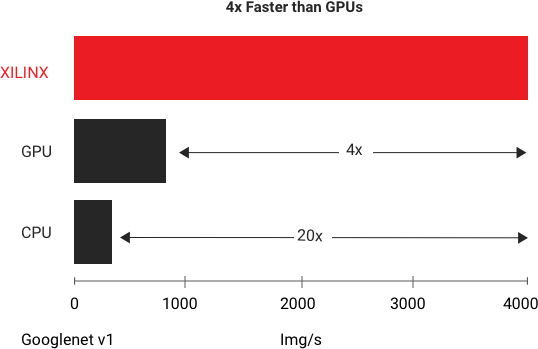
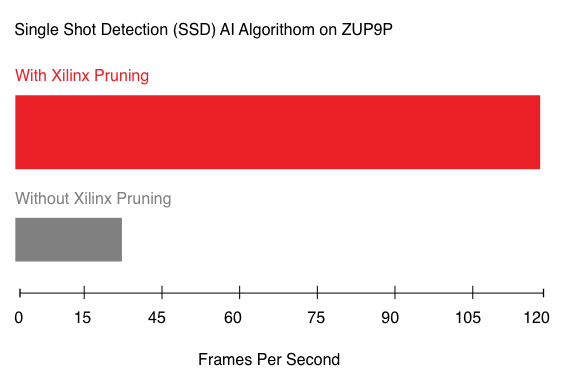
而在邊緣 AI 平臺,賽靈思方案利用 CNN 剪枝技術獲得了 AI 推斷性能的領導地位,比如,可實現 5-50 倍的網絡性能優化;大幅增加 FPS 的前提下降低功耗。對于開發者來說,賽靈思支持 Tensorflow、Caffe 和 MXNet 等網絡,并用賽靈思提供的工具鏈將網絡部署到賽靈思的加速器上。
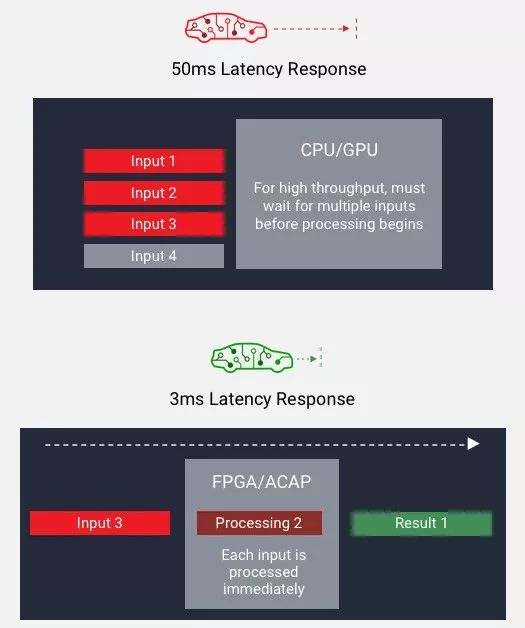
如下圖所示,傳統 CPU/GPU 只能在“高吞吐量”和“低時延”兩者選擇其一,如需低時延則無法滿足大批量規模的吞吐量;而一旦需要使用大批量規模實現吞吐量,在處理之前,器件必須等待所有輸入就緒之后再處理,從而導致高時延。而使用 FPGA,則可以采用小批量規模實現吞吐量,并在每個輸入就緒之時開始處理,從而降低時延。
02 整體應用加速
通過將自定義加速器緊密耦合在動態架構芯片器件中,優化了 AI 推斷,并對其它對性能有關鍵影響的功能進行硬件加速。
提供端對端的應用性能,該性能比 GPU 等固定架構 AI 加速器高很多;因為使用 GPU,在沒有自定義硬件加速性能或效率的情況下,應用的其它性能關鍵功能須仍在軟件中運行。

03 匹配 AI 創新的速度
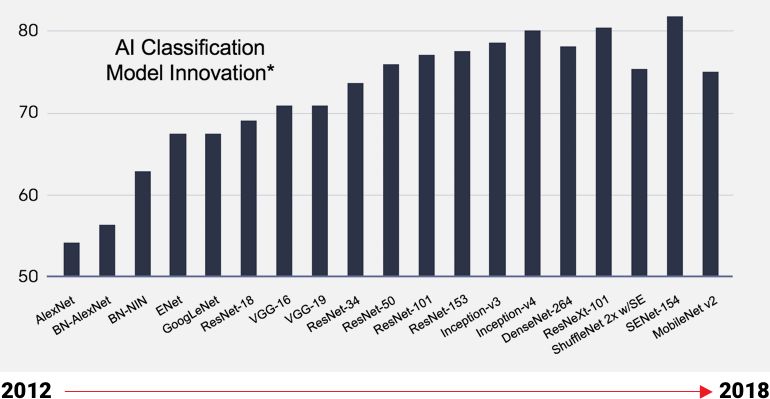
人工智能模型正在迅速發展,新算法層出不窮,靈活應變的芯片支持基于特定區領域架構(DSA)的設計,從而無需更換芯片,即可開始優化最新的人工智能模型。從而最大限度地匹配創新的速度,為客戶贏得寶貴的 Time To Market。從下圖可以看出,專用芯片開發周期長,在對 DSA 的支持上非常不友好,無法滿足現階段 AI 創新的更迭速度。
賽靈思是 FPGA、硬件可編程 SoC 及 ACAP 的發明者,旨在提供業界最具活力的處理器技術,實現自適應、智能且互連的未來世界。
-
cpu
+關注
關注
68文章
10877瀏覽量
212134 -
數據中心
+關注
關注
16文章
4804瀏覽量
72208 -
人工智能
+關注
關注
1792文章
47404瀏覽量
238910
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論