") DeepMind最新研究通過函數(shù)正則化解決災(zāi)難性遺忘
DeepMind最新研究通過函數(shù)正則化解決災(zāi)難性遺忘
當(dāng)遇到序列任務(wù)時,神經(jīng)網(wǎng)絡(luò)會遭受災(zāi)難性遺忘。DeepMind研究人員通過在函數(shù)空間中引入貝葉斯推理,使用誘導(dǎo)點(diǎn)稀疏GP方法和優(yōu)化排練數(shù)據(jù)點(diǎn)來克服這個問題。今天和大家分享這篇Reddit高贊論文。
這篇由DeepMind研究團(tuán)隊(duì)出品的論文名字叫“Functional Regularisation for Continual Learning”(持續(xù)學(xué)習(xí)的功能正規(guī)化)。研究人員引入了一個基于函數(shù)空間貝葉斯推理的持續(xù)學(xué)習(xí)框架,而不是深度神經(jīng)網(wǎng)絡(luò)的參數(shù)。該方法被稱為用于持續(xù)學(xué)習(xí)的函數(shù)正則化,通過在底層任務(wù)特定功能上構(gòu)造和記憶一個近似的后驗(yàn)信念,避免忘記先前的任務(wù)。
為了實(shí)現(xiàn)這一點(diǎn),他們依賴于通過將神經(jīng)網(wǎng)絡(luò)的最后一層的權(quán)重視為隨機(jī)和高斯分布而獲得的高斯過程。然后,訓(xùn)練算法依次遇到任務(wù),并利用誘導(dǎo)點(diǎn)稀疏高斯過程方法構(gòu)造任務(wù)特定函數(shù)的后驗(yàn)信念。在每個步驟中,首先學(xué)習(xí)新任務(wù),然后構(gòu)建總結(jié)(summary),其包括(i)引入輸入和(ii)在這些輸入處的函數(shù)值上的后驗(yàn)分布。然后,這個總結(jié)通過Kullback-Leibler正則化術(shù)語規(guī)范學(xué)習(xí)未來任務(wù),從而避免了對早期任務(wù)的災(zāi)難性遺忘。他們在分類數(shù)據(jù)集中演示了自己的算法,例如Split-MNIST,Permuted-MNIST和Omniglot。
通過函數(shù)正則化解決災(zāi)難性遺忘
近年來,人們對持續(xù)學(xué)習(xí)(也稱為終身學(xué)習(xí))的興趣再度興起,這是指以在線方式從可能與不斷增加的任務(wù)相關(guān)的數(shù)據(jù)中學(xué)習(xí)的系統(tǒng)。持續(xù)學(xué)習(xí)系統(tǒng)必須適應(yīng)所有早期任務(wù)的良好表現(xiàn),而無需對以前的數(shù)據(jù)進(jìn)行大量的重新訓(xùn)練。
持續(xù)學(xué)習(xí)的兩個主要挑戰(zhàn)是:
(i)避免災(zāi)難性遺忘,比如記住如何解決早期任務(wù);
(ii)任務(wù)數(shù)量的可擴(kuò)展性。
其他可能的設(shè)計包括向前和向后轉(zhuǎn)移,比如更快地學(xué)習(xí)后面的任務(wù)和回顧性地改進(jìn)前面的任務(wù)。值得注意的是,持續(xù)學(xué)習(xí)與元學(xué)習(xí)(meta-learning)或多任務(wù)學(xué)習(xí)有很大的不同。在后一種方法中,所有任務(wù)都是同時學(xué)習(xí)的,例如,訓(xùn)練是通過對小批量任務(wù)進(jìn)行二次抽樣,這意味著沒有遺忘的風(fēng)險。
與許多最近關(guān)于持續(xù)學(xué)習(xí)的著作相似,他們關(guān)注的是理想化的情況,即一系列有監(jiān)督的學(xué)習(xí)任務(wù),具有已知的任務(wù)邊界,呈現(xiàn)給一個深度神經(jīng)網(wǎng)絡(luò)的持續(xù)學(xué)習(xí)系統(tǒng)。一個主要的挑戰(zhàn)是有效地規(guī)范化學(xué)習(xí),使深度神經(jīng)網(wǎng)絡(luò)避免災(zāi)難性的遺忘,即避免導(dǎo)致早期任務(wù)的預(yù)測性能差的網(wǎng)絡(luò)參數(shù)配置。在不同的技術(shù)中,他們考慮了兩種不同的方法來管理災(zāi)難性遺忘。
一方面,這些方法限制或規(guī)范網(wǎng)絡(luò)的參數(shù),使其與以前的任務(wù)中學(xué)習(xí)的參數(shù)沒有明顯的偏差。 這包括將持續(xù)學(xué)習(xí)構(gòu)建為順序近似貝葉斯推理的方法,包括EWC和VCL。這種方法由于表征漂移(representation drift)而具有脆弱性(brittleness)。也就是說,隨著參數(shù)適應(yīng)新任務(wù),其他參數(shù)被約束/正規(guī)化的值變得過時。
另一方面,他們有預(yù)演/回放緩沖方法,它使用過去觀察的記憶存儲來記住以前的任務(wù)。它們不會受到脆弱性的影響,但是它們不表示未知函數(shù)的不確定性(它們只存儲輸入-輸出),并且如果任務(wù)復(fù)雜且需要許多觀察來正確地表示,那么它們的可擴(kuò)展性會降低。優(yōu)化存儲在重放緩沖區(qū)中的最佳觀察結(jié)果也是一個未解決的問題。
在論文中,研究人員發(fā)展了一種新的持續(xù)學(xué)習(xí)方法,解決了這兩個類別的缺點(diǎn)。它是基于近似貝葉斯推理,但基于函數(shù)空間而不是神經(jīng)網(wǎng)絡(luò)參數(shù),因此不存在上述的脆弱性。這種方法通過記住對底層特定任務(wù)功能的近似后驗(yàn)信念,避免忘記先前的任務(wù)。
為了實(shí)現(xiàn)這一點(diǎn),他們考慮了高斯過程(GPs),并利用誘導(dǎo)點(diǎn)稀疏GP方法總結(jié)了使用少量誘導(dǎo)點(diǎn)的函數(shù)的后驗(yàn)分布。這些誘導(dǎo)點(diǎn)及其后驗(yàn)分布通過變分推理框架內(nèi)的KullbackLeibler正則化項(xiàng),來規(guī)范未來任務(wù)的持續(xù)學(xué)習(xí),避免了對早期任務(wù)的災(zāi)難性遺忘。因此,他們的方法與基于重播的方法相似,但有兩個重要的優(yōu)勢。
首先,誘導(dǎo)點(diǎn)的近似后驗(yàn)分布捕獲了未知函數(shù)的不確定性,并總結(jié)了給定所有觀測值的全后驗(yàn)分布。其次,誘導(dǎo)點(diǎn)可以使用來自GP文獻(xiàn)的專門標(biāo)準(zhǔn)進(jìn)行優(yōu)化,實(shí)現(xiàn)比隨機(jī)選擇觀測更好的性能。
為了使他們的函數(shù)正則化方法能夠處理高維和復(fù)雜的數(shù)據(jù)集,他們使用具有神經(jīng)網(wǎng)絡(luò)參數(shù)化特征的線性核。這樣的GPs可以理解為貝葉斯神經(jīng)網(wǎng)絡(luò),其中只有最后一層的權(quán)重以貝葉斯方式處理,而早期層的權(quán)重是優(yōu)化的。這種觀點(diǎn)允許在權(quán)重空間中進(jìn)行更有效和準(zhǔn)確的計算訓(xùn)練程序,然后將近似轉(zhuǎn)換為函數(shù)空間,在函數(shù)空間中構(gòu)造誘導(dǎo)點(diǎn),然后用于規(guī)范未來任務(wù)的學(xué)習(xí)。他們在分類中展示了自己的方法,并證明它在Permuted-MNIST,Split-MNIST和Omniglot上具有最先進(jìn)的性能。
實(shí)驗(yàn)簡介
研究人員考慮了三個持續(xù)學(xué)習(xí)分類問題中的實(shí)驗(yàn):Split-MNIST,PermutedMNIST和Sequenn Omniglot。他們比較了其方法的兩種變體,稱為功能正則化持續(xù)學(xué)習(xí)(FRCL)。
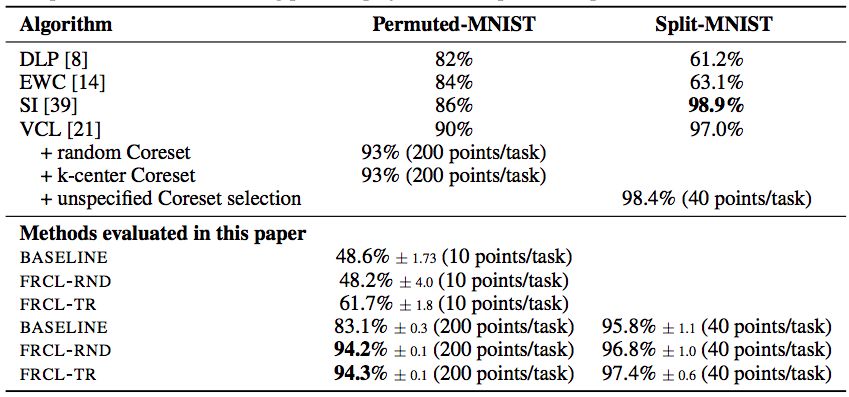
表1:Permuted-MNIST和Split-MNIST的結(jié)果。對于在這項(xiàng)工作中進(jìn)行的實(shí)驗(yàn),他們顯示了10次隨機(jī)重復(fù)的平均值和標(biāo)準(zhǔn)差。在適用的情況下,他們還會在括號中報告每個任務(wù)的誘導(dǎo)點(diǎn)/重放緩沖區(qū)大小的數(shù)量。
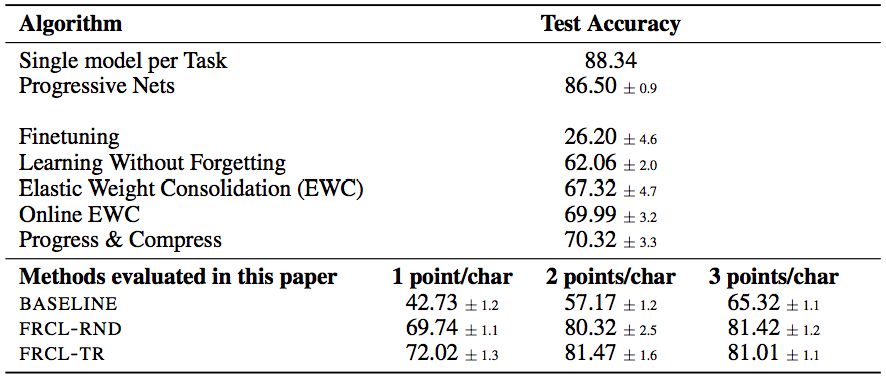
表2:Sequential Omniglo的結(jié)果。所示為超過5個隨機(jī)任務(wù)排列的平均值和標(biāo)準(zhǔn)偏差。請注意,由于不現(xiàn)實(shí)的假設(shè),“每個任務(wù)的單一模型”和“漸進(jìn)網(wǎng)絡(luò)”方法不能直接比較。他們將其包括在內(nèi),因?yàn)樗鼈優(yōu)槠溆嗟某掷m(xù)學(xué)習(xí)方法提供了性能的上限。
他們將自己的方法與文獻(xiàn)中的其他方法進(jìn)行比較,引用公布的結(jié)果,并使用與簡單的重放-緩沖方法相對應(yīng)的附加基線(BASELINE)進(jìn)行持續(xù)學(xué)習(xí)。對于所有實(shí)現(xiàn)的方法,即FRCL-RND,F(xiàn)RCL-TR和BASELINE,他們不在共享特征向量參數(shù)θ上放置任何額外的正則化器(例如“2懲罰”或批量規(guī)范化等)。
鑒于Permuted-MNIST和Omniglot是多類分類問題,其中每個第k個任務(wù)涉及對Ck類的分類,他們需要推廣模型和變分方法來處理每個任務(wù)的多個GP函數(shù)。正如他們在補(bǔ)充中詳述的那樣,這樣做很簡單。FRCL方法已使用GPflow實(shí)現(xiàn)。

圖1:左欄中的面板顯示隨機(jī)誘導(dǎo)點(diǎn)(BASELINE&FRCL-RND;見頂部圖像)和相應(yīng)的最終/優(yōu)化誘導(dǎo)點(diǎn)(FRCL-TR);請參閱Permuted-MNIST基準(zhǔn)測試的第一項(xiàng)任務(wù)。誘導(dǎo)點(diǎn)的數(shù)量限制為10個,每行對應(yīng)于不同的運(yùn)行。右欄中的面板提供隨機(jī)誘導(dǎo)點(diǎn)的tsne可視化,最終/優(yōu)化的那些將一起顯示所有剩余的訓(xùn)練輸入。為了獲得這種可視化,他們將tsne應(yīng)用于訓(xùn)練輸入的完整神經(jīng)網(wǎng)絡(luò)特征向量矩陣ΦX1。
討論與未來研究
研究人員引入了一種用于監(jiān)督連續(xù)學(xué)習(xí)的函數(shù)正則化方法,該方法將誘導(dǎo)點(diǎn)GP推理與深度神經(jīng)網(wǎng)絡(luò)相結(jié)合。該方法構(gòu)造特定于任務(wù)的后驗(yàn)信念或總結(jié),包括對函數(shù)值的誘導(dǎo)輸入和分布,這些函數(shù)值捕獲了與任務(wù)相關(guān)的未知函數(shù)的不確定性。隨后,任務(wù)特定的總結(jié)使他們能夠規(guī)范持續(xù)學(xué)習(xí)并避免災(zāi)難性的遺忘。
關(guān)于使用GPs進(jìn)行在線學(xué)習(xí)的相關(guān)工作,請注意先前的算法是以在線方式學(xué)習(xí)單個任務(wù),其中來自該任務(wù)的數(shù)據(jù)依次到達(dá)。相比之下,論文提出了一種處理一系列不同任務(wù)的連續(xù)學(xué)習(xí)方法。
未來研究的方向是強(qiáng)制執(zhí)行固定的內(nèi)存緩沖區(qū),在這種情況下,需要將所有先前看到的任務(wù)的總結(jié)壓縮為單個總結(jié)。最后,在論文中,他們將該方法應(yīng)用于具有已知任務(wù)邊界的監(jiān)督分類任務(wù),將其擴(kuò)展到處理未知任務(wù)邊界,并考慮在其他領(lǐng)域的應(yīng)用,如強(qiáng)化學(xué)習(xí)。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4771瀏覽量
100715 -
函數(shù)
+關(guān)注
關(guān)注
3文章
4327瀏覽量
62573 -
DeepMind
+關(guān)注
關(guān)注
0文章
130瀏覽量
10848
原文標(biāo)題:Reddit熱議!DeepMind最新研究解決災(zāi)難性遺忘難題
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
*** 災(zāi)難性故障,求救,經(jīng)驗(yàn)分享
***災(zāi)難性故障
有沒人在使用AD過程中出現(xiàn)災(zāi)難性故障啊,怎么解決的?
未來的AI 深挖谷歌 DeepMind 和它背后的技術(shù)
如何創(chuàng)建正則的表達(dá)式?
AD畫圖出現(xiàn)“災(zāi)難性故障 (異常來自 HRESULT:0x8000FFFF (E_UNEXPECTED))”
DeepMind破解災(zāi)難性遺忘密碼,讓AI更像人
DeepMind徹底解決人工智能災(zāi)難性遺忘問題
Batch的大小、災(zāi)難性遺忘將如何影響學(xué)習(xí)速率
在沒有災(zāi)難性遺忘的情況下,實(shí)現(xiàn)深度強(qiáng)化學(xué)習(xí)的偽排練

實(shí)現(xiàn)人工智能戰(zhàn)略性遺忘的三個方法
python正則表達(dá)式中的常用函數(shù)
基于先驗(yàn)指導(dǎo)的對抗樣本初始化方法提升FAT效果
準(zhǔn)確性超Moshi和GLM-4-Voice,端到端語音雙工模型Freeze-Omni






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論