 Analytics Zoo: 統一的大數據分析+AI 平臺
Analytics Zoo: 統一的大數據分析+AI 平臺
5月25日-26日,由中國人工智能學會主辦,南京市麒麟科技創新園管理委員會與京東云共同承辦的2019全球人工智能技術大會(2019 GAITC)在南京紫金山莊成功舉行。
在第一天的主論壇上,英特爾高級首席工程師、大數據技術全球 CTO戴金權發表了主題為《Analytics Zoo: 統一的大數據分析+AI 平臺》的精彩演講。
戴金權
英特爾高級首席工程師、大數據技術全球 CTO
以下是戴總的演講實錄:
在英特爾如何構建統一的大數據分析+AI 平臺(我們稱為開源項目),幫助客戶更高效地開發大數據、大規模深度學習的應用。英特爾致力于提供端到端,從設備端到邊緣,再到數據中心云端完整的計算架構,比如在數據中心,今天英特爾志強服務器是 AI 應用分析的基礎架構,月提供了多種像神經網絡處理器等豐富的硬件架構。同樣在軟件上,我們也是致力于提供全站的解決方案,從最底層的核心算子開源項目可以幫助用戶更高效開發他們的計算庫;再到上層各種機器學習或者深度學習的框架,比如對開源的 Analytics Zoo,深度學習做了大量的優化工作;再到最上層,也提供了一些開源工具包,目的是幫助應用開發人員更高效地開發基于深度學習的應用。
今天在這里著重分享的是基于大數據分析處理的框架上開發并且開源的兩個項目,一個是 BIGDL,是我們兩年半以前開源的一個深度學習的框架;在這個基礎上,去年又開源了 Analytics Zoo,構建一個端到端的大數據分析 + 深度學習的平臺。為什么在英特爾開發,并且開源基于大數據平臺上的大數據分析 +AI 的平臺工具?
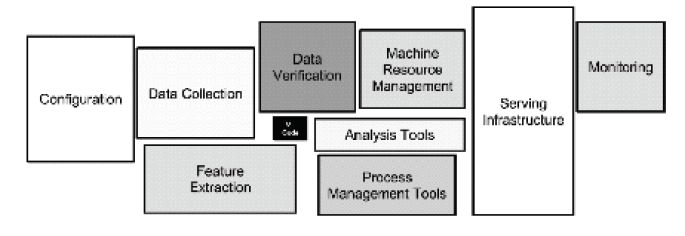
下圖中黑色的小框代表機器學習或者深度學習的模型,它很關鍵,從某種意義上決定了硬件有怎樣的功能,做到怎樣的事情。但是會發現,當想把這樣一個深度學習、機器學習模型應用到實際場景,從實驗室搬到現實工業級機器學習中,構建這樣的端到端應用是非常復雜的,要有大量的其他模塊,比如怎樣收集數據、處理數據和驗證數據,包括資源管理、集群監控等。整個端到端的流水線是由一個非常多的模塊組成的,一個端到端大數據處理分析再加上深度學習、機器學習的流水線。
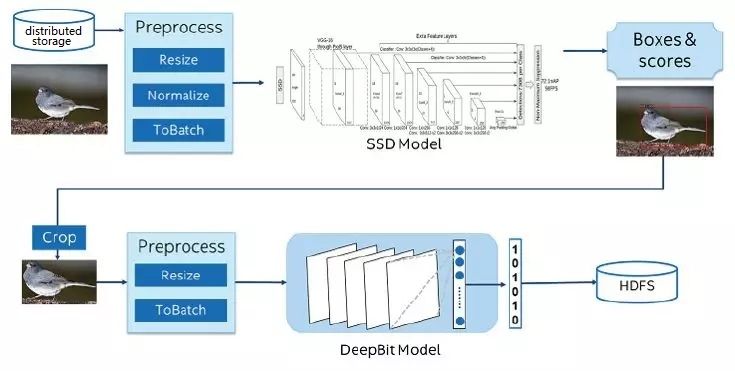
下圖是我們在兩年前和京東的一個合作。京東帶來的幾億張圖片,存儲在一個大規模分布式大數據集群里,我們做的事情是要對這些圖片——識別物品。比如,這張圖片上是一只鳥,然后提取特征。從深度學習、機器學習來說,不是特別復雜的應用,做物品識別、提取持證就可以了。但是事實上發現,在對大規模的圖片讀取數據,對圖片進行分布式處理,再進行模型推理;當識別物品時,對物品進行抽取,再進行處理,再提取特征等,把整個端到端流水線在大規模的圖片里是跑不好的。當要把這些機器學習、深度學習等技術應用到實際應用中,會有一個比較大的斷層,今天很多的科學家做了非常多的深度學習、機器學習的有效工作,但是如何將新技術、新創新應用到現實環境中,特別是在一些非常大規模、大數據生產系統中,從軟硬件架構上有非常大的一個斷層。這就是為什么我們會去開源,像BIGDL,特別是 Analytics Zoo 平臺,能夠將不同的模塊不管是用 TensorFlow 還是用Keras,將這些不同模塊的程序能夠無縫運行在端到端流水線上,大大提升開發效率。
總之,我們開發并且開源的目的是讓大家更加方便開發大數據、大規模深度學習的應用。通常很多用戶開始開發應用時,可能在一個筆記本上構建一個簡單原形,當你覺得原形看還不錯時,希望可以跑歷史數據,對過去幾個月或者幾年的數據進行一些驗證,為端到端的流水線構造原形。在實驗上覺得效果還不錯,就希望部署到生產系統中,可能進行上線。同時也是大規模、大數據處理的流水線,可以讓你的程序運行在一個大標準集群里,直接利用現有的大數據集群、大數據計算資源運行你的程序,從而能夠提高你進行開發并且部署深度學習應用的效率。
有關 Analytics Zoo 一些技術細節的構成。總的來說,構建在很多不同底層計算的庫和框架上,在上面構建一些豐富的流水線支持;再上面也提供了一些解決方案,包括預定模型。
下面來看一下具體的例子。有人和我說不要放太多代碼在里面,用 Spark 構建一個 RDD,對大規模數據進行分布式處理。對各種各樣的數據源,不管是數據倉庫的方式,還是讀寫數據庫,或者是讀寫各種各樣的分布式文件系統,可以直接使用 Spark Dataframe。下面的圖片是說,如能夠使用剛才訓練的模型,就可以使用我們的模型推理進行大規模分布式應用,在自己 Keras 等框架內都很容易將我們深度學習模型集成在這些流水式處理或者在線處理中,而且在這個背后也可以透明地使用像 Analytics Zoo 的工具,對模型進行壓縮加速,包括至強深度學習加速指令對它進行加速;同時可以跑在大規模集群上進行分布式推理。

我們真正的用戶是怎么具體使用的?解決他們什么問題?下圖是我們和美的的合作,他們希望通過計算機視覺將其生產線生產出來的產品自動識別瑕疵、沒有貼標簽等。

工業機器人接上攝像機,對流水線出來的產品進行拍照,拿到照片后進行識別,產品上是不是有缺陷。比如,下圖中可以看到空調上少了一個螺絲。上圖中,粉紅色是對大規模圖片進行處理;黃色是 SSDLite這樣的一個模型,使用 Analytics Zoo API和 Spark 數據可以整合起來,在 Spark 上進行訓練。
下面這個例子是我們和微軟中國團隊的合作,他們希望給大家提供客戶。比如,他們有一個微信公眾號,在他們的微信公眾號上可以提問題,如怎么聯不上我的虛擬機、怎么重啟我的虛擬機、怎么開發票等。原來他們的做法是,在特定領域完成特定任務的對話。上午的報告中有很多專家提到,在垂直領域定義模版。他們有很多定義好的流程,可以隨著流程走。現在很多人不隨著流程走,隨便問一些問題,怎么開不了發票?因為內部有大量知識庫和準備好的問答,通過關鍵詞的匹配可以幫你去搜索,搜索出一些文章,希望滿足你的問題。這里,希望我們幫他做一些問答匹配,把相關的回答反饋給用戶,用戶看到這些問題后,可能解決了他的問題或者沒有;如果沒有解決,就要轉人工處理。轉人工處理是非常昂貴的事情,不同的問題要轉到不同的后臺,所以要有對意圖進行分類的模塊,將問題做一些分類,到底是財務的問題,還是網絡的問題,還是虛擬機的問題。
Office Depot,賣辦公用品的一個電商,做一些產品的推薦,當把一個物品加入到購物車后,根據你的行為推薦一些相關的物品。這是一個跑在云上的應用,使用 Spark 和 Analytics Zoo 上進行訓練,使用 mleap 就可以直接將 pipeline 模型保存下來,訓練出來的模型直接部署在 AWS S3,通過 BigDL 把它部署在一個 DNN 進行在線推理。
萬事達,希望給大家推送一些促銷信息,到哪里去購物,我給你一個立減等類似的優惠,希望把這些推送到相關的客戶,客戶收到這些信息后會買東西。但是有一個特別的問題,我們會根據用戶過去購買行為進行分析,將用戶過去的購買行為、交易的數據是放在數據庫里的,怎樣能夠在Apache Hadoop 現有集群上運行這些新的深度學習應用?這時就可以使用 Analytics Zoo 深度學習框架,可以在現有大數據分析集群上,和其他的業務共享同一個集群,來運行這些新的深度學習應用。
CENR,歐洲的盒子研究中心,他們每天都在進行每秒大約 4 000 萬原子對撞,產生 1 TB 數據,他們希望把這些數據存下來;希望有一個過濾機制,將有用的事件保留、存儲下來。這樣做可能每秒只存不超過 10 GB 的數據,這些數據可以用于以后的分析。他們希望過濾的越準確越好,因此分為三種事件,構建了一個深度學習模型,通過深度學習進行學習分類,將這些數據精確分析,用于以后的工作中。你可以很方便地在 Analytics Zoo 在單機上進行驗證,直接運行在一個分布式環境里進行訓練,最后訓練出結果。因為每秒都會產生 1 TB 數據,所以需要一個在線的、類似于像流式處理的平臺,這里他們用了 Spark DataFrame 進行在線預測,對原子對撞事件進行分類。
怎么應用 Analytics Zoo ?比如在阿里云上面部署 EMR,使用 Analytics Zoo。
最后總結一下。我們之所以構建Analytics Zoo 這樣的統計大數據分析 +AI平臺,就是希望能夠讓用戶在現實的生產環境中可以更方便構架深度學習的應用,將各種不同的模塊、不同的框架下統一到一個端到端流水線上,大大提高客戶開發部署大數據分析和深度學習的能力。
-
AI
+關注
關注
87文章
30762瀏覽量
268905 -
阿里云
+關注
關注
3文章
952瀏覽量
43008
原文標題:演講實錄丨戴金權 Analytics Zoo: 統一的大數據分析+AI 平臺
文章出處:【微信號:CAAI-1981,微信公眾號:中國人工智能學會】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
LLM在數據分析中的作用
raid 在大數據分析中的應用
emc技術在大數據分析中的角色
云計算在大數據分析中的應用
使用AI大模型進行數據分析的技巧
IP 地址大數據分析如何進行網絡優化?






 工商網監
工商網監
評論