 深度學習改變的五大計算機視覺技術
深度學習改變的五大計算機視覺技術
摘要:本文主要介紹計算機視覺中主要的五大技術,分別為圖像分類、目標檢測、目標跟蹤、語義分割以及實例分割。針對每項技術都給出了基本概念及相應的典型方法,簡單通俗、適合閱讀。
計算機視覺是當前最熱門的研究之一,是一門多學科交叉的研究,涵蓋計算機科學(圖形學、算法、理論研究等)、數學(信息檢索、機器學習)、工程(機器人、NLP等)、生物學(神經系統科學)和心理學(認知科學)。由于計算機視覺表示對視覺環境及背景的相對理解,很多科學家相信,這一領域的研究將為人工智能行業的發展奠定基礎。
那么,什么是計算機視覺呢?下面是一些公認的定義:
1.從圖像中清晰地、有意義地描述物理對象的結構(Ballard & Brown,1982);
2.由一個或多個數字圖像計算立體世界的性質(Trucco & Verri,1998);
3.基于遙感圖像對真實物體和場景做出有用的決定(Sockman & Shapiro,2001);
那么,為什么研究計算機視覺呢?答案很明顯,從該領域可以衍生出一系列的應用程序,比如:
1.人臉識別:人臉檢測算法,能夠從照片中認出某人的身份;
2.圖像檢索:類似于谷歌圖像使用基于內容的查詢來搜索相關圖像,算法返回與3.查詢內容最佳匹配的圖像。
4.游戲和控制:體感游戲;
5.監控:公共場所隨處可見的監控攝像機,用來監視可疑行為;
6.生物識別技術:指紋、虹膜和人臉匹配是生物特征識別中常用的方法;
7.智能汽車:視覺仍然是觀察交通標志、信號燈及其它視覺特征的主要信息來源;
正如斯坦福大學公開課CS231所言,計算機視覺任務大多是基于卷積神經網絡完成。比如圖像分類、定位和檢測等。那么,對于計算機視覺而言,有哪些任務是占據主要地位并對世界有所影響的呢?本篇文章將分享給讀者5種重要的計算機視覺技術,以及其相關的深度學習模型和應用程序。相信這5種技術能夠改變你對世界的看法。
1.圖像分類

圖像分類這一任務在我們的日常生活中經常發生,我們習慣了于此便不以為然。每天早上洗漱刷牙需要拿牙刷、毛巾等生活用品,如何準確的拿到這些用品便是一個圖像分類任務。官方定義為:給定一組圖像集,其中每張圖像都被標記了對應的類別。之后為一組新的測試圖像集預測其標簽類別,并測量預測準確性。
如何編寫一個可以將圖像分類的算法呢?計算機視覺研究人員已經提出了一種數據驅動的方法來解決這個問題。研究人員在代碼中不再關心圖像如何表達,而是為計算機提供許多很多圖像(包含每個類別),之后開發學習算法,讓計算機自己學習這些圖像的特征,之后根據學到的特征對圖像進行分類。
鑒于此,完整的圖像分類步驟一般形式如下:
1.首先,輸入一組訓練圖像數據集;
2.然后,使用該訓練集訓練一個分類器,該分類器能夠學習每個類別的特征;
3.最后,使用測試集來評估分類器的性能,即將預測出的結果與真實類別標記進行比較;
對于圖像分類而言,最受歡迎的方法是卷積神經網絡(CNN)。CNN是深度學習中的一種常用方法,其性能遠超一般的機器學習算法。CNN網絡結構基本是由卷積層、池化層以及全連接層組成,其中,卷積層被認為是提取圖像特征的主要部件,它類似于一個“掃描儀”,通過卷積核與圖像像素矩陣進行卷積運算,每次只“掃描”卷積核大小的尺寸,之后滑動到下一個區域進行相關的運算,這種計算叫作滑動窗口。
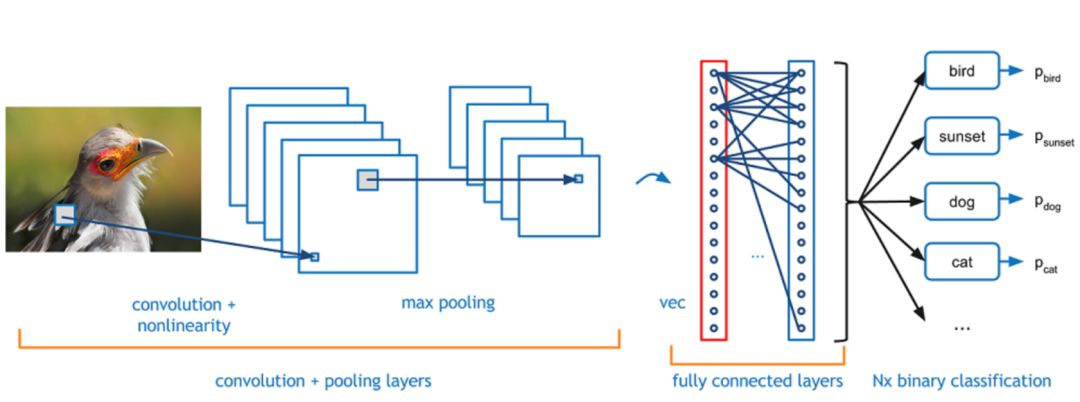
從圖中可以看到,輸入圖像送入卷積神經網絡中,通過卷積層進行特征提取,之后通過池化層過濾細節(一般采用最大值池化、平均池化),最后在全連接層進行特征展開,送入相應的分類器得到其分類結果。
大多數圖像分類算法都是在ImageNet數據集上訓練的,該數據集由120萬張的圖像組成,涵蓋1000個類別,該數據集也可以稱作改變人工智能和世界的數據集。ImagNet 數據集讓人們意識到,構建優良數據集的工作是 AI 研究的核心,數據和算法一樣至關重要。為此,世界組織也舉辦了針對該數據集的挑戰賽——ImageNet挑戰賽。
第一屆ImageNet挑戰賽的第一名是由Alex Krizhevsky(NIPS 2012)獲得,采用的方法是深層卷積神經網絡,網絡結構如下圖所示。在該模型中,采用了一些技巧,比如最大值池化、線性修正單元激活函數ReLU以及使用GPU仿真計算等,AlexNet模型拉開了深度學習研究的序幕。
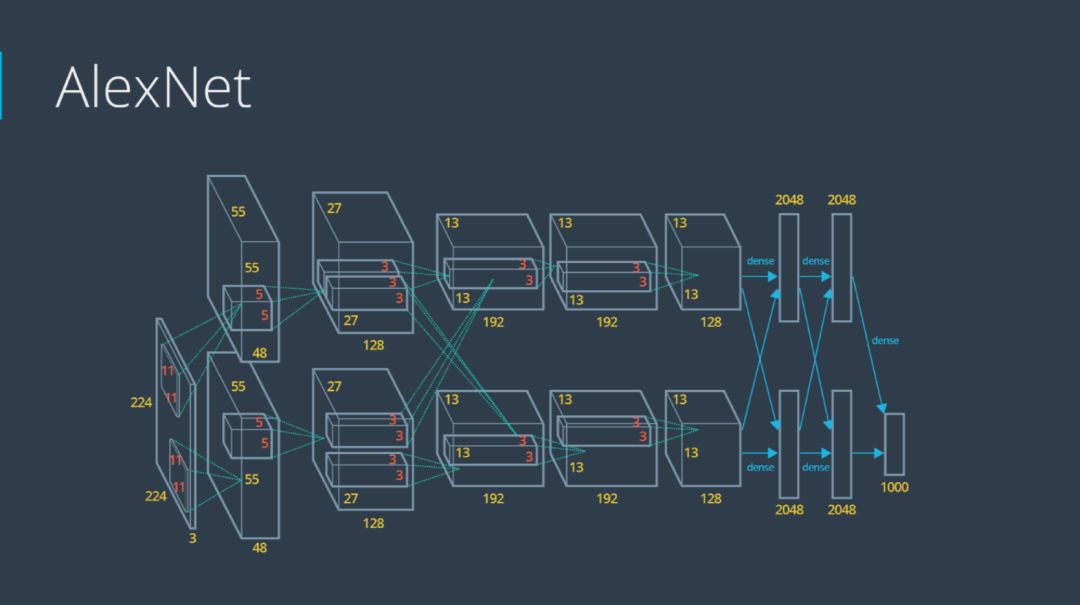
自從AlexNet網絡模型贏得比賽之后,有很多基于CNN的算法也在ImageNet上取得了特別好的成績,比如ZFNet(2013)、GoogleNet(2014)、VGGNet(2014)、ResNet(2015)以及DenseNet(2016)等。
2.目標檢測
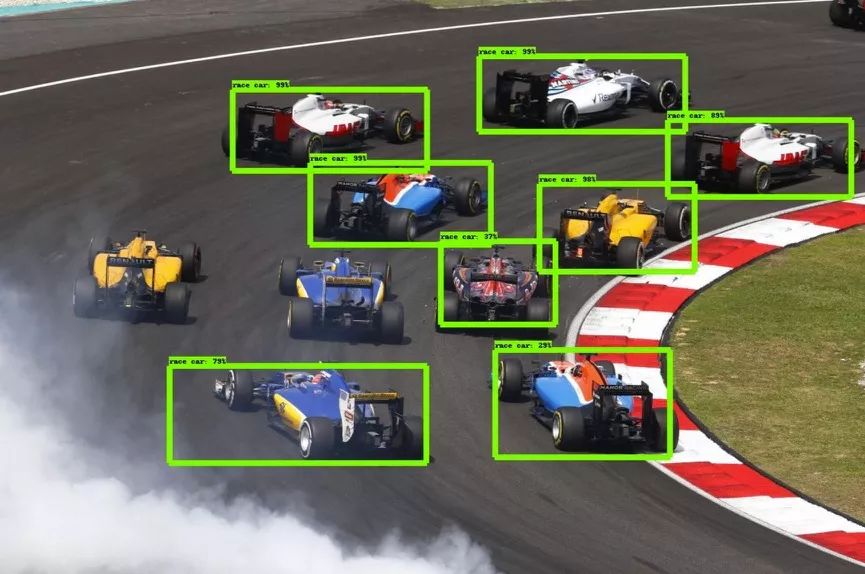
目標檢測通常是從圖像中輸出單個目標的Bounding Box(邊框)以及標簽。比如,在汽車檢測中,必須使用邊框檢測出給定圖像中的所有車輛。
之前在圖像分類任務中大放光彩的CNN同樣也可以應用于此。第一個高效模型是R-CNN(基于區域的卷積神經網絡),如下圖所示。在該網絡中,首先掃描圖像并使用搜索算法生成可能區域,之后對每個可能區域運行CNN,最后將每個CNN網絡的輸出送入SVM分類器中來對區域進行分類和線性回歸,并用邊框標注目標。
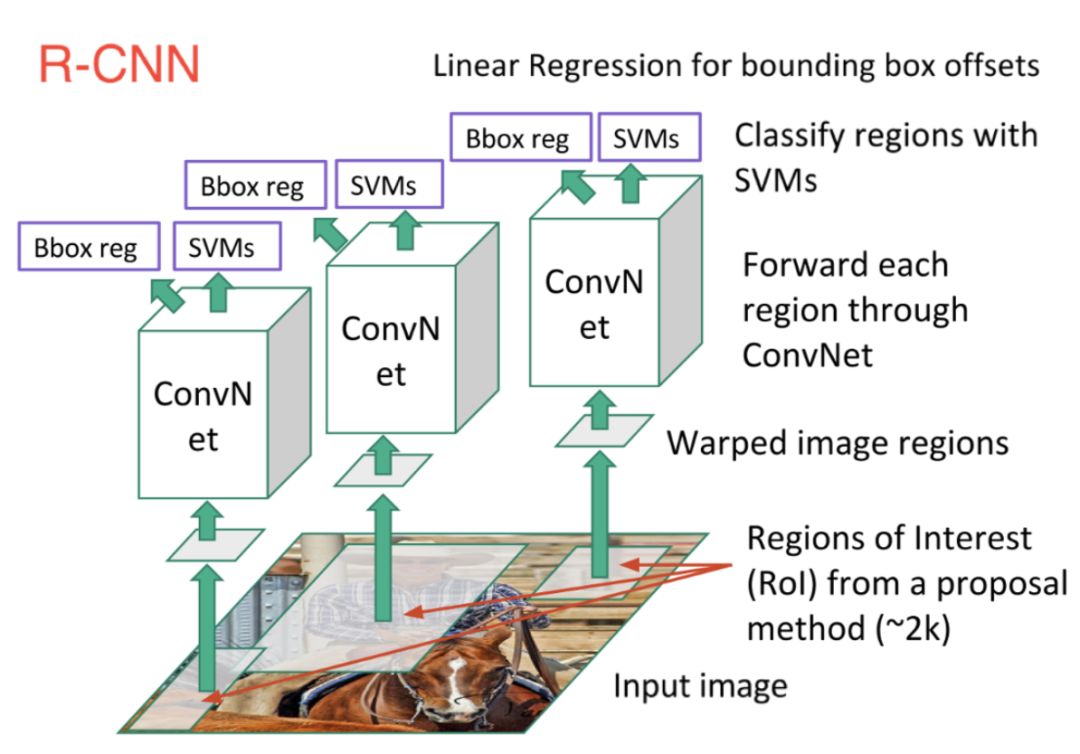
本質上,是將物體檢測轉換成圖像分類問題。但該方法存在一些問題,比如訓練速度慢,耗費內存、預測時間長等。
為了解決上述這些問題,Ross Girshickyou提出Fast R-CNN算法,從兩個方面提升了檢測速度:
1)在給出建議區域之前執行特征提取,從而只需在整幅圖像上運行一次CNN;2)使用Softmax分類器代替SVM分類器;
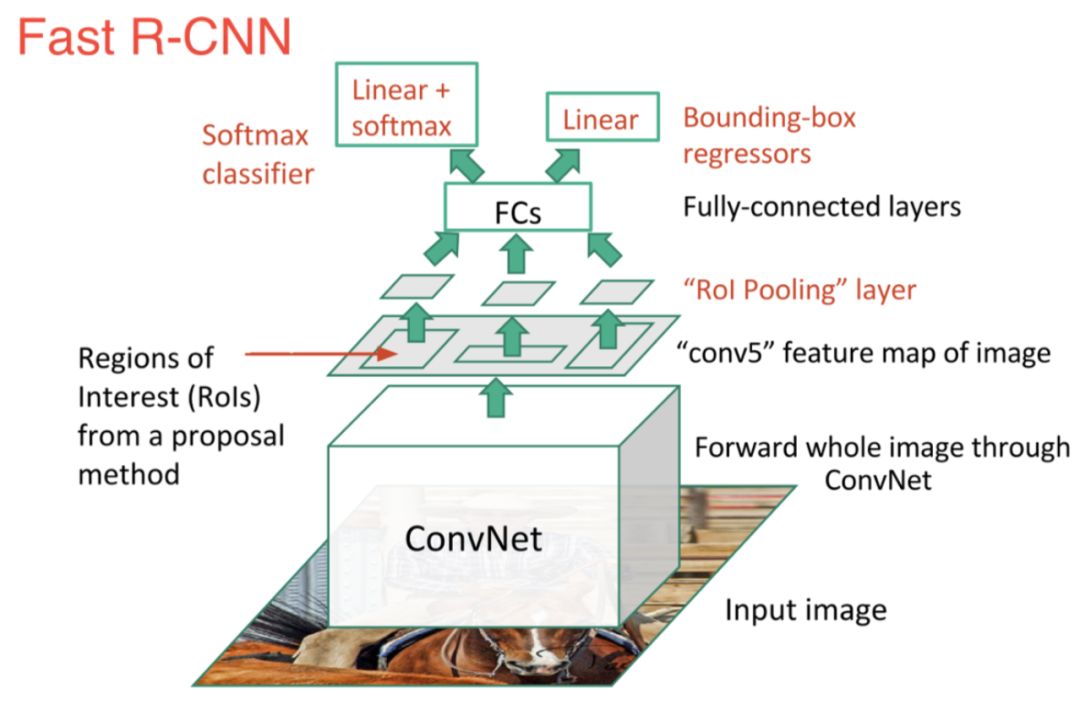
雖然Fast R-CNN在速度方面有所提升,然而,選擇搜索算法仍然需要大量的時間來生成建議區域。為此又提出了Faster R-CNN算法,該模型提出了候選區域生成網絡(RPN),用來代替選擇搜索算法,將所有內容整合在一個網絡中,大大提高了檢測速度和精度。
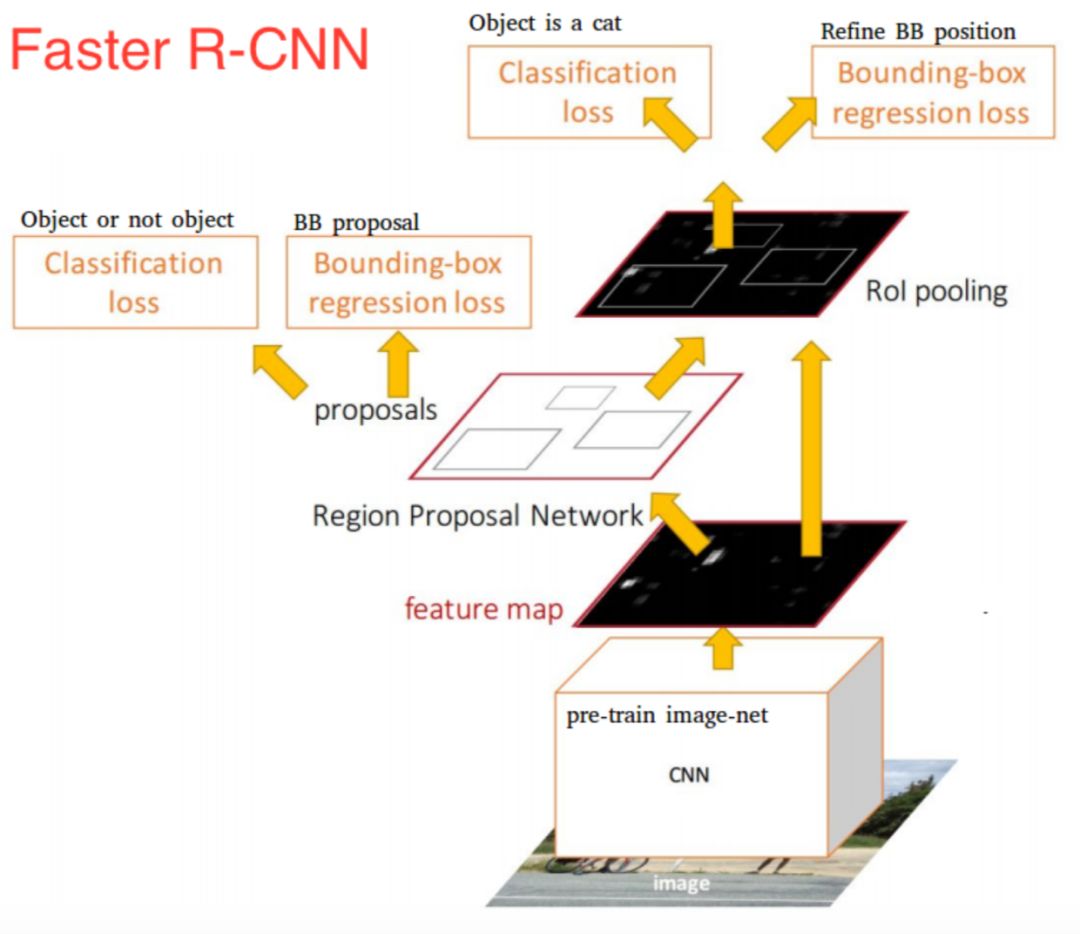
近年來,目標檢測研究趨勢主要向更快、更有效的檢測系統發展。目前已經有一些其它的方法可供使用,比如YOLO、SSD以及R-FCN等。
3.目標跟蹤
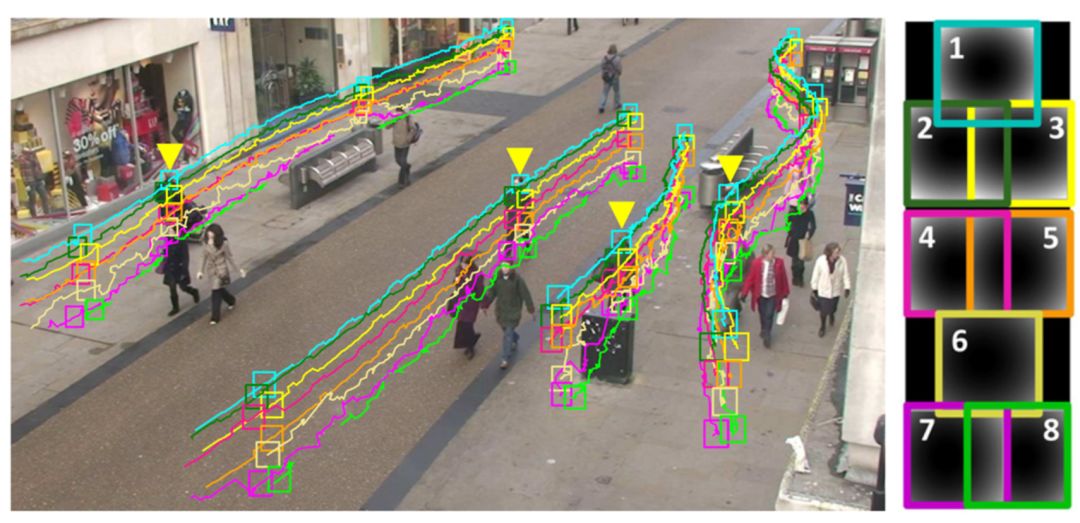
目標跟蹤是指在給定場景中跟蹤感興趣的具體對象或多個對象的過程。簡單來說,給出目標在跟蹤視頻第一幀中的初始狀態(如位置、尺寸),自動估計目標物體在后續幀中的狀態。該技術對自動駕駛汽車等領域顯得至關重要。
根據觀察模型,目標跟蹤可以分為兩類:產生式(generative method)和判別式(discriminative method)。其中,產生式方法主要運用生成模型描述目標的表觀特征,之后通過搜索候選目標來最小化重構誤差。常用的算法有稀疏編碼(sparse coding)、主成分分析(PCA)等。與之相對的,判別式方法通過訓練分類器來區分目標和背景,其性能更為穩定,逐漸成為目標跟蹤這一領域的主要研究方法。常用的算法有堆棧自動編碼器(SAE)、卷積神經網絡(CNN)等。
使用SAE方法進行目標跟蹤的最經典深層網絡是Deep Learning Tracker(DLT),提出了離線預訓練和在線微調。該方法的主要步驟如下:
1.先使用棧式自動編碼器(SDAE)在大規模自然圖像數據集上進行無監督離線預訓練來獲得通用的物體表征能力。
2.將預訓練網絡的編碼部分與分類器相結合組成分類網絡,然后利用從初始幀獲得的正、負樣本對網絡進行微調,使其可以區分當前對象和背景。在跟蹤過程中,選擇分類網絡輸出得分最大的patch作為最終預測目標。
3.模型更新策略采用限定閾值的方法。

基于CNN完成目標跟蹤的典型算法是FCNT和MD Net。
FCNT的亮點之一在于對ImageNet上預訓練得到的CNN特征在目標跟蹤任務上的性能做了深入的分析:
1.CNN的特征圖可以用來做跟蹤目標的定位;
2.CNN的許多特征圖存在噪聲或者和物體跟蹤區分目標和背景的任務關聯較小;
3.CNN不同層提取的特征不一樣。高層特征更加抽象,擅長區分不同類別的物體,而低層特征更加關注目標的局部細節。
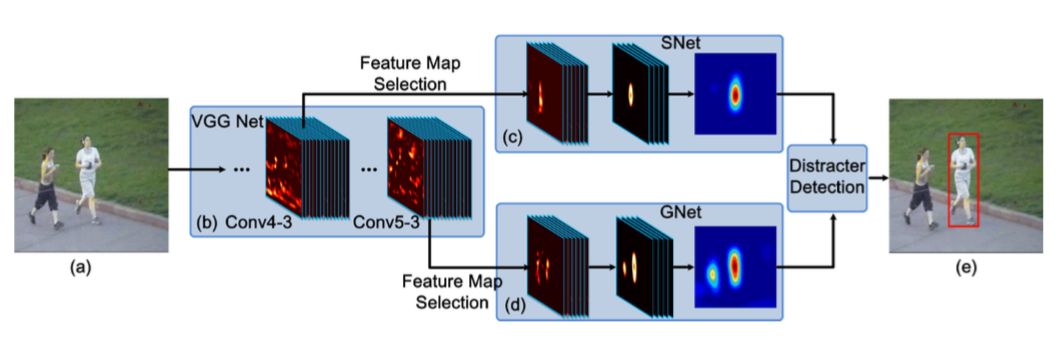
基于以上觀察,FCNT最終提出了如下圖所示的模型結構:
1.對于Conv4-3和Con5-3采用VGG網絡的結構,選出和當前跟蹤目標最相關的特征圖通道;
2.為了避免過擬合,對篩選出的Conv5-3和Conv4-3特征分別構建捕捉類別信息GNet和SNet;
3.在第一幀中使用給出的邊框生成熱度圖(heap map)回歸訓練SNet和GNet;
4.對于每一幀,其預測結果為中心裁剪區域,將其分別輸入GNet和SNet中,得到兩個預測的熱圖,并根據是否有干擾來決定使用哪個熱圖。
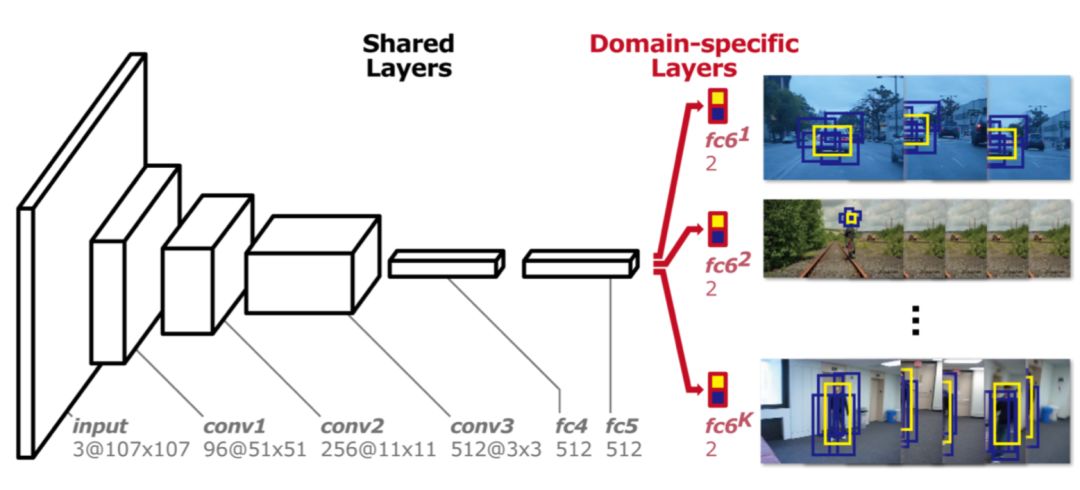
區別與FCNT,MD Net使用視頻中所有序列來跟蹤它們的運動。但序列訓練也存在問題,即不同跟蹤序列與跟蹤目標完全不一樣。最終MD Net提出多域的訓練思想,網絡結構如下圖所示,該網絡分為兩個部分:共享層和分類層。網絡結構部分用于提取特征,最后分類層區分不同的類別。
4.語義分割

計算機視覺的核心是分割過程,它將整個圖像分成像素組,然后對其進行標記和分類。語言分割試圖在語義上理解圖像中每個像素的角色(例如,汽車、摩托車等)。
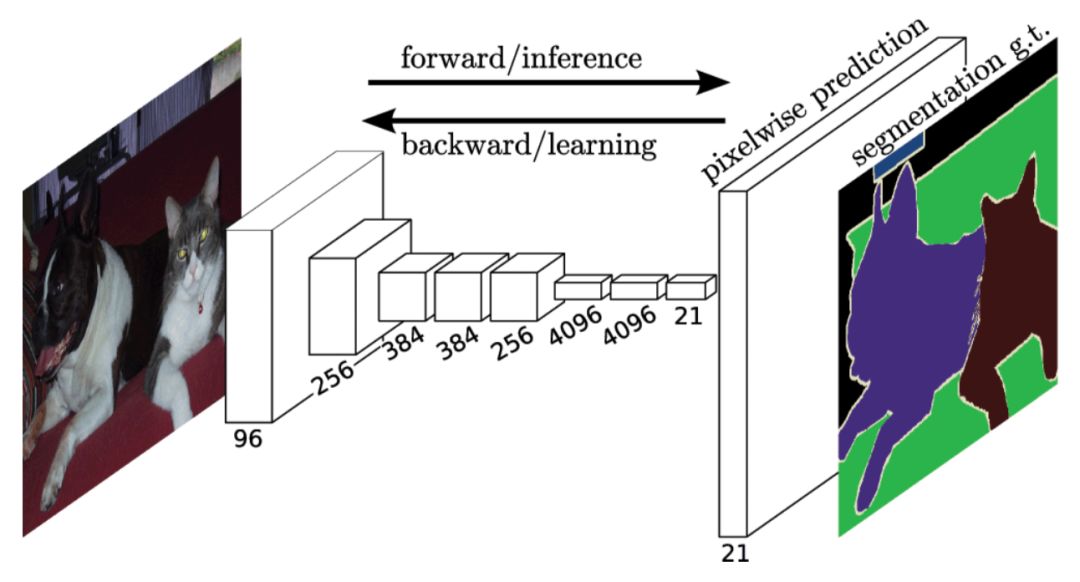
CNN同樣在此項任務中展現了其優異的性能。典型的方法是FCN,結構如下圖所示。FCN模型輸入一幅圖像后直接在輸出端得到密度預測,即每個像素所屬的類別,從而得到一個端到端的方法來實現圖像語義分割。
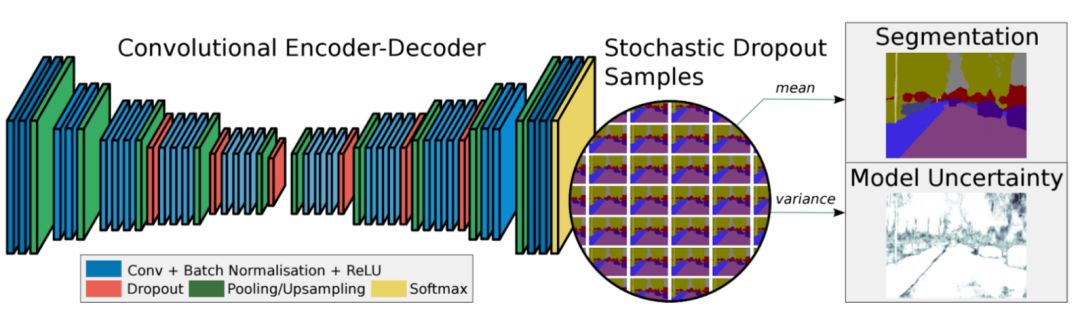
與FCN上采樣不同,SegNet將最大池化轉移至解碼器中,改善了分割分辨率。提升了內存的使用效率。
還有一些其他的方法,比如全卷積網絡、擴展卷積,DeepLab以及RefineNet等。
5.實例分割

除了語義分割之外,實例分割還分割了不同的類實例,例如用5種不同顏色標記5輛汽車。在分類中,通常有一個以一個物體為焦點的圖像,任務是說出這個圖像是什么。但是為了分割實例,我們需要執行更復雜的任務。我們看到復雜的景象,有多個重疊的物體和日常背景,我們不僅對這些日常物體進行分類,而且還確定它們的邊界、差異和彼此之間的關系。

到目前為止,我們已經看到了如何以許多有趣的方式使用CNN功能來在帶有邊界框的圖像中有效地定位日常用品。我們可以擴展這些技術來定位每個對象的精確像素,而不僅僅是邊界框嗎?
CNN在此項任務中同樣表現優異,典型算法是Mask R-CNN。Mask R-CNN在Faster R-CNN的基礎上添加了一個分支以輸出二元掩膜。該分支與現有的分類和邊框回歸并行,如下圖所示:
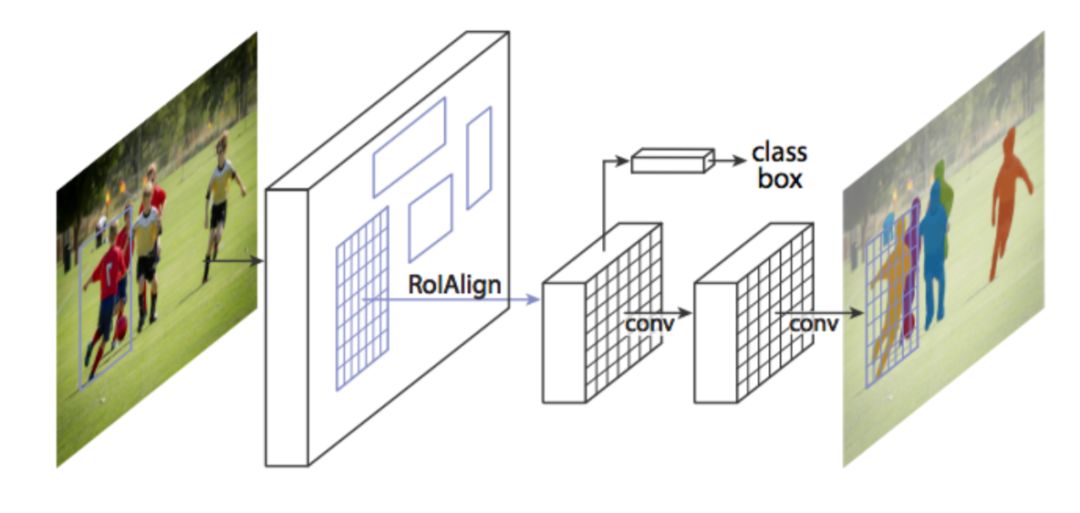
Faster-RCNN在實例分割任務中表現不好,為了修正其缺點,Mask R-CNN提出了RolAlign層,通過調整Rolpool來提升精度。從本質上講,RolAlign使用雙線性插值避免了取整誤差,該誤差導致檢測和分割不準確。
一旦掩膜被生成,Mask R-CNN結合分類器和邊框就能產生非常精準的分割:

結論
以上五種計算機視覺技術可以幫助計算機從單個或一系列圖像中提取、分析和理解有用信息。此外,還有很多其它的先進技術等待我們的探索,比如風格轉換、動作識別等。希望本文能夠引導你改變看待這個世界的方式。
-
計算機視覺
+關注
關注
8文章
1698瀏覽量
45977 -
深度學習
+關注
關注
73文章
5500瀏覽量
121113
原文標題:一文看懂深度學習改變的五大計算機視覺技術
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【小白入門必看】一文讀懂深度學習計算機視覺技術及學習路線

計算機視覺有哪些優缺點
計算機視覺技術的AI算法模型
計算機視覺的工作原理和應用
計算機視覺與人工智能的關系是什么
計算機視覺與智能感知是干嘛的
計算機視覺怎么給圖像分類
機器視覺與計算機視覺的區別
計算機視覺的主要研究方向
計算機視覺的十大算法






 工商網監
工商網監
評論