 讓Ceph存儲的性能飆升的原因竟然是因為它?
讓Ceph存儲的性能飆升的原因竟然是因為它?
?Ceph作為一款開源的分布式存儲軟件解決方案,由于其功能豐富、社區活躍,在公有云和私有云環境中有著廣泛的應用。
然而,由于Ceph的大規模分布式架構原因,其IO路徑過長,使得其性能一直被業界所詬病。
現實中,Ceph更多用在備份和歸檔等性能要求不高的場景。在這種場景下,一般存儲介質采用HDD,很少采用全閃存的配置。
伴隨著固態盤(SSD)價格的不斷走低,云提供商紛紛開始著手為客戶打造具備卓越性能和高可靠性的全閃存存儲。
為此,他們迫切希望獲得基于 Ceph 的全閃存參考架構,并了解具體的性能表現和最佳優化實踐。
英特爾?傲騰? 技術前所未有地集高吞吐量、低延遲、高服務質量和高耐用性優勢于一身,它由 3D XPoint? 內存介質和英特爾?軟件等組合而成。
這些構建模塊相互配合,配合至強可擴展處理器,在降低延遲和加速系統性能方面實現了具體提升,能夠全面滿足工作負載對于大容量和快速存儲的需求。
本篇文章將圍繞 Ceph 全閃存存儲系統參考架構和基于英特爾?至強?可擴展處理器的軟件優化等方面,介紹Intel所取得的進展。
在本文中,將重點為您介紹Ceph 參考架構和性能結果,該架構的配置包括 RADOS 塊設備(RBD)接口、英特爾?傲騰? 技術和英特爾?至強?可擴展處理器產品家族(英特爾?至強?鉑金 8180 處理器和英特爾?至強?金牌 6140 處理器)。
我們先介紹采用英特爾?傲騰? 技術和英特爾?至強?可擴展處理器的Ceph 全閃存陣列(AFA)參考架構,然后介紹典型工作負載的性能結果和系統特性。
Intel建議Ceph AFA采用英特爾?至強?鉑金 8180 處理器,它是英特爾?至強?可擴展處理器產品家族中先進的處理器。
建議使用英特爾?傲騰? 固態盤(SSD)作為BlueStore WAL(Write-Ahead Logging) 設備,使用基于 NAND 固態盤作為數據硬盤,并使用 Mellanox 40 GbE 網絡接口卡(NIC)作為高速以太網數據端口,具備最高性能(吞吐量和延遲)。它是 I/O 密集型工作負載的最佳選擇。

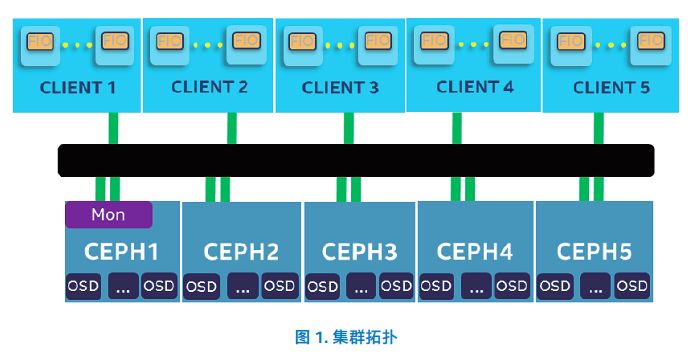
測試系統由5個Ceph存儲服務器和5個客戶端節點組成。
每個存儲節點配置Intel Xeon Platinum 8180處理器和384 GB內存,使用1x Intel Optane SSD DC P4800X 375GB作為BlueStore WAL設備,4x Intel SSD DC P3520 2TB作為數據驅動器,以及2x Mellanox 40 GbE NIC作為Ceph的獨立集群和公共網絡。
同時,每個節點均使用 Ceph 12.2.2,并且每個英特爾?固態盤 DC P3520 系列運行一個對象存儲守護程序(OSD)。用于測試的 RBD 池配置有 2 個副本。
對于客戶端,每個節點配置了英特爾?至強?鉑金 8180 處理器、384 GB 內存和 1 個 Mellanox 40GbE 網卡。
Intel設計了四種不同的工作負載來模擬云中典型的全閃存 Ceph 集群(基于帶 librbd 的 fio),其中包括 4K 隨機讀寫和 64K 順序讀寫,以分別模擬隨機工作負載和順序工作負載。對于每個測試用例,IO 性能(IOPS 或帶寬)使用卷擴展數量(最大擴展到 100)來衡量,每個卷配置為 30 GB。
這些卷已預先分配,以消除 Ceph 精簡配置機制的影響,獲得穩定且可復制的結果。每次測試之前停止 OSD 頁高速緩存,以消除頁高速緩存的影響。在每個測試用例中,fio 配置了 300 秒的準備時限和 300 秒的數據采集時限。
?
4K隨機寫特性
用戶空間消耗的CPU利用率為37%,占CPU總利用率的75%。分析結果顯示Ceph OSD過程消耗了大部分CPU周期; CPU還有空間的可疑原因是軟件線程和鎖定模型實現限制了Ceph在單個節點上的擴展能力,這仍然是下一步優化工作。
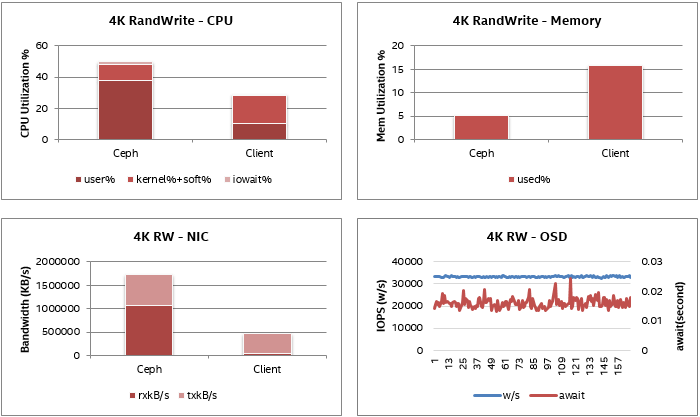
4K隨機寫入的系統指標
?
4K隨機讀取特性
CPU利用率約為60%,其中IOWAIT約占15%,因此實際CPU消耗也約為45%;類似于隨機寫例。OSD磁盤的讀取IOPS非常穩定在80K,40 GBbE NIC帶寬約為2.1 GB/s。沒有觀察到明顯的硬件瓶頸;疑似軟件瓶頸類似于4K隨機寫入案例,需要進一步調查。
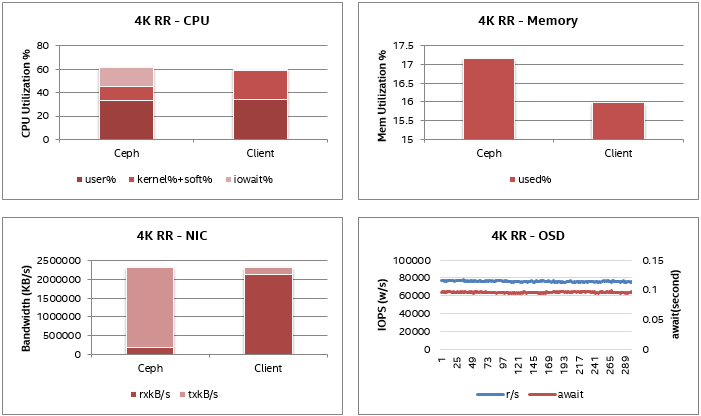
4K隨機讀取的系統指標
64K順序寫入特性
順序寫入的CPU利用率和內存消耗非常低。由于OSD復制數為2,因此NIC數據的傳輸帶寬是接收帶寬的兩倍,傳輸帶寬包括兩個NIC的帶寬,一個用于公共網絡,一個用于群集網絡,每個NIC大約1.8 GB /每個端口。OSD磁盤AWAIT時間受到嚴重波動,最高磁盤延遲超過4秒,而磁盤IOPS非常穩定。
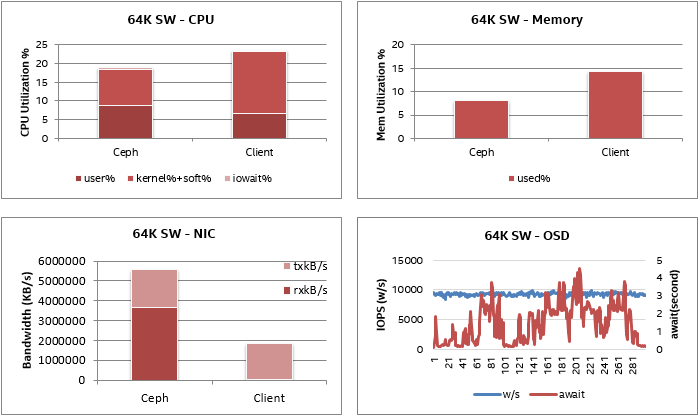
64K順序寫入的系統指標
?
64K順序讀取特性
對于順序讀取案例,我們觀察到一個NIC的帶寬達到4.4 GB/s,約占總帶寬的88%。順序寫入的CPU利用率和內存消耗非常低。OSD磁盤讀取IOPS和延遲穩定。
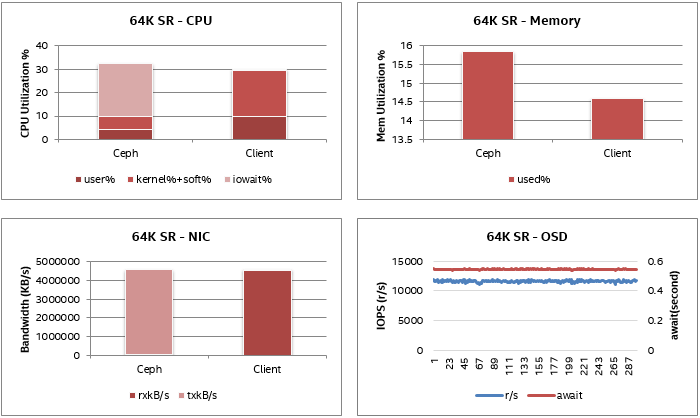
64K順序讀取的系統指標
總體來看,基于英特爾Optane技術的Ceph AFA集群展示了出色的吞吐量和延遲。
64K順序讀寫吞吐量分別為21,949 MB/s和8,714 MB/s(最大為40 GbE NIC)。4K隨機讀取吞吐量為2,453K IOPS,平均延遲為5.36 ms,而4K隨機寫入吞吐量為500K IOPS,平均延遲為12.79 ms。

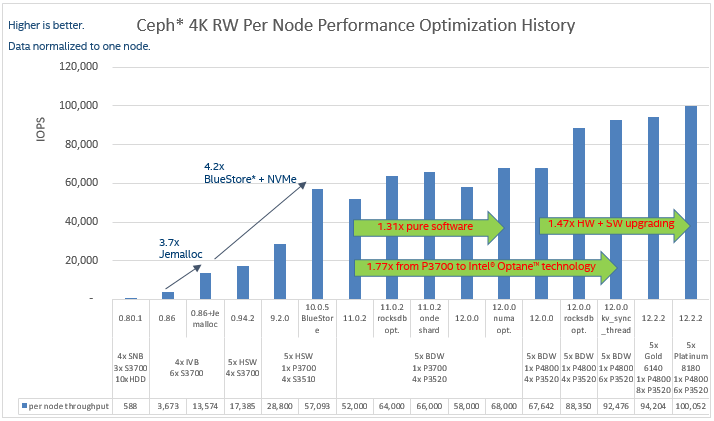
其實自從Ceph Giant發布以來,英特爾一直與社區,生態系統和合作伙伴密切合作,一直優化Ceph的性能。下圖顯示了Ceph主要版本和不同Intel平臺上4K隨機寫入工作負載的性能優化歷史記錄。
憑借新的Ceph主要版本,后端存儲,結合核心平臺變化和SSD升級,單個節點的4K隨機寫入性能提高了27倍(每個節點每秒輸入/輸出操作3,673次(IOPS)至每個節點100,052 IOPS)!
這使得使用Ceph構建高性能存儲解決方案成為可能。
在本文中,我們在英特爾至強可擴展處理器上看到了采用Ceph AFA參考架構的英特爾Optane技術的性能結果。此配置展示了出色的吞吐量和延遲,除了延遲比傳統的高端存儲有些差距外,帶寬和IOPS都達到了高端存儲的水平。
對于讀取密集型工作負載,尤其是小塊讀,對CPU性能要求比較高,建議使用英特爾至強可擴展處理器系列的頂級處理器,例如英特爾至強鉑金8000系列處理器。
與采用英特爾至強可擴展處理器上的Ceph AFA集群的默認配置的英特爾Optane技術相比,軟件調優和優化還為讀取和寫入提供了高達19%的性能提升。
由于使用當前的硬件配置可以觀察到硬件性能還有凈空,因此性能有望在不久的將來通過持續的Ceph優化(如RDMA messenger,NVMe-focus對象存儲,async-osd等)不斷改進。
相信有了英特爾?至強?可擴展處理器和傲騰?技術的支持,加上Ceph不斷優化,未來Ceph的性能將會更好,Ceph也將越來越多用于主存儲場景,而不僅僅是目前聚焦的第二存儲場景。
-
存儲器
+關注
關注
38文章
7484瀏覽量
163765 -
Ceph
+關注
關注
1文章
22瀏覽量
9401
原文標題:讓Ceph存儲的性能飆升的原因竟然是因為它?
文章出處:【微信號:TopStorage,微信公眾號:存儲加速器】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
PCM2704的ROM編程好了,竟然是亂碼,為什么?
遠程升級頻頻失敗?原因竟然是…

異常重啟怎么破?多方排查后,原因竟然是。。。



谷景科普一體成型貼片電感很燙是因為短路嗎
基于DPU的Ceph存儲解決方案


見證歷史!SpaceX的PCB供應商竟然是它

使用tc397進行收發的時候沒有響應是因為什么?
IBM積極推進Ceph擴展,以打造AI領域的底層數據存儲基石
請問怎樣使用cephadm部署ceph集群呢?

錫膏不上錫是因為活性不足嗎?






 工商網監
工商網監
評論