 深度學習和智能理論在未來會帶來什么?
深度學習和智能理論在未來會帶來什么?
近日,圖靈獎得主、深度學習巨頭Geoffrey Hinton和Yann LeCun在ACM FCRC 2019上發表了精彩演講。
二人分別在大會上做了題為《深度學習革命》和《深度學習革命:續集》的精彩演講。目前視頻已經公開:
https://www.youtube.com/watch?v=VsnQf7exv5I
新智元對演講內容進行了整理。
Geoffrey Hinton:《深度學習革命》
Geoffrey Hinton
Hinton表示,自從20世紀50年代開始,人工智能存在兩種范式:分別是邏輯啟發的方法和生物學啟發的方法。
邏輯啟發的方法(The logic-inspired approach):智能的本質是使用符號規則來操縱符號表達。我們應該專注于推理。
生物學啟發的方法(The biologically-inspired approach):智能的本質是學習神經網絡中連接的優勢。我們應該專注于學習和感知。
不同的范式便使得最終的目標有所不同。因此,在內部表示(internal representation)方面也存在著兩種觀點:
內部表示是符號表達式。程序員可以用一種明確的語言把它們交給計算機;可以通過對現有表示應用規則派生新的表示。
內部表示與語言完全不同。它們是神經活動的向量(big vectors);它們對神經活動的其他載體有直接的因果影響;這些向量是從數據中學到的。
由此也導致了兩種讓計算機完成任務的方式。
首先是智能設計:有意識地精確計算出你將如何操縱符號表示來執行任務,然后極其詳細地告訴計算機具體要做什么。
其次是學習:向計算機展示大量輸入和所需輸出的例子。讓計算機學習如何使用通用的學習程序將輸入映射到輸出。
Hinton舉了一個例子:人們花了50年的時間,用符號型人工智能(symbolic AI)來完成的任務就是“看圖說話”。
針對這項任務,人們嘗試了很長時間來編寫相應的代碼,即便采用神經網絡的方法依舊嘗試了很長一段時間。最終,這項任務得到很好解決的方法竟然是基于純學習的方法。
因此,對于神經網絡而言,存在如下的核心問題:
包含數百萬權重和多層非線性神經元的大型神經網絡是非常強大的計算設備。但神經網絡能否從隨機權重開始,并從訓練數據中獲取所有知識,從而學習一項困難的任務(比如物體識別或機器翻譯)?
針對這項問題,前人們付出了不少的努力:



針對如何訓練人工神經網絡,Hinton認為分為兩大方法,分別是監督訓練和無監督訓練。
監督訓練:向網絡顯示一個輸入向量,并告訴它正確的輸出;調整權重,減少正確輸出與實際輸出之間的差異。
無監督訓練:僅向網絡顯示輸入;調整權重,以便更好地從隱含神經元的活動中重建輸入(或部分輸入)。

而反向傳播(backpropagation algorithm)只是計算權重變化如何影響輸出錯誤的一種有效方法。不是一次一個地擾動權重并測量效果,而是使用微積分同時計算所有權重的誤差梯度。
當有一百萬個權重時,反向傳播方法要比變異方法效率高出一百萬倍。
然而,反向傳播算法卻又讓人感到失望。
在20世紀90年代,雖然反向傳播算法的效果還算不錯,但并沒有達到人們所期待的那樣——深度網絡訓練非常困難;在中等規模的數據集上,一些其他機器學習方法甚至比反向傳播更有效。
符號型人工智能的研究人員稱,期望在大型深層神經網絡中學習困難的任務是愚蠢的,因為這些網絡從隨機連接開始,且沒有先驗知識。
Hinton舉了三個非常荒誕的理論:

而后,深度學習開始被各種拒絕:
2007年:NIPS program committee拒絕了Hinton等人的一篇關于深度學習的論文。因為他們已經接收了一篇關于深度學習的論文,而同一主題的兩篇論文就會“顯得過多”。
2009年:一位評審員告訴Yoshua Bengio,有關神經網絡的論文在ICML中沒有地位。
2010年:一位CVPR評審員拒絕了Yann LeCun的論文,盡管它擊敗了最先進的論文。審稿人說它沒有告訴我們任何關于計算機視覺的信息,因為一切都是“學到的”。
而在2005年至2009年期間,研究人員(在加拿大!)取得了幾項技術進步,才使反向傳播能夠更好地在前饋網絡中工作。
到了2012年,ImageNet對象識別挑戰賽(ImageNet object recognition challenge)有大約100萬張從網上拍攝的高分辨率訓練圖像。
來自世界各地的領先計算機視覺小組在該數據集上嘗試了一些當時最好的計算機視覺方法。其結果如下:

這次比賽的結果后,計算機視覺相關的組委會們才突然發覺原來深度學習是有用的!
Hinton在演講中討論了一種全新的機器翻譯方式。
對于每種語言,我們都有一個編碼器神經網絡和一個解碼器神經網絡。編碼器按原句中的單詞順序讀取(它最后的隱藏狀態代表了句子所表達的思想)。而解碼器用目標語言表達思想。
自2014年年以來,神經網絡機器翻譯得了很大的發展。

接下來,Hinton談到了神經網絡視覺的未來。
他認為卷積神經網絡獲得了巨大的勝利,因為它若是在一個地方能行得通,在其它地方也能使用。但它們識別物體的方式與我們不同,因此是對抗的例子。
人們通過使用對象的坐標系與其部分的坐標系之間的視點不變幾何關系來識別對象。Hinton認為神經網絡也能做到這一點(參考鏈接:arxiv.org/abs/1906.06818)。
那么,神經網絡的未來又是什么呢?
Hinton認為:
幾乎所有人工神經網絡只使用兩個時間尺度:對權重的緩慢適應和神經活動的快速變化。但是突觸在多個不同的時間尺度上適應。它可以使快速權重(fast weight)進行short-term memory將使神經網絡變得更好,可以改善優化、可以允許真正的遞歸。
Yann LeCun演講:《深度學習革命:續集》
Yann LeCun

Jeff剛才提到了監督學習,監督學習在數據量很大時效果很好,可以做語音識別、圖像識別、面部識別、從圖片生成屬性、機器翻譯等。
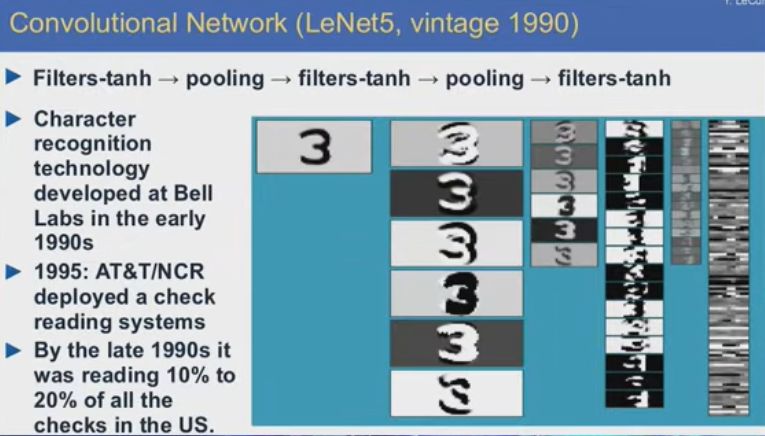
如果神經網絡具有某些特殊架構,比如Jeff在上世紀八九十年代提出的那些架構,可以識別手寫文字,效果很好,到上世紀90年代末時,我在貝爾實驗室研發的這類系統承擔了全美手寫文字識別工作的10%-20%,不僅在技術上,而且在商業上也是一個成功。
到后來,整個社群一度幾乎拋棄了神經網絡,一方面是因為是缺乏大型數據集,還有部分原因是當時編寫的軟件過于復雜,投資很大,還有一部分原因是當時的計算機速度不夠快,不足以運行其他所有應用。

卷積神經網絡其實是受到了生物學的啟發,它并不是照搬生物學,但確實從中得到很多啟發,比如視覺皮層的結構,以及在學習信號處理時自然而然產生的一些觀點,比如filtering是處理音視頻信號的好辦法,而卷積是filtering的一種方式。這些經典理念早在上世紀五六十年代就由Hubel和wiesel等人在神經科學領域提出,日本科學家Fukushima在上世紀80年代對其也有貢獻。
我從這些觀點和成果中受到啟發,我發現可以利用反向傳播訓練神經網絡來復現這些現象。卷積網絡的理念是,世界上的物體是由各個部分構成的,各個部分由motif構成,而motif是由材質和邊緣的基本組合,邊緣是由像素的分布構成的。如果一個層級系統能夠檢測到有用的像素組合,再依次到邊緣、motif、最后到物體的各個部分,這就是一個目標識別系統。
層級表示不僅適用于視覺目標,也適用于語音、文本等自然信號。我們可以使用卷積網絡識別面部、識別路上的行人。

在上世紀90年代到2010年左右,出現了一段所謂“AI寒冬”,但我們沒有停下腳步,在人臉識別、行人識別,將機器學習用在機器人技術上,使用卷積網絡標記整個圖像,圖像中的每個像素都會標記為“能”或“不能”被機器人穿越,而且數據收集是自動的,無需手動標記。
幾年之后,我們使用類似的系統完成目標分割任務,整個系統可以實現VGA實時部署,對圖像上的每個像素進行分割。這個系統可以檢測行人、道路、樹木,但當時這個結果并未馬上得到計算機社群的認可。

最近的視覺識別系統的一個范例是Facebook的“全景特征金字塔網絡”,可以通過多層路徑提取圖像特征,由多層路徑特征生成輸出圖像,其中包含圖像中全部實例和目標的掩模,并輸出分類結果,告訴你圖像中目標的分類信息。不僅是目標本身的分類,還包括背景、材質等分類,比如草地、沙地、樹林等。可以想象,這種系統對于自動駕駛會很有用。
醫療成像及圖像分割
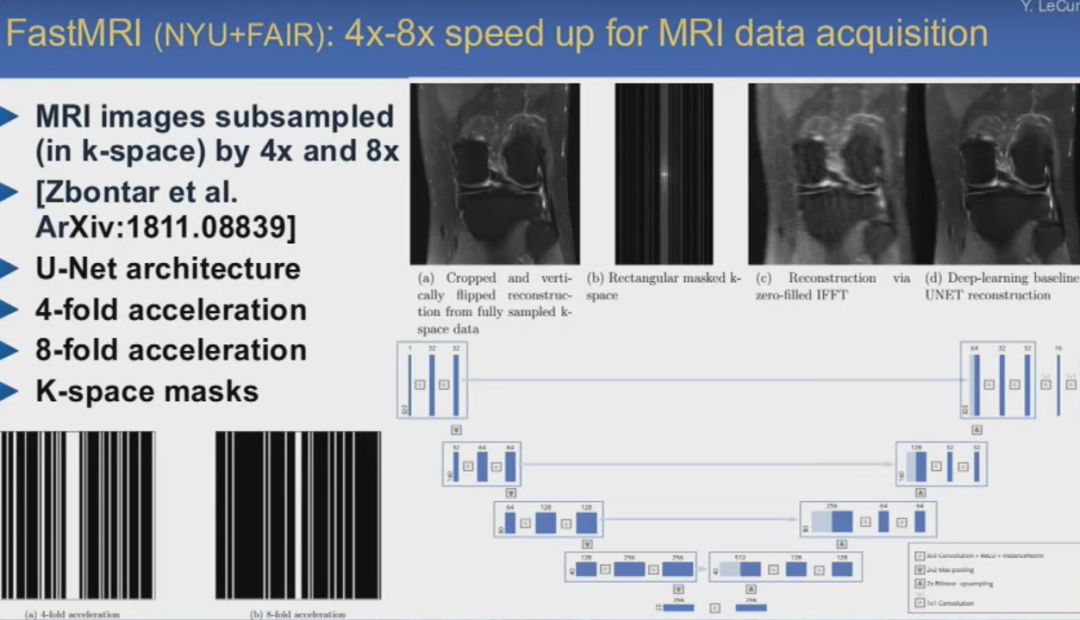
卷積網絡對于醫學成像應用也很有幫助。與上面提到的網絡類似,它也分為解碼器部分,負責提取圖像特征,另一部分負責生成輸出圖像,對其進行分割。
神經網絡機器翻譯
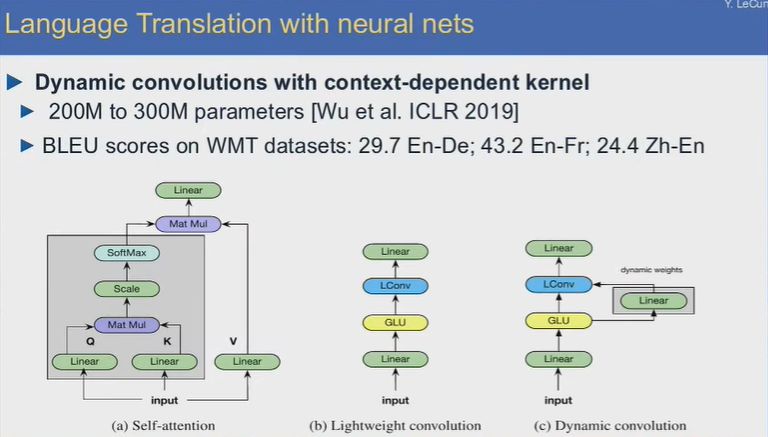
在翻譯應用上,采用了許多網絡架構上的創新,如自注意力機制、輕量卷積、動態卷積等,實現基于語境的動態卷積網絡內核。在ICML2019上的最新機器翻譯卷積網絡模型,其參數數量達到200M至300M,WMT數據集上的BLEU得分:英語-德語29.7,英語-法語43.2,漢語-英語24.4。
自動駕駛系統

游戲
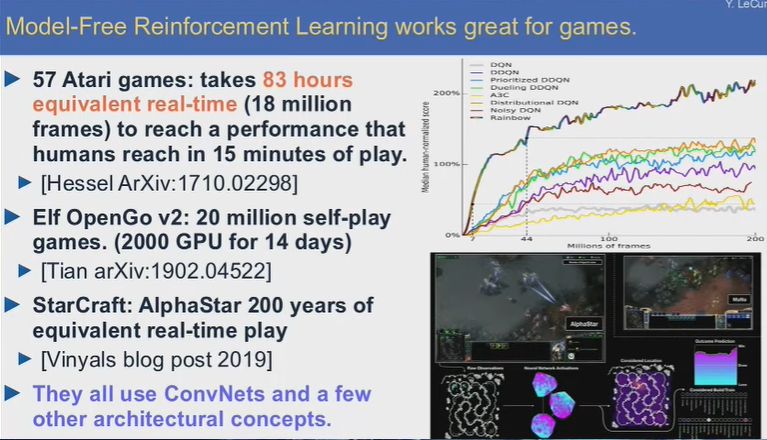
無模型強化學習很適合游戲領域應用。現在強化學習領域的一大問題就是數據的缺乏,使用強化學習訓練系統需要大量的重復試驗和試錯,要達到人類訓練15分鐘的水平,機器需要大概80小時的實時游戲,對于圍棋來說,要達到超人的水平,機器需要完成大約2000萬盤的自對弈。Deepmind最近的《星際爭霸2》AI則完成了大約200年的游戲時間。

這種海量重復試驗的方式在現實中顯然不可行,如果你想教一個機器人抓取目標,或者教一臺自動駕駛車學會駕駛,如此多的重復次數是不行的。純粹的強化學習只能適用于虛擬世界,那里的嘗試速度要遠遠快于現實世界。
這就引出了一個問題:為什么人和動物的學習速度這么快?
和自動駕駛系統不同,我們能夠建立直覺上真實的模型,所以不會把車開下懸崖。這是我們掌握的內部模型,那么我們是怎么學習這個模型的,如何讓機器學會這個模型?基本上是基于觀察學會的。
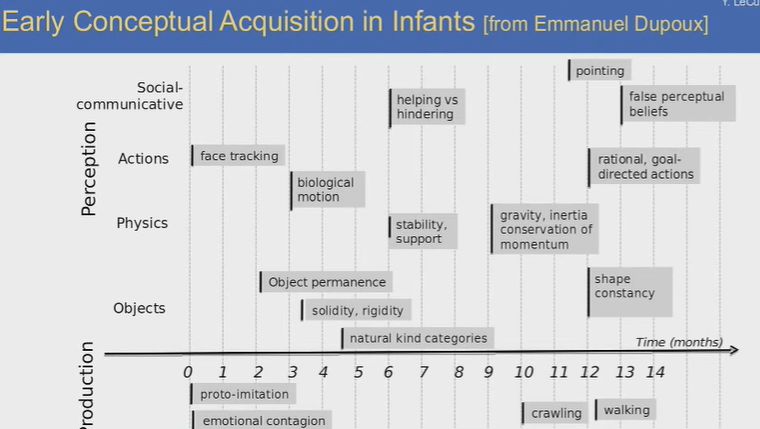
動物身上也存在類似的機制。預測是智能的不可或缺的組成部分,當實際情況和預測出現差異時,實際上就是學習的過程。

上圖顯示了嬰兒學習早期概念和語言的過程。嬰兒基本上是通過觀察學習這個世界的,但其中也有一小部分是通過交流。
自監督學習:預測與重建
以視頻內容預測為例,給定一段視頻數據,從其中一段視頻內容預測另外一段空白處的內容。自監督學習的典型場景是,事先不公布要空出哪一段內容,實際上根本不用真的留出空白,只是讓系統根據一些限制條件來對輸入進行重建。系統只通過觀察來完成任務,無需外部交互,學習效率更高。

機器在學習過程中被輸入了多少信息?對于純強化學習而言,獲得了一些樣本的部分碎片信息(就像蛋糕上的櫻桃)。對于監督學習,每個樣本獲得10-10000bit信息(蛋糕表面的冰層),對于半監督學習,每個樣本可獲得數百萬bit的信息(整個蛋糕內部)。

自監督學習的必要性
機器學習的未來在與自監督和半監督學習,而非監督學習和純強化學習。自監督學習就像填空,在NLP任務上表現很好(實際上是預測句子中缺失的單詞),但在圖像識別和理解任務上就表現一般。

為什么?因為這世界并不全是可預測的。對于視頻預測任務,結果可能有多重可能,訓練系統做出唯一一種預測的結果往往會得到唯一“模糊”的結果,即所有未來結果的“平均”。這并不是理想的預測。
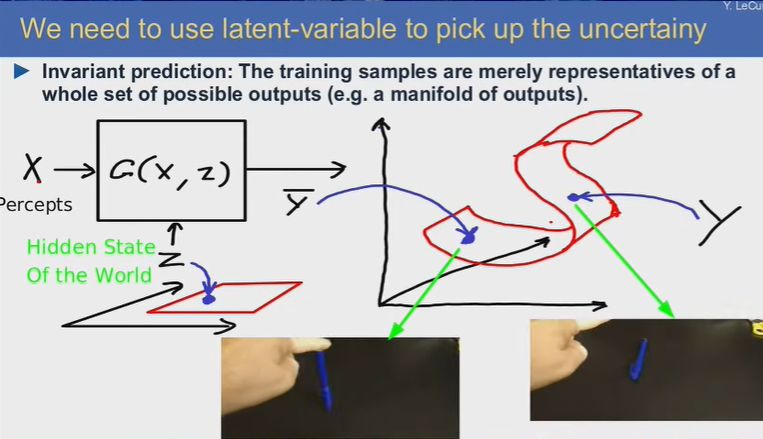
我們需要利用隱變量來處理不確定性。訓練樣本只是整個可能的輸出集合的表示。

幾百年以來,理論的提出往往伴隨著之后的偉大發明和創造。深度學習和智能理論在未來會帶來什么?值得我們拭目以待。
-
人工智能
+關注
關注
1791文章
47200瀏覽量
238269 -
深度學習
+關注
關注
73文章
5500瀏覽量
121113
原文標題:圖靈獎得主Hinton和 LeCun最新演講:深度學習如何繼續革命?
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
GPU在深度學習中的應用 GPUs在圖形設計中的作用
NPU在深度學習中的應用
《AI for Science:人工智能驅動科學創新》第一章人工智能驅動的科學創新學習心得
FPGA做深度學習能走多遠?
深度學習算法在集成電路測試中的應用
深度學習中的時間序列分類方法
深度學習在視覺檢測中的應用
基于深度學習的小目標檢測
人工智能、機器學習和深度學習是什么
深度學習與卷積神經網絡的應用
深度學習在自動駕駛中的關鍵技術
FPGA在深度學習應用中或將取代GPU
詳解深度學習、神經網絡與卷積神經網絡的應用






 工商網監
工商網監
評論