 能生成Deepfake也能診斷癌癥,GAN與惡的距離
能生成Deepfake也能診斷癌癥,GAN與惡的距離
GAN可能是最近人工智能圈最為人熟知的技術之一。但是它的爆火不僅是由于這個技術出神入化的好用,還因為由他催生的相關應用導致了各種倫理道德問題。
最受關注的當然是Deepfake(深度偽造),這款操作容易且效果完美的換臉應用,讓人們談“GAN”色變。
而近期,Deepfake甚至有了升級版,走紅網絡的一鍵生成裸照軟件DeepNude,只要輸入一張完整的女性圖片就可自動生成相應的裸照,由于廣泛傳播而造成了預料之外的后果,開發者最終將APP下架。
被一鍵脫衣的霉霉
相關技術引發了一系列社會后果,并且引發了政府立法部門的重視。2019年6月13日,美國眾議院情報委員會召開關于人工智能深度偽造的聽證會,公開談論了深度偽造技術對國家、社會和個人的風險及防范和應對措施。
讓人嗤之以鼻的同時,真正的研究者們也在用GAN推動人類社會的發展。據《MIT科技評論》報道,呂貝克大學研究人員近期剛剛利用deepfake背后同樣的技術,合成了與真實影像無異的醫學圖像,解決了沒有足夠的訓練數據的問題,而這些圖像將可以用于訓練AI通過X光影像發現不同的癌癥。
那么,技術本身就存在原罪么?又是哪里出了錯呢?
讓我們回到GAN誕生的那天,從頭回顧這一讓人又愛又恨的技術發展的前世今生。
GAN的誕生故事:一場酒后的奇思妙想
時間拉回到2014年的一晚,Ian Goodfellow和一個剛剛畢業的博士生一起喝酒慶祝。在蒙特利爾一個酒吧,一些朋友希望他能幫忙看看手頭上一個棘手的項目:計算機如何自己生成圖片。
研究人員已經使用了神經網絡(模擬人腦的神經元網絡的一種算法),作為生成模型來創造合理的新數據。但結果往往不盡人意。計算機生成的人臉圖像通常不是模糊不清,就是缺耳少鼻。
Ian Goodfellow朋友們提出的方案是對那些組成圖片的元素進行復雜的統計分析以幫助機器自己生成圖片。這需要進行大量的數據運算,Ian Goodfellow告訴他們這根本行不通。
邊喝啤酒邊思考問題時,他突然有了一個想法。如果讓兩個神經網絡相互對抗會出現什么結果呢?他的朋友對此持懷疑態度。
當他回到家,他女朋友已經熟睡,他決定馬上實驗自己的想法。那天他一直寫代碼寫到凌晨,然后進行測試。第一次運行就成功了!
那天晚上他提出的方法現在叫做GAN,即生成對抗網絡(generative adversarial network)。
Goodfellow自己可能沒想到這個領域會發展得如此迅速,GAN的應用會如此廣泛。
下面我們先來看幾張照片。
如果你沒有親眼看到我去過的地方,那就可以認為這些照片完全是假的。
當然,我并不是說這些都是ps的或者CGI編輯過的,無論Nvidia稱他們的新技術是如何了得,那也只是圖片,不是真實的世界。
也就是說,這些圖像完全是用GPU計算層層疊加,并且通過燒錢生成的。
能夠做出這些東西的算法就是對抗生成網絡,對于那些剛開始學習機器學習的人而言,編寫GAN是一個漫長的旅途。在過去的幾年中,基于對抗生成網絡應用的創新越來越多,甚至比Facebook上發生的隱私丑聞還多。
2014年以來GANs不斷進行改進才有了如今的成就,但是要一項一項來回顧這個過程,就像是要重新看一遍長達八季的“權力的游戲”,非常漫長。所以,在此我將僅僅重溫這些年來GAN研究中一些酷炫成果背后的關鍵思想。
我不準備詳細解釋轉置卷積(transposed convolutions)和瓦瑟斯坦距離(Wasserstein distance)等概念。相反,我將提供一些我覺得比較好的資源鏈接,你可以使用這些資源快速了解這些概念,這樣你就可以看到它們在算法中是如何使用的。
下文的閱讀需要你掌握深度學習的基礎知識,并且知道卷積神經網絡的工作原理,否則讀起來可能會有點難度。
鑒于此,先上一張GAN發展路線圖:
GAN路線圖
圖中的過程我們將在下文一步一步地講解。讓我們先來看看內容大綱吧。
GAN:Generative Adversarial Networks
DCGAN:Deep Convolutional Generative Adversarial Network
CGAN:Conditional Generative Adversarial Network
CycleGAN
CoGAN:Coupled Generative Adversarial Networks
ProGAN:Progressive growing of Generative Adversarial Networks
WGAN:Wasserstein Generative Adversarial Networks
SAGAN:Self-Attention Generative Adversarial Networks
BigGAN:Big Generative Adversarial Networks
StyleGAN:Style-based Generative Adversarial Networks
GAN:Generative Adversarial Networks
看到這張圖你首先想到的是什么,是不是覺得這像素也太低了,還看得人難受,尤其是對于密集恐懼癥患者來說,這張圖片看起來像是某個數學書呆子在excel表中放大了一張縮小的照片。
我們來看看這圖片究竟是什么?
看完視頻是不是發現除了Excel,其他都猜對了。
早在2014年,Ian Goodfellow提出了這個革命性的想法——讓兩個神經網絡互相競爭(或合作,這是一個視角問題)。
感興趣的同學可以查看Ian Goodfellow 提出GAN時的原文。
論文鏈接:
https://arxiv.org/abs/1406.2661
代碼鏈接:
https://github.com/goodfeli/adversarial
作者相關論文鏈接:
https://arxiv.org/abs/1701.00160
一個神經網絡試圖生成真實數據(注意:GAN可用于給任何數據分布建模,但近來其主要用于圖像),而另一個神經網絡則試圖判別真實數據和生成器網絡生成的數據。
生成器網絡使用判別器作為損失函數,并更新其參數以生成看起來更真實的數據。
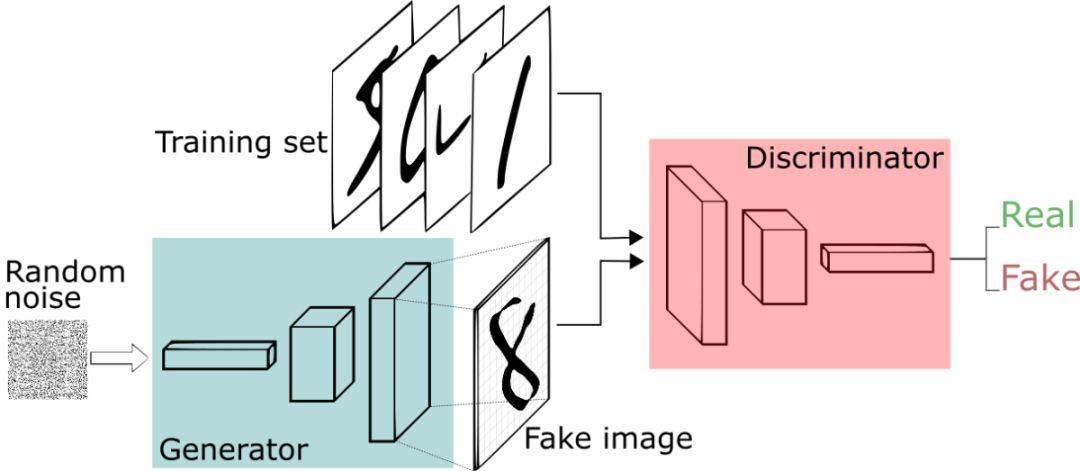
另一方面,判別器網絡更新其參數以使其更好地從真實數據中鑒別出假數據,所以它這方面的工作會變得更好。
這就像貓和老鼠的游戲,持續進行,直到系統達到所謂的“平衡”,其中生成器能夠生成看起來足夠真實的數據,然后判別器則輕易就能正確判斷真假。
到目前為止,如果順利的話,你的代碼無誤,亞馬遜也沒有斃掉你的spot實例(順便說一句,如果使用FloydHub就不會出現這個問題,因為他們提供了備用的GPU機器),那么你現在就留下了一個能從同樣的數據分布中準確生成新數據的生成器,它生成的數據則可以成為你的訓練集。
這只是非常簡單的一種GAN。到此,你應該掌握GAN就是使用了兩個神經網絡——一個用于生成數據,一個是用來對假數據和真實數據進行判別。理論上,您可以同時訓練它們,然后不斷迭代,直至收斂,這樣生成器就可以生成全新的,逼真的數據。
DCGAN:Deep Convolutional Generative Adversarial Network
論文:
https://arxiv.org/abs/1511.06434
代碼:
https://github.com/floydhub/dcgan
其他文章:
https://towardsdatascience.com/up-sampling-with-transposed-convolution-9ae4f2df52d0
看原文是非常慢的,看本文將為您節省一些時間。
先來看幾個公式:
卷積=擅長圖片
GANs=擅長生成一些數據
由此推出:卷積+GANs=擅長生成圖片
事后看來,正如Ian Goodfellow自己在與Lex Fridman的播客中指出的那樣,將這個模型稱為DCGAN(“深度卷積生成對抗網絡”的縮寫)似乎很愚蠢,因為現在幾乎所有與深度學習和圖像相關的內容都是深度的(deep)和卷積的(convolutional)。
此外,當大多數人了解到GANs時,都會先學習“深度學習和卷積”(deep and convolutional)。
然而,有一段時間GANs不一定會使用基于卷積的操作,而是依賴于標準的多層感知器架構。
DCGAN通過使用稱為轉置卷積運算(transposed convolution operation)來改變了這一現狀,它還有個不太好聽的名字——反卷積層( Deconvolution layer)。
轉置卷積是一種提升運算,它幫助我們將低分辨率圖像轉換為更高分辨率的圖像。
但是嚴格來說,如果您要掌握轉置卷積原理,只看上文介紹不夠,是需要深入研究鏈接里的資源,畢竟這是現代所有GAN架構的基礎。
如果你沒有足夠多的的時間來看,我們可以通過一個總結得很好的動畫來了解轉置卷積是如何工作:
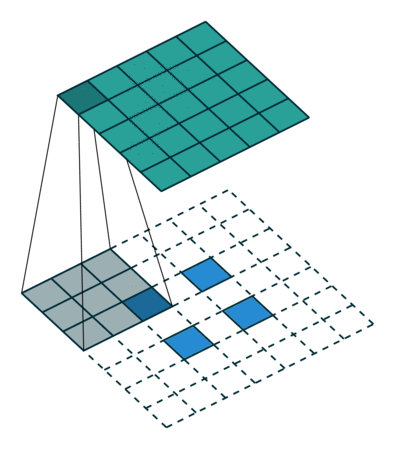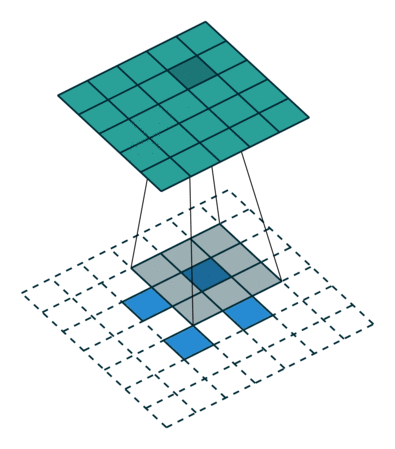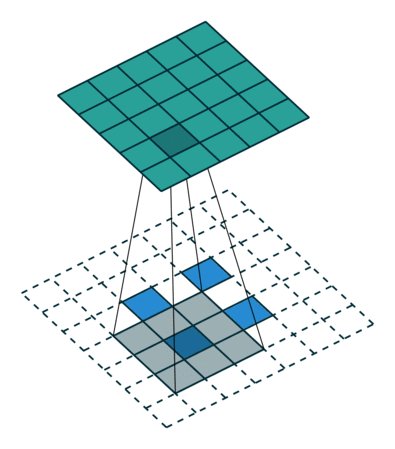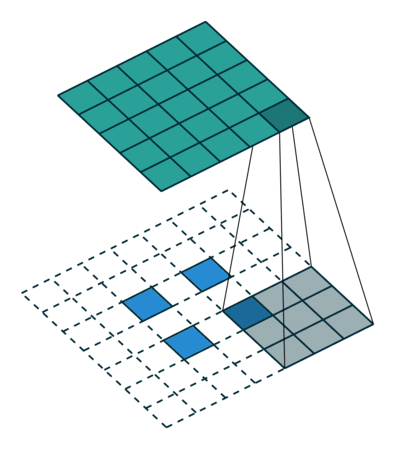
在一般的卷積神經網絡中,你會用一系列卷積(以及其他操作)將圖像映射到通常是較低維度的向量。
類似地,運用多個反卷積允許我們映射出單個低分辨率的陣列,并使之成為鮮明的全彩圖像。
在我們繼續之前,讓我們嘗試使用GAN的一些獨特方法。
你現在的位置:紅色的X
CGAN:Conditional Generative Adversarial Network
原始GAN根據隨機噪聲生成數據。這意味著你可以在此基礎上訓練它,比如狗的圖像,它會產生更多的狗的圖像。
您也可以在貓的圖像上訓練它,在這種情況下,它會生成貓的圖像。
您也可以在尼古拉斯·凱奇(Nicholas Cage)圖像上訓練它,在這種情況下,它會生成尼古拉斯·凱奇(Nicholas Cage)圖像。
你也可以在其他圖像上訓練它,以此類推。
但是,如果你試圖同時訓練狗和貓的圖像,它會產生模糊的半品種。
CGAN旨在通過只告訴生成器生成一個特定物種的圖像來解決這個問題,比如一只貓,一只狗或一個尼古拉斯·凱奇。
具體地來說,CGAN將單編碼向量yy連接到隨機噪聲向量zz,產生如下所示的體系結構:
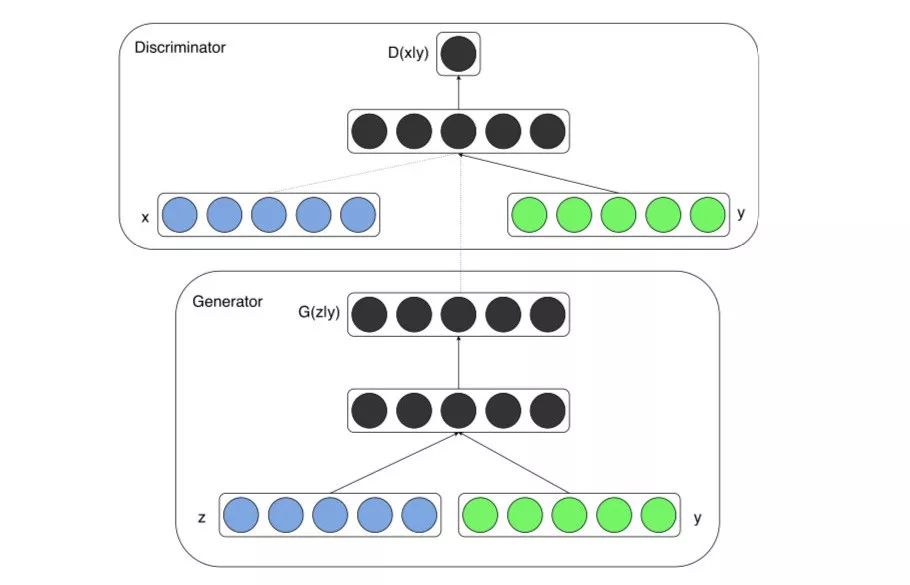
現在,我們可以用同一個GAN同時生成貓和狗。
CycleGAN
GANs并不僅僅用于生成圖像。他們還可以創建“馬+斑馬”這樣的新生物,如上圖所示。
為了創建這些圖像,CycleGAN旨在解決“圖像到圖像”轉換的問題。
CycleGAN并不是一個推動藝術圖像合成的新GAN架構,相反,它是使用了GAN的智能方式。因此,您可以自由地將此技術應用于您喜歡的任何架構。
此時,我會建議你閱讀一篇論文(https://arxiv.org/abs/1703.10593v6)。寫得非常好,即使是初學者也很容易理解。
CycleGAN的任務是訓練一個網絡G(X)G(X),該網絡會將圖像從源域XX映射到目標域YY。
但是,你可能會問:“這與常規的深度學習或樣式遷移有什么不同。”
嗯,下面的圖片很好地總結了這個問題。CycleGAN將不成對的圖像進行圖像平移。這意味著我們正在訓練的圖像不必代表相同的東西。

如果我們有大量的圖像對:(圖像,達芬奇的繪畫圖像)(圖像,達芬奇繪畫圖像),那么訓練達芬奇的繪畫圖像就會(相對)容易一些。
不幸的是,這個家伙并沒有太多的畫作。
然而,CycleGAN可以在未配對的數據上進行訓練,所以我們不需要兩個相同的圖像。
另一方面,我們可以使用樣式遷移。但這只會提取一個特定圖像的風格并將其轉移到另一個圖像,這意味著我們無法轉化一些假設性事物,如將馬轉化為斑馬。
然而,CycleGAN會學習從一個圖像域到另一個域的映射。所以我們就說一下所有的莫奈畫作訓練。

他們使用的方法非常優雅。CycleGAN由兩個生成器GG和FF,以及兩個判別器DXDX和DYDY組成。
GG從XX獲取圖像并嘗試將其映射到YY中的某個圖像。判別器 DYDY預測圖像是由GG生成還是實際在YY中生成。
類似地,FF從YY接收圖像并嘗試將其映射到XX中的某個圖像,而判別器DXDX 預測圖像是由FF生成還是實際上是在XX中。
所有的這四個神經網絡都是以通常的GAN方式進行訓練,直到我們留下了強大的生成器GG和FF,它們可以很好地執行圖像到圖像的轉換任務,乃至愚弄了DYDY 和DXDX。
這種類型的對抗性損失聽起來是個好主意,但這還不夠。為了進一步提高性能,CycleGAN使用另一個度量標準,循環一致性損失。
一般來說,優秀的轉換應該具備以下屬性,當你來回轉換時,你應該再次得到同樣的東西。
CycleGAN用巧妙的方式實現了這個想法,它迫使神經網絡遵守這些約束:
F(G(x))≈x,x∈XF(G(x))≈x,x∈X G(F(y))≈y,y∈YG(F(y))≈y,y∈Y
在視覺上看,循環一致性如下所示:
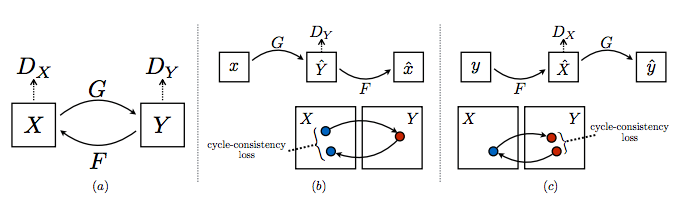
總損失函數是以懲罰網絡不符合上述特性的方式構造的。我不打算在這里寫出這個損失函數,因為這會破壞它在文章中匯總的方式。
好的,七龍珠還沒有召喚完,讓我們回到我們找尋更好的GAN架構的主要任務。
CoGAN:Coupled Generative Adversarial Networks
你知道比一個GAN更好的網絡是什么嗎?兩個GAN!
CoGAN(即“Coupled Generative Adversarial Networks”,不要與CGAN混淆,后者代表的是條件生成對抗網絡)就是這樣做的。它會訓練兩個GAN而不是一個單一的GAN。
當然,GAN研究人員不停止地將此與那些警察和偽造者的博弈理論進行類比。所以這就是CoGAN背后的想法,用作者自己的話說就是:
在游戲中,有兩個團隊,每個團隊有兩個成員。生成模型組成一個團隊,在兩個不同的域中合作共同合成一對圖像,用以混淆判別模型。判別模型試圖將從各個域中的訓練數據分布中繪制的圖像與從各個生成模型中繪制的圖像區分開。同一團隊中,參與者之間的協作是根據權重分配約束建立的。
這樣就有了一個GAN的多人局域網競賽,聽起來不錯,但你怎么能讓它真正起作用呢?
事實證明這并不復雜,只需使網絡對某些層使用完全相同的權重。
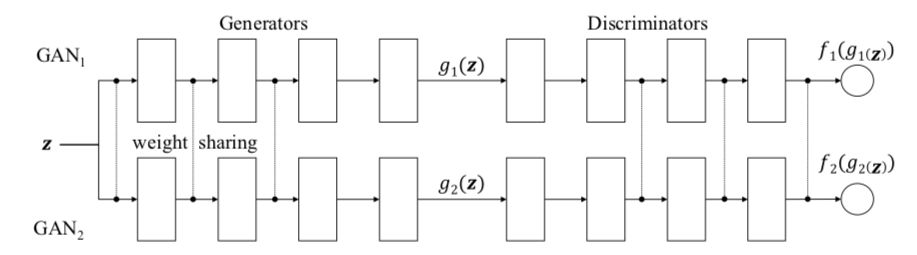
在我認為(可能不太謙虛),關于CoGAN最酷的事情不是提高圖像生成質量,也不是你可以在多個圖像域中進行訓練的事實。
而是,事實上,你獲得兩張圖片的價格僅是之前的四分之三。
由于我們共享一些權重,因此CoGAN將比兩個單獨的GAN具有更少的參數(因此將節省更多的內存,計算和存儲)。
這是一種微妙技術,但是有點過時,所以我們今天看到的一些新GAN并不會使用這種技術。
不過,我認為這一想法會在未來再次得到重視。
ProGAN:Progressive growing of Generative Adversarial Networks
訓練集GAN存在許多問題,其中最重要的是其不穩定性。
有時,GAN的損失會發生振蕩,因為生成器和判別器會消除對方的學習。也有時,錯誤會在網絡收斂后立即發生,這時圖像就會看起來很糟糕。
ProGAN是一種通過逐步提高生成圖像的分辨率來使其訓練集穩定的技術。
常識認為,生成4x4的圖像比生成1024x1024圖像更容易。此外,將16x16的圖像映射到32x32的圖像比將2x2圖像映射到32x32圖像更容易。
因此,ProGAN首先訓練4x4生成器和4x4判別器,并在訓練過程的后期添加相對應的更高分辨率的層。我們用一個動畫來總結一下:
WGAN:Wasserstein Generative Adversarial Networks
這篇文獻可能是此列表中最具理論性和數學性的論文。作者在文中用了一卡車的證據、推論以及另一種數學術語。因此,如果積分概率計量和Lipschitz連續與你無關,我們也不會在這個上花太多時間。
簡而言之,WGAN('W'代表Wasserstein)提出了一個新的成本函數,這些函數在純數學家和統計學家中風靡一時。
這是GAN minimax函數的舊版本:
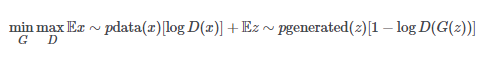
這是WGAN使用的新版本:
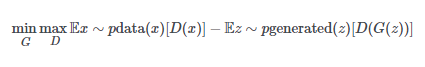
在大多數情況下,你需要知道WGAN函數是清除了舊的成本函數,該函數近似于稱為Jensen-Shannon散度的統計量,并在新的成本函數中滑動,使其近似于稱為1-Wasserstein距離的統計量。
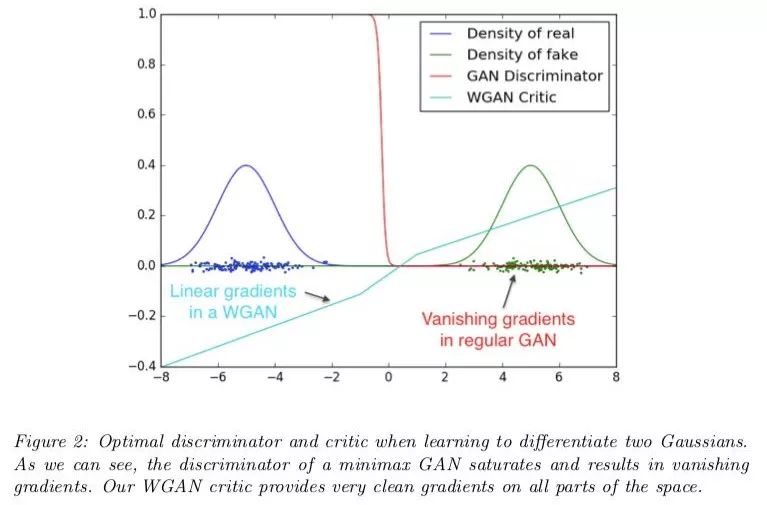
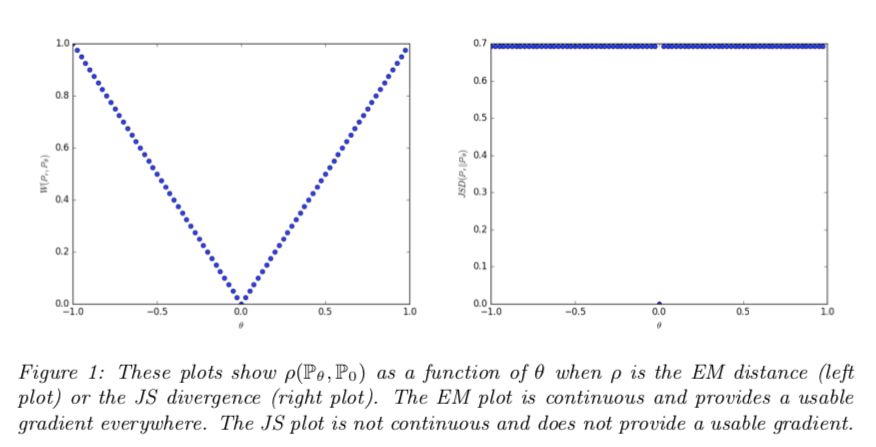
看了下圖您就知道為什么要這么做。
當然,如果您感興趣的話,接下來的是對數學細節的快速回顧,這也是WGAN論文備受好評的原因。
最初的GAN論文里認為,當判別器是最優的時,生成器以最小化Jensen-Shannon散度的方式更新。
如果你不太明白的話,Jensen-Shannon散度是一種衡量不同兩種概率分布的方法。JSD越大,兩個分布越“不同”,反之亦然。計算公式如下:
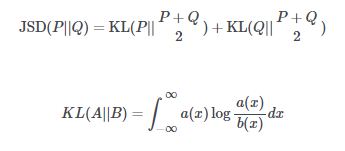
然而,把JSD最小化是最好的選擇嗎?
WGAN論文的作者認為可能不是。出于特殊原因,當兩個發行版完全不重疊時,可以顯示JSD的值保持為2log22log?2的常量值。
具有常量值的函數有一個梯度等于零,而零梯度是不好的,因為這意味著生成器完全沒有學習。
WGAN作者提出的備用距離度量是1-Wasserstein距離,也稱為搬土距離(EMD距離)。
“搬土距離”來源于類比,想象一下,兩個分布中的一個是一堆土,另一個是一個坑。
假設盡可能有效地運輸淤泥,沙子,松土等物品,搬土距離測量將土堆運輸到坑中的成本。這里,“成本”被認為是點之間的距離×土堆移動的距離×移動的土堆量。
也就是說(沒有雙關語),兩個分布之間的EMD距離可以寫成:
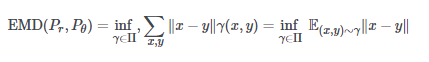
當inf是最小值時,xx和yy是兩個分布上的點,γγ是最佳運輸計劃。
可是,計算這個是很難的。于是,我們計算完全不同的另一個值:
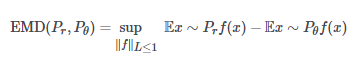
這兩個方程式之間的聯系一開始似乎并不明顯,但通過一些稱為Kantorovich-Rubenstein二重性的復雜數學(試著快讀三次),可以證明這些Wasserstein / Earth mover距離的公式在試計算同樣的東西。
如果你跟不上我提供的鏈接中的的論文和博客文章中的一些重要的數學概念,也不要過于擔心。關于WGAN的大部分工作都是為一個簡單的想法提供一個復雜的理由。
SAGAN:Self-Attention Generative Adversarial Networks
由于GAN使用轉置卷積來“掃描”特征映射,因此它們只能訪問附近的信息。
單獨使用轉置卷積就像繪制圖片,只在畫筆的小半徑范圍內查看畫布區域。
即使是能完善最獨特和復雜細節的最偉大的藝術家,在創作過程中也需要退后一步,看看大局。
SAGAN(全稱為“自我關注生成對抗網絡”)使用自我關注機制,由于遷移模型架構,近年來這種方式已經變得十分流行。
自我關注讓生成器退后一步,查看“大局”。
BigGAN:Big Generative Adversarial Networks
經過四年漫長的歲月,DeepMind前所未有地決定與GAN合作,他們使用了一種深度學習的神秘技術,這種技術非常強大,是最先進的技術,超越了先進技術排行榜上所有其他的技術。
接下來展示BigGAN,GAN絕對沒有做什么(但是運行了一堆TPU集群,卻不知何故應該在這個列表中)。
開個玩笑!DeepMind團隊確實在BigGAN上取得了很多成就。除了用逼真的圖像吸睛之外,BigGAN還向我們展示了一些非常詳細的訓練GAN的大規模結果。
BigGAN背后的團隊引入了各種技術來對抗在許多機器上大批量培訓GAN的不穩定性。
首先,DeepMind使用SAGAN作為基線,并添加了一個稱為譜歸一化的功能。
接下來,他們將圖片批量大小縮放50%,寬度(通道數)縮放20%。最初,增加層數似乎并沒有幫助。
在進行了一些其他單位數百分比改進之后,作者使用“截斷技巧”來提高采樣圖像的質量。
BigGAN在訓練期間從z N(0,I)提取其潛在向量,如果潛在向量在生成圖像時落在給定范圍之外,則重新采樣。
范圍是超參數,由ψψ表示。較小的ψψ會縮小范圍,從而以多樣化為代價提高樣本保真度。
那么所有這些錯綜復雜的調整工作會有什么后顧呢?好吧,有人稱之為狗球。
BigGAN技術還發現更大規模的GAN訓練可能會有一系列問題。
值得注意的是,訓練集似乎可以通過增加批量大小和寬度等參數來很好地擴展,但不知什么原因,最終總會崩潰。
如果你對通過分析奇異值來理解這種不穩定性感興趣的話,請查看論文,因為你會在那里找到很多東西。
最后,作者還在一個名為JFT-300的新數據集上訓練BigGAN,這是一個類似ImageNet的數據集,它有3億個圖像。他們表明BigGAN在這個數據集上的表現更好,這表明更大規模的數據集可能是GAN的發展方向。
在論文的第一版發布后,作者在幾個月后重新訪問了BigGAN。還記得我怎么說增加層數不起作用?事實證明,這是由于糟糕的訓練集選擇導致的。
該團隊不再只是在模型上填充更多層,還進行了實驗,發現使用ResNet突破瓶頸是可行的。
通過以上不斷地調整、縮放和仔細實驗,BigGAN的頂級線條完全抹殺了先前的最新狀態,得分高達52.52分,總分是152.8。
如果這不是正確步驟的話,那我不知道哪個是正確的。
StyleGAN:Style-based Generative Adversarial Networks
StyleGAN是Nvidia的一個延伸研究,它主要與傳統的GAN研究關系不大,傳統GAN主要關注損失函數,穩定性,體系結構等。
如果你想生成汽車的圖像的話,僅僅擁有一個可以欺騙地球上大多數人的世界級人臉生成器是沒有用的。
因此,StyleGAN不是專注于創建更逼真的圖像,而通過提高GAN的能力,可以對生成的圖像進行精細控制。
正如我所提到的那樣,StyleGAN沒有開發架構和計算損失函數功能。相反,它是一套可以與任何GAN聯用的技術,允許您執行各種很酷的操作,例如混合圖像,在多個級別上改變細節,以及執行更高級的樣式傳輸。
換句話說,StyleGAN就像一個photoshop插件,只是大多數GAN開發都是photoshop的新版本。
為了實現這種級別的圖像風格控制,StyleGAN采用了現有的一些技術,如自適應實例規范化,潛在矢量映射網絡和常量學習輸入。
如果沒有深入細節,是很難再描述StyleGAN的,所以如果你有興趣的話,請查看我的文章,其中展示了如何使用StyleGAN生成權力游戲角色。我對所有技術都有詳細的解釋,一路上有很多很酷的結果等你哦。
結論
恭喜你,堅持看到了最后!你們都跟上了創造虛假個人照片的高度學術領域的最新進展。
但是在你癱在沙發上并開始無休止地刷微博票圈之前,請稍微停一下看看你到底還有多少路要走:
接下來是什么?!未被開發的區域!
在掌握了ProGAN和StyleGAN,且規模到達BigGAN之后,你很容易迷失在這里邊。
但請放大地圖仔細觀察,看到那個綠色土地了嗎?看到北方的紅三角了嗎?
這些都是等待被突破的未知開發區域,如果你放膽一試,他們都可以成為你的。
-
GaN
+關注
關注
19文章
1933瀏覽量
73299 -
DeepFake
+關注
關注
0文章
15瀏覽量
6677
原文標題:能生成Deepfake也能診斷癌癥,GAN與惡的距離
文章出處:【微信號:BigDataDigest,微信公眾號:大數據文摘】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
LG AI Research使用亞馬遜云科技開發AI模型 加快癌癥診斷速度




請問LM311能準確的交截生成對應的PWM波形嗎?
EM儲能網關 ZWS智慧儲能云應用(3) — 收益接入介紹






 工商網監
工商網監
評論