") “現(xiàn)代版羅塞塔石碑”,MIT&谷歌大腦用AI破解失傳的古代文字
“現(xiàn)代版羅塞塔石碑”,MIT&谷歌大腦用AI破解失傳的古代文字
漫漫塵埃下,掩藏了許多曾經(jīng)輝煌燦爛古代文明,但我們現(xiàn)在卻無(wú)法清晰地知道,這些地方究竟發(fā)生了什么。
搞懂這些歷史的最佳方式,就是找到他們的文字記載。However,記載文字的石碑可以被考古學(xué)家們挖出來(lái),但這些古文字究竟啥意思,現(xiàn)代的人們看不懂,需要語(yǔ)言學(xué)家們耗盡青春來(lái)推測(cè)。
現(xiàn)在,MIT CSAIL和谷歌大腦的研究者出手了,他們用機(jī)器學(xué)習(xí)破譯了烏加里特文和線(xiàn)性文字B。
△ 烏加里特王宮
烏加里特文,Ugaritic,是一種楔形文字,屬于閃米特語(yǔ)族。從字面上來(lái)看,就知道它是一個(gè)叫做烏加里特(Ugarit)的文明使用的語(yǔ)言,這個(gè)文明位于當(dāng)今地中海沿岸的敘利亞,在公元前6000年前后就初現(xiàn)蹤跡,在公元前1190年前后滅亡。
△ 烏加里特文
線(xiàn)性文字B,Linear B,由一種人類(lèi)還沒(méi)有破譯出來(lái)的線(xiàn)性文字A演化而來(lái),主要存活于公元前1500年到公元前1200年的克里特島和希臘南部,是希臘語(yǔ)的一種古代書(shū)寫(xiě)形式。
△ 線(xiàn)性文字B
研究者們利用同一語(yǔ)族內(nèi)不同語(yǔ)言之間的聯(lián)系,用機(jī)器學(xué)習(xí)的方法來(lái)破譯這兩種失傳的語(yǔ)言,這是破譯古代語(yǔ)言的新方法,也將對(duì)羅曼語(yǔ)族的語(yǔ)言學(xué)研究有巨大的影響和提升。
這個(gè)方法讓許多人驚嘆:
簡(jiǎn)直是現(xiàn)代版的羅塞塔石碑!
PS,羅塞塔石碑是一塊用3種語(yǔ)言寫(xiě)了同一個(gè)內(nèi)容的石碑,幫助語(yǔ)言學(xué)家們讀懂古文字。
希望能先把動(dòng)物和植物的語(yǔ)言破譯了,可以發(fā)現(xiàn)打開(kāi)新世界的大門(mén)。
人類(lèi)語(yǔ)言總相通
這項(xiàng)研究的核心方法,是借助人類(lèi)語(yǔ)言的相似性。
比如,知乎用戶(hù)@拉隊(duì)短 在介紹歐洲語(yǔ)言相似性的時(shí)候,舉了這么個(gè)栗子:
句子“那是六月末潮濕陰沉的一個(gè)夏日。”
英語(yǔ):It was a humid, grey summer day at the end of June.
丹麥語(yǔ):Det var en fugtig, gr? sommerdag i slutningen af juni.
瑞典語(yǔ):Det var en fuktig, gr? sommardag i slutet av juni.
挪威語(yǔ):Det var en fuktig, gr? sommerdag i slutten av juni.
冰島語(yǔ):Tae var rakur, grár sumardagur í lok júní.
看,長(zhǎng)得差不多嘛,畢竟同屬印歐語(yǔ)系日耳曼語(yǔ)族,單詞的分布位置、句子的結(jié)構(gòu)都很相似,如果你能看懂一種語(yǔ)言,就能大致猜測(cè)和它“血緣”關(guān)系近的另一種語(yǔ)言。
模型訓(xùn)練
為了破解這兩種文字,研究者們提出了一個(gè)基于字符的seq2seq模型。
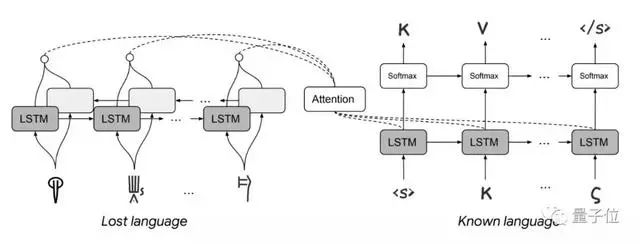
模型主要包含通用字符嵌入、剩余連接、單調(diào)排列正則化幾個(gè)部分。
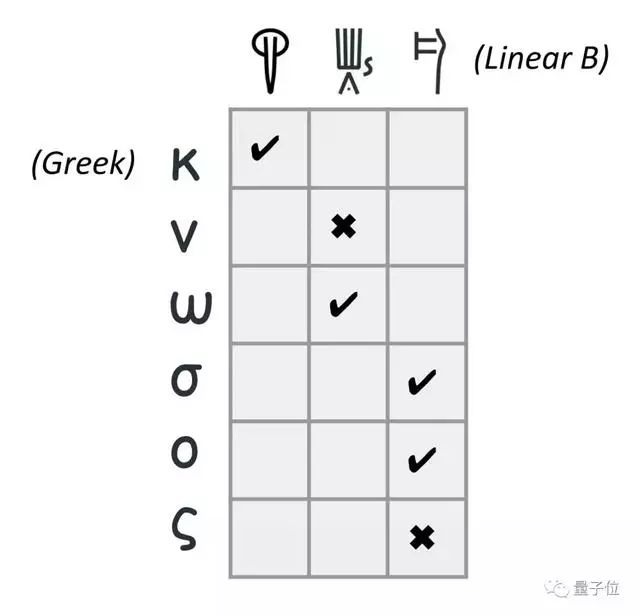
其中,線(xiàn)性文字B的字母和希臘文需要進(jìn)行對(duì)應(yīng)。
之后,借助神經(jīng)解密算法,在具有不同語(yǔ)言特征的多種語(yǔ)言中提供強(qiáng)大的性能。

你懂的語(yǔ)言,和你不懂的語(yǔ)言
在算法模型的基礎(chǔ)之下,需要的語(yǔ)料庫(kù)除了待破解的烏加里特文和線(xiàn)性文字B,還需要一些現(xiàn)在的人類(lèi)能看懂的語(yǔ)言。
研究團(tuán)隊(duì)選擇了羅曼語(yǔ)族的數(shù)據(jù)庫(kù),包含意大利語(yǔ)、西班牙語(yǔ)和葡萄牙語(yǔ)三種語(yǔ)言的同源語(yǔ)音轉(zhuǎn)錄,需要對(duì)它們進(jìn)行同源檢測(cè)。
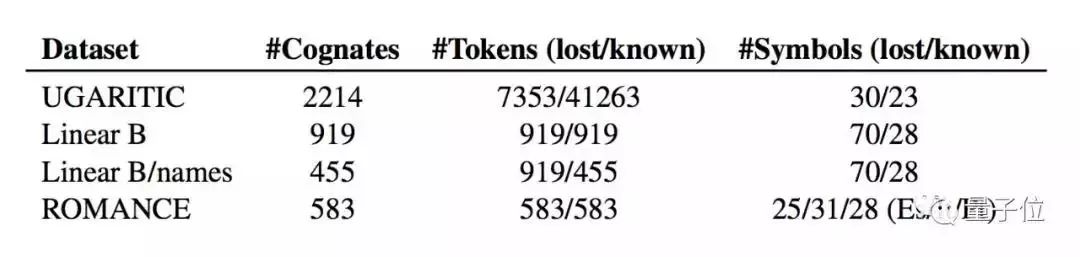
因此,數(shù)據(jù)集就用到上面這些,Symbols指的是語(yǔ)言中的字符,Token則是語(yǔ)言學(xué)中類(lèi)似于單詞的存在。
準(zhǔn)確率
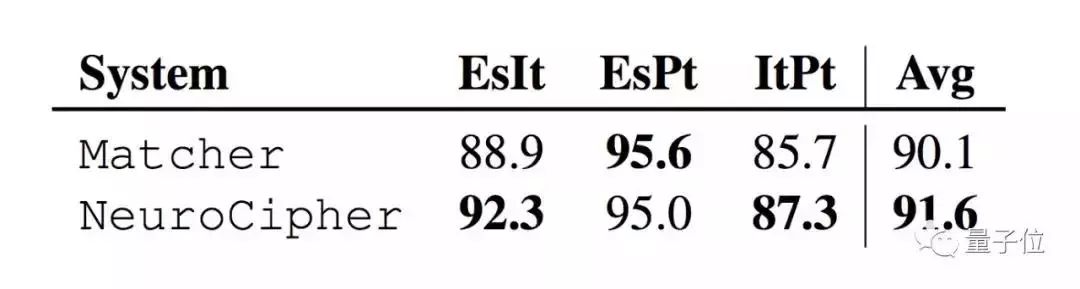
運(yùn)行成果還不錯(cuò),烏加里特文在無(wú)噪聲條件下優(yōu)于現(xiàn)有方法3.1%,在有噪聲條件下優(yōu)于現(xiàn)在的貝葉斯方法5.5%。

而線(xiàn)性文字B,在無(wú)噪聲條件下準(zhǔn)確率高達(dá)84.7%,在更具挑戰(zhàn)性的LinearB名稱(chēng)數(shù)據(jù)集中達(dá)到67.3%的準(zhǔn)確度。

在羅曼語(yǔ)族同源識(shí)別任務(wù)中,西班牙語(yǔ)準(zhǔn)確度提升3.4%,葡萄牙語(yǔ)提升1.6%。
線(xiàn)性文字B的祖先,線(xiàn)性文字A還沒(méi)有被人類(lèi)破譯,它被譽(yù)為考古界圣杯。
未來(lái),在這項(xiàng)研究起作用的情況下,或許可以像借助羅曼語(yǔ)族三種語(yǔ)言的數(shù)據(jù)庫(kù)一樣,直接用機(jī)器借助其他已知的人類(lèi)語(yǔ)言,實(shí)現(xiàn)暴力破解。
想破腦殼的語(yǔ)言學(xué)家們,可以把工作重心放到別的事情上了。
-
谷歌
+關(guān)注
關(guān)注
27文章
6172瀏覽量
105513 -
MIT
+關(guān)注
關(guān)注
3文章
253瀏覽量
23413
原文標(biāo)題:MIT&谷歌大腦用AI破解失傳的古代文字,被稱(chēng)“現(xiàn)代版羅塞塔石碑”丨ACL 2019
文章出處:【微信號(hào):worldofai,微信公眾號(hào):worldofai】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
《算力芯片 高性能 CPUGPUNPU 微架構(gòu)分析》第3篇閱讀心得:GPU革命:從圖形引擎到AI加速器的蛻變
機(jī)場(chǎng)運(yùn)營(yíng)商Fraport與羅德與施瓦茨簽訂合作協(xié)議
喆塔科技先進(jìn)制程AI賦能中心&校企聯(lián)合實(shí)驗(yàn)室落戶(hù)蘇州

喆塔智芯簽約儀式暨喆塔科技半導(dǎo)體AI創(chuàng)新總部啟動(dòng)儀式圓滿(mǎn)舉辦

pcb板樹(shù)脂塞孔和油墨塞孔的區(qū)別?
Character.AI創(chuàng)始人加入谷歌,被買(mǎi)斷的股票估值25億美元
羅德與施瓦茨加入AI-RAN聯(lián)盟,共同推進(jìn)無(wú)線(xiàn)通信創(chuàng)新發(fā)展
智譜AI推出“AI老羅”,全模型矩陣降價(jià)
谷歌發(fā)布多模態(tài)AI新品,加劇AI巨頭競(jìng)爭(zhēng)
印度塔塔電子開(kāi)始出口封裝芯片
谷歌整合安卓系統(tǒng)與Pixel硬件團(tuán)隊(duì),奧斯特羅引領(lǐng)新&quot;Platfo&quot;
谷歌模型合成工具怎么用
谷歌AI大模型Gemma全球開(kāi)放使用
【國(guó)產(chǎn)FPGA+OMAPL138開(kāi)發(fā)板體驗(yàn)】(原創(chuàng))5.FPGA的AI加速源代碼
塔塔集團(tuán)宣布在印度古吉拉特邦投資建設(shè)半導(dǎo)體晶圓廠(chǎng)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論