 使用機器學習預測公交車延誤
使用機器學習預測公交車延誤
全球數億人的日常通勤都依靠公共交通工具,其中超過半數在出行時會選擇乘坐公交車。隨著全球城市的不斷發展,通勤一族希望了解公共交通工具尤其是公交車可能出現的延誤時間,以便提前安排出行計劃。因為公交車往往會遇到交通擁堵。Google 地圖的公交路線實時數據由眾多公共交通運營機構提供,但因技術和資源限制,仍有許多公共交通運營機構無法提供這些信息。
近日,Google 地圖為全球數百個城市(包括亞特蘭大、薩格勒布、伊斯坦布爾、馬尼拉等),推出了基于機器學習的實時公交延誤預測服務。如此一來,六千多萬人便能更準確地把握出行時間。這套系統于三周前率先在印度發布,系統采用機器學習模型,整合了實時汽車交通預測與公交路線和站臺數據,以便更準確地預測公交出行的時間。
模型初探
許多城市的公共交通運營機構并不提供實時預測數據,在對這類城市的用戶進行調查后,我們發現,他們借助一種巧妙方法來粗略估計公交車的延誤時間:使用 Google 地圖的駕駛路線功能。然而,公交車并非只是大型汽車。公交車在站臺停靠,加速、減速和轉彎都需要更長時間,有時甚至擁有專屬道路特權(如公交專用車道)。
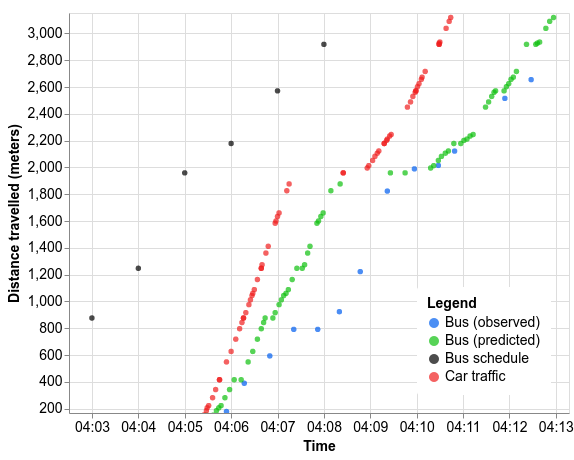
舉個例子,我們于周三下午在悉尼測試了一次公交車之旅。相較于公交時刻表(黑點),公交車的實際行駛時間(藍點)會晚幾分鐘。汽車行駛速度(紅點)確實會對公交車造成影響,例如行駛至 2000 米處的減速情形。但與汽車相比,公交車在 800 米標記處的長時間停靠也會大大減慢自身的速度。
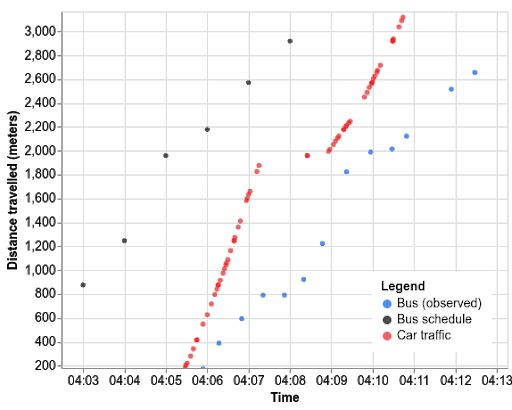
為了開發模型,我們從公共交通運營機構的實時反饋中獲得了公交車位置序列,從中提取訓練數據,并將其與汽車在公交行駛路線上的行駛速度進行調整。我們將該模型劃分為時間線單元(表示在街區和站臺停靠),每個單元對應一段公交車的時間線,并預測持續時間。由于報告頻率低、再加上公交車行駛速度較快、街區和站臺停靠時間較短,相鄰的觀測數據可能會跨越多個單元。
此結構非常適合于神經序列模型,如近期在語音處理和機器翻譯等領域成功實現應用的模型。而我們的模型更加簡單。每個單元會獨立預測其持續時間,最終的輸出結果為每單元預測時間的總和。
與許多序列模型不同,我們的模型并不需要學習組合單元輸出,也無需通過單元序列傳遞狀態。相反,序列結構讓我們能夠共同:(1) 訓練一個單元持續時間的模型,(2) 優化“線性系統”,其中每條觀測到的軌跡會將總持續時間分配給其跨越的所有單元。
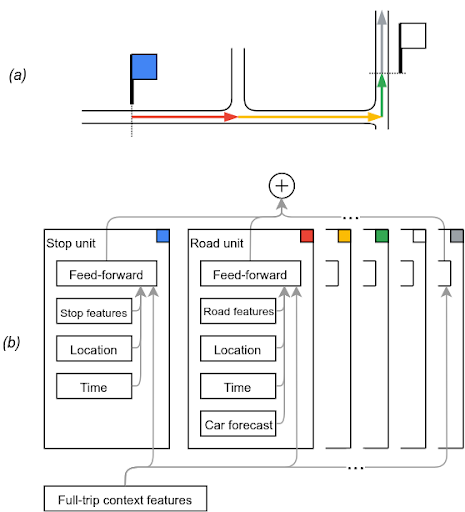
為模擬從藍色站臺開始的公交車行程 (a),模型 (b) 將藍色站臺、三個路段和白色站臺等各處的時間線單元延誤預測進行相加
構建“地點”模型
除了因交通擁堵導致的延誤之外,我們在訓練模型時還詳細考慮了公交車路線,以及行程中各地點與時段的交通信號燈。
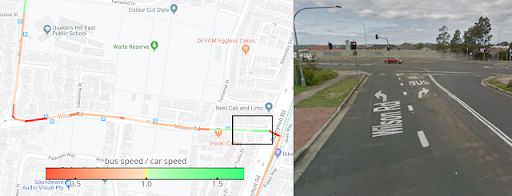
即便是在小區內,該模型也需根據各個街道的路況,以不同方式將汽車速度預測轉化為公交車速度。如下方左圖所示,模型預測了公交車行程中汽車與公交車速度之比,我們用不同顏色對其進行標記。
紅色(表示車速較慢)的部分符合公交車在站臺附近減速的實況。針對突出顯示的綠色路段(表示車速較快),我們查看了相關街景,了解到該模型發現了一條公交車專用的轉彎車道。順便一提,這條路線位于澳大利亞,該國右轉車速低于左轉車速,而這也是不考慮地點特殊性的模型會忽略的另一方面。
為獲取特定街道、街區和城市的獨特屬性,我們讓該模型學習不同大小區域的表示層次結構,通過地區位置的總嵌入,在模型中按不同比例表示時間線單元的地理位置(即道路或站臺的精確定位)。
我們首先訓練模型,對特殊情況下的細粒度位置進行逐漸加重的處罰,并使用結果進行特征選擇。這樣就可以確保考慮到百米影響公交行為的復雜區域中的細粒度特征,而不像開放的鄉村那樣細致的特征很少。
訓練期間,我們還模擬了訓練數據以外地區可能的后續查詢。在每個訓練批次中,我們會隨機抽取一些示例,隨機選取某一比例并丟棄地理特征。某些示例擁有準確的公交路線和街道信息,某些僅包含街區或城市位置,還有一些則沒有任何地理環境信息。如此一來,模型便能做好充足準備,從而在后續查詢訓練數據不足的地區。我們通過匿名用戶的公交行程,并使用與 Google 地圖在商業繁忙、停車難度及其他特征的相同數據集,來擴展我們的培訓語料庫覆蓋范圍。然而,即使是這類數據也無法涵蓋全球大部分公交路線,因此我們必須大幅提升模型的泛化能力,使其適應更多新地區。
學習地方性節奏
不同城市和街區的運轉節奏各有差異,因此我們讓模型將其位置表示與時間信號進行結合。
公交車對時間的依賴包含不同情形:周二下午 6:30 至 6:45,一些街區的下班高峰可能已逐漸淡去,另一些街區可能在忙于用餐,而冷清的小鎮可能已是萬籟俱寂。我們的模型學習嵌入了局部地區的當日時間與星期信號,當此類信號與地點表示相結合時,模型便可獲取顯著的局部地區變化(如上下班高峰期在公交站臺等候的人群),而我們無法通過交通情況觀測這類變化。
這種嵌入會向一天的時間分配四維向量。與大多數神經網絡內部架構不同,四維空間幾乎無法實現可視化。因此,讓我們以如下所示的藝術渲染圖為例,向您展示此模型如何在其中的三個維度內安排一天的時間。此模型確實知道時間具有周期性,因而會將其放在“循環”內。但此循環并非只是時鐘表面的平面圓環。
此模型學習了大量彎曲 (wide bends),讓其他神經元組成簡單的規則,以輕松區分“午夜”或“傍午”等概念。而在此類概念中,公交車的行駛狀態不會產生太大變化。另一方面,不同街區和城市的夜間通勤模式差異甚大。針對下午 4 點至晚上 9 點之間的時段,模型似乎創建了更復雜的“折皺”模式,從而能對每個城市的高峰時間進行更復雜的推理。
效果圖作者:Will Cassella,所用貼圖來源:textures.com,所用 HERI 來源:hdrihaven。模型的時間表示(四維空間中的三個維度)形成循環,在此處您可以將其重新想象成手表的表盤。越依賴位置的時間窗口(如下午 4 點至 9 點,上午 7 點至 9 點)會獲得更復雜的“折皺”,而沒有特征的大窗口(如凌晨 2 點至 5點)則會發生平面彎曲,進而生成更簡單的規則。
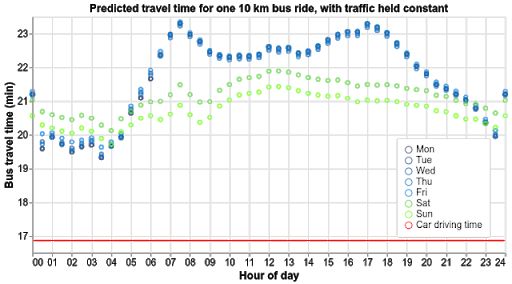
借助此時間表示與其他信號,我們可在車速恒定的情況下預測復雜模式。例如,在乘坐公交車完成新澤西州的 10 公里行程時,我們的模型能夠了解午餐時間的人群狀況以及工作日的高峰時段:
全面整合
在對模型進行充分訓練后,讓我們看看它對上例中悉尼公交車之旅的了解程度。
如果基于當日的車輛交通數據運行模型,我們會得到如下所示的綠色預測點(該模型無法獲取所有信息,例如,模型檢測到公交車在 800 米僅停靠了 10 秒,而實際的停靠時間為 31 秒多)。與公交時刻表和汽車行駛時間相比,我們的預測與公交車實際運行時間的差異相對較小,為 1.5 分鐘。
未來行程
目前,我們的模型尚缺一類數據,即公交時刻表。截止目前,經試驗證明,官方機構提供的公交車時刻表尚無法對我們的預測做出顯著改進。在某些城市,變化無常的交通狀況可能會打亂出行計劃。而在其他城市,公交車時刻表則非常精準,這或許是因為當地公共交通運營機構仔細考慮了本地的交通狀況。而我們可以從數據中推斷出這些。
我們將繼續進行實驗,更好地考慮行程限制和其他影響因素,從而推動更精確的預測,為用戶的出行計劃提供便利。此外,我們希望能為您的出行計劃提供幫助。祝您旅途愉快!
-
Google
+關注
關注
5文章
1766瀏覽量
57614 -
機器學習
+關注
關注
66文章
8424瀏覽量
132765
原文標題:使用機器學習預測公交車延誤
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
中車鯨典客車批量交付1032輛
億緯鋰能與遠程新能源商用車合作共塑杭州綠色公交新風貌
城市公交充電站設計策略與綜合解決方案探討

【《時間序列與機器學習》閱讀體驗】+ 時間序列的信息提取
【「時間序列與機器學習」閱讀體驗】+ 簡單建議
【《時間序列與機器學習》閱讀體驗】+ 了解時間序列
公交車安全與監控:車載監控的應用與發展
機器學習的經典算法與應用

名單公布!【書籍評測活動NO.35】如何用「時間序列與機器學習」解鎖未來?
淺談電動公交充電站預制艙式儲能系統設計方案研究
國內首批!行業唯一!蘇州金龍超充純電公交車正式投運張家港
歐洲議會批準“歐7”汽車監管標準,強制純電、混合動力汽車采用電動技術
公交站配電箱安裝安全用電監測終端,實時監測公交車站配電系統漏電電流
公交站安全用電云平臺-實時監測公交車站配電系統漏電電流及水浸狀態Acrelsale1
公交站安全用電云平臺





 工商網監
工商網監
評論