") 介紹來自不同領域中有代表性的8篇論文
介紹來自不同領域中有代表性的8篇論文
編者按:ACL 2019將于7月28日至8月2日在意大利佛羅倫薩舉行。在本屆大會的錄取論文中,共有25篇來自微軟亞洲研究院和微軟(亞洲)互聯(lián)網(wǎng)工程院。內(nèi)容涵蓋文本摘要、機器閱讀理解、推薦系統(tǒng)、視頻理解、語義解析、機器翻譯、人機對話等多個熱門領域。本文將為大家介紹來自不同領域中有代表性的8篇論文。
抽取式文本摘要
近兩年,自然語言中的預訓練模型如ELMo、GPT和BERT給自然語言處理帶來了巨大的進步,成為研究熱點中的熱點。這些模型首先需要在大量未標注的文本上訓練一個從左到右(left-to-right language model)或從右到左(right-to-left languagemodel)或完形填空式(masked language model)的語言模型。以上過程稱為預訓練(pre-training)。預訓練完的模型便具有了表示一個句子或一個詞序列的能力,再針對不同的下游任務進行微調(diào)(finetuning),然后可以在下游任務上取得不錯的效果。
但是上述預訓練模型無論是對句子還是文章進行建模時都把它們看成一個詞的序列。而文章是有層級結(jié)構(gòu)的,即文章是句子的序列,句子是詞的序列。微軟亞洲研究院針對文章的層級結(jié)構(gòu)提出文章表示模型HIBERT(HIerachical Bidirectional Encoder Representations from Transformers),HIBERT模型在抽取式文本摘要任務中取得了很好的效果。
代表論文:HIBERT: Document Level Pre-training of Hierarchical Bidirectional Transformers for Document Summarization
論文鏈接:https://arxiv.org/abs/1905.06566
如圖1所示,HIBERT的編碼器是一個Hierachical Transformer(句子級別的Transformer和文章級別的Transformer)。句子級別的Transformer通過句內(nèi)信息學習句子表示,而文章級別的Transformer通過句間信息學習帶上下句背景的句子表示。
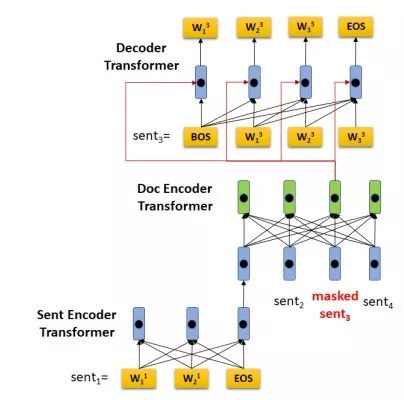
圖1:HIBERT模型架構(gòu)
與BERT類似,HIBERT需要先進行無監(jiān)督的預訓練(pre-training),然后在下游任務上進行有監(jiān)督的微調(diào)(finetuning)。HIBERT預訓練的任務是掩蓋(MASK)文章中的幾句話,然后再預測這幾句話。如圖1所示,文章的第三句話被MASK掉了,我們用一個Decoder Transformer去預測這句話。
在大量未標注數(shù)據(jù)上進行預訓練后,我們把HIBERT用在抽取式摘要中。抽取式摘要的任務定義如下:給定一篇文章,摘要模型判斷文章中的每個句子是否為這篇文章的摘要。得分最高的K個句子將被選為文章摘要(K一般在dev數(shù)據(jù)上調(diào)試得到)。基于HIBERT的摘要模型架構(gòu)如圖2所示,編碼器仍然是一個Hierachical Transformer,一篇文章的句子被HIBERT讀入后,對通過HIBERT學習到的帶上下句背景的句子表示進行分類。
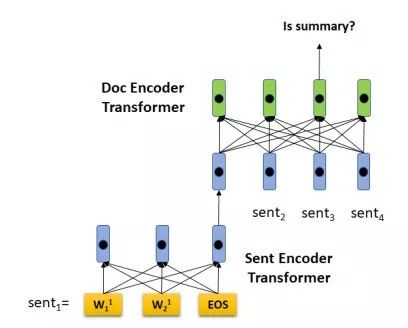
圖2:基于HIBERT的摘要模型架構(gòu)
HIBERT在兩個著名的摘要數(shù)據(jù)集CNN/DailyMail和New York Times上結(jié)果都表現(xiàn)很好,超越了BERT及其它在2018年和2019年初提出的所有摘要模型。
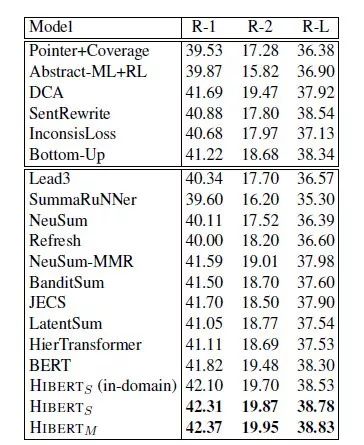
表1:摘要數(shù)據(jù)集CNN/DailyMail上不同模型的實驗結(jié)果
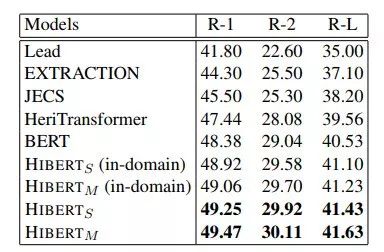
表2:摘要數(shù)據(jù)集New York Times上不同模型的實驗結(jié)果
機器閱讀理解
機器閱讀理解在近兩年取得了巨大的進步,當答案為文檔中的一個連續(xù)片段時,系統(tǒng)已經(jīng)可以十分準確地從文檔中抽取答案。有許多工作從模型結(jié)構(gòu)的角度來提高閱讀理解系統(tǒng)的表現(xiàn),借助大規(guī)模標注數(shù)據(jù)訓練復雜模型,并不斷刷新評測結(jié)果;同時也有工作通過增強訓練數(shù)據(jù)來幫助系統(tǒng)取得更好的結(jié)果,如借助其它數(shù)據(jù)集聯(lián)合訓練、通過回譯(back translation)豐富原文等。
然而在現(xiàn)實生活中,往往無法保證給定的文檔一定包含某個問題的答案,這時閱讀理解系統(tǒng)應拒絕回答,而不是強行輸出文檔中的一個片段。針對這一問題,同樣有很多工作從模型角度切入,以提高系統(tǒng)判斷問題是否可以被回答的能力,做法可大致分為在抽取答案的同時預測問題可答性和先抽取答案再驗證兩類。而微軟亞洲研究院的研究員從數(shù)據(jù)增廣的角度來嘗試解決這一問題。
代表論文:Learning to Ask Unanswerable Questions for Machine Reading Comprehension
論文鏈接:https://arxiv.org/abs/1906.06045
該論文提出根據(jù)可答問題、原文和答案來自動生成相關(guān)的不可答問題,進而作為一種數(shù)據(jù)增強的方法來提升閱讀理解系統(tǒng)的表現(xiàn)。我們利用現(xiàn)有閱讀理解數(shù)據(jù)集SQuAD 2.0來構(gòu)造不可答問題生成模型的訓練數(shù)據(jù),引入Pair2Seq作為問題生成模型來更好地利用輸入的可答問題和原文。

圖3:SQuAD 2.0數(shù)據(jù)集中的問題樣例
SQuAD 2.0數(shù)據(jù)集包含5萬多個不可答問題,并且為不可答問題標注了一個看起來正確的答案(plausible answer)。圖3展示了SQuAD 2.0中一個文檔和相應的可答與不可答問題,可以看到這兩個問題的(plausible)答案對應到同一個片段,用詞十分相似且答案具有的類型(organization),通過對可答問題進行修改就能得到相應的不可答問題。根據(jù)這一觀察,我們以被標注的文本片段為支點來構(gòu)造訓練問題生成模型所需的數(shù)據(jù)。
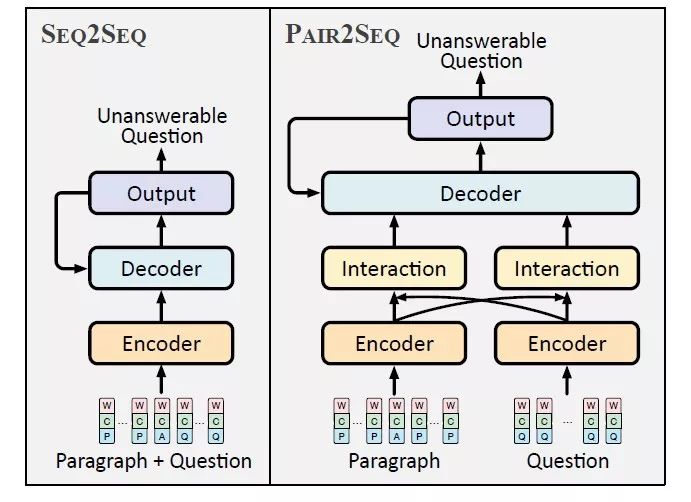
圖4:Pair2Seq模型與Seq2Seq模型的流程圖對比
在閱讀理解系統(tǒng)中,問題與文檔的交互是最為關(guān)鍵的組成部分,受此啟發(fā),該論文提出Pair2Seq模型,在編碼(encoding)階段通過注意力機制(attention mechanism)得到問題和文檔的加強表示,共同用于解碼(decoding)。如表3所示,Pair2Seq模型在多個評價指標上超過Seq2Seq模型。
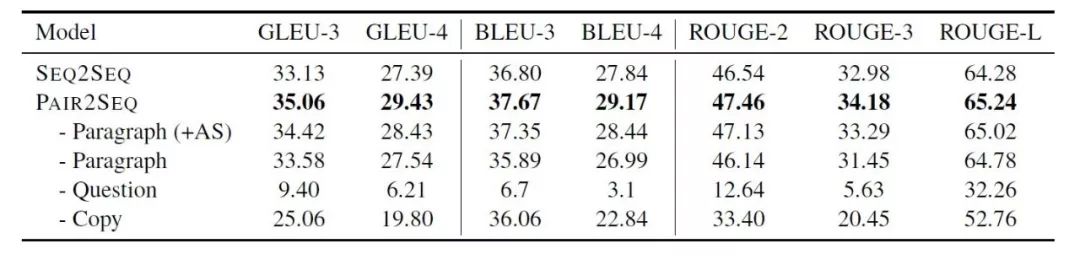
表3:Pair2Seq模型與Seq2Seq模型在多個評價指標上的對比結(jié)果
如表4所示,生成的問題作為增強數(shù)據(jù)能夠提高機器閱讀理解模型的表現(xiàn)。
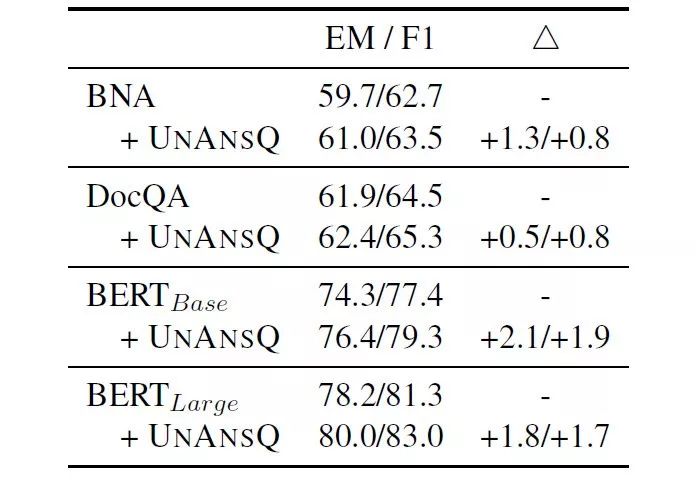
表4:SQuAD 2.0數(shù)據(jù)集上的實驗結(jié)果
個性化推薦系統(tǒng)
個性化新聞推薦是解決新聞信息過載和實現(xiàn)個性化新聞信息獲取的重要技術(shù),能夠有效提升用戶的新聞閱讀體驗,被廣泛應用于各種在線新聞網(wǎng)站和新聞APP中。學習準確的用戶興趣的表示是實現(xiàn)個性化新聞推薦的核心步驟。對于很多用戶來說,他們不僅存在長期的新聞閱讀偏好,也往往由于受社會和個人環(huán)境的影響,擁有一些短期和動態(tài)的興趣。然而已有的新聞推薦方法通常只構(gòu)建單一的用戶表示,很難同時準確建模這兩種興趣。
代表論文:Neural News Recommendation with Long- and Short-term User Representations
論文鏈接:https://nvagus.github.io/paper/ACL19NewsRec.pdf
該論文提出了Long- and Short-term User Representations(LSTUR)模型,用于在新聞推薦任務中同時學習用戶長期和短期的興趣表示。模型的整體結(jié)構(gòu)可分為四個模塊,分別是新聞編碼器、用戶長期興趣和短期興趣模型、以及候選新聞的個性化分數(shù)預測模型。
新聞編碼器模塊從新聞標題、新聞的類別和子類別構(gòu)建新聞表示向量。新聞標題的原始文本先映射為詞向量,然后通過CNN獲得局部表示,最后通過Attention網(wǎng)絡選取重要的語義信息構(gòu)成新聞標題表示。新聞的類別和子類別分別映射為稠密向量,與新聞標題表示拼接作為最終的新聞表示。

圖5:LSTUR模型架構(gòu)
用戶短期興趣表示模塊用于從用戶近期點擊過的新聞歷史中學習用戶的表示向量,然后將這些點擊的新聞的表示向量按時間順序依次通過GRU模型得到用戶短期興趣表示。用戶長期興趣表示模塊則是從用戶的ID中學習用戶的表示向量。對于如何同時學習用戶長期和短期的興趣表示,該論文提出了兩種結(jié)合方式:(1)將用戶長期興趣表示作為用戶短期用戶表示計算中GRU的初始狀態(tài)(LSTUR-ini);(2)將用戶長短期興趣表示拼接作為最終用戶表示(LSTUR-con)。候選新聞的個性化分數(shù)通過用戶表示向量和新聞表示向量的內(nèi)積計算,作為眾多候選新聞針對特定用戶個性化排序的依據(jù)。
該論文提出的方法存在的一個問題是無法學習新到來用戶的長期興趣的表示向量。在預測的過程中簡單地將新用戶的長期興趣表示置為零向量可能無法取得最優(yōu)的效果。為了解決這個問題,該論文提出在模型訓練的過程中模擬新用戶存在的情況,具體做法是隨機掩蓋(mask)部分用戶的長期興趣表示向量,即用戶的長期興趣表示向量會以概率p被置為全零向量。實驗表明,無論是LSTUR-ini還是LSTUR-con,在訓練過程中加入長期興趣隨機掩蓋(random mask)的做法均能明顯提升模型效果。
該論文在MSN新聞推薦數(shù)據(jù)集上進行了實驗,并和眾多基線方法進行了對比,結(jié)果如表5所示。
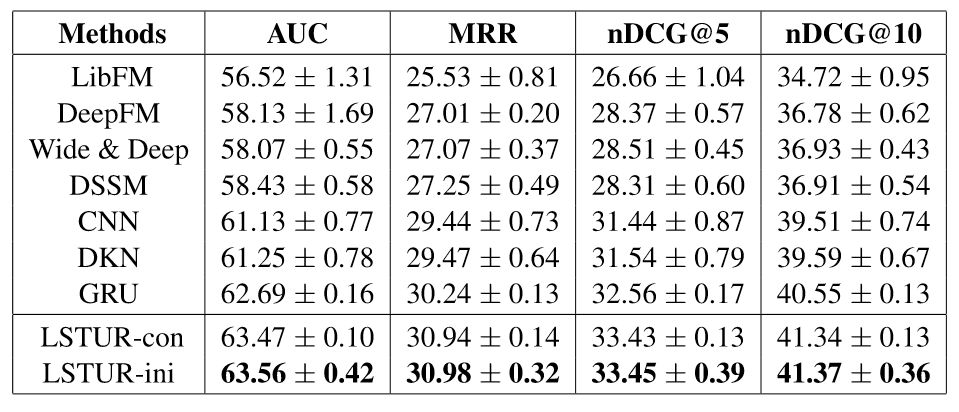
表5:不同模型在MSN新聞推薦數(shù)據(jù)集上的實驗結(jié)果
實驗結(jié)果表明,同時學習長期和短期用戶興趣表示能夠有效地提升新聞個性化推薦的效果,因此該論文提出的兩種方法均明顯優(yōu)于基線方法。
視頻理解
近年來,隨著運算能力的提升和數(shù)據(jù)集的涌現(xiàn),有關(guān)視頻理解的研究逐漸成為熱點。視頻數(shù)據(jù)往往蘊含著豐富的信息。其中,既包含較底層的特征信息,例如視頻幀的編碼表示;也包含一些高級的語義信息,例如視頻中出現(xiàn)的實體、實體所執(zhí)行的動作和實體之間的交互等;甚至還包含很多時序結(jié)構(gòu)性語義信息,例如動作序列、步驟和段落結(jié)構(gòu)等。而從數(shù)據(jù)的角度來看,視頻往往同時包含了圖像序列、音頻(波形)和語音(文本)等模態(tài)。視頻理解的目的就是通過各種精心設計的任務,利用多種不同模態(tài)的數(shù)據(jù),來讓計算機學會“瀏覽”視頻,并產(chǎn)生“理解”行為。
代表論文:Dense Procedure Captioning in Narrated Instructional Videos
論文鏈接:
https://www.msra.cn/wp-content/uploads/2019/06/DenseProcedureCaptioninginNarratedInstructionalVideos.pdf
視頻可以看作是在時間維度上展開的一系列圖像幀,但相較于“一目了然”的圖片,視頻需要人們花費更多的精力去觀看并進行理解。如果機器能自動地提取視頻內(nèi)容的摘要,并對視頻中的每一個結(jié)構(gòu)化的片段給出相應的文字描述,這將能夠大量地節(jié)省用戶的時間——用戶不再需要完整地瀏覽整個視頻,而只需要瀏覽文字化的摘要即可獲悉其中內(nèi)容。(場景如圖6所示)

圖6:視頻結(jié)構(gòu)化片段相應文字描述的場景展示
為了滿足這個需求,我們針對 “指導性視頻 (Instructional Video)”,設計了一個名為Procedure Extractor的視頻理解系統(tǒng):通過輸入視頻和視頻內(nèi)的敘述性旁白(Narrative Transcript),輸出視頻中每一個步驟(Procedure)的時間片段(起始時間與結(jié)束時間),并且為每一個視頻片段生成一段文本描述。
模型結(jié)構(gòu)如圖7所示。我們首先對視頻旁白(Transcript)進行分句,再使用一個經(jīng)過預訓練的BERT模型提取句子特征表示,然后通過多層self attention獲得整個transcript的特征表示,將其與利用ResNet抽取的視頻幀特征拼接,并形成一個完整的特征矩陣。
為了能處理不同長度Procedure的信息流動,我們仿照Fast-RCNN系列模型的方法,使用了多個不同大小的卷積核和多個不同尺度的Anchor來對整個視頻特征矩陣進行卷積操作,并通過一個LSTM模型來挑選包含正確Procedure的Anchors。在描述生成階段,我們使用與片段時間對應的視頻、Transcript信息,通過一個Sequence to Sequence模型來生成最終的視頻片段描述。
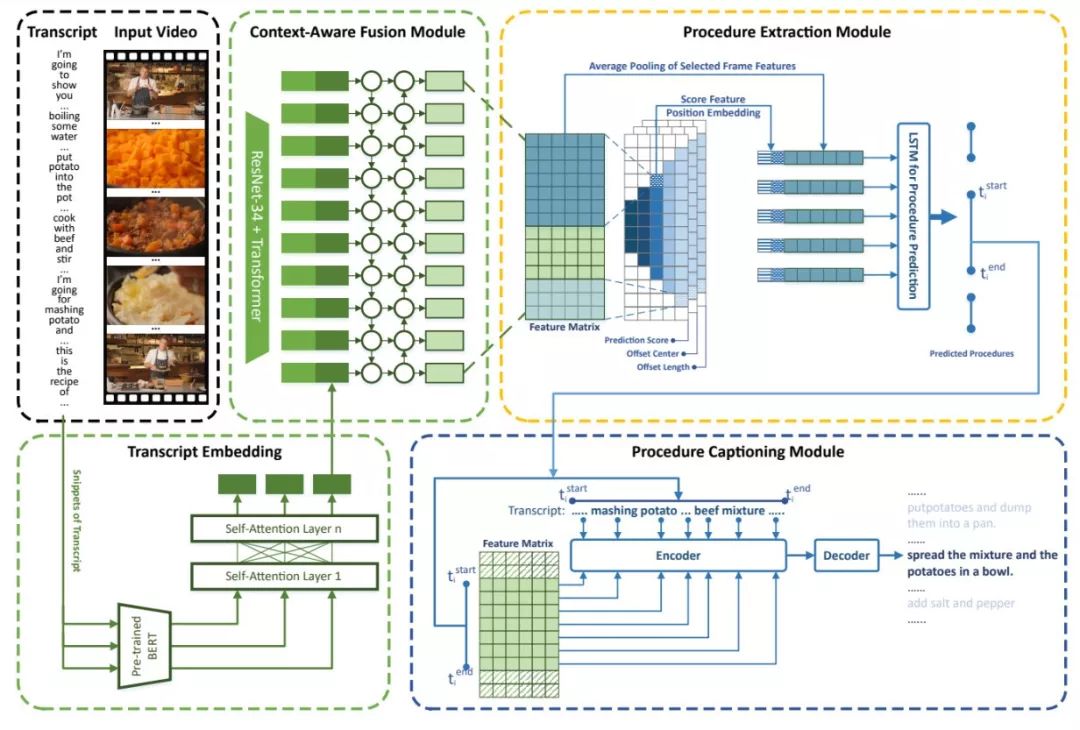
圖7:Procedure Extractor模型架構(gòu)
這項工作通過Azure Speech to Text云服務從視頻中抽取旁白中Transcript。在YouCook II數(shù)據(jù)集上的Procedure Extraction和Procedure Captioning任務上都取得了最好的成績。
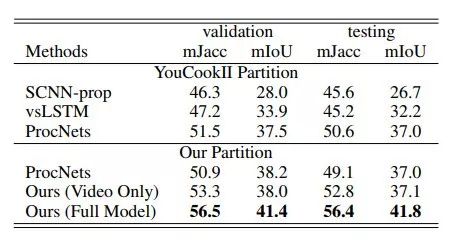
表6:不同模型在YouCook II數(shù)據(jù)集的Procedure Extraction任務上的實驗結(jié)果
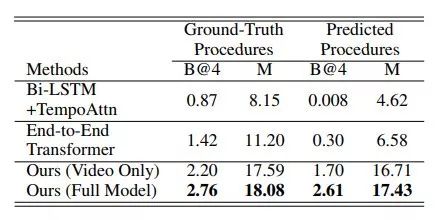
表7:不同模型在YouCook II數(shù)據(jù)集的Procedure Captioning任務上的實驗結(jié)果
語義解析
語義解析(semantic parsing)的目的是把自然語言自動轉(zhuǎn)化為一種機器可以理解并執(zhí)行的表達形式。在基于知識庫的搜索場景中,語義解析模型可以將用戶查詢轉(zhuǎn)換為可以在結(jié)構(gòu)化知識庫(如Microsoft Satori、Google Knowledge Graph)上可以執(zhí)行的SPARQL語句;在企業(yè)數(shù)據(jù)交互場景中,語義解析模型可以將用戶的語言轉(zhuǎn)換為結(jié)構(gòu)化查詢語句(Structured Query Language, SQL);在虛擬語音助手場景中,語義解析模型可以將用戶的語言轉(zhuǎn)換為調(diào)用不同應用程序的API語句。
代表論文:Coupling Retrieval and Meta-Learning for Context-Dependent Semantic Parsing
論文鏈接:https://arxiv.org/abs/1906.07108
在該論文中,我們以對話式問答和基于上下文的代碼生成為例介紹了我們在語義解析領域的研究進展。人們在對樣例x做決策的時候,往往不是從頭開始寫,而是先從已有的知識庫中找到相似的樣例(x’,y’),然后進行改寫。傳統(tǒng)的retrieve-and-edit的方法通常只考慮一個(x’,y’)樣例,而一個結(jié)構(gòu)化規(guī)范語義表示可能來自于多個相關(guān)的樣例中。以此為出發(fā)點,本論文提出了一種結(jié)合檢索與元學習(meta-learning)的語義解析方法。
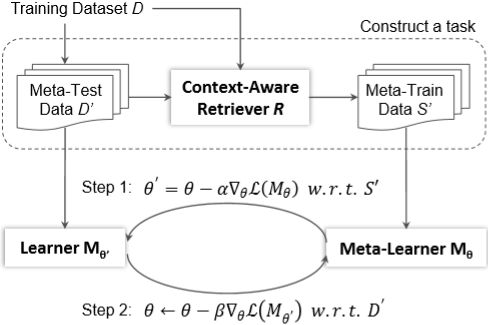
圖8:結(jié)合檢索與元學習和語義解析方法框架
整體框架如圖8所示,其中包含了檢索和元學習兩部分。在檢索部分,首先采樣一批測試數(shù)據(jù)D’,然后利用基于上下文的檢索模型R找到相似的樣例S’作為訓練數(shù)據(jù),從而構(gòu)成一個任務。在訓練階段,首先使用訓練數(shù)據(jù)得到特定任務的模型M_(θ^')(step 1),然后再利用測試數(shù)據(jù)更新元學習器M_θ(step 2)。在預測階段,先使用相似樣本更新元學習器的參數(shù),然后再進行預測。
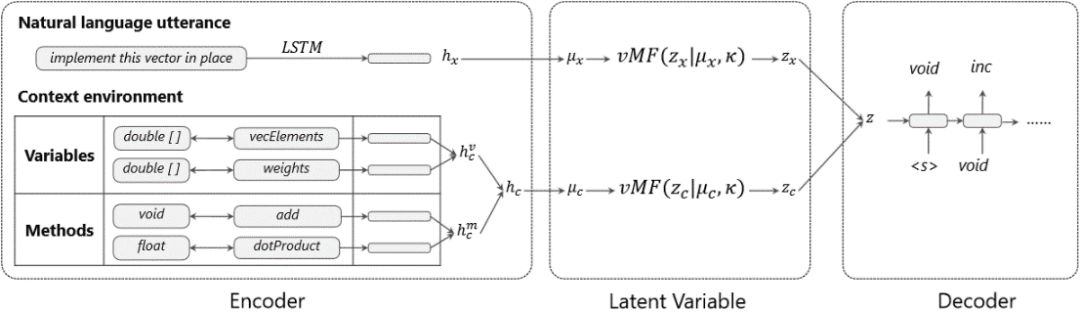
圖9:基于上下文的檢索模型框架
圖9是基于上下文的檢索模型,該模型是一個建立在變分自編碼器(VAE)框架下的編碼-解碼(encoder-decoder)模型,將文本和上下文環(huán)境編碼成一個潛層變量z,然后利用該變量解碼出邏輯表達式。在檢索的過程中,使用KL散度作為距離度量得到相似的樣本。
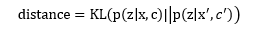
該論文在CONCODE和CSQA兩個公開數(shù)據(jù)集上進行實驗,可以看出結(jié)合檢索和元學習取得了最好的成績。
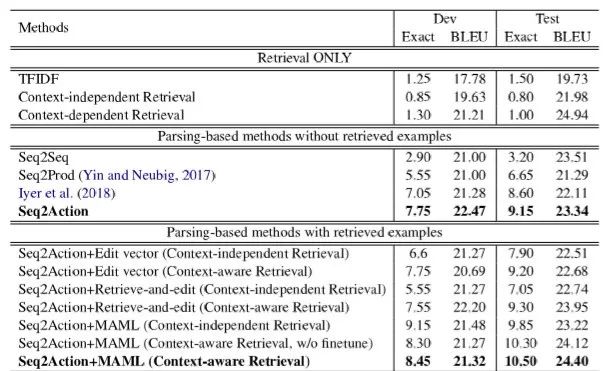
表8:不同模型在CONCODE數(shù)據(jù)集上的實驗結(jié)果
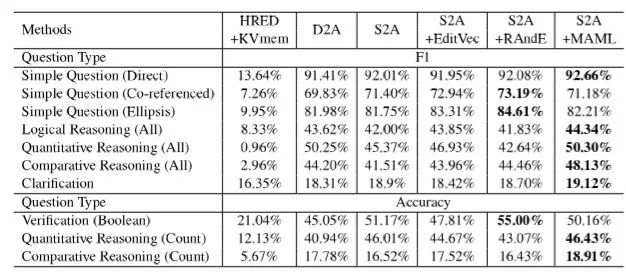
表9:不同模型在CSQA數(shù)據(jù)集上的實驗結(jié)果
同時,這種檢索模型不僅能夠考慮語義信息,如“spouse” 和 “married”,而且能夠考慮上下文信息,如HashMap和Map,因此能夠很好提升檢索的質(zhì)量。
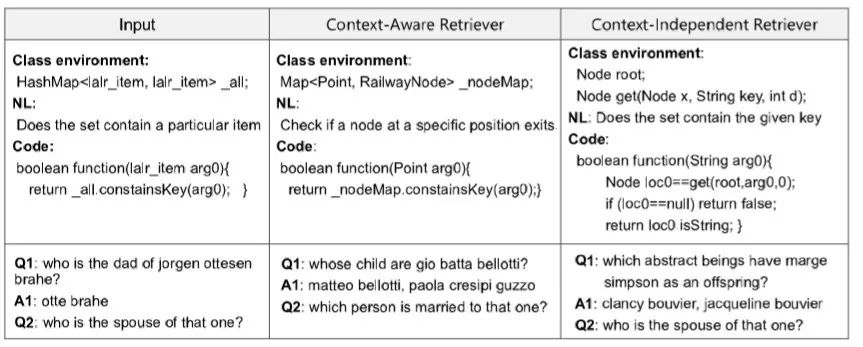
圖10:檢索模型在CONCODE和CSQA數(shù)據(jù)集上的結(jié)果展示
代表論文:Towards Complex Text-to-SQL in Cross-Domain Database with Intermediate Representation
論文鏈接:https://arxiv.org/abs/1905.08205
近年來,通過自然語言直接生成SQL查詢語句引起了越來越多的關(guān)注。目前比較先進的模型在已有的NL-to-SQL的數(shù)據(jù)集上(例如WikiSQL、ATIS、GEO等)都取得超過80%的準確率。然而,在最近發(fā)布的Spider數(shù)據(jù)集上,這些已有的模型并沒有取得令人滿意的效果。究其原因,Spider數(shù)據(jù)集有兩個特點:首先,Spider數(shù)據(jù)集里的SQL查詢語句比目前已有的Text-to-SQL數(shù)據(jù)集更加復雜,例如SQL語句中包含GROUPBY、HAVING、JOIN、NestedQuery等部分。通過自然語言生成復雜的SQL查詢語句尤其困難,本質(zhì)原因是面向語義的自然語言和面向執(zhí)行的SQL查詢語句之間不匹配,SQL越復雜,不匹配的越明顯;其次,Spider數(shù)據(jù)集是跨領域的(cross-domain),即訓練和測試是在完全不同的database上做的。在跨領域的設置下,自然語言中出現(xiàn)了大量的out-of-domain(OOD)的單詞,給預測列名造成了困難。
針對這兩個挑戰(zhàn),我們提出了IRNet模型。IRNet使用了一個schema linking模塊,根據(jù)數(shù)據(jù)庫的schema信息,識別自然語言中的提到的表名和列名,建立自然語言和數(shù)據(jù)庫之間的連接。接下來,為了解決面向語義的自然語言和面向執(zhí)行的SQL查詢語句之間不匹配的問題,與以往的Text-to-SQL方法直接生成SQL查詢語句不同的是,IRNet首先生成一種中間的語義表示形式SemQL,然后再將中間表示轉(zhuǎn)換成SQL查詢語句。
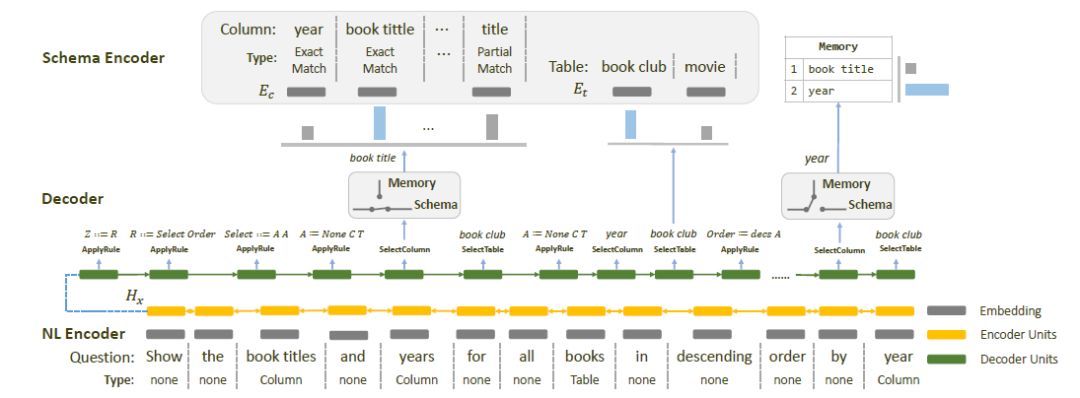
圖11:IRNet模型框架
實驗結(jié)果如表10所示,在Spider數(shù)據(jù)集上,IRNet實現(xiàn)了46.7%的準確率,比已有的最好方法提升了19.5%的準確率。同時,IRNet+Bert實現(xiàn)了54.7%的準確率。
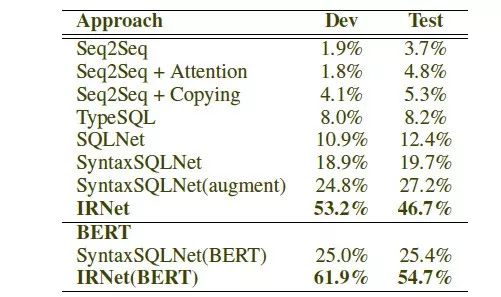
表10:不同模型在Spider數(shù)據(jù)集上的實驗結(jié)果
到目前為止,微軟亞洲研究院的IRNet模型在Spider Challenge比賽上取得了第一名的成績。
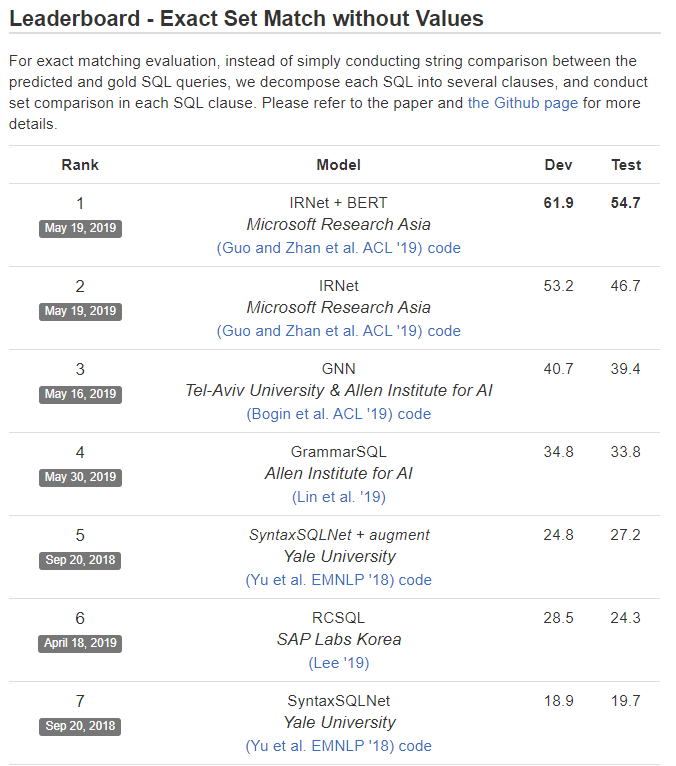
圖12:Spider Challenge比賽結(jié)果
無監(jiān)督機器翻譯
無監(jiān)督機器翻譯僅僅利用單語的數(shù)據(jù)而不是雙語并行數(shù)據(jù)進行訓練,對于低資源的語言翻譯非常重要。當前,無監(jiān)督機器翻譯在相似語言對上(例如英語-德語、葡萄牙語-加利西亞語)取得了非常好的效果。然而在距離較遠的語言對上(例如丹麥語-加利西亞語),由于無監(jiān)督的語義對齊比較困難,通常表現(xiàn)較差。在實驗中,我們發(fā)現(xiàn)在距離較近的葡萄牙語-加利西亞語上能取得23.43的BLEU分,而在距離較遠的丹麥語-加利西亞語上只有6.56分。微軟亞洲研究院的研究人員嘗試解決遠距離語言的無監(jiān)督翻譯問題。
代表論文:Unsupervised Pivot Translation for Distant Languages
論文鏈接:https://arxiv.org/abs/1906.02461
我們考慮到兩個距離較遠的語言能通過多個中轉(zhuǎn)語言鏈接起來,其中兩個相鄰的中轉(zhuǎn)語言間的翻譯易于兩個原始語言的翻譯(距離更近或者可用單語數(shù)據(jù)更多)。如圖13所示,距離較遠的丹麥語-加利西亞語(Da-Gl,圖中紅色路徑)能拆分成丹麥語-英語(Da-En)、英語-西班牙語(En-Es)、西班牙語-加利西亞語(Es-Gl)三跳無監(jiān)督翻譯路徑(圖中藍色路徑),拆分后的翻譯性能為12.14分,相比直接的丹麥語-加利西亞語翻譯(6.56分)有大幅提高。因此,我們在論文中針對遠距離語言對提出了無監(jiān)督中轉(zhuǎn)翻譯(Unsupervised Pivot Translation)方法。
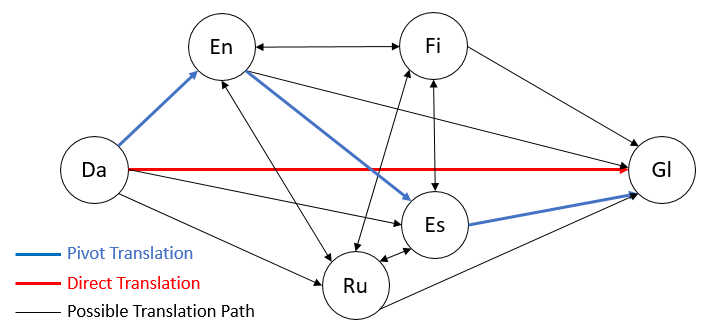
圖13:無監(jiān)督中轉(zhuǎn)翻譯在兩個語言之間有多條可選路徑
無監(jiān)督中轉(zhuǎn)翻譯面臨的一個挑戰(zhàn)是兩個語言之間可選路徑很多(如圖13藍色、黑色路徑所示,實際場景中可選路徑更多),而不同路徑的翻譯精度不同,如何選擇精度最高的路徑對于保證無監(jiān)督中轉(zhuǎn)翻譯的效果非常重要。由于可選路徑隨著跳數(shù)以及中轉(zhuǎn)語言數(shù)呈指數(shù)增長趨勢,遍歷計算每條路徑的精度代價巨大。對此,我們提出了Learning to Route(LTR)的路徑選擇算法,該算法以單跳的BLEU分及語言ID作為特征,利用多層LSTM模型預測多跳翻譯的精度,并據(jù)此來選擇最好的中轉(zhuǎn)路徑。關(guān)于LTR算法的詳細內(nèi)容可參考論文。
我們在20個語言一共294個語言對上進行了實驗,來驗證我們的無監(jiān)督中轉(zhuǎn)翻譯以及LTR路徑選擇算法的性能。表11列出了部分語言對的實驗結(jié)果,其中DT代表直接從源語言到目標語言的無監(jiān)督翻譯,LTR代表我們提出的中轉(zhuǎn)算法,GT(Ground Truth)代表最好的中轉(zhuǎn)翻譯,也決定了我們方法的上限,GT(?)和LTR(?)分別代表GT和LTR相對于直接翻譯DT的提升,Pivot-1和Pivot-2代表中轉(zhuǎn)路徑的兩個中轉(zhuǎn)語言(我們最多考慮三跳路徑)。如果是一個兩跳路徑,那么Pivot-1和Pivot-2相同;如果是直接翻譯,那么Pivot-1和Pivot-2為空。
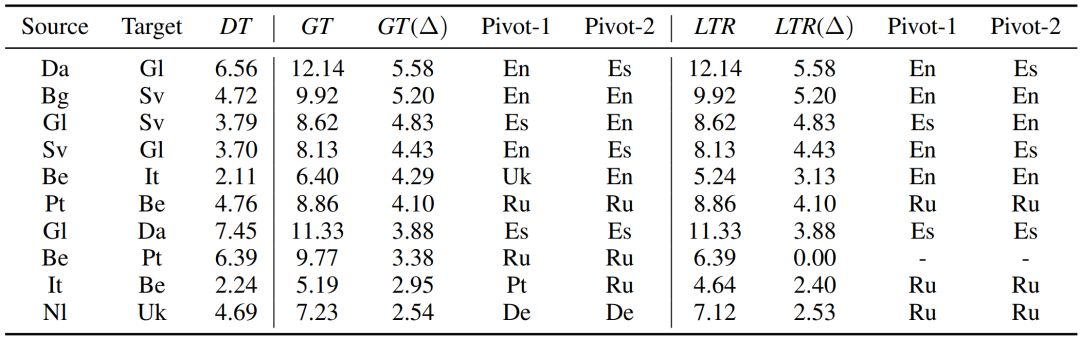
表11:Learning to Route(LTR)路徑選擇算法在部分語言對上的實驗結(jié)果
可以看到,無監(jiān)督中轉(zhuǎn)翻譯相比無監(jiān)督直接翻譯有較大的BLEU分提升,而且我們提出的LTR方法的精度非常接近于最好的中轉(zhuǎn)翻譯GT,表明了我們提出的無監(jiān)督中轉(zhuǎn)翻譯以及LTR路徑選擇算法的有效性。例如,我們的方法(LTR)在丹麥語-加利西亞語(Da-Gl)、保加利亞語-瑞典語(Bg-Sv)、葡萄牙-白俄羅斯語(Pt-Be)上分別有5.58、5.20、4.10分的提升。
人機對話
端到端開放域?qū)υ捝墒侨藱C對話領域近幾年的一個研究熱點。開放域?qū)υ捝芍械囊粋€基本問題是如何避免產(chǎn)生平凡回復(safe response)。一般來講,平凡回復的產(chǎn)生來源于開放域?qū)υ捴写嬖诘妮斎牒突貜烷g的 “一對多”關(guān)系。相對于已有工作“隱式”地對這些關(guān)系進行建模,我們考慮“顯式”地表示輸入和回復間的對應關(guān)系,從而使得對話生成的結(jié)果變得可解釋。不僅如此,我們還希望生成模型可以允許開發(fā)者能夠像“拼樂高玩具”一樣通過控制一些屬性定制對話生成的結(jié)果。
代表論文:Neural Response Generation with Meta-Words
論文鏈接:https://arxiv.org/pdf/1906.06050.pdf
在這篇論文中,我們提出用meta-word來表示輸入和回復間的關(guān)系。Meta-word代表了一組回復屬性(如圖14中的回復意圖(Act),回復長度(Len)等)。利用meta-word進行對話生成的好處包括:(1)模型具有很好的可解釋性;(2)通過訂制meta-word,開發(fā)者可以控制回復生成;(3)情感,話題,人格等都可以定義為meta-word中的一個屬性,因此諸如情感對話生成,個性化對話生成等熱點問題都可通過該論文提出的框架解決;(4)工程師們可以通過增加或調(diào)整meta-word不斷提升生成模型的性能。

圖14:基于meta-word的回復生成
利用meta-word進行回復生成需要解決兩個問題:(1)如何確保回復和輸入相關(guān);(2)如何確保回復能夠如實地表達預先定義的meta-word。為了解決這兩個問題,我們將meta-word的表達形式化成回復生成中的目標,提出了一個基于目標跟蹤記憶網(wǎng)絡的生成模型(如圖15)。該網(wǎng)絡由一個狀態(tài)記憶板和一個狀態(tài)控制器組成,前者記錄生成過程中meta-word的表達情況,后者則根據(jù)當前已經(jīng)生成的部分動態(tài)地更新記憶板中的存儲并將目前的表達情況和最終表達目的的差距傳達給解碼器。
在模型學習過程中,我們在傳統(tǒng)的似然目標之外增加了一個狀態(tài)更新?lián)p失,以使得目標追蹤能夠更好地利用訓練數(shù)據(jù)中的監(jiān)督信號。不僅如此,我們還提出了一個meta-word的預測方案,從而使得整個架構(gòu)可以在實際中使用。
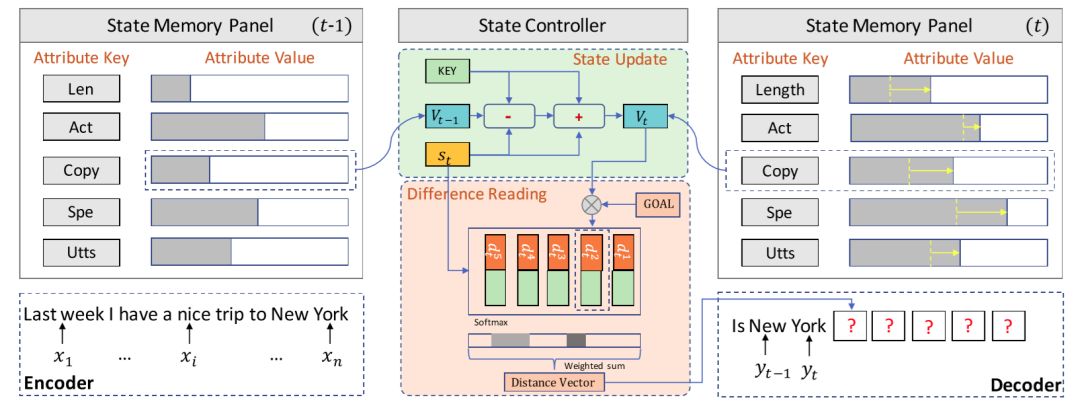
圖15:目標追蹤記憶網(wǎng)絡
我們在Twitter和Reddit兩個數(shù)據(jù)集上考察了生成回復的相關(guān)性、多樣性、“一對多“關(guān)系建模的準確性、以及meta-word表達的準確性。不僅如此,我們還對生成結(jié)果進行了人工評測。實驗結(jié)果如下:
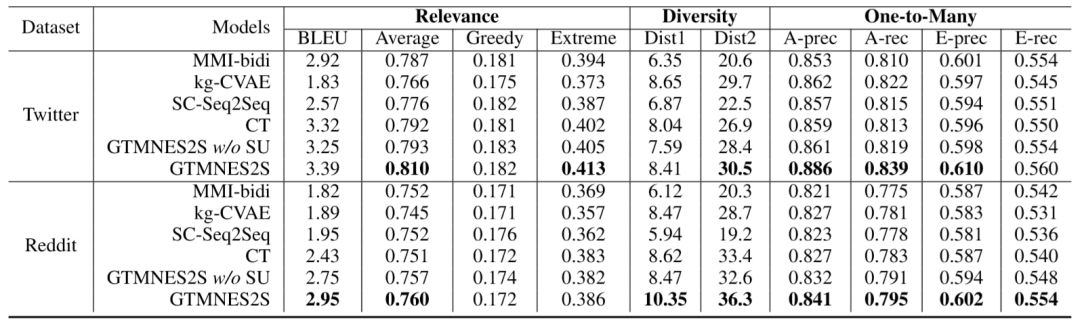
表12:相關(guān)性、多樣性、“一對多”關(guān)系建模準確性評測結(jié)果
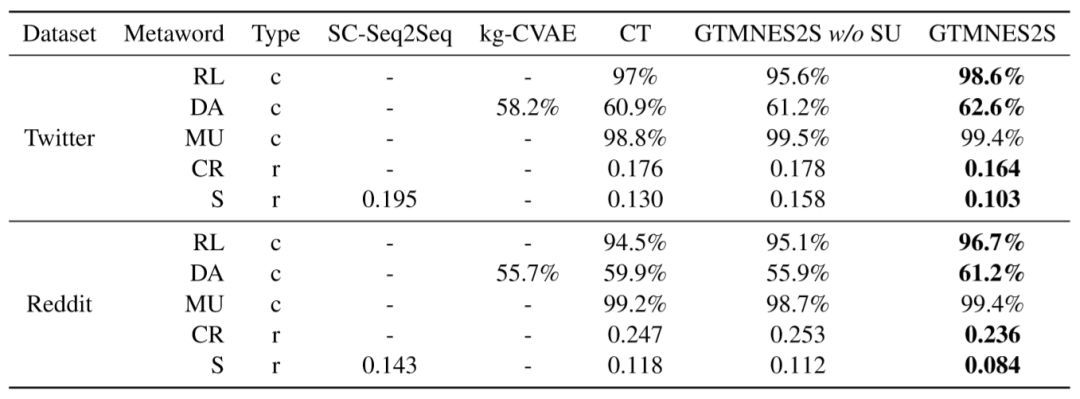
表13:Meta-word表達準確性評測結(jié)果
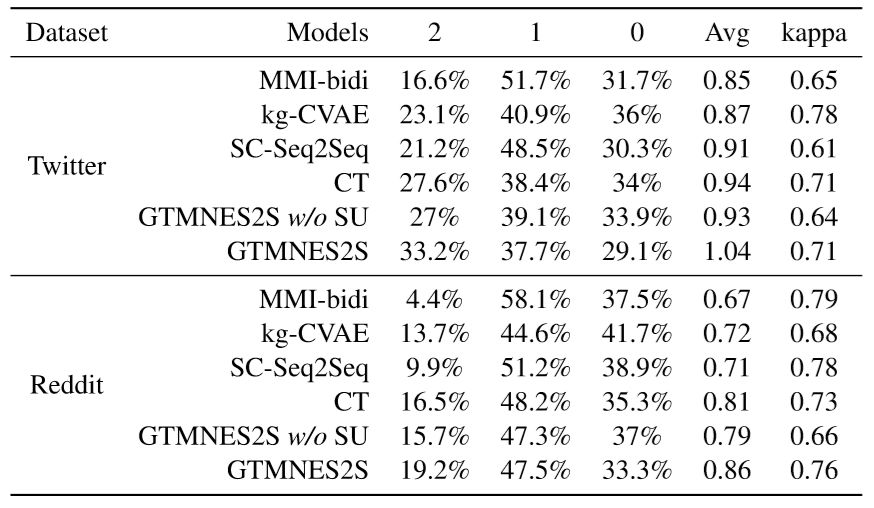
表14:人工評測結(jié)果
更有意思的是,當我們逐漸地增加meta-word中的屬性變量,我們發(fā)現(xiàn)驗證集上的PPL會逐漸降低,這也印證了“通過調(diào)整meta-word可以不斷提升模型性能”的論斷。
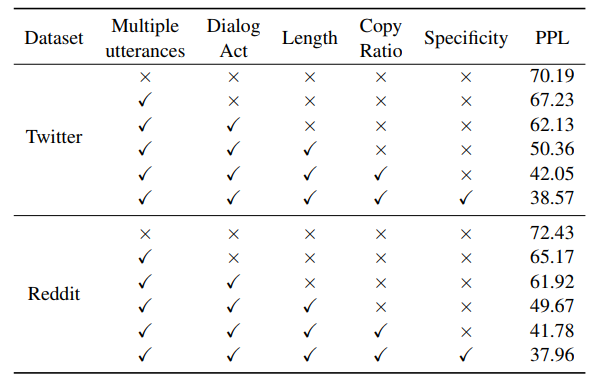
表15:不同屬性帶來的驗證集PPL變化
-
編碼器
+關(guān)注
關(guān)注
45文章
3647瀏覽量
134711 -
論文
+關(guān)注
關(guān)注
1文章
103瀏覽量
14969 -
自然語言處理
+關(guān)注
關(guān)注
1文章
619瀏覽量
13579
原文標題:一覽微軟在機器閱讀理解、推薦系統(tǒng)、人機對話等最新研究進展 | ACL 2019
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
芯盾時代入選《API安全技術(shù)應用指南(2024版)》API安全十大代表性廠商
FPGA中有狀態(tài)表項的存儲與管理
艾畢勝電子MS39549 電機驅(qū)動芯片在智能門鎖領域中的應用

Aigtek功率放大器在各領域中有何應用

深入了解IXYS固態(tài)繼電器:可靠性與應用領域的完美結(jié)合
CNN在多個領域中的應用
滾珠花鍵在工業(yè)自動化領域中有什么優(yōu)勢?

8芯M16插頭耐磨性怎么樣

標貝語音識別技術(shù)在金融領域中的應用實例

AC/DC電源模塊在新能源領域中的應用前景展望

滑軌屏能不能應用到交通領域中?會有怎樣的效果?
濾波器:工作原理和分類及應用領域?|深圳比創(chuàng)達電子EMC a
嵌入式工控機在應用領域當中有哪些優(yōu)勢?
電抗器在工業(yè)領域中的重要性






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論