") 能不能用GAN破解標(biāo)注數(shù)據(jù)不足的問題呢
能不能用GAN破解標(biāo)注數(shù)據(jù)不足的問題呢
在計(jì)算機(jī)視覺領(lǐng)域,深度學(xué)習(xí)方法已全方位在各個(gè)方向獲得突破,這從近幾年CVPR 的論文即可看出。
但這往往需要大量的標(biāo)注數(shù)據(jù),比如最著明的ImageNet數(shù)據(jù)集,人工標(biāo)注了100多萬幅圖像,盡管只是每幅圖像打個(gè)標(biāo)簽,但也耗費(fèi)了大量的人力物力。
說到標(biāo)注這件事,打個(gè)標(biāo)簽其實(shí)還好,如果是針對圖像分割任務(wù),要對圖像進(jìn)行像素級標(biāo)注,那標(biāo)注的成本就太高了。跟專業(yè)的標(biāo)注公司打過交道的朋友都知道,打標(biāo)簽、標(biāo)關(guān)鍵點(diǎn)和標(biāo)像素區(qū)域,所要付出的成本可大不同。
在醫(yī)學(xué)影像領(lǐng)域,圖像數(shù)據(jù)往往難以獲取,而這又是一個(gè)對標(biāo)注精度要求極高的領(lǐng)域。
最近幾年,以GAN為代表的生成模型經(jīng)常見諸報(bào)端,那能否用GAN破解標(biāo)注數(shù)據(jù)不足的問題呢?
最近發(fā)現(xiàn)一篇論文Generating large labeled data sets for laparoscopic image processing tasks using unpaired image-to-image translation,來自德國國家腫瘤疾病中心等單位的幾位作者,提出通過GAN對計(jì)算機(jī)合成的人體腹腔鏡圖像進(jìn)行轉(zhuǎn)換的方法,能夠大批量得到與真實(shí)圖像相似的合成圖像,并在器官分割實(shí)驗(yàn)中,大大改進(jìn)了真實(shí)圖像的分割精度。非常值得一讀。
下面是作者信息:

下圖即為作者用計(jì)算機(jī)圖形學(xué)方法合成的腹腔鏡圖像(A,下圖第一列),和轉(zhuǎn)換后的具有真實(shí)感的合成圖像(Bsyn,下圖第二列和第三列)。
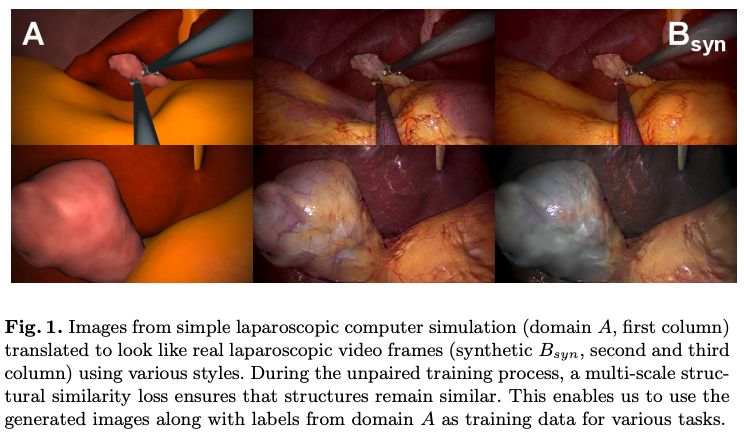
CV君不是專業(yè)的醫(yī)務(wù)人員,不過也可以看出轉(zhuǎn)換后的圖像的確比之前更具真實(shí)感。
方法介紹
作者使用Nvidia發(fā)布的MUNIT庫進(jìn)行圖像轉(zhuǎn)換,并進(jìn)行了改進(jìn)。
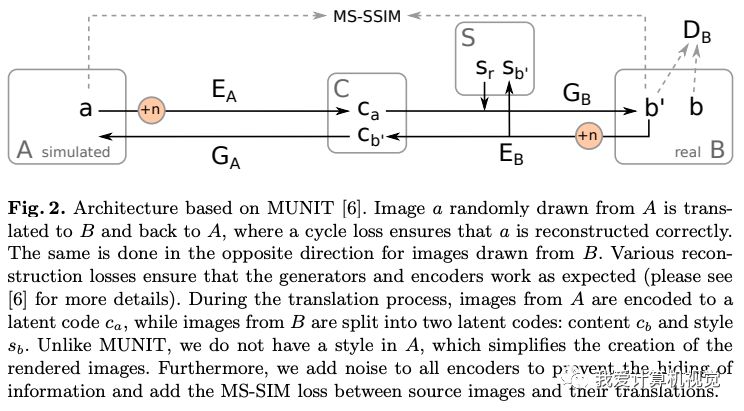
這是一個(gè)非成對數(shù)據(jù)的圖像轉(zhuǎn)換問題,作者使用一種循環(huán)loss,將A 域(模擬圖)和B域(少部分真實(shí)圖)進(jìn)行循環(huán)的編碼、生成、鑒別。
因?yàn)锳 域內(nèi)圖像是計(jì)算機(jī)模擬出來的,所以天然的帶有像素級標(biāo)簽。
作者的改進(jìn)之處在于添加了MS-SSIM loss (Multi-Scale Structural Similarity,多尺度結(jié)構(gòu)相似性損失函數(shù)),保證轉(zhuǎn)換后圖像結(jié)構(gòu)相同。
另外,作者對編碼器加入隨機(jī)噪聲,防止生成的紋理都完全相同。
下圖為作者提供的訓(xùn)練數(shù)據(jù)的例子:
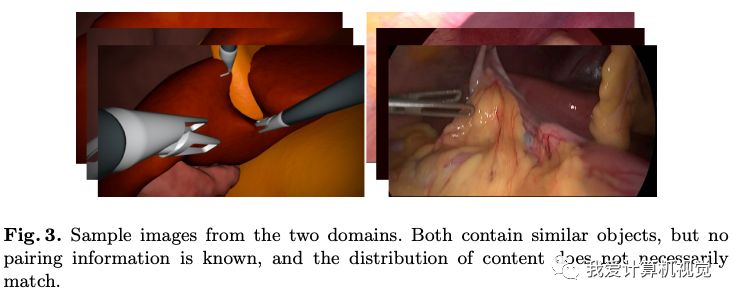
請注意,他們含有相似的目標(biāo),但很顯然內(nèi)容并不是匹配的,這樣的訓(xùn)練數(shù)據(jù)是比較好找到的。
實(shí)驗(yàn)結(jié)果
作者用上述方法生成了10萬幅圖像,并在圖像分割任務(wù)中驗(yàn)證了,這種合成數(shù)據(jù)對醫(yī)學(xué)圖像分割模型訓(xùn)練的價(jià)值。
下圖對各種情況進(jìn)行了分割結(jié)果比較:
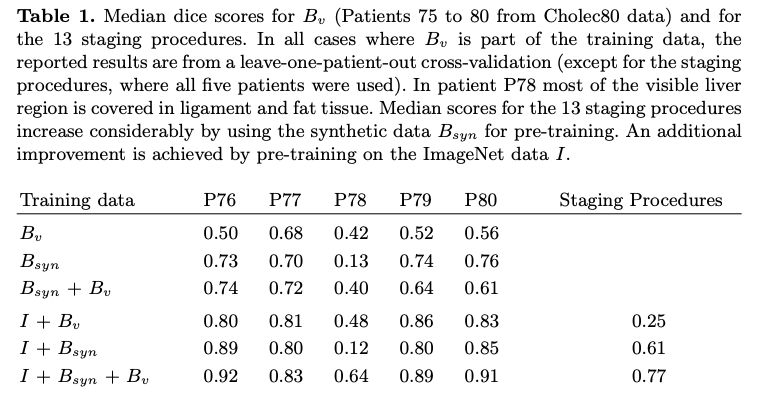
Bv是原有真實(shí)數(shù)據(jù),Bsyn是合成數(shù)據(jù),I代表模型在Imagenet進(jìn)行了預(yù)訓(xùn)練。
可見,使用這種合成數(shù)據(jù)大幅改進(jìn)了分割精度。而在Imagenet數(shù)據(jù)集上預(yù)訓(xùn)練的結(jié)果更好。這種方法對你有什么啟發(fā)?歡迎留言。
-
GaN
+關(guān)注
關(guān)注
19文章
2051瀏覽量
74951 -
計(jì)算機(jī)視覺
+關(guān)注
關(guān)注
8文章
1702瀏覽量
46225 -
大數(shù)據(jù)
+關(guān)注
關(guān)注
64文章
8925瀏覽量
138170 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5527瀏覽量
121833
原文標(biāo)題:數(shù)據(jù)不夠,用GAN來湊!
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論