") 用AI對抗AI——基于視頻人臉篡改的檢測
用AI對抗AI——基于視頻人臉篡改的檢測
還記得權力的游戲第八季么? Jon Snow也加入了千萬罵編劇的粉絲的陣營,并且因此向粉絲道歉。
這個視頻當然是假的,他嘴巴的移動方式看起來就很奇怪。
這是一個DeepFake生成的視頻,一個用來娛樂或欺騙大眾人工智能產(chǎn)物。
之前文摘菌也報道過,這項技術的上線后就廣受詬病,后來又有一個小團隊開發(fā)出一款新的應用DeepNude,可以一鍵實現(xiàn)脫衣,之后也因為反響惡劣而被迫下架。
人們對于無法分辨真假的恐懼是合理的,畢竟這種技術的出現(xiàn)將會滋生出許多想象不到的新的犯罪手段的誕生。
最近,南加州大學信息科學研究所計算機的研究人員發(fā)表一篇論文,研究通過訓練AI尋找視頻畫面中的不一致性來檢測AI生成的假視頻,論文同時也被提交到CVPR 2019。
用AI對抗AI,來看看如何實現(xiàn)
對于偽造生成的假視頻,研究人員發(fā)現(xiàn),用于生成虛假視頻的主流AI模型(以及其他方法,如2016年的Face2Face程序),都是通過逐幀修改視頻且并不注意時間的連貫性。這會使得生成視頻中的人物移動看起來非常笨拙,人們通常會注意到這類奇怪的動作。
為了實現(xiàn)找出奇怪動作這一過程的自動化,研究人員首先要訓練一個神經(jīng)網(wǎng)絡—這種人工智能程序以個人的海量視頻為基礎,可以用來“學習”人類在說話時如何移動的重要特征。
然后,研究人員使用這些參數(shù)將偽造視頻的堆疊幀輸入AI模型,以檢測視頻隨時間的不一致性。根據(jù)該論文,這種方法可以判斷“AI偽造視頻”,準確率超過90%。
研究人員使用的模型是一個遞歸卷積模型(Recurrent convolutional model),這個深度學習模型能夠很好的提取到視頻中的信息。
整個過程分為兩步:
將視頻中的人臉進行裁剪對齊
對于獲取人臉區(qū)域,研究人員使用由FaceForensics++提供的模型。
論文鏈接:
https://arxiv.org/abs/1901.08971
研究人員嘗試了兩種人臉對齊技術的結合:
顯式使用面部坐標對齊,在參考坐標系中,人的面部是先天決定的,所有的面孔是使用同一個參考坐標系;
隱式排列對齊,使用STN。
在后一種情況下,網(wǎng)絡根據(jù)輸入圖像預測對齊參數(shù),因此可能學會縮放人臉的特定部分,必要時可將訓練集中的預期損失最小化。
在這兩種情況下,核心思想都是我們希望循環(huán)卷積模型將人臉“tubelet”作為輸入,這是一個跨越視頻幀的時空緊密對齊的人臉序列。
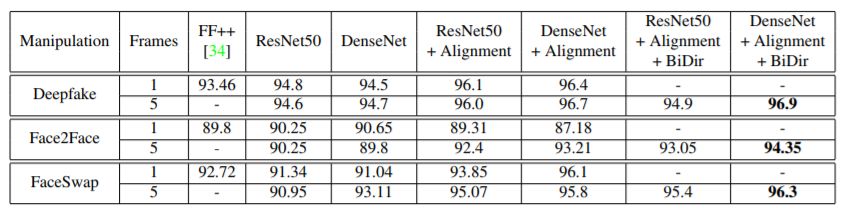
所有篡改類型的檢測精度。結果表明,采用線性和雙向遞歸網(wǎng)絡的DenseNet性能最好
基于視頻人臉篡改的檢測
對于人臉篡改的檢測,我們使用一個類似于用于視覺識別的Long-term循環(huán)卷積網(wǎng)絡。
論文鏈接:
https://arxiv.org/abs/1411.4389
其中輸入是來自查詢視頻的幀序列,這個模型背后是在利用跨幀的時間差異。由于篡改是在逐幀的基礎上進行的,研究人員認為圖像中會存在時間差異。因此,由對人臉的篡改引起的低層次的差別則有可能表現(xiàn)為跨幀不一致特性的時間差異。
骨干網(wǎng)絡(Backbone encoding network)
在實驗中,研究人員探索了ResNet和DenseNet兩種架構作為模型的CNN分量。
無論采用何種架構,首先對主干網(wǎng)絡進行FF++訓練分割,使交叉熵損失最小化,進行二值分類,形成特征,從合成人臉中識別真實人臉。然后用RNN對Backbone進行擴展,最后在多種策略下形成端到端訓練。
RNN的訓練策略
研究人員使用放置在骨干網(wǎng)絡不同位置的多個循環(huán)模型進行實驗:用它將骨干網(wǎng)絡連接在一起,用來進行特征學習,將特征傳遞給隨時間推移聚合輸入的RNN。
在這里研究人員也嘗試了兩種策略:一是在骨干網(wǎng)的最終特性基礎上,簡單地使用單一的遞歸網(wǎng)絡;二是嘗試在骨干網(wǎng)結構的不同層次上訓練多個遞歸神經(jīng)網(wǎng)絡。
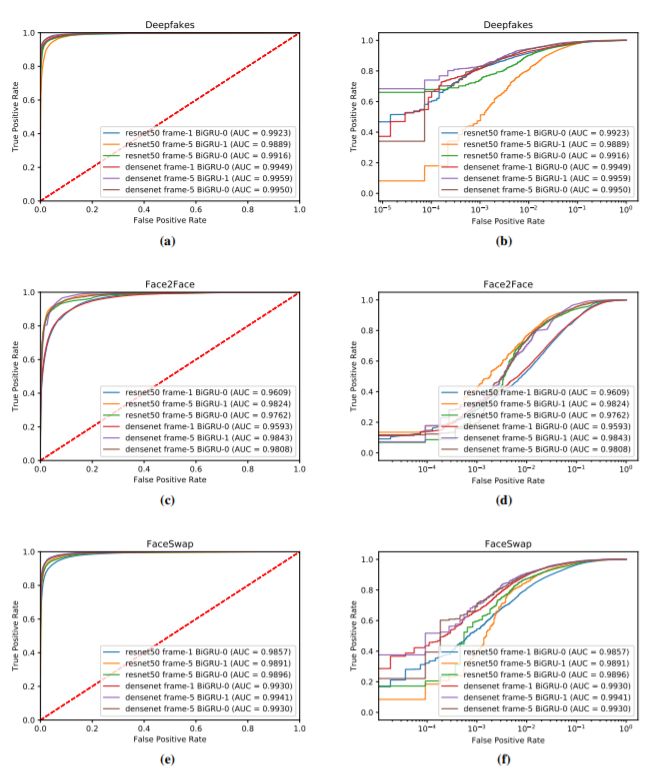
所有篡改類型的ROC曲線。每一行對應一個不同的篡改類型。左列為線性圖,右列為線性對數(shù)圖
希望能從源頭阻止deepfake假視頻
研究的共同作者Wael AbdAlmageed表示,這種模式可以被社交網(wǎng)站和視頻網(wǎng)站用于大規(guī)模識別deepfake假視頻,因為它不需要通過“學習”特定個體的關鍵特征來進行識別,而是通用的。
“我們的模型對于任何人來說都是通用的,因為我們不關注某個人的身份,而是關注面部運動的一致性,”AbdAlmageed說,“我們將發(fā)布自己的模型,所以社交網(wǎng)絡無需訓練新的模型。網(wǎng)站只需要在其平臺中加上該檢測軟件,以檢查上傳到平臺的視頻是否為deepfake生成的假視頻。”
機器學習的出現(xiàn)讓造假的成本逐漸變低,很多玩火不嫌事大的開發(fā)者還開發(fā)出許多不需要寫代碼直接可以造假的小軟件,盡管他們不一定是出于惡意,但是不排除軟件最后被用到“作惡”的地方。
雖然還有許多方法可以反“AI造假”(例如在拍攝圖片時生成"噪聲水印"),但利用AI來識別AI造假,并且將這項技術加載到視頻網(wǎng)站的審查過程中,那么從源頭大規(guī)模地阻止假視頻流向公眾,或許可以成為現(xiàn)實。
-
AI
+關注
關注
87文章
30746瀏覽量
268897 -
DeepFake
+關注
關注
0文章
15瀏覽量
6677
原文標題:解鈴還須系鈴人!南加大訓練AI檢測Deepfake“假視頻”,準確率超90%
文章出處:【微信號:BigDataDigest,微信公眾號:大數(shù)據(jù)文摘】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
可靈AI全球首發(fā)視頻模型定制功能,助力AI視頻創(chuàng)作
AI項目管理平臺怎么用
《AI for Science:人工智能驅(qū)動科學創(chuàng)新》第二章AI for Science的技術支撐學習心得
基于迅為RK3568/RK3588開發(fā)板的AI圖像識別方案
基于迅為RK3588開發(fā)板的AI圖像識別方案
人臉檢測和人臉識別的區(qū)別是什么
防止AI大模型被黑客病毒入侵控制(原創(chuàng))聆思大模型AI開發(fā)套件評測4
ai_reloc_network.h引入后,ai_datatypes_format.h和formats_list.h報錯的原因?
NanoEdge AI的技術原理、應用場景及優(yōu)勢
Stability AI與Morph AI共同推出一體化AI視頻創(chuàng)作工具
AI視頻年大爆發(fā)!2023年AI視頻生成領域的現(xiàn)狀全盤點






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論