") 不用寫(xiě)一行就帶就可以參加 Kaggle,這個(gè)真香!
不用寫(xiě)一行就帶就可以參加 Kaggle,這個(gè)真香!
【導(dǎo)讀】給大家分享一些 Kaggle 上的資源,如 Kaggle 開(kāi)放的數(shù)據(jù)集,也會(huì)分享一些好的競(jìng)賽方案或有意義的競(jìng)賽經(jīng)驗(yàn),幫助大家成長(zhǎng)。今天,我們要給大家介紹的這個(gè)工具特別推薦給以往只能仰望別人的,缺乏競(jìng)賽技能和經(jīng)驗(yàn)的朋友,你不需要寫(xiě)一行代碼就可以參與 Kaggle 競(jìng)賽,甚至連安裝環(huán)境都免了。是不是很神奇?下面我們一起 get 一下這個(gè)“真香”的工具!
參賽項(xiàng)目
Freesound Audio Tagging 2019
Kaggel 的競(jìng)賽項(xiàng)目 Freesound Audio Tagging 2019,同時(shí)也是 DCASE 2019 挑戰(zhàn)賽的任務(wù)之一(Task 2),今天不對(duì)這個(gè)競(jìng)賽做過(guò)多介紹,感興趣的朋友們可以通過(guò)我們下面給出的鏈接訪問(wèn)。
Freesound Audio Tagging 2019 是由 Freesound(MTG?—?Universitat Pompeu Fabra)和 Google 機(jī)器感知組舉辦的,數(shù)據(jù)通過(guò) Freesound Annotator 收集,比賽參考論文:
(1)《Audio tagging with noisy labels and minimal supervision》
https://arxiv.org/pdf/1906.02975.pdf
(2)《FREESOUND DATASETS: A PLATFORM FOR THE CREATION OF OPEN AUDIO DATASETS》
https://ismir2017.smcnus.org/wp-content/uploads/2017/10/161_Paper.pdf
隨著 AI 技術(shù)的不斷發(fā)展與落地,有越來(lái)越多的平臺(tái)和工具可供大家使用,這些平臺(tái)針對(duì)不同領(lǐng)域、不同層次的開(kāi)發(fā)者和學(xué)習(xí)者,只要你想學(xué)就有辦法。但問(wèn)題是,對(duì)于剛?cè)腴T(mén),沒(méi)有多少經(jīng)驗(yàn),對(duì) TensorFlow、PyTorch 等工具和框架也不熟悉的人,能參加這樣的競(jìng)賽嗎?
不會(huì)寫(xiě)代碼,也不會(huì) TensorFlow、PyTorch,怎么訓(xùn)練模型?
Peltarion 平臺(tái) 你值得擁有,訓(xùn)練你的模型只需 5 步!
Peltarion是怎樣的一個(gè)平臺(tái)?它部署在云端,在平臺(tái)上你只需要簡(jiǎn)單的“拖拉拽”就可以從0到1完成一個(gè) AI 模型的創(chuàng)建到部署。平臺(tái)給初始者提供了免費(fèi)使用50 小時(shí)、共有50 GB的 GPU存儲(chǔ)容量。

AI科技大本營(yíng)也注冊(cè)了一個(gè)賬號(hào),準(zhǔn)備利用一下免費(fèi)資源把模型跑起來(lái)。注冊(cè)賬號(hào)很簡(jiǎn)單,先用一個(gè)郵箱在平臺(tái)上注冊(cè)賬號(hào),然后在郵箱中完成驗(yàn)證,最后設(shè)置一個(gè)密碼——done。接下來(lái)就可以開(kāi)始進(jìn)入“正餐”環(huán)節(jié),為了能讓大家使用該平臺(tái),原作者和 Kaggle 競(jìng)賽聯(lián)合起來(lái),讓大家可以邊學(xué)邊用。

具體步驟示例
0、獲取數(shù)據(jù)集
模型預(yù)訓(xùn)練中要使用的數(shù)據(jù)集是 FSDKaggle 2019,已經(jīng)在 Peltarion 平臺(tái)經(jīng)過(guò)預(yù)處理,所以音頻文件經(jīng)過(guò)轉(zhuǎn)化,與 index.csv 一起保存為 Numpy 文件格式,所以,大家直接下載 dataset.zip 即可。
下載地址:
https://www.kaggle.com/carlthome/preprocess-freesound-data-to-train-with-peltarion/output

1、Project:一鍵創(chuàng)建
直接 New 一鍵即可建立一個(gè)新 project,可以保存為“project v1”。

2、數(shù)據(jù)集:Upload 或者 Import
新建的 project v1 在左側(cè)就可以看到,點(diǎn)擊 Datasets → New dataset 就可以上傳數(shù)據(jù)集。然后選擇剛剛下載的數(shù)據(jù)集,等待上傳,最后命名保存為“Audio”。

默認(rèn) 80%的數(shù)據(jù)集作為訓(xùn)練集,其余20% 用于測(cè)試集。在頂部的 New feature set進(jìn)行捆綁,除 fname 外所有的功能,保存為“Lable”。右上角保存 version 后,就可以進(jìn)一步建模了。

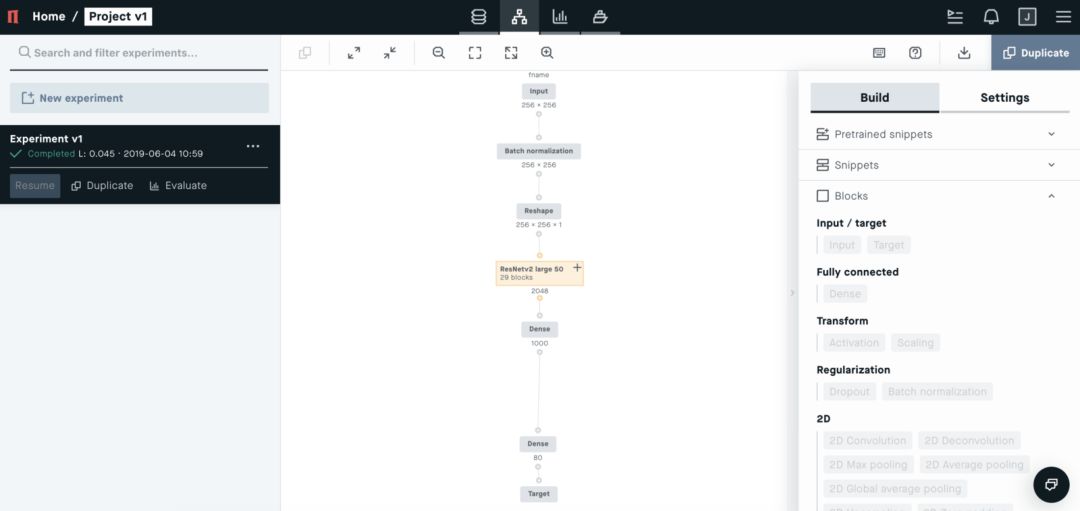
3、Modeling:一鍵創(chuàng)建深度學(xué)習(xí)項(xiàng)目
New Experiment 后進(jìn)入 Modeling 界面,你可以在右側(cè)看到“Build”和“Settings”兩個(gè)工具選項(xiàng)幫助進(jìn)行編譯模型。在這個(gè)示例中,訓(xùn)練的是如下圖所示的聲譜圖,以完成圖片分類(lèi)任務(wù)。
在該任務(wù)中,我們可以選擇 CNN 網(wǎng)絡(luò)模型,比如 ResNetv2 large 50。(右側(cè) Build-Snippets 中,有一些不同任務(wù)的模型可供選擇。)
接下來(lái)幾個(gè)步驟中,我們就在右側(cè)欄中設(shè)定模型的關(guān)鍵配置:

(1)在 Blocks 中添加 Input,F(xiàn)eature 選擇為 fname;
(2)添加 Batch normalization,勾選 Trainable;
(3)添加 Reshape,設(shè)置 Target Shape 為(256,256,1);
(4)在 Snippets 中添加 ResNetv2 large 50;
(5)單擊并刪除 ResNetv2 large 50 頂部“Input” 模塊;
(6)將 BN 塊連接到 ResNetv2 large 50 上
(7)更改 Dense 塊 中 Activation 為 ReLU,ReLU 經(jīng)常在模型中被選為激活函數(shù);
(8)在 Target 塊 之前再添加一個(gè) Dense 塊,節(jié)點(diǎn)設(shè)置為 80,激活 sigmoid;
(9)將 Target塊 的 Feature 改為 Lable,Loss 為 Binary crossentropy;
(10)跳轉(zhuǎn)到 Settings 選項(xiàng)卡,配置模型的步長(zhǎng)、epoch、優(yōu)化器等;Batch 設(shè)為 28,適合 GPU 內(nèi)存、epoch 設(shè)為 30,模型足以收斂、Optimizer 選為 Adam,這是一個(gè)很常用的標(biāo)準(zhǔn)優(yōu)化器;
(11)上面的配置都完成后,點(diǎn)擊 RUN 就可以讓模型跑起來(lái)了。

4、Evaluating
模型訓(xùn)練后,我們還需要對(duì)模型進(jìn)行評(píng)估,在 Evaluating 界面,可以看到模型訓(xùn)練的實(shí)時(shí)數(shù)據(jù),我們關(guān)注的指標(biāo)是 Precision 和 Recall。模型訓(xùn)練完成后,可以直接下載,如果訓(xùn)練了多個(gè)模型,記得下載模型精度最高的。

5、提交模型

首先,進(jìn)入競(jìng)賽頁(yè)面。點(diǎn)擊 New Kernel 連接到 Notebook,將下載的模型 H5 文件作為數(shù)據(jù)集添加。溫馨提示:要使用正確的 H5 文件路徑,添加下面這行代碼到 Kaggle notebook 中運(yùn)行,此處注意保存路徑,后面會(huì)用到。
!find../input-name'*.h5'
下面這段代碼可以直接復(fù)制-粘貼到 Kaggle notebook 中;將模型變量路徑更改為前面保存的路徑,最后點(diǎn)擊 Commit,完成。
import numpy as npimport pandas as pdimport librosa as lrimport tensorflow as tffrom tqdm import tqdmmodel = tf.keras.models.load_model('../input/freesound-audio-tagging-2019-model/resnet50.h5', compile=False) ##Changedf = pd.read_csv('../input/freesound-audio-tagging-2019/sample_submission.csv', index_col='fname') ##Changedef preprocess(wavfile): # Load roughly 8 seconds of audio. samples = 512*256 - 1 samplerate = 16000 waveform = lr.load(wavfile, samplerate, duration=samples/samplerate)[0] # Loop too short audio clips. if len(waveform) < samples: waveform = np.pad(waveform, (0, samples - len(waveform)), mode='wrap') # Convert audio to log-mel spectrogram. spectrogram = lr.feature.melspectrogram(waveform, samplerate, n_mels=256) spectrogram = lr.power_to_db(spectrogram) spectrogram = spectrogram.astype(np.float32) return spectrogramfor fname, scores in tqdm(df.iterrows(), total=len(df), desc='Predicting'): spectrogram = preprocess('../input/freesound-audio-tagging-2019/test/' + fname) scores = model.predict_on_batch(spectrogram[None, ...])[0] df.loc[fname] = scoresdf.to_csv('submission.csv')
競(jìng)賽地址:
https://www.kaggle.com/c/freesound-audio-tagging-2019
通過(guò)上面的示例,大家也發(fā)現(xiàn)了,訓(xùn)練模型的每一個(gè)步驟都在平臺(tái)上內(nèi)置好了,大家只需要托拉拽,勾勾選選的操作就可以訓(xùn)練你的模型了,另外還有一些免費(fèi)的 GPU 資源、內(nèi)存使用。對(duì)于代碼不會(huì)寫(xiě),框架不會(huì)寫(xiě)的你們來(lái)說(shuō)簡(jiǎn)直不要太好用!營(yíng)長(zhǎng)的模型要準(zhǔn)備跑起來(lái)了,你們的呢?
-
AI
+關(guān)注
關(guān)注
87文章
31053瀏覽量
269393 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1208瀏覽量
24729 -
訓(xùn)練模型
+關(guān)注
關(guān)注
1文章
36瀏覽量
3865
原文標(biāo)題:不寫(xiě)一行代碼,也能玩轉(zhuǎn)Kaggle競(jìng)賽?
文章出處:【微信號(hào):rgznai100,微信公眾號(hào):rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
中碳登一行到訪中汽中心
TFP401AMP第一行丟失4個(gè)像素是什么原因?qū)е碌模?/a>
ADS5404EVM 和TSW1400EVM一起使用就可以開(kāi)發(fā)嗎?
泰國(guó)國(guó)家石油一行到訪商湯科技
政府關(guān)懷 | 省、市、區(qū)領(lǐng)導(dǎo)干部一行蒞臨鑫金暉進(jìn)行參觀調(diào)研

中國(guó)中車(chē)與中國(guó)電信一行座談交流
TAS5782用三線的IIC. LRCK/FS,SCLK,SDIN是否就可以不用接入MCLK實(shí)現(xiàn)倍頻?
軟通動(dòng)力領(lǐng)導(dǎo)一行訪問(wèn)福州大學(xué)
RIMAC與IMD一行來(lái)訪聲揚(yáng)科技,共話AI語(yǔ)音賦能產(chǎn)業(yè)升級(jí)







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論