 回顧3年來的所有主流深度學習CTR模型
回顧3年來的所有主流深度學習CTR模型
今天我們一起回顧一下近3年來的所有主流深度學習CTR模型,也是我工作之余的知識總結,希望能幫大家梳理推薦系統、計算廣告領域在深度學習方面的前沿進展。
隨著微軟的Deep Crossing,Google的Wide&Deep,以及FNN,PNN等一大批優秀的深度學習CTR預估模型在2016年被提出,計算廣告和推薦系統領域全面進入了深度學習時代,時至今日,深度學習CTR模型已經成為廣告和推薦領域毫無疑問的主流。在進入深度學習時代之后,CTR模型不僅在表達能力、模型效果上有了質的提升,而且大量借鑒并融合了深度學習在圖像、語音以及自然語言處理方向的成果,在模型結構上進行了快速的演化。
本文總結了廣告、推薦領域最為流行的10個深度學習CTR模型的結構特點,構建了它們之間的演化圖譜。選擇模型的標準盡量遵循下面三個原則:
模型的在業界影響力較大的;
工程導向的,而不是僅用實驗數據驗證或學術創新用的。
下面首先列出這張深度學習CTR模型的演化圖譜,再對其進行逐一介紹:
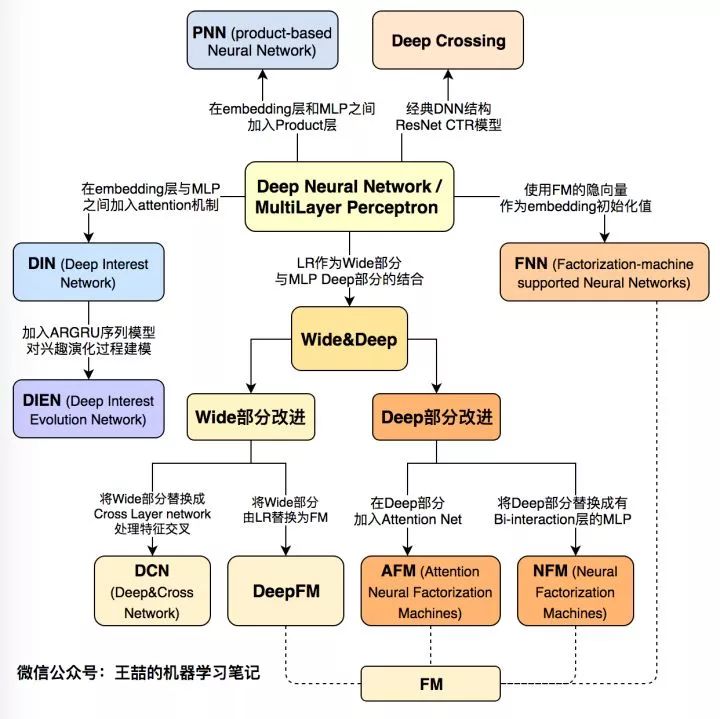
圖1 深度學習CTR模型演化圖譜
一、微軟Deep Crossing(2016年)——深度學習CTR模型的base model
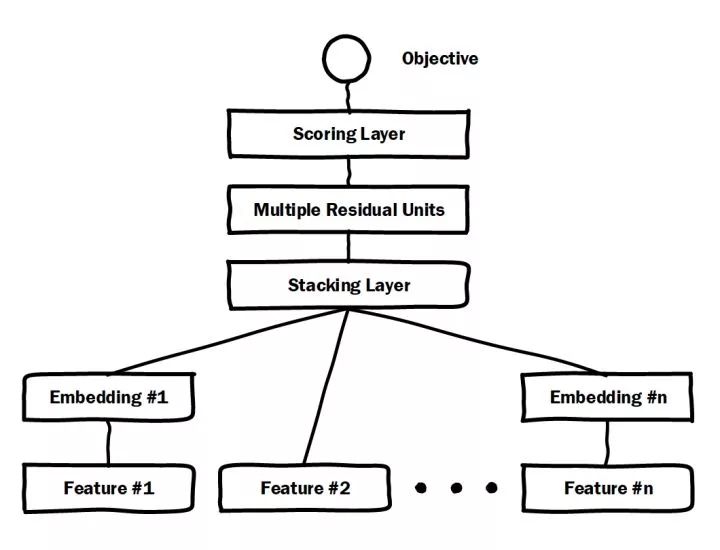
圖2 微軟Deep Crossing模型架構圖
微軟于2016年提出的Deep Crossing可以說是深度學習CTR模型的最典型和基礎性的模型。如圖2的模型結構圖所示,它涵蓋了深度CTR模型最典型的要素,即通過加入embedding層將稀疏特征轉化為低維稠密特征,用stacking layer,或者叫做concat layer將分段的特征向量連接起來,再通過多層神經網絡完成特征的組合、轉換,最終用scoring layer完成CTR的計算。跟經典DNN有所不同的是,Deep crossing采用的multilayer perceptron是由殘差網絡組成的,這無疑得益于MSRA著名研究員何愷明提出的著名的152層ResNet。
論文:[Deep Crossing] Deep Crossing - Web-Scale Modeling without Manually Crafted Combinatorial Features (Microsoft 2016)
二、FNN(2016年)——用FM的隱向量完成Embedding初始化
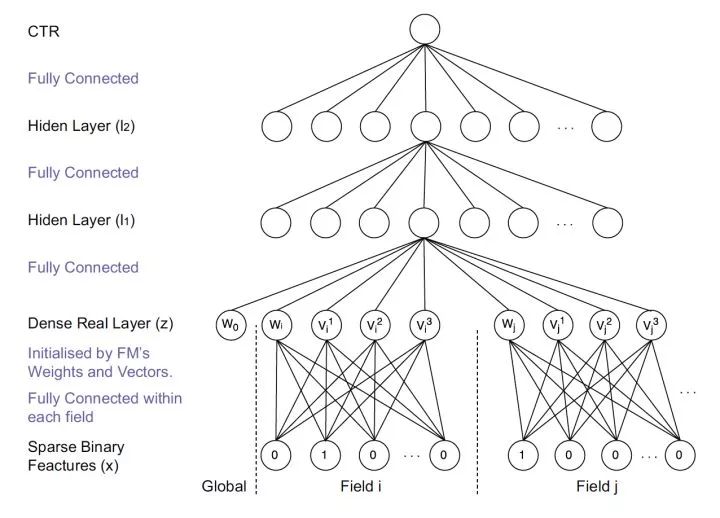
圖3 FNN模型架構圖
FNN相比Deep Crossing的創新在于使用FM的隱層向量作為user和item的Embedding,從而避免了完全從隨機狀態訓練Embedding。由于id類特征大量采用one-hot的編碼方式,導致其維度極大,向量極稀疏,所以Embedding層與輸入層的連接極多,梯度下降的效率很低,這大大增加了模型的訓練時間和Embedding的不穩定性,使用pre train的方法完成Embedding層的訓練,無疑是降低深度學習模型復雜度和訓練不穩定性的有效工程經驗。
論文:[FNN] Deep Learning over Multi-field Categorical Data (UCL 2016)
三、PNN (2016年)——豐富特征交叉的方式
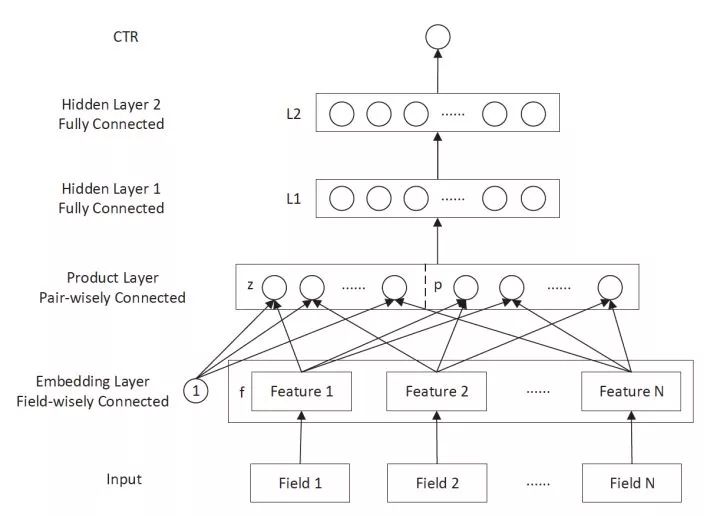
圖4 PNN模型架構圖
PNN的全稱是Product-based Neural Network,PNN的關鍵在于在embedding層和全連接層之間加入了Product layer。傳統的DNN是直接通過多層全連接層完成特征的交叉和組合的,但這樣的方式缺乏一定的“針對性”。首先全連接層并沒有針對不同特征域之間進行交叉;其次,全連接層的操作也并不是直接針對特征交叉設計的。但在實際問題中,特征交叉的重要性不言而喻,比如年齡與性別的交叉是非常重要的分組特征,包含了大量高價值的信息,我們急需深度學習網絡能夠有針對性的結構能夠表征這些信息。因此PNN通過加入Product layer完成了針對性的特征交叉,其product操作在不同特征域之間進行特征組合。并定義了inner product,outer product等多種product的操作捕捉不同的交叉信息,增強模型表征不同數據模式的能力 。
論文:[PNN] Product-based Neural Networks for User Response Prediction (SJTU 2016)
四、Google Wide&Deep(2016年)——記憶能力和泛化能力的綜合權衡
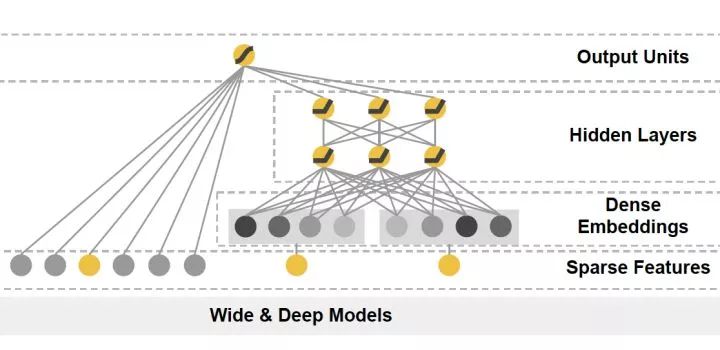
圖5 Google Wide&Deep模型架構圖
Google Wide&Deep模型的主要思路正如其名,把單輸入層的Wide部分和經過多層感知機的Deep部分連接起來,一起輸入最終的輸出層。其中Wide部分的主要作用是讓模型具有記憶性(Memorization),單層的Wide部分善于處理大量稀疏的id類特征,便于讓模型直接“記住”用戶的大量歷史信息;Deep部分的主要作用是讓模型具有“泛化性”(Generalization),利用DNN表達能力強的特點,挖掘藏在特征后面的數據模式。最終利用LR輸出層將Wide部分和Deep部分組合起來,形成統一的模型。Wide&Deep對之后模型的影響在于——大量深度學習模型采用了兩部分甚至多部分組合的形式,利用不同網絡結構挖掘不同的信息后進行組合,充分利用和結合了不同網絡結構的特點。
論文:[Wide&Deep] Wide & Deep Learning for Recommender Systems (Google 2016)
五、華為 DeepFM (2017年)——用FM代替Wide部分
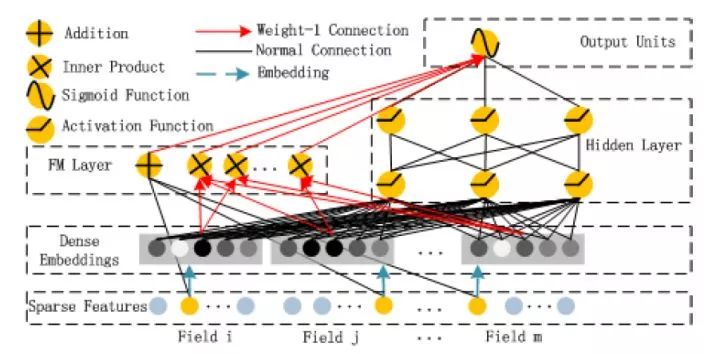
圖6 華為DeepFM模型架構圖
在Wide&Deep之后,諸多模型延續了雙網絡組合的結構,DeepFM就是其中之一。DeepFM對Wide&Deep的改進之處在于,它用FM替換掉了原來的Wide部分,加強了淺層網絡部分特征組合的能力。事實上,由于FM本身就是由一階部分和二階部分組成的,DeepFM相當于同時組合了原Wide部分+二階特征交叉部分+Deep部分三種結構,無疑進一步增強了模型的表達能力。
論文:[DeepFM] A Factorization-Machine based Neural Network for CTR Prediction (HIT-Huawei 2017)
六、Google Deep&Cross(2017年)——使用Cross網絡代替Wide部分
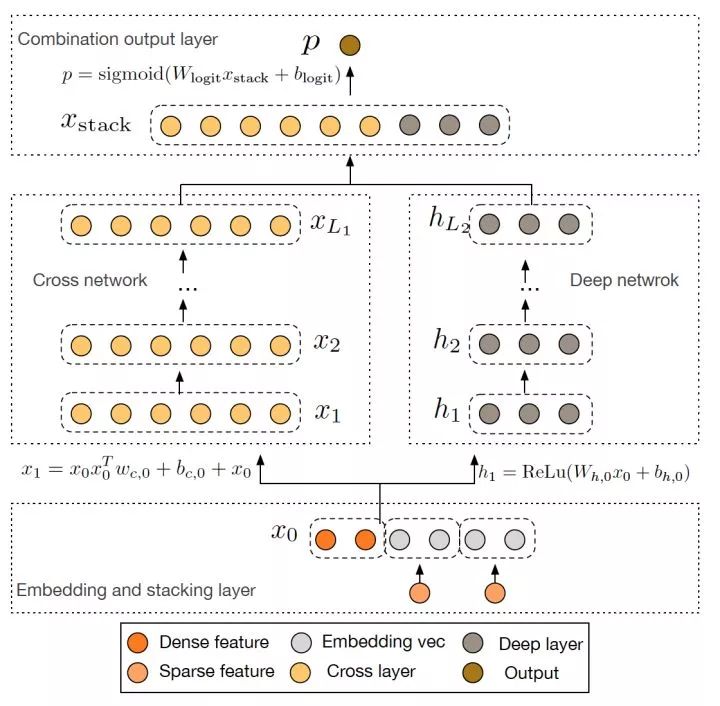
圖7 Google Deep Cross Network模型架構圖
Google 2017年發表的Deep&Cross Network(DCN)同樣是對Wide&Deep的進一步改進,主要的思路使用Cross網絡替代了原來的Wide部分。其中設計Cross網絡的基本動機是為了增加特征之間的交互力度,使用多層cross layer對輸入向量進行特征交叉。單層cross layer的基本操作是將cross layer的輸入向量xl與原始的輸入向量x0進行交叉,并加入bias向量和原始xl輸入向量。DCN本質上還是對Wide&Deep Wide部分表達能力不足的問題進行改進,與DeepFM的思路非常類似。
論文:[DCN] Deep & Cross Network for Ad Click Predictions (Stanford 2017)
七、NFM(2017年)——對Deep部分的改進
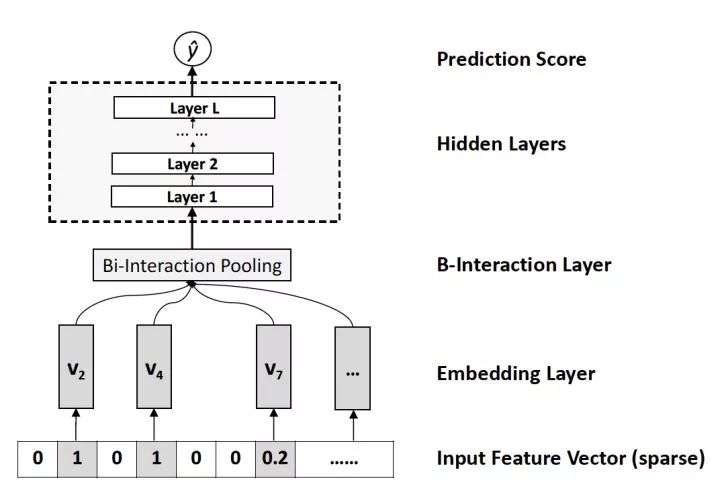
圖8 NFM的深度網絡部分模型架構圖
相對于DeepFM和DCN對于Wide&Deep Wide部分的改進,NFM可以看作是對Deep部分的改進。NFM的全稱是Neural Factorization Machines,如果我們從深度學習網絡架構的角度看待FM,FM也可以看作是由單層LR與二階特征交叉組成的Wide&Deep的架構,與經典W&D的不同之處僅在于Deep部分變成了二階隱向量相乘的形式。再進一步,NFM從修改FM二階部分的角度出發,用一個帶Bi-interaction Pooling層的DNN替換了FM的特征交叉部分,形成了獨特的Wide&Deep架構。其中Bi-interaction Pooling可以看作是不同特征embedding的element-wise product的形式。這也是NFM相比Google Wide&Deep的創新之處。
論文:[NFM] Neural Factorization Machines for Sparse Predictive Analytics (NUS 2017)
八、AFM(2017年)——引入Attention機制的FM
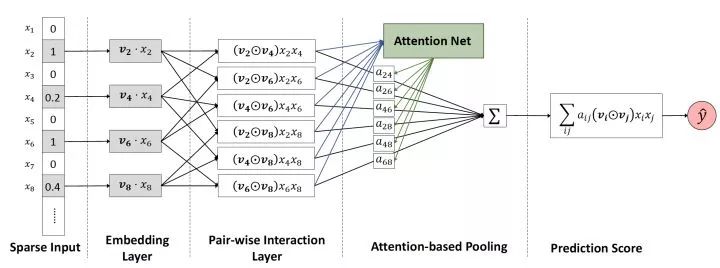
圖9 AFM模型架構圖
AFM的全稱是Attentional Factorization Machines,通過前面的介紹我們很清楚的知道,FM其實就是經典的Wide&Deep結構,其中Wide部分是FM的一階部分,Deep部分是FM的二階部分,而AFM顧名思義,就是引入Attention機制的FM,具體到模型結構上,AFM其實是對FM的二階部分的每個交叉特征賦予了權重,這個權重控制了交叉特征對最后結果的影響,也就非常類似于NLP領域的注意力機制(Attention Mechanism)。為了訓練Attention權重,AFM加入了Attention Net,利用Attention Net訓練好Attention權重后,再反向作用于FM二階交叉特征之上,使FM獲得根據樣本特點調整特征權重的能力。
論文:[AFM] Attentional Factorization Machines - Learning the Weight of Feature Interactions via Attention Networks (ZJU 2017)
九、阿里DIN(2018年)——阿里加入Attention機制的深度學習網絡
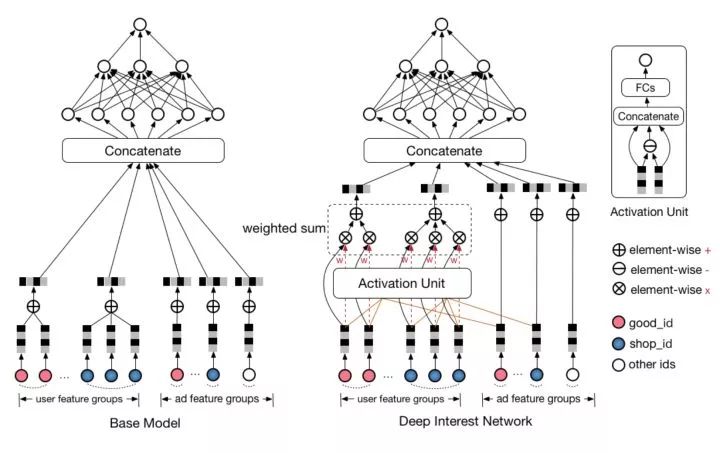
圖10 阿里DIN模型與Base模型的架構圖
AFM在FM中加入了Attention機制,2018年,阿里巴巴正式提出了融合了Attention機制的深度學習模型——Deep Interest Network。與AFM將Attention與FM結合不同的是,DIN將Attention機制作用于深度神經網絡,在模型的embedding layer和concatenate layer之間加入了attention unit,使模型能夠根據候選商品的不同,調整不同特征的權重。
論文:[DIN] Deep Interest Network for Click-Through Rate Prediction (Alibaba 2018)
十、阿里DIEN(2018年)——DIN的“進化”
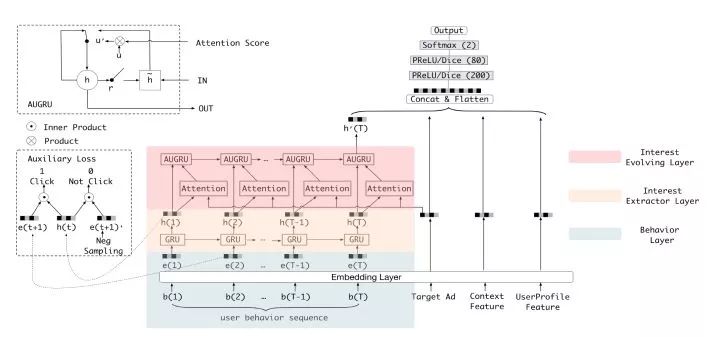
阿里DIEN模型架構圖
DIEN的全稱為Deep Interest Evolution Network,它不僅是對DIN的進一步“進化”,更重要的是DIEN通過引入序列模型 AUGRU模擬了用戶興趣進化的過程。具體來講模型的主要特點是在Embedding layer和Concatenate layer之間加入了生成興趣的Interest Extractor Layer和模擬興趣演化的Interest Evolving layer。其中Interest Extractor Layer使用了DIN的結構抽取了每一個時間片內用戶的興趣,Interest Evolving layer則利用序列模型AUGRU的結構將不同時間的用戶興趣串聯起來,形成興趣進化的鏈條。最終再把當前時刻的“興趣向量”輸入上層的多層全連接網絡,與其他特征一起進行最終的CTR預估。
論文:[DIEN] Deep Interest Evolution Network for Click-Through Rate Prediction (Alibaba 2019)
總結—— CTR模型的深度學習時代
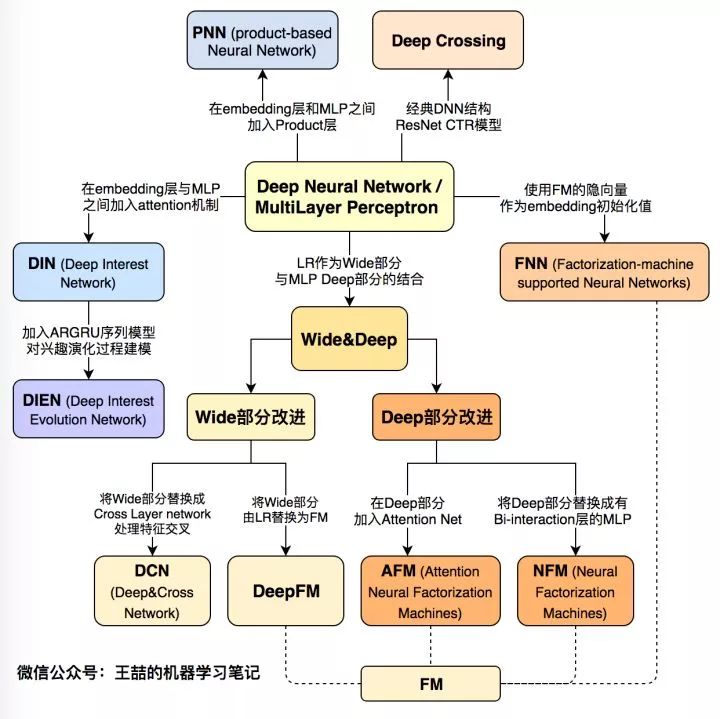
文章的最后,我再次強調這張深度學習CTR模型演化圖,可以毫不夸張的說,這張演化圖包括了近年來所有主流的深度學習CTR模型的結構特點以及它們之間的演化關系。希望能夠幫助推薦、廣告、搜索領域的算法工程師們建立起完整的知識體系,能夠駕輕就熟的針對業務特點應用并比較不同模型的效果,從而用最適合當前數據模式的模型驅動公司業務。
結合自己的工作經驗,關于深度學習模型我想再分享兩點內容:
沒有銀彈。從來沒有一個深度學習模型能夠在所有數據集上都表現最優,特別是推薦、廣告領域,各家的數據集,數據pattern、業務領域差異巨大,不存在能夠解決一切問題的“銀彈”模型。比如,阿里的DIEN對于數據質量、用戶整個life cycle行為完整性的要求很高,如果在某些DSP場景下運用這個模型,預計不會收到良好的效果。再比如Google 的Deep&Cross,我們也要考慮自己的數據集需不需要如此復雜的特征交叉方式,在一些百萬量級的數據集上,也許淺層神經網絡的表現更好。
算法工程師永遠要在理想和現實間做trade off。有一種思想要避免,就是我為了要上某個模型就要強轉團隊的技術棧,強買某些硬件設備。模型的更新過程一定是迭代的,一定是從簡單到復雜的,一定是你證明了某個模型是work的,然后在此基礎上做改進的。這也是我們要熟悉所有模型演化關系的原因。
就在我們熟悉這些已有模型的時候,深度學習CTR模型的發展從沒有停下它的腳步。從阿里的多模態、多目標的深度學習模型,到YouTube基于RNN等序列模型的推薦系統,再到Airbnb使用Embedding技術構建的搜索推薦模型,深度學習的應用不僅越來越廣泛,而且得到了越來越快的進化。在今后的專欄文章中,我們不僅會更深入的介紹深度學習CTR模型的知識,而且會更加關注深度學習CTR模型的應用與落地,期待與大家一同學習。
-
微軟
+關注
關注
4文章
6590瀏覽量
104025 -
互聯網
+關注
關注
54文章
11148瀏覽量
103233 -
深度學習
+關注
關注
73文章
5500瀏覽量
121112
原文標題:谷歌、阿里們的殺手锏:三大領域,十大深度學習CTR模型演化圖譜
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
目前主流的深度學習算法模型和應用案例

2017全國深度學習技術應用大會
Nanopi深度學習之路(1)深度學習框架分析
深度學習在計算機視覺領域圖像應用總結 精選資料下載
什么是深度學習?使用FPGA進行深度學習的好處?
實例分析深度學習在廣告搜索中的應用

Scale API支持所有主流傳感器的高級3D感知
阿里深度學習:在深度學習CTR預估核心問題上的應用進展

深度學習如何訓練出好的模型






 工商網監
工商網監
評論