


前言
本文全長 14237 字,配有 70 張圖片和動畫,和你一起一步步看懂排序算法的運行過程。
預計閱讀時間 47 分鐘,強烈建議先收藏然后通過電腦端進行閱讀。
No.1 冒泡排序
冒泡排序無疑是最為出名的排序算法之一,從序列的一端開始往另一端冒泡(你可以從左往右冒泡,也可以從右往左冒泡,看心情),依次比較相鄰的兩個數的大小(到底是比大還是比小也看你心情)。

冒泡排序動圖演示
▌圖解冒泡排序
以 [ 8,2,5,9,7 ] 這組數字來做示例,上圖來戰:
從左往右依次冒泡,將小的往右移動
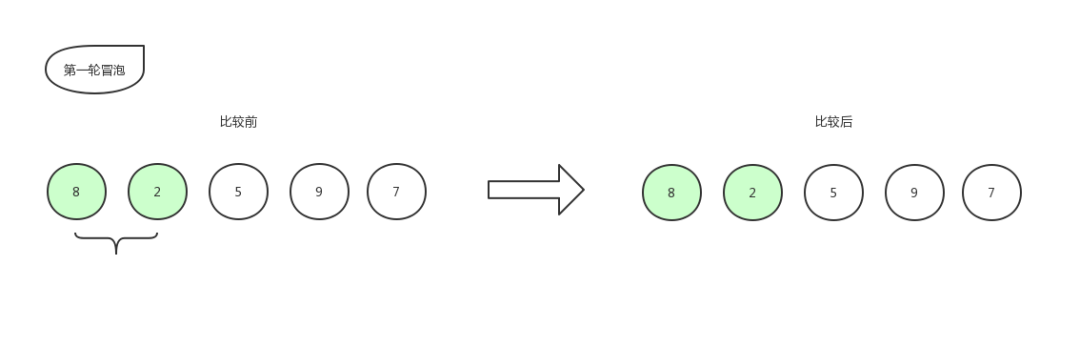
冒泡排序1
首先比較第一個數和第二個數的大小,我們發現 2 比 8 要小,那么保持原位,不做改動。位置還是 8,2,5,9,7 。
指針往右移動一格,接著比較:

冒泡排序2
比較第二個數和第三個數的大小,發現 2 比 5 要小,所以位置交換,交換后數組更新為:[ 8,5,2,9,7 ]。
指針再往右移動一格,繼續比較:

冒泡排序3
比較第三個數和第四個數的大小,發現 2 比 9 要小,所以位置交換,交換后數組更新為:[ 8,5,9,2,7 ]
同樣,指針再往右移動,繼續比較:

冒泡排序4
比較第 4 個數和第 5 個數的大小,發現 2 比 7 要小,所以位置交換,交換后數組更新為:[ 8,5,9,7,2 ]
下一步,指針再往右移動,發現已經到底了,則本輪冒泡結束,處于最右邊的 2 就是已經排好序的數字。
通過這一輪不斷的對比交換,數組中最小的數字移動到了最右邊。
接下來繼續第二輪冒泡:

冒泡排序5

冒泡排序6

冒泡排序7
由于右邊的 2 已經是排好序的數字,就不再參與比較,所以本輪冒泡結束,本輪冒泡最終冒到頂部的數字 5 也歸于有序序列中,現在數組已經變化成了[ 8,9,7,5,2 ]。

冒泡排序8
讓我們開始第三輪冒泡吧!

冒泡排序9

冒泡排序10
由于 8 比 7 大,所以位置不變,此時第三輪冒泡也已經結束,第三輪冒泡的最后結果是[ 9,8,7,5,2 ]
緊接著第四輪冒泡:

冒泡排序11
9 和 8 比,位置不變,即確定了 8 進入有序序列,那么最后只剩下一個數字 9 ,放在末尾,自此排序結束。
▌代碼實現
public static void sort(int arr[]){ for( int i = 0 ; i < arr.length - 1 ; i++ ){ for(int j = 0;j < arr.length - 1 - i ; j++){ int temp = 0; if(arr[j] < arr[j + 1]){ temp = arr[j]; arr[j] = arr[j + 1]; arr[j + 1] = temp; } } }}
冒泡的代碼還是相當簡單的,兩層循環,外層冒泡輪數,里層依次比較,江湖中人人盡皆知。
我們看到嵌套循環,應該立馬就可以得出這個算法的時間復雜度為O(n2)。
▌冒泡優化
冒泡有一個最大的問題就是這種算法不管不管你有序還是沒序,閉著眼睛把你循環比較了再說。
比如我舉個數組例子:[ 9,8,7,6,5 ],一個有序的數組,根本不需要排序,它仍然是雙層循環一個不少的把數據遍歷干凈,這其實就是做了沒必要做的事情,屬于浪費資源。
針對這個問題,我們可以設定一個臨時遍歷來標記該數組是否已經有序,如果有序了就不用遍歷了。
public static void sort(int arr[]){ for( int i = 0;i < arr.length - 1 ; i++ ){ boolean isSort = true; for( int j = 0;j < arr.length - 1 - i ; j++ ){ int temp = 0; if(arr[j] < arr[j + 1]){ temp = arr[j]; arr[j] = arr[j + 1]; arr[j + 1] = temp; isSort = false; } } if(isSort){ break; } }}
No.2選擇排序
選擇排序的思路是這樣的:首先,找到數組中最小的元素,拎出來,將它和數組的第一個元素交換位置,第二步,在剩下的元素中繼續尋找最小的元素,拎出來,和數組的第二個元素交換位置,如此循環,直到整個數組排序完成。
至于選大還是選小,這個都無所謂,你也可以每次選擇最大的拎出來排,也可以每次選擇最小的拎出來的排,只要你的排序的手段是這種方式,都叫選擇排序。

選擇排序動畫演示
▌圖解選擇排序
我們還是以[ 8,2,5,9,7 ]這組數字做例子。
第一次選擇,先找到數組中最小的數字 2 ,然后和第一個數字交換位置。(如果第一個數字就是最小值,那么自己和自己交換位置,也可以不做處理,就是一個 if 的事情)

選擇排序1
第二次選擇,由于數組第一個位置已經是有序的,所以只需要查找剩余位置,找到其中最小的數字5,然后和數組第二個位置的元素交換。
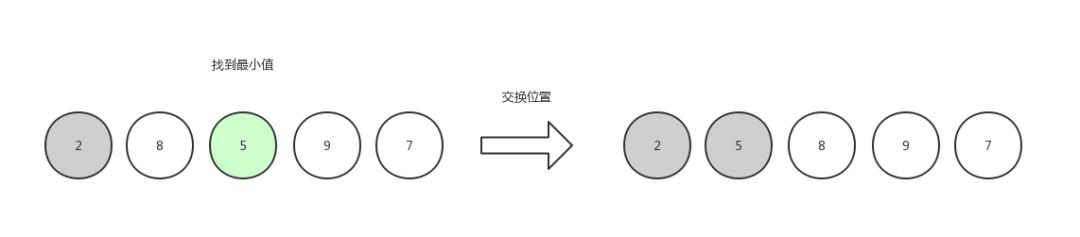
選擇排序2
第三次選擇,找到最小值 7 ,和第三個位置的元素交換位置。

選擇排序3
第四次選擇,找到最小值8,和第四個位置的元素交換位置。
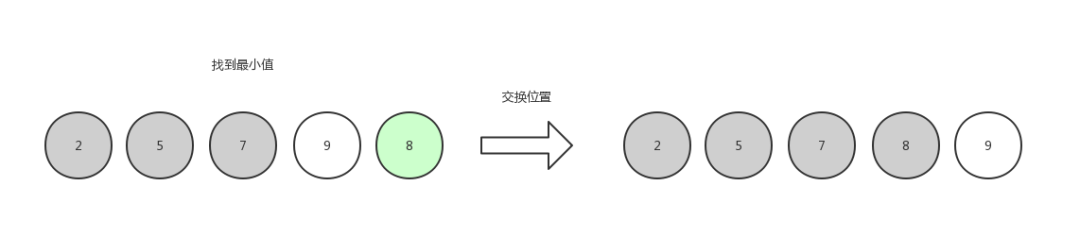
選擇排序4
最后一個到達了數組末尾,沒有可對比的元素,結束選擇。
如此整個數組就排序完成了。
▌代碼實現
public static void sort(int arr[]){ for( int i = 0;i < arr.length ; i++ ){ int min = i;//最小元素的下標 for(int j = i + 1;j < arr.length ; j++ ){ if(arr[j] < arr[min]){ min = j;//找最小值 } } //交換位置 int temp = arr[i]; arr[i] = arr[min]; arr[min] = temp; }}
雙層循環,時間復雜度和冒泡一模一樣,都是O(n2)。
No.3插入排序
插入排序的思想和我們打撲克摸牌的時候一樣,從牌堆里一張一張摸起來的牌都是亂序的,我們會把摸起來的牌插入到左手中合適的位置,讓左手中的牌時刻保持一個有序的狀態。
那如果我們不是從牌堆里摸牌,而是左手里面初始化就是一堆亂牌呢? 一樣的道理,我們把牌往手的右邊挪一挪,把手的左邊空出一點位置來,然后在亂牌中抽一張出來,插入到左邊,再抽一張出來,插入到左邊,再抽一張,插入到左邊,每次插入都插入到左邊合適的位置,時刻保持左邊的牌是有序的,直到右邊的牌抽完,則排序完畢。

插入排序動畫演示
▌圖解插入排序
數組初始化:[ 8,2,5,9,7 ],我們把數組中的數據分成兩個區域,已排序區域和未排序區域,初始化的時候所有的數據都處在未排序區域中,已排序區域是空。

插入排序1
第一輪,從未排序區域中隨機拿出一個數字,既然是隨機,那么我們就獲取第一個,然后插入到已排序區域中,已排序區域是空,那么就不做比較,默認自身已經是有序的了。(當然了,第一輪在代碼中是可以省略的,從下標為1的元素開始即可)
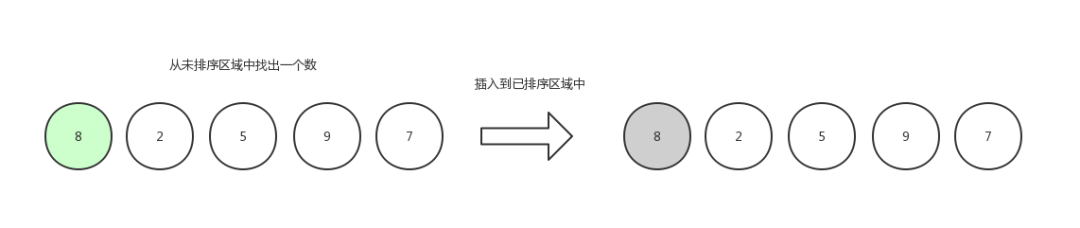
插入排序2
第二輪,繼續從未排序區域中拿出一個數,插入到已排序區域中,這個時候要遍歷已排序區域中的數字挨個做比較,比大比小取決于你是想升序排還是想倒序排,這里排升序:
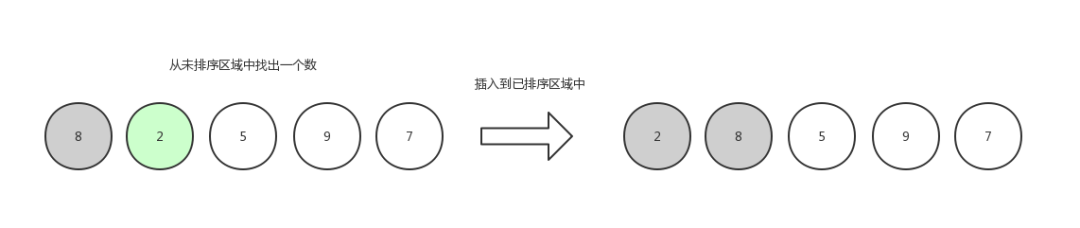
插入排序3
第三輪,排 5 :
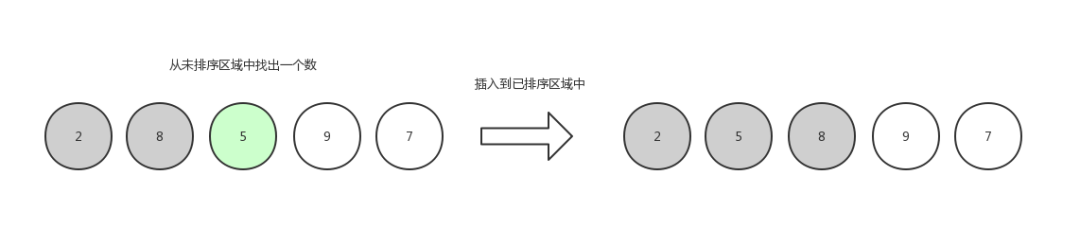
插入排序4
第四輪,排 9 :

插入排序5
第五輪,排 7

插入排序6
排序結束。
▌代碼實現
public static void sort(int[] arr) { int n = arr.length; for (int i = 1; i < n; ++i) { int value = arr[i]; int j = 0;//插入的位置 for (j = i-1; j >= 0; j--) { if (arr[j] > value) { arr[j+1] = arr[j];//移動數據 } else { break; } } arr[j+1] = value; //插入數據 }}
從代碼里我們可以看出,如果找到了合適的位置,就不會再進行比較了,就好比牌堆里抽出的一張牌本身就比我手里的牌都小,那么我只需要直接放在末尾就行了,不用一個一個去移動數據騰出位置插入到中間。
所以說,最好情況的時間復雜度是 O(n),最壞情況的時間復雜度是 O(n2),然而時間復雜度這個指標看的是最壞的情況,而不是最好的情況,所以插入排序的時間復雜度是 O(n2)。
No.4希爾排序
希爾排序這個名字,來源于它的發明者希爾,也稱作“縮小增量排序”,是插入排序的一種更高效的改進版本。
我們知道,插入排序對于大規模的亂序數組的時候效率是比較慢的,因為它每次只能將數據移動一位,希爾排序為了加快插入的速度,讓數據移動的時候可以實現跳躍移動,節省了一部分的時間開支。

希爾排序動畫演示
▌圖解希爾排序
待排序數組 10 個數據:

希爾排序1
假設計算出的排序區間為 4 ,那么我們第一次比較應該是用第 5 個數據與第 1 個數據相比較。

希爾排序2
調換后的數據為[ 7,2,5,9,8,10,1,15,12,3 ],然后指針右移,第 6 個數據與第 2 個數據相比較。

希爾排序3
指針右移,繼續比較。

希爾排序4

希爾排序5
如果交換數據后,發現減去區間得到的位置還存在數據,那么繼續比較,比如下面這張圖,12 和 8 相比較,原地不動后,指針從 12 跳到 8 身上,繼續減去區間發現前面還有一個下標為 0 的數據 7 ,那么 8 和 7 相比較。

希爾排序6
比較完之后的效果是 7,8,12 三個數為有序排列。
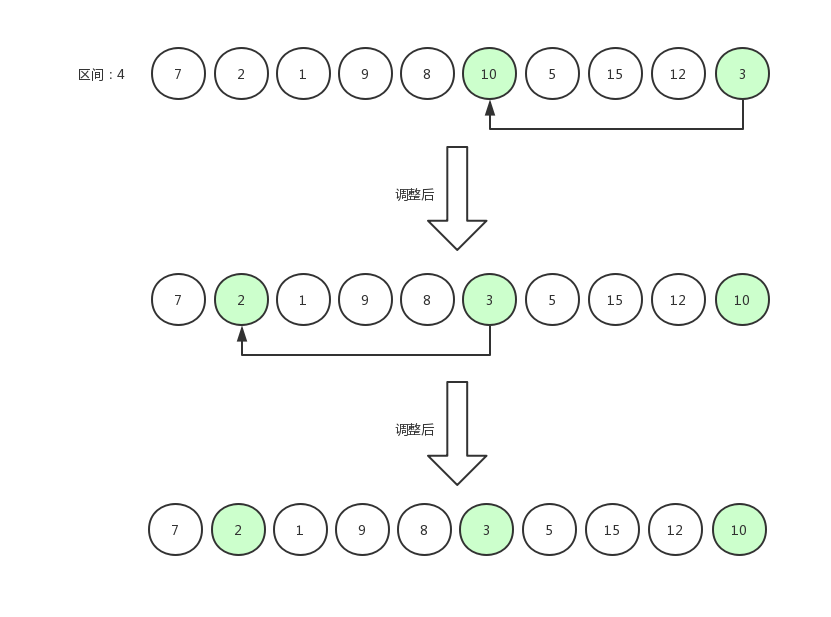
希爾排序7
當最后一個元素比較完之后,我們會發現大部分值比較大的數據都似乎調整到數組的中后部分了。
假設整個數組比較長的話,比如有 100 個數據,那么我們的區間肯定是四五十,調整后區間再縮小成一二十還會重新調整一輪,直到最后區間縮小為 1,就是真正的排序來了。

希爾排序8
指針右移,繼續比較:

希爾排序9
重復步驟,即可完成排序,重復的圖就不多畫了。
我們可以發現,當區間為 1 的時候,它使用的排序方式就是插入排序。
▌代碼實現
public static void sort(int[] arr) { int length = arr.length; //區間 int gap = 1; while (gap < length) { gap = gap * 3 + 1; } while (gap > 0) { for (int i = gap; i < length; i++) { int tmp = arr[i]; int j = i - gap; //跨區間排序 while (j >= 0 && arr[j] > tmp) { arr[j + gap] = arr[j]; j -= gap; } arr[j + gap] = tmp; } gap = gap / 3; }}
可能你會問為什么區間要以 gap = gap*3 + 1 去計算,其實最優的區間計算方法是沒有答案的,這是一個長期未解決的問題,不過差不多都會取在二分之一到三分之一附近。
No.5歸并排序
歸并字面上的意思是合并,歸并算法的核心思想是分治法,就是將一個數組一刀切兩半,遞歸切,直到切成單個元素,然后重新組裝合并,單個元素合并成小數組,兩個小數組合并成大數組,直到最終合并完成,排序完畢。

歸并排序動畫演示
▌圖解歸并排序
我們以[ 8,2,5,9,7 ]這組數字來舉例

歸并排序1
首先,一刀切兩半:

歸并排序2
再切:

歸并排序3
再切

歸并排序4
粒度切到最小的時候,就開始歸并

歸并排序5

歸并排序6

歸并排序7
數據量設定的比較少,是為了方便圖解,數據量為單數,是為了讓你看到細節,下面我畫了一張更直觀的圖可能你會更喜歡:

歸并排序8
▌代碼實現
我們上面講過,歸并排序的核心思想是分治,分而治之,將一個大問題分解成無數的小問題進行處理,處理之后再合并,這里我們采用遞歸來實現:
public static void sort(int[] arr) { int[] tempArr = new int[arr.length]; sort(arr, tempArr, 0, arr.length-1); } /** * 歸并排序 * @param arr 排序數組 * @param tempArr 臨時存儲數組 * @param startIndex 排序起始位置 * @param endIndex 排序終止位置 */ private static void sort(int[] arr,int[] tempArr,int startIndex,int endIndex){ if(endIndex <= startIndex){ return; } //中部下標 int middleIndex = startIndex + (endIndex - startIndex) / 2; //分解 sort(arr,tempArr,startIndex,middleIndex); sort(arr,tempArr,middleIndex + 1,endIndex); //歸并 merge(arr,tempArr,startIndex,middleIndex,endIndex); } /** * 歸并 * @param arr 排序數組 * @param tempArr 臨時存儲數組 * @param startIndex 歸并起始位置 * @param middleIndex 歸并中間位置 * @param endIndex 歸并終止位置 */ private static void merge(int[] arr, int[] tempArr, int startIndex, int middleIndex, int endIndex) { //復制要合并的數據 for (int s = startIndex; s <= endIndex; s++) { tempArr[s] = arr[s]; } int left = startIndex;//左邊首位下標 int right = middleIndex + 1;//右邊首位下標 for (int k = startIndex; k <= endIndex; k++) { if(left > middleIndex){ //如果左邊的首位下標大于中部下標,證明左邊的數據已經排完了。 arr[k] = tempArr[right++]; } else if (right > endIndex){ //如果右邊的首位下標大于了數組長度,證明右邊的數據已經排完了。 arr[k] = tempArr[left++]; } else if (tempArr[right] < tempArr[left]){ arr[k] = tempArr[right++];//將右邊的首位排入,然后右邊的下標指針+1。 } else { arr[k] = tempArr[left++];//將左邊的首位排入,然后左邊的下標指針+1。 } } }
我們可以發現 merge 方法中只有一個 for 循環,直接就可以得出每次合并的時間復雜度為 O(n) ,而分解數組每次對半切割,屬于對數時間 O(log n) ,合起來等于 O(log2n) ,也就是說,總的時間復雜度為 O(nlogn) 。
關于空間復雜度,其實大部分人寫的歸并都是在 merge 方法里面申請臨時數組,用臨時數組來輔助排序工作,空間復雜度為 O(n),而我這里做的是原地歸并,只在最開始申請了一個臨時數組,所以空間復雜度為 O(1)。
如果你對空間復雜度這一塊不太了解,可以查看小吳之前的數據結構系列文章---冰與火之歌:「時間」與「空間」復雜度。
No.6快速排序
快速排序的核心思想也是分治法,分而治之。它的實現方式是每次從序列中選出一個基準值,其他數依次和基準值做比較,比基準值大的放右邊,比基準值小的放左邊,然后再對左邊和右邊的兩組數分別選出一個基準值,進行同樣的比較移動,重復步驟,直到最后都變成單個元素,整個數組就成了有序的序列。
(周知:動圖里面的大于小于寫反,小吳修正重新錄制后,上傳新動圖到微信后臺卻一直失敗)

快速排序動畫演示
▌圖解快速排序
我們以[ 8,2,5,0,7,4,6,1 ]這組數字來進行演示
首先,我們隨機選擇一個基準值:

快速排序1
與其他元素依次比較,大的放右邊,小的放左邊:

快速排序2
然后我們以同樣的方式排左邊的數據:

快速排序3
繼續排 0 和 1 :

快速排序4
由于只剩下一個數,所以就不用排了,現在的數組序列是下圖這個樣子:

快速排序5
右邊以同樣的操作進行,即可排序完成。
▌單邊掃描
快速排序的關鍵之處在于切分,切分的同時要進行比較和移動,這里介紹一種叫做單邊掃描的做法。
我們隨意抽取一個數作為基準值,同時設定一個標記 mark 代表左邊序列最右側的下標位置,當然初始為 0 ,接下來遍歷數組,如果元素大于基準值,無操作,繼續遍歷,如果元素小于基準值,則把 mark + 1 ,再將 mark 所在位置的元素和遍歷到的元素交換位置,mark 這個位置存儲的是比基準值小的數據,當遍歷結束后,將基準值與 mark 所在元素交換位置即可。
▌代碼實現
public static void sort(int[] arr) { sort(arr, 0, arr.length - 1);}private static void sort(int[] arr, int startIndex, int endIndex) { if (endIndex <= startIndex) { return; } //切分 int pivotIndex = partitionV2(arr, startIndex, endIndex); sort(arr, startIndex, pivotIndex-1); sort(arr, pivotIndex+1, endIndex);}private static int partition(int[] arr, int startIndex, int endIndex) { int pivot = arr[startIndex];//取基準值 int mark = startIndex;//Mark初始化為起始下標 for(int i=startIndex+1; i<=endIndex; i++){ if(arr[i]
▌雙邊掃描
另外還有一種雙邊掃描的做法,看起來比較直觀:我們隨意抽取一個數作為基準值,然后從數組左右兩邊進行掃描,先從左往右找到一個大于基準值的元素,將下標指針記錄下來,然后轉到從右往左掃描,找到一個小于基準值的元素,交換這兩個元素的位置,重復步驟,直到左右兩個指針相遇,再將基準值與左側最右邊的元素交換。
我們來看一下實現代碼,不同之處只有 partition 方法:
public static void sort(int[] arr) { sort(arr, 0, arr.length - 1);}private static void sort(int[] arr, int startIndex, int endIndex) { if (endIndex <= startIndex) { return; } //切分 int pivotIndex = partition(arr, startIndex, endIndex); sort(arr, startIndex, pivotIndex-1); sort(arr, pivotIndex+1, endIndex);}private static int partition(int[] arr, int startIndex, int endIndex) { int left = startIndex; int right = endIndex; int pivot = arr[startIndex];//取第一個元素為基準值 while (true) { //從左往右掃描 while (arr[left] <= pivot) { left++; if (left == right) { break; } } //從右往左掃描 while (pivot < arr[right]) { right--; if (left == right) { break; } } //左右指針相遇 if (left >= right) { break; } //交換左右數據 int temp = arr[left]; arr[left] = arr[right]; arr[right] = temp; } //將基準值插入序列 int temp = arr[startIndex]; arr[startIndex] = arr[right]; arr[right] = temp; return right;}
▌極端情況
快速排序的時間復雜度和歸并排序一樣,O(n log n),但這是建立在每次切分都能把數組一刀切兩半差不多大的前提下,如果出現極端情況,比如排一個有序的序列,如[ 9,8,7,6,5,4,3,2,1 ],選取基準值 9 ,那么需要切分 n - 1 次才能完成整個快速排序的過程,這種情況下,時間復雜度就退化成了 O(n2),當然極端情況出現的概率也是比較低的。
所以說,快速排序的時間復雜度是 O(nlogn),極端情況下會退化成 O(n2),為了避免極端情況的發生,選取基準值應該做到隨機選取,或者是打亂一下數組再選取。
另外,快速排序的空間復雜度為 O(1)。
No.7堆排序
堆排序顧名思義,是利用堆這種數據結構來進行排序的算法。
如果你不了解堆這種數據結構,可以查看小吳之前的數據結構系列文章---看動畫輕松理解堆
如果你了解堆這種數據結構,你應該知道堆是一種優先隊列,兩種實現,最大堆和最小堆,由于我們這里排序按升序排,所以就直接以最大堆來說吧。
我們完全可以把堆(以下全都默認為最大堆)看成一棵完全二叉樹,但是位于堆頂的元素總是整棵樹的最大值,每個子節點的值都比父節點小,由于堆要時刻保持這樣的規則特性,所以一旦堆里面的數據發生變化,我們必須對堆重新進行一次構建。
既然堆頂元素永遠都是整棵樹中的最大值,那么我們將數據構建成堆后,只需要從堆頂取元素不就好了嗎? 第一次取的元素,是否取的就是最大值?取完后把堆重新構建一下,然后再取堆頂的元素,是否取的就是第二大的值? 反復的取,取出來的數據也就是有序的數據。

堆排序動畫演示
▌圖解堆排序
我們以[ 8,2,5,9,7,3 ]這組數據來演示。
首先,將數組構建成堆。

堆排序1
既然構建成堆結構了,那么接下來,我們取出堆頂的數據,也就是數組第一個數 9 ,取法是將數組的第一位和最后一位調換,然后將數組的待排序范圍 -1。
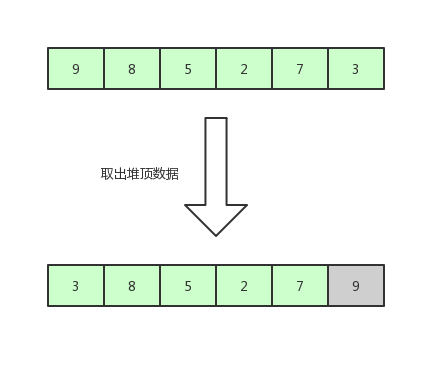
堆排序2
現在的待排序數據是[ 3,8,5,2,7 ],我們繼續將待排序數據構建成堆。

堆排序3
取出堆頂數據,這次就是第一位和倒數第二位交換了,因為待排序的邊界已經減 1 。
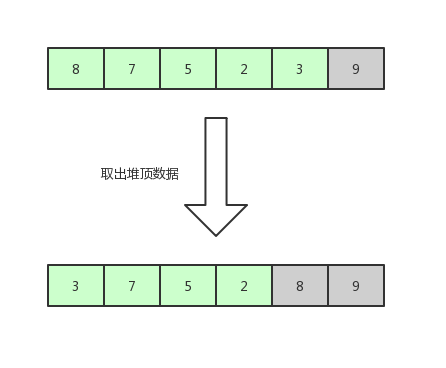
堆排序4
繼續構建堆

堆排序5
從堆頂取出來的數據最終形成一個有序列表,重復的步驟就不再贅述了,我們來看一下代碼實現。
▌代碼實現
public static void sort(int[] arr) { int length = arr.length; //構建堆 buildHeap(arr, length); for ( int i = length - 1; i > 0; i-- ) { //將堆頂元素與末位元素調換 int temp = arr[0]; arr[0] = arr[i]; arr[i] = temp; //數組長度-1 隱藏堆尾元素 length--; //將堆頂元素下沉 目的是將最大的元素浮到堆頂來 sink(arr, 0, length); }}private static void buildHeap(int[] arr, int length) { for (int i = length / 2; i >= 0; i--) { sink(arr, i, length); }}/** * 下沉調整 * @param arr 數組 * @param index 調整位置 * @param length 數組范圍 */private static void sink(int[] arr, int index, int length) { int leftChild = 2 * index + 1;//左子節點下標 int rightChild = 2 * index + 2;//右子節點下標 int present = index;//要調整的節點下標 //下沉左邊 if (leftChild < length && arr[leftChild] > arr[present]) { present = leftChild; } //下沉右邊 if (rightChild < length && arr[rightChild] > arr[present]) { present = rightChild; } //如果下標不相等 證明調換過了 if (present != index) { //交換值 int temp = arr[index]; arr[index] = arr[present]; arr[present] = temp; //繼續下沉 sink(arr, present, length); }}
堆排序和快速排序的時間復雜度都一樣是 O(nlogn)。
No.8計數排序
計數排序是一種非基于比較的排序算法,我們之前介紹的各種排序算法幾乎都是基于元素之間的比較來進行排序的,計數排序的時間復雜度為 O(n + m ),m 指的是數據量,說的簡單點,計數排序算法的時間復雜度約等于 O(n),快于任何比較型的排序算法。

計數排序動畫演示
▌圖解計數排序
以下以[ 3,5,8,2,5,4 ]這組數字來演示。
首先,我們找到這組數字中最大的數,也就是 8,創建一個最大下標為 8 的空數組 arr 。

計數排序1
遍歷數據,將數據的出現次數填入arr中對應的下標位置中。

計數排序2
遍歷 arr ,將數據依次取出即可。

計數排序3
▌代碼實現
public static void sort(int[] arr) { //找出數組中的最大值 int max = arr[0]; for (int i = 1; i < arr.length; i++) { if (arr[i] > max) { max = arr[i]; } } //初始化計數數組 int[] countArr = new int[max + 1]; //計數 for (int i = 0; i < arr.length; i++) { countArr[arr[i]]++; arr[i] = 0; } //排序 int index = 0; for (int i = 0; i < countArr.length; i++) { if (countArr[i] > 0) { arr[index++] = i; } }}
▌穩定排序
有一個需求就是當對成績進行排名次的時候,如何在原來排前面的人,排序后還是處于相同成績的人的前面。
解題的思路是對 countArr 計數數組進行一個變形,變來和名次掛鉤,我們知道 countArr 存放的是分數的出現次數,那么其實我們可以算出每個分數的最大名次,就是將 countArr 中的每個元素順序求和。
如下圖:

穩定排序
變形之后是什么意思呢?
我們把原數組[ 2,5,8,2,5,4 ]中的數據依次拿來去 countArr 去找,你會發現 3 這個數在 countArr[3] 中的值是 2 ,代表著排名第二名,(因為第一名是最小的 2,對吧?),5 這個數在 countArr[5] 中的值是 5 ,為什么是 5 呢?我們來數數,排序后的數組應該是[ 2,3,4,5,5,8 ],5 的排名是第五名,那 4 的排名是第幾名呢?對應 countArr[4] 的值是 3 ,第三名,5 的排名是第五名是因為 5 這個數有兩個,自然占據了第 4 名和第 5 名。
所以我們取排名的時候應該特別注意,原數組中的數據要從右往左取,從 countArr 取出排名后要把 countArr 中的排名減 1 ,以便于再次取重復數據的時候排名往前一位。
對應代碼實現:
public static void sort(int[] arr) { //找出數組中的最大值 int max = arr[0]; for (int i = 1; i < arr.length; ++i) { if (arr[i] > max) { max = arr[i]; } } //初始化計數數組 int[] countArr = new int[max + 1]; //計數 for (int i = 0; i < arr.length; ++i) { countArr[arr[i]]++; } //順序累加 for (int i = 1; i < max + 1; ++i) { countArr[i] = countArr[i-1] + countArr[i]; } //排序后的數組 int[] sortedArr = new int[arr.length]; //排序 for (int i = arr.length - 1; i >= 0; --i) { sortedArr[countArr[arr[i]]-1] = arr[i]; countArr[arr[i]]--; } //將排序后的數據拷貝到原數組 for (int i = 0; i < arr.length; ++i) { arr[i] = sortedArr[i]; }}
計數局限性
計數排序的毛病很多,我們來找找 bug 。
如果我要排的數據里有 0 呢? int[] 初始化內容全是 0 ,排毛線。
如果我要排的數據范圍比較大呢?比如[ 1,9999 ],我排兩個數你要創建一個 int[10000] 的數組來計數?
對于第一個 bug ,我們可以使用偏移量來解決,比如我要排[ -1,0,-3 ]這組數字,這個簡單,我全給你們加 10 來計數,變成[ 9,10,7 ]計完數后寫回原數組時再減 10。不過有可能也會踩到坑,萬一你數組里恰好有一個 -10,你加上 10 后又變 0 了,排毛線。
對于第二個 bug ,確實解決不了,如果是[ 9998,9999 ]這種雖然值大但是相差范圍不大的數據我們也可以使用偏移量解決,比如這兩個數據,我減掉 9997 后只需要申請一個 int[3] 的數組就可以進行計數。
由此可見,計數排序只適用于正整數并且取值范圍相差不大的數組排序使用,它的排序的速度是非常可觀的。
No.9桶排序
桶排序可以看成是計數排序的升級版,它將要排的數據分到多個有序的桶里,每個桶里的數據再單獨排序,再把每個桶的數據依次取出,即可完成排序。

桶排序動畫演示
▌圖解桶排序
我們拿一組計數排序啃不掉的數據 [ 500,6123,1700,10,9999 ] 來舉例。
第一步,我們創建 10 個桶,分別來裝 0-1000 、1000-2000 、 2000-3000 、 3000-4000 、 4000-5000 、5000-6000、 6000-7000 、7000-8000 、8000-9000 區間的數據。

桶排序1
第二步,遍歷原數組,對號入桶。

桶排序2
第三步,對桶中的數據進行單獨排序,只有第一個桶中的數量大于 1 ,顯然只需要排第一個桶。

桶排序3
最后,依次將桶中的數據取出,排序完成。

桶排序4
▌代碼實現
這個桶排序乍一看好像挺簡單的,但是要敲代碼就需要考慮幾個問題了。
桶這個東西怎么表示?
怎么確定桶的數量?
桶內排序用什么方法排?
代碼如下:
public static void sort(int[] arr){ //最大最小值 int max = arr[0]; int min = arr[0]; int length = arr.length; for(int i=1; i
桶當然是一個可以存放數據的集合,我這里使用 arrayList ,如果你使用 LinkedList 那其實也是沒有問題的。
桶的數量我認為設置為原數組的長度是合理的,因為理想情況下每個數據裝一個桶。
數據入桶的映射算法其實是一個開放性問題,我承認我這里寫的方案并不佳,因為我測試過不同的數據集合來排序,如果你有什么更好的方案或想法,歡迎留言討論。
桶內排序為了方便起見使用了當前語言提供的排序方法,如果對于穩定排序有所要求,可以選擇使用自定義的排序算法。
▌桶排序的思考及其應用
在額外空間充足的情況下,盡量增大桶的數量,極限情況下每個桶只有一個數據時,或者是每只桶只裝一個值時,完全避開了桶內排序的操作,桶排序的最好時間復雜度就能夠達到 O(n)。
比如高考總分 750 分,全國幾百萬人,我們只需要創建 751 個桶,循環一遍挨個扔進去,排序速度是毫秒級。
但是如果數據經過桶的劃分之后,桶與桶的數據分布極不均勻,有些數據非常多,有些數據非常少,比如[ 8,2,9,10,1,23,53,22,12,9000 ]這十個數據,我們分成十個桶裝,結果發現第一個桶裝了 9 個數據,這是非常影響效率的情況,會使時間復雜度下降到 O(nlogn),解決辦法是我們每次桶內排序時判斷一下數據量,如果桶里的數據量過大,那么應該在桶里面回調自身再進行一次桶排序。
No.10基數排序
基數排序是一種非比較型整數排序算法,其原理是將數據按位數切割成不同的數字,然后按每個位數分別比較。假設說,我們要對 100 萬個手機號碼進行排序,應該選擇什么排序算法呢?排的快的有歸并、快排時間復雜度是 O(nlogn),計數排序和桶排序雖然更快一些,但是手機號碼位數是11位,那得需要多少桶?內存條表示不服。
這個時候,我們使用基數排序是最好的選擇。

▌圖解基數排序
我們以[ 892, 846, 821, 199, 810,700 ]這組數字來做例子演示。
首先,創建十個桶,用來輔助排序。
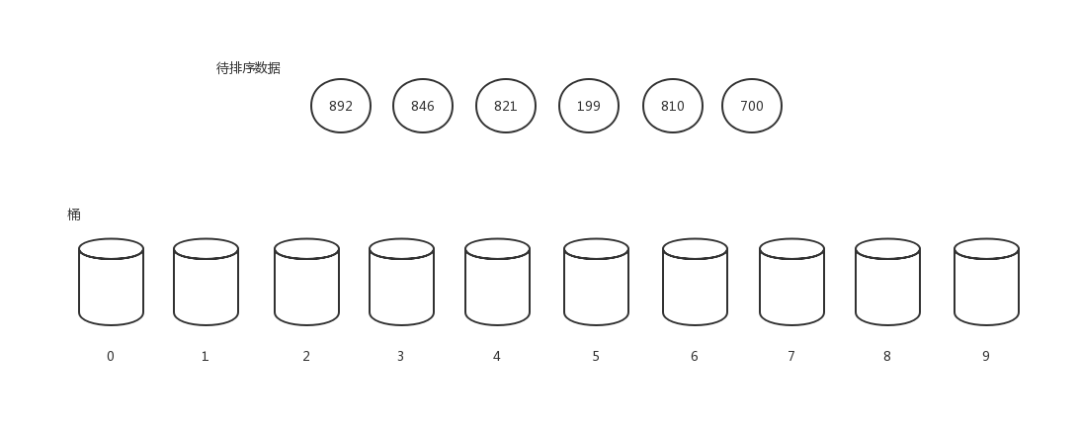
基數排序1
先排個位數,根據個位數的值將數據放到對應下標值的桶中。

基數排序2
排完后,我們將桶中的數據依次取出。
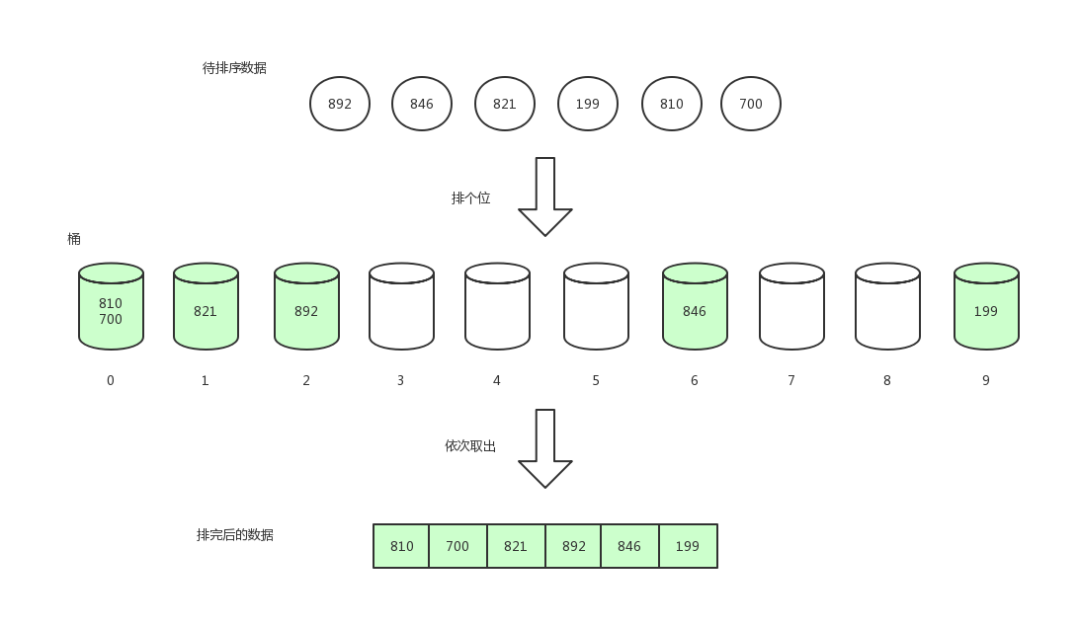
基數排序3
那么接下來,我們排十位數。

基數排序4
最后,排百位數。
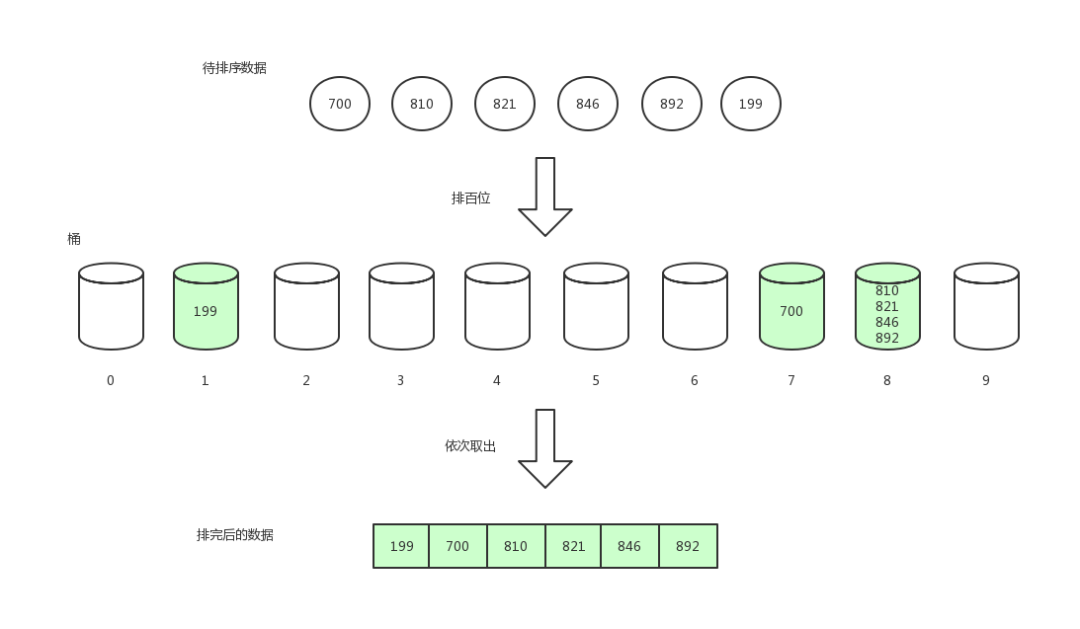
基數排序5
排序完成。
▌代碼實現
基數排序可以看成桶排序的擴展,也是用桶來輔助排序,代碼如下:
public static void sort(int[] arr){ int length = arr.length; //最大值 int max = arr[0]; for(int i = 0;i < length;i++){ if(arr[i] > max){ max = arr[i]; } } //當前排序位置 int location = 1; //桶列表 ArrayList
其實它的思想很簡單,不管你的數字有多大,按照一位一位的排,0 - 9 最多也就十個桶:先按權重小的位置排序,然后按權重大的位置排序。
當然,如果你有需求,也可以選擇從高位往低位排。
總結
感謝你看到了這里,希望看完這篇文章能讓你清晰的理解平時最常用的十大排序算法。
-
代碼
+關注
關注
30文章
4902瀏覽量
70855 -
排序算法
+關注
關注
0文章
53瀏覽量
10256 -
數組
+關注
關注
1文章
420瀏覽量
26624
原文標題:這或許是東半球分析十大排序算法最好的一篇文章
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
虛擬現實正一步步向我們走來

CC2530一步步演示程序燒寫
一步步進行調試GPRS模塊
ARM嵌入式系統如何入門?怎樣一步步的去學習
看電工技術是如何一步步淪為勤雜工的
ROM與RAM 單片機上電后如何一步步執行?資料下載

基于一步步蒸餾(Distilling step-by-step)機制





 工商網監
工商網監

評論