 MelNet 捕捉“高層結構”更勝一籌
MelNet 捕捉“高層結構”更勝一籌
計算機生成語音領域,正在醞釀著和一場革命。Facebook 工程師們設計創建的機器學習模型 MelNet 就是一個啟示。
下面這段聽起來怪異的話像極了比爾·蓋茨是吧?
但事實上,這幾句話是 Facebook 的工程師們設計創建的機器學習模型 MelNet 生成的。AI 合成逼真語音已不是新鮮事,George Takei、Jane Goodall、Stephen Hawking 等大佬的聲音早已被模仿了個遍,而且逼真程度讓人驚嘆。Facebook 此次合成的聲音樣本還有很多,可以在這里查看:https://audio-samples.github.io/
那么,這次合成比爾·蓋茨聲音背后的技術有何區別呢?答案是生成聲音的機器學習模型 MelNet是通過一種叫做頻譜圖的技術實現的。而且實驗表明,這個模型的性能高于此前曾紅火一時的 SampleRNN 和 WaveNet 等模型。
MelNet 的出現并非平地一聲雷。最近幾年,語音克隆的質量一直在穩步提高,最近著名美國播客 Joe Rogan 的聲音克隆證明了我們到底已經走了多遠。追溯到 2016 年,AI 聲音克隆技術已經有了很大的發展,SampleRNN 和 WaveNet 橫空出世,后者是由位于倫敦的人工智能實驗室 DeepMind 創建的機器學習文本到語音轉換程序,該實驗室現在為 Google 智能助理提供支持。
MelNet 技術解讀
在論文中,Facebook 的工程師對 MelNet 進行了詳解,我們從中摘取重要部分進行了解讀。
論文地址:https://arxiv.org/pdf/1906.01083.pdf
本文的主要貢獻如下:
提出了 MelNet。一個語譜圖的生成模型,它結合了細粒度的自回歸模型和多尺度生成過程,能夠同時捕獲局部和全局的結構。
展示了MelNet 在長程依賴性上卓越的性能。
展示了MelNet 在多種音頻生成任務上優秀的能力:無條件語音生成任務、音樂生成任務、文字轉語音合成任務。而且在這些任務上,MelNet 都是端到端的實現。
摘要
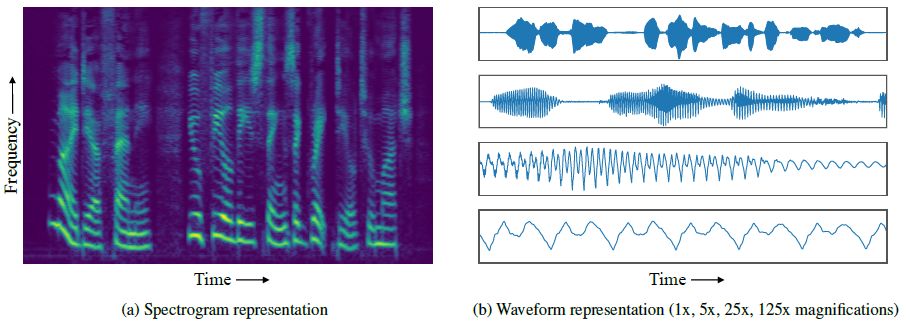
WaveNet、SampleRNN 和類似程序的基本方法是為 AU 系統提供大量數據,并用它來分析人聲中的細微差別。(早一點的文本到語音系統不會生成音頻,而是進行重構:將語音樣本切割成音素,然后拼接在一起創建新單詞。)當 WaveNet 和其他模型使用音頻波形進行訓練時,Facebook 的 MelNet 已經可以使用更多、包含更豐富信息的密集格式:頻譜圖。
(注:頻譜可以表示一個信號是由哪些頻率的弦波所組成,也可以看出各頻率弦波的大小及相位等信息,是分析振動參數的主要工具)
為了捕獲音頻波形中的高級結構,本文將時域的波形轉化為二維時頻的表達,通過將高度表達的概率模型和多尺度的生成模型相結合,提出了一種能夠生成高保真音頻樣本的模型,該模型能夠在時間尺度上捕獲結構信息,而現存的時域模型尚未實現該功能。為了驗證模型的有效性,本文將模型運用到多種音頻生成任務,包括無條件語音生成、音樂生成,以及文字轉語音合成。運用人工判別和密度估計的評價方法,本文模型的效果都超越了現存的模型。
MelNet 捕捉“高層結構”更勝一籌
在一篇隨附的論文(https://arxiv.org/pdf/1906.01083.pdf)中,Facebook 的研究人員指出,雖然 WaveNet 生成更高保真的音頻輸出,但 MelNet 在捕捉“高層結構”方面更勝一籌——說話者的聲音中包含了微妙的一致性,而這幾乎無法用文字描述,但是人的耳朵很好地辨別出來。
他們表示,這是因為頻譜圖中捕獲的數據比音頻波形中的數據“更緊湊”。這種密度允許算法產生更一致的聲音,而不是被波形記錄的極端細節分散和磨練(使用過于簡單的人類比喻)。
具體來說,在劇烈變化的時間尺度上,音頻波形具有復雜的結構,這對音頻生成模型提出了挑戰。局部結構用于產生高保真音頻,跨越數萬個時間步長的長程依賴性,則用于產生全局一致的音頻,同時捕獲局部結構和長程依賴性,是一項很具有挑戰的任務。WaveNet 和 SampleRNN 等現存的生成模型擅長捕獲局部依賴性,但是它們無法捕獲長時的高級結構。基于此,本文引入了一種新的音頻生成模型,它捕獲了比先存模型更為長程的依賴性。該模型主要通過建模2D時頻表示來實現這一目標,如下圖所示。
建模頻譜圖可以簡化捕獲全局結構的任務,但是會削弱與音頻保真度相關的局部特征的捕獲。為了減少信息損失,我們對高分辨率頻譜圖進行了建模。為了限制過度平滑,我們使用了高度表達的自回歸模型,在時間和頻率維度上對分布進行了分解。除此之外,為了捕獲具有數十萬個維度的頻譜圖中的局部和全局結構,我們采用了多尺度的方法,由粗略到精細的方式生成了頻譜圖。結合這些表征和建模技術,我們可以提出了高度表達、廣泛適用且完全端到端的音頻生成模型 MelNet。
缺陷:無法復制人類聲音在較長時間內的變化
但是,MelNet 也有一些缺陷,其中最重要的一點是該模型無法復制人類聲音在較長時間內的變化。有趣的是,這類似于我們在 AI 文本生成中的限制,它只能捕獲表面級別的一致性,而不是長期結構。
拋開這些缺陷,MelNet 取得的結果非常好。此外,MelNet 是一個多功能系統,它不僅可以產生逼真的聲音,還可以用于生成音樂(雖然有時候輸出有點差強人意,但不能以商業用途標準來衡量)。
概率模型
本文使用了自回歸模型,將語譜圖 x 的聯合分布作為條件分布的乘積進行分解。聯合概率分解如下:
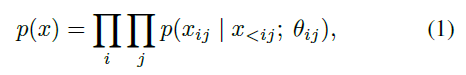
然后,我們用高斯混合模型對其中的每個因子進行建模,每個因子可以被分解如下:
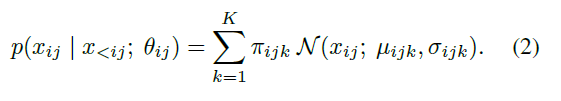
其中圖片: https://uploader.shimo.im/f/EInGnyOdsdgBDRKS.png是某個神經網絡的輸出,為了確保網絡輸出能夠參數化一個有效的高斯混合模型,網絡首先要計算無約束的參數,讓后再對參數實施以下的限制:
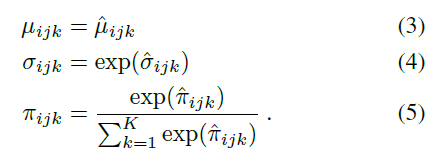
上述限制保證了正的標準差,以及保證了混合系數的和為 1 。
MelNet 網絡結構
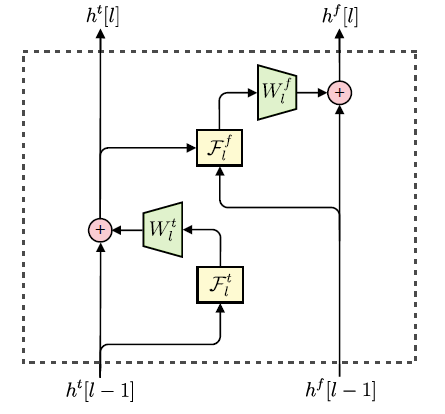
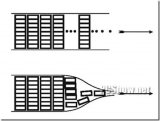
類似圖像空間分布的逐點估計,MelNet 模型在語譜圖的時間和頻率維度上,對元素的分布逐個進行估計。由于語譜圖在頻率軸上,沒有平移不變性,因此本模型用多維遞歸代替了 2D 卷積。該模型和 Gated PixelCNN 的結構較為相似,都采用了多層堆疊(stacks)的結構,它們用于提取輸入中不同片段的特征,進而綜合所有的信息。該模型主要有兩類 stack:
Time-delayed stack: 綜合歷史所有頻譜幀的信息
Frequency-delayed stack: 針對某一頻譜幀,使用該幀中所有元素的信息,以及 time-dealyed stack 的輸出信息,從而計算所有提取到的信息。
這些 stacks 之間相互連接,簡單來講,第 L 層 time-delayed stack 提取的特征,將作為第 L 層 frequency-delayed stack 的輸入。為了能夠訓練更深的網路,兩類 stack 內部都采用了殘差連接。最后一層 frequency-delayed stack 的輸出用于計算非受限的高斯混合參數。
Time-delayed stack
Time-delayed stack 使用了多層多維 RNN來提取歷史頻譜幀的信息,每層多維RNN 都由 3個1-D RNN組成:一個沿著頻率軸向前推進,一個沿著頻率軸向后推進,一個沿著時間軸向前推進,如下圖所示。
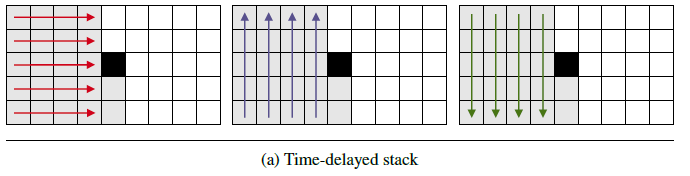
每個 Time-delayed stack 的功能可以用下面的式子表示:
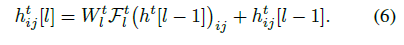
Frequency-delayed stack
Frequency-delayed stack 由1個 1-D RNN組成,該 RNN 沿頻率軸向前推進,如下圖所示。
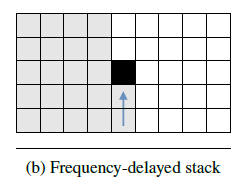
Frequency-delayed stack 具有兩個輸入:前一層的 Frequency-delayed stack 輸出,以及當前層的 Time-delayed stack 輸出。兩個輸入簡單相加后作為當前層的 Frequency-delayed stack 的最終輸入,表達式如下:
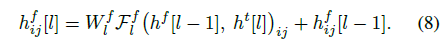
在網絡的最后一層中,對 Frequency-delayed stack 進行一個線性映射,從而得到非受限的高斯混合參數:
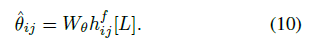
下圖所示為網絡中每層的 Time-delayed stack 和 Frequency-delayed stack 的連接方式:
Centralized Stack
為了獲取更加集中的特征表示,MelNet 模型選擇性地加入了 Centralized Stack 。Centralized Stack 由一個 RNN 組成,在每個時間步長下,接受一整幀頻譜作為輸入,輸出由 RNN 隱狀態組成的單個向量,公式如下:
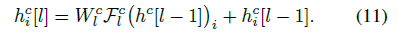
Centralized Stack 的輸出將作為 Frequency-delayed stack 的輸入,因此,Frequency-delayed stack 將會有三個輸入。
條件信息
為了將額外的條件信息(例如說話人 ID)加入到模型中,我們將條件特征 z 沿著輸入語譜圖 x 的方向,簡單投影到輸入層,公式如下所示。
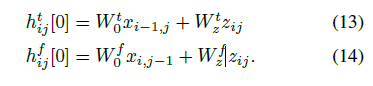
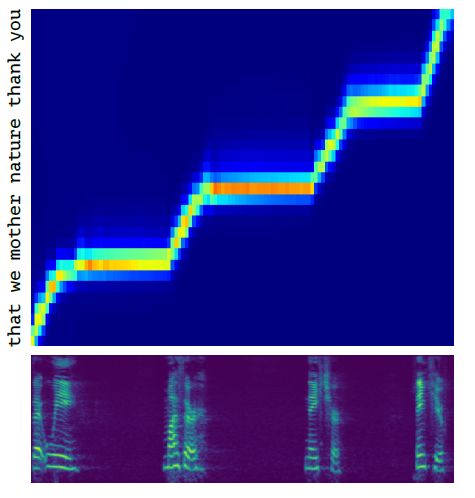
學習對齊
如何將語譜幀和離散字符對齊,是端到端文字轉語音任務的關鍵點,為了學習這一功能,MelNet 模型采用了注意力機制,該機制是基于位置的高斯混合注意力的一種直接變體。如下圖所示,為本模型所學習到的對齊效果。
多尺度建模
為了提高合成音頻的保真度,我們生成了高分辨率的語譜圖,它與相應的時域表示具有相同的維度。由于高維的分布對于自回歸模型具有很大的挑戰,我們使用了一種多尺度的方法,有效地置換自回歸排序,從而由粗到細地生成語譜圖。
訓練
首先對每幀語譜圖進行降采樣,從而生成不同分辨率的語譜圖。具體做法如下:將語譜圖 x 的列標記為奇列和偶列,所有偶列按順序組合成新的語譜圖,剩余的奇列重復前面的操作,從而得到不同分辨率的語譜圖,具體操作用 split 函數代替,如下所示:
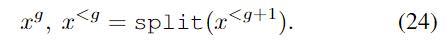
然后我們用低分辨率的語譜圖來重建高分辨率的語譜圖。在此過程中,我們引入了由一個多維RNN組成的特征提取網絡,它由4 個 1-D RNN 組成,用于在各個低分辨率語譜圖的兩個軸上雙向運行,最終生成高分辨率的語譜圖。
采樣
為了得到高分辨率的結果,我們利用網絡學習到的參數,在受限于圖片: https://uploader.shimo.im/f/vT2XqPWPsYYitpw7.png的情況下,迭代地對圖片: https://uploader.shimo.im/f/WkQfHvaeGq4yQdcd.png進行采樣,公式如下:
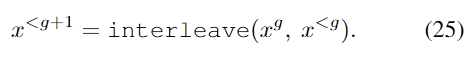
當一個完整的語譜圖生成后,采樣過程就停止了迭代,生成的各級別分辨率的語譜圖如下所示:

采樣過程的示意圖如下所示:

實驗結果
數據集
Blizzard:由專業人士以高度動畫的方式進行的有聲讀物敘述
MAESTRO:包括超過 172 小時的鋼琴獨奏表演
VoxCeleb2:超過 2000 小時的語音數據,包括笑聲、串擾、頻道效果、音樂和其他聲音。 該數據集也是多語言的,包括來自 145 個不同國籍的演講者,涵蓋了廣泛的口音、年齡、種族和語言
TED-LIUM 3:包括長達 452 小時的 TED 演講
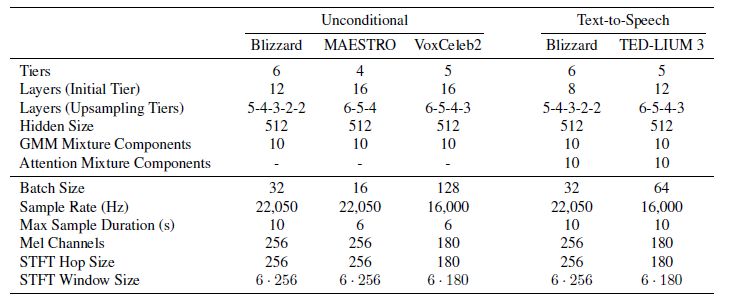
模型的超參數
結果
在無條件音頻生成任務上,Facebook 團隊進行了三個子實驗,分別是單說活人語音生成,多說話人語音生成,以及音樂生成,分別使用 Blizzard、VoxCeleb2 和 MAESTRO 數據集進行實驗。實驗中,將本文的 MelNet 和 現存的 WaveNet 模型進行比較,采用人工判別的方法來評價兩者的生成長時結構語音的性能,從下圖可以看出,MelNet 的性能要好于 WaveNet 。
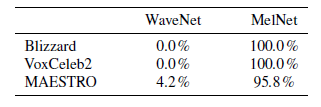
在文字轉語音合成的任務上,進行了三個子實驗,分別是單說活人 TTS,多說話人 TTS,以及密度估計實驗。實驗中,將本文的 MelNet 和 現存的 MAESTRO 模型進行比較,從下圖可以看出,MelNet 的性能要好于 MAESTRO 。
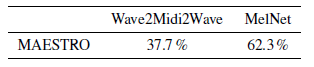
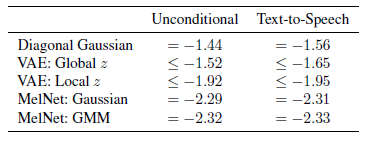
對于密度估計實驗,將本文的衍生模型 MelNet: Gaussian 和 MelNet: GMM,與 Diagonal Gaussian、VAE: Global z、VAE: Local z 進行比較,實驗結果如下,可以看到 MelNet 可以極大地改善無條件語音生成和 TTS 的密度估計。
結論
這種用于語譜表示的生成模型 MelNet 將高度表達的自回歸模型與多尺度模型方案相結合,在局部和全局尺度上生成具有真實結構的高分辨率語譜圖。與直接模擬時域信號的模型相比,MelNet 更加適合模擬長程的時間依賴性。實驗表明,MelNet 在各種任務中均表現了優秀的性能。
老調重談:它是把雙刃劍
與以往一樣,這項技術同樣也是一把雙刃劍。它能帶來什么好處呢?答案很明顯,比如幫助創建更高質量的 AI 助手;對于有語言障礙的人,它是實用的語音模型;此外,還可以用于娛樂業。危險也顯而易見? 比如破壞對傳統證據形式的信任,以及音頻騷擾、詐騙和越來越普遍的誹謗。
還記得最近的一項研究嗎?如果你想對一段人物特寫視頻進行重新編輯,只需要對視頻所對應的文本內容進行修改,隨后人臉會根據修改的文本內容作出與之相配的動作表達,這會造成什么樣的后果難以想象。AI 科技大本營在《“篡改”視頻腳本,讓特朗普輕松“變臉”?AI Deepfake再升級》中對此進行報道。
當然,等到類似技術更加普遍應用之時,會給傳統影視行業造成巨大沖擊倒是可以預見的,畢竟人臉可以生成,聲音可以生成,明星們連出鏡,甚至配音的麻煩都可以直接跳過,因為 AI 可以幫他們一鍵搞定,也許某一天,我們會發現,明星們的盈利模式將變成“人臉出租”?
-
Facebook
+關注
關注
3文章
1429瀏覽量
54721 -
機器學習
+關注
關注
66文章
8406瀏覽量
132565 -
rnn
+關注
關注
0文章
89瀏覽量
6886
原文標題:Facebook頻譜圖模型生成比爾·蓋茨聲音,性能完勝WaveNet、MAESTRO
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Oculus Rift與PS VR:誰會更勝一籌?
射頻技術和射頻標識對比分析誰更勝一籌?
公共云與私有云大比拼 成本計算誰更勝一籌?
小米mix對比華為Mate9誰更勝一籌?到底哪個值得買?
努比亞M2今日發布,對比小米6s,誰能更勝一籌?
小米電視4 55吋與雷鳥I55參數對比,誰能更勝一籌?
逐鹿新能源汽車:奔馳VS寶馬誰更勝一籌?
奔馳和寶馬面對新能源汽車時競爭實力到底誰更勝一籌
微軟、谷歌、英特爾都發力AI,3巨頭誰更勝一籌?
在各項生物識別技術中,哪種識別技術更勝一籌?
UVLED面光源與傳統光源對比:誰更勝一籌?






 工商網監
工商網監
評論