 電子發燒友App
電子發燒友App


1、串行程序
串行程序是基于嵌入式Linux串行通信GUI終端設計及實現。傳統意義上的寫法,我們得到的往往會是串行執行的程序形態,程序的總的執行時間是method1的執行時間time1加上method2的執行時間time2,這樣總的執行時間time=time1+time2。我們得到的是串行的程序形態。
import com.yang.domain.BaseResult;
import java.util.concurrent.TimeUnit;
/**
* @Description:
* @Author: yangzl2008
* @Date: 2016/1/9 19:06
*/
public class Serial {
@Test
public void test() {
long start = System.currentTimeMillis();
BaseResult baseResult1 = method1();// 耗時操作1,時間 time1
BaseResult baseResult2 = method2();// 耗時操作2,時間 time2
long end = System.currentTimeMillis();
//總耗時 time = time1 + time2
System.out.println(“baseResult1 is ” + baseResult1 + “\nbaseResult2 is ” + baseResult2 + “\ntime cost is ” + (end - start));
}
private BaseResult method1() {
BaseResult baseResult = new BaseResult();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
baseResult.setCode(1);
baseResult.setMsg(“method1”);
return baseResult;
}
private BaseResult method2() {
BaseResult baseResult = new BaseResult();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
baseResult.setCode(1);
baseResult.setMsg(“method2”);
return baseResult;
}
}
執行結果:
[plain]
BaseResult{code=1, msg=‘method1’}
baseResult2 is BaseResult{code=1, msg=‘method2’}
time cost is 2000
2、串行程序的多線程過渡
而這種代碼是不是可優化的地方呢?加快程序的執行效率,降低程序的執行時間。在這里method1和method2是相互不關聯的,即method1的執行和method2的執行位置可以調整,而不影響程序的執行結果,我們可不可以為建立線程1執行method1然后建立線程2來執行method2呢,因為method1和method2都需要得到結果,因此我們需要使用Callable接口,然后使用Future.get()得到執行的結果,但實際上Future.get()在程序返回結果之前是阻塞的,即,線程1在執行method1方式時,程序因為調用了Future.get()會等待在這里直到method1返回結果result1,然后線程2才能執行method2,同樣,Future.get()也會一直等待直到method2的結果result2返回,這樣,我們開啟了線程1,開啟了線程2并沒有得到并發執行method1,method2的效果,反而會因為程序開啟線程而多占用了程序的執行時間,這樣程序的執行時間time=time1+time2+time(線程開啟時間)。于是我們得到了串行程序的過渡態。
[java] view plain copyimport com.yang.domain.BaseResult;
import org.junit.Test;
import java.lang.reflect.Method;
import java.util.concurrent.*;
/**
* @Description:
* @Author: yangzl2008
* @Date: 2016/1/9 19:13
*/
public class SerialCallable {
@Test
public void test01() throws Exception {
// 兩個線程的線程池
ExecutorService executorService = Executors.newFixedThreadPool(2);
long start = System.currentTimeMillis();
// 開啟線程執行
Future《BaseResult》 future1 = executorService.submit(new Task(this, “method1”, null));
// 阻塞,直到程序返回。耗時time1
BaseResult baseResult1 = future1.get();
// 開啟線程執行
Future《BaseResult》 future2 = executorService.submit(new Task(this, “method1”, null));
// 阻塞,直到程序返回。耗時time2
BaseResult baseResult2 = future2.get();
long end = System.currentTimeMillis();
// 總耗時 time = time1 + time2 + time(線程執行耗時)
System.out.println(“baseResult1 is ” + baseResult1 + “\nbaseResult2 is ” + baseResult2 + “\ntime cost is ” + (end - start));
}
public BaseResult method1() {
BaseResult baseResult = new BaseResult();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
baseResult.setCode(1);
baseResult.setMsg(“method1”);
return baseResult;
}
public BaseResult method2() {
BaseResult baseResult = new BaseResult();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
baseResult.setCode(1);
baseResult.setMsg(“method2”);
return baseResult;
}
class Task《T》 implements Callable《T》 {
private Object object;
private Object[] args;
private String methodName;
public Task(Object object, String methodName, Object[] args) {
this.object = object;
this.args = args;
this.methodName = methodName;
}
@Override
public T call() throws Exception {
Method method = object.getClass().getMethod(methodName);
return (T) method.invoke(object, args);
}
}
}
執行結果:
[plain]
BaseResult{code=1, msg=‘method1’}
baseResult2 is BaseResult{code=1, msg=‘method1’}
time cost is 2001
3、并行程序
有沒有方法可以在執行method1的時候同時執行method2,最后得到結果再進行處理?我們回到問題的出處,程序首先執行完method1得到結果result1之后,在執行method2獲得結果result2,然后再按照result1和result2的結果來判定程序下一步的執行,最終我們得到的結果是result1和result2,然后再進行下一步操作,那么在我們得到result1和result2的時候,method1和method2其實是可以并發執行的,即我首先執行method1然后再執行mothod2,我不管他們的返回結果,只有在我要拿result1和result2進行操作的時候,程序才會調用Future.get()方法(這個方法會一直等待,直到結果返回),這是一種延遲加載的思想,與Hibernate中屬性的延遲加載是一致的,即對于屬性A,平時我是不用時不會進行賦值,只有我在用的時候,才執行SQL查詢對其進行賦值操作。于是,我們得到了并發執行的程序形態。
Hibernate亦使用CGLIB來實現延遲加載,因此,我們可以考慮使用CGLIB的延遲加載類,將串行的程序并行化!
[java] view plain copyimport com.yang.domain.BaseResult;
import net.sf.cglib.proxy.Enhancer;
import net.sf.cglib.proxy.LazyLoader;
import org.junit.Test;
import java.lang.reflect.Method;
import java.util.concurrent.*;
/**
* @Description:
* @Author: yangzl2008
* @Date: 2016/1/9 19:39
*/
public class Parallel {
@Test
public void test02() throws Exception {
ExecutorService executorService = Executors.newFixedThreadPool(2);
long start = System.currentTimeMillis();
// 開啟線程執行
Future《BaseResult》 future1 = executorService.submit(new Task(this, “method1”, null));
// 不阻塞,正常執行,baseResult1是cglib的代理類,采用延遲加載,只有在使用的時候才調用方法進行賦值。
BaseResult baseResult1 = futureGetProxy(future1, BaseResult.class);
// 開啟線程執行
Future《BaseResult》 future2 = executorService.submit(new Task(this, “method2”, null));
// 不阻塞,正常執行,baseResult1是cglib的代理類,采用延遲加載,只有在使用的時候才調用方法進行賦值。
BaseResult baseResult2 = futureGetProxy(future2, BaseResult.class);
// 這里要使用baseResult1和baseResult2
System.out.println(“baseResult1 is ” + baseResult1 + “\nbaseResult2 is ” + baseResult2);
long end = System.currentTimeMillis();
// 總耗時time = max(time1,time2)
System.out.println(“time cost is ” + (end - start));
}
private 《T》 T futureGetProxy(Future《T》 future, Class clazz) {
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(clazz);
return (T) enhancer.create(clazz, new FutureLazyLoader(future));
}
/**
* 延遲加載類
* @param 《T》
*/
class FutureLazyLoader《T》 implements LazyLoader {
private Future《T》 future;
public FutureLazyLoader(Future《T》 future) {
this.future = future;
}
@Override
public Object loadObject() throws Exception {
return future.get();
}
}
public BaseResult method1() {
BaseResult baseResult = new BaseResult();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
baseResult.setCode(1);
baseResult.setMsg(“method1”);
return baseResult;
}
public BaseResult method2() {
BaseResult baseResult = new BaseResult();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
baseResult.setCode(1);
baseResult.setMsg(“method2”);
return baseResult;
}
class Task《T》 implements Callable《T》 {
private Object object;
private Object[] args;
private String methodName;
public Task(Object object, String methodName, Object[] args) {
this.object = object;
this.args = args;
this.methodName = methodName;
}
@Override
public T call() throws Exception {
Method method = object.getClass().getMethod(methodName);
return (T) method.invoke(object, args);
}
}
}
執行結果:
[plain] view plain copybaseResult1 is BaseResult{code=1, msg=‘method1’}
baseResult2 is BaseResult{code=1, msg=‘method2’}
time cost is 1057
4、串行程序并行化
考慮這樣一個問題:統計某個工程的代碼行數。首先想到的思路便是,遞歸文件樹,每層遞歸里,循環遍歷父文件夾下的所有子文件,如果子文件是文件夾,那么再對這個文件夾進行遞歸調用。于是問題很輕松的解決了。這個方案可以優化嗎??
再回想這個問題,可以發現,循環里的遞歸調用其實相互之間是獨立的,互不干擾,各自統計自己路徑下的代碼文件的行數。于是,發現了這個方案的可優化點——利用線程池進行并行處理。于是一個串行的求解方案被改進成了并行方案。
不能光說不練,寫了一個Demo,對串行方案和并行方案進行了量化對比。代碼如下:
[java] view plain copyimport java.io.*;
import java.util.Queue;
import java.util.concurrent.*;
/**
* Created by cdlvsheng on 2016/5/16.
*/
public class ParallelSequentialContrast {
int coreSize = Runtime.getRuntime().availableProcessors();
ThreadPoolExecutor exec = new ThreadPoolExecutor(coreSize * 4, coreSize * 5, 0, TimeUnit.SECONDS,
new LinkedBlockingQueue《Runnable》(10000), new ThreadPoolExecutor.CallerRunsPolicy());
Queue《Future《Integer》》 queue = new ConcurrentLinkedQueue《Future《Integer》》();
private int countLineNum(File f) {
if (!f.getName().endsWith(“java”) && !f.getName().endsWith(“.js”) && !f.getName().endsWith(“.vm”)) return 0;
int sum = 0;
try {
BufferedReader br = new BufferedReader(new FileReader(f));
String str = null;
while ((str = br.readLine()) != null) sum++;
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return sum;
}
private class Task implements Callable《Integer》 {
File f;
public Task(File f) {
this.f = f;
}
public Integer call() throws Exception {
int sum = 0;
if (f.isDirectory()) {
File[] fs = f.listFiles();
for (File file : fs) {
if (file.isDirectory()) queue.add(exec.submit(new Task(file)));
else sum += countLineNum(file);
}
} else sum += countLineNum(f);
return sum;
}
}
public int parallelTraverse(File f) {
queue.add(exec.submit(new Task(f)));
int sum = 0;
while (!queue.isEmpty()) {
try {
Future《Integer》 future = queue.poll();
sum += future.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
exec.shutdown();
return sum;
}
public int sequentialTraverse(File f) {
int sum = 0;
if (f.isDirectory()) {
File[] fs = f.listFiles();
for (File file : fs) {
if (file.isDirectory()) sum += sequentialTraverse(file);
else sum += countLineNum(file);
}
} else sum += countLineNum(f);
return sum;
}
public void parallelTest(ParallelSequentialContrast psc, String pathname) {
long start = System.currentTimeMillis();
int sum = psc.parallelTraverse(new File(pathname));
long duration = System.currentTimeMillis() - start;
System.out.println(String.format(“parallel test, %d lines of code were found, time cost is %d ms”, sum, duration));
}
public void sequentialTest(ParallelSequentialContrast psc, String pathname) {
long start = System.currentTimeMillis();
int sum = psc.sequentialTraverse(new File(pathname));
long duration = System.currentTimeMillis() - start;
System.out.println(String.format(“sequential test, %d lines of code were found, time cost is %d ms”, sum, duration));
}
public static void main(String[] args) {
ParallelSequentialContrast psc = new ParallelSequentialContrast();
String pathname = “D:\\Code_Git”;
psc.sequentialTest(psc, pathname);
psc.parallelTest(psc, pathname);
}
}
因為要不斷的掃磁盤(雖然我的是固態硬盤),所以并行方案的線程池開的很大。IO密集型程序的相對CPU密集型程序的線程池會更大。
程序運行結果如下:
[plain] view plain copysequential test, 415079 lines of code were found, time cost is 364 ms
parallel test, 415079 lines of code were found, time cost is 163 ms
可以發現,在結果同等精確的情況下,串行方案耗時是并行方案的兩倍多。這個是在我個人PC上做的測試,如果是線上服務器運行,恐怕差距只會更加明顯。
如果一個大任務,由許多個相互獨立的子任務組成,我們就可以在這里找突破點,把一個串行程序并行化,榨干多和服務器的性能!
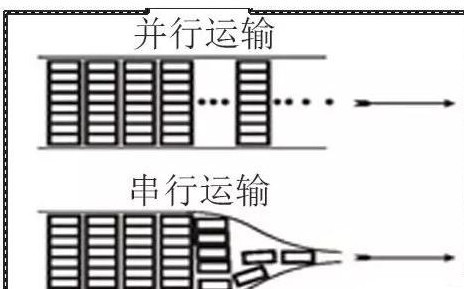
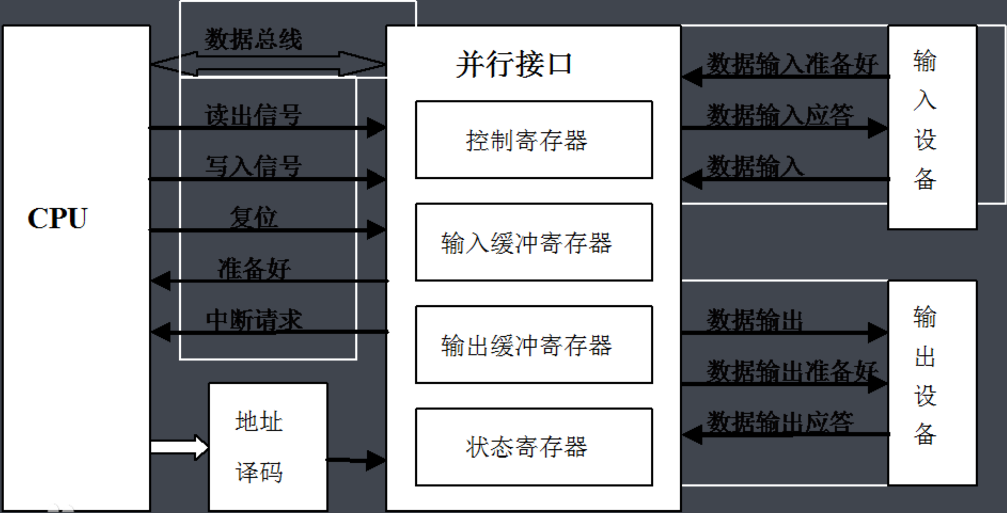
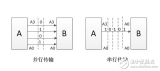
5、串行和并行的區別
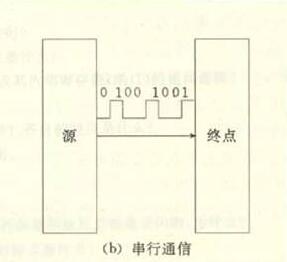
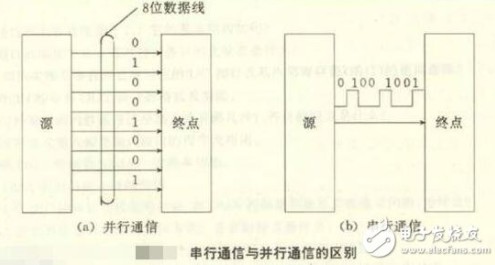
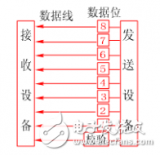
串行通信是指 使用一條數據線,將數據一位一位地依次傳輸,每一位數據占據一個固定的時間長度。其只需要少數幾條線就可以在系統間交換信息,特別使用于計算機與計算機、計算機與外設之間的遠距離通信。終端與其他設備(例如其他終端、計算機和外部設備)通過數據傳輸進行通信。數據傳輸可以通過兩種方式進行:并行通信和串行通信。 在計算機和終端之間的數據傳輸通常是靠電纜或信道上的電流或電壓變化實現的。如果一組數據的各數據位在多條線上同時被傳輸,這種傳輸方式稱為并行通信。 并行通信時數據的各個位同時傳送,可以字或字節為單位并行進行。并行通信速度快,但用的通信線多、成本高,故不宜進行遠距離通信。計算機或plc各種內部總線就是以并行方式傳送數據的。另外,在PLC底板上,各種模塊之間通過底板總線交換數據也以并行方式進行。
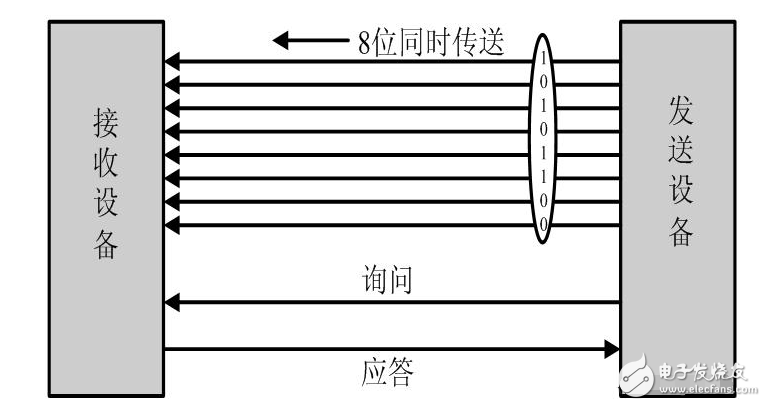
并行通信傳輸中有多個數據位,同時在兩個設備之間傳輸。發送設備將這些數據位通過 對應的數據線傳送給接收設備,還可附加一位數據校驗位。接收設備可同時接收到這些數據,不需要做任何變換就可直接使用。并行方式主要用于近距離通信。計算 機內的總線結構就是并行通信的例子。這種方法的優點是傳輸速度快,處理簡單。
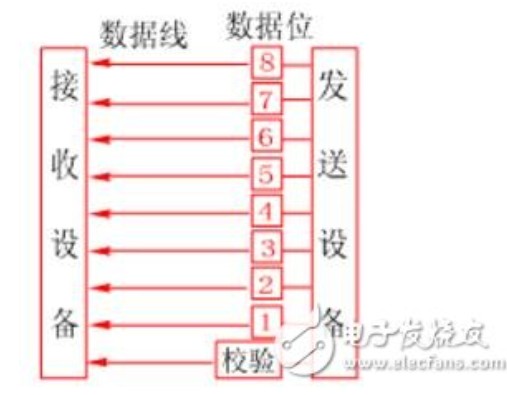
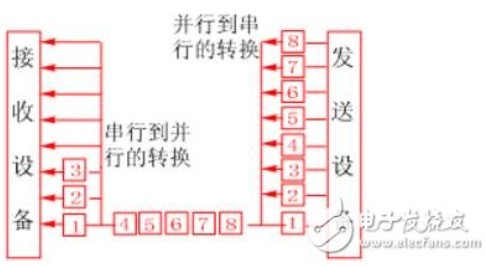
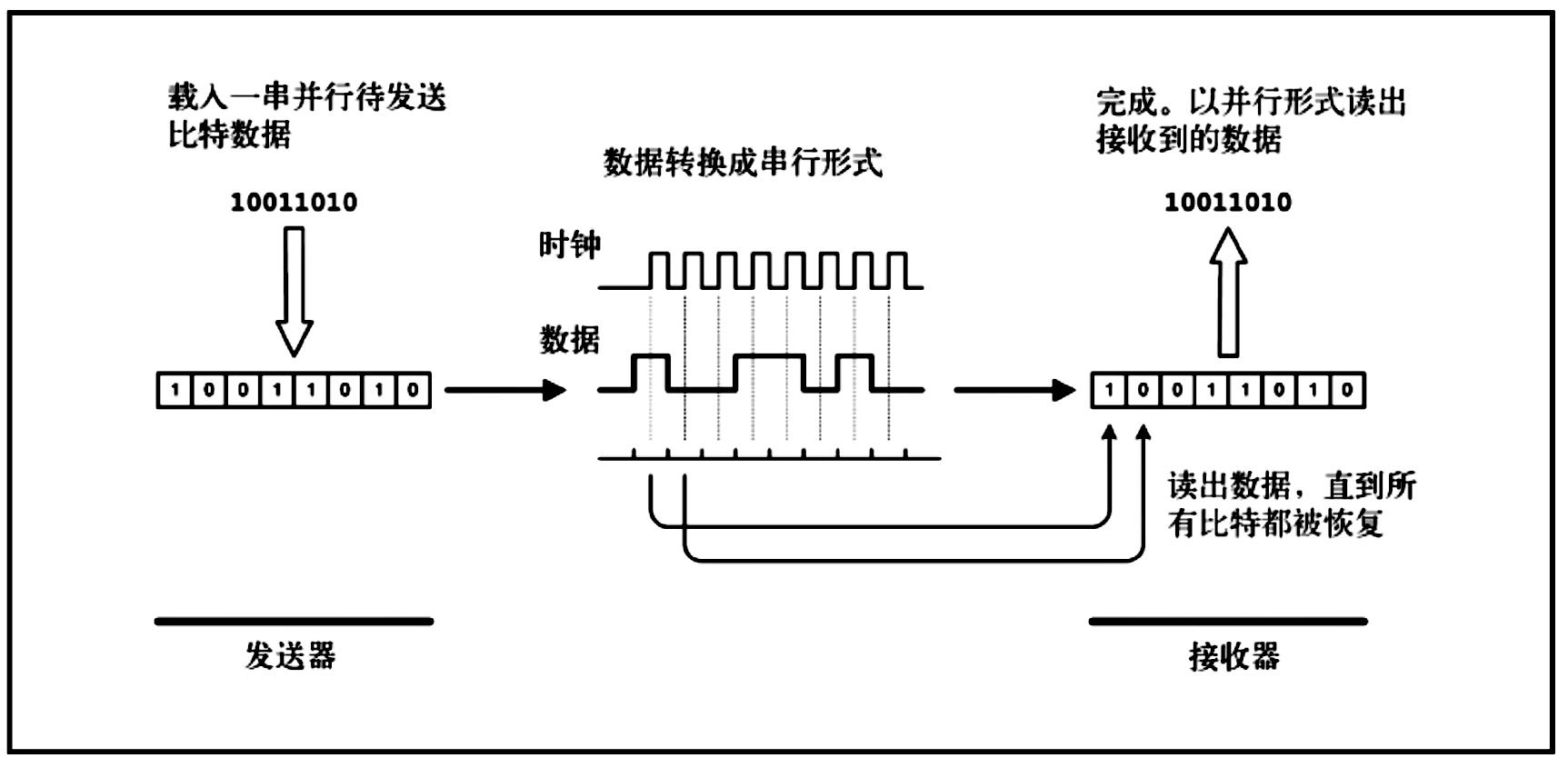
串行數據傳輸時,數據是一位一位地在通信線上傳輸的,先由具有幾位總線的計算機內的發送設備,將幾位并行數據經并--串轉換硬件轉換成串行方式,再逐位經 傳輸線到達接收站的設備中,并在接收端將數據從串行方式重新轉換成并行方式,以供接收方使用。串行數據傳輸的速度要比并行傳輸慢得多,但對于覆蓋面極其廣 闊的公用電話系統來說具有更大的現實意義。
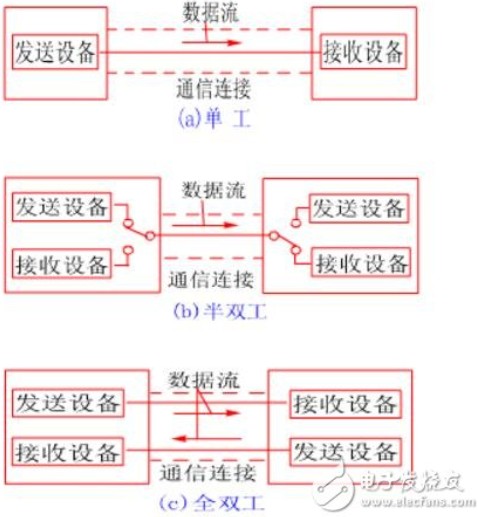
串行數據通信的方向性結構有三種,即單工、半雙工和全雙工。













 工商網監
工商網監
評論