 電子發燒友App
電子發燒友App


這篇文章主要是為了對深度學習(DeepLearning)有個初步了解,算是一個科普文吧,文章中去除了復雜的公式和圖表,主要內容包括深度學習概念、國內外研究現狀、深度學習模型結構、深度學習訓練算法、深度學習的優點、深度學習已有的應用、深度學習存在的問題及未來研究方向、深度學習開源軟件。
一、 深度學習概念
深度學習(Deep Learning, DL)由Hinton等人于2006年提出,是機器學習(MachineLearning, ML)的一個新領域。
深度學習被引入機器學習使其更接近于最初的目標----人工智能(AI,Artificial Intelligence)。深度學習是學習樣本數據的內在規律和表示層次,這些學習過程中獲得的信息對諸如文字、圖像和聲音等數據的解釋有很大的幫助。它的最終目標是讓機器能夠像人一樣具有分析學習能力,能夠識別文字、圖像和聲音等數據。
深度學習是一個復雜的機器學習算法,在語言和圖像識別方面取得的效果,遠遠超過先前相關技術。它在搜索技術、數據挖掘、機器學習、機器翻譯、自然語言處理、多媒體學習、語音、推薦和個性化技術,以及其它相關領域都取得了很多成果。深度學習使機器模仿視聽和思考等人類的活動,解決了很多復雜的模式識別難題,使得人工智能相關技術取得了很大進步。
2006年,機器學習大師、多倫多大學教授Geoffrey Hinton及其學生Ruslan發表在世界頂級學術期刊《科學》上的一篇論文引發了深度學習在研究領域和應用領域的發展熱潮。這篇文獻提出了兩個主要觀點:(1)、多層人工神經網絡模型有很強的特征學習能力,深度學習模型學習得到的特征數據對原數據有更本質的代表性,這將大大便于分類和可視化問題;(2)、對于深度神經網絡很難訓練達到最優的問題,可以采用逐層訓練方法解決。將上層訓練好的結果作為下層訓練過程中的初始化參數。在這一文獻中深度模型的訓練過程中逐層初始化采用無監督學習方式。
2010年,深度學習項目首次獲得來自美國國防部門DARPA計劃的資助,參與方有美國NEC研究院、紐約大學和斯坦福大學。自2011年起,谷歌和微軟研究院的語音識別方向研究專家先后采用深度神經網絡技術將語音識別的錯誤率降低20%-30%,這是長期以來語音識別研究領域取得的重大突破。2012年,深度神經網絡在圖像識別應用方面也獲得重大進展,在ImageNet評測問題中將原來的錯誤率降低了9%。同年,制藥公司將深度神經網絡應用于藥物活性預測問題取得世界范圍內最好結果。2012年6月,Andrew NG帶領的科學家們在谷歌神秘的X實驗室創建了一個有16000個處理器的大規模神經網絡,包含數十億個網絡節點,讓這個神經網絡處理大量隨機選擇的視頻片段。經過充分的訓練以后,機器系統開始學會自動識別貓的圖像。這是深度學習領域最著名的案例之一,引起各界極大的關注。
深度學習本質上是構建含有多隱層的機器學習架構模型,通過大規模數據進行訓練,得到大量更具代表性的特征信息。從而對樣本進行分類和預測,提高分類和預測的精度。這個過程是通過深度學習模型的手段達到特征學習的目的。深度學習模型和傳統淺層學習模型的區別在于:(1)、深度學習模型結構含有更多的層次,包含隱層節點的層數通常在5層以上,有時甚至包含多達10層以上的隱藏節點;(2)、明確強調了特征學習對于深度模型的重要性,即通過逐層特征提取,將數據樣本在原空間的特征變換到一個新的特征空間來表示初始數據,這使得分類或預測問題更加容易實現。和人工設計的特征提取方法相比,利用深度模型學習得到的數據特征對大數據的豐富內在信息更有代表性。
在統計機器學習領域,值得關注的問題是如何對輸入樣本進行特征空間的選擇。例如對行人檢測問題,需要尋找表現人體不同特點的特征向量。一般來說,當輸入空間中的原始數據不能被直接分開時,則將其映射到一個線性可分的間接特征空間。而此間接空間通常可由3種方式獲得:定義核函數映射到高維線性可分空間,如支持向量機(support vector machine,SVM)、手工編碼或自動學習。前2種方式對專業知識要求很高,且耗費大量的計算資源,不適合高維輸入空間。而第3種方式利用帶多層非線性處理能力的深度學習結構進行自動學習,經實際驗證被普遍認為具有重要意義與價值。深度學習結構相對于淺層學習結構[如SVM、人工神經網絡(artificial neural networks,ANN),能夠用更少的參數逼近高度非線性函數。
深度學習是機器學習領域一個新的研究方向,近年來在語音識別、計算機視覺等多類應用中取得突破性的進展。其動機在于建立模型模擬人類大腦的神經連接結構,在處理圖像、聲音和文本這些信號時,通過多個變換階段分層對數據特征進行描述,進而給出數據的解釋。以圖像數據為例,靈長類的視覺系統中對這類信號的處理依次為:首先檢測邊緣、初始形狀、然后再逐步形成更復雜的視覺形狀,同樣地,深度學習通過組合低層特征形成更加抽象的高層表示、屬性類別或特征,給出數據的分層特征表示。
深度學習之所以被稱為“深度”,是相對支持向量機(supportvector machine, SVM)、提升方法(boosting)、最大熵方法等“淺層學習”方法而言的,深度學習所學得的模型中,非線性操作的層級數更多。淺層學習依靠人工經驗抽取樣本特征,網絡模型學習后獲得的是沒有層次結構的單層特征;而深度學習通過對原始信號進行逐層特征變換,將樣本在原空間的特征表示變換到新的特征空間,自動地學習得到層次化的特征表示,從而更有利于分類或特征的可視化。深度學習理論的另外一個理論動機是:如果一個函數可用k層結構以簡潔的形式表達,那么用k-1層的結構表達則可能需要指數級數量的參數(相對于輸入信號),且泛化能力不足。
深度學習算法打破了傳統神經網絡對層數的限制,可根據設計者需要選擇網絡層數。它的訓練方法與傳統的神經網絡相比有很大區別,傳統神經網絡隨機設定參數初始值,采用BP算法利用梯度下降算法訓練網絡,直至收斂。但深度結構訓練很困難,傳統對淺層有效的方法對于深度結構并無太大作用,隨機初始化權值極易使目標函數收斂到局部極小值,且由于層數較多,殘差向前傳播會丟失嚴重,導致梯度擴散,因此深度學習過程中采用貪婪無監督逐層訓練方法。即在一個深度學習設計中,每層被分開對待并以一種貪婪方式進行訓練,當前一層訓練完后,新的一層將前一層的輸出作為輸入并編碼以用于訓練;最后每層參數訓練完后,在整個網絡中利用有監督學習進行參數微調。
深度學習的概念最早由多倫多大學的G. E.Hinton等于2006年提出,基于樣本數據通過一定的訓練方法得到包含多個層級的深度網絡結構的機器學習過程。傳統的神經網絡隨機初始化網絡中的權值,導致網絡很容易收斂到局部最小值,為解決這一問題,Hinton提出使用無監督預訓練方法優化網絡權值的初值,再進行權值微調的方法,拉開了深度學習的序幕。
深度學習所得到的深度網絡結構包含大量的單一元素(神經元),每個神經元與大量其他神經元相連接,神經元間的連接強度(權值)在學習過程中修改并決定網絡的功能。通過深度學習得到的深度網絡結構符合神經網絡的特征,因此深度網絡就是深層次的神經網絡,即深度神經網絡(deep neural networks, DNN)。
深度學習的概念起源于人工神經網絡的研究,有多個隱層的多層感知器是深度學習模型的一個很好的范例。對神經網絡而言,深度指的是網絡學習得到的函數中非線性運算組合水平的數量。當前神經網絡的學習算法多是針對較低水平的網絡結構,將這種網絡稱為淺結構神經網絡,如一個輸入層、一個隱層和一個輸出層的神經網絡;與此相反,將非線性運算組合水平較高的網絡稱為深度結構神經網絡,如一個輸入層、三個隱層和一個輸出層的神經網絡。
深度學習的基本思想:假設有系統S,它有n層(S1,…,Sn),輸入為I,輸出為O,可形象的表示為:I=》S1=》S2=》… =》Sn=》O。為了使輸出O盡可能的接近輸入I,可以通過調整系統中的參數,這樣就可以得到輸入I的一系列層次特征S1,S2,…,Sn。對于堆疊的多個層,其中一層的輸出作為其下一層的輸入,以實現對輸入數據的分級表達,這就是深度學習的基本思想。
二、 國內外研究現狀
深度學習極大地促進了機器學習的發展,受到世界各國相關領域研究人員和高科技公司的重視,語音、圖像和自然語言處理是深度學習算法應用最廣泛的三個主要研究領域:
1、深度學習在語音識別領域研究現狀
長期以來,語音識別系統大多是采用混合高斯模型(GMM)來描述每個建模單元的統計概率模型。由于這種模型估計簡單,方便使用大規模數據對其訓練,該模型有較好的區分度訓練算法保證了該模型能夠被很好的訓練。在很長時間內占據了語音識別應用領域主導性地位。但是這種混合高斯模型實質上是一種淺層學習網絡建模,特征的狀態空間分布不能夠被充分描述。而且,使用混合高斯模型建模方式數據的特征維數通常只有幾十維,這使得特征之間的相關性不能被充分描述。最后混合高斯模型建模實質上是一種似然概率建模方式,即使一些模式分類之間的區分性能夠通過區分度訓練模擬得到,但是效果有限。
從2009年開始,微軟亞洲研究院的語音識別專家們和深度學習領軍人物Hinton取得合作。2011年微軟公司推出了基于深度神經網絡的語音識別系統,這一成果將語音識別領域已有的技術框架完全改變。采用深度神經網絡后,樣本數據特征間相關性信息得以充分表示,將連續的特征信息結合構成高維特征,通過高維特征樣本對深度神經網絡模型進行訓練。由于深度神經網絡采用了模擬人腦神經架構,通過逐層地進行數據特征提取,最終得到適合進行模式分類處理的理想特征。深度神經網絡建模技術,在實際線上應用時,能夠很好地和傳統語音識別技術結合,語音識別系統識別率大幅提升。
國際上,谷歌也使用深層神經網絡對聲音進行建模,是最早在深度神經網絡的工業化應用領域取得突破的企業之一。但谷歌的產品中使用的深度神經網絡架構只有4、5層,與之相比百度使用的深度神經網絡架構多達9層,正是這種結構上的差別使深度神經網絡在線學習的計算難題得以更好的解決。這使得百度的線上產品能夠采用更加復雜的神經網絡模型。這種結構差異的核心其實是百度更好地解決了深度神經網絡在線計算的技術難題,因此百度線上產品可以采用更復雜的網絡模型。這對將來拓展大規模語料數據對深度神經網絡模型的訓練有更大的幫助。
2、深度學習在圖像識別領域研究現狀
對于圖像的處理是深度學習算法最早嘗試應用的領域。早在1989年,加拿大多倫多大學教授Yann LeCun就和他的同事們一起提出了卷積神經網絡(Convolutional Neural Networks)。卷積神經網絡也稱為CNN,它是一種包含卷積層的深度神經網絡模型。通常一個卷積神經網絡架構包含兩個可以通過訓練產生的非線性卷積層,兩個固定的子采樣層和一個全連接層,隱藏層的數量一般至少在5個以上。CNN的架構設計是受到生物學家Hubel和Wiesel的動物視覺模型啟發而發明的,尤其是模擬動物視覺皮層V1層和V2層中簡單細胞(Simple Cell)和復雜細胞(Complex Cell)在視覺系統的功能。起初卷積神經網絡在小規模的應用問題上取得了當時世界最好成果。但在很長一段時間里一直沒有取得重大突破。主要原因是由于卷積神經網絡應用在大尺寸圖像上一直不能取得理想結果,比如對于像素數很大的自然圖像內容的理解,這使得它沒有引起計算機視覺研究領域足夠的重視。直到2012年10月,Hinton教授以及他的兩個學生采用更深的卷積神經網絡模型在著名的ImageNet問題上取得了世界最好成果,使得對于圖像識別的研究工作前進了一大步。Hinton構建的深度神經網絡模型是使用原始的自然圖像訓練的,沒有使用任何人工特征提取方法。
自卷積神經網絡提出以來,在圖像識別問題上并沒有取得質的提升和突破,直到2012年Hinton構建的深度神經網絡才取得驚人成果。這主要是因為對算法的改進,在網絡的訓練中引入了權重衰減的概念,有效的減小權重幅度,防止網絡過擬合。更關鍵的是計算機計算能力的提升,GPU加速技術的發展,這使得在訓練過程中可以產生更多的訓練數據,使網絡能夠更好的擬合訓練樣本。2012年國內互聯網巨頭百度公司將相關最新技術成功應用到人臉識別和自然圖像識別問題,并推出了相應的產品。現在深度學習網絡模型已能夠理解和識別一般的自然圖像。深度學習模型不僅大幅提高了圖像識別的精度,同時也避免了需要消耗大量的時間進行人工特征提取的工作,使得在線運算效率大大提升。深度學習將有可能取代以往人工和機器學習相結合的方式成為主流圖像識別技術。
3、深度學習在自然語言處理領域研究現狀
自然語言處理(NLP)問題是深度學習在除了語音和圖像處理之外的另一個重要應用領域。數十年以來,自然語言處理的主流方法是基于統計的模型,人工神經網絡也是基于統計方法模型之一,但在自然語言處理領域卻一直沒有被重視。語言建模是最早采用神經網絡進行自然語言處理的問題。美國的NEC研究院最早將深度學習引入到自然語言處理研究工作中,其研究人員從2008年起采用將詞匯映射到一維矢量空間方法和多層一維卷積結構去解決詞性標注、分詞、命名實體識別和語義角色標注四個典型的自然語言處理問題。他們構建了同一個網絡模型用于解決四個不同問題,都取得了相當精確的結果。總體而言,深度學習在自然語言處理問題上取得的成果和在圖像語音識別方面還有相當的差距,仍有待深入探索。
由于深度學習能夠很好地解決一些復雜問題,近年來許多研究人員對其進行了深人研究,出現了許多有關深度學習研究的新進展。下面分別從初始化方法、網絡層數和激活函數的選擇、模型結構兩個個方面對近幾年深度學習研究的新進展進行介紹。
1、 初始化方法、網絡層數和激活函數的選擇
研究人員試圖搞清網絡初始值的設定與學習結果之間的關系。Erhan等人在軌跡可視化研究中指出即使從相近的值開始訓練深度結構神經網絡,不同的初始值也會學習到不同的局部極值,同時發現用無監督預訓練初始化模型的參數學習得到的極值與隨機初始化學習得到的極值差異比較大,用無監督預訓練初始化模型的參數學習得到的模型具有更好的泛化誤差。Bengio與Krueger等人指出用特定的方法設定訓練樣例的初始分布和排列順序可以產生更好的訓練結果,用特定的方法初始化參數,使其與均勻采樣得到的參數不同,會對梯度下降算法訓練的結果產生很大的影響。Glorot等人指出通過設定一組初始權值使得每一層深度結構神經網絡的Jacobian矩陣的奇異值接近1,在很大程度上減小了監督深度結構神經網絡和有預訓練過程設定初值的深度結構神經網絡之間的學習結果差異。另外,用于深度學習的學習算法通常包含許多超參數,一些常用的超參數,尤其適用于基于反向傳播的學習算法和基于梯度的優化算法。
選擇不同的網絡隱層數和不同的非線性激活函數會對學習結果產生不同的影響。Glorot等人研究了隱層非線性映射關系的選擇和網絡的深度相互影響的問題,討論了隨機初始化的標準梯度下降算法用于深度結構神經網絡學習得到不好的學習性能的原因。Glorot等人觀察不同非線性激活函數對學習結果的影響,得到邏輯斯蒂S型激活單元的均值會驅使頂層和隱層進入飽和,因而邏輯斯蒂S型激活單元不適合用隨機初始化梯度算法學習深度結構神經網絡;并據此提出了標準梯度下降算法的一種新的初始化方案來得到更快的收斂速度。Bengio等人從理論上說明深度學習結構的表示能力隨著神經網絡深度的增加以指數的形式增加,但是這種增加的額外表示能力會引起相應局部極值數量的增加,使得在其中尋找最優值變得困難。
2、 模型結構
(1)、DBN的結構及其變種:采用二值可見單元和隱單元RBM作為結構單元的DBN,在MNIST等數據集上表現出很好的性能。近幾年,具有連續值單元的RBM,如mcRBM、mPoT模型和spike—and-slab RBM等已經成功應用。Spike—and—slab RBM中spike表示以0為中心的離散概率分布,slab表示在連續域上的稠密均勻分布,可以用吉布斯采樣對spike—and—slab RBM進行有效推斷,得到優越的學習性能。
(2)、和--積網絡;深度學習最主要的困難是配分函數的學習,如何選擇深度結構神經網絡的結構使得配分函數更容易計算? Poon等人提出一種新的深度模型結構----和--積網絡(sum—product network,SPN),引入多層隱單元表示配分函數,使得配分函數更容易計算。SPN是有根節點的有向無環圖,圖中的葉節點為變量,中間節點執行和運算與積運算,連接節點的邊帶有權值,它們在Caltech-101和Olivetti兩個數據集上進行實驗證明了SPN的性能優于DBN和最近鄰方法。
(3)、基于rectified單元的學習:Glorot與Mesnil等人用降噪自編碼模型來處理高維輸入數據。與通常的S型和正切非線性隱單元相比,該自編碼模型使用rectified單元,使隱單元產生更加稀疏的表示。對于高維稀疏數據,Dauphin等人采用抽樣重構算法,訓練過程只需要計算隨機選擇的很小的樣本子集的重構和重構誤差,在很大程度上提高了學習速度,實驗結果顯示提速了20倍。Glorot等人提出在深度結構神經網絡中,在圖像分類和情感分類問題中用rectified非線性神經元代替雙曲正切或S型神經元,指出rectified神經元網絡在零點產生與雙曲正切神經元網絡相當或者有更好的性能,能夠產生有真正零點的稀疏表示,非常適合本質稀疏數據的建模,在理解訓練純粹深度監督神經網絡的困難,搞清使用或不使用無監督預訓練學習的神經網絡造成的性能差異方面,可以看做新的里程碑;Glorot等人還提出用增加L1正則化項來促進模型稀疏性,使用無窮大的激活函數防止算法運行過程中可能引起的數值問題。在此之前,Nair等人提出在RBM環境中rectifed神經元產生的效果比邏輯斯蒂S型激活單元好,他們用無限數量的權值相同但是負偏差變大的一組單元替換二值單元,生成用于RBM的更好的一類隱單元,將RBM泛化,可以用噪聲rectified線性單元(rectified linear units)有效近似這些S型單元。用這些單元組成的RBM在NORB數據集上進行目標識別以及在數據集上進行已標記人臉實際驗證,得到比二值單元更好的性能,并且可以更好地解決大規模像素強度值變化很大的問題。
(4)、卷積神經網絡:研究了用生成式子抽樣單元組成的卷積神經網絡,在MNIST數字識別任務和Cahech一101目標分類基準任務上進行實驗,顯示出非常好的學習性能。Huang等人提出一種新的卷積學習模型----局部卷積RBM,利用對象類中的總體結構學習特征,不假定圖像具有平穩特征,在實際人臉數據集上進行實驗,得到性能很好的實驗結果。
三、 深度學習模型結構
深度神經網絡是由多個單層非線性網絡疊加而成的,常見的單層網絡按照編碼解碼情況分為3類:只包含編碼器部分、只包含解碼器部分、既有編碼器部分也有解碼器部分。編碼器提供從輸入到隱含特征空間的自底向上的映射,解碼器以重建結果盡可能接近原始輸入為目標將隱含特征映射到輸入空間。
人的視覺系統對信息的處理是分級的。從低級的提取邊緣特征到形狀(或者目標等),再到更高層的目標、目標的行為等,即底層特征組合成了高層特征,由低到高的特征表示越來越抽象。深度學習借鑒的這個過程就是建模的過程。
深度神經網絡可以分為3類,前饋深度網絡(feed-forwarddeep networks, FFDN),由多個編碼器層疊加而成,如多層感知機(multi-layer perceptrons, MLP)、卷積神經網絡(convolutionalneural networks, CNN)等。反饋深度網絡(feed-back deep networks, FBDN),由多個解碼器層疊加而成,如反卷積網絡(deconvolutionalnetworks, DN)、層次稀疏編碼網絡(hierarchical sparse coding, HSC)等。雙向深度網絡(bi-directionaldeep networks, BDDN),通過疊加多個編碼器層和解碼器層構成(每層可能是單獨的編碼過程或解碼過程,也可能既包含編碼過程也包含解碼過程),如深度玻爾茲曼機(deep Boltzmann machines, DBM)、深度信念網絡(deep beliefnetworks, DBN)、棧式自編碼器(stacked auto-encoders, SAE)等。
1、 前潰深度網絡
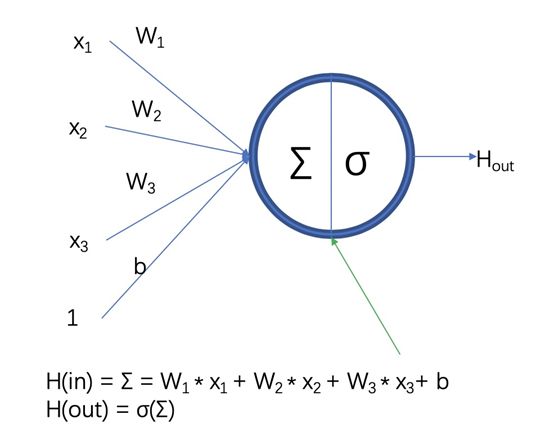
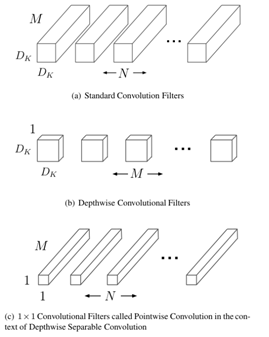
前饋神經網絡是最初的人工神經網絡模型之一。在這種網絡中,信息只沿一個方向流動,從輸入單元通過一個或多個隱層到達輸出單元,在網絡中沒有封閉環路。典型的前饋神經網絡有多層感知機和卷積神經網絡等。F. Rosenblatt提出的感知機是最簡單的單層前向人工神經網絡,但隨后M. Minsky等證明單層感知機無法解決線性不可分問題(如異或操作),這一結論將人工神經網絡研究領域引入到一個低潮期,直到研究人員認識到多層感知機可解決線性不可分問題,以及反向傳播算法與神經網絡結合的研究,使得神經網絡的研究重新開始成為熱點。但是由于傳統的反向傳播算法,具有收斂速度慢、需要大量帶標簽的訓練數據、容易陷入局部最優等缺點,多層感知機的效果并不是十分理想。1984年日本學者K. Fukushima等基于感受野概念,提出的神經認知機可看作卷積神經網絡的一種特例。Y. Lecun等提出的卷積神經網絡是神經認知機的推廣形式。卷積神經網絡是由多個單層卷積神經網絡組成的可訓練的多層網絡結構。每個單層卷積神經網絡包括卷積、非線性變換和下采樣3個階段,其中下采樣階段不是每層都必需的。每層的輸入和輸出為一組向量構成的特征圖(feature map)(第一層的原始輸入信號可以看作一個具有高稀疏度的高維特征圖)。例如,輸入部分是一張彩色圖像,每個特征圖對應的則是一個包含輸入圖像彩色通道的二維數組(對于音頻輸入,特征圖對應的是一維向量;對于視頻或立體影像,對應的是三維數組);對應的輸出部分,每個特征圖對應的是表示從輸入圖片所有位置上提取的特定特征。
(1)、單層卷積神經網絡:卷積階段,通過提取信號的不同特征實現輸入信號進行特定模式的觀測。其觀測模式也稱為卷積核,其定義源于由D. H. Hubel等基于對貓視覺皮層細胞研究提出的局部感受野概念。每個卷積核檢測輸入特征圖上所有位置上的特定特征,實現同一個輸入特征圖上的權值共享。為了提取輸入特征圖上不同的特征,使用不同的卷積核進行卷積操作。卷積階段的輸入是由n1個n2*n3大小的二維特征圖構成的三維數組。每個特征圖記為xi,該階段的輸出y,也是個三維數組,由m1個m2*m3大小的特征圖構成。在卷積階段,連接輸入特征圖xi和輸出特征圖yj的權值記為wij,即可訓練的卷積核(局部感受野),卷積核的大小為k2*k3,輸出特征圖為yj。
非線性階段,對卷積階段得到的特征按照一定的原則進行篩選,篩選原則通常采用非線性變換的方式,以避免線性模型表達能力不夠的問題。非線性階段將卷積階段提取的特征作為輸入,進行非線性映射R=h(y)。傳統卷積神經網絡中非線性操作采用sigmoid、tanh 或softsign等飽和非線性(saturating nonlinearities)函數,近幾年的卷積神經網絡中多采用不飽和非線性(non-saturating nonlinearity)函數ReLU(rectifiedlinear units)。在訓練梯度下降時,ReLU比傳統的飽和非線性函數有更快的收斂速度,因此在訓練整個網絡時,訓練速度也比傳統的方法快很多。
下采樣階段,對每個特征圖進行獨立操作,通常采用平均池化(average pooling)或者最大池化(max pooling)的操作。平均池化依據定義的鄰域窗口計算特定范圍內像素的均值PA,鄰域窗口平移步長大于1(小于等于池化窗口的大小);最大池化則將均值PA替換為最值PM輸出到下個階段。池化操作后,輸出特征圖的分辨率降低,但能較好地保持高分辨率特征圖描述的特征。一些卷積神經網絡完全去掉下采樣階段,通過在卷積階段設置卷積核窗口滑動步長大于1達到降低分辨率的目的。
(2)、卷積神經網絡:將單層的卷積神經網絡進行多次堆疊,前一層的輸出作為后一層的輸入,便構成卷積神經網絡。其中每2個節點間的連線,代表輸入節點經過卷積、非線性變換、下采樣3個階段變為輸出節點,一般最后一層的輸出特征圖后接一個全連接層和分類器。為了減少數據的過擬合,最近的一些卷積神經網絡,在全連接層引入“Dropout”或“DropConnect”的方法,即在訓練過程中以一定概率P將隱含層節點的輸出值(對于“DropConnect”為輸入權值)清0,而用反向傳播算法更新權值時,不再更新與該節點相連的權值。但是這2種方法都會降低訓練速度。在訓練卷積神經網絡時,最常用的方法是采用反向傳播法則以及有監督的訓練方式。網絡中信號是前向傳播的,即從輸入特征向輸出特征的方向傳播,第1層的輸入X,經過多個卷積神經網絡層,變成最后一層輸出的特征圖O。將輸出特征圖O與期望的標簽T進行比較,生成誤差項E。通過遍歷網絡的反向路徑,將誤差逐層傳遞到每個節點,根據權值更新公式,更新相應的卷積核權值wij。在訓練過程中,網絡中權值的初值通常隨機初始化(也可通過無監督的方式進行預訓練),網絡誤差隨迭代次數的增加而減少,并且這一過程收斂于一個穩定的權值集合,額外的訓練次數呈現出較小的影響。
(3)、卷積神經網絡的特點:卷積神經網絡的特點在于,采用原始信號(一般為圖像)直接作為網絡的輸入,避免了傳統識別算法中復雜的特征提取和圖像重建過程。局部感受野方法獲取的觀測特征與平移、縮放和旋轉無關。卷積階段利用權值共享結構減少了權值的數量進而降低了網絡模型的復雜度,這一點在輸入特征圖是高分辨率圖像時表現得更為明顯。同時,下采樣階段利用圖像局部相關性的原理對特征圖進行子抽樣,在保留有用結構信息的同時有效地減少數據處理量。
CNN(convolutional neuralnetworks)是一種有監督深度的模型架構,尤其適合二維數據結構。目前研究與應用都較廣泛,在行人檢測、人臉識別、信號處理等領域均有新的成果與進展。它是帶有卷積結構的深度神經網絡,也是首個真正意義上成功訓練多層網絡的識別算法。CNN與傳統ANN 算法的主要區別在于權值共享以及非全連接。權值共享能夠避免算法過擬合,通過拓撲結構建立層與層間非全連接空間關系來降低訓練參數的數目,同時也是CNN的基本思想。CNN的實質是學習多個能夠提取輸入數據特征的濾波器,通過這些濾波器與輸入數據進行逐層卷積及池化,逐級提取隱藏在數據中拓撲結構特征。隨網絡結構層層深入,提取的特征也逐漸變得抽象,最終獲得輸入數據的平移、旋轉及縮放不變性的特征表示。較傳統神經網絡來說,CNN將特征提取與分類過程同時進行,避免了兩者在算法匹配上的難點。
CNN主要由卷積層與下采樣層交替重復出現構建網絡結構,卷積層用來提取輸入神經元數據的局部特征,下采樣層用來對其上一層提取的數據進行縮放映射以減少訓練數據量,也使提取的特征具有縮放不變性。一般來說,可以選擇不同尺度的卷積核來提取多尺度特征,使提取的特征具有旋轉、平移不變性。輸入圖像與可學習的核進行卷積,卷積后的數據經過激活函數得到一個特征圖。卷積層的特征圖可以由多個輸入圖組合獲得,但對于同一幅輸入圖其卷積核參數是一致的,這也是權值共享的意義所在。卷積核的初始值并非隨機設置,而是通過訓練或者按照一定標準預先給定,如仿照生物視覺特征用Gabor 濾波器進行預處理。下采樣層通過降低網絡空間分辨率來增強縮放不變性。
CNN的輸出層一般采用線性全連接,目前最常用的就是Softmax 分類方法。CNN的參數訓練過程與傳統的人工神經網絡類似,采用反向傳播算法,包括前向傳播與反向傳播2個重要階段。
CNN實際應用中會遇到諸多問題,如網絡權值的預學習問題,收斂條件以及非全連接規則等,這些均需要實際應用中進一步解決與優化。
卷積神經網絡模型:在無監督預訓練出現之前,訓練深度神經網絡通常非常困難,而其中一個特例是卷積神經網絡。卷積神經網絡受視覺系統的結構啟發而產生。第一個卷積神經網絡計算模型是在Fukushima的神經認知機中提出的,基于神經元之間的局部連接和分層組織圖像轉換,將有相同參數的神經元應用于前一層神經網絡的不同位置,得到一種平移不變神經網絡結構形式。后來,LeCun等人在該思想的基礎上,用誤差梯度設計并訓練卷積神經網絡,在一些模式識別任務上得到優越的性能。至今,基于卷積神經網絡的模式識別系統是最好的實現系統之一,尤其在手寫體字符識別任務上表現出非凡的性能。LeCun的卷積神經網絡由卷積層和子抽樣層兩種類型的神經網絡層組成。每一層有一個拓撲圖結構,即在接收域內,每個神經元與輸入圖像中某個位置對應的固定二維位置編碼信息關聯。在每層的各個位置分布著許多不同的神經元,每個神經元有一組輸入權值,這些權值與前一層神經網絡矩形塊中的神經元關聯;同一組權值和不同輸入矩形塊與不同位置的神經元關聯。卷積神經網絡是多層的感知器神經網絡,每層由多個二維平面塊組成,每個平面塊由多個獨立神經元組成。為了使網絡對平移、旋轉、比例縮放以及其他形式的變換具有不變性,對網絡的結構進行一些約束限制:(1)、特征提取:每一個神經元從上一層的局部接收域得到輸入,迫使其提取局部特征。(2)、特征映射:網絡的每一個計算層由多個特征映射組成,每個特征映射都以二維平面的形式存在,平面中的神經元在約束下共享相同的權值集。(3)、子抽樣:該計算層跟隨在卷積層后,實現局部平均和子抽樣,使特征映射的輸出對平移等變換的敏感度下降。卷積神經網絡通過使用接收域的局部連接,限制了網絡結構。卷積神經網絡的另一個特點是權值共享,但是由于同一隱層的神經元共享同一權值集,大大減少了自由參數的數量。卷積神經網絡本質上實現一種輸入到輸出的映射關系,能夠學習大量輸入與輸出之間的映射關系,不需要任何輸入和輸出之間的精確數學表達式,只要用已知的模式對卷積神經網絡加以訓練,就可以使網絡具有輸入輸出之間的映射能力。卷積神經網絡執行的是有監督訓練,在開始訓練前,用一些不同的小隨機數對網絡的所有權值進行初始化。
卷積神經網絡的訓練分為兩個階段:(1)、向前傳播階段:從樣本集中抽取一個樣本(X,Yp),將x輸入給網絡,信息從輸入層經過逐級變換傳送到輸出層,計算相應的實際輸出Op;(2)、向后傳播階段:也稱為誤差傳播階段。計算實際輸出Op與理想輸出Yp的差異。并按最小化誤差的方法調整權值矩陣。
卷積神經網絡的特征檢測層通過訓練數據來進行學習,避免了顯式的特征提取,而是隱式地從訓練數據中學習特征,而且同一特征映射面上的神經元權值相同,網絡可以并行學習,這也是卷積神經網絡相對于其他神經網絡的一個優勢。權值共享降低了網絡的復雜性,特別是多維向量的圖像可以直接輸入網絡這一特點避免了特征提取和分類過程中數據重建的復雜度。
卷積神經網絡的成功依賴于兩個假設:(1)、每個神經元有非常少的輸入,這有助于將梯度在盡可能多的層中進行傳播;(2)、分層局部連接結構是非常強的先驗結構,特別適合計算機視覺任務,如果整個網絡的參數處于合適的區域,基于梯度的優化算法能得到很好的學習效果。卷積神經網絡的網絡結構更接近實際的生物神經網絡,在語音識別和圖像處理方面具有獨特的優越性,尤其是在視覺圖像處理領域進行的實驗,得到了很好的結果。
2、 反饋深度網絡
與前饋網絡不同,反饋網絡并不是對輸入信號進行編碼,而是通過解反卷積或學習數據集的基,對輸入信號進行反解。前饋網絡是對輸入信號進行編碼的過程,而反饋網絡則是對輸入信號解碼的過程。典型的反饋深度網絡有反卷積網絡、層次稀疏編碼網絡等。以反卷積網絡為例,M. D. Zeiler等提出的反卷積網絡模型和Y. LeCun等提出的卷積神經網絡思想類似,但在實際的結構構件和實現方法上有所不同。卷積神經網絡是一種自底向上的方法,該方法的每層輸入信號經過卷積、非線性變換和下采樣3個階段處理,進而得到多層信息。相比之下,反卷積網絡模型的每層信息是自頂向下的,組合通過濾波器組學習得到的卷積特征來重構輸入信號。層次稀疏編碼網絡和反卷積網絡非常相似,只是在反卷積網絡中對圖像的分解采用矩陣卷積的形式,而在稀疏編碼中采用矩陣乘積的方式。
(1)、單層反卷積網絡:反卷積網絡是通過先驗學習,對信號進行稀疏分解和重構的正則化方法。
(2)、反卷積網絡:單層反卷積網絡進行多層疊加,可得到反卷積網絡。多層模型中,在學習濾波器組的同時進行特征圖的推導,第L層的特征圖和濾波器是由第L-1層的特征圖通過反卷積計算分解獲得。反卷積網絡訓練時,使用一組不同的信號y,求解C(y),進行濾波器組f和特征圖z的迭代交替優化。訓練從第1層開始,采用貪心算法,逐層向上進行優化,各層間的優化是獨立的。
(3)、反卷積網絡的特點:反卷積網絡的特點在于,通過求解最優化輸入信號分解問題計算特征,而不是利用編碼器進行近似,這樣能使隱層的特征更加精準,更有利于信號的分類或重建。
自動編碼器:對于一個給定的神經網絡,假設其輸出等于輸入(理想狀態下),然后通過訓練調整其參數得到每一層的權重,這樣就可以得到輸入的幾種不同的表示,這些表示就是特征。當在原有特征的基礎上加入這些通過自動學習得到的特征時,可以大大提高精確度,這就是自動編碼(AutoEncoder)。如果再繼續加上一些約束條件的話,就可以得到新的深度學習方法。比如在自動編碼的基礎上加上稀疏性限制,就可得到稀疏自動編碼器(Sparse AutoEncoder)。
稀疏自動編碼器:與CNN不同,深度自動編碼器是一種無監督的神經網絡學習架構。此類架構的基本結構單元為自動編碼器,它通過對輸入特征X按照一定規則及訓練算法進行編碼,將其原始特征利用低維向量重新表示。自動編碼器通過構建類似傳統神經網絡的層次結構,并假設輸出Y與輸入X相等,反復訓練調整參數得到網絡參數值。上述自編碼器若僅要求X≈Y,且對隱藏神經元進行稀疏約束,從而使大部分節點值為0或接近0的無效值,便得到稀疏自動編碼算法。一般情況下,隱含層的神經元數應少于輸入X的個數,因為此時才能保證這個網絡結構的價值。正如主成分分析(principal component analysis,PCA)算法,通過降低空間維數去除冗余,利用更少的特征來盡可能完整的描述數據信息。實際應用中將學習得到的多種隱層特征(隱層數通常多個)與原始特征共同使用,可以明顯提高算法的識別精度。
自動編碼器參數訓練方法有很多,幾乎可以采用任何連續化訓練方法來訓練參數。但由于其模型結構不偏向生成型,無法通過聯合概率等定量形式確定模型合理性。稀疏性約束在深度學習算法優化中的地位越來越重要,主要與深度學習特點有關。大量的訓練參數使訓練過程復雜,且訓練輸出的維數遠比輸入的維數高,會產生許多冗余數據信息。加入稀疏性限制,會使學習到的特征更加有價值,同時這也符合人腦神經元響應稀疏性特點。
3、 雙向深度網絡
雙向網絡由多個編碼器層和解碼器層疊加形成,每層可能是單獨的編碼過程或解碼過程,也可能同時包含編碼過程和解碼過程。雙向網絡的結構結合了編碼器和解碼器2類單層網絡結構,雙向網絡的學習則結合了前饋網絡和反饋網絡的訓練方法,通常包括單層網絡的預訓練和逐層反向迭代誤差2個部分,單層網絡的預訓練多采用貪心算法:每層使用輸入信號IL與權值w計算生成信號IL+1傳遞到下一層,信號IL+1再與相同的權值w計算生成重構信號I‘L 映射回輸入層,通過不斷縮小IL與I’L間的誤差,訓練每層網絡。網絡結構中各層網絡結構都經過預訓練之后,再通過反向迭代誤差對整個網絡結構進行權值微調。其中單層網絡的預訓練是對輸入信號編碼和解碼的重建過程,這與反饋網絡訓練方法類似;而基于反向迭代誤差的權值微調與前饋網絡訓練方法類似。典型的雙向深度網絡有深度玻爾茲曼機、深度信念網絡、棧式自編碼器等。以深度玻爾茲曼機為例,深度玻爾茲曼機由R. Salakhutdinov等提出,它由多層受限玻爾茲曼機(restricted Boltzmann machine, RBM )疊加構成。
(1)、受限玻爾茲曼機:玻爾茲曼機(Boltzmann machine, BM)是一種隨機的遞歸神經網絡,由G. E.Hinton等提出,是能通過學習數據固有內在表示、解決復雜學習問題的最早的人工神經網絡之一。玻爾茲曼機由二值神經元構成,每個神經元只取0或1兩種狀態,狀態1代表該神經元處于激活狀態,0表示該神經元處于抑制狀態。然而,即使使用模擬退火算法,這個網絡的學習過程也十分慢。Hinton等提出的受限玻爾茲曼機去掉了玻爾茲曼機同層之間的連接,從而大大提高了學習效率。受限玻爾茲曼機分為可見層v以及隱層h,可見層和隱層的節點通過權值w相連接,2層節點之間是全連接,同層節點間互不相連。
受限玻爾茲曼機一種典型的訓練方法:首先隨機初始化可見層,然后在可見層與隱層之間交替進行吉布斯采樣:用條件分布概率P(h|v)計算隱層;再根據隱層節點,同樣用條件分布概率P(v|h)來計算可見層;重復這一采樣過程直到可見層和隱層達到平穩分布。而Hinton提出了一種快速算法,稱作對比離差(contrastive divergence, CD)學習算法。這種算法使用訓練數據初始化可見層,只需迭代k次上述采樣過程(即每次迭代包括從可見層更新隱層,以及從隱層更新可見層),就可獲得對模型的估計。
(2)、深度玻爾茲曼機:將多個受限玻爾茲曼機堆疊,前一層的輸出作為后一層的輸入,便構成了深度玻爾茲曼機。網絡中所有節點間的連線都是雙向的。深度玻爾茲曼機訓練分為2個階段:預訓練階段和微調階段。在預訓練階段,采用無監督的逐層貪心訓練方法來訓練網絡每層的參數,即先訓練網絡的第1個隱含層,然后接著訓練第2,3,…個隱含層,最后用這些訓練好的網絡參數值作為整體網絡參數的初始值。預訓練之后,將訓練好的每層受限玻爾茲曼機疊加形成深度玻爾茲曼機,利用有監督的學習對網絡進行訓練(一般采用反向傳播算法)。由于深度玻爾茲曼機隨機初始化權值以及微調階段采用有監督的學習方法,這些都容易使網絡陷入局部最小值。而采用無監督預訓練的方法,有利于避免陷入局部最小值問題。
受限玻爾茲曼機(RBM,RestrictBoltzmann Machine):假設有一個二部圖(二分圖),一層是可視層v(即輸入層),一層是隱層h,每層內的節點之間設有連接。在已知v時,全部的隱藏節點之間都是條件獨立的(因為這個模型是二部圖),即p(h|v) = p(h1|v1) … p(hn|v)。同樣的,在已知隱層h的情況下,可視節點又都是條件獨立的,又因為全部的h和v滿足玻爾茲曼分布,所以當輸入v的時候,通過p(h|v)可得到隱層h,得到h之后,通過p(v|h)又可以重構可視層v。通過調整參數,使得從隱層計算得到的可視層與原來的可視層有相同的分布。這樣的話,得到的隱層就是可視層的另外一種表達,即可視層的特征表示。若增加隱層的層數,可得到深度玻爾茲曼機(DBM,Deep Boltzmann Machine)。若在靠近可視層v的部分使用貝葉斯信念網,遠離可視層的部分使用RBM,那么就可以得到一個深度信念網絡(DBNs,Deep Belief Nets)。
受限玻爾茲曼機模型是玻爾茲曼機(BM,BoltzmannMachine)模型的一種特殊形式,其特殊性就在于同層內的節點沒有連接,是以二部圖的形式存在。
由于受限玻爾茲曼機是一種隨機網絡,而隨機神經網絡又是根植于統計力學的,所以受統計力學能量泛函的啟發引入了能量函數。在隨機神經網絡中,能量函數是用來描述整個系統狀態的測度。網絡越有序或概率分布越集中,網絡的能量就越小;反之,網絡越無序或概率分布不集中,那么網絡的能量就越大。所以當網絡最穩定時,能量函數的值最小。
深度信念神經網絡:深度結構的訓練大致有無監督的訓練和有監督的訓練兩種,而且兩者擁有不一樣的模型架構。比如卷積神經網絡就是一種有監督下的深度結構學習模型(即需要大量有標簽的訓練樣本),但深度信念網絡是一種無監督和有監督混合下的深度結構學習模型(即需要一部分無標簽的訓練樣本和一部分有標簽的樣本)。
一個典型的深度信念網絡可看成多個受限玻爾茲曼機的累加,而DBNs則是一個復雜度較高的有向無環圖。
深度信念網絡在訓練的過程中,所需要學習的即是聯合概率分布。在機器學習領域中,其所表示的就是對象的生成模型。如果想要全局優化具有多隱層的深度信念網絡是比較困難的。這個時候,可以運用貪婪算法,即逐層進行優化,每次只訓練相鄰兩層的模型參數,通過逐層學習來獲得全局的網絡參數。這種訓練方法(非監督逐層貪婪訓練)已經被Hinton證明是有效的,并稱其為相對收斂(contrastive divergence)。
深度信任網絡模型:DBN可以解釋為貝葉斯概率生成模型,由多層隨機隱變量組成,上面的兩層具有無向對稱連接,下面的層得到來自上一層的自頂向下的有向連接,最底層單元的狀態為可見輸入數據向量。DBN由若干結構單元堆棧組成,結構單元通常為RBM。堆棧中每個RBM單元的可視層神經元數量等于前一RBM單元的隱層神經元數量。根據深度學習機制,采用輸入樣例訓練第一層RBM單元,并利用其輸出訓練第二層RBM模型,將RBM模型進行堆棧通過增加層來改善模型性能。在無監督預訓練過程中,DBN編碼輸入到頂層RBM后解碼頂層的狀態到最底層的單元實現輸入的重構。作為DBN的結構單元,RBM與每一層DBN共享參數。
RBM是一種特殊形式的玻爾茲曼機(Boltzmannmachine,BM),變量之間的圖模型連接形式有限制,只有可見層節點與隱層節點之間有連接權值,而可見層節點與可見層節點及隱層節點與隱層節點之間無連接。BM是基于能量的無向圖概率模型。
BM的典型訓練算法有變分近似法、隨機近似法(stochastic approximation procedure,SAP)、對比散度算法(contrastivedivergence,CD)、持續對比散度算法(persistent contrastive divergence,PCD)、快速持續對比散度算法(fastpersistent contrastive divergence,FPCD)和回火MCMC算法等。
堆棧自編碼網絡模型:堆棧自編碼網絡的結構與DBN類似,由若干結構單元堆棧組成,不同之處在于其結構單元為自編碼模型(auto—en—coder)而不是RBM。自編碼模型是一個兩層的神經網絡,第一層稱為編碼層,第二層稱為解碼層。
堆棧自編碼網絡的結構單元除了自編碼模型之外,還可以使用自編碼模型的一些變形,如降噪自編碼模型和收縮自編碼模型等。降噪自編碼模型避免了一般的自編碼模型可能會學習得到無編碼功能的恒等函數和需要樣本的個數大于樣本的維數的限制,嘗試通過最小化降噪重構誤差,從含隨機噪聲的數據中重構真實的原始輸入。降噪自編碼模型使用由少量樣本組成的微批次樣本執行隨機梯度下降算法,這樣可以充分利用圖處理單元(graphical processing unit,GPU)的矩陣到矩陣快速運算使得算法能夠更快地收斂。
收縮自編碼模型的訓練目標函數是重構誤差和收縮罰項(contraction penalty)的總和,通過最小化該目標函數使已學習到的表示C(x)盡量對輸入x保持不變。為了避免出現平凡解,編碼器權值趨于零而解碼器權值趨于無窮,并且收縮自編碼模型采用固定的權值,令解碼器權值為編碼器權值的置換陣。與其他自編碼模型相比,收縮自編碼模型趨于找到盡量少的幾個特征值,特征值的數量對應局部秩和局部維數。收縮自編碼模型可以利用隱單元建立復雜非線性流形模型。
MKMs:受SVM算法中核函數的啟發,在深度模型結構中加入核函數,構建一種基于核函數的深度學習模型。MKMs深度模型,如同深度信念網絡(deep belief network,DBNs),反復迭代核PCA 來逼近高階非線性函數,每一層核PCA 的輸出作為下一層核PCA 的輸入。作者模擬大型神經網絡計算方法創建核函數族,并將其應用在訓練多層深度學習模型中。L層MKMs深度模型的訓練過程如下:
(1)、去除輸入特征中無信息含量的特征;
(2)、重復L次:A、計算有非線性核產生特征的主成分;B、去除無信息含量的主成分特征;
(3)、采用Mahalanobis距離進行最近鄰分類。
在參數訓練階段,采用核主成分分析法(kernelprincipal component analysis,KPCA)進行逐層貪婪無監督學習,并提取第k層數據特征中的前nk 主成分,此時第k+1層便獲得第k層的低維空間特征。為進一步降低每層特征的維數,采用有監督的訓練機制進行二次篩選:首先,根據離散化特征點邊緣直方圖,估計它與類標簽之間的互信息,將nk 主成分進行排序;其次,對于不同的k 和w 采用KNN 聚類方法,每次選取排序最靠前的w驗證集上的特征并計算其錯誤率,最終選擇錯誤率最低的w個特征。該模型由于特征選取階段無法并行計算,導致交叉驗證階段需耗費大量時間。據此,提出了一種改進方法,通過在隱藏層采用有監督的核偏最小二乘法(kernel partial least squares,KPLS)來優化此問題。
DeSTIN:目前較成熟的深度學習模型大多建立在空間層次結構上,很少對時效性(temporal)有所體現。相關研究表明,人類大腦的運行模式是將感受到的模式與記憶存儲的模式進行匹配,并對下一時刻的模式進行預測,反復進行上述步驟,這個過程包含了時空信息。因此在深度結構中將時效性考慮在內,會更接近人腦的工作模式。DeSTIN便是基于這種理念被提出的。DeSTIN 是一種基于貝葉斯推理理論、動態進行模式分類的深度學習架構,它是一種區分性的層次網絡結構。在該深度模型中,數據間的時空相關性通過無監督方式來學習。網絡的每一層的每個節點結構一致,且包含多個聚類中心,通過聚類和動態建模來模擬輸入。每個節點通過貝葉斯信念推理輸出該節點信念值,根據信念值提取整個DeSTIN網絡的模式特征,最后一層網絡輸出特征可以輸入分類器如SVM中進行模式分類。
DeSTIN 模型的每一個節點都用來學習一個模式時序,底層節點通過對輸入數據的時間與空間特征進行提取,改變其信念值,輸入到下一層。由于每一個節點結構相同,訓練時可采樣并行計算,節約運算資源。該模型最重要的步驟就是信念值更新算法。信念值更新算法同時考慮了數據的時間與空間特征。目前將時效性考慮在內的深度學習架構雖然不是很成熟,但也逐漸應用在不同領域,也是深度學習模型未來發展的一個新方向。
四、 深度學習訓練算法
實驗結果表明,對深度結構神經網絡采用隨機初始化的方法,基于梯度的優化使訓練結果陷入局部極值,而找不到全局最優值,并且隨著網絡結構層次的加深,更難以得到好的泛化性能,使得深度結構神經網絡在隨機初始化后得到的學習結果甚至不如只有一個或兩個隱層的淺結構神經網絡得到的學習結果好。由于隨機初始化深度結構神經網絡的參數得到的訓練結果和泛化性能都很不理想,在2006年以前,深度結構神經網絡在機器學習領域文獻中并沒有進行過多討論。通過實驗研究發現,用無監督學習算法對深度結構神經網絡進行逐層預訓練,能夠得到較好的學習結果。最初的實驗對每層采用RBM生成模型,后來的實驗采用自編碼模型來訓練每一層,兩種模型得到相似的實驗結果。一些實驗和研究結果證明了無監督預訓練相比隨機初始化具有很大的優勢,無監督預訓練不僅初始化網絡得到好的初始參數值,而且可以提取關于輸入分布的有用信息,有助于網絡找到更好的全局最優解。對深度學習來說,無監督學習和半監督學習是成功的學習算法的關鍵組成部分,主要原因包括以下幾個方面:
(1)、與半監督學習類似,深度學習中缺少有類標簽的樣本,并且樣例大多無類標簽;
(2)、逐層的無監督學習利用結構層上的可用信息進行學習,避免了監督學習梯度傳播的問題,可減少對監督準則函數梯度給出的不可靠更新方向的依賴;
(3)、無監督學習使得監督學習的參數進入一個合適的預置區域內,在此區域內進行梯度下降能夠得到很好的解;
(4)、在利用深度結構神經網絡構造一個監督分類器時,無監督學習可看做學習先驗信息,使得深度結構神經網絡訓練結果的參數在大多情況下都具有意義;
(5)、在深度結構神經網絡的每一層采用無監督學習將一個問題分解成若干與多重表示水平提取有關的子問題,是一種常用的可行方法,可提取輸入分布較高水平表示的重要特征信息。
基于上述思想,Hinton等人在2006年引入了DBN并給出了一種訓練該網絡的貪婪逐層預訓練算法。貪婪逐層無監督預訓練學習的基本思想為:首先采用無監督學習算法對深度結構神經網絡的較低層進行訓練,生成第一層深度結構神經網絡的初始參數值;然后將第一層的輸出作為另外一層的輸入,同樣采用無監督學習算法對該層參數進行初始化。在對多層進行初始化后,用監督學習算法對整個深度結構神經網絡進行微調,得到的學習性能具有很大程度的提高。
以堆棧自編碼網絡為例,深度結構神經網絡的訓練過程如下:
(1)、將第一層作為一個自編碼模型,采用無監督訓練,使原始輸入的重建誤差最小;
(2)、將自編碼模型的隱單元輸出作為另一層的輸入;
(3)、按步驟(2)迭代初始化每一層的參數;
(4)、采用最后一個隱層的輸出作為輸入施加于一個有監督的層(通常為輸出層),并初始化該層的參數;
(5)、根據監督準則調整深度結構神經網絡的所有參數,堆棧所有自編碼模型組成堆棧自編碼網絡。
基本的無監督學習方法在2006年被Hinton等人提出用于訓練深度結構神經網絡,該方法的學習步驟如下:
(1)、令h0(x)=x為可觀察的原始輸入x的最低階表示;
(2)、對l=1,。..,L,訓練無監督學習模型,將可觀察數據看做l-1階上表示的訓練樣例hl-1(x),訓練后產生下一階的表示hl(x)=Rl(hl-1(x))。
隨后出現了一些該算法的變形拓展,最常見的是有監督的微調方法,該方法的學習步驟如下所示:
(1)、初始化監督預測器:a、用參數表示函數hL(x);b、將hL(x)作為輸入得到線性或非線性預測器;
(2)、基于已標記訓練樣本對(x,y)采用監督訓練準則微調監督預測器,在表示階段和預測器階段優化參數。
深度學習的訓練過程:
1、自下向上的非監督學習:采用無標簽數據分層訓練各層參數,這是一個無監督訓練的過程(也是一個特征學習的過程),是和傳統神經網絡區別最大的部分。具體是:用無標簽數據去訓練第一層,這樣就可以學習到第一層的參數,在學習得到第n-1層后,再將第n-1層的輸出作為第n層的輸入,訓練第n層,進而分別得到各層的參數。這稱為網絡的預訓練。
2、自頂向下的監督學習:在預訓練后,采用有標簽的數據來對網絡進行區分性訓練,此時誤差自頂向下傳輸。預訓練類似傳統神經網絡的隨機初始化,但由于深度學習的第一步不是隨機初始化而是通過學習無標簽數據得到的,因此這個初值比較接近全局最優,所以深度學習效果好很多程序上歸功于第一步的特征學習過程。
使用到的學習算法包括:
(1)、深度費希爾映射方法:Wong等人提出一種新的特征提取方法----正則化深度費希爾映射(regularized deep Fisher mapping,RDFM)方法,學習從樣本空間到特征空間的顯式映射,根據Fisher準則用深度結構神經網絡提高特征的區分度。深度結構神經網絡具有深度非局部學習結構,從更少的樣本中學習變化很大的數據集中的特征,顯示出比核方法更強的特征識別能力,同時RDFM方法的學習過程由于引入正則化因子,解決了學習能力過強帶來的過擬合問題。在各種類型的數據集上進行實驗,得到的結果說明了在深度學習微調階段運用無監督正則化的必要性。
(2)、非線性變換方法:Raiko等人提出了一種非線性變換方法,該變換方法使得多層感知器(multi—layer perceptron,MLP)網絡的每個隱神經元的輸出具有零輸出和平均值上的零斜率,使學習MLP變得更容易。將學習整個輸入輸出映射函數的線性部分和非線性部分盡可能分開,用shortcut權值(shortcut weight)建立線性映射模型,令Fisher信息陣接近對角陣,使得標準梯度接近自然梯度。通過實驗證明非線性變換方法的有效性,該變換使得基本隨機梯度學習與當前的學習算法在速度上不相上下,并有助于找到泛化性能更好的分類器。用這種非線性變換方法實現的深度無監督自編碼模型進行圖像分類和學習圖像的低維表示的實驗,說明這些變換有助于學習深度至少達到五個隱層的深度結構神經網絡,證明了變換的有效性,提高了基本隨機梯度學習算法的速度,有助于找到泛化性更好的分類器。
(3)、稀疏編碼對稱機算法:Ranzato等人提出一種新的有效的無監督學習算法----稀疏編碼對稱機(sparse encoding symmetric machine,SESM),能夠在無須歸一化的情況下有效產生稀疏表示。SESM的損失函數是重構誤差和稀疏罰函數的加權總和,基于該損失函數比較和選擇不同的無監督學習機,提出一種相關的迭代在線學習算法,并在理論和實驗上將SESM與RBM和PCA進行比較,在手寫體數字識別MNIST數據集和實際圖像數據集上進行實驗,表明該方法的優越性。
(4)、遷移學習算法:在許多常見學習場景中訓練和測試數據集中的類標簽不同,必須保證訓練和測試數據集中的相似性進行遷移學習。Mesnil等人研究了用于無監督遷移學習場景中學習表示的不同種類模型結構,將多個不同結構的層堆棧使用無監督學習算法用于五個學習任務,并研究了用于少量已標記訓練樣本的簡單線性分類器堆棧深度結構學習算法。Bengio等人研究了無監督遷移學習問題,討論了無監督預訓練有用的原因,如何在遷移學習場景中利用無監督預訓練,以及在什么情況下需要注意從不同數據分布得到的樣例上的預測問題。
(5)、自然語言解析算法:Collobert基于深度遞歸卷積圖變換網絡(graphtransformer network,GTN)提出一種快速可擴展的判別算法用于自然語言解析,將文法解析樹分解到堆棧層中,只用極少的基本文本特征,得到的性能與現有的判別解析器和標準解析器的性能相似,而在速度上有了很大提升。
(6)、學習率自適應方法:學習率自適應方法可用于提高深度結構神經網絡訓練的收斂性并且去除超參數中的學習率參數,其中包括全局學習率、層次學習率、神經元學習率和參數學習率等。最近研究人員提出了一些新的學習率自適應方法,如Duchi等人提出的自適應梯度方法和Schaul等人提出的學習率自適應方法;Hinton提出了收縮學習率方法使得平均權值更新在權值大小的1/1000數量級上;LeRoux等人提出自然梯度的對角低秩在線近似方法,并說明該算法在一些學習場景中能加速訓練過程。
五、 深度學習的優點
深度學習與淺學習相比具有許多優點:
1、 在網絡表達復雜目標函數的能力方面,淺結構神經網絡有時無法很好地實現高變函數等復雜高維函數的表示,而用深度結構神經網絡能夠較好地表征。
2、 在網絡結構的計算復雜度方面,當用深度為k的網絡結構能夠緊湊地表達某一函數時,在采用深度小于k的網絡結構表達該函數時,可能需要增加指數級規模數量的計算因子,大大增加了計算的復雜度。另外,需要利用訓練樣本對計算因子中的參數值進行調整,當一個網絡結構的訓練樣本數量有限而計算因子數量增加時,其泛化能力會變得很差。
3、 在仿生學角度方面,深度學習網絡結構是對人類大腦皮層的最好模擬。與大腦皮層一樣,深度學習對輸入數據的處理是分層進行的,用每一層神經網絡提取原始數據不同水平的特征。
4、 在信息共享方面,深度學習獲得的多重水平的提取特征可以在類似的不同任務中重復使用,相當于對任務求解提供了一些無監督的數據,可以獲得更多的有用信息。
5、 深度學習比淺學習具有更強的表示能力,而由于深度的增加使得非凸目標函數產生的局部最優解是造成學習困難的主要因素。反向傳播基于局部梯度下降,從一些隨機初始點開始運行,通常陷入局部極值,并隨著網絡深度的增加而惡化,不能很好地求解深度結構神經網絡問題。2006年,Hinton等人提出的用于深度信任網絡(deep belief network,DBN)的無監督學習算法,解決了深度學習模型優化困難的問題。求解DBN方法的核心是貪婪逐層預訓練算法,在與網絡大小和深度呈線性的時間復雜度上優化DBN的權值,將求解的問題分解成為若干更簡單的子問題進行求解。
6、 深度學習方法試圖找到數據的內部結構,發現變量之間的真正關系形式。大量研究表明,數據表示的方式對訓練學習的成功產生很大的影響,好的表示能夠消除輸入數據中與學習任務無關因素的改變對學習性能的影響,同時保留對學習任務有用的信息。深度學習中數據的表示有局部表示(local representation)、分布表示(distributed representation),和稀疏分布表示(sparsedistributed representation) 三種表示形式。學習輸入層、隱層和輸出層的單元均取值0或1。舉個簡單的例子,整數i∈{1,2,。..,N}的局部表示為向量R(i),該向量有N位,由1個1和N-1個0組成,即Rj(i)=1i=j。分布表示中的輸入模式由一組特征表示,這些特征可能存在相互包含關系,并且在統計意義上相互獨立。對于例子中相同整數的分布表示有log2N位的向量,這種表示更為緊湊,在解決降維和局部泛化限制方面起到幫助作用。稀疏分布表示介于完全局部表示和非稀疏分布表示之間,稀疏性的意思為表示向量中的許多單元取值為0。對于特定的任務需要選擇合適的表示形式才能對學習性能起到改進的作用。當表示一個特定的輸入分布時,一些結構是不可能的,因為它們不相容。例如在語言建槨中,運用局部表示可以直接用詞匯表中的索引編碼詞的特性,而在句法特征、形態學特征和語義特征提取中,運用分布表示可以通過連接一個向量指示器來表示一個詞。分布表示由于其具有的優點,常常用于深度學習中表示數據的結構。由于聚類簇之間在本質上互相不存在包含關系,因此聚類算法不專門建立分布表示,而獨立成分分析(independent component analysis,ICA)和主成分分析(principalcomponent analysis,PCA)通常用來構造數據的分布表示。
六、 深度學習已有的應用
深度學習架構由多層非線性運算單元組成,每個較低層的輸出作為更高層的輸入,可以從大量輸入數據中學習有效的特征表示,學習到的高階表示中包含輸入數據的許多結構信息,是一種從數據中提取表示的好方法,能夠用于分類、回歸和信息檢索等特定問題中。
深度學習目前在很多領域都優于過去的方法。如語音和音頻識別、圖像分類及識別、人臉識別、視頻分類、行為識別、圖像超分辨率重建、紋理識別、行人檢測、場景標記、門牌識別、手寫體字符識別、圖像檢索、人體運行行為識別等。
1、 深度學習在語音識別、合成及機器翻譯中的應用
微軟研究人員使用深度信念網絡對數以千計的senones(一種比音素小很多的建模單元)直接建模,提出了第1個成功應用于大詞匯量語音識別系統的上下文相關的深層神經網絡--隱馬爾可夫混合模型(CD-DNN-HMM),比之前最領先的基于常規CD-GMM-HMM的大詞匯量語音識別系統相對誤差率減少16%以上。隨后又在含有300h語音訓練數據的Switchboard標準數據集上對CD-DNN-HMM模型進行評測。基準測試字詞錯誤率為18.5%,與之前最領先的常規系統相比,相對錯誤率減少了33%。
H. Zen等提出一種基于多層感知機的語音合成模型。該模型先將輸入文本轉換為一個輸入特征序列,輸入特征序列的每幀分別經過多層感知機映射到各自的輸出特征,然后采用算法,生成語音參數,最后經過聲紋合成生成語音。訓練數據包含由一名女性專業演講者以美國英語錄制的3.3萬段語音素材,其合成結果的主觀評價和客觀評價均優于基于HMM方法的模型。
K. Cho等提出一種基于循環神經網絡(recurrentneural network, RNN)的向量化定長表示模型(RNNenc模型),應用于機器翻譯。該模型包含2個RNN,一個RNN用于將一組源語言符號序列編碼為一組固定長度的向量,另一個RNN將該向量解碼為一組目標語言的符號序列。在該模型的基礎上,D. Bahdanau等克服了固定長度的缺點(固定長度是其效果提升的瓶頸),提出了RNNsearch的模型。該模型在翻譯每個單詞時,根據該單詞在源文本中最相關信息的位置以及已翻譯出的其他單詞,預測對應于該單詞的目標單詞。該模型包含一個雙向RNN作為編碼器,以及一個用于單詞翻譯的解碼器。在進行目標單詞位置預測時,使用一個多層感知機模型進行位置對齊。采用BLEU評價指標,RNNsearch模型在ACL2014機器翻譯研討會(ACL WMT 2014)提供的英/法雙語并行語料庫上的翻譯結果評分均高于RNNenc模型的評分,略低于傳統的基于短語的翻譯系統Moses(本身包含具有4.18 億個單詞的多語言語料庫)。另外,在剔除包含未知詞匯語句的測試預料庫上,RNNsearch的評分甚至超過了Moses。
2、 深度學習在圖像分類及識別中的應用
(1)、深度學習在大規模圖像數據集中的應用:
A. Krizhevsky等首次將卷積神經網絡應用于ImageNet大規模視覺識別挑戰賽(ImageNetlargescale visual recognition challenge, ILSVRC)中,所訓練的深度卷積神經網絡在ILSVRC—2012挑戰賽中,取得了圖像分類和目標定位任務的第一。其中,圖像分類任務中,前5選項錯誤率為15.3%,遠低于第2名的26.2%的錯誤率;在目標定位任務中,前5選項錯誤率34%,也遠低于第2名的50%。在ILSVRC—2013比賽中,M. D. Zeiler等采用卷積神經網絡的方法,對A. Krizhevsky的方法進行了改進,并在每個卷積層上附加一個反卷積層用于中間層特征的可視化,取得了圖像分類任務的第一名。其前5 選項錯誤率為11.7%,如果采用ILSVRC—2011 數據進行預訓練,錯誤率則降低到11.2%。在目標定位任務中,P. Sermanet等采用卷積神經網絡結合多尺度滑動窗口的方法,可同時進行圖像分類、定位和檢測,是比賽中唯一一個同時參加所有任務的隊伍。多目標檢測任務中,獲勝隊伍的方法在特征提取階段沒有使用深度學習模型,只在分類時采用卷積網絡分類器進行重打分。在ILSVRC—2014比賽中,幾乎所有的參賽隊伍都采用了卷積神經網絡及其變形方法。其中GoogLeNet小組采用卷積神經網絡結合Hebbian理論提出的多尺度的模型,以6.7%的分類錯誤,取得圖形分類“指定數據”組的第一名;CASIAWS小組采用弱監督定位和卷積神經網絡結合的方法,取得圖形分類“額外數據”組的第一名,其分類錯誤率為11%。
在目標定位任務中,VGG小組在深度學習框架Caffe的基礎上,采用3個結構不同的卷積神經網絡進行平均評估,以26%的定位錯誤率取得“指定數據”組的第一名;Adobe 組選用額外的2000類ImageNet數據訓練分類器,采用卷積神經網絡架構進行分類和定位,以30%的錯誤率,取得了“額外數據”組的第一名。
在多目標檢測任務中,NUS小組采用改進的卷積神經網絡----網中網(networkin network, NIN)與多種其他方法融合的模型,以37%的平均準確率(mean average precision, mAP)取得“提供數據”組的第一名;GoogLeNet以44%的平均準確率取得“額外數據”組的第一名。
從深度學習首次應用于ILSVRC挑戰賽并取得突出的成績,到2014年挑戰賽中幾乎所有參賽隊伍都采用深度學習方法,并將分類識錯率降低到6.7%,可看出深度學習方法相比于傳統的手工提取特征的方法在圖像識別領域具有巨大優勢。
(2)、深度學習在人臉識別中的應用:
基于卷積神經網絡的學習方法,香港中文大學的DeepID項目以及Facebook的DeepFace項目在戶外人臉識別(labeledfaces in the wild, LFW)數據庫上的人臉識別正確率分別達97.45%和97.35%,只比人類識別97.5%的正確率略低一點點。DeepID項目采用4層卷積神經網絡(不含輸入層和輸出層)結構,DeepFace采用5層卷積神經網絡(不含輸入層和輸出層,其中后3層沒有采用權值共享以獲得不同的局部統計特征)結構,之后,采用基于卷積神經網絡的學習方法。香港中文大學的DeepID2項目將識別率提高到了99.15%,超過目前所有領先的深度學習和非深度學習算法在LFW 數據庫上的識別率以及人類在該數據庫的識別率。DeepID2項目采用和DeepID項目類似的深度結構,包含4個卷積層,其中第3層采用2*2鄰域的局部權值共享,第4層沒有采用權值共享,且輸出層與第3、4層都全連接。
(3)、深度學習在手寫體字符識別中的應用:
Bengio等人運用統計學習理論和大量的實驗工作證明了深度學習算法非常具有潛力,說明數據中間層表示可以被來自不同分布而相關的任務和樣例共享,產生更好的學習效果,并且在有62個類別的大規模手寫體字符識別場景上進行實驗,用多任務場景和擾動樣例來得到分布外樣例,并得到非常好的實驗結果。Lee等人對RBM進行拓展,學習到的模型使其具有稀疏性,可用于有效地學習數字字符和自然圖像特征。Hinton等人關于深度學習的研究說明了如何訓練深度s型神經網絡來產生對手寫體數字文本有用的表示,用到的主要思想是貪婪逐層預訓練RBM之后再進行微調。
3、 深度學習在行人檢測中的應用
將CNN應用到行人檢測中,提出一種聯合深度神經網絡模型(unified deep net,UDN)。輸入層有3個通道,均為對YUV空間進行相關變換得到,實驗結果表明在此實驗平臺前提下,此輸入方式較灰色像素輸入方式正確率提高8%。第一層卷積采用64個不同卷積核,初始化采用Gabor濾波器,第二層卷積采用不同尺度的卷積核,提取人體的不同部位的具體特征,訓練過程作者采用聯合訓練方法。最終實驗結果在Caltech及ETH 數據集上錯失率較傳統的人體檢測HOG-SVM算法均有明顯下降,在Caltech庫上較目前最好的算法錯失率降低9%。
4、 深度學習在視頻分類及行為識別中的應用
A. Karpathy等基于卷積神經網絡提供了一種應用于大規模視頻分類上的經驗評估模型,將Sports-1M數據集的100萬段YouTube視頻數據分為487類。該模型使用4種時空信息融合方法用于卷積神經網絡的訓練,融合方法包括單幀(single frame)、不相鄰兩幀(late fusion)、相鄰多幀(early fusion)以及多階段相鄰多幀(slow fusion);此外提出了一種多分辨率的網絡結構,大大提升了神經網絡應用于大規模數據時的訓練速度。該模型在Sports-1M上的分類準確率達63.9%,相比于基于人工特征的方法(55.3%),有很大提升。此外,該模型表現出較好的泛化能力,單獨使用slow fusion融合方法所得模型在UCF-101動作識別數據集上的識別率為65.4%,而該數據集的基準識別率為43.9%。
S. Ji等提出一個三維卷積神經網絡模型用于行為識別。該模型通過在空間和時序上運用三維卷積提取特征,從而獲得多個相鄰幀間的運動信息。該模型基于輸入幀生成多個特征圖通道,將所有通道的信息結合獲得最后的特征表示。該三維卷積神經網絡模型在TRECVID數據上優于其他方法,表明該方法對于真實環境數據有較好的效果;該模型在KTH數據上的表現,遜于其他方法,原因是為了簡化計算而縮小了輸入數據的分辨率。
M. Baccouche等提出一種時序的深度學習模型,可在沒有任何先驗知識的前提下,學習分類人體行為。模型的第一步,是將卷積神經網絡拓展到三維,自動學習時空特征。接下來使用RNN方法訓練分類每個序列。該模型在KTH上的測試結果優于其他已知深度模型,KTH1和KTH2上的精度分別為94.39%和92.17%。
七、 深度學習存在的問題及未來研究方向
1、 深度學習目前存在的問題:
(1)、理論問題:深度學習在理論方面存在的困難主要有兩個,第一個是關于統計學習,另一個和計算量相關。相對淺層學習模型來說,深度學習模型對非線性函數的表示能力更好。根據通用的神經網絡逼近理論,對任何一個非線性函數來說,都可以由一個淺層模型和一個深度學習模型很好的表示,但相對淺層模型,深度學習模型需要較少的參數。關于深度學習訓練的計算復雜度也是我們需要關心的問題,即我們需要多大參數規模和深度的神經網絡模型去解決相應的問題,在對構建好的網絡進行訓練時,需要多少訓練樣本才能足以使網絡滿足擬合狀態。另外,網絡模型訓練所需要消耗的計算資源很難預估,對網絡的優化技術仍有待進步。由于深度學習模型的代價函數都是非凸的,這也造成理論研究方面的困難。
(2)、建模問題:在解決深層學習理論和計算困難的同時,如何構建新的分層網絡模型,既能夠像傳統深層模型一樣能夠有效的抽取數據的潛在特征,又能夠像支持向量機一樣便于進行理論分析,另外,如何針對不同的應用問題構建合適的深層模型同樣是一個很有挑戰性的問題。現在用于圖像和語言的深度模型都擁有相似卷積和降采樣的功能模塊,研究人員在聲學模型方面也在進行相應的探索,能不能找到一個統一的深度模型適用于圖像,語音和自然語言的處理仍需要探索。
(3)、工程應用問題:在深度學習的工程應用問題上,如何利用現有的大規模并行處理計算平臺進行大規模樣本數據訓練是各個進行深度學習研發公司首要解決的難題。由于像Hadoop這樣的傳統大數據處理平臺的延遲過高,不適用于深度學習的頻繁迭代訓練過程。現在最多采用的深度網絡訓練技術是隨機梯度下降算法。這種算法不適于在多臺計算機間并行運算,即使采用GPU加速技術對深度神經網絡模型進行訓練也是需要花費漫長的時間。隨著互聯網行業的高速發展,特別是數據挖掘的需要,往往面對的是海量需要處理的數據。由于深度學習網絡訓練速度緩慢無法滿足互聯網應用的需求。
2、 深度學習未來研究方向:深度學習算法在計算機視覺(圖像識別、視頻識別等)和語音識別中的應用,尤其是大規模數據集下的應用取得突破性的進展,但仍有以下問題值得進一步研究:
(1)、無標記數據的特征學習
目前,標記數據的特征學習仍然占據主導地位,而真實世界存在著海量的無標記數據,將這些無標記數據逐一添加人工標簽,顯然是不現實的。所以,隨著數據集和存儲技術的發展,必將越來越重視對無標記數據的特征學習,以及將無標記數據進行自動添加標簽技術的研究。
(2)、模型規模與訓練速度
訓練精度之間的權衡。一般地,相同數據集下,模型規模越大,訓練精度越高,訓練速度會越慢。例如一些模型方法采用ReLU非線性變換、GPU運算,在保證精度的前提下,往往需要訓練5~7d。雖然離線訓練并不影響訓練之后模型的應用,但是對于模型優化,諸如模型規模調整、超參數設置、訓練時調試等問題,訓練時間會嚴重影響其效率。故而,如何在保證一定的訓練精度的前提下,提高訓練速度,依然是深度學習方向研究的課題之一。
(3)、理論分析
需要更好地理解深度學習及其模型,進行更加深入的理論研究。深度學習模型的訓練為什么那么困難?這仍然是一個開放性問題。一個可能的答案是深度結構神經網絡有許多層,每一層由多個非線性神經元組成,使得整個深度結構神經網絡的非線性程度更強,減弱了基于梯度的尋優方法的有效性;另一個可能的答案是局部極值的數量和結構隨著深度結構神經網絡深度的增加而發生定性改變,使得訓練模型變得更加困難。造成深度學習訓練困難的原因究竟是由于用于深度學習模型的監督訓練準則大量存在不好的局部極值,還是因為訓練準則對優化算法來說過于復雜,這是值得探討的問題。此外,對堆棧自編碼網絡學習中的模型是否有合適的概率解釋,能否得到深度學習模型中似然函數梯度的小方差和低偏差估計,能否同時訓練所有的深度結構神經網絡層,除了重構誤差外,是否還存在其他更合適的可供選擇的誤差指標來控制深度結構神經網絡的訓練過程,是否存在容易求解的RBM配分函數的近似函數,這些問題還有待未來研究。考慮引入退火重要性抽樣來解決局部極值問題,不依賴于配分函數的學習算法也值得嘗試。
(4)、數據表示與模型
數據的表示方式對學習性能具有很大的影響,除了局部表示、分布表示和稀疏分布表示外,可以充分利用表示理論研究成果。是否還存在其他形式的數據表示方式,是否可以通過在學習的表示上施加一些形式的稀疏罰從而對RBM和自編碼模型的訓練性能起到改進作用,以及如何改進。是否可以用便于提取好的表示并且包含更簡單優化問題的凸模型代替RBM和自編碼模型;不增加隱單元的數量,用非參數形式的能量函數能否提高RBM的容量等,未來還需要進一步探討這些問題。此外,除了卷積神經網絡、DBN和堆棧自編碼網絡之外,是否還存在其他可以用于有效訓練的深度學習模型,有沒有可能改變所用的概率模型使訓練變得更容易,是否存在其他有效的或者理論上有效的方法學習深度學習模型,這也是未來需要進一步研究的問題。現有的方法,如DBN.HMM和DBN—CRF,在利用DBN的能力方面只是簡單的堆棧疊加基本模型,還沒有充分發掘出DBN的優勢,需要研究DBN的結構特點,充分利用DBN的潛在優勢,找到更好的方法建立數據的深度學習模型,可以考慮將現有的社會網絡、基因調控網絡、結構化建模理論以及稀疏化建模等理論運用其中。
(5)、特征提取
除了高斯--伯努利模型之外,還有哪些模型能用來從特征中提取重要的判別信息,未來需要提出有效的理論指導在每層搜索更加合適的特征提取模型。自編碼模型保持了輸入的信息,這些信息在后續的訓練過程中可能會起到重要作用,未來需要研究用CD訓練的RBM是否保持了輸入的信息,在沒有保持輸入信息的情況下如何進行修正。樹和圖等結構的數據由于大小和結構可變而不容易用向量表示其中包含的信息,如何泛化深度學習模型來表示這些信息,也是未來需要研究的問題。盡管當前的產生式預訓練加判別式微調學習策略看起來對許多任務都運行良好,但是在某些語言識別等其他任務中卻失敗了,對這些任務,產生式預訓練階段的特征提取似乎能很好地描述語音變化,但是包含的信息不足以區分不同的語言,未來需要提出新的學習策略,對這些學習任務提取合適的特征,這可以在很大程度上減小當前深度學習系統所需模型的大小。
(6)、訓練與優化求解
為什么隨機初始化的深度結構神經網絡采用基于梯度的算法訓練總是不能成功,產生式預訓練方法為什么有效?未來需要研究訓練深度結構神經網絡的貪婪逐層預訓練算法到底在最小化訓練數據的似然函數方面結果如何,是否過于貪婪,以及除了貪婪逐層預訓練的許多變形和半監督嵌入算法之外,還有什么其他形式的算法能得到深度結構神經網絡的局部訓練信息。此外,無監督逐層訓練過程對訓練深度學習模型起到幫助作用,但有實驗表明訓練仍會陷入局部極值并且無法有效利用數據集中的所有信息,能否提出用于深度學習的更有效的優化策略來突破這種限制,基于連續優化的策略能否用于有效改進深度學習的訓練過程,這些問題還需要繼續研究。二階梯度方法和自然梯度方法在理論研究中可證明對訓練求解深度學習模型有效,但是這些算法還不是深度結構神經網絡優化的標準算法,未來還需要進一步驗證和改進這些算法,研究其能否代替微批次隨機梯度下降類算法。當前的基于微批次隨機梯度優化算法難以在計算機上并行處理,目前最好的解決方法是用GPU來加速學習過程,但是單個機器的GPU無法用于處理大規模語音識別和類似的大型數據集的學習,因此未來需要提出理論上可行的并行學習算法來訓練深度學習模型。
(7)、與其他方法的融合
從上述應用實例中可發現,單一的深度學習方法,往往并不能帶來最好的效果,通常融合其他方法或多種方法進行平均打分,會帶來更高的精確率。因此,深度學習方法與其他方法的融合,具有一定的研究意義。
(8)、研究拓展
當深度模型沒有有效的自適應技術,在測試數據集分布不同于訓練集分布時,它們很難得到比常用模型更好的性能,因此未來有必要提出用于深度學習模型的自適應技術以及對高維數據具有更強魯棒性的更先進的算法。目前的深度學習模型訓練算法包含許多階段,而在在線學習場景中一旦進入微調階段就有可能陷入局部極值,因此目前的算法對于在線學習環境是不可行的。未來需要研究是否存在訓練深度學習的完全在線學習過程能夠一直具有無監督學習成分。DBN模型很適合半監督學習場景和自教學習場景,當前的深度學習算法如何應用于這些場景并且在性能上優于現有的半監督學習算法,如何結合監督和無監督準則來學習輸入的模型表示,是否存在一個深度使得深度學習模型的計算足夠接近人類在人工智能任務中表現出的水平,這也是未來需要進一步研究的問題。









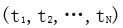











 工商網監
工商網監
評論