 電子發燒友App
電子發燒友App


fork函數的作用
在Linux中fork函數是非常重要的函數,它的作用是從已經存在的進程中創建一個子進程,而原進程稱為父進程。
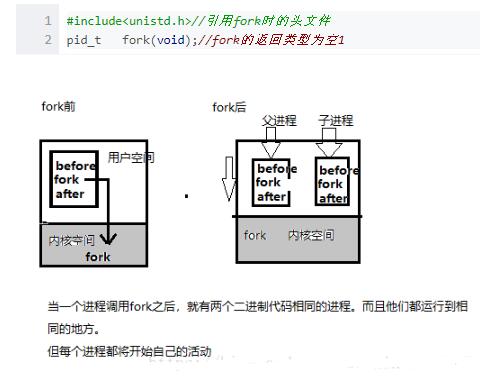
調用fork(),當控制轉移到內核中的fork代碼后,內核開始做:
1.分配新的內存塊和內核數據結構給子進程。
2.將父進程部分數據結構內容拷貝至子進程。
3.將子進程添加到系統進程列表。
4.fork返回開始調度器,調度。
來段代碼:
1 #include《stdio.h》
2 #include《unistd.h》
3 #include《stdlib.h》
4 int main()
5 {
6 pid_t pid;
7 printf(“before :pid is %d ”,getpid());
8 if((pid=fork())==-1)
9 perror(“fork()”),exit(1);
10 printf(“After:pid=%d,fork return %d ”,getpid(),pid);
11 sleep(1);
12
13 return 0;
14 }
15 123456789101112131415
這個簡單的例子有一些微妙的方面:
?調用一次,返回兩次
fork函數被父進程調用一次,但是卻返回兩次;一次是返回到父進程,一次是返回到新創建的子進程。
?并發執行
子進程和父進程是并發運行的獨立進程。內核能夠以任意的方式交替執行他們的邏輯控制流中的指令。在我們的系統上運行這個程序時,父進程先運行它的printf語句,然后是子進程。
?相同但是獨立的地址空間
因為父進程和子進程是獨立的進程,他們都有自己私有的地址空間,當父進程或者子進程單獨改變時,不會影響到彼此,類似于c++的寫實拷貝的形式自建一個副本。
?fork的返回值
1.fork的子進程返回為0;
2.父進程返回的是子進程的pid。
?fork的常規用法
1.一個父進程希望復制自己,使得子進程同時執行不同的代碼段,例如:父進程等待客戶端請求,生成一個子進程來等待請求處理。
2.一個進程要執行一個不同的程序。
?fokr調用失敗的原因
1.系統中有太多進程
2.實際用戶的進程數超過限制
fork函數創建進程
在linux下,C語言創建進程用fork函數,接下來我們通過代碼來一步步了解fork函數的各個知識點。
1、依賴的頭文件
1#include 《unistd.h》
2、fork的原理和概念
fork子進程就是從父進程拷貝一個新的進程出來,子進程和父進程的進程ID不同,但用戶數據一樣。
在C語言中,創建一個子進程代碼如下:
pid_t pid; //pid_t 從底層來看,實際上是int類型。
pid = fork();
3、父進程和子進程
執行fork函數后有2種返回值:對于父進程,返回的是子進程的PID(即返回一個大于0的數字);對于子進程,則返回0,所以我們可以通過pid這個返回值來判斷當前進程是父進程還是子進程。如下代碼所示:
if(pid 》 0)
{
printf(“im parent process, pid: %d ”, getpid());
}
else if(pid == 0)
{
printf(“im child process, pid: %d, parent pid: %d ”, getpid(), getppid());
}
else
{
printf(“fork failed ”);
}
溫馨提示:
getpid() -獲取當前進程的pid
getppid() -獲取當前進程的父進程的pid
4、完整例子&子進程代碼執行位置
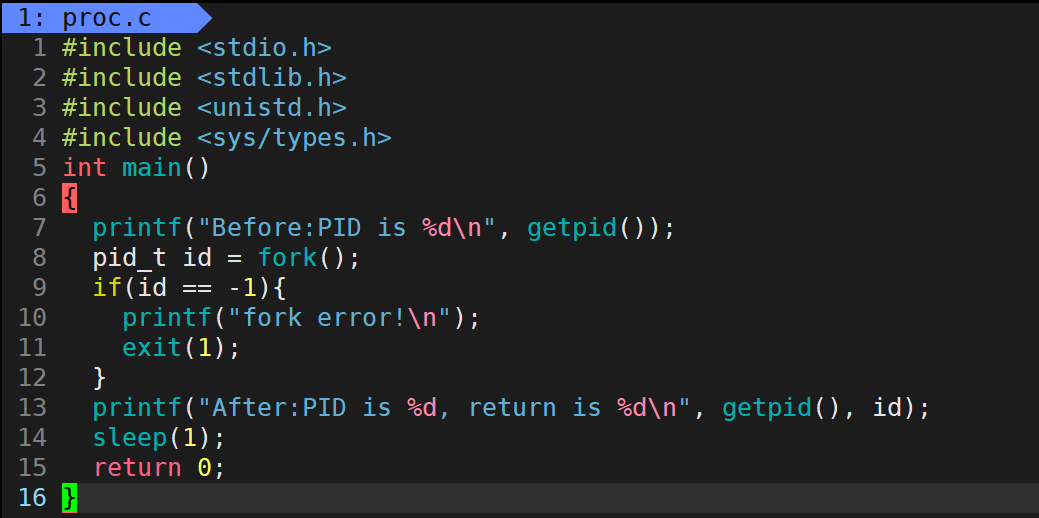
了解這些之后,我們來看一個創建子進程的完整代碼示例:
#include 《stdio.h》
#include 《unistd.h》
int main(int argc, char *argv[])
{
printf(“========== before fork ============= ”);
pid_t pid;
pid = fork();
printf(“========== after fork ============= ”);
if(pid 》 0)
{
printf(“im parent process, pid: %d ”, getpid());
}
else if(pid == 0)
{
printf(“im child process, pid: %d, parent pid: %d ”, getpid(), getppid());
}
else
{
printf(“fork failed ”);
}
printf(“========== process end ============= ”);
sleep(1);
return 0;
}
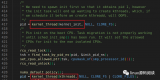
運行結果如下圖:
從上圖可以看出,程序只輸出了1個“before fork”,但輸出了2個“after fork”,所以我們可以得出:子進程的代碼執行是從fork()位置之后開始的。事實也確實是如此。
5、循環創建子進程
有時候,我們需要創建多個子進程,可以通過for循環來實現,代碼如下:
#include 《stdio.h》
#include 《unistd.h》
int main(int argc, char *argv[])
{
int i = 0;
pid_t pid;
for(i = 0; i 《 3; i++)
{
pid = fork();
}
if (pid == 0)
{
printf(“im child process, pid: %d, parent pid: %d ”, getpid(), getppid());
}
else
{
printf(“im parent process, pid: %d ”, getpid());
}
sleep(1);
return 0;
}
運行結果如下圖:
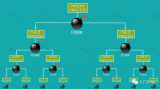
咦,我們不是循環創建3個子進程嗎,怎么輸出了這么多次parent process和child process呢?
這是因為子進程也創建了子進程,大家可以觀察一下圖中的pid。數了一下,共輸出了8次,剛好是2的3次方。
我畫了一個fork步驟圖,便于大家更好的理解,如下:
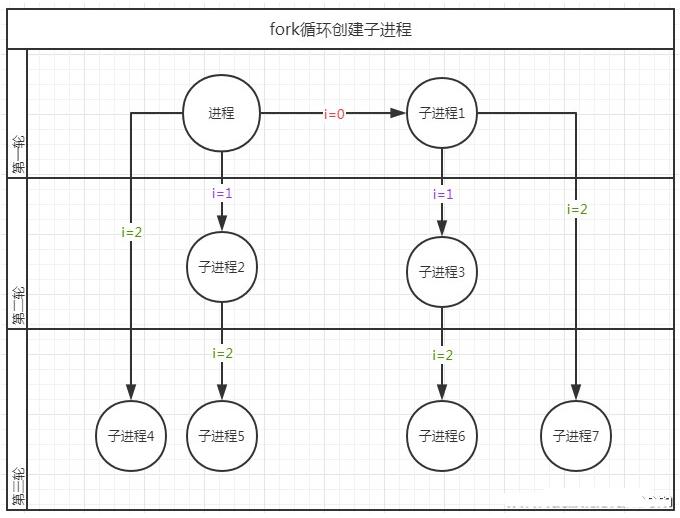
如上圖所示,子進程在第2輪、3輪,也會相當于父進程一樣繼續fork子進程,所以for循環3次后,剛好得到共8個進程。
那如果我們就想通過循環3次,得到3個子進程,要怎么辦呢?
思路:不讓子進程fork出新的子進程。
代碼片段如下:
for(i = 0; i 《 3; i++)
{
pid = fork();
if (pid == 0)
{
break;
}
}
運行結果:
至此,fork函數創建子進程介紹完畢。
責任編輯:YYX















 工商網監
工商網監
評論