 電子發燒友App
電子發燒友App


1 定義
互斥鎖(英語:Mutual exclusion,縮寫 Mutex)是一種用于多線程編程中,防止兩條線程同時對同一公共資源(比如全域變量)進行讀寫的機制。
該目的通過將代碼切片成一個一個的臨界區域(critical section)達成。臨界區域指的是一塊對公共資源進行存取的代碼,并非一種機制或是算法。一個程序、進程、線程可以擁有多個臨界區域,但是并不一定會應用互斥鎖。
例如:一段代碼(甲)正在分步修改一塊數據。這時,另一條線程(乙)由于一些原因被喚醒。如果乙此時去讀取甲正在修改的數據,而甲碰巧還沒有完成整個修改過程,這個時候這塊數據的狀態就處在極大的不確定狀態中,讀取到的數據當然也是有問題的。更嚴重的情況是乙也往這塊地方寫數據,這樣的一來,后果將變得不可收拾。
因此,多個線程間共享的數據必須被保護。達到這個目的的方法,就是確保同一時間只有一個臨界區域處于運行狀態,而其他的臨界區域,無論是讀是寫,都必須被掛起并且不能獲得運行機會。
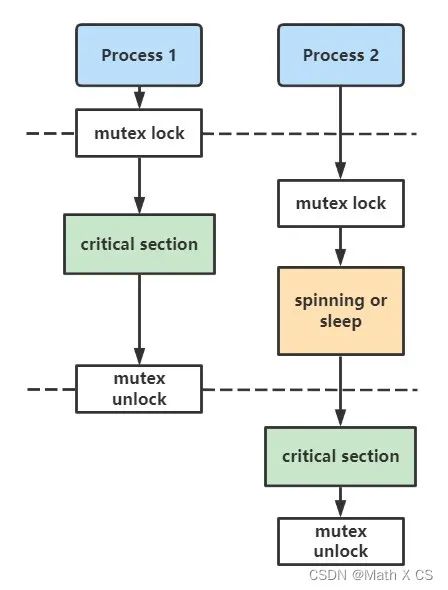
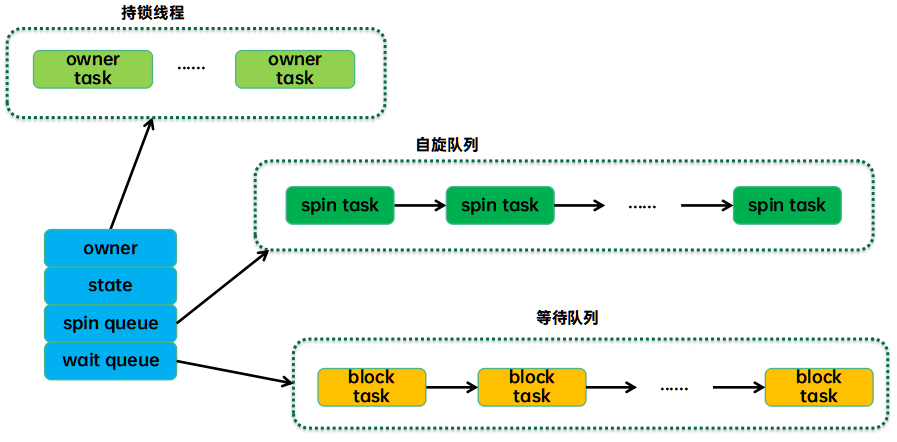
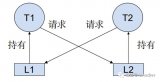
互斥鎖實現多線程同步的核心思想是:有線程訪問進程空間中的公共資源時,該線程執行“加鎖”操作(將資源“鎖”起來),阻止其它線程訪問。訪問完成后,該線程負責完成“解鎖”操作,將資源讓給其它線程。當有多個線程想訪問資源時,誰最先完成“加鎖”操作,誰就最先訪問資源。
當有多個線程想訪問“加鎖”狀態下的公共資源時,它們只能等待資源“解鎖”,所有線程會排成一個等待(阻塞)隊列。資源解鎖后,操作系統會喚醒等待隊列中的所有線程,第一個訪問資源的線程會率先將資源“鎖”起來,其它線程則繼續等待。
mutex有什么缺點?
不同于mutex最初的設計與目的,現在的struct mutex是內核中最大的鎖之一,比如在x86-64上,它差不多有32bytes的大小,而struct samaphore是24bytes,rw_semaphore為40bytes,更大的數據結構意味著占用更多的CPU緩存和更多的內存占用。
什么時候應該使用mutex?
除非mutex的嚴格語義要求不合適或者臨界區域阻止鎖的共享,否則相較于其他鎖原語來說更傾向于使用mutex
mutex與spinlock的區別?
?
spinlock是讓一個嘗試獲取它的線程在一個循環中等待的鎖,線程在等待時會一直查看鎖的狀態。而mutex是一個可以讓多個進程輪流分享相同資源的機制
spinlock通常短時間持有,mutex可以長時間持有
spinlock任務在等待鎖釋放時不可以睡眠,mutex可以
看到一個非常有意思的解釋:
spinlock就像是坐在車后座的熊孩子,一直問”到了嗎?到了嗎?到了嗎?…“
mutex就像一個司機返回的信號,說”我們到了!“
2 實現
看一下Linux kernel-5.8是如何實現mutex的
?
struct?mutex?{
? atomic_long_t??owner;
? spinlock_t??wait_lock;
#ifdef?CONFIG_MUTEX_SPIN_ON_OWNER
?struct?optimistic_spin_queue?osq;?/*?Spinner?MCS?lock?*/
#endif
?struct?list_head?wait_list;
#ifdef?CONFIG_DEBUG_MUTEXES
?void???*magic;
#endif
#ifdef?CONFIG_DEBUG_LOCK_ALLOC
?struct?lockdep_map?dep_map;
#endif
};
?
可以看到,mutex使用了原子變量owner來追蹤鎖的狀態,owner實際上是指向當前mutex鎖擁有者的struct task_struct *指針,所以當鎖沒有被持有時,owner為NULL。
?
/* ?*?This?is?the?control?structure?for?tasks?blocked?on?mutex, ?*?which?resides?on?the?blocked?task's?kernel?stack: ?*?表示等待隊列wait_list中進程的結構體 ?*/ struct?mutex_waiter?{ ?struct?list_head?list; ?struct?task_struct?*task; ?struct?ww_acquire_ctx?*ww_ctx; #ifdef?CONFIG_DEBUG_MUTEXES ? void???*magic; #endif };
?
上鎖
當要獲取mutex時,通常有三種路徑方式
fastpath:通過 cmpxchg() 當前任務與所有者來嘗試原子性的獲取鎖。這僅適用于無競爭的情況(cmpxchg() 檢查 0UL,因此上面的所有 3 個狀態位都必須為 0)。如果鎖被爭用,它會轉到下一個可能的路徑。
midpath:又名樂觀旋轉(optimistic spinning)—在鎖的持有者正在運行并且沒有其他具有更高優先級(need_resched)的任務準備運行時,通過旋轉來獲取鎖。理由是如果鎖的所有者正在運行,它很可能很快就會釋放鎖。mutex spinner使用 MCS 鎖排隊,因此只有一個spinner可以競爭mutex。
MCS 鎖(由 Mellor-Crummey 和 Scott 提出)是一個簡單的自旋鎖,具有公平的理想屬性,每個 cpu 都試圖獲取在本地變量上旋轉的鎖,排隊采用的是鏈表實現的FIFO。它避免了常見的test-and-set自旋鎖實現引起的昂貴的cacheline bouncing。類似MCS的鎖是專門為睡眠鎖的樂觀旋轉而量身定制的(畢竟如果只是短暫的自旋比休眠效率要高)。
自定義 MCS 鎖的一個重要特性是它具有額外的屬性,即當spinner需要重新調度時,它們能夠直接退出 MCS 自旋鎖隊列。這有助于避免需要重新調度的 MCS spinner持續在mutex持有者上自旋,而僅需直接進入慢速路徑獲取MCS鎖。
slowpath:最后的手段,如果仍然無法獲得鎖,則將任務添加到等待隊列并休眠,直到被解鎖路徑喚醒。在正常情況下它阻塞為 TASK_UNINTERRUPTIBLE。
雖然正式的內核互斥鎖是可休眠的鎖,但midpath路徑 (ii) 使它們更實際地成為混合類型。通過簡單地不中斷任務并忙于等待幾個周期而不是立即休眠,此鎖的性能已被視為顯著改善了許多工作負載。請注意,此技術也用于 rw 信號量。
具體代碼調用鏈很長…
?
/*不可中斷的獲取鎖*/
void?__sched?mutex_lock(struct?mutex?*lock)
{
?might_sleep();
????/*fastpath*/
?if?(!__mutex_trylock_fast(lock))
????????/*midpath?and?slowpath*/
? ?__mutex_lock_slowpath(lock);
}
__mutex_trylock_fast(lock)?->?atomic_long_try_cmpxchg_acquire(&lock->owner,?&zero,?curr)?->?atomic64_try_cmpxchg_acquire(v,?(s64?*)old,?new);
__mutex_lock_slowpath(lock)->__mutex_lock(lock,?TASK_UNINTERRUPTIBLE,?0,?NULL,?_RET_IP_)?->??__mutex_lock_common(lock,?state,?subclass,?nest_lock,?ip,?NULL,?false)
????
????
/*可中斷的獲取鎖*/
int?mutex_lock_interruptible(struct?mutex?*lock);
?
嘗試上鎖
?
int?__sched?mutex_trylock(struct?mutex?*lock)
{
?bool?locked;
#ifdef?CONFIG_DEBUG_MUTEXES
?DEBUG_LOCKS_WARN_ON(lock->magic?!=?lock);
#endif
? locked?=?__mutex_trylock(lock);
?if?(locked)
??mutex_acquire(&lock->dep_map,?0,?1,?_RET_IP_);
?return?locked;
}
static?inline?bool?__mutex_trylock(struct?mutex?*lock)
{
?return?!__mutex_trylock_or_owner(lock);
}
?
釋放鎖
?
void?__sched?mutex_unlock(struct?mutex?*lock)
{
#ifndef?CONFIG_DEBUG_LOCK_ALLOC
?if?(__mutex_unlock_fast(lock))
? ?return;
#endif
?__mutex_unlock_slowpath(lock,?_RET_IP_);
}
?
跟加鎖對稱,也有fastpath, midpath, slowpath三條路徑。
判斷鎖狀態
?
bool?mutex_is_locked(struct?mutex?*lock)
{
?return?__mutex_owner(lock)?!=?NULL;
}
?
很顯而易見,mutex持有者不為NULL即表示鎖定狀態。
3 實際案例
實驗:
?
#include?#include? #define?LOOP?1000000 int?cnt?=?0; int?cs1?=?0,?cs2?=?0; void*?task(void*?args)?{ ????while(1) ????{ ????????if(cnt?>=?LOOP) ????????{ ????????????break; ????????} ????????cnt++; ????????if((int)args?==?1)?cs1?++;?else?cs2++; ????} ????return?NULL; } int?main()?{ ????pthread_t?tid1; ?pthread_t?tid2; ?/*?create?the?thread?*/ ?pthread_create(&tid1,?NULL,?task,?(void*)1); ????pthread_create(&tid2,?NULL,?task,?(void*)2); ?/*?wait?for?thread?to?exit?*/ ?pthread_join(tid1,?NULL); ????pthread_join(tid2,?NULL); ?printf("cnt?=?%d?cs1=%d?cs2=%d?total=%d ",?cnt,cs1,cs2,cs1+cs2); ?return?0; }
?
輸出:
?
cnt?=?1000000?cs1=958560?cs2=1520226?total=2478786
?
正確結果不應該是1000000嗎?為什么會出錯呢,我們可以從匯編角度來分析一下。
?
$> g++ -E test.c -o test.i
$> g++ -S test.i -o test.s
$> vim test.s
.file"test.c"
.globl_cnt
.bss
.align 4
_cnt:
.space 4
.text
.globl__Z5task1Pv
.def__Z5task1Pv;.scl2;.type32;.endef
__Z5task1Pv:
...
?
我們可以看到一個簡單的cnt++,對應
?
movl_cnt, %eax addl$1, %eax movl%eax, _cnt
?
CPU先將cnt的值讀到寄存器eax中,然后將[eax] + 1,最后將eax的值返回到cnt中,這些操作不是原子性質(atomic)的,這就導致cnt被多個線程操作時,+1過程會被打斷。
加入mutex保護臨界資源
?
#include?#include? #define?LOOP?1000000 pthread_mutex_t?mutex; int?cnt?=?0; int?cs1?=?0,?cs2?=?0; void*?task(void*?args)?{ ????while(1) ????{ ????????pthread_mutex_lock(&mutex); ????????if(cnt?>=?LOOP) ????????{ ????????????pthread_mutex_unlock(&mutex); ????????????break; ????????} ????????cnt++; ????????pthread_mutex_unlock(&mutex); ????????if((int)args?==?1)?cs1?++;?else?cs2++; ????} ????return?NULL; } int?main()?{ ????pthread_mutex_init(&mutex?,?NULL); ????pthread_t?tid1; ? pthread_t?tid2; ?/*?create?the?thread?*/ ?pthread_create(&tid1,?NULL,?task,?(void*)1); ????pthread_create(&tid2,?NULL,?task,?(void*)2); ?/*?wait?for?thread?to?exit?*/ ?pthread_join(tid1,?NULL); ????pthread_join(tid2,?NULL); ?printf("cnt?=?%d?cs1=%d?cs2=%d?total=%d ",?cnt,cs1,cs2,cs1+cs2); ?return?0; } 輸出: cnt?=?1000000?cs1=517007?cs2=482993?total=1000000 結果正確
















 工商網監
工商網監
評論