 電子發燒友App
電子發燒友App


在一個炎熱的夏天,引爆了埋藏已久的大炸彈。本文作者從實際案例出發講解 Redis 使用的誤區。
案例一:一個產品線開發人員搭建起了一套龐大的價格存儲系統,底層是關系型數據庫,只用來處理一些事務性的操作和存放一些基礎數據。
在關系型數據庫的上面還有一套 MongoDB,因為 MongoDB 的文檔型數據結構,讓他們用起來很順手,同時也可以支撐一定量的并發。
在大部分的情況下,一次大數據量的計算后結果可以重用但會出現細節數據的頻繁更新,所以他們又在 MongoDB 上搭建了一層 Redis 的緩存。
這樣就形成了數據庫→MongoDB→Redis三級的方式,方案本身先不評價不是本文重點,我們來看 Redis 這層的情況。
由于數據量巨大,所以需要 200GB 的 Redis,并且在真實的調用過程中,Redis 是請求量最大的點。
當然如果 Redis 有故障時,也會有備用方案,從后面的 MongoDB 和數據庫中重新加載數據到 Redis,就是這么一套簡單的方案上線了。
當這個系統剛開始運行的時候,一切都還安好,只是運維同學有點傻眼了, 200GB 的 Redis 單服務器去做,它的故障可能性太大了。
所以大家建議將它分片,沒分不知道,一分嚇一跳,各種類型用的太多了,特別是里面還有一些類似消息隊列使用的場景。
由于開發同學對 Redis 使用的注意點關注不夠,一味的濫用,一錘了事,所以讓事情變的困難了。
有些僥幸不死的想法是會傳染,這時的每個人都心存僥幸,懶惰心理,都想著:“這個應該沒事,以后再說吧,先做個主從,掛了就起從”,這種僥幸也是對 Redis 的虛偽的信心,無知者無畏。
可惜事情往往就是怕什么來什么,在大家快樂的放肆使用時,系統中重要的節點 MongoDB 由于系統內核版本的 Bug,造成整個 MongoDB 集群掛了!(這里不多說 MongoDB 的事情,這也是一個好玩的哭器)。
當然,這個對天天與故障為朋友的運維同學來說并沒什么,對整個系統來說問題也不大,因為大部分請求調用都是在最上層的 Redis 中完成的,只要做一定降級就行,等拉起了 MongoDB 集群后自然就會好了。
但此時可別忘了那個 Redis,是一個 200G 大的 Redis,更是帶了個從機的 Redis。
所以這時的 Redis 是絕對不能出任何問題的,一旦有故障,所有請求會立即全部打向最低層的關系型數據庫,在如此大量的壓力下,數據庫瞬間就會癱瘓。
但是,怕什么來什么,還是出了狀況:主從 Redis 之間的網絡出現了一點小動蕩,想想這么大的一個東西在主從同步,一旦網絡動蕩了一下下,會怎么樣呢?
主從同步失敗,同步失敗,就直接開啟全同步,于是 200GB 的 Redis 瞬間開始全同步,網卡瞬間打滿。
為了保證 Redis 能夠繼續提供服務,運維同學直接關掉從機,主從同步不存在了,流量也恢復正常。不過,主從的備份架構變成了單機 Redis,心還是懸著的。
俗話說,福無雙至,禍不單行。這 Redis 由于下層降級的原因并發操作量每秒增加到四萬多,AOF 和 RDB 庫明顯扛不住。
同樣為了保證能持續地提供服務,運維同學也關掉了 AOF 和 RDB 的數據持久化,連最后的保護也沒有了(其實這個保護本來也沒用,200GB 的 Redis 恢復太大了)。
至此,這個 Redis 變成了完全的單機內存型,除了祈禱它不要掛,已經沒有任何方法了。
這事懸著好久,直到修復 MongoDB 集群才了事。如此的僥幸,沒出大事,但心里會踏實嗎?回答是不會。
在這個案例中主要的問題在于:對 Redis 過度依賴,Redis 看似為系統帶來了簡單又方便的性能提升和穩定性,但在使用中缺乏對不同場景的數據的分離造成了一個邏輯上的單點問題。
當然這問題我們可以通過更合理的應用架構設計來解決,但是這樣解決不夠優雅也不夠徹底,也增加了應用層的架構設計的麻煩。
Redis 的問題就應該在基礎緩存層來解決,這樣即使還有類似的情況也沒有問題。
因為基礎緩存層已經能適應這樣的用法,也會讓應用層的設計更為簡單(簡單一直是架構設計所追求的,Redis 的大量隨意使用本身就是追求簡單的副產品,那我們為什么不讓這簡單變為真實呢?)
2
案例二:我們再來看第二個案例,有個部門用自己現有 Redis 服務器做了一套日志系統,將日志數據先存儲到 Redis 里面,再通過其他程序讀取數據并進行分析和計算,用來做數據報表。
當他們做完這個項目之后,這個日志組件讓他們覺得用的還很過癮。他們都覺得這個做法不錯,可以輕松地記錄日志,分析起來也挺快,還用什么公司的分布式日志服務啊?
隨著時間的流逝,這個 Redis 上已經悄悄地掛載了數千個客戶端,每秒的并發量數萬,系統的單核 CPU 使用率也接近 90% 了,此時這個 Redis 已經開始不堪重負。
終于,壓死駱駝的最后一根稻草來了,有程序向這個日志組件寫入了一條 7MB 的日志(哈哈,這個容量可以寫一部小說了,這是什么日志啊)。
于是 Redis 堵死了,一旦堵死,數千個客戶端就全部無法連接,所有日志記錄的操作全部失敗。
其實日志記錄失敗本身應該不至于影響正常業務,但是由于這個日志服務不是公司標準的分布式日志服務,所以關注的人很少。
最開始寫它的開發同學也不知道會有這么大的使用量,運維同學更不知有這個非法的日志服務存在。
這個服務本身也沒有很好地設計容錯,所以在日志記錄的地方就直接拋出異常,結果全公司相當一部分的業務系統都出現了故障,監控系統中“5XX”的錯誤直線上升。
一幫人欲哭無淚,頂著巨大的壓力排查問題,但是由于受災面實在太廣,排障的壓力是可以想像的。
這個案例中看似是一個日志服務沒做好或者是開發流程管理不到位,而且很多日志服務也都用到了 Redis 做收集數據的緩沖,好像也沒什么問題。
其實不然,像這樣大規模大流量的日志系統從收集到分析要細細考慮的技術點是巨大的,而不只是簡單的寫入性能的問題。
在這個案例中 Redis 給程序帶來的是超簡單的性能解決方案,但這個簡單是相對的,它是有場景限制的。
在這里,這樣的簡單就是毒藥,無知的吃下是要害死自己的,這就像“一條在小河溝里無所不能傲慢的小魚,那是因為它沒見過大海,等到了大海……”。
在這個案例的另一問題:一個非法日志服務的存在,表面上是管理問題,實質上還是技術問題。
因為 Redis 的使用無法像關系型數據庫那樣有 DBA 的監管,它的運維者無法管理和提前知道里面放的是什么數據,開發者也無需任何申明就可以向 Redis 中寫入數據并使用。
所以這里我們發現 Redis 的使用沒這些場景的管理后在長期的使用中比較容易失控,我們需要一個對 Redis 使用可治理和管控的透明層。
兩個小例子中看到在 Redis 亂用的那個年代里,使用它的兄弟們一定是痛的,承受了各種故障的狂轟濫炸:
Redis 被 Keys 命令堵塞了
Keepalived 切換虛 IP 失敗,虛IP被釋放了
用 Redis 做計算了,Redis 的 CPU 占用率成了 100% 了
主從同步失敗了
Redis 客戶端連接數爆了
……
如何改變 Redis 用不好的誤區?
這樣的亂象一定是不可能繼續了,最少在同程,這樣的使用方式不可以再繼續了,使用者也開始從喜歡到痛苦了。
怎么辦?這是一個很沉重的事情:“一個被人用亂的系統就像一桌燒壞的菜,讓你重新回爐,還讓人叫好,是很困難的”。
關鍵是已經用的這樣了,總不可能讓所有系統都停下來,等待新系統上線并瞬間切換好吧?這是個什么活:“高速公路上換輪胎”。
但問題出現了總是要解決的,想了再想,論了再論,總結以下幾點:
必須搭建完善的監控系統,在這之前要先預警,不能等到發生了,我們才發現問題。
控制和引導 Redis 的使用,我們需要有自己研發的 Redis 客戶端,在使用時就開始控制和引導。
Redis的部分角色要改,將 Redis 由 Storage 角色降低為 Cache 角色。
Redis 的持久化方案要重新做,需要自己研發一個基于 Redis 協議的持久化方案讓使用者可以把 Redis 當 DB 用。
Redis 的高可用要按照場景分開,根據不同的場景決定采用不同的高可用方案。
留給開發同學的時間并不多,只有兩個月的時間來完成這些事情。這事還是很有挑戰的,考驗開發同學這個輪胎到底能不換下來的時候到來了。
同學們開始研發我們自己的 Redis 緩存系統,下面我們來看一下這個代號為鳳凰的緩存系統第一版方案:
首先是監控系統。原有的開源 Redis 監控從大面上講只是一些監控工具,不能算作一個完整的監控系統。當然這個監控是全方位從客戶端開始一直到返回數據的全鏈路的監控。
其次是改造 Redis 客戶端。廣泛使用的 Redis 客戶端有的太簡單,有的太重,總之不是我們想要的東西。
比如 .Net 下的 BookSleeve 和 servicestack.Redis(同程還有一點老的 .Net 開發的應用),前者已經好久沒人維護了,后者直接收費了。
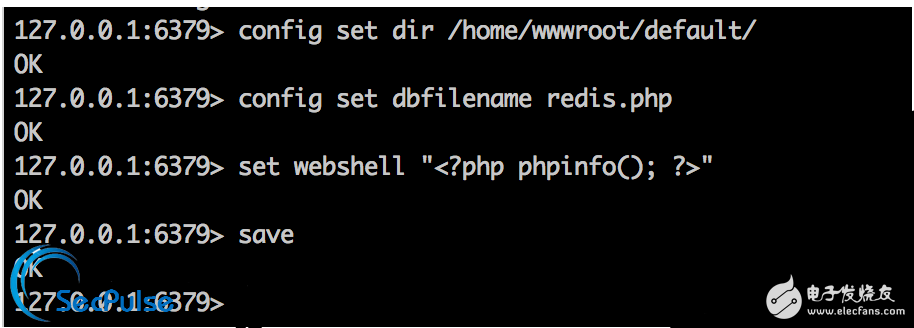
好吧,我們就開發一個客戶端,然后督促全公司的研發用它來替換目前正在使用的客戶端。
在這個客戶端里面,我們植入了日志記錄,記錄了代碼對 Redis 的所有操作事件,例如耗時、Key、Value 大小、網絡斷開等。
我們將這些有問題的事件在后臺進行收集,由一個收集程序進行分析和處理,同時取消了直接的 IP 端口連接方式,通過一個配置中心分配 IP 地址和端口。
當 Redis 發生問題并需要切換時,直接在配置中心修改,由配置中心推送新的配置到客戶端,這樣就免去了 Redis 切換時需要業務員修改配置文件的麻煩。
另外,把 Redis 的命令操作分拆成兩部分:
安全的命令,對于安全的命令可以直接使用。
不安全的命令,對于不安全的命令需要分析和審批后才能打開,這也是由配置中心控制的。
這樣就解決了研發人員使用 Redis 時的規范問題,并且將 Redis 定位為緩存角色,除非有特殊需求,否則一律以緩存角色對待。
最后,對 Redis 的部署方式也進行了修改,以前是 Keepalived 的方式,現在換成了主從+哨兵的模式。
另外,我們自己實現了 Redis 的分片,如果業務需要申請大容量的 Redis 數據庫,就會把 Redis 拆分成多片,通過 Hash 算法均衡每片的大小,這樣的分片對應用層也是無感知的。
當然重客戶端方式不好,并且我們要做的是緩存,不僅僅是單單的 Redis,于是我們會做一個 Redis 的 Proxy,提供統一的入口點。
Proxy 可以多份部署,客戶端無論連接的是哪個 Proxy,都能取得完整的集群數據,這樣就基本完成了按場景選擇不同的部署方式的問題。
這樣的一個 Proxy 也解決了多種開發語言的問題,例如,運維系統是使用 Python 開發的,也需要用到 Redis,就可以直接連 Proxy,然后接入到統一的 Redis 體系中來。
做客戶端也好,做 Proxy 也好,不只是為代理請求而是為了統一的治理 Redis 緩存的使用,不讓亂象出現。
讓緩存在一個可管可控的場景下穩定的運維,讓開發者可以安全并肆無忌憚繼續亂用 Redis,但這個“亂”是被虛擬化的亂,因為它的底層是可以治理的。
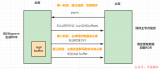
系統架構圖
當然以上這些改造都需要在不影響業務的情況下進行。實現這個還是有不小的挑戰,特別是分片。
將一個 Redis 拆分成多個,還能讓客戶端正確找到所需要的 Key,這需要非常小心,因為稍有不慎,內存的數據就全部消失了。
在這段時間里,我們開發了多種同步工具,幾乎把 Redis 的主從協議整個實現了一遍,終于可以將 Redis 平滑過渡到新的模式上了。
(PS:大家可能會有這樣的疑問,為什么不用 Redis 的集群模式?我們在線的情況是 2.X 和 3.X 的版本居多,2.X 也正在大量減少,代理的加入不是為簡單的分片,是為了更多的其他功能,比如單 Key 的高熱度問題等,總的來看我們做的是一個私有緩存云,并不只有一個緩存管理容器。)










 工商網監
工商網監
評論