 電子發燒友App
電子發燒友App


隨著嵌入式Linux系統的廣泛應用,對系統的可靠性提出了更高的要求,尤其是涉及到生命財產等重要領域,要求系統達到安全完整性等級3級以上 ,故障率(每小時出現危險故障的可能性)為10-7以下,相當于系統的平均故障間隔時間(MTBF)至少要達到1141年以上,因此提高系統可靠性已成為一項艱巨的任務。對某公司在工業領域14 878個控制器系統的應用調查表明,從2004年初到2007年9月底,隨著硬軟件的不斷改進,根據錯誤報告統計的故障率已降低到2004年的五分之一以下,但查找錯誤的時間卻增加到原來的3倍以上。
這種解決問題所需時間呈上升的趨勢固然有軟件問題,但缺乏必要的手段以輔助解決問題才是主要的原因。通過對故障的統計跟蹤發現,難以解決的軟件錯誤和從發現到解決耗時較長的軟件錯誤都集中在操作系統的核心部分,這其中又有很大比例集中在驅動程序部分 。因此,錯誤跟蹤技術被看成是提高系統安全完整性等級的一個重要措施 ,大多數現代操作系統均為發展提供了操作系統內核“崩潰轉儲”機制,即在軟件系統宕機時,將內存內容保存到磁盤 ,或者通過網絡發送到故障服務器 ,或者直接啟動內核調試器 等,以供事后分析改進。
基于Linux操作系統內核的崩潰轉儲機制近年來有以下幾種:
(1) LKCD(Linux Kernel Crash Dump)機制? ;
(2) KDUMP(Linux Kernel Dump)機制 ;
(3) KDB機制 ;
(4) KGDB機制 。
綜合上述幾種機制可以發現,這四種機制之間有以下三個共同點:
(1) 適用于為運算資源豐富、存儲空間充足的應用場合;
(2) 發生系統崩潰后恢復時間無嚴格要求;
(3) 主要針對較通用的硬件平臺,如X86平臺。
在嵌入式應用場合想要直接使用上列機制中的某一種,卻遇到以下三個難點無法解決:
(1) 存儲空間不足
嵌入式系統一般采用Flash作為存儲器,而Flash容量有限,且可能遠遠小于嵌入式系統中的內存容量。因此將全部內存內容保存到Flash不可行。
(2) 記錄時間要求盡量短
嵌入式系統一般有復位響應時間盡量短的要求,有的嵌入式操作系統復位重啟時間不超過2s,而上述幾種可用于Linux系統的內核崩潰轉儲機制耗時均不可能在30s內。寫Flash的操作也很耗時間,實驗顯示,寫2MB數據到Flash耗時達到400ms之多。
(3) 要求能夠支持特定的硬件平臺
嵌入式系統的硬件多種多樣,上面提到的四種機制均是針對X86平臺提供了較好的支持,而對于其他體系的硬件支持均不成熟。
由于這些難點的存在,要將上述四種內核崩潰轉儲機制中的一種移植到特定的嵌入式應用平臺是十分困難的。因此,針對上述嵌入式系統的三個特點,本文介紹一種基于特定平臺的嵌入式Linux內核崩潰信息記錄機制LCRT(Linux Crash Record and Trace),為定位嵌入式Linux系統中軟件故障和解決軟件故障提供輔助手段。
1 Linux內核崩潰的分析
分析Linux內核對于運行期間各種“陷阱”的處理可以得知,Linux內核對于應用程序導致的錯誤可以予以監控,在應用程序發生除零、內存訪問越界、緩沖區溢出等錯誤時,Linux內核的異常處理例程可以對這些由應用程序引起的異常情況予以處理。當應用程序產生不可恢復的錯誤時,Linux內核可以僅僅終止產生錯誤的應用程序,其他應用程序仍然可以正常運行。
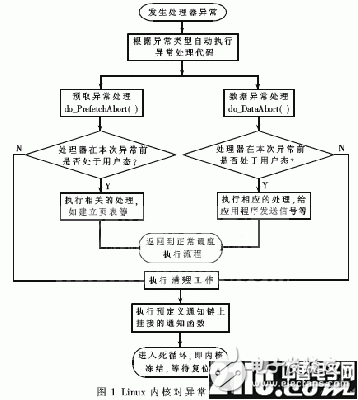
如果Linux內核本身或者新開發的Linux內核模塊存在bug,產生了“除零”,“內存訪問越界”、“緩沖區溢出”等錯誤,同樣會由Linux內核的異常處理例程來處理。Linux內核通過在異常處理程序中判斷,如果發現是“嚴重的不可恢復”的內核異常,則會導致“內核恐慌”(kernel panic),即Linux內核崩潰。圖1所示為Linux內核對異常情況的處理流程。
2 LCRT機制的設計與實現
通過對Linux內核代碼的分析可知,Linux內核本身提供了一種“內核通知機制” ,并預定義了“內核事件通知鏈”,使得Linux內核擴展開發人員可以通過這些預定義的內核事件通知鏈在特定的內核事件發生時執行附加的處理流程。通過對Linux內核源代碼的研究發現,對于上文中提到的“嚴重不可恢復的內核異常”,預定義了一個通知鏈和通知點,使得在發生Linux內核崩潰之后,可以在Linux內核的panic函數中預定義的一個“內核崩潰通知鏈” 上掛接LCRT機制來獲得Linux內核崩潰現場的一些信息并記錄到非易失性存儲器中,以便分析引起Linux內核崩潰的原因。
2.1 設計要點
LCRT機制的設計和實現基于如下特定的機制:
(1) 編譯器選項與內核依賴
Linux內核及相應的驅動程序都采用GNU 的開源編譯器GCC 編譯,為了結合LCRT機制方便地提取信息和記錄信息,需要采用特定的GCC編譯器選項來編譯Linux內核和相關的驅動程序以及應用程序。用到的選項為:-mpoke-function-name 。使用這個選項編譯出的二進制程序中可以包含C語言函數名稱的信息,以方便函數調用鏈回溯時記錄信息的可讀性。
(2) Linux內核notify_chain機制?
Linux內核提供“通知鏈”功能,并預定義了一個內核崩潰通知鏈,在Linux內核的異常處理例程中判斷出系統進入“不可恢復”狀態時,會沿預定義的通知鏈順序調用注冊到相應鏈中的通知函數。
(3) 函數調用的棧布局
Linux內核的絕大部分由C語言實現,而且C語言也多用來進行Linux內核開發。Linux內核及使用LKM擴展而加入Linux內核執行環境的代碼是有規律可循的,這些代碼在執行過程中產生的棧布局和這些規律的代碼相關聯。例如,這些函數在執行函數之前會保存本函數調用后的返回地址、本函數被調用時傳遞過來的參數及調用本函數的函數所擁有的棧幀的棧底。
2.2 LCRT機制的設計思想
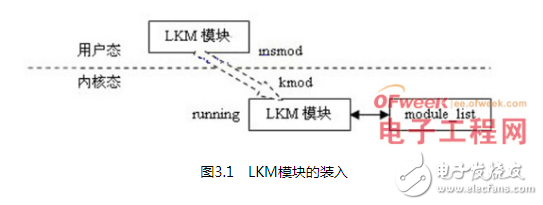
LCRT機制分為Linux內核模塊 部分和Linux用戶程序部分。內核模塊部分的設計采用了Linux內核模塊的模式而不是直接修改Linux內核。這樣的設計降低了Linux內核和LCRT機制之間的耦合度,同時滿足了Linux內核和LCRT機制獨立升級完善的便利性。用戶程序部分完成從非易失性存儲器中讀取、清除LCRT機制保存的信息等相關功能。
在LCRT機制的設計中,針對嵌入式系統的特點,其設計決策有:
(1) 將對于解決和定位問題最具輔助意義的函數調用關系鏈記錄下來。
(2) 為了不占用過多的存儲空間,有選擇性地將函數調用序列上的函數各自用到的棧內容保存起來,而不是保存全部內容。
(3) 將記錄的信息保存到非易失性存儲器中,這樣既達到了掉電保存的目的、又縮短了寫入時間。
LCRT機制的設計包括以下五個方面。
(1) 設計Linux內核模塊、動態地加載LCRT機制、盡量少地修改Linux內核代碼。
(2)在相應、預定義的Linux內核通知鏈上掛接LCRT的通知函數。
(3) 在LCRT機制的通知處理函數中進行堆棧回溯得到函數調用信息。
(4) 記錄回溯到的函數調用信息和堆棧空間內容到非易失性存儲器。
(5) 開發用戶空間的工具,可以從非易失性存儲器中讀取保存的信息。
2.3 LCRT機制的實現
LCRT機制的實現可參照2.2節的設計思想,分步予以實現。限于篇幅,本文不過多涉及Linux內核模塊的原理和實現相關的細節,僅僅給出LCRT機制的內核模塊實現偽代碼。用偽代碼描述LCRT機制的加載函數如下:
int lcrt_init(void)
{
printk(“Registering my__panic notifier.\n”);
bt_nvram_ptr=(volatile unsigned char*)ioremap_
nocache (BT_NVRAM_BASE,BT_NVRAM_LENGTH);
bt_nvram_index+=sizeof(struct bt_info);
*)bt_nvram_ptr,BT_NVRAM_LENGTH);
notifier_chain_register(&panic_notifier_list,&my_
panic_block);
return 0;
}
LCRT機制的通知處理函數完成函數調用關系回溯、得到函數名稱、函數棧內容等工作,限于篇幅,在這里用下面偽代碼說明:
void ll_bt_information(struct pt_regs *pr)
{
變量定義等初始化工作
do{
reglist=*(unsigned long *)(*myfp-8);
//從函數棧幀的頂部獲取函數開始執行時保存的寄存器信息
//從函數的代碼區中取得函數的名稱
//從函數的棧幀里取出函數執行函數體代碼之前保存的函數參數信息
//從本函數的棧幀中得到調用本函數的代碼所在位置和調用本函數的函數棧幀的棧底
}while(直到函數調用鏈的鏈頭);
//取得函數調用棧幀的內容
//填充信息記錄的記錄頭部
//將上面的循環中取得的信息保存到非易失性存儲器中
write_to_nvram((void *)bt_nvram_ptr,&bt_record_header,sizeof(bt_info_t));
}
3 驗證評估LCRT機制
3.1 部署LCRT機制
部署LCRT機制,使LCRT機制發揮作用前需要做的相關工作有:
(1)針對目標Linux內核編譯LCRT機制的Linux內核模塊部分;
(2) 將LCRT機制的內核模塊部分載入Linux內核。
3.2 實驗結果
為了實驗LCRT機制的作用效果,構造一個會造成Linux內核崩潰的設備驅動模塊,記這個內核驅動模塊為bugguy.ko,列出如下所示的bugguy.ko中會引起Linux內核崩潰的代碼如下所示:
irqreturn_t my_timer_interrupt(int irq,void *dev_id,struct pt_regs* regs)
{
確認硬件狀態并清除中斷狀態
if(ujiffies 》 5000) {
void * ill_pointer=NULL;
*(unsigned long *)ill_pointer=0;
}
else {
ujiffies++;
}
return IRQ_HANDLED;
}
說明:用黑體標出的代碼即為產生bug的代碼
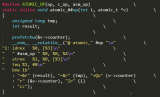
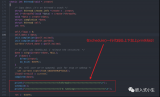
從上面的代碼可以看出,這個錯誤是對空指針進行解析而造成的。在一個中斷處理函數中如果發生對空指針的解析,將會引起Linux內核的崩潰。在部署完成LCRT機制的嵌入式linux系統上將這個bugguy.ko載入Linux內核,使得會引起Linux內核崩潰的中斷處理程序得以運行,LCRT機制可以將相關的信息保存到非易失性存儲器中,在系統復位后,通過LCRT機制的用戶空間工具,可以將保存的信息讀取出來。實驗結果顯示,可以得到如圖2所示的函數調用鏈信息。
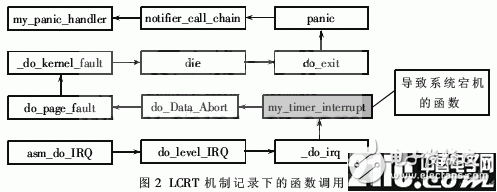
圖2標注即為會引起Linux內核崩潰的錯誤代碼的中斷處理函數即真正引起系統宕機的“罪魁禍首”。而記錄下的所有信息僅僅占用了不到1KB的存儲空間,寫入非易失性存儲器所耗用的時間控制在50ms以內。在使用少量空間和少量時間的情況下,所記錄下的信息對于查找問題和解決問題都有較大的幫助。
實驗結果表明,在LCRT機制的作用下,可以快速地定位到嵌入式Linux系統中隱藏的可能會導致系統宕機的軟件缺陷。這就為后續的故障解決和軟件完善提供了關鍵的輔助信息。對嵌入式Linux內核而言,即是為提高Linux內核的穩定性和可靠性提供了幫助。
在基于ARM的嵌入式Linux應用中,開發LCRT機制來記錄系統內核發生崩潰時引起崩潰的函數調用鏈和棧信息到非易失性存儲器中,截至目前為止,LCRT機制可以記錄基于ARM的嵌入式Linux內核發生崩潰時的函數調用鏈信息,可直接得到函數名稱、函數調用鏈中單個函數被調用時的參數信息以及函數調用鏈中的函數各自的棧幀信息。這些記錄下來的信息對于完善和發展基于ARM的嵌入式Linux應用具有重要的輔助意義。











 工商網監
工商網監
評論