 電子發(fā)燒友App
電子發(fā)燒友App


1. 背景知識(shí)
1.1 與性能調(diào)優(yōu)相關(guān)的硬件特性
硬件特性之cache
內(nèi)存讀寫是很快的,但還是無法和處理器的指令執(zhí)行速度相比。為了從內(nèi)存中讀取指令和數(shù)據(jù),處理器需要等待,用處理器的時(shí)間來衡量,這種等待非常漫長。Cache 是一種 SRAM,它的讀寫速率非常快,能和處理器處理速度相匹配。因此將常用的數(shù)據(jù)保存在 cache 中,處理器便無須等待,從而提高性能。Cache 的尺寸一般都很小,充分利用 cache 是軟件調(diào)優(yōu)非常重要的部分。
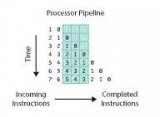
硬件特性之流水線,超標(biāo)量體系結(jié)構(gòu),亂序執(zhí)行
提高性能最有效的方式之一就是并行。處理器在硬件設(shè)計(jì)時(shí)也盡可能地并行,比如流水線,超標(biāo)量體系結(jié)構(gòu)以及亂序執(zhí)行。
處理器處理一條指令需要分多個(gè)步驟完成,比如先取指令,然后完成運(yùn)算,最后將計(jì)算結(jié)果輸出到總線上。第一條指令在運(yùn)算時(shí),第二條指令已經(jīng)在取指了;而第一條指令輸出結(jié)果時(shí),第二條指令則又可以運(yùn)算了,而第三天指令也已經(jīng)取指了。這樣從長期看來,像是三條指令在同時(shí)執(zhí)行。在處理器內(nèi)部,這可以看作一個(gè)三級流水線。
超標(biāo)量(superscalar)指一個(gè)時(shí)鐘周期發(fā)射多條指令的流水線機(jī)器架構(gòu),比如 Intel 的 Pentium 處理器,內(nèi)部有兩個(gè)執(zhí)行單元,在一個(gè)時(shí)鐘周期內(nèi)允許執(zhí)行兩條指令。
在處理器內(nèi)部,不同指令所需要的處理步驟和時(shí)鐘周期是不同的,如果嚴(yán)格按照程序的執(zhí)行順序執(zhí)行,那么就無法充分利用處理器的流水線。因此指令有可能被亂序執(zhí)行。
上述三種并行技術(shù)對所執(zhí)行的指令有一個(gè)基本要求,即相鄰的指令相互沒有依賴關(guān)系。假如某條指令需要依賴前面一條指令的執(zhí)行結(jié)果數(shù)據(jù),那么 pipeline 便失去作用,因?yàn)榈诙l指令必須等待第一條指令完成。因此好的軟件必須盡量避免這種代碼的生成。
硬件特性之分支預(yù)測
分支指令對軟件性能有比較大的影響。尤其是當(dāng)處理器采用流水線設(shè)計(jì)之后,假設(shè)流水線有三級,當(dāng)前進(jìn)入流水的第一條指令為分支指令。假設(shè)處理器順序讀取指令,那么如果分支的結(jié)果是跳轉(zhuǎn)到其他指令,那么被處理器流水線預(yù)取的后續(xù)兩條指令都將被放棄,從而影響性能。為此,很多處理器都提供了分支預(yù)測功能,根據(jù)同一條指令的歷史執(zhí)行記錄進(jìn)行預(yù)測,讀取最可能的下一條指令,而并非順序讀取指令。
分支預(yù)測對軟件結(jié)構(gòu)有一些要求,對于重復(fù)性的分支指令序列,分支預(yù)測硬件能得到較好的預(yù)測結(jié)果,而對于類似 switch case 一類的程序結(jié)構(gòu),則往往無法得到理想的預(yù)測結(jié)果。
上面介紹的幾種處理器特性對軟件的性能有很大的影響,然而依賴時(shí)鐘進(jìn)行定期采樣的 profiler 模式無法揭示程序?qū)@些處理器硬件特性的使用情況。處理器廠商針對這種情況,在硬件中加入了 PMU 單元,即 performance monitor unit。PMU 允許軟件針對某種硬件事件設(shè)置 counter,此后處理器便開始統(tǒng)計(jì)該事件的發(fā)生次數(shù),當(dāng)發(fā)生的次數(shù)超過 counter 內(nèi)設(shè)置的值后,便產(chǎn)生中斷。比如 cache miss 達(dá)到某個(gè)值后,PMU 便能產(chǎn)生相應(yīng)的中斷。
捕獲這些中斷,便可以考察程序?qū)@些硬件特性的利用效率了。
1.2 Tracepoints
Tracepoint 是散落在內(nèi)核源代碼中的一些 hook,一旦使能,它們便可以在特定的代碼被運(yùn)行到時(shí)被觸發(fā),這一特性可以被各種 trace/debug 工具所使用。Perf 就是該特性的用戶之一。
假如您想知道在應(yīng)用程序運(yùn)行期間,內(nèi)核內(nèi)存管理模塊的行為,便可以利用潛伏在 slab 分配器中的 tracepoint。當(dāng)內(nèi)核運(yùn)行到這些 tracepoint 時(shí),便會(huì)通知 perf。Perf 將 tracepoint 產(chǎn)生的事件記錄下來,生成報(bào)告,通過分析這些報(bào)告,調(diào)優(yōu)人員便可以了解程序運(yùn)行時(shí)期內(nèi)核的種種細(xì)節(jié),對性能癥狀作出更準(zhǔn)確的診斷。
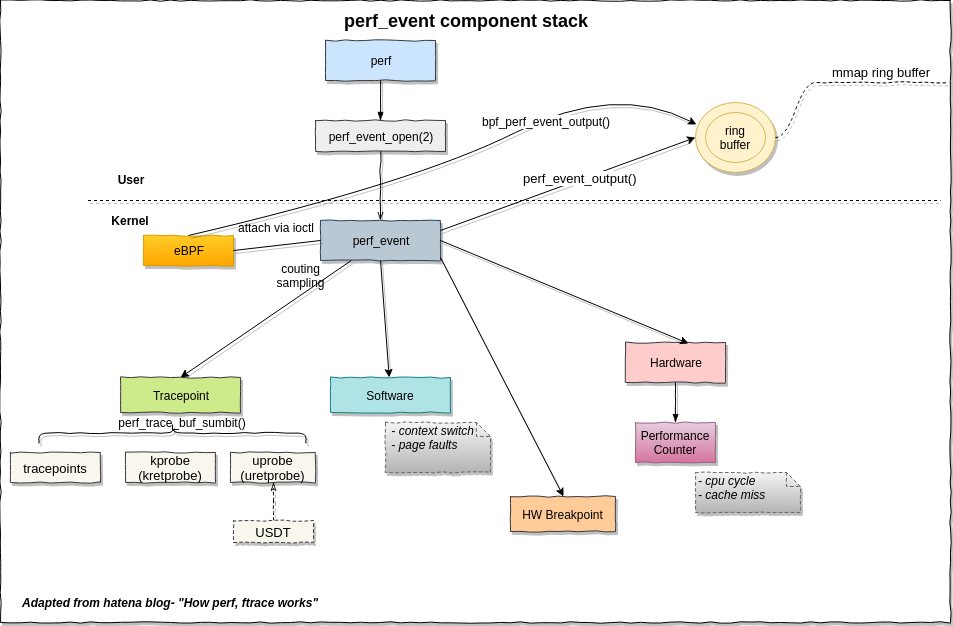
2.Perf簡介
Perf是Linux內(nèi)核自帶的系統(tǒng)性能優(yōu)化工具,原理是:
CPU的PMU registers中Get/Set performance counters來獲得諸如instructions executed, cache-missed suffered, branches mispredicted等信息。linux?kernel對這些registers進(jìn)行了一系列抽象,所以你可以按進(jìn)程,按CPU或者按counter group等不同類別來查看Sample信息。
通過Perf,應(yīng)用程序可以利用 PMU,tracepoint 和內(nèi)核中的特殊計(jì)數(shù)器來進(jìn)行性能統(tǒng)計(jì)。它不但可以分析指定應(yīng)用程序的性能問題 (per thread),也可以用來分析內(nèi)核的性能問題,當(dāng)然也可以同時(shí)分析應(yīng)用代碼和內(nèi)核,從而全面理解應(yīng)用程序中的性能瓶頸。
Perf 不僅可以用于應(yīng)用程序的性能統(tǒng)計(jì)分析,也可以應(yīng)用于內(nèi)核代碼的性能統(tǒng)計(jì)和分析。得益于其優(yōu)秀的體系結(jié)構(gòu)設(shè)計(jì),越來越多的新功能被加入 Perf,使其已經(jīng)成為一個(gè)多功能的性能統(tǒng)計(jì)工具集 。
3.perf 的基本使用
性能調(diào)優(yōu)工具如 perf,Oprofile 等的基本原理都是對被監(jiān)測對象進(jìn)行采樣,最簡單的情形是根據(jù) tick 中斷進(jìn)行采樣,即在 tick 中斷內(nèi)觸發(fā)采樣點(diǎn),在采樣點(diǎn)里判斷程序當(dāng)時(shí)的上下文。假如一個(gè)程序 90% 的時(shí)間都花費(fèi)在函數(shù) foo() 上,那么 90% 的采樣點(diǎn)都應(yīng)該落在函數(shù) foo() 的上下文中。運(yùn)氣不可捉摸,但我想只要采樣頻率足夠高,采樣時(shí)間足夠長,那么以上推論就比較可靠。因此,通過 tick 觸發(fā)采樣,我們便可以了解程序中哪些地方最耗時(shí)間,從而重點(diǎn)分析。稍微擴(kuò)展一下思路,就可以發(fā)現(xiàn)改變采樣的觸發(fā)條件使得我們可以獲得不同的統(tǒng)計(jì)數(shù)據(jù):以時(shí)間點(diǎn) ( 如 tick) 作為事件觸發(fā)采樣便可以獲知程序運(yùn)行時(shí)間的分布。以 cache miss 事件觸發(fā)采樣便可以知道 cache miss 的分布,即 cache 失效經(jīng)常發(fā)生在哪些程序代碼中。如此等等。
因此讓我們先來了解一下 perf 中能夠觸發(fā)采樣的事件有哪些。
3.1 Perf list,perf 事件
使用 perf list 命令可以列出所有能夠觸發(fā) perf 采樣點(diǎn)的事件。比如 # perf list List of pre-defined events (to be used in -e): cpu-cycles OR cycles [Hardware event] instructions [Hardware event] … cpu-clock [Software event] task-clock [Software event] context-switches OR cs [Software event] … ext4:ext4_allocate_inode [Tracepoint event] kmem:kmalloc [Tracepoint event] module:module_load [Tracepoint event] workqueue:workqueue_execution [Tracepoint event] sched:sched_{wakeup,switch} [Tracepoint event] syscalls:sys_{enter,exit}_epoll_wait [Tracepoint event] …不同的系統(tǒng)會(huì)列出不同的結(jié)果,在 2.6.35 版本的內(nèi)核中,該列表已經(jīng)相當(dāng)?shù)拈L,但無論有多少,我們可以將它們劃分為三類:
Hardware Event 是由 PMU 硬件產(chǎn)生的事件,比如 cache 命中,當(dāng)您需要了解程序?qū)τ布匦缘氖褂们闆r時(shí),便需要對這些事件進(jìn)行采樣;
Software Event 是內(nèi)核軟件產(chǎn)生的事件,比如進(jìn)程切換,tick 數(shù)等 ;
Tracepoint event 是內(nèi)核中的靜態(tài) tracepoint 所觸發(fā)的事件,這些 tracepoint 用來判斷程序運(yùn)行期間內(nèi)核的行為細(xì)節(jié),比如 slab 分配器的分配次數(shù)等。
上述每一個(gè)事件都可以用于采樣,并生成一項(xiàng)統(tǒng)計(jì)數(shù)據(jù),時(shí)至今日,尚沒有文檔對每一個(gè) event 的含義進(jìn)行詳細(xì)解釋。
3.2 Perf stat
面對一個(gè)問題程序,最好采用自頂向下的策略。先整體看看該程序運(yùn)行時(shí)各種統(tǒng)計(jì)事件的大概,再針對某些方向深入細(xì)節(jié)。而不要一下子扎進(jìn)瑣碎細(xì)節(jié),會(huì)一葉障目的。
有些程序慢是因?yàn)橛?jì)算量太大,其多數(shù)時(shí)間都應(yīng)該在使用 CPU 進(jìn)行計(jì)算,這叫做 CPU bound 型;有些程序慢是因?yàn)檫^多的 IO,這種時(shí)候其 CPU 利用率應(yīng)該不高,這叫做 IO bound 型;對于 CPU bound 程序的調(diào)優(yōu)和 IO bound 的調(diào)優(yōu)是不同的。
如果您認(rèn)同這些說法的話,Perf stat 應(yīng)該是您最先使用的一個(gè)工具。它通過概括精簡的方式提供被調(diào)試程序運(yùn)行的整體情況和匯總數(shù)據(jù)。
下面演示了 perf stat 針對程序 t1 的輸出:
$perf stat ./t1 Performance counter stats for './t1':
262.738415 task-clock-msecs # 0.991 CPUs 2 context-switches # 0.000 M/sec 1 CPU-migrations # 0.000 M/sec 81 page-faults # 0.000 M/sec 9478851 cycles # 36.077 M/sec (scaled from 98.24%) 6771 instructions # 0.001 IPC (scaled from 98.99%) 111114049 branches # 422.908 M/sec (scaled from 99.37%) 8495 branch-misses # 0.008 % (scaled from 95.91%) 12152161 cache-references # 46.252 M/sec (scaled from 96.16%) 7245338 cache-misses # 27.576 M/sec (scaled from 95.49%) 0.265238069 seconds time elapsed
上面告訴我們,程序 t1 是一個(gè) CPU bound 型,因?yàn)?task-clock-msecs 接近 1。
對 t1 進(jìn)行調(diào)優(yōu)應(yīng)該要找到熱點(diǎn) ( 即最耗時(shí)的代碼片段 ),再看看是否能夠提高熱點(diǎn)代碼的效率。
缺省情況下,除了 task-clock-msecs 之外,perf stat 還給出了其他幾個(gè)最常用的統(tǒng)計(jì)信息:
Task-clock-msecs:CPU 利用率,該值高,說明程序的多數(shù)時(shí)間花費(fèi)在 CPU 計(jì)算上而非 IO。 Context-switches:進(jìn)程切換次數(shù),記錄了程序運(yùn)行過程中發(fā)生了多少次進(jìn)程切換,頻繁的進(jìn)程切換是應(yīng)該避免的。 Cache-misses:程序運(yùn)行過程中總體的 cache 利用情況,如果該值過高,說明程序的 cache 利用不好 CPU-migrations:表示進(jìn)程 t1 運(yùn)行過程中發(fā)生了多少次 CPU 遷移,即被調(diào)度器從一個(gè) CPU 轉(zhuǎn)移到另外一個(gè) CPU 上運(yùn)行。 Cycles:處理器時(shí)鐘,一條機(jī)器指令可能需要多個(gè) cycles, Instructions: 機(jī)器指令數(shù)目。 IPC:是 Instructions/Cycles 的比值,該值越大越好,說明程序充分利用了處理器的特性。 Cache-references: cache 命中的次數(shù) Cache-misses: cache 失效的次數(shù)。
通過指定 -e 選項(xiàng),您可以改變 perf stat 的缺省事件 ( 關(guān)于事件,在上一小節(jié)已經(jīng)說明,可以通過 perf list 來查看 )。假如您已經(jīng)有很多的調(diào)優(yōu)經(jīng)驗(yàn),可能會(huì)使用 -e 選項(xiàng)來查看您所感興趣的特殊的事件。
3.3perf Top
Perf top 用于實(shí)時(shí)顯示當(dāng)前系統(tǒng)的性能統(tǒng)計(jì)信息。該命令主要用來觀察整個(gè)系統(tǒng)當(dāng)前的狀態(tài),比如可以通過查看該命令的輸出來查看當(dāng)前系統(tǒng)最耗時(shí)的內(nèi)核函數(shù)或某個(gè)用戶進(jìn)程。
下面是 perf top 的可能輸出:
PerfTop: 705 irqs/sec kernel:60.4% [1000Hz cycles] -------------------------------------------------- sampl pcnt function DSO 1503.00 49.2% t2 72.00 2.2% pthread_mutex_lock /lib/libpthread-2.12.so 68.00 2.1% delay_tsc [kernel.kallsyms] 55.00 1.7% aes_dec_blk [aes_i586] 55.00 1.7% drm_clflush_pages [drm] 52.00 1.6% system_call [kernel.kallsyms] 49.00 1.5% __memcpy_ssse3 /lib/libc-2.12.so 48.00 1.4% __strstr_ia32 /lib/libc-2.12.so 46.00 1.4% unix_poll [kernel.kallsyms] 42.00 1.3% __ieee754_pow /lib/libm-2.12.so 41.00 1.2% do_select [kernel.kallsyms] 40.00 1.2% pixman_rasterize_edges libpixman-1.so.0.18.0 37.00 1.1% _raw_spin_lock_irqsave [kernel.kallsyms] 36.00 1.1% _int_malloc /lib/libc-2.12.so ^C
很容易便發(fā)現(xiàn) t2 是需要關(guān)注的可疑程序。不過其作案手法太簡單:肆無忌憚地浪費(fèi)著 CPU。所以我們不用再做什么其他的事情便可以找到問題所在。但現(xiàn)實(shí)生活中,影響性能的程序一般都不會(huì)如此愚蠢,所以我們往往還需要使用其他的 perf 工具進(jìn)一步分析。
通過添加 -e 選項(xiàng),您可以列出造成其他事件的 TopN 個(gè)進(jìn)程 / 函數(shù)。比如 -e cache-miss,用來看看誰造成的 cache miss 最多。
3.4 使用 perf record, 解讀 report
lenny@hbt:~/test$ perf record ./a.out [ perf record: Woken up 1 times to write data ] [ perf record: Captured and wrote 0.015 MB perf.data (~656 samples) ] lenny@hbt:~/test$ perf report Events: 12 cycles 62.29% a.out a.out [.] longa 35.17% a.out [kernel.kallsyms] [k] unmap_vmas 1.76% a.out [kernel.kallsyms] [k] __schedule 0.75% a.out [kernel.kallsyms] [k] ____cache_alloc 0.03% a.out [kernel.kallsyms] [k] native_write_msr_safe
perf record時(shí)加上-g選項(xiàng),可以記錄函數(shù)的調(diào)用關(guān)系,顯示類似下面這樣:
lenny@hbt:~/test$ perf record -g ./a.out [ perf record: Woken up 1 times to write data ] [ perf record: Captured and wrote 0.016 MB perf.data (~701 samples) ] lenny@hbt:~/test$ perf report Events: 14 cycles - 87.12% a.out a.out [.] longa - longa - 52.91% fun1 main __libc_start_main - 47.09% fun2 main __libc_start_main + 9.12% a.out [kernel.kallsyms] [k] vm_normal_page + 3.48% a.out [kernel.kallsyms] [k] _cond_resched + 0.28% a.out [kernel.kallsyms] [k] native_write_msr_safe
***使用 PMU 的例子下面這個(gè)例子 t3 參考了文章“Branch and Loop Reorganization to Prevent Mispredicts”該例子考察程序?qū)Ρ简v處理器分支預(yù)測的利用率,如前所述,分支預(yù)測能夠顯著提高處理器的性能,而分支預(yù)測失敗則顯著降低處理器的性能。首先給出一個(gè)存在 BTB 失效的例子:
清單 3. 存在 BTB 失效的例子程序
//test.c #include #include void foo() { int i,j; for(i=0; i< 10; i++) j+=2; } int main(void) { int i; for(i = 0; i< 100000000; i++) foo(); return 0; }
用 gcc 編譯生成測試程序 t3: gcc – o t3 – O0 test.c
用 perf stat 考察分支預(yù)測的使用情況: [lm@ovispoly perf]$ ./perf stat ./t3
Performance counter stats for './t3': 6240.758394 task-clock-msecs # 0.995 CPUs 126 context-switches # 0.000 M/sec 12 CPU-migrations # 0.000 M/sec 80 page-faults # 0.000 M/sec 17683221 cycles # 2.834 M/sec (scaled from 99.78%) 10218147 instructions # 0.578 IPC (scaled from 99.83%) 2491317951 branches # 399.201 M/sec (scaled from 99.88%) 636140932 branch-misses # 25.534 % (scaled from 99.63%) 126383570 cache-references # 20.251 M/sec (scaled from 99.68%) 942937348 cache-misses # 151.093 M/sec (scaled from 99.58%) 6.271917679 seconds time elapsed
可以看到 branche-misses 的情況比較嚴(yán)重,25% 左右。我測試使用的機(jī)器的處理器為 Pentium4,其 BTB 的大小為 16。而 test.c 中的循環(huán)迭代為 20 次,BTB 溢出,所以處理器的分支預(yù)測將不準(zhǔn)確。對于上面這句話我將簡要說明一下,但關(guān)于 BTB 的細(xì)節(jié),請閱讀參考文獻(xiàn) [6]。for 循環(huán)編譯成為 IA 匯編后如下:
清單 4. 循環(huán)的匯編
// C code for ( i=0; i < 20; i++ ) { … } //Assembly code; mov esi, data mov ecx, 0 ForLoop: cmp ecx, 20 jge EndForLoop … add ecx, 1 jmp ForLoop EndForLoop:
可以看到,每次循環(huán)迭代中都有一個(gè)分支語句 jge,因此在運(yùn)行過程中將有 20 次分支判斷。每次分支判斷都將寫入 BTB,但 BTB 是一個(gè) ring buffer,16 個(gè) slot 寫滿后便開始覆蓋。假如迭代次數(shù)正好為 16,或者小于 16,則完整的循環(huán)將全部寫入 BTB。
清單 5. 沒有 BTB 失效的代碼
#include #include void foo() { int i,j; for(i=0; i< 10; i++) j+=2; } int main(void) { int i; for(i = 0; i< 100000000; i++) foo(); return 0; }
此時(shí)再次用 perf stat 采樣得到如下結(jié)果: [lm@ovispoly perf]$ ./perf stat ./t3
Performance counter stats for './t3: 2784.004851 task-clock-msecs # 0.927 CPUs 90 context-switches # 0.000 M/sec 8 CPU-migrations # 0.000 M/sec 81 page-faults # 0.000 M/sec 33632545 cycles # 12.081 M/sec (scaled from 99.63%) 42996 instructions # 0.001 IPC (scaled from 99.71%) 1474321780 branches # 529.569 M/sec (scaled from 99.78%) 49733 branch-misses # 0.003 % (scaled from 99.35%) 7073107 cache-references # 2.541 M/sec (scaled from 99.42%) 47958540 cache-misses # 17.226 M/sec (scaled from 99.33%) 3.002673524 seconds time elapsed
Branch-misses 減少了。本例只是為了演示 perf 對 PMU 的使用,本身并無意義,關(guān)于充分利用 processor 進(jìn)行調(diào)優(yōu)可以參考 Intel 公司出品的調(diào)優(yōu)手冊,其他的處理器可能有不同的方法,還希望讀者明鑒。
3.5 使用 tracepoint
當(dāng) perf 根據(jù) tick 時(shí)間點(diǎn)進(jìn)行采樣后,人們便能夠得到內(nèi)核代碼中的 hot spot。那什么時(shí)候需要使用 tracepoint 來采樣呢?我想人們使用 tracepoint 的基本需求是對內(nèi)核的運(yùn)行時(shí)行為的關(guān)心,如前所述,有些內(nèi)核開發(fā)人員需要專注于特定的子系統(tǒng),比如內(nèi)存管理模塊。這便需要統(tǒng)計(jì)相關(guān)內(nèi)核函數(shù)的運(yùn)行情況。另外,內(nèi)核行為對應(yīng)用程序性能的影響也是不容忽視的:以之前的遺憾為例,假如時(shí)光倒流,我想我要做的是統(tǒng)計(jì)該應(yīng)用程序運(yùn)行期間究竟發(fā)生了多少次系統(tǒng)調(diào)用。在哪里發(fā)生的?下面我用 ls 命令來演示 sys_enter 這個(gè) tracepoint 的使用: [root@ovispoly /]# perf stat -e raw_syscalls:sys_enter ls bin dbg etc lib media opt root selinux sys usr boot dev home lost+found mnt proc sbin srv tmp var
Performance counter stats for 'ls':
101 raw_syscalls:sys_enter
0.003434730 seconds time elapsed
[root@ovispoly /]# perf record -e raw_syscalls:sys_enter ls
[root@ovispoly /]# perf report Failed to open .lib/ld-2.12.so, continuing without symbols # Samples: 70 # # Overhead Command Shared Object Symbol # ........ ............... ............... ...... # 97.14% ls ld-2.12.so [.] 0x0000000001629d 2.86% ls [vdso] [.] 0x00000000421424 # # (For a higher level overview, try: perf report --sort comm,dso) #
這個(gè)報(bào)告詳細(xì)說明了在 ls 運(yùn)行期間發(fā)生了多少次系統(tǒng)調(diào)用 ( 上例中有 101 次 ),多數(shù)系統(tǒng)調(diào)用都發(fā)生在哪些地方 (97% 都發(fā)生在 ld-2.12.so 中 )。有了這個(gè)報(bào)告,或許我能夠發(fā)現(xiàn)更多可以調(diào)優(yōu)的地方。比如函數(shù) foo() 中發(fā)生了過多的系統(tǒng)調(diào)用,那么我就可以思考是否有辦法減少其中有些不必要的系統(tǒng)調(diào)用。您可能會(huì)說 strace 也可以做同樣事情啊,的確,統(tǒng)計(jì)系統(tǒng)調(diào)用這件事完全可以用 strace 完成,但 perf 還可以干些別的,您所需要的就是修改 -e 選項(xiàng)后的字符串。羅列 tracepoint 實(shí)在是不太地道,本文當(dāng)然不會(huì)這么做。但學(xué)習(xí)每一個(gè) tracepoint 是有意義的,類似背單詞之于學(xué)習(xí)英語一樣,是一項(xiàng)緩慢痛苦卻不得不做的事情。
3.6 perf probe
tracepoint 是靜態(tài)檢查點(diǎn),意思是一旦它在哪里,便一直在那里了,您想讓它移動(dòng)一步也是不可能的。內(nèi)核代碼有多少行?我不知道,100 萬行是至少的吧,但目前 tracepoint 有多少呢?我最大膽的想象是不超過 1000 個(gè)。所以能夠動(dòng)態(tài)地在想查看的地方插入動(dòng)態(tài)監(jiān)測點(diǎn)的意義是不言而喻的。
Perf 并不是第一個(gè)提供這個(gè)功能的軟件,systemTap 早就實(shí)現(xiàn)了。但假若您不選擇 RedHat 的發(fā)行版的話,安裝 systemTap 并不是件輕松愉快的事情。perf 是內(nèi)核代碼包的一部分,所以使用和維護(hù)都非常方便。
我使用的 Linux 版本為 2.6.33。因此您自己做實(shí)驗(yàn)時(shí)命令參數(shù)有可能不同。
[root@ovispoly perftest]# perf probe schedule:12 cpu Added new event: probe:schedule (on schedule+52 with cpu) You can now use it on all perf tools, such as: perf record -e probe:schedule -a sleep 1 [root@ovispoly perftest]# perf record -e probe:schedule -a sleep 1 Error, output file perf.data exists, use -A to append or -f to overwrite. [root@ovispoly perftest]# perf record -f -e probe:schedule -a sleep 1 [ perf record: Woken up 1 times to write data ] [ perf record: Captured and wrote 0.270 MB perf.data (~11811 samples) ] [root@ovispoly perftest]# perf report # Samples: 40 # # Overhead Command Shared Object Symbol # ........ ............... ................. ...... # 57.50% init 0 [k] 0000000000000000 30.00% firefox [vdso] [.] 0x0000000029c424 5.00% sleep [vdso] [.] 0x00000000ca7424 5.00% perf.2.6.33.3-8 [vdso] [.] 0x00000000ca7424 2.50% ksoftirqd/0 [kernel] [k] 0000000000000000 # # (For a higher level overview, try: perf report --sort comm,dso) #
上例利用 probe 命令在內(nèi)核函數(shù) schedule() 的第 12 行處加入了一個(gè)動(dòng)態(tài) probe 點(diǎn),和 tracepoint 的功能一樣,內(nèi)核一旦運(yùn)行到該 probe 點(diǎn)時(shí),便會(huì)通知 perf。可以理解為動(dòng)態(tài)增加了一個(gè)新的 tracepoint。此后便可以用 record 命令的 -e 選項(xiàng)選擇該 probe 點(diǎn),最后用 perf report 查看報(bào)表。如何解讀該報(bào)表便是見仁見智了,既然您在 shcedule() 的第 12 行加入了 probe 點(diǎn),想必您知道自己為什么要統(tǒng)計(jì)它吧?
3.7 Perf sched
調(diào)度器的好壞直接影響一個(gè)系統(tǒng)的整體運(yùn)行效率。在這個(gè)領(lǐng)域,內(nèi)核黑客們常會(huì)發(fā)生爭執(zhí),一個(gè)重要原因是對于不同的調(diào)度器,每個(gè)人給出的評測報(bào)告都各不相同,甚至常常有相反的結(jié)論。因此一個(gè)權(quán)威的統(tǒng)一的評測工具將對結(jié)束這種爭論有益。Perf sched 便是這種嘗試。
Perf sched 有五個(gè)子命令:
perf sched record # low-overhead recording of arbitrary workloads perf sched latency # output per task latency metrics perf sched map # show summary/map of context-switching perf sched trace # output finegrained trace perf sched replay # replay a captured workload using simlated threads
用戶一般使用’ perf sched record ’收集調(diào)度相關(guān)的數(shù)據(jù),然后就可以用’ perf sched latency ’查看諸如調(diào)度延遲等和調(diào)度器相關(guān)的統(tǒng)計(jì)數(shù)據(jù)。其他三個(gè)命令也同樣讀取 record 收集到的數(shù)據(jù)并從其他不同的角度來展示這些數(shù)據(jù)。下面一一進(jìn)行演示。
perf sched record sleep 10 # record full system activity for 10 seconds perf sched latency --sort max # report latencies sorted by max ------------------------------------------------------------------------------------- Task | Runtime ms | Switches | Average delay ms | Maximum delay ms | ------------------------------------------------------------------------------------- :14086:14086 | 0.095 ms | 2 | avg: 3.445 ms | max: 6.891 ms | gnome-session:13792 | 31.713 ms | 102 | avg: 0.160 ms | max: 5.992 ms | metacity:14038 | 49.220 ms | 637 | avg: 0.066 ms | max: 5.942 ms | gconfd-2:13971 | 48.587 ms | 777 | avg: 0.047 ms | max: 5.793 ms | gnome-power-man:14050 | 140.601 ms | 434 | avg: 0.097 ms | max: 5.367 ms | python:14049 | 114.694 ms | 125 | avg: 0.120 ms | max: 5.343 ms | kblockd/1:236 | 3.458 ms | 498 | avg: 0.179 ms | max: 5.271 ms | Xorg:3122 | 1073.107 ms | 2920 | avg: 0.030 ms | max: 5.265 ms | dbus-daemon:2063 | 64.593 ms | 665 | avg: 0.103 ms | max: 4.730 ms | :14040:14040 | 30.786 ms | 255 | avg: 0.095 ms | max: 4.155 ms | events/1:8 | 0.105 ms | 13 | avg: 0.598 ms | max: 3.775 ms | console-kit-dae:2080 | 14.867 ms | 152 | avg: 0.142 ms | max: 3.760 ms | gnome-settings-:14023 | 572.653 ms | 979 | avg: 0.056 ms | max: 3.627 ms | ... ----------------------------------------------------------------------------------- TOTAL: | 3144.817 ms | 11654 | ---------------------------------------------------
上面的例子展示了一個(gè) Gnome 啟動(dòng)時(shí)的統(tǒng)計(jì)信息。
各個(gè) column 的含義如下: Task: 進(jìn)程的名字和 pid Runtime: 實(shí)際運(yùn)行時(shí)間 Switches: 進(jìn)程切換的次數(shù) Average delay: 平均的調(diào)度延遲 Maximum delay: 最大延遲
這里最值得人們關(guān)注的是 Maximum delay,一般從這里可以看到對交互性影響最大的特性:調(diào)度延遲,如果調(diào)度延遲比較大,那么用戶就會(huì)感受到視頻或者音頻斷斷續(xù)續(xù)的。
其他的三個(gè)子命令提供了不同的視圖,一般是由調(diào)度器的開發(fā)人員或者對調(diào)度器內(nèi)部實(shí)現(xiàn)感興趣的人們所使用。
首先是 map:
$ perf sched map ...
N1 O1 . . . S1 . . . B0 . *I0 C1 . M1 . 23002.773423 secs N1 O1 . *Q0 . S1 . . . B0 . I0 C1 . M1 . 23002.773423 secs N1 O1 . Q0 . S1 . . . B0 . *R1 C1 . M1 . 23002.773485 secs N1 O1 . Q0 . S1 . *S0 . B0 . R1 C1 . M1 . 23002.773478 secs *L0 O1 . Q0 . S1 . S0 . B0 . R1 C1 . M1 . 23002.773523 secs L0 O1 . *. . S1 . S0 . B0 . R1 C1 . M1 . 23002.773531 secs L0 O1 . . . S1 . S0 . B0 . R1 C1 *T1 M1 . 23002.773547 secs T1 => irqbalance:2089 L0 O1 . . . S1 . S0 . *P0 . R1 C1 T1 M1 . 23002.773549 secs *N1 O1 . . . S1 . S0 . P0 . R1 C1 T1 M1 . 23002.773566 secs N1 O1 . . . *J0 . S0 . P0 . R1 C1 T1 M1 . 23002.773571 secs N1 O1 . . . J0 . S0 *B0 P0 . R1 C1 T1 M1 . 23002.773592 secs N1 O1 . . . J0 . *U0 B0 P0 . R1 C1 T1 M1 . 23002.773582 secs N1 O1 . . . *S1 . U0 B0 P0 . R1 C1 T1 M1 . 23002.773604 secs
星號表示調(diào)度事件發(fā)生所在的 CPU。
點(diǎn)號表示該 CPU 正在 IDLE。
Map 的好處在于提供了一個(gè)的總的視圖,將成百上千的調(diào)度事件進(jìn)行總結(jié),顯示了系統(tǒng)任務(wù)在 CPU 之間的分布,假如有不好的調(diào)度遷移,比如一個(gè)任務(wù)沒有被及時(shí)遷移到 idle 的 CPU 卻被遷移到其他忙碌的 CPU,類似這種調(diào)度器的問題可以從 map 的報(bào)告中一眼看出來。如果說 map 提供了高度概括的總體的報(bào)告,那么 trace 就提供了最詳細(xì),最底層的細(xì)節(jié)報(bào)告。
Perf replay 這個(gè)工具更是專門為調(diào)度器開發(fā)人員所設(shè)計(jì),它試圖重放 perf.data 文件中所記錄的調(diào)度場景。很多情況下,一般用戶假如發(fā)現(xiàn)調(diào)度器的奇怪行為,他們也無法準(zhǔn)確說明發(fā)生該情形的場景,或者一些測試場景不容易再次重現(xiàn),或者僅僅是出于“偷懶”的目的,使用 perf replay,perf 將模擬 perf.data 中的場景,無需開發(fā)人員花費(fèi)很多的時(shí)間去重現(xiàn)過去,這尤其利于調(diào)試過程,因?yàn)樾枰欢伲俣刂貜?fù)新的修改是否能改善原始的調(diào)度場景所發(fā)現(xiàn)的問題。
下面是 replay 執(zhí)行的示例: $ perf sched replay run measurement overhead: 3771 nsecs sleep measurement overhead: 66617 nsecs the run test took 999708 nsecs the sleep test took 1097207 nsecs nr_run_events: 200221 nr_sleep_events: 200235 nr_wakeup_events: 100130 task 0 ( perf: 13519), nr_events: 148 task 1 ( perf: 13520), nr_events: 200037 task 2 ( pipe-test-100k: 13521), nr_events: 300090 task 3 ( ksoftirqd/0: 4), nr_events: 8 task 4 ( swapper: 0), nr_events: 170 task 5 ( gnome-power-man: 3192), nr_events: 3 task 6 ( gdm-simple-gree: 3234), nr_events: 3 task 7 ( Xorg: 3122), nr_events: 5 task 8 ( hald-addon-stor: 2234), nr_events: 27 task 9 ( ata/0: 321), nr_events: 29 task 10 ( scsi_eh_4: 704), nr_events: 37 task 11 ( events/1: 8), nr_events: 3 task 12 ( events/0: 7), nr_events: 6 task 13 ( flush-8:0: 6980), nr_events: 20 ------------------------------------------------------------ #1 : 2038.157, ravg: 2038.16, cpu: 0.09 / 0.09 #2 : 2042.153, ravg: 2038.56, cpu: 0.11 / 0.09 ^C
3.8 perf bench
除了調(diào)度器之外,很多時(shí)候人們都需要衡量自己的工作對系統(tǒng)性能的影響。benchmark 是衡量性能的標(biāo)準(zhǔn)方法,對于同一個(gè)目標(biāo),如果能夠有一個(gè)大家都承認(rèn)的 benchmark,將非常有助于”提高內(nèi)核性能”這項(xiàng)工作。
目前,就我所知,perf bench 提供了 3 個(gè) benchmark:
Sched message
sched message 是從經(jīng)典的測試程序 hackbench 移植而來,用來衡量調(diào)度器的性能,overhead 以及可擴(kuò)展性。該 benchmark 啟動(dòng) N 個(gè) reader/sender 進(jìn)程或線程對,通過 IPC(socket 或者 pipe) 進(jìn)行并發(fā)的讀寫。一般人們將 N 不斷加大來衡量調(diào)度器的可擴(kuò)展性。Sched message 的用法及用途和 hackbench 一樣。
Sched Pipe
Sched pipe 從 Ingo Molnar 的 pipe-test-1m.c 移植而來。當(dāng)初 Ingo 的原始程序是為了測試不同的調(diào)度器的性能和公平性的。其工作原理很簡單,兩個(gè)進(jìn)程互相通過 pipe 拼命地發(fā) 1000000 個(gè)整數(shù),進(jìn)程 A 發(fā)給 B,同時(shí) B 發(fā)給 A。。。因?yàn)?A 和 B 互相依賴,因此假如調(diào)度器不公平,對 A 比 B 好,那么 A 和 B 整體所需要的時(shí)間就會(huì)更長。
Mem memcpy
這個(gè)是 perf bench 的作者 Hitoshi Mitake 自己寫的一個(gè)執(zhí)行 memcpy 的 benchmark。該測試衡量一個(gè)拷貝 1M 數(shù)據(jù)的 memcpy() 函數(shù)所花費(fèi)的時(shí)間。我尚不明白該 benchmark 的使用場景。。。或許是一個(gè)例子,告訴人們?nèi)绾卫?perf bench 框架開發(fā)更多的 benchmark 吧。
這三個(gè) benchmark 給我們展示了一個(gè)可能的未來:不同語言,不同膚色,來自不同背景的人們將來會(huì)采用同樣的 benchmark,只要有一份 Linux 內(nèi)核代碼即可。
3.9 perf lock
鎖是內(nèi)核同步的方法,一旦加了鎖,其他準(zhǔn)備加鎖的內(nèi)核執(zhí)行路徑就必須等待,降低了并行。因此對于鎖進(jìn)行專門分析應(yīng)該是調(diào)優(yōu)的一項(xiàng)重要工作。
3.10 perf Kmem
Perf Kmem 專門收集內(nèi)核 slab 分配器的相關(guān)事件。比如內(nèi)存分配,釋放等。可以用來研究程序在哪里分配了大量內(nèi)存,或者在什么地方產(chǎn)生碎片之類的和內(nèi)存管理相關(guān)的問題。
Perf kmem 和 perf lock 實(shí)際上都是 perf tracepoint 的特例,您也完全可以用 Perf record – e kmem:?或者 perf record – e lock:?來完成同樣的功能。但重要的是,這些工具在內(nèi)部對原始數(shù)據(jù)進(jìn)行了匯總和分析,因而能夠產(chǎn)生信息更加明確更加有用的統(tǒng)計(jì)報(bào)表。
3.11 Perf timechart
很多 perf 命令都是為調(diào)試單個(gè)程序或者單個(gè)目的而設(shè)計(jì)。有些時(shí)候,性能問題并非由單個(gè)原因所引起,需要從各個(gè)角度一一查看。為此,人們常需要綜合利用各種工具,比如 top,vmstat,oprofile 或者 perf。這非常麻煩。
此外,前面介紹的所有工具都是基于命令行的,報(bào)告不夠直觀。更令人氣餒的是,一些報(bào)告中的參數(shù)令人費(fèi)解。所以人們更愿意擁有一個(gè)“傻瓜式”的工具。
以上種種就是 perf timechart 的夢想,其靈感來源于 bootchart。采用“簡單”的圖形“一目了然”地揭示問題所在。
Timechart 可以顯示更詳細(xì)的信息,實(shí)際上是一個(gè)矢量圖形 SVG 格式,用 SVG viewer 的放大功能,我們可以將該圖的細(xì)節(jié)部分放大,timechart 的設(shè)計(jì)理念叫做”infinitely zoomable”。放大之后便可以看到一些更詳細(xì)的信息,類似網(wǎng)上的 google 地圖,找到國家之后,可以放大,看城市的分布,再放大,可以看到某個(gè)城市的街道分布,還可以放大以便得到更加詳細(xì)的信息。完整的 timechart 圖形和顏色解讀超出了本文的范圍,感興趣的讀者可以到作者 Arjan 的博客上查看。
?















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論