 電子發燒友App
電子發燒友App


一、前言
隨著內核版本的演進,其源代碼的膨脹速度也在遞增,這讓Linux的學習曲線變得越來越陡峭了。這對初識內核的同學而言當然不是什么好事情,滿腔熱情很容易被當頭澆滅。我有一個循序漸進的方法,那就是先不要看最新的內核,首先找到一個古老版本的內核(一般都會比較簡單),將其吃透,然后一點點的迭代,理解每個版本變更背后的緣由和目的,最終推進到最新內核版本。
本文就是從2.4時代的任務調度器開始,詳細描述其實現并慢慢向前遞進。當然,為了更好的理解Linux調度器設計和實現,我們在第二章給出了一些通用的概念。之后,我們會在第四章講述O(1)調度器如何改進并提升調度器性能。真正有劃時代意義的是CFS調度器,在2.6.23版本的內核中并入主線。它的設計思想是那么的眩目,即便是目前最新的內核中,完全公平的設計思想仍然沒有太大變化,這些我們會在第六章描述。第五章是關于公平調度思想的引入,通過這一章可以了解Con Kolivas的RSDL調度器,它是開啟公平調度的先鋒,通過這一章的鋪墊,我們可以更順暢的理解CFS。
二、任務調度器概述
為了不引起混亂,我們一開始先澄清幾個概念。進程調度器是傳統的說法,但是實際上進程是資源管理的單位,線程才是調度的單位,但是線程調度器的說法讓我覺得很不舒服,因此最終采用進程調度器或者任務調度器的說法。為了節省字,本文有些地方也直接簡稱調度器,此外,除非特別說明,本文中的“進程”指的是task struct代表的那個實體,畢竟這是一篇講調度器的文檔。
任務調度器是操作系統一個很重要的部件,它的主要功能就是把系統中的task調度到各個CPU上去執行滿足如下的性能需求:
1、對于time-sharing的進程,調度器必須是公平的
2、快速的進程響應時間
3、系統的throughput要高
4、功耗要小
當然,不同的任務有不同的需求,因此我們需要對任務進行分類:一種是普通進程,另外一種是實時進程。對于實時進程,毫無疑問快速響應的需求是最重要的,而對于普通進程,我們需要兼顧前三點的需求。相信你也發現了,這些需求是互相沖突的,對于這些time-sharing的普通進程如何平衡設計呢?這里需要進一步將普通進程細分為交互式進程(interactive processs)和批處理進程(batch process)。交互式進程需要和用戶進行交流,因此對調度延遲比較敏感,而批處理進程屬于那種在后臺默默干活的,因此它更注重throughput的需求。當然,無論如何,分享時間片的普通進程還是需要兼顧公平,不能有人大魚大肉,有人連湯都喝不上。功耗的需求其實一直以來都沒有特別被調度器重視,當然在linux大量在手持設備上應用之后,調度器不得不面對這個問題了,當然限于篇幅,本文就不展開了。
為了達到這些設計目標,調度器必須要考慮某些調度因素,比如說“優先級”、“時間片”等。很多RTOS的調度器都是priority-based的,官大一級壓死人,調度器總是選擇優先級最高的那個進程執行。而在Linux內核中,優先級就是實時進程調度的主要考慮因素。而對于普通進程,如何細分時間片則是調度器的核心思考點。過大的時間片會嚴重損傷系統的響應延遲,讓用戶明顯能夠感知到延遲,卡頓,從而影響用戶體驗。較小的時間片雖然有助于減少調度延遲,但是頻繁的切換對系統的throughput會造成嚴重的影響。因為這時候大部分的CPU時間用于進程切換,而忘記了它本來的功能其實就是推動任務的執行。
由于Linux是一個通用操作系統,它的目標是星辰大海,既能運行在嵌入式平臺上,又能在服務器領域中獲得很好的性能表現,此外在桌面應用場景中,也不能讓用戶有較差的用戶體驗。因此,Linux任務調度器的設計是一個極具挑戰性的工作,需要在各種有沖突的需求中維持平衡。還好,經過幾十年內核黑客孜孜不倦的努力,Linux內核正在向著最終目標邁進。
三、2.4時代的O(n)調度器
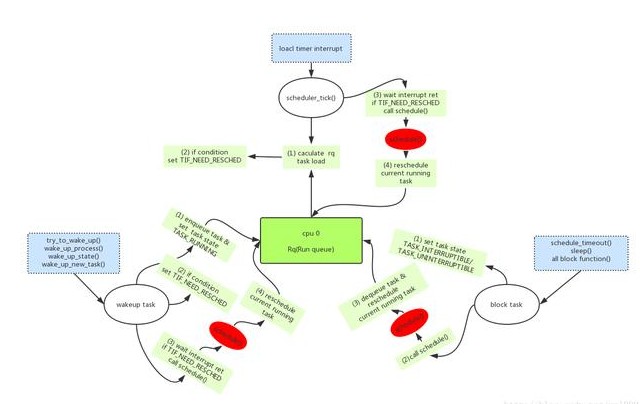
網上有很多的linux內核考古隊,挖掘非常古老內核的設計和實現。雖然我對進程調度器歷史感興趣,但是我只對“近代史”感興趣,因此,讓我們從2.4時代開始吧,具體的內核版本我選擇的是2.4.18版本,該版本的調度器相關軟件結構可以參考下面的圖片:
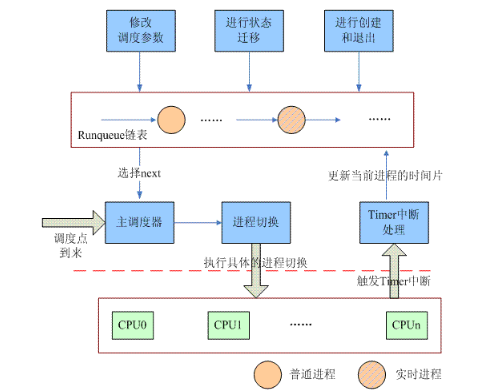
本章所有的描述都是基于上面的軟件結構圖。
1、進程描述符
|
struct task_struct { volatile long need_resched; long counter; long nice; unsigned long policy; int processor; unsigned long cpus_runnable, cpus_allowed; struct list_head run_list; unsigned long rt_priority; ...... }; |
對于2.4內核,進程切換有兩種,一種是當進程由于需要等待某種資源而無法繼續執行下去,這時候只能是主動將自己掛起(調用schedule函數),引發一次任務調度過程。另外一種是進程歡快執行,但是由于各種調度事件的發生(例如時間片用完)而被迫讓出CPU,被其他進程搶占。這時候的調度并不是立刻發送,而是延遲執行,具體的方法是設定當前進程的need_resched等于1,然后靜靜的等待最近一個調度點的來臨,當調度點到來的時候,內核會調用schedule函數,搶占當前task的執行。
nice成員就是普通進程的靜態優先級,通過NICE_TO_TICKS宏可以將一個進程的靜態優先級映射成缺省時間片,保存在counter成員中。因此在一次調度周期開始的時候,counter其實就是該進程分配的CPU時間額度(對于睡眠的進程還有些獎勵,后面會描述),以tick為單位,并且在每個tick到來的時候減一,直到耗盡其時間片,然后等待下一個調度周期從頭再來。
Policy是調度策略,2.4內核主要支持三種調度策略,SCHED_OTHER是普通進程,SCHED_RR和SCHED_FIFO是實時進程。SCHED_RR和SCHED_FIFO的調度策略在rt_priority不同的時候,都是誰的優先級高誰先執行,唯一的不同是相同優先級的處理:SCHED_RR采用時間片輪轉,而SCHED_FIFO采用的策略是先到先得,先占有CPU的進程會持續執行,直到退出或者阻塞的時候才會讓出CPU。也只有這時候,其他同優先級的實時進程才有機會執行。如果進程是實時進程,那么rt_priority表示該進程的靜態優先級。這個成員對普通進程是無效的,可以設定為0。除了上面描述的三種調度策略,policy成員也可以設定SCHED_YIELD的標記,當然它和調度策略無關,主要處理sched_yield系統調用的。
Processor、cpus_runnable和cpus_allowed這三個成員都是和CPU相關。Processor說明了該進程正在執行(或者上次執行)的邏輯CPU號;cpus_allowed是該task允許在那些CPU上執行的掩碼;cpus_runnable是為了計算一個指定的進程是否適合調度到指定的CPU上去執行而引入的,如果該進程沒有被任何CPU執行,那么所有的bit被設定為1,如果進程正在被某個CPU執行,那么正在執行的CPU bit設定為1,其他設定為0。具體如何使用cpus_runnable可以參考can_schedule函數。
run_list成員是鏈接入各種鏈表的節點,下一小節會描述內核如何組織task,這里不再贅述。
2、如何組織task
Linux2.4版本的進程調度器使用了非常簡陋的方法來管理可運行狀態的進程。調度器模塊定義了一個runqueue_head的鏈表頭變量,無論進程是普通進程還是實時進程,只要進程狀態變成可運行狀態的時候,它會被掛入這個全局runqueue鏈表中。隨著系統的運行,runqueue鏈表中的進程會不斷的插入或者移除。例如當fork進程的時候,新鮮出爐的子進程會掛入這個runqueue。當阻塞或者退出的時候,進程會從這個runqueue中刪除。但是無論如何變遷,調度器始終只是關注這個全局runqueue鏈表中的task,并把最適合的那個任務丟到CPU上去執行。由于整個系統中的所有CPU共享一個runqueue,為了解決同步問題,調度器模塊定義了一個自旋鎖來保護對這個全局runqueue的并發訪問
除了這個runqueue隊列,系統還有一個囊括所有task(不管其進程狀態為何)的鏈表,鏈表頭定義為init_task,在一個調度周期結束后,重新為task賦初始時間片值的時候會用到該鏈表。此外,進入sleep狀態的進程分別掛入了不同的等待隊列中。當然,由于這些進程鏈表和調度關系不是那么密切,因此上圖中并沒有標識出來。
3、動態優先級和靜態優先級
所謂靜態優先級就是task固有的優先級,不會隨著進程的行為而改變。對于實時進程,靜態優先級就是rt_priority,而對于普通進程,靜態優先級就是(20 – nice)。然而實際上調度器在進行調度的時候,并沒有采用靜態優先級,而是比對動態優先級來決定誰更有資格獲得CPU資源,當然動態優先級的計算是基于靜態優先級的。
在計算動態優先級(goodness函數)的時候,我們可以分成兩種情況:實時進程和普通進程。對于實時進程而言,動態優先級等于靜態優先級加上一個固定的偏移:
| weight = 1000 + p->rt_priority; |
之所以這么做是為了將實時進程和普通進程區別開,這樣的操作也保證了實時進程會完全優先于普通進程的調度。而對于普通進程,動態優先級的計算稍微有些復雜,我們可以摘錄部分代碼如下:
|
weight = p->counter; if (!weight) goto out; weight += 20 - p->nice; |
對于普通進程,計算動態優先級的策略如下:
(1) 如果該進程的時間片已經耗盡,那么動態優先級是0,這也意味著在本次調度周期中該進程已經再也沒有機會獲取CPU資源了。
(2) 如果該進程的時間片還有剩余,那么其動態優先級等于該進程剩余的時間片和靜態優先級之和。之所以用(20-nice value)表示靜態優先級,主要是為了讓靜態優先級變成單調上升。之所以要考慮剩余時間片是為了獎勵睡眠的進程,因為睡眠的進程剩余的時間片較多,因此動態優先級也就會高一些,更容易被調度器調度執行。
調度器是根據動態優先級來進行調度,誰大就先執行誰。我們可以用普通進程作為例子:如果進程靜態優先級高(即nice value小),剩余時間片多,那么必定是優先執行。如果靜態優先級高,但是所剩時間片無幾,那么可能會讓位給其他剩余時間片較多,優先級適中的任務。靜態優先級低的任務毫無疑問是受到雙重打擊,因為本來它的缺省時間片就不多,而且優先級也很低。不過,無論靜態優先級如何高,只要時間片用完,那么低優先級的任務總是能夠有機會執行,不至于餓死。
在計算普通進程的動態優先級的時候,除了考慮進程剩余時間片信息和靜態優先級,調度器也會酌情考慮cache和TLB的性能問題。例如,例如A和B進程優先級相同,剩余的時間片都是3個tick,但是A進程上一次就是運行在本CPU上,如果選擇A,可能會有更好的cache和TLB的命中率,從而提高性能。在這種情況下,調度器會提升A進程的動態優先級。此外,如果備選進程和當前進程共享同一個地址空間,那么在計算調度指數的時候也會做小小的傾斜。這里有兩種可能的情況:一種是備選進程和當前進程在一個線程組中(即是進程中的兩個線程),另外一種情況是備選進程是內核線程,這時候,它往往會借用上一個進程地址空間。不論是哪一種情況,在進程切換的時候,由于不需要進行進程地址空間的切換,因此也會有性能的優勢。
3、調度時機
對于2.4內核,產生調度的時機主要包括:
(1) 進程主動發起調度。
(2) 在timer中斷處理中發現當前進程耗盡其時間片
(3) 進程喚醒的時候(例如喚醒一個RT進程)。更詳細的信息可以參考下一個小節。
(4) 父進程在fork的時候,其時間片會均分到父子進程,但是如果只剩下一個tick,這個tick會分配給子進程,而父進程的時間片則被清零,這時候,進程遭遇的場景等同與在timer中斷處理中發現當前進程耗盡其時間片。如果父進程在fork的時候,其時間片較大,父子進程的時間片都不為0,這時候的場景類似于喚醒進程。因為這兩個場景都是向runqueue中添加了一個task node,從而引發的調度。
(5) 進程切換的時候。當在系統中的某個CPU上發生了進程切換,例如A任務切換到了B任務,這時候是否A任務就失去了執行的機會了呢?當然也未必,因為雖然競爭本CPU失敗,但是也許其他的CPU上運行的task動態優先級還不如A呢,抑或正好其他CPU有進入idle狀態,正等待著新進程入駐。
(6) 用戶進程主動讓出CPU的時候
(7) 用戶進程修改調度參數的時候
上面的種種場景,除了進程主動調度之外,其他的場景都不是立刻調度schedule函數,而是設定need_resched標記,然后等待調度點的到來。由于2.4內核不是preemptive kernel,因此調度點總是在返回用戶空間的時候才會到來。當調度點到來的時候,進程調度就會在該CPU上啟動。搶占的場景太多,我們選擇進程喚醒的場景來詳細描述,其他場景大家自行分析吧。
4、進程喚醒的處理
當進程被喚醒的時候(try_to_wake_up),該task會被加入到那個全局runqueue中,但是是否啟動調度還需要進行一系列的判斷。為了能清楚的描述這個場景,我們定義執行喚醒的那個進程是waker,而被喚醒的進程是wakee。Wakeup有兩種,一種是sync wakeup,另外一種是non-sync wakeup。所謂sync wakeup就是waker在喚醒wakee的時候就已經知道自己很快就進入sleep狀態,而在調用try_to_wake_up的時候最好不要進行搶占,因為waker很快就主動發起調度了。此外,一般而言,waker和wakee會有一定的親和性(例如它們通過share memory進行通信),在SMP場景下,waker和wakee調度在一個CPU上執行的時候往往可以獲取較佳的性能。而如果在try_to_wake_up的時候就進行調度,這時候wakee往往會調度到系統中其他空閑的CPU上去。這時候,通過sync wakeup,我們往往可以避免不必要的CPU bouncing。對于non-sync wakeup而言,waker和wakee沒有上面描述的同步關系,waker在喚醒wakee之后,它們之間是獨立運作,因此在喚醒的時候就可以嘗試去觸發一次調度。
當然,也不是說sync wakeup就一定不調度,假設waker在CPU A上喚醒wakee,而根據wakee進程的cpus_allowed成員發現它根本不能在CPU A上調度執行,那么管他sync不sync,這時候都需要去嘗試調度(調用reschedule_idle函數),反正waker和wakee命中注定是天各一方(在不同的CPU上執行)。
我們首先看看UP上的情況。這時候waker和wakee在同一個CPU上運行(當然系統中也只有一個CPU,哈哈),這時候誰能搶占CPU資源完全取決于waker和wakee的動態優先級,如果wakee的動態優先級大于waker,那么就標記waker的need_resched標志,并在調度點到來的時候調用schedule函數進行調度。
SMP情況下,由于系統的CPU資源比較多,waker和wakee沒有必要爭個你死我活,wakee其實也可以選擇去其他CPU執行,相關的算法大致如下:
(1) 優先調度wakee去系統其他空閑的CPU上執行,如果wakee上次運行的CPU恰好處于idle狀態的時候,可以考慮優先將wakee調度到那個CPU上執行。如果不是,那么需要掃描系統中所有的CPU找到最合適的idle CPU。所謂最合適就是指最近才進入idle的那個CPU。
(2) 如果所有的CPU都是busy的,那么需要遍歷所有CPU上當前運行的task,比對它們的動態優先級,找到動態優先級最低的那個CPU。
(3) 如果動態優先級最低的那個task的優先級仍然高于wakee,那么沒有必要調度,runqueue中的wakee需要耐心等待下一次機會。如果wakee的動態優先級高于找到的那個動態優先級最低的task,那么標記其need_resched標志。如果不是搶占waker,那么我們還需要發送IPI去觸發該CPU的調度。
當然,這是2.4內核調度器的設計選擇,實際上這樣的操作值得商榷。限于篇幅,本文就不再展開敘述,如果有機會寫負載均衡的文章就可以好好的把這些關系梳理一下。
5、主調度器算法
主調度器(schedule函數)核心代碼如下:
|
list_for_each(tmp, &runqueue_head) { p = list_entry(tmp, struct task_struct, run_list); int weight = goodness(p, this_cpu, prev->active_mm); if (weight > c) c = weight, next = p; } |
list_for_each用來遍歷runqueue_head鏈表上的所有的進程,臨時變量p就是本次需要檢查的進程描述符。如何判斷哪一個進程是最適合調度執行的進程呢?我們需要計算進程的動態優先級(對應上面程序中的變量weight),它是通過goodness函數實現的。動態優先級最大的那個進程就是當前最適合調度到CPU執行的進程。一旦選中,調度器會啟動進程切換,運行該進程以替換之前的那個進程。
根據代碼可知:即便鏈表第一個節點就是最合的下一個要調度執行的進程,調度器算法仍然會遍歷全局runqueue鏈表,一一比對。由此我們可以判斷2.4內核中的調度器的算法復雜度是O(n)。一旦選中了下一個要執行的進程,進程切換模塊就會在該CPU上執行具體的進程切換。
對于SCHED_RR的實時進程,優先級相等的情況下還需要有一個時間片輪轉的概念。因此,在遍歷鏈表之前我們就先處理該進程的時間片處理:
|
if (unlikely(prev->policy == SCHED_RR)) if (!prev->counter) { prev->counter = NICE_TO_TICKS(prev->nice); move_last_runqueue(prev); } |
如果時間片(對應上面程序中的prev->counter)用完,SCHED_RR的實時進程會被移到runqueue鏈表的尾部。通過這樣的處理,優先級相等的SCHED_RR在遍歷runqueue鏈表的時候會命中鏈表中的第一個task,從而實現時間片輪轉的概念。這里有一個比較奇葩的事情就是SCHED_RR的時間片是根據其nice value設定,而實際上nice value應該只適用于普通進程的。
6、時間片處理
普通進程的時間片處理思路是這樣:
(1)每個進程根據其靜態優先級可以固定分配一個缺省的時間片,靜態優先級越大,分配的時間片就越大。
(2)一旦Runqueue中的進程被調度執行,那么其時間片就會在tick到來的時候遞減,如果進程時間片耗盡,那么該進程將失去分配CPU資源的資格。
(3)Runqueue中的進程的時間片全部被用完之后,我們稱一個調度周期結束,這時候需要為runqueue中的進程重新設定其缺省時間片,這樣,一個新的調度周期又開始了。
如何確定每個進程的缺省時間片呢?由于時間片是按照tick來分配的,那么最小的時間片也是1個tick,也就是說最低優先級(nice value等于19)的缺省時間片就是1個tick。對于中間優先級(nice value等于0)的時間片,我們將其設定為50ms左右,具體的算法大家可以自行參考NICE_TO_TICKS的代碼實現。不得不承認這個根據nice value計算缺省時間片的過程還是很丑陋的,不同的HZ設定,計算得到的缺省時間片是不一樣的。也就是說系統的調度行為和HZ的設定有關,這叫有代碼潔癖的同學如何能夠接受。不論如何,我們還是給出實際的例子來感受一下:
| ? | -20 | -10 | 0 | 10 | 19 |
| HZ=100 |
11個tick 110ms |
8個tick 80ms |
6個tick 60ms |
3個tick 30ms |
1個tick 10ms |
| HZ=1000 |
81個tick 81ms |
61個tick 61ms |
41個tick 41ms |
21tick 21ms |
3個tick 3ms |
當runqueue中所有進程的時間片耗盡之后,這時候就會開啟一次重新加載進程缺省時間片的過程,代碼如下(在schedule函數中):
|
if (unlikely(!c)) { struct task_struct *p; for_each_task(p) p->counter = (p->counter >> 1) + NICE_TO_TICKS(p->nice); goto repeat_schedule; } |
這里c就是遍歷runqueue鏈表之后找到的最大動態優先級,如果它等于0則說明:首先,系統中沒有處于可運行狀態的實時進程,其次,所有的處于可運行狀態的普通進程都已經消耗完了它們的時間片,這時候是需要重新“充值”了。for_each_task這個宏是遍歷所有系統中的進程描述符,不論是否是可運行狀態的。對于掛入runqueue鏈表中的普通進程而言,其當前的時間片p->counter已經是等于0了,因此它獲得的新的時間片就是NICE_TO_TICKS(p->nice),也就是根據nice value計算得到的缺省時間片。對于掛入等待隊列中處于睡眠狀態的進程而言,其時間片p->counter還有剩余,當然會累積到進程時間片配額中,這也算是對睡眠進程的一種獎勵吧。為了防止經常睡眠的交互式進程獲得過于龐大的時間片,這里并不是累積其全部存留時間片,而是打了個對折(p->counter >> 1)。
新的一個周期開始了,當前進程已經在CPU上奔跑了,消耗其時間片的代碼位于timer中斷處理中,如下:
|
if (--p->counter <= 0) { p->counter = 0; p->need_resched = 1; } |
每一個tick到來的時候,進程的時間片都會減一,當時間片是0的時候,調度器剝奪其執行的權力,從而從而引發一次調度,選擇其他時間片不是0的進程運行,直到runqueue中的所有進程時間片耗盡,又會重新賦值,開始一個新的周期。調度器就這樣周而復始,推動整個系統的運作。
四、2.6時代的O(1)調度器
1、Why O(1)調度器
如果簡單是判斷調度器好壞的唯一標準,那么無疑O(n)調度器是最優秀的調度器。雖然它非常的簡單,容易理解,但是存在嚴重的擴展性問題和性能問題。下面讓我們一起來控訴O(n)調度器的“七宗罪”,同時這也是Ingo Molnar發起O(1)調度器項目背后的原因。
(1)算法復雜度問題
讓人最不爽的就是對runqueue隊列的遍歷,當系統中runnable進程不多的時候,遍歷鏈表的開銷還可以接受,但是隨著系統中runnable狀態的進程數目增多,那么調度器select next的運算量也隨之呈線性的增長,這也是我們為什么叫它O(n)調度器的原因。
此外,調度周期結束后,調度器會為所有進程的時間片進行“充值“的動作。在大型系統中,同時存在的進程(包括睡眠的進程)可能會有數千個,為每一個進程計算其時間片的過程太耗費時間。
(2)SMP擴展性問題
2.4內核的O(n)調度器有非常差的SMP擴展性。我們知道,O(n)調度器是通過一個鏈表來管理系統中的所有的等待調度的進程,訪問這個runqueue鏈表的場景很多:進行調度的時候,我們需要遍歷runqueue,找到合適的next task;wakeup或者block進程的時候,我們需要從runqueue中增加節點或者刪除節點……在訪問runqueue這個鏈表的時候,我們都會首先會上自旋鎖,同時disable本地CPU中斷,然后訪問鏈表執行相應的動作,完成之后釋放鎖,開中斷。通過這樣的內核同步機制,我們可以保證來自多個CPU對runqueue鏈表的并發訪問。當系統中的CPU數目比較少的時候,自旋鎖的開銷還可以接受,但是在大型系統中,CPU數目非常多,這時候runqueue spin lock就成為系統的性能瓶頸。
(3)CPU空轉問題
每當runqueue鏈表中的所有進程耗盡了其時間片,這時候就需要啟動對系統中所有進程時間片重新計算的過程。這個計算過程異常丑陋,需要遍歷系統中的所有進程(注意:是所有進程!),為進程描述符的counter成員賦一個新值。而這個操作足以把該CPU上的L1 cache全部干掉。當完成了時間片重新計算過程后,你幾乎面對的就是一個全空的L1 cache(當然不是全空,主要是cache中的數據沒有任何意義,這時候L1 cache的命中率急劇下降)。除此之外,時間片重新計算過程會帶來CPU資源的浪費,我們用下面的圖片來描述:

在runqueue隊列中的全部進程時間片被耗盡之前,系統總會處于這樣一個狀態:最后的一組尚存時間片的進程分分別調度到各個CPU上去。我們以4個CPU為例,T0~T3分別運行在CPU0~CPU3上。隨著系統的運行,CPU2上的T2首先耗盡了其時間片,但是這時候,其實CPU2上也是無法進行調度的,因為遍歷runqueue鏈表,找不到適合的進程調度運行,因此它只能是處于idle狀態。也許隨后T0和T3也耗盡其時間片,從而導致CPU0和CPU3也進入了idle狀態。現在只剩下最后一個進程T1仍然在CPU1上運行,而其他系統中的處理器處于idle狀態,白白的浪費資源。唯一能改變這個狀態的是T1耗盡其時間片,從而啟動一個重新計算時間片的過程,這時候,正常的調度就可以恢復了。隨著系統中CPU數目的加大,資源浪費會越來越嚴重。
(4)task bouncing issue
一般而言,一個進程最好是從一而終,假如它運行在系統中的某個CPU中,那么在其處于可運行狀態的過程中,最好是一直保持在該CPU上運行。不過在O(n)調度器下,很多人都反映有進程在CPU之間跳來跳去的現象。其根本的原因也是和時間片算法相關。在一個新的周期開后,runqueue中的進程時間片都是滿滿的,在各個CPU上調度進程的時候,它可選擇的比較多,再加上調度器傾向于調度上次運行在本CPU的進程,因此調度器有很大的機會把上次運行的進程調度到同一個處理器上。但是隨著runqueue中的進程一個個的耗盡其時間片,cpu可選擇的余地在不斷的壓縮,從而導致進程執行在一個和它親和性不大的處理器(例如上次該進程運行在CPU0,但是這個將其調度到CPU1執行,但是實際上該進程和CPU0的親和性更大些)。
(5)RT進程調度性能問題
實時調度的性能一般。通過上一節的介紹,我們知道,實時進程和普通進程掛在一個鏈表中。當調度實時進程的時候,我們需要遍歷整個runqueue列表,掃描并計算所有進程的調度指數,從而選擇出心儀的那個實時進程。按理說實時進程和普通進程位于不同的調度空間,兩不相干,但是現在調度實時進程還需要掃描計算普通進程,這樣糟糕的算法讓那些關注實時性的工程師不能忍受。
當然,上面的這些還不是關鍵,最重要的是整個linux內核不是搶占式內核,在整個內核態都不能被搶占。對于一些比較耗時(可能幾個毫秒)的系統調用或者中斷處理,必須返回用戶空間才啟動調度是不可接受的。除了內核搶占性之外,優先級翻轉問題也需要引起調度器的重視,否則即便一個rt進程變成runnable狀態了,但是也只能眼睜睜的看著比它優先級低的進程運行,直到該rt進程等待的資源被釋放。
(6)交互式普通進程的調度延遲問題
O(n)并不區分交互式進程和批處理進程,它只是獎勵經常睡眠的那些進程。但是有些批處理進程也屬于IO-bound進程,例如數據庫服務進程,它本身是一個后臺進程,對調度延遲不敏感,但是由于它需要和磁盤打交道,因此也會經常阻塞在disk IO上。對這樣的后臺進程進行動態優先級的升高其實是沒有意義的,會增大其他交互式進程的調度延遲。另外一方面,用戶交互式進程也可能是CPU-bound的,而這時候調度器不會正確的了解到該進程的調度需求并對其進行補償。
(7)時間片粒度問題。
用戶感知到的響應延遲是和系統負載相關,我們可以用runnable進程數目來粗略的描述系統的負載。當系統負載高的時候,runqueue中的進程數目會比較多,一次調度周期的時間就會比較長,例如在HZ=100的情況下,runqueue上有5個runnable進程,nice value是0,每個時間片配額是60ms,那么一個調度周期就是300ms。隨著runnable進程增大,調度周期也變大。當一個進程耗盡其時間片之后,只能等待下一個調度周期到來。因此隨著調度周期變大,系統響應也會變的較差。
雖然O(n)調度器存在不少的issue,但是社區的人還是基本認可這套算法的,因此在設計新的調度器的時候并不是完全推翻O(n)調度器的設計,而是針對O(n)調度器的問題進行改進。在本章中我們選擇2.6.11版本的內核來描述O(1)調度器如何運作。鑒于O(1)調度器和O(n)調度器沒有本質區別,因此我們只是描述它們之間不同的地方。
2、O(1)調度器的軟件功能劃分
下圖是一個O(1)調度器的軟件框架:

O(n)調度器中只有一個全局的runqueue,嚴重影響了擴展性,因此在O(1)調度器中引入了per-CPU runqueue的概念。系統中所有的可運行狀態的進程首先經過負載均衡模塊掛入各個CPU的runqueue,然后由主調度器和tick調度器驅動該CPU上的調度行為。由于篇幅的原因,我們在本文中不講解負載均衡模塊,把重點放在單個CPU上的任務調度算法。
由于引入了per-CPU runqueue,O(1)調度器刪除了全局runqueue的spin lock,而是把這個spin lock放入到per-CPU runqueue數據結構中(rq->lock),通過把一個大鎖細分成小鎖,可以大大降低調度延遲,提升系統響應時間。這種方法在內核中經常使用,是一個比較通用的性能優化方法。
通過上面的軟件結構劃分可以解決O(n)調度的SMP擴展性問題和CPU空轉問題。此外,好的復雜均衡算法也可以解決O(n)調度器的task bouncing 問題。
3、O(1)調度器的runqueue結構
O(1)調度器的基本優化思路就是把原來runqueue上的單鏈表變成多個鏈表,即每一個優先級的進程被掛入不同鏈表中。相關的軟件結構可以參考下面的圖片:
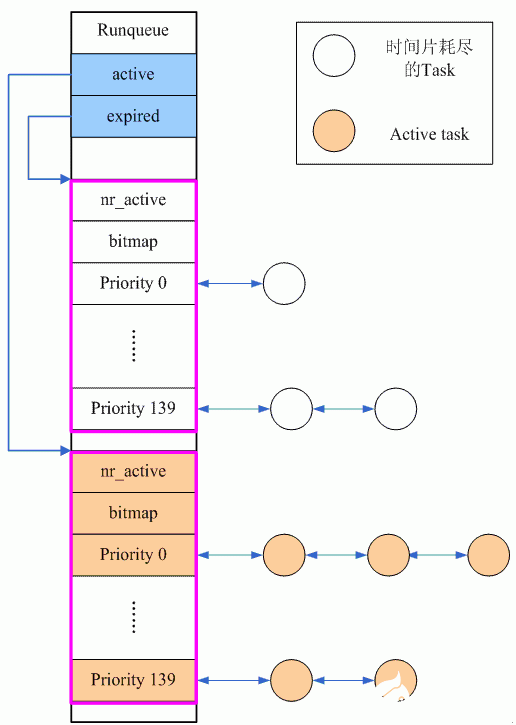
在調度器中,runqueue是一個很重要的數據結構,它最重要的作用是管理那些處于可運行狀態的進程。O(1)調度器引入了優先級隊列的概念來管理task,具體由struct prio_array抽象:
|
struct prio_array { unsigned int nr_active; unsigned long bitmap[BITMAP_SIZE]; struct list_head queue[MAX_PRIO]; }; |
由于支持140個優先級,因此queue成員中有140個分別表示各個優先級的鏈表頭,不同優先級的進程掛入不同的鏈表中。bitmap 是表示各個優先級進程鏈表是空還是非空。nr_active表示這個隊列中有多少個task。在這些隊列中,100~139是普通進程的優先級,其他的是實時進程的優先級。因此,在O(1)調度器中,RT進程和普通進程被區分開了,普通進程根本不會影響RT進程的調度。
Runqueue中有兩個優先級隊列(struct prio_array)分別用來管理active(即時間片還有剩余)和expired(時間片耗盡)的進程。Runqueue中有兩個優先級隊列的指針,分別指向這兩個優先級隊列。隨著系統的運行,active隊列的task一個個的耗盡其時間片,掛入到expired隊列。當active隊列的task為空的時候,切換active和expired隊列,開始一輪新的調度過程。
雖然在O(1)調度器中task組織的形式發生了變化,但是其核心思想仍然和O(n)調度器一致的,都是把CPU資源分成一個個的時間片,分配給每一個runnable的進程。進程用完其額度后被搶占,等待下一個調度周期的到來。
4、核心調度算法
主調度器(就是schedule函數)的主要功能是從該CPU的runqueue找到一個最合適的進程調度執行。其基本的思路就是從active優先級隊列中尋找,代碼如下:
|
idx = sched_find_first_bit(array->bitmap); queue = array->queue + idx; next = list_entry(queue->next, task_t, run_list); |
首先在當前active優先級隊列的bitmap尋找第一個非空的進程鏈表,然后從該鏈表中找到的第一個節點就是最適合下一個調度執行的進程。由于沒有遍歷整個鏈表的操作,因此這個調度器的算法復雜度是一個常量,從而解決了O(n)算法復雜度的issue。
如果當前active優先級隊列中“空無一人”(nr_active等于0),那么這時候就需要切換active和expired優先級隊列了:
|
if (unlikely(!array->nr_active)) { rq->active = rq->expired; rq->expired = array; array = rq->active; } |
切換很快,并沒有一個遍歷所有進程重新賦default時間片的操作(大大縮減了runqueue臨界區的size)。這些都避免了O(n)調度器帶來的種種問題,從而提高了調度器的性能。
5、靜態優先級和動態優先級
在前面的小節中,我們有意的忽略了優先級隊列中“優先級”的具體含義,現在是需要澄清的時候了。其實優先級隊列中“優先級”指的是動態優先級,從這個角度看,O(1)和O(n)調度器的調度算法又統一了,都是根據動態優先級進行調度。
O(1)的靜態優先級的概念和O(n)是類似的,對于實時進程保存在進程描述符的rt_priority成員中,取值范圍是1(優先級最低)~99(優先級最高)。對于普通進程,靜態優先級則保存在static_prio成員中,取值范圍是100(優先級最高)~139(優先級最低),分別對應nice value的-20 ~ 19。
了解了靜態優先級之后,我們一起來看看動態優先級(保存在進程描述符的prio成員中)。鑒于在實際調度的時候使用的是動態優先級,我們必須要保證它是單調的(靜態優先級未能保持單調,rt的99和普通進程的100都是靜態優先級的最高點,也就是說在靜態優先級數軸上,rt段是單調上升,而在普通進程段是單調下降的)。為了解決這個問題,在計算實時進程動態優先級的時候進行了一個簡單的映射:
| p->prio = MAX_USER_RT_PRIO-1 - p->rt_priority; |
通過這樣的轉換,rt的動態優先級在數軸上也是單調下降的了。普通進程的動態優先級計算沒有那么簡單,除了靜態優先級,還需要考慮進程的平均睡眠時間(保存在進程描述符的sleep_avg成員中),并根據該值對進程進行獎懲。具體代碼可以參考effective_prio函數,這里不再詳述,最終普通進程的動態優先級是100(優先級最高)~139(優先級最低),和靜態優先級的取值范圍是一致的。
在本小節的最后,我們一起來對比普通進程在O(1)和O(n)調度器的動態優先級算法。這個兩個調度器的基本思路是一致的:考慮靜態優先級,輔以對該進程的“用戶交互指數”的評估,用戶交互指數高的,調升其動態優先級,反之則降低。不過在評估用戶交互指數上,O(1)顯然做的更好。O(n)調度器僅僅考慮了睡眠進程的剩余時間片,而O(1)的“平均睡眠時間”算法顯然考慮更多的因素:在cpu上的執行時間、在runqueue中的等待時間、睡眠時間、睡眠時候的進程狀態(是否可被信號打斷),什么上下文喚醒(中斷上下文喚醒還是在進程上下文中喚醒)……因此O(1)調度器更好的判斷了進程是屬于interactive process還是batch process,從而精準的為interactive process打call。
6、時間片處理
缺省時間片的計算是通過task_timeslice完成的,在O(1)調度器中,缺省時間片已經和HZ無關了,無論如何設置HZ,靜態優先級為[ -20 ... 0 ... 19 ]的普通進程其缺省時間片為[800ms ... 100ms ... 5ms]。
在tick到來的時候,當前task的時間片會遞減(--p->time_slice),當時間片等于0的時候,會將該task從active優先級列表中摘下,設定resched標記,并且重置時間片,代碼如下:
|
dequeue_task(p, rq->active); set_tsk_need_resched(p); p->time_slice = task_timeslice(p); |
task_timeslice函數就是用來計算進程時間片的配額的。對于O(1)調度器,時間片的重新賦值是分散處理的,在各個task耗盡其時間片之后立刻進行的。這樣的改動也修正了O(n)調度器一次性的遍歷系統所有進程,重新為時間片賦值的過程。
6、識別用戶交互式進程
一般而言,時間片耗盡之后,該task會被掛入到expired優先級隊列,這時候如果想要被調度只能等到下次active和expired切換了。不過,有些特殊的場景需要特殊處理:
|
if (!TASK_INTERACTIVE(p) || EXPIRED_STARVING(rq)) { enqueue_task(p, rq->expired); if (p->static_prio < rq->best_expired_prio) rq->best_expired_prio = p->static_prio; } else enqueue_task(p, rq->active); |
這里TASK_INTERACTIVE是用來判斷一個進程是否是一個用戶交互式進程(也是和平均睡眠時間相關,由此可見,平均睡眠時間不僅用于計算動態優先級,還用來決定一個進程是否回插入active隊列),如果是的話,說明該進程對用戶響應比較敏感,這時候不能粗暴的掛入expired隊列,而是重新掛入active隊列,繼續有機會獲取調度執行的機會。由此可見,O(1)調度器真是對用戶交互式進程非常的照顧,一旦被判斷是用戶交互型進程,那么它將獲取連續執行的機會。當然,調度器也不能太過分,如果用戶交互型進程持續占用CPU,那么在expired隊列中苦苦等待進程怎么辦?這時候就要看看expired隊列中的進程的饑餓狀態了,這也就是EXPIRED_STARVING這個宏定義的功能。如果expired隊列中的進程等待了太長的時間,那么說明調度器已經出現嚴重不公平的現象,因此這時候即便是判斷當前耗盡時間片的進程是用戶交互型進程,也把它掛入expired隊列,盡快的完成本次調度周期,讓active和expired發生切換。
O(1)調度器使用非常復雜的算法來判斷進程的用戶交互指數以及進程是否是交互式進程,hardcode了很多的不知其所以然的常數,估計也是通過各種大量的實驗場景總結出來的。這部分的設計概念我是在是沒有勇氣去探索,因此這里就略過了。但是無論如何,它總是比僅僅考慮睡眠時間的O(n)調度器性能要好。
7、搶占式內核
2.4時代,大部分的Linux應用都集中在服務器領域,因此非搶占式內核的設計選擇也無可厚非。不過隨著Linux在桌面和嵌入式上的滲透,系統響應慢慢的稱為用戶投訴的主要方面,因此,在2.5的開發過程中,Linux引入了搶占式內核的概念(CONFIG_PREEMPT),如果沒有配置該選項,那么一切和2.4內核保持一致,如果配置了該選項,那么不需要在返回用戶空間的時候才苦苦等到調度點,大部分的內核執行路徑都是可以被搶占的。同樣的,限于篇幅,這里不再展開描述。
五、公平調度思想的引入
1、傳統調度器時間片悖論
在O(n)和O(1)調度器中,時間片是固定分配的,靜態優先級高的進程獲取更大的time slice。例如nice value等于20的進程獲取的default timeslice是5ms,而nice value等于0的進程獲取的是100ms。直觀上,這樣的策略沒有毛病(高優先級的獲取更多的執行時間),但是,這樣的設定潛臺詞就是:高優先級的進程會獲得更多的連續執行的機會,這是CPU-bound進程期望的,但是實際上,CPU-bound進程往往在后臺執行,其優先級都是比較低的。
因此,假設我們調度策略就是根據進程靜態優先級確定一個固定大小的時間片,這時候我們在如何分配時間片上會遇到兩難的狀況:想要給用戶交互型進程設定高優先級,以便它能有更好的用戶體驗,但是分配一個大的時間片是毫無意義的,因為這種進程多半是處于阻塞態,等待用戶的輸入。而后臺進程的優先級一般不高,但是根據其優先級分配一個較小的時間片往往會影響其性能,這種類型的進程最好是趁著cache hot的時候狂奔。
怎么辦?或者傳統調度器固定分配時間片這個設計概念就是錯誤的。
2、傳統調度器的卡頓問題
在Linux 2.5版本的開發過程中,Ingo Molnar設計的O(1)調度器替換掉了原始的、簡陋的O(n)調度器,從而解決了擴展性很差,性能不佳的問題。在大部分的場景中,該調度器都獲得了滿意的性能,在商用的Linux 2.4發行版中,O(1)調度器被很多廠商反向移植到Linux 2.4中,由此可見O(1)調度器性能還是優異的。
然而O(1)并非完美,在實際的使用過程中,還是有不少的桌面用戶在抱怨用戶交互性比較差。當一個相當消耗CPU資源的進程啟動的時候,現存的那些用戶交互程序(例如你在通過瀏覽器查看網頁)都可以感覺到明顯的延遲。針對這些issue,很多天才工程師試圖通過對用戶交互指數算法的的修改來解決問題,這里面就包括公平調度思想的提出者Con Kolivas。不過無論如何調整算法,總是有點拆東墻補西墻的感覺,一個場景的issue修復了,另外一個場景又冒出來交互性不好的issue,刁鉆的客戶總是能夠在邊邊角角的場景中找到讓用戶感覺到的響應延遲。
在反反復復修復用戶卡頓issue的過程中,工程師最容易煩躁,而往往這時候最需要冷靜的思考。Con Kolivas仔細的檢視了調度器代碼,他發現出問題的是評估進程用戶交互指數的代碼。為何調度器要根據進程的行為猜測其對交互性的需求?這根本是一項不可能完成的任務,因為你總是不會100%全部猜中,就好像你去猜測你喜歡的女孩子的心事一樣,你細心的收集了關于這個女孩子的性格特點,業余愛好,做事風格,邏輯思維水平,星座……甚至生理周期,并期望著能總是正確的猜中其心中所想,坦率的講這是不可能的。在進程調度這件事情上為何不能根據實實在在確定的東西來調度呢?一個進程的靜態優先級已經完成的說明了其調度需求了,這就足夠了,不需要猜測進程對交互性的需求,只要維持公平就OK了,而所謂的公平就是進程獲取和其靜態優先級匹配的CPU執行時間。在這樣的思想指導下,Con Kolivas提出了RSDL(Rotating Staircase Deadline)調度器。
3、RSDL調度器
RSDL調度器仍然沿用了O(1)調度的數據結構和軟件結構,當然刪除了那些令人毛骨悚然的評估進程交互指數的代碼。我們這一小節不可能詳細描述RSDL算法,不過只要講清楚Rotating、Staircase和Deadline這三個基本概念,大家就應該對RSDL有基本的了解了。
首先看Staircase概念,它更詳細表述應該是priority staircase,即在進程調度過程中,其優先級會象下樓梯那樣一點點的降低。在傳統的調度概念中,一個進程有一個和其靜態優先級相匹配的時間片,在RSDL中,同樣也存在這樣的時間片,但是時間片是散布在很多優先級中。例如如果一個進程的優先級是120,那么整個時間片散布在120~139的優先級中,在一個調度周期,進程開始是掛入120的優先級隊列,并在其上運行6ms(這是一個可調參數,我們假設每個優先級的時間配額是6ms),一旦在120級別的時間配額使用完畢之后,該進程會轉入121的隊列中(優先級降低一個level),發生一次Rotating,更準確的說是Priority minor rotating。之后,該進程沿階而下,直到139的優先級,在這個優先級上如果耗盡了6ms的時間片,這時候,該進程所有的時間片就都耗盡了,就會被掛入到expired隊列中去等待下一個調度周期。這次rotating被稱為major rotating。當然,這時候該進程會掛入其靜態優先級對應的expired隊列,即一切又回到了調度的起點。
Deadline是指在RSDL算法中,任何一個進程可以準確的預估其調度延遲。一個簡單的例子,假設runqueue中有兩個task,靜態優先級分別是130的A進程和139的B進程。對于A進程,只有在進程沿著優先級樓梯從130走到139的時候,B進程才有機會執行,其調度延遲是9 x 6ms = 54ms。
多么簡潔的算法,只需要維持公平,沒有對進程睡眠/運行時間的統計,沒有對用戶交互指數的計算,沒有那些奇奇怪怪的常數……調度,就是這么簡單。
六、CFS調度器
Con Kolivas的RSDL調度器始終沒有能夠進入kernel mainline,取而代之的是同樣基于公平調度思想的CFS調度器,在CFS調度器并入主線的同時,仍然提供了模塊化的設計,為RSDL或者其他的調度器可以進入內核提供了方便。然而Con Kolivas帶著對內核開發模式的不滿永遠的退出了社區,正所謂有人的地方就有江湖,其中的是非留給后人評說吧。
CFS的設計理念就是一句話:在真實的硬件上實現理想的、精準、完全公平的多任務調度。當然,這樣的調度器不存在,在實際設計和實現的時候還是需要做一些折衷。其實CFS調度器的所有的設計思想在上一章都已經非常明晰,本章我們唯一需要描述的是Ingo Molnar如何把完全公平調度的理想照進現實。
1、模塊化思想的引入
從2.6.23內核開始,調度器采用了模塊化設計的思想,從而把進程調度的軟件分成了兩個層次,一個是core scheduler layer,另外一個是specific scheduler layer:

從功能層面上看,進程調度仍然分成兩個部分,第一個部分是通過負載均衡模塊將各個runnable task根據負載情況平均分配到各個CPU runqueue上去。第二部分的功能是在各個CPU的Main scheduler和Tick scheduler的驅動下進行單個CPU上的調度。調度器處理的task各不相同,有RT task,有normal task,有Deal line task,但是無論哪一種task,它們都有共同的邏輯,這部分被抽象成Core scheduler layer,同時各種特定類型的調度器定義自己的sched_class,并以鏈表的形式加入到系統中。這樣的模塊化設計可以方便用戶根據自己的場景定義specific scheduler,而不需要改動Core scheduler layer的邏輯。
2、關于公平
和RSDL調度器一樣,CFS調度器追求的公平是CPU資源分配的公平,即CPU的運算資源被精準的平均分配給在其上運行的task。例如:如果有2個靜態優先級一樣的task運行在某一個CPU上,那么每一個task都消耗50%的CPU計算資源。如果靜態優先級不一樣,那么,CPU資源是根據其靜態優先級來具體分配。具體如何根據優先級來分配CPU資源呢?這里就需要引入一個load weight的概念。
在CFS中,我們是通過一個常量數組(sched_prio_to_weight)可以把進程靜態優先級映射成進程權重,而所謂的權重就是進程應該占有cpu資源的比重。例如:系統中有3個runnable thread A、B和C,權重分別是a、b、c,那么A thread應該分配到的CPU資源是a/(a+b+c)。因此CFS調度器的公平就是保證所有的可運行狀態的進程按照權重分配其CPU資源。
3、時間粒度
CPU資源分配是一個抽象的概念,最終在實現調度器的時候,我們需要把它具體化。一個最簡單的方法就是把CPU資源的分配變成CPU時間片的分配。看到“時間片”這個術語,你可能本能的覺得CFS和O(1)也沒有什么不同,不都是分配時間片嗎?其實不然,Linux內核的CFS調度器已經摒棄了傳統的固定時間片的概念了。O(1)調度器會為每一個進程分配一個缺省的時間片,當進程使用完自己的時間片之后就會被掛入expire隊列,當系統中的所有進程都耗光了自己的時間片,那么一切從來,所有的進程又恢復了自己的時間片,進入active隊列。CFS調度器沒有傳統的靜態時間片的概念,她的時間片是動態的,和當前CPU的可運行狀態的進程以及它們的優先級相關,因此CFS調度器中,時間片是動態變化的。
對于理想的完全公平調度算法,無論觀察的時間段多么短,CPU的時間片都是公平分配的。以100ms的粒度來觀察,那么兩個可運行狀態的進程A和B(靜態優先級一樣)各分50ms。當然,也不是一定是A執行50ms,切換到B,然后再執行50ms,在觀察過程中,A和B可能切換了很多次,但是A進程總共占用CPU的時間和就是50ms,B進程亦然。如果用1ms的粒度來觀察呢?是否A和B個運行500us?如果繼續縮減觀察時間,在一個微秒的時間段觀察呢?顯然,不太可能每個進程運行500ns,如果那樣的話,CPU的時間大量的消耗在了進程切換上,真正做事情的CPU時間變得越來越少了。因此,CFS調度器是有一個時間粒度的定義,我們稱之調度周期。也就是說,在一個調度周期內,CFS調度器可以保證所有的可運行狀態的進程平均分配CPU時間。下一小節我們會詳細描述調度周期的概念。
4、如何保證有界的調度延遲?
傳統的調度器無法保證調度延遲,為了說明這個問題我們設想這樣一個場景:CPU runqueue中有兩個nice value等于0的runnable進程A和B,傳統調度器會為每一個進程分配一個固定的時間片100ms,這時候A先運行,直到100ms的時間片耗盡,然后B運行。這兩個進程會交替運行,調度延遲就是100ms。隨著系統負荷的加重,例如又有兩個兩個nice value等于0的runnable進程C和D掛入runqueue,這時候,A、B、C、D交替運行,調度延遲就是300ms。因此,傳統調度器的調度延遲是和系統負載相關的,當系統負載增加的時候,用戶更容易觀察到卡頓現象。
CFS調度器設計之初就確定了調度延遲的參數,我們稱之targeted latency,這個概念類似傳統調度器中的調度周期的概念,只不過在過去,一個調度周期中的時間片被固定分配給了runnable的進程,而在CFS中,調度器會不斷的檢查在一個targeted latency中,公平性是否得到了保證。下面的代碼說明了targeted latency的計算過程:
|
static u64 __sched_period(unsigned long nr_running) { if (unlikely(nr_running > sched_nr_latency)) return nr_running * sysctl_sched_min_granularity; else return sysctl_sched_latency; } |
當runqueue中的runnable進程的數目小于sched_nr_latency(8個)的時候,targeted latency就是sysctl_sched_latency(6ms),當runqueue中的runnable進程的數目大于等于sched_nr_latency的時候,targeted latency等于runnable進程數目乘以sysctl_sched_min_granularity(0.75ms)。顯然sysctl_sched_min_granularity這個參數就是一段一個進程被調度執行,它需要至少執行的時間片大小,設立這個參數是為了防止overscheduling而產生的性能下降。
CFS調度器保證了在一個targeted latency中,所有的runnable進程都會至少執行一次,從而保證了有界的、可預測的調度延遲。
5、為何引入虛擬時間?
雖然Con Kolivas提出了精采絕倫的設計思想,但是在具體實現的時候相對保守。CFS調度器則不然,它采用了相對激進的方法,把runqueue中管理task的優先級鏈表變成了紅黑樹結構。有了這樣一顆runnable進程的紅黑樹,在插入操作的時候如何確定進程在紅黑樹中的位置?也就是說這棵樹的“key”是什么?
CFS的紅黑樹使用vruntime(virtual runtime)作為key,為了理解vruntime,這里需要引入一個虛擬時間軸的概念。在上一章中,我們已經清楚的表述了公平的含義:按照進程的靜態優先級來分配CPU資源,當然,CPU資源也就是CPU的時間片,因此在物理世界中,公平就是分配和靜態優先級匹配的CPU時間片。但是紅黑樹需要一個單一數軸上的量進行比對,而這里有兩個度量因素:靜態優先級和物理時間片,因此我們需要把它們映射到一個虛擬的時間軸上,屏蔽掉靜態優先級的影響,具體的計算公式如下:
Virtual runtime = (physical runtime) X (nice value 0的權重)/進程的權重
通過上面的公式,我們構造了一個虛擬的世界。二維的(load weight,physical runtime)物理世界變成了一維的virtual runtime的虛擬世界。在這個虛擬的世界中,各個進程的vruntime可以比較大小,以便確定其在紅黑樹中的位置,而CFS調度器的公平也就是維護虛擬世界vruntime的公平,即各個進程的vruntime是相等的。
根據上面的公式,我們可以看出:實際上對于靜態優先級是120(即nice value等于0)的進程,其物理時間軸等于虛擬時間軸,而其他的靜態優先級的虛擬時間都是根據其權重和nice 0的權重進行尺度縮放。對于更高優先級的進程,其虛擬時間軸過的比較慢,而對于優先級比較低的進程,其虛擬時間軸過的比較快。
我們可以舉一個簡單的例子來描述虛擬世界的公平性:例如在時間點a到b之間(虛擬時間軸),如果有兩個可運行狀態的進程A和B,那么從a到b這個時間段上去觀察,CPU的時間是平均分配到每個一個進程上,也就是說A和B進程各自運行了(b-a)/2的時間,也就是各占50%的時間片。在b時間點,一個新的可運行狀態的進程C產生了,直到c時間點。那么從b到c這個時間段上去觀察,進程A、B和進程C都是執行了(c-b)/3的時間,也就是各占1/3的CPU資源。再強調一次,上面說的時間都是虛擬時間。
6、如何計算virtual runtime
想要計算時間我們必須有類似手表這樣的計時工具,對于CFS調度器,這個“手表”保存在runqueue中(clock和clock_task成員)。Runqueue戴兩塊表,一塊記錄實際的物理時間,另外一塊則是記錄執行task的時間(clock_task)。之所以有clock_task是為了更準確的記錄進程執行時間。實際上一個task執行過程中不免會遇到一些異步事件,例如中斷。這時候,進程的執行被打斷從而轉入到對異步事件的處理過程。如果把這些時間也算入該進程的執行時間會有失偏頗,因此clock_task會把這些異步事件的處理時間去掉,只有在真正執行任務的時候,clock_task的counter才會不斷累加計時。
有了clock進程計時變得比較簡單了,當進程進入執行狀態的時候,看一下clock_task這塊“手表”,記錄數值為A。在需要統計運行時間的時候,再次看一下clock_task這塊“手表”,記錄數值為B。B-A就是該進程已經運行的物理時間。當然,CFS關心的是虛擬時間,這時候還需要通過calc_delta_fair函數將這個物理時間轉換成虛擬時間,然后累積的該進程的virtual runtime中(sched_entity中的vruntime),而這個vruntime就是紅黑樹的key。
7、CFS調度器的運作
對于CFS調度器,沒有固定分配時間片的概念,只有一個固定權重的概念,是根據進程靜態優先級計算出來的。CFS調度器一旦選擇了一個進程進入執行狀態,會立刻開啟對其virtual runtime的跟蹤過程,并且在tick到來時會更新這個virtual runtime。有了這個virtual runtime信息,調度器就可以不斷的檢查目前系統的公平性(而不是檢查是否時間片用完),具體的方法是:根據當前系統的情況計算targeted latency(調度周期),在這個調度周期中計算當前進程應該獲得的時間片(物理時間),然后計算當前進程已經累積執行的物理時間,如果大于當前應該獲得的時間片,那么更新本進程的vruntime并標記need resched flag,并在最近的一個調度點發起調度。
在進行進程調度時候,調度器需要選擇下一個占用CPU資源的那個next thread。對于CFS而言,其算法就是從紅黑樹中找到left most的那個task并調度其運行。這時候,失去CPU執行權的那個task會被重新插入紅黑樹,其在紅黑樹中的位置是由task的vruntime值決定的。













 工商網監
工商網監
評論