 電子發燒友App
電子發燒友App


前 言
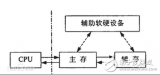
雖然CPU主頻的提升會帶動系統性能的改善,但系統性能的提高不僅僅取決于CPU,還與系統架構、指令結構、信息在各個部件之間的傳送速度及存儲部件的存取速度等因素有關,特別是與CPU/內存之間的存取速度有關。若CPU工作速度較高,但內存存取速度較低,則造成CPU等待,降低處理速度,浪費CPU的能力。如500MHz的PⅢ,一次指令執行時間為2ns,與其相配的內存(SDRAM)存取時間為10ns,比前者慢5倍,CPU和PC的性能怎么發揮出來?
如何減少CPU與內存之間的速度差異?有4種辦法:一種是在基本總線周期中插入等待,這樣會浪費CPU的能力。另一種方法是采用存取時間較快的SRAM作存儲器,這樣雖然解決了CPU與存儲器間速度不匹配的問題,但卻大幅提升了系統成本。第3種方法是在慢速的DRAM和快速CPU之間插入一速度較快、容量較小的SRAM,起到緩沖作用;使CPU既可以以較快速度存取SRAM中的數據,又不使系統成本上升過高,這就是Cache法。還有一種方法,采用新型存儲器。目前,一般采用第3種方法。它是PC系統在不大增加成本的前提下,使性能提升的一個非常有效的技術。
本文簡介了Cache的概念、原理、結構設計以及在PC及CPU中的實現。
Cache的工作原理
Cache的工作原理是基于程序訪問的局部性。
對大量典型程序運行情況的分析結果表明,在一個較短的時間間隔內,由程序產生的地址往往集中在存儲器邏輯地址空間的很小范圍內。指令地址的分布本來就是連續的,再加上循環程序段和子程序段要重復執行多次。因此,對這些地址的訪問就自然地具有時間上集中分布的傾向。數據分布的這種集中傾向不如指令明顯,但對數組的存儲和訪問以及工作單元的選擇都可以使存儲器地址相對集中。這種對局部范圍的存儲器地址頻繁訪問,而對此范圍以外的地址則訪問甚少的現象,就稱為程序訪問的局部性。
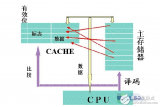
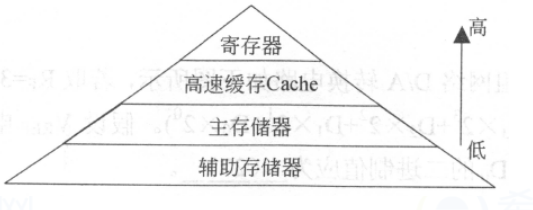
根據程序的局部性原理,可以在主存和CPU通用寄存器之間設置一個高速的容量相對較小的存儲器,把正在執行的指令地址附近的一部分指令或數據從主存調入這個存儲器,供CPU在一段時間內使用。這對提高程序的運行速度有很大的作用。這個介于主存和CPU之間的高速小容量存儲器稱作高速緩沖存儲器(Cache)。
系統正是依據此原理,不斷地將與當前指令集相關聯的一個不太大的后繼指令集從內存讀到Cache,然后再與CPU高速傳送,從而達到速度匹配。CPU對存儲器進行數據請求時,通常先訪問Cache。由于局部性原理不能保證所請求的數據百分之百地在Cache中,這里便存在一個命中率。即CPU在任一時刻從Cache中可靠獲取數據的幾率。命中率越高,正確獲取數據的可靠性就越大。一般來說,Cache的存儲容量比主存的容量小得多,但不能太小,太小會使命中率太低;也沒有必要過大,過大不僅會增加成本,而且當容量超過一定值后,命中率隨容量的增加將不會有明顯地增長。只要Cache的空間與主存空間在一定范圍內保持適當比例的映射關系,Cache的命中率還是相當高的。一般規定Cache與內存的空間比為4:1000,即128kB Cache可映射32MB內存;256kB Cache可映射64MB內存。在這種情況下,命中率都在90%以上。至于沒有命中的數據,CPU只好直接從內存獲取。獲取的同時,也把它拷進Cache,以備下次訪問。
Cache的基本結構
Cache通常由相聯存儲器實現。相聯存儲器的每一個存儲塊都具有額外的存儲信息,稱為標簽(Tag)。當訪問相聯存儲器時,將地址和每一個標簽同時進行比較,從而對標簽相同的存儲塊進行訪問。
Cache的3種基本結構如下:
全相聯Cache
在全相聯Cache中,存儲的塊與塊之間,以及存儲順序或保存的存儲器地址之間沒有直接的關系。程序可以訪問很多的子程序、堆棧和段,而它們是位于主存儲器的不同部位上。因此,Cache保存著很多互不相關的數據塊,Cache必須對每個塊和塊自身的地址加以存儲。當請求數據時,Cache控制器要把請求地址同所有地址加以比較,進行確認。這種Cache結構的主要優點是,它能夠在給定的時間內去存儲主存器中的不同的塊,命中率高;缺點是每一次請求數據同Cache中的地址進行比較需要相當的時間,速度較慢。
?
系統
l0
l1cache
l2cache
l3cache
cache
主存儲器
8088
無
無
無
無
dram
80286
無
無
無
無
無
dram
80386dx
無
外部sram
無
無
sram
dram
80486dx
無
內部8kb
外部sram
無
sram
dram
pentium
無
內部8kb+8kb
外部sram
無
sram
dram
ppro
無
內部8kb+8kb
內部封裝256kb或512kb
無
sram
dram
mmx
無
內部16kb+16kb
外部sram
無
sram
dram
pⅡ/pⅢ
無
內部16kb+16kb
卡上封裝512kb~1mb
無
sram
dram
k6-Ⅲ
?內部32kb+32kb
芯片背上封裝256kb
外部1mb
sram
dram
?
直接映像Cache
直接映像Cache不同于全相聯Cache,地址僅需比較一次。在直接映像Cache中,由于每個主存儲器的塊在Cache中僅存在一個位置,因而把地址的比較次數減少為一次。其做法是,為Cache中的每個塊位置分配一個索引字段,用Tag字段區分存放在Cache位置上的不同的塊。單路直接映像把主存儲器分成若干頁,主存儲器的每一頁與Cache存儲器的大小相同,匹配的主存儲器的偏移量可以直接映像為Cache偏移量。Cache的Tag存儲器(偏移量)保存著主存儲器的頁地址(頁號)。以上可以看出,直接映像Cache優于全相聯Cache,能進行快速查找,其缺點是當主存儲器的組之間做頻繁調用時,Cache控制器必須做多次轉換。
組相聯Cache
組相聯Cache是介于全相聯Cache和直接映像Cache之間的一種結構。這種類型的Cache使用了幾組直接映像的塊,對于某一個給定的索引號,可以允許有幾個塊位置,因而可以增加命中率和系統效率。
Cache與DRAM存取的一致性
在CPU與主存之間增加了Cache之后,便存在數據在CPU和Cache及主存之間如何存取的問題。讀寫各有2種方式。
貫穿讀出式(Look Through)
該方式將Cache隔在CPU與主存之間,CPU對主存的所有數據請求都首先送到Cache,由Cache自行在自身查找。如果命中,則切斷CPU對主存的請求,并將數據送出;不命中,則將數據請求傳給主存。該方法的優點是降低了CPU對主存的請求次數,缺點是延遲了CPU對主存的訪問時間。
旁路讀出式(Look Aside)
在這種方式中,CPU發出數據請求時,并不是單通道地穿過Cache,而是向Cache和主存同時發出請求。由于Cache速度更快,如果命中,則Cache在將數據回送給CPU的同時,還來得及中斷CPU對主存的請求;不命中,則Cache不做任何動作,由CPU直接訪問主存。它的優點是沒有時間延遲,缺點是每次CPU對主存的訪問都存在,這樣,就占用了一部分總線時間。
寫穿式(Write Through)
任一從CPU發出的寫信號送到Cache的同時,也寫入主存,以保證主存的數據能同步地更新。它的優點是操作簡單,但由于主存的慢速,降低了系統的寫速度并占用了總線的時間。
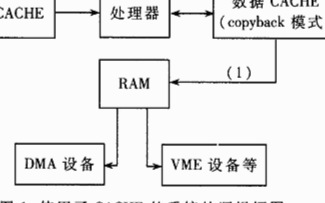
回寫式(Copy Back)
為了克服貫穿式中每次數據寫入時都要訪問主存,從而導致系統寫速度降低并占用總線時間的弊病,盡量減少對主存的訪問次數,又有了回寫式。它是這樣工作的:數據一般只寫到Cache,這樣有可能出現Cache中的數據得到更新而主存中的數據不變(數據陳舊)的情況。但此時可在Cache 中設一標志地址及數據陳舊的信息,只有當Cache中的數據被再次更改時,才將原更新的數據寫入主存相應的單元中,然后再接受再次更新的數據。這樣保證了Cache和主存中的數據不致產生沖突。
Cache的分級體系設計
微處理器性能由如下幾種因素估算:性能=k(fⅹ1/CPI-(1-H)ⅹN) 式中:k為比例常數,f為工作頻率,CPI為執行每條指令需要的周期數,H為Cache的命中率,N為存儲周期數。
雖然,為了提高處理器的性能,應提高工作頻率,減少執行每條指令需要的周期數,提高Cache的命中率。同時分發多條指令和采用亂序控制,可以減少CPI值;采用轉移預測和增加Cache容量,可以提高H值。為了減少存儲周期數N,可采用高速的總線接口和不分塊的Cache方案。以前提高處理器的性能,主要靠提高工作頻率和提高指令級的并行度,今后則主要靠提高Cache的命中率。設計出無阻塞Cache分級結構。
Cache分級結構的主要優勢在于,對于一個典型的一級緩存系統的80%的內存申請都發生在CPU內部,只有20%的內存申請是與外部內存打交道。而這20%的外部內存申請中的80%又與二級緩存打交道。因此,只有4%的內存申請定向到DRAM中。
Cache分級結構的不足在于高速緩存組數目受限,需要占用線路板空間和一些支持邏輯電路,會使成本增加。綜合比較結果還是采用分級Cache。
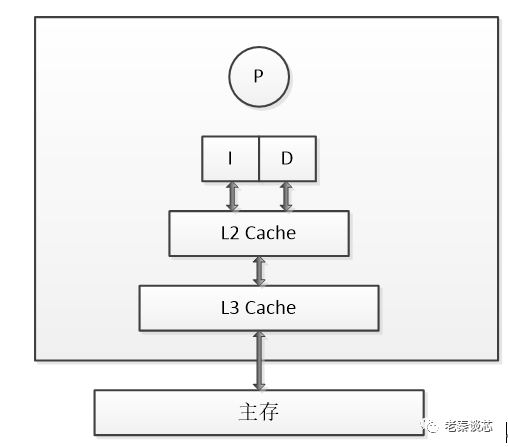
L1 Cache的設計有在片一級分離和統一設計兩種方案。
Intel、AMD、原DEC等公司將L1 Cache設計成指令Cache與數據Cache分離型。因為這種雙路高速緩存結構減少了爭用高速緩存所造成的沖突,改進了處理器效能,以便數據訪問和指令調用在同一時鐘周期內進行。
但是,僅依靠增加在片一級Cache的容量,并不能使微處理器性能隨之成正比例地提高,還需設置二級Cache。
在L1 Cache結構方面,一般采用回寫式靜態隨機存儲器(SRAM)。目前,L1 Cache容量有加大的趨勢。
L2 Cache的設計分芯片內置和外置兩種設計。
如AMD K6-3內置的256kB L2 Cache與CPU同步工作。外置L2 Cache,一般都要使二級Cache與CPU實現緊密耦合,并且與在片一級Cache形成無阻塞階層結構。同時還要采用分離的前臺總線(外部I/O總線)和后臺總線(二級Cache總線)模式。顯然,將來隨著半導體集成工藝的提高,如果CPU與二級Cache集成在單芯片上,則CPU與二級Cache的耦合效果可能更佳。
由于L2 Cache內置,因此,還可以在原主板上再外置大容量緩存1MB~2MB,它被稱為L3 Cache。
PC中的Cache技術的實現
PC中Cache的發展是以80386為界的。主要內容請參見“跟著CPU的腳步”一文。
目前,PC中部分已實現的Cache技術如表1所示。
結 語
目前,PC系統的發展趨勢之一是CPU主頻越做越高,系統架構越做越先進,而主存DRAM的結構和存取時間改進較慢。因此,Cache技術愈顯重要,在PC系統中Cache越做越大。廣大用戶已把Cache做為評價和選購PC系統的一個重要指標。本文小結了Cache的源脈。希望可以給廣大用戶一個較系統的參考。



















 工商網監
工商網監
評論