 電子發(fā)燒友App
電子發(fā)燒友App


?
在這一期中,我們延續(xù)上一期 ?Bert 中文短句相似度計算 Docker CPU鏡像,繼續(xù)使用 huggingface transformer 和 sentence-transformer 類庫,并將英語句子生成 bert embedding,然后引入 faiss 類庫來建立索引,最后查詢最接近的句子。
?
Docker 鏡像獲取方式
本期 docker 鏡像獲取方式為,關(guān)注 MyEncyclopedia 公眾號后回復(fù) docker-faiss-transformer 即可獲取如下完整命令。
docker?run?-p?8888:8888?myencyclopedia/faiss-demo?bash?-c?'jupyter?notebook?--allow-root?--port?8888?--NotebookApp.token=?--ip?0.0.0.0'
然后打開瀏覽器,輸入 http://localhost:8888/notebooks/faiss_demo.ipynb
faiss 簡介
Faiss 的全稱是Facebook AI Similarity Search,是由 Facebook 開發(fā)的適用于稠密向量匹配的開源庫,作為向量化檢索開山鼻祖,F(xiàn)aiss 提供了一套查詢海量高維數(shù)據(jù)集的解決方案,它從兩個方面改善了暴力搜索算法存在的問題:降低空間占用和加快檢索速度。此外,F(xiàn)aiss 提供了若干種方法實(shí)現(xiàn)數(shù)據(jù)壓縮,包括 PCA、Product-Quantization等。
Faiss 主要特性:
Faiss 使用流程
使用 faiss 分成兩部,第一步需要對原始向量建立索引文件,第二步再對索引文件進(jìn)行向量 search 操作。
在第一次建立索引文件的時候,需要經(jīng)過 train 和 add 兩個過程;后續(xù)如果有新的向量需要被添加到索引文件,只需要一個 add 操作來實(shí)現(xiàn)增量索引更新,但是如果增量的量級與原始索引差不多的話,整個向量空間就可能發(fā)生了一些變化,這個時候就需要重新建立整個索引文件,也就是再用全部的向量來走一遍 train 和 add,至于具體是如何 train 和 add的,就和特定的索引類型有關(guān)了。
1. IndexFlatL2 indexFlatIP
對于精確搜索,例如歐式距離 faiss.indexFlatL2 或 內(nèi)積距離 faiss.indexFlatIP,沒有 train 過程,add 完直接可以 search。
import?faiss?
#?建立索引,?定義為dimension?d?=?128
index?=?faiss.IndexFlatL2(d)
?#?add?vectors,?xb?為?(100000,128)大小的numpy
index.add(xb)?????????????????
print(index.ntotal)?
#?索引中向量的數(shù)量,?輸出100000
#?求4-近鄰
k?=?4
#?xq為query?embedding,?大小為(10000,128)
D,?I?=?index.search(xq,?k)?????
##?D?shape?(10000,4),表示每個返回點(diǎn)的embedding?與?query?embedding的距離,
##?I?shape?(10000,4),表示和query?embedding最接近的k個物品id,
print(I[:5])
2. IndexIVFFlat
IndexFlatL2 的結(jié)果雖然精確,但當(dāng)數(shù)據(jù)集比較大的時候,暴力搜索的時間復(fù)雜度很高,因此我們一般會使用其他方式的索引來加速。比如 IndexIVFFlat,將數(shù)據(jù)集在 train 階段分割為幾部分,技術(shù)術(shù)語為 Voronoi Cells,每個數(shù)據(jù)向量只能落在一個cell中。Search 時只需要查詢query向量落在cell中的數(shù)據(jù)了,降低了距離計算次數(shù)。這個過程本質(zhì)就是高維 KNN 聚類算法。search 階段使用倒排索引來。
IndexIVFFlat 需要一個訓(xùn)練的階段,其與另外一個索引 quantizer 有關(guān),通過 quantizer 來判斷屬于哪個cell。IndexIVFFlat 在搜索階段,引入了nlist(cell的數(shù)量)與nprob(執(zhí)行搜索的cell數(shù))參數(shù)。增大nprobe可以得到與brute-force更為接近的結(jié)果,nprobe就是速度與精度的調(diào)節(jié)器。
import?faiss
nlist?=?100
k?=?4
#?建立索引,?定義為dimension?d?=?128
quantizer?=?faiss.IndexFlatL2(d)
#?使用歐式距離 L2 建立索引。
index?=?faiss.IndexIVFFlat(quantizer,?d,?nlist,?faiss.METRIC_L2)
##?xb:?(100000,128)
index.train(xb)?
index.add(xb)????????????????
index.nprobe?=?10??#?默認(rèn)?nprobe?是?1?,可以設(shè)置的大一些試試
D,?I?=?index.search(xq,?k)
print(I[-5:])???#?最后五次查詢的結(jié)果
3. IndexIVFPQ
IndexFlatL2 和 IndexIVFFlat都要存儲所有的向量數(shù)據(jù)。對于超大規(guī)模數(shù)據(jù)集來說,可能會不大現(xiàn)實(shí)。因此IndexIVFPQ 索引可以用來壓縮向量,具體的壓縮算法就是 Product-Quantization,注意,由于高維向量被壓縮,因此 search 時候返回也是近似的結(jié)果。
import?faiss
nlist?=?100
#?每個向量分8段
m?=?8?
#?求4-近鄰
k?=?4?
quantizer?=?faiss.IndexFlatL2(d)????#?內(nèi)部的索引方式依然不變
index?=?faiss.IndexIVFPQ(quantizer,?d,?nlist,?m,?8)?#?每個向量都被編碼為8個字節(jié)大小
index.train(xb)
index.add(xb)
index.nprobe?=?10????????????????
D,?I?=?index.search(xq,?k)??#?檢索
print(I[-5:])
在本期中,我們僅使用基本的 IndexIVFFlat 和 IndexFlatIP 完成 bert embedding 的索引和搜索,后續(xù)會有篇幅來解讀 Product-Quantization 的論文原理和代碼實(shí)踐。
ag_news 新聞數(shù)據(jù)集
ag_news 新聞數(shù)據(jù)集 3.0 包含了英語新聞標(biāo)題,training 部分包含 120000條數(shù)據(jù), test 部分包含 7600條數(shù)據(jù)。
ag_news 可以通過 huggingface datasets API 自動下載
def?load_dataset(part='test')?->?List[str]:
????ds?=?datasets.load_dataset("ag_news")
????list_str?=?[r['text']?for?r?in?ds[part]]
????return?list_str
????
list_str?=?load_dataset(part='train')
print(f'{len(list_str)}')
for?s?in?list_str[:3]:
????print(s)
????print('
')
顯示前三條新聞標(biāo)題為
120000
Wall St. Bears Claw Back Into the Black (Reuters) Reuters - Short-sellers, Wall Street's dwindlingand of ultra-cynics, are seeing green again.
Carlyle Looks Toward Commercial Aerospace (Reuters) Reuters - Private investment firm Carlyle Group,which has a reputation for making well-timed and occasionallycontroversial plays in the defense industry, has quietly placedits bets on another part of the market.
Oil and Economy Cloud Stocks' Outlook (Reuters) Reuters - Soaring crude prices plus worriesabout the economy and the outlook for earnings are expected tohang over the stock market next week during the depth of thesummer doldrums.
sentence-transformer
和上一期一樣,我們利用sentence-transformer 生成句子級別的embedding。其原理基于 Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks (https://arxiv.org/abs/1908.10084)這篇論文。基本思想很直接,將句子中的每個詞的 bert embedding ,輸進(jìn)入一個池化層(pooling),例如選擇最簡單的平均池化層,將所有token embedding 的均值作為輸出,便得到跟輸入句子長度無關(guān)的一個定長的 sentence embedding。
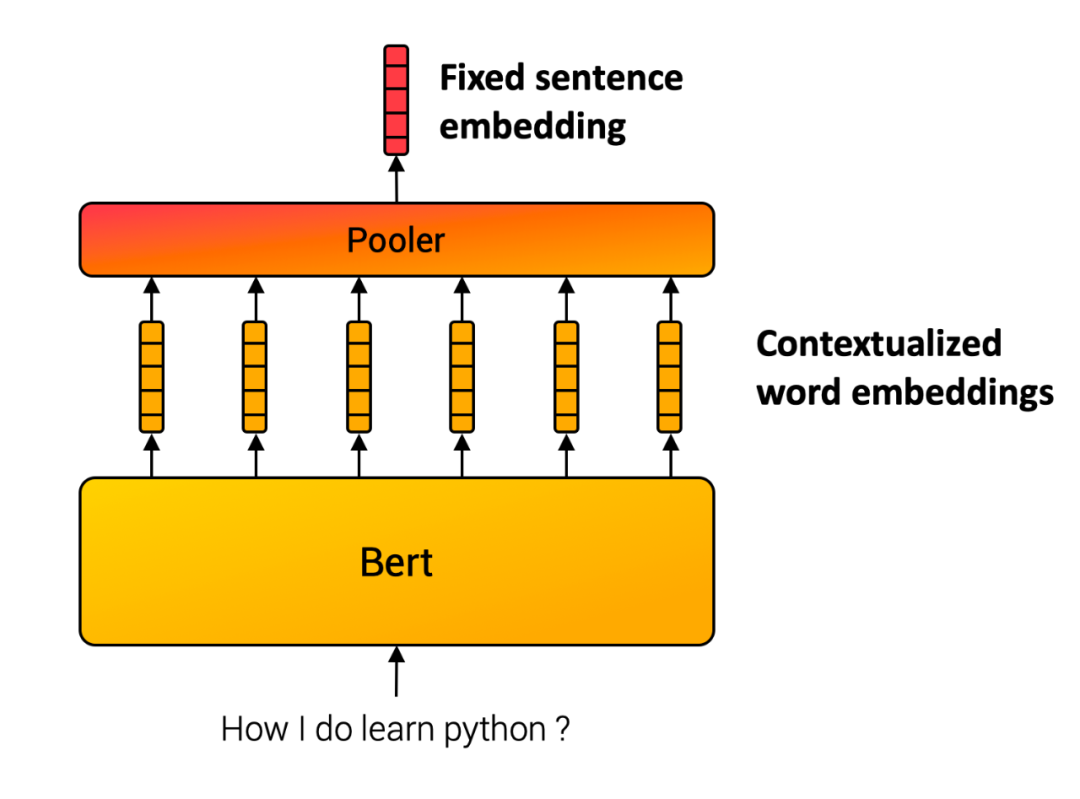
結(jié)果展示
數(shù)據(jù)集 train 部分由于包含的樣本比較多,需要一段時間生成 bert embedding,大家可以使用 load_dataset(part='test') 來快速體驗(yàn)。下面我們演示一個查詢 how to make money 的最接近結(jié)果。
index?=?load_index('news_train.index')
list_id?=?query(model,?index,?'how?to?make?money')
for?id?in?list_id:
????print(list_str[id])
Profit From That Traffic Ticket Got a traffic ticket? Can't beat 'em? Join 'em by investing in the company that processes those tickets.
Answers in the Margins By just looking at operating margins, investors can find profitable industry leaders.
Types of Investors: Which Are You? Learn a little about yourself, and it may improve your performance.
Target Can Aim High Target can maintain its discount image while offering pricier services and merchandise.
Finance moves Ford into the black US carmaker Ford Motor returns to profit, as the money it makes from lending to customers outweighs losses from selling vehicles.
核心代碼
所有可運(yùn)行代碼和數(shù)據(jù)都已經(jīng)包含在 docker 鏡像中了,下面列出核心代碼
建立索引
def?train_flat(index_name,?id_list,?embedding_list,?num_clusters):
????import?numpy?as?np
????import?faiss
????dim?=?768
????m?=?16
????
????embeddings?=?np.asarray(embedding_list)
????
????quantiser?=?faiss.IndexFlatIP(dim)
????index?=?faiss.IndexIVFFlat(quantiser,?dim,?num_clusters,?faiss.METRIC_INNER_PRODUCT)
????index.train(embeddings)??##?clustering
????
????ids?=?np.arange(0,?len(id_list))
????ids?=?np.asarray(ids.astype('int64'))
????
????index.add_with_ids(embeddings,?ids)
????print(index.is_trained)?
????print("Total?Number?of?Embeddings?in?the?index",?index.ntotal)
????faiss.write_index(index,?index_name)
查詢結(jié)果
def?query(model,?index,?query_str:?str)?->?List[int]:
????topk?=?5
????q_embed?=?model.encode([query_str])
????D,?I?=?index.search(q_embed,?topk)
????print(D)
????print(I)
????return?I[0].tolist()
?
?
審核編輯 :李倩
?



















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論