 電子發燒友App
電子發燒友App


?
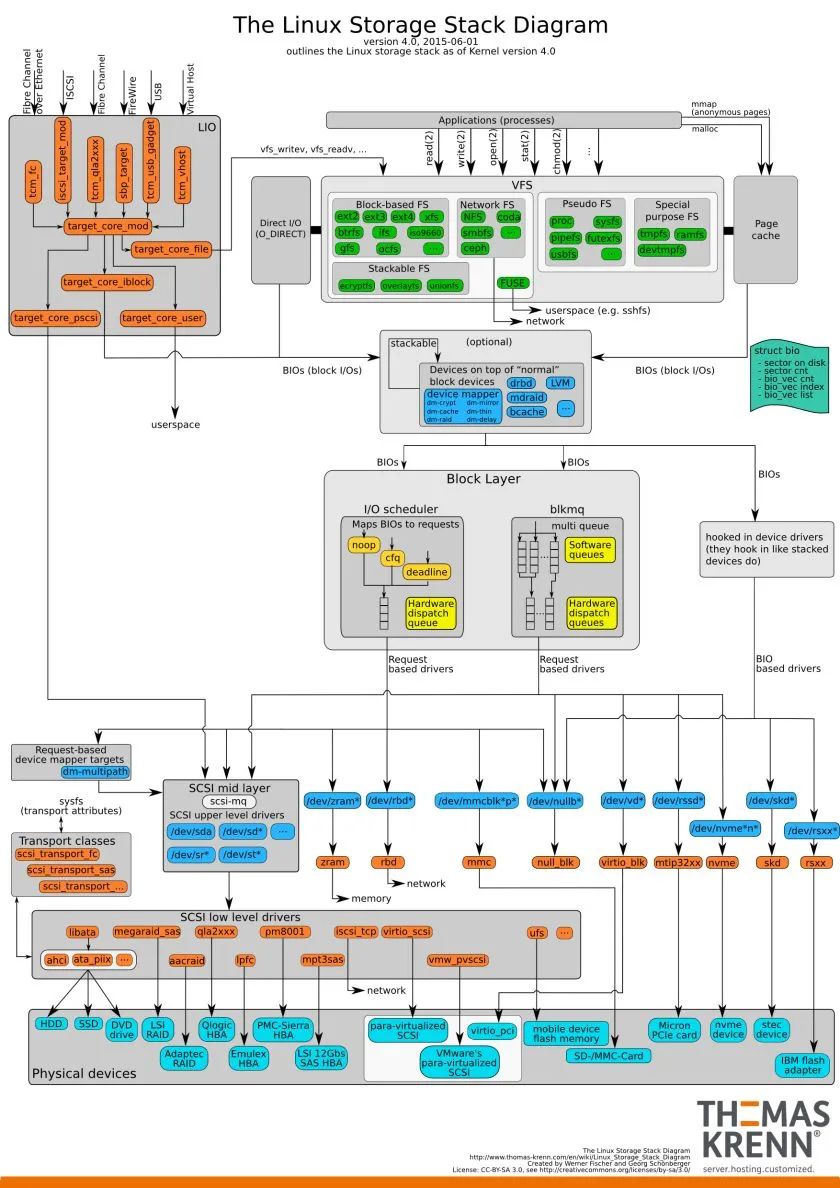
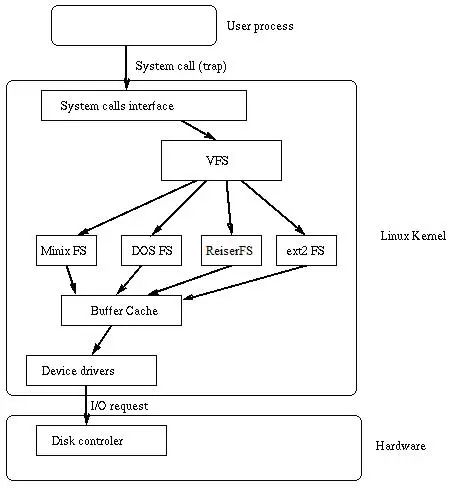
一、IO 系統的分層
?
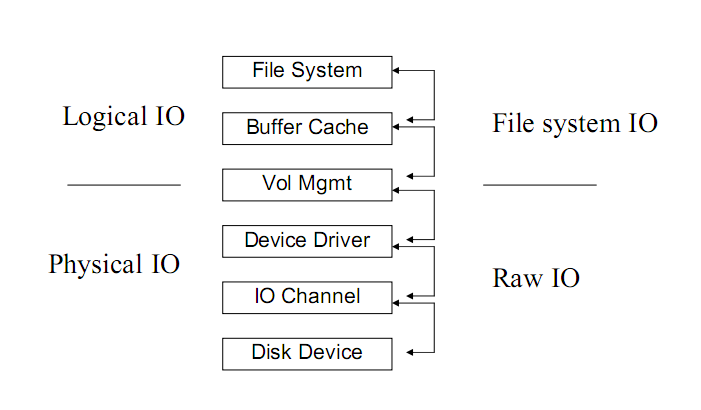
二、IO 模型
這部分的東西在網絡編程經常能看到,不過在所有IO處理中都是類似的。2.1 IO請求的兩個階段等待資源階段:IO請求一般需要請求特殊的資源(如磁盤、RAM、文件),當資源被上一個使用者使用沒有被釋放時,IO請求就會被阻塞,直到能夠使用這個資源。使用資源階段:真正進行數據接收和發生。2.2 在等待數據階段,IO分為阻塞IO和非阻塞IO。
阻塞IO:資源不可用時,IO請求一直阻塞,直到反饋結果(有數據或超時)。非阻塞IO:資源不可用時,IO請求離開返回,返回數據標識資源不可用2.3 在使用資源階段,IO分為同步IO和異步IO。
同步IO:應用阻塞在發送或接收數據的狀態,直到數據成功傳輸或返回失敗。異步IO:應用發送或接收數據后立刻返回,數據寫入OS緩存,由OS完成數據發送或接收,并返回成功或失敗的信息給應用。 2.4 按照Unix的5個IO模型劃分
2.4 按照Unix的5個IO模型劃分-
阻塞IO
-
非阻塞IO
-
IO復用
-
信號驅動的IO
-
異步IO
三、最重要的三個指標
?3.1 IOPSIOPS,即每秒鐘處理的IO請求數量。IOPS是隨機訪問類型業務(OLTP類)很重要的一個參考指標。3.12 一塊物理硬盤能提供多少IOPS?從磁盤上進行數據讀取時,比較重要的幾個時間是:尋址時間(找到數據塊的起始位置),旋轉時間(等待磁盤旋轉到數據塊的起始位置),傳輸時間(讀取數據的時間和返回的時間)。其中尋址時間是固定的(磁頭定位到數據的存儲的扇區即可),旋轉時間受磁盤轉速的影響,傳輸時間受數據量大小的影響和接口類型的影響(不同的硬盤接口速度不同),但是在隨機訪問類業務中,他的時間也很少。因此,在硬盤接口相同的情況下,IOPS主要受限于尋址時間和傳輸時間。以一個15K的硬盤為例,尋址時間固定為4ms,旋轉時間為60s/15000*1/2(最多轉半圈)=2ms,一般計算IOPS都忽略傳輸時間。1000ms/6ms=167個IOPS。3.13 OS的一次IO請求對應物理硬盤一個IO嗎?在沒有文件系統、沒有VM(卷管理)、沒有RAID、沒有存儲設備的情況下,這個答案還是成立的。但是當這么多中間層加進去以后,這個答案就不是這樣了。物理硬盤提供的IO是有限的,也是整個IO系統存在瓶頸的最大根源。所以,如果一塊硬盤不能提供,那么多塊在一起并行處理,這不就行了嗎?確實是這樣的。可以看到,越是高端的存儲設備的cache越大,硬盤越多,一方面通過cache異步處理IO,另一方面通過盤數增加,盡可能把一個OS的IO分布到不同硬盤上,從而提高性能。文件系統則是在cache上會影響,而VM則可能是一個IO分布到多個不同設備上(Striping)。所以,一個OS的IO在經過多個中間層以后,發生在物理磁盤上的IO是不確定的。可能是一對一個,也可能一個對應多個。3.14 IOPS能算出來嗎?對單塊磁盤的IOPS的計算沒有沒問題,但是當系統后面接的是一個存儲系統時、考慮不同讀寫比例,IOPS則很難計算,而需要根據實際情況進行測試。主要的因素有:存儲系統本身有自己的緩存。緩存大小直接影響IOPS,理論上說,緩存越大能cache的東西越多,在cache命中率保持的情況下,IOPS會越高。RAID級別。不同的RAID級別影響了物理IO的效率。讀寫混合比例。對讀操作,一般只要cache能足夠大,可以大大減少物理IO,而都在cache中進行;對寫操作,不論cache有多大,最終的寫還是會落到磁盤上。因此,100%寫的IOPS要越獄小于100%的讀的IOPS。同時,100%寫的IOPS大致等同于存儲設備能提供的物理的IOPS。一次IO請求數據量的多少。一次讀寫1KB和一次讀寫1MB,顯而易見,結果是完全不同的。當時上面N多因素混合在一起以后,IOPS的值就變得撲朔迷離了。所以,一般需要通過實際應用的測試才能獲得。3.2 IO Response Time即IO的響應時間。IO響應時間是從操作系統內核發出一個IO請求到接收到IO響應的時間。因此,IO Response time除了包括磁盤獲取數據的時間,還包括了操作系統以及在存儲系統內部IO等待的時間。一般看,隨IOPS增加,因為IO出現等待,IO響應時間也會隨之增加。對一個OLTP系統,10ms以內的響應時間,是比較合理的。下面是一些IO性能示例:一個8K的IO會比一個64K的IO速度快,因為數據讀取的少些。一個64K的IO會比8個8K的IO速度快,因為前者只請求了一個IO而后者是8個IO。串行IO會比隨機IO快,因為串行IO相對隨機IO說,即便沒有Cache,串行IO在磁盤處理上也會少些操作。需要注意,IOPS與IO Response Time有著密切的聯系。一般情況下,IOPS增加,說明IO請求多了,IO Response Time會相應增加。但是會出現IOPS一直增加,但是IO Response Time變得非常慢,超過20ms甚至幾十ms,這時候的IOPS雖然還在提高,但是意義已經不大,因為整個IO系統的服務時間已經不可取。3.3 Throughput為吞吐量。這個指標衡量標識了最大的數據傳輸量。如上說明,這個值在順序訪問或者大數據量訪問的情況下會比較重要。尤其在大數據量寫的時候。吞吐量不像IOPS影響因素很多,吞吐量一般受限于一些比較固定的因素,如:網絡帶寬、IO傳輸接口的帶寬、硬盤接口帶寬等。一般他的值就等于上面幾個地方中某一個的瓶頸。3.4 一些概念3.41 IO Chunk Size即單個IO操作請求數據的大小。一次IO操作是指從發出IO請求到返回數據的過程。IO Chunk Size與應用或業務邏輯有著很密切的關系。比如像Oracle一類數據庫,由于其block size一般為8K,讀取、寫入時都此為單位,因此,8K為這個系統主要的IO Chunk Size。IO Chunk Size小,考驗的是IO系統的IOPS能力;IO Chunk Size大,考驗的時候IO系統的IO吞吐量。3.42 Queue Deep熟悉數據庫的人都知道,SQL是可以批量提交的,這樣可以大大提高操作效率。IO請求也是一樣,IO請求可以積累一定數據,然后一次提交到存儲系統,這樣一些相鄰的數據塊操作可以進行合并,減少物理IO數。而且Queue Deep如其名,就是設置一起提交的IO請求數量的。一般Queue Deep在IO驅動層面上進行配置。Queue Deep與IOPS有著密切關系。Queue Deep主要考慮批量提交IO請求,自然只有IOPS是瓶頸的時候才會有意義,如果IO都是大IO,磁盤已經成瓶頸,Queue Deep意義也就不大了。一般來說,IOPS的峰值會隨著Queue Deep的增加而增加(不會非常顯著),Queue Deep一般小于256。3,43 隨機訪問(隨機IO)、順序訪問(順序IO)隨機訪問的特點是每次IO請求的數據在磁盤上的位置跨度很大(如:分布在不同的扇區),因此N個非常小的IO請求(如:1K),必須以N次IO請求才能獲取到相應的數據。順序訪問的特點跟隨機訪問相反,它請求的數據在磁盤的位置是連續的。當系統發起N個非常小的IO請求(如:1K)時,因為一次IO是有代價的,系統會取完整的一塊數據(如4K、8K),所以當第一次IO完成時,后續IO請求的數據可能已經有了。這樣可以減少IO請求的次數。這也就是所謂的預取。隨機訪問和順序訪問同樣是有應用決定的。如數據庫、小文件的存儲的業務,大多是隨機IO。而視頻類業務、大文件存取,則大多為順序IO。3.44 選取合理的觀察指標:以上各指標中,不用的應用場景需要觀察不同的指標,因為應用場景不同,有些指標甚至是沒有意義的。隨機訪問和IOPS:?在隨機訪問場景下,IOPS往往會到達瓶頸,而這個時候去觀察Throughput,則往往遠低于理論值。順序訪問和Throughput:在順序訪問的場景下,Throughput往往會達到瓶頸(磁盤限制或者帶寬),而這時候去觀察IOPS,往往很小。
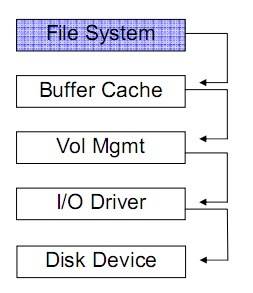
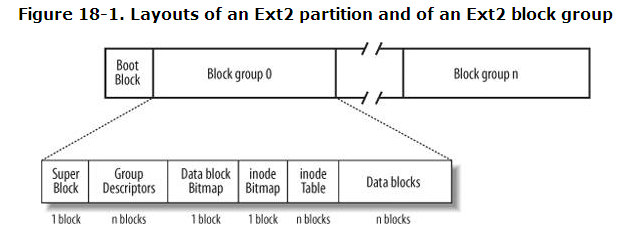
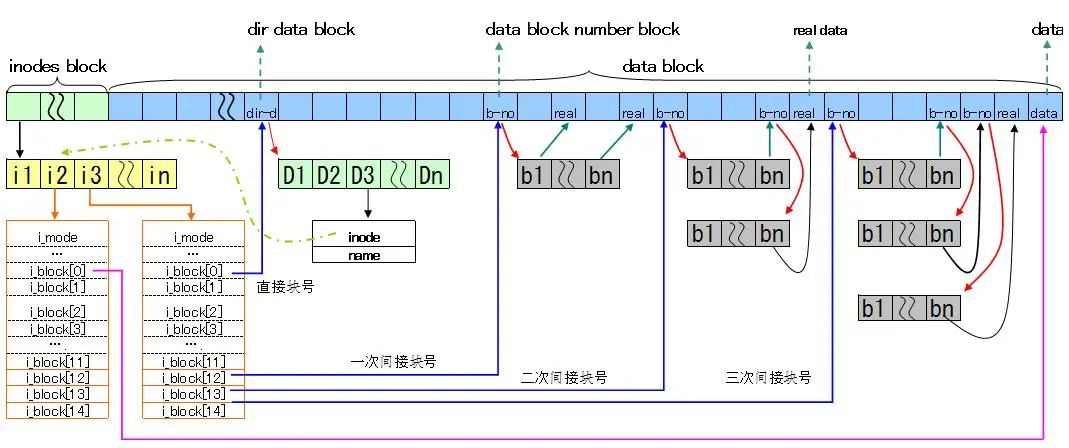
四、文件系統的結構
各種文件系統實現方式不同,因此性能、管理性、可靠性等也有所不同。下面為Linux Ext2(Ext3)的一個大致文件系統的結構。
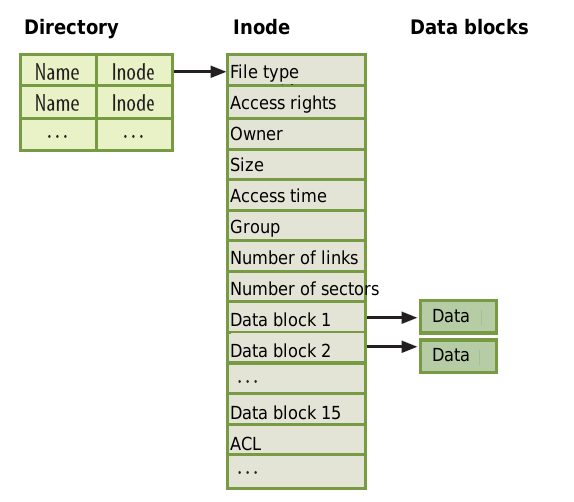
- 直接索引:直接指向實際內容信息,公有12個。因此如果,一個文件系統block size為1k,那么直接索引到的內容最大為12k
- 間接索引
- 兩級間接索引
- 三級間接索引
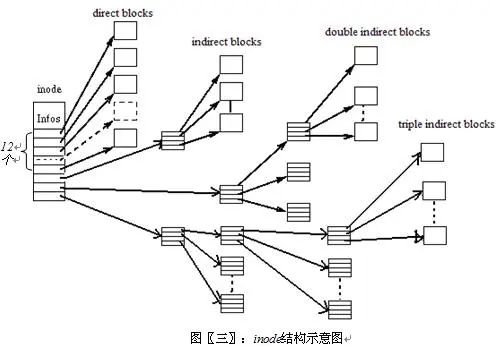
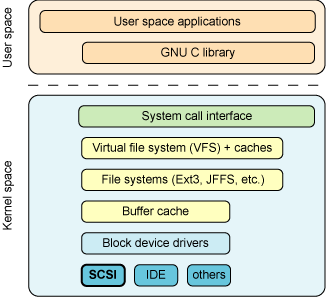
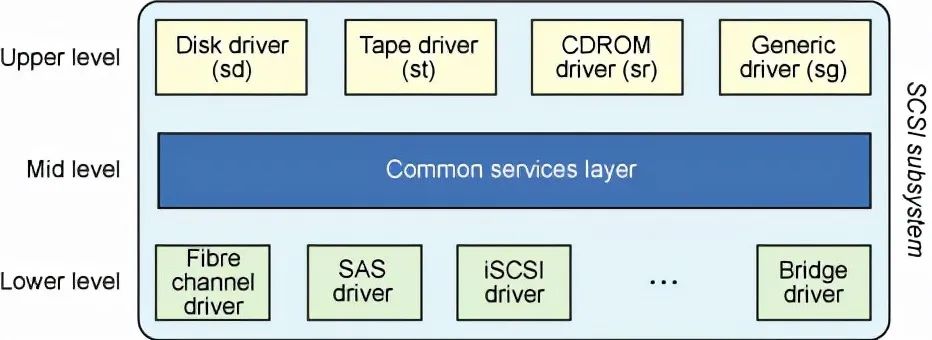
- 塊設備就是以塊(比如磁盤扇區)為單位收發數據的設備,它們支持緩沖和隨機訪問(不必順序讀取塊,而是可以在任何時候訪問任何塊)等特性。塊設備包括硬盤、CD-ROM 和 RAM 盤。
- 字符設備則沒有可以進行物理尋址的媒體。字符設備包括串行端口和磁帶設備,只能逐字符地讀取這些設備中的數據。
- ?
- ?
- ?
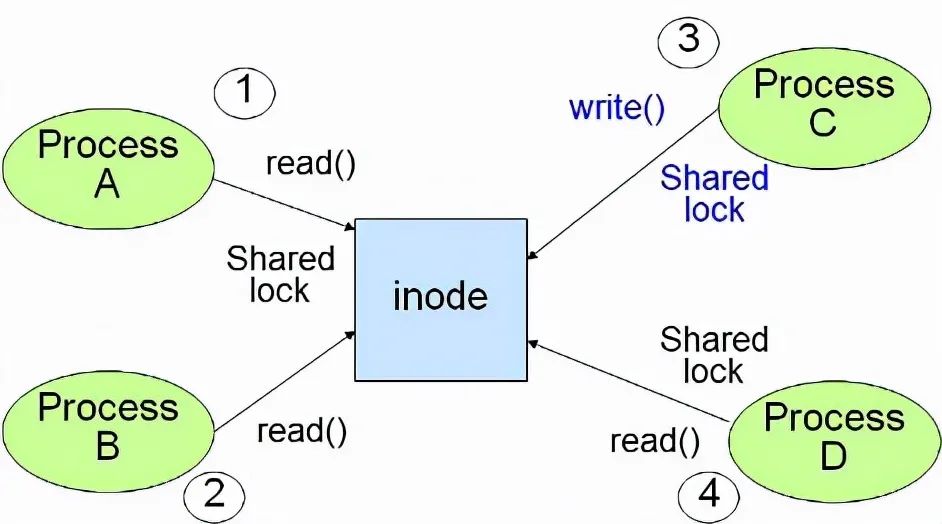
# ls -l /dev/*lvbrw------- 1 root system 22, 2 May 15 2007 lvcrw------- 2 root system 22, 2 May 15 2007 rlv-
塊設備能支持緩沖和隨機讀寫。即讀取和寫入時,可以是任意長度的數據。最小為1byte。對塊設備,你可以成功執行下列命令:dd if=/dev/zero of=/dev/vg01/lv bs=1 count=1。即:在設備中寫入一個字節。硬件設備是不支持這樣的操作的(最小是512),這個時候,操作系統首先完成一個讀取(如1K,操作系統最小的讀寫單位,為硬件設備支持的數據塊的整數倍),再更改這1k上的數據,然后寫入設備。
-
字符設備只能支持固定長度數據的讀取和寫入,這里的長度就是操作系統能支持的最小讀寫單位,如1K,所以塊設備的緩沖功能,這里就沒有了,需要使用者自己來完成。由于讀寫時不經過任何緩沖區,此時執行dd if=/dev/zero of=/dev/vg01/lv bs=1 count=1,這個命令將會出錯,因為這里的bs(block size)太小,系統無法支持。如果執行dd if=/dev/zero of=/dev/vg01/lv bs=1024 count=1,則可以成功。這里的block size有OS內核參數決定。
- 統一進行磁盤管理。按需分配空間,提供動態擴展。
- 條帶化(Striped)
- 鏡像(mirrored)
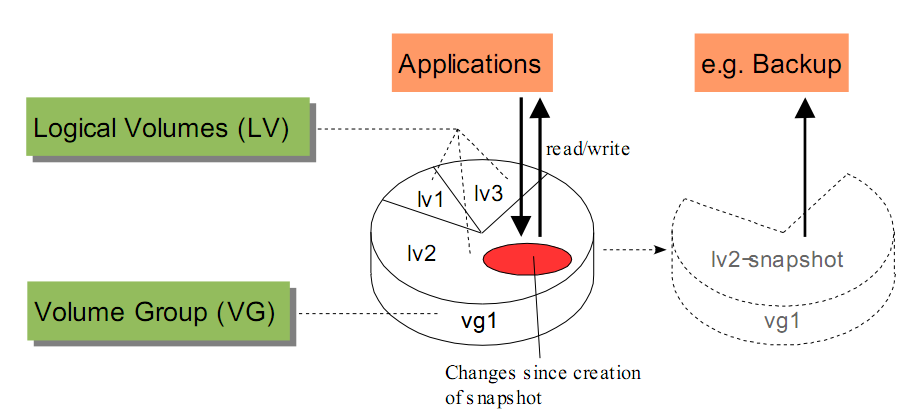
- 快照(snapshot)
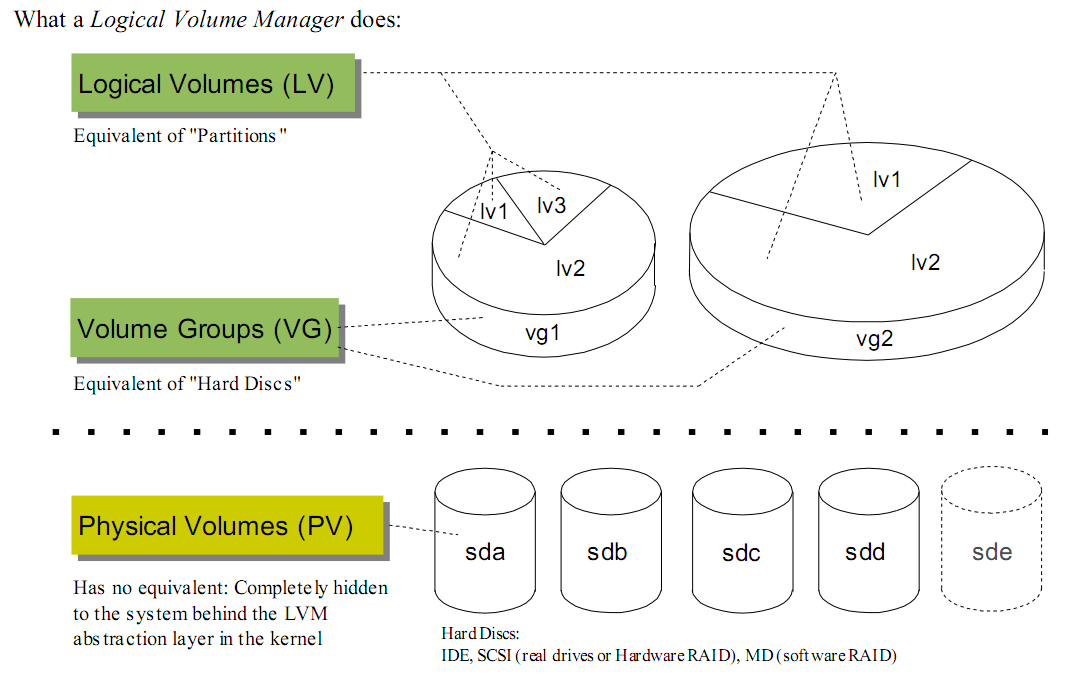
- PV(physical volume):物理卷。在LVM中,一個PV對應就是操作系統能看見的一塊物理磁盤,或者由存儲設備分配操作系統的lun。一塊磁盤唯一對應一個PV,PV創建以后,說明這塊空間可以納入到LVM的管理。創建PV時,可以指定PV大小,即可以把整個磁盤的部分納入PV,而不是全部磁盤。這點在表面上看沒有什么意義,但是如果主機后面接的是存儲設備的話就很有意義了,因為存儲設備分配的lun是可以動態擴展的,只有當PV可以動態擴展,這種擴展性才能向上延伸。
- VG(volume group):卷組。一個VG是多個PV的集合,簡單說就是一個VG就是一個磁盤資源池。VG對上屏蔽了多個物理磁盤,上層是使用時只需考慮空間大小的問題,而VG解決的空間的如何在多個PV上連續的問題。
- LV(logical volume):邏輯卷。LV是最終可供使用卷,LV在VG中創建,有了VG,LV創建是只需考慮空間大小等問題,對LV而言,他看到的是一直聯系的地址空間,不用考慮多塊硬盤的問題。
- PE(physical extend): 物理擴展塊。LVM在創建PV,不會按字節方式去進行空間管理。而是按PE為單位。PE為空間管理的最小單位。即:如果一個1024M的物理盤,LVM的PE為4M,那么LVM管理空間時,會按照256個PE去管理。分配時,也是按照分配了多少PE、剩余多少PE考慮。
- LE(logical extend):邏輯擴展塊。類似PV,LE是創建LV考慮,當LV需要動態擴展時,每次最小的擴展單位。
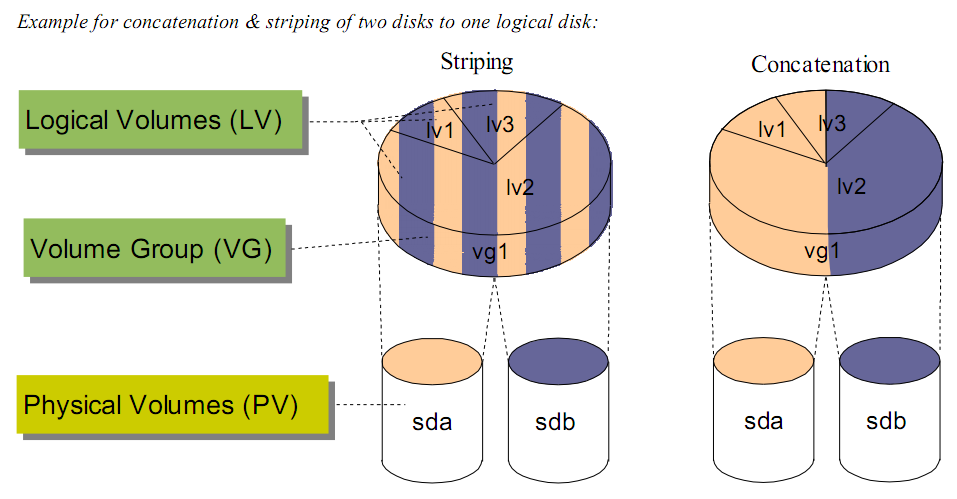
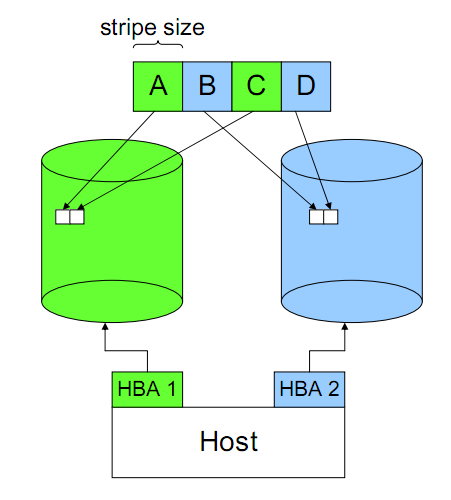
- 數據完整性的風險。Striping導致一份完整的數據被分布到多個磁盤上,任何一個磁盤上的數據都是不完整,也無法進行還原。一個條帶的損壞會導致所有數據的失效。因此這個問題只能通過存儲設備來彌補。
- 條帶大小的設定很大程度決定了Striping帶來的好處。如果條帶設置過大,一個IO操作最終還是發生在一個磁盤上,無法帶來并行的好處;當條帶設置國小,本來一次并行IO可以完成的事情會最終導致了多次并行IO。
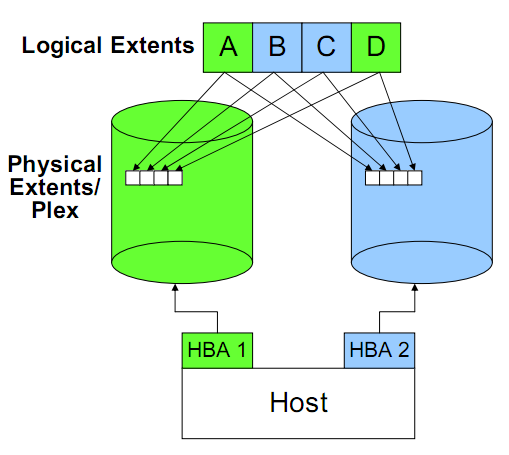
- 讀取操作可以從兩個磁盤上獲取,因此讀效率會更好些。
- 數據完整復雜了一份,安全性更高。
- 所有的寫操作都會同時發送在兩個磁盤上,因此實際發送的IO是請求IO的2倍
- 由于寫操作在兩個磁盤上發生,因此一些完整的寫操作需要兩邊都完成了才算完成,帶來了額外負擔。
- 在處理串行IO時,有些IO走一個磁盤,另外一些IO走另外的磁盤,一個完整的IO請求會被打亂,LVM需要進行IO數據的合并,才能提供給上層。像一些如預讀的功能,由于有了多個數據獲取同道,也會存在額外的負擔。
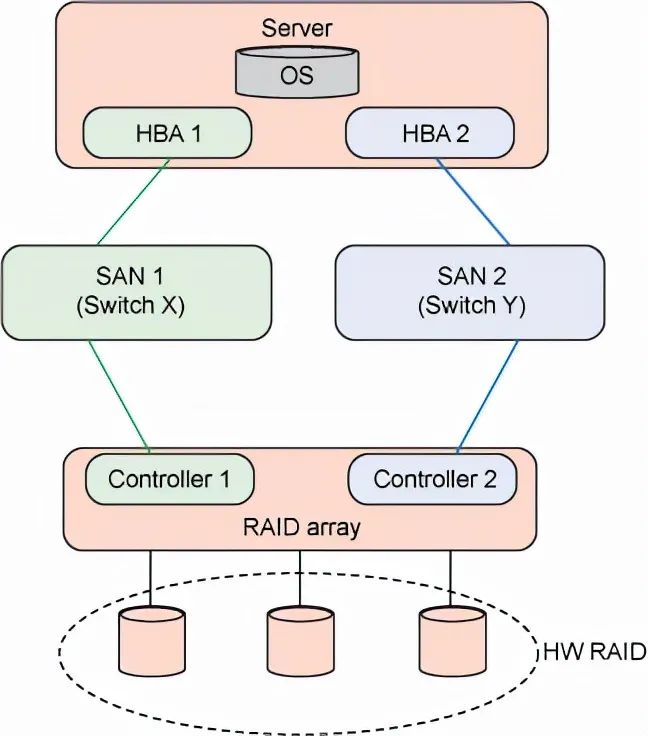
- 把多個映射到同一塊空間的路徑合并為一個提供給主機
- 提供fail over的支持。當一條通路出現問題時,及時切換到其他通路
- 提供load balance的支持。即同時使用多條路徑進行數據傳送,發揮多路徑的資源優勢,提高系統整體帶寬。
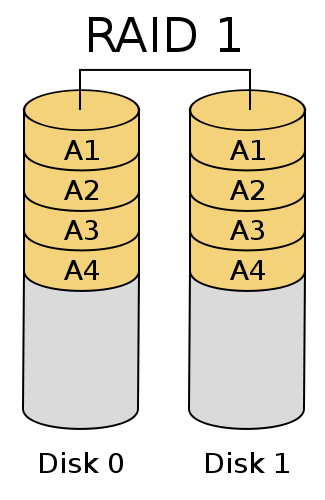
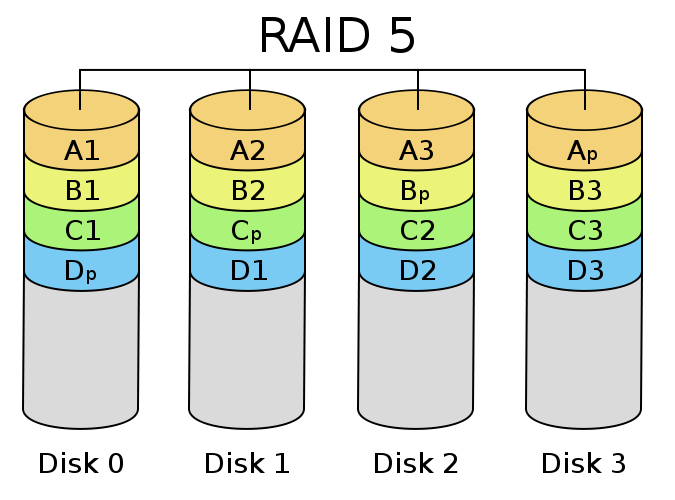
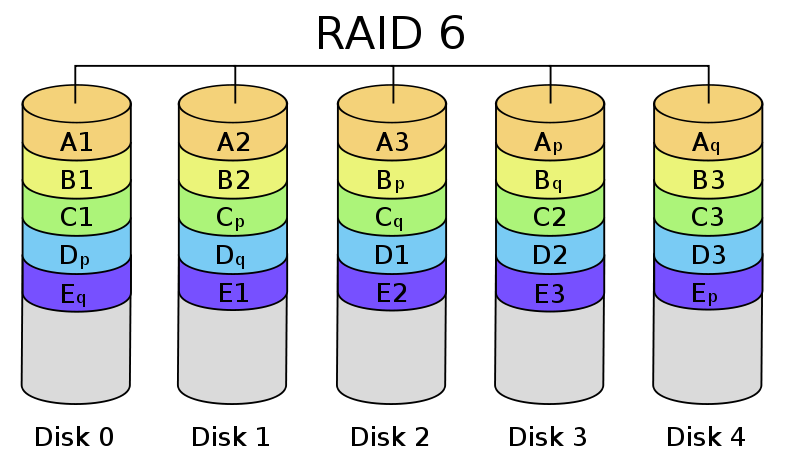
?
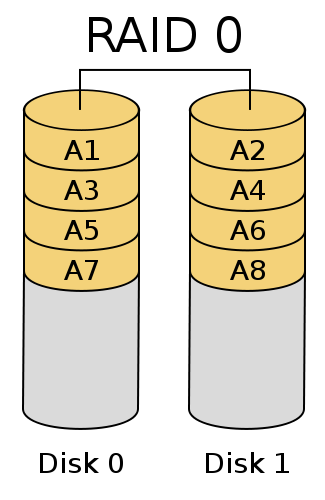
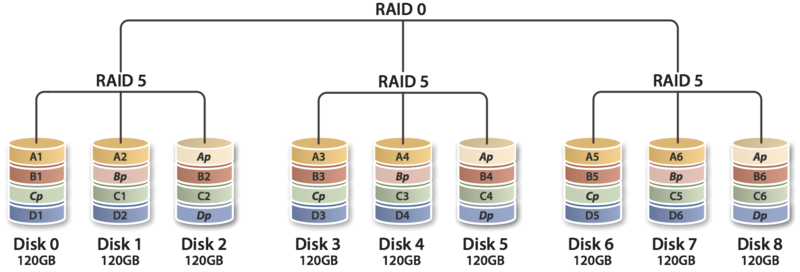
RAID 6與RAID 5類似。但是提供了兩塊校驗盤(下圖右下角為p和q的)。安全性更高,寫性能更差了。RAID 0最少需要4塊盤。
RAID 10(Striped mirror)RAID 10是RAID 0 和RAID 1的結合,同時兼顧了二者的特點,提供了高性能,但是同時空間使用也是最大。RAID 10最少需要4塊盤。需要注意,使用RAID 10來稱呼其實很容易產生混淆,因為RAID 0+1和RAID 10基本上只是兩個數字交換了一下位置,但是對RAID來說就是兩個不同的組成。因此,更容易理解的方式是“Striped mirrors”,即:條帶化后的鏡像——RAID 10;或者“mirrored stripes”,即:鏡像后的條帶化。比較RAID 10和RAID 0+1,雖然最終都是用到了4塊盤,但是在數據組織上有所不同,從而帶來問題。RAID 10在可用性上是要高于RAID 0+1的:- RAID 0+1 任何一塊盤損壞,將失去冗余。如圖4塊盤中,右側一組損壞一塊盤,左側一組損壞一塊盤,整個盤陣將無法使用。而RAID 10左右各損壞一塊盤,盤陣仍然可以工作。
- RAID 0+1 損壞后的恢復過程會更慢。因為先經過的mirror,所以左右兩組中保存的都是完整的數據,數據恢復時,需要完整恢復所以數據。而RAID 10因為先條帶化,因此損壞數據以后,恢復的只是本條帶的數據。如圖4塊盤,數據少了一半。
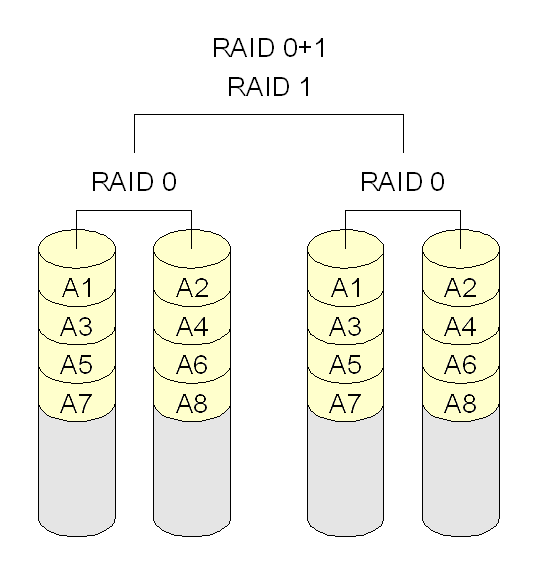
-
RAID與LVM中的條帶化原理上類似,只是實現層面不同。在存儲上實現的RAID一般有專門的芯片來完成,因此速度上遠比LVM塊。也稱硬RAID。
-
如上介紹,RAID的使用是有風險的,如RAID 0,一塊盤損壞會導致所有數據丟失。因此,在實際使用中,高性能環境會使用RAID 10,兼顧性能和安全;一般情況下使用RAID 5(RAID 50),兼顧空間利用率和性能;
-
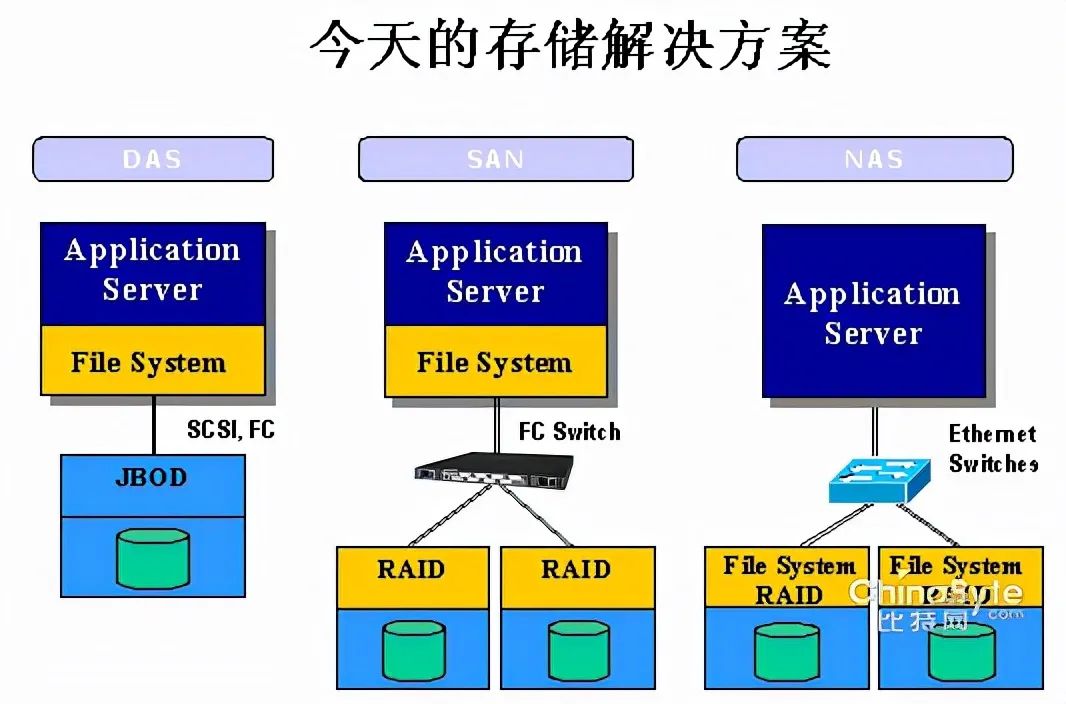
單臺主機。在這種情況下,存儲作為主機的一個或多個磁盤存在,這樣局限性也是很明顯的。由于受限于主機空間,一個主機只能裝一塊到幾塊硬盤,而硬盤空間時受限的,當磁盤滿了以后,你不得不為主機更換更大空間的硬盤。
-
獨立存儲空間。為了解決空間的問題,于是考慮把磁盤獨立出來,于是有了DAS(Direct Attached Storage),即:直連存儲。DAS就是一組磁盤的集合體,數據讀取和寫入等也都是由主機來控制。但是,隨之而來,DAS又面臨了一個他無法解決的問題——存儲空間的共享。接某個主機的JBOD(Just a Bunch Of Disks,磁盤組),只能這個主機使用,其他主機無法用。因此,如果DAS解決空間了,那么他無法解決的就是如果讓空間能夠在多個機器共享。因為DAS可以理解為與磁盤交互,DAS處理問題的層面相對更低。使用協議都是跟磁盤交互的協議
-
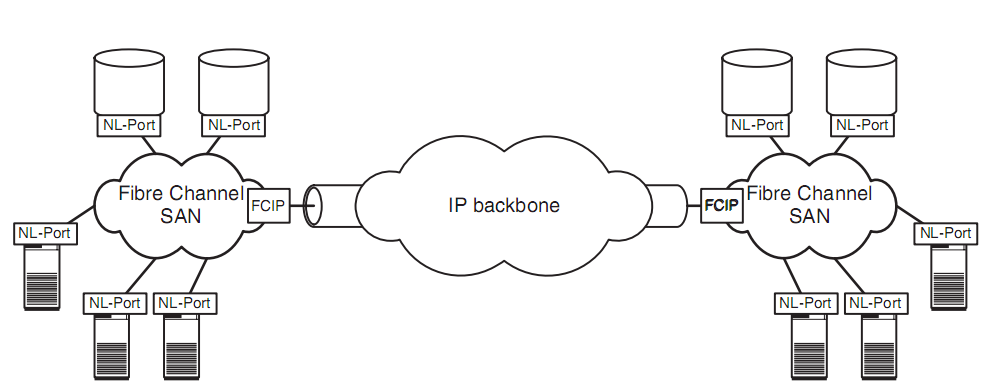
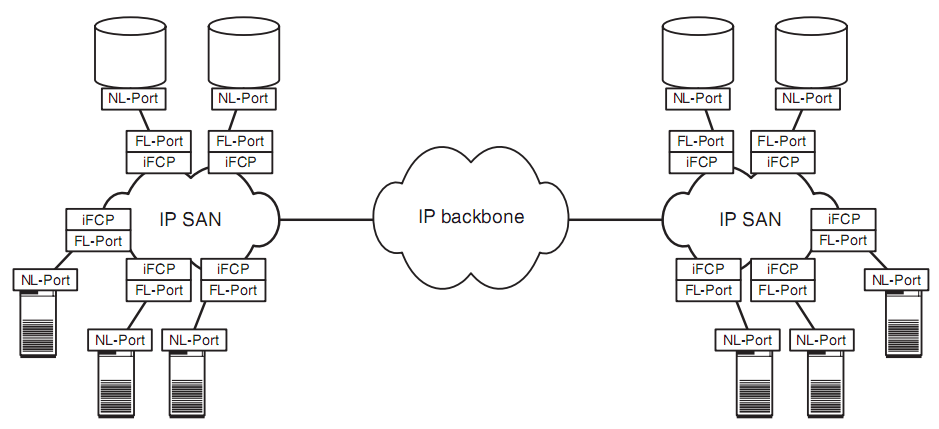
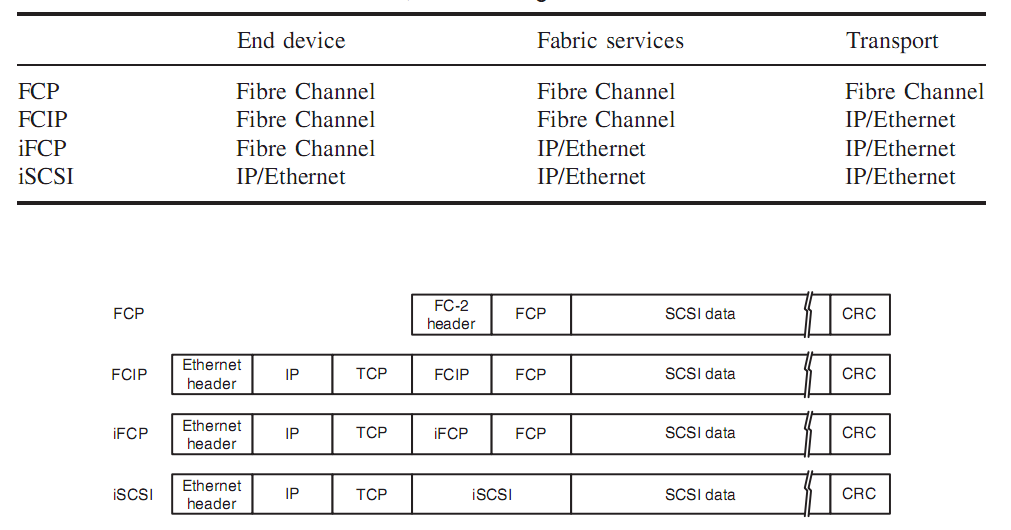
獨立的存儲網絡。為了解決共享的問題,借鑒以太網的思想,于是有了SAN(Storage Area Network),即:存儲網絡。對于SAN網絡,你能看到兩個非常特點,一個就是光纖網絡,另一個是光纖交換機。SAN網絡由于不會之間跟磁盤交互,他考慮的更多是數據存取的問題,因此使用的協議相對DAS層面更高一些。光纖網絡:對于存儲來說,與以太網很大的一個不同就是他對帶寬的要求非常高,因此SAN網絡下,光纖成為了其連接的基礎。而其上的光纖協議相比以太網協議而言,也被設計的更為簡潔,性能也更高。光纖交換機:這個類似以太網,如果想要做到真正的“網絡”,交換機是基礎。
-
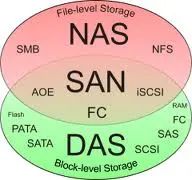
網絡文件系統。存儲空間可以共享,那文件也是可以共享的。NAS(Network attached storage)相對上面兩個,看待問題的層面更高,NAS是在文件系統級別看待問題。因此他面的不再是存儲空間,而是單個的文件。因此,當NAS和SAN、DAS放在一起時,很容易引起混淆。NAS從文件的層面考慮共享,因此NAS相關協議都是文件控制協議。NAS解決的是文件共享的問題;SAN(DAS)解決的是存儲空間的問題。NAS要處理的對象是文件;SAN(DAS)要處理的是磁盤。為NAS服務的主機必須是一個完整的主機(有OS、有文件系統,而存儲則不一定有,因為可以他后面又接了一個SAN網絡),他考慮的是如何在各個主機直接高效的共享文件;為SAN提供服務的是存儲設備(可以是個完整的主機,也可以是部分),它考慮的是數據怎么分布到不同磁盤。NAS使用的協議是控制文件的(即:對文件的讀寫等);SAN使用的協議是控制存儲空間的(即:把多長的一串二進制寫到某個地址)
?
審核編輯:湯梓紅











 工商網監
工商網監
評論