對于嵌入式系統,最終代碼的體積和效率取決于由編譯器生成的可執行代碼,而非開發人員編寫的源代碼;但是源代碼的優化,可以幫助編譯器生成更加優質的可執行代碼。
2021-11-09 10:31:50 1265
1265 
編譯器工具鏈將 LLVM 升級到 7 . 0 ,這將啟用新功能并有助于改進 NVIDIA GPU 的編譯器代碼生成。
2022-04-06 10:13:143385 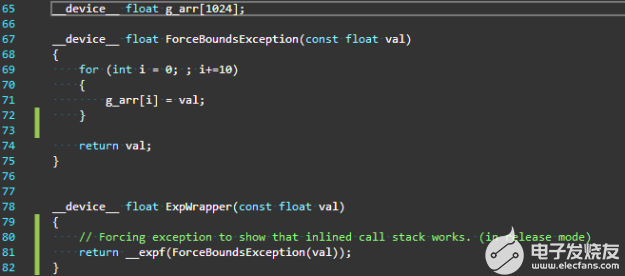
首先說一下什么是交叉編譯:我們在 ubuntu 中寫了一個程序,比如 main.c,然后使用 ubuntu 的編譯器進行編譯,生成的可執行文件自然可以在 ubuntu 中運行。但是生成的可執行
2023-07-15 16:06:371381 
Triton是一種用于編寫高效自定義深度學習原語的語言和編譯器。Triton的目的是提供一個開源環境,以比CUDA更高的生產力編寫快速代碼,但也比其他現有DSL具有更大的靈活性。Triton已被采用
2023-12-16 11:22:07791 
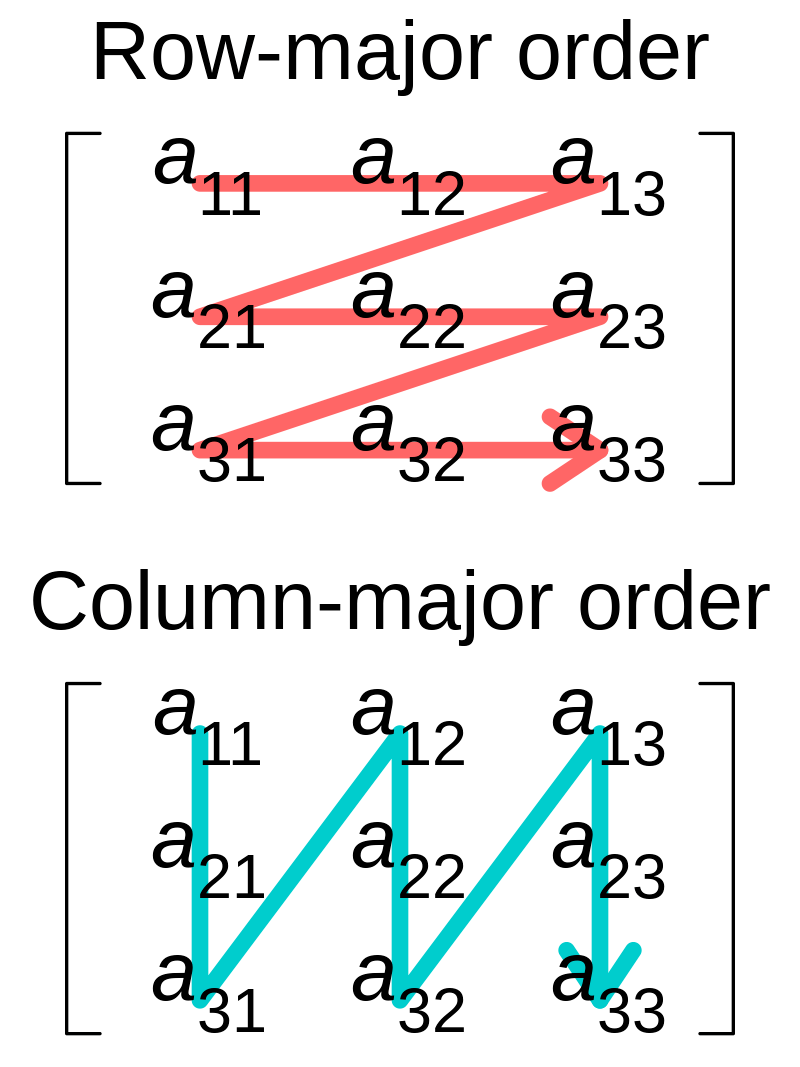
程度下被編譯器優化。即使對源代碼做微小改動也可能會對編譯器生成的代碼運行效率產生重大影響。因此,源代碼的優化可以在一定程度上幫助編譯器生成更高效的可執行代碼。本文將以Loop Interchange
2022-08-03 14:08:24
當將char變量與常數比較時,編譯器不會生成帶有IF-()語句的代碼。XC16I會把這個分類成嚴重的編譯器錯誤!沒有警告,結果代碼在輸出(程序內存)中丟失。也就是說,if語句和括號之間的整個代碼都不
2019-02-27 12:26:55
ARM編譯器armcc可以優化您的代碼以實現小代碼和高性能。
本教程介紹了編譯器執行的主要優化技術,并解釋了如何控制編譯器優化。
本教程假定您已經安裝并許可了ARM DS-5 Development Studio。
有關詳細信息,請參閱ARM DS-5 Development Studio快速入門。
2023-08-28 07:11:23
: 只能編譯 arm匯編代碼?armlink: 鏈接器,用來將目標代碼,鏈接成可執行程序?armar: 打包,將目標代碼打包成一個庫?fromelf: 將可執行程序,轉換為其他的鏡像文件。以下是編譯流程
2022-08-04 14:36:55
目標代碼文件、可執行文件和庫 C編程的基本策略是使用程序將源代碼文件轉換為可執行文件,此文件包含可以運行的機器語言代碼。C分兩步完成這一工作:編譯和鏈接。編譯器將源代碼轉換為中間代碼,鏈接器將此
2015-01-22 16:10:08
,ArkCompiler有能力提供具有高效執行性能且具有跨語言優勢的多語言運行時,也可以在小設備上提供高效輕量的單一語言運行時。組件可配置:ArkCompiler具有豐富的編譯器運行時組件系統。通過定制化配置
2021-11-22 17:04:47
編譯器,對生成的C代碼結合GNU帶有的底層驅動庫,進行編譯,產生可直接寫入到目標板子的.elf文件 整個過程不需要手動添加代碼,只需要matlab建立模型。GNU+matlab2.pdf (1.29 MB )
2018-12-14 10:40:44
模塊,但不具備編譯可執行文件等高級功能。professional development system(PDS)才是最完整的版本,不僅有各種模塊可供調用,還有源代碼版本控制,編譯可執行程序等高級功能
2019-05-30 07:40:07
MPLAB C18編譯器是適用于PIC18 PICmicro單片機的獨立而優化的ANSI C編譯器。僅在ANSI標準X3.159-1989與高效的PICmicro單片機支持有沖突的情況下,此編譯器
2011-03-09 15:23:10
是:Minimalist GNU on Windows 。它實際上是將經典的開源 C語言 編譯器 GCC 移植到了 Windows 平臺下,并且包含了 Win32API ,因此可以將源代碼編譯為可在 Windows
2020-04-15 14:47:45
你好,我想問一下你的經歷。我有這個代碼:編譯器如何編譯它是有趣的。同一類型有兩個變量TASK1和TASK2。當我將&ela1Tasks[0]分配給task1時,編譯器生成代碼:當我將&
2020-05-05 07:13:29
調用編譯器的 make 功能,把的源文件以及 Main 文件,以及各種庫源文件都編譯,然后鏈接,變成目標可執行文件。左邊是實際上需要使用的 make 文件,后綴名.mk。它描寫了如何將源文件編譯生成
2022-05-31 11:19:02
針對lsl,已經根據自己的需求定義完成了,其中一個需求是將text段的程序copy到ram中,根據生成的map文件看,也已經實現了該功能,但是我想請問一下,編譯器是如何調用lsl生成map的,具體執行是通過什么方式執行的?或者顯示的代碼能不能讓我看到這個過程?
2020-03-07 20:17:17
編譯:在會話級別中打開JIT編譯: 這是手動打開 JIT 編譯: 還可以通過將操作指定在特定的 XLA 設備(XLA_CPU 或 XLA_GPU)上,通過 XLA 來運行計算: AoT編譯:獨立使用 tfcompile 將 TensorFlow 圖轉換為不同設備(手機)的可執行代碼。
2020-07-28 14:31:51
的輸出信息,或者對最后生成的二進制文件進行控制,以便通過加入不同數量和種類的調試代碼來為今后的調試做好準備。與其他常用的編譯器一樣,gcc 也提供了靈活而強大的代碼優化功能,利用它可以生成執行效率更高
2018-07-03 09:51:12
的輸出信息,或者對最后生成的二進制文件進行控制,以便通過加入不同數量和種類的調試代碼來為今后的調試做好準備。與其他常用的編譯器一樣,gcc 也提供了靈活而強大的代碼優化功能,利用它可以生成執行效率更高
2018-07-09 07:49:03
可執行程序(他們會引用那個靜態鏈接庫)。由于無論是arm平臺,還是pc平臺,用的編譯器都是一致的,應該可以排除編譯器的問題吧? 1:當是用交叉編譯器編譯的,為的是能夠在arm平臺下運行。但在這一步出現
2019-08-23 12:56:50
程序做了錯誤提示功能,但是生成可執行文件后,不提示錯誤呢
2012-05-09 18:22:41
壇子里有沒有哪位大神知道關于labview生成的可執行程序的反編譯問題,如何反編譯exe的應用程序?
2013-07-17 14:19:04
,當然我沒有!我也相信使用的語言是PICBASIC。那么,關于我應該從哪里開始的指針呢?我已經下載了MPLAB IDV8。我可以使用其他編譯器來編譯代碼嗎?如何查看我的代碼,運行它?我確實有MPLAB ICD 3,所以一旦我獲得代碼運行并理解它的運行,應該會有幫助。謝謝。
2019-08-19 11:46:07
嗨, 當我使用帶有stm8編譯器的Ride 7時,我將僅在匯編中執行以下代碼選項字節。它的工作。 但是當我嘗試使用帶有stm8 cosmic編譯器的stvd時,以下代碼無效。如何為stm8
2019-02-13 16:01:26
windows 下 NucleiStdio編譯不成功,不能生成可執行文件(.elf, .verilog等)具體見下圖所示:
2023-08-12 06:25:27
以生成關于鏈接文件的調試和引用信息、生成靜態調用圖并列出堆棧的使用情況、控制輸出映像中符號表的內容、顯示輸出中代碼和數據的大小。鏈接器針對下一次文件編譯提供反饋信息,提示編譯器有關未使用函數的情況。可以
2021-08-21 10:11:40
= var_value3 funcmainvim filename.c=> srcgcc 編譯器filename.c => a.out一個源文件生成二進制可執行文件經過四步:1 預處理處于偽代碼和特殊字符宏命令條件編譯頭文件gcc -E filename.c -o
2021-10-27 07:04:40
我是用Qt交叉編譯生成的一個可執行文件,移植到開發板執行,點擊open camera,就報如下問題
2021-12-30 07:48:37
1.為什么要有交叉編譯器?\qquad一般電腦是X86架構,而單片機一般不是,比如單片機是ARM架構,那么gcc編譯生成的程序只能在X86的架構上運行,而不能在ARM架構上運行,所以需要交叉編譯器
2022-01-25 06:36:23
界面(UI)動態調整過濾器的系數。內容介紹生成代碼和構建可執行文件運行示例介紹multibandParametricEQ允許級聯中最多十個均衡器頻段。在此示例中,您將創建一個具有三個波段的均衡器。三個雙
2018-07-28 13:37:52
基本概念一、交叉編譯器:是什么?在一個平臺上生成僅可在另個平臺上運行的可執行代碼→區別于本地編譯為什么?(嵌入式硬件受限于成本)運行速度:目標平臺的嵌入式硬件通常被設計為低成本和低功耗,沒有太高
2021-12-15 08:38:52
) → 預處理器 (preprocessor) → 編譯器 (compiler) → 目標代碼 (object code) → 鏈接器 (Linker) → 可執行程序 (executables) 。一
2016-12-16 09:47:47
) → 預處理器 (preprocessor) → 編譯器 (compiler) → 目標代碼 (object code) → 鏈接器 (Linker) → 可執行程序 (executables) 。一
2016-12-21 16:57:13
什么是交叉編譯交叉編譯是在一個平臺上生成另一個平臺上的可執行代碼(例如我們在windows上用keil編譯代碼生成hex文件,供51單片機使用,這個過程就是交叉編譯。這是一個行為。)。為什么要交叉
2022-01-13 06:04:21
一、什么是交叉編譯在一種計算機環境中運行的編譯程序,能編譯出在另外一種環境下運行的代碼,我們就稱這種編譯器支持交叉編譯。這個編譯過程就叫交叉編譯。簡單地說,就是在一個平臺上生成另一個平臺上的可執行
2019-09-23 15:43:15
1.從源代碼到CPU執行過程.c等高級語言經過編譯器編譯后轉換為.s匯編源代碼經過匯編器轉化為elf格式二進制可執行程序通過Objcopy工具轉化成Bin格式燒錄文件通過總線傳送到CPU中進行解碼在
2021-12-20 07:55:29
?汽車上使用的ECU中運行的程序,是軟件工程師基于C/C++語言編寫出來,然后通過編譯器編譯得到可執行文件,最后將可執行文件刷寫入ECU中實現的,今天我們介紹下編譯過程。通常我們使用GCC編譯器來
2021-12-21 06:42:28
生成了一個可執行文件,在打開.exe文件時,出現了如圖所示的錯誤,請問該怎么處理?
2018-01-29 16:19:47
寫好的LabView程序怎么生成可執行文件,客戶端只要安裝可執行文件就能操作運行了,
2014-12-17 10:51:04
編寫C或C++應用程序時,需要使用編譯器工具鏈將其編譯為機器代碼。然后,您可以在基于Arm的處理器上運行此編譯的可執行代碼,或者使用模型對其進行模擬。
裸機編譯編譯器工具鏈包括以下組件:
?將C
2023-08-02 17:28:39
可以使用 ARM/Keil 編譯器版本 6 編譯代碼)?我目前必須將 STM32CubeMX 為 MDK-ARM V5.27(或 V5)生成的代碼修改為:使用 MDK ARM 編譯器版本 6手動修改生成
2023-01-13 07:13:16
,最終代碼的體積和效率取決于由編譯器生成的可執行代碼,而非開發人員編寫的源代碼;但是源代碼的優化,可以幫助編譯器生成更加優質的可執行代碼。因此,開發人員不僅要從整體效率等因素上去構思源代碼體系,也要
2021-11-21 08:00:00
,最終代碼的體積和效率取決于由編譯器生成的可執行代碼,而非開發人員編寫的源代碼;但是源代碼的優化,可以幫助編譯器生成更加優質的可執行代碼。因此,開發人員不僅要從整體效率等因素上去構思源代碼體系,也要
2022-04-11 10:17:09
用官方SDK提供的交叉編譯器編譯生成的可執行程序helloworld2,D1燒寫的sipeed debian的固件。將其放在debian下執行,失敗通過ldd和file命令查看也沒有發現問題請問問題出在哪?
2021-12-28 06:35:18
。-c選項告訴GCC僅把源程序編譯為目標代碼而不做鏈接工作,所以采用該選項的編譯指令不會生成最終的可執行程序,而是生成一個與源程序文件名相同的以.o為后綴的目標文件。例如一個Test.c的源程序經過
2011-03-11 18:10:04
你好。我有一個基于PIC32的設備,它實現了USB閃存驅動器。我想在MPLAB X中編譯一個C程序,將可執行代碼復制到設備上,并告訴PIC32運行它。XC32工具鏈能夠生成這樣的二進制文件嗎?在其
2018-11-21 15:46:58
親愛的大家,有沒有辦法使用安裝在我筆記本電腦上的用于MPLAB的C8和C16編譯器來生成用于編譯和鏈接在Windows筆記本電腦上執行的二進制文件的通用C代碼,而不是為微芯片控制器生成二進制文件
2019-05-29 09:59:02
怎么不能生成可執行文件呢大家幫幫忙
2012-04-02 23:00:41
ARM編譯器符合ISO C、ISO C++、ELF、DWARF 2和DWARF 3標準。
每項標準的合規性級別為:
AR Armar生產和使用Unix風格的目標代碼檔案。
Armar可以列出和提取
2023-08-23 07:12:44
請問 matlab 生成 TMS C6747可執行的代碼具體步驟 是什么??具體應該怎么設置 real_time workshop??謝謝
2020-07-27 07:16:27
如何在KeilμVision5上執行ARM編譯器的代碼優化?
2020-12-11 07:40:56
gcc-buildroot-9.3.0-2020.03-x86_64_aarch64-rockchip-linux-gnu,我理解是交叉編譯器,應該在Ubuntu主機上使用,無法在開發板使用在開發板上直接編譯正常,但執行可執行文件過程中報錯:262, check error
2023-01-10 14:28:17
本章內容對應視頻講解鏈接(在線觀看): 我們寫了 linux 上第一個 c 程序 heollo world ,是使用 gcc 編譯器進行代碼的編譯,編譯得到的可執行文件只能在 X86 結構的 PC
2021-08-16 10:09:23
用MDK 生成bin 文件1用MDK 生成bin 文件Embest 徐良平在RV MDK 中,默認情況下生成*.hex 的可執行文件,但是當我們要生成*.bin 的可執行文件時怎么辦呢?答案是可以使用RVCT
2008-08-02 10:52:27 71
71 根據緩沖區溢出原理,提出一種基于可執行代碼的緩沖區溢出檢測模型,給出該模型的理論基礎,描述模型構建的過程,提出新的緩沖區引用實例的識別方法。該模型將可執行代碼
2009-04-20 09:26:1831 C-編譯器的設計文檔與源代碼:本壓縮包包含了C-編譯器的設計文檔與源代碼,供學習參考。 整體框架. 3 詞法分析. 3 Class CTokenizer 3 Cla
2010-02-09 11:13:5645 本內容介紹了Keil C編譯器編程規則和代碼優化,要實用好單片機就必須清楚它的內部結構組織結構,無論是在芯片的選擇還是代碼的編寫
2011-04-20 17:37:10315 CoSy是ACE公司開發的編譯器構造框架[1]。它提供共享工具和引擎來構造編譯器,編譯器開發者只專注于目標機相關代碼的開發。CoSy框架生成的編譯器具有可擴展性和可移植性。可以根據目
2013-08-19 17:49:100 的典型用法。 CMP x, #0 MOVGE y, #1 MOVLT y, #0 但當代碼中連續的條件執行指令超過4條時,就會影響程序的執行速度。所以編譯器在編譯程序時,限制條件指令連續出現的次數。 ARM編譯器常把C語言中的ifelse結構編譯成條件執行指令,但子程序調用一
2017-10-17 16:52:052 。理解這些問題,將有助于編寫出在提高執行速度和減少代碼尺寸方面更高效的C源代碼。 本章假定讀者熟悉C語言,并且有一些匯編語言編程方面的知識。有關ARM編程的詳細信息,請參閱本書的相關章節。 14.1 C編譯器及其優化 本章主要講解C編譯器在代碼優化
2017-10-17 17:22:262 C語言的編譯鏈接過程要把我們編寫的一個c程序(源代碼)轉換成可以在硬件上運行的程序(可執行代碼),需要進行編譯和鏈接。
2018-04-18 10:08:0734733 
通過一定的方法來編寫C程序,可以幫助C編譯器生成執行速度更快的ARM代碼。
2018-05-12 02:12:003667 本視頻介紹了MPLAB? XC8 C編譯器的架構特性。該編譯器的編譯過程不同于傳統的編譯器,采用了一種稱為"OCG(全知代碼生成)"的技術。
2018-05-23 12:47:005379 
本文檔介紹了針對PIC18 MCU的MPLAB? C編譯器(以前的說法,本文檔稱為MPLAB C18)與MPLAB XC8 C編譯器間的差異,以及如何將針對MPLAB C18定制的C源代碼和編譯器選項移植到MPLAB XC8。
2018-06-07 09:28:0030 只要知道其中的幾個就夠了. -o選項我們已經知道 了,表示我們要求輸出的可執行文件名. -c選項表示我們只要求編譯器輸出目標代碼,而 不必要輸出可執行文件. -g選項表示我們要求編譯器在編譯的時候提供我們以后對程序 進行調試的信息.
2018-07-16 17:02:495494 
https://software.intel.com/zh-cn/intel-advisor-xe使用新的英特爾?編譯器15.0版中的編譯器和庫,可以更快地構建快速代碼。
2018-11-12 07:03:001665 Steve Lionel談到英特爾Fortran編譯器如何生成更快的應用程序。他使用Polyhedron的基準來獨立突出卓越的性能。
2018-11-06 06:39:001953 編程語言是怎樣工作的
理解編譯器內部原理,可以讓你更高效利用它。按照編譯的工作順序,逐步深入編程語言和編譯器是怎樣工作的。本文有大量的鏈接、樣例代碼和圖表幫助你理解編譯器。
2018-12-23 17:25:3610638 理解編譯器內部原理,可以讓你更高效利用它。按照編譯的工作順序,逐步深入編程語言和編譯器是怎樣工作的。本文有大量的鏈接、樣例代碼和圖表幫助你理解編譯器。
2018-12-26 09:53:034058 gcc是linux環境下的asm和c語言編譯器,生成的是可以在x86平臺上運行的可執行程序;
2019-04-26 16:12:536252 的m68k編譯器結合,比較成熟。主要特征是:應用程式可以在目標程式中添加獨立于系統的信息,同時不影響對目標程式的訪問;為調試器預留空間,以便添加調試信息;可以通過編譯選項改變目標文件的生成方式。elf
2019-04-02 14:46:501330 8月31日,華為方舟編譯器開源網站上線,開發者可以通過華為云與開源中國代碼托管網址獲得相關和文檔,以便參考學習、了解方舟編譯器的架構和代碼。可以說,對于全球終端用戶、開發者以及應用廠商而言,“方舟”開源都有著非凡的意義。
2019-09-04 10:05:003368 如果你使用的是集成開發環境,那么你點擊編譯按鈕就可生成可執行文件,然后點擊運行即可運行。那么,你知道從源代碼到可執行文件經歷了哪些過程嗎。僅僅是編譯?
2020-06-24 11:49:012842 選擇一種合適的數據結構很重要,如果在一堆隨機存放的數中使用了大量的插入和刪除指令,那使用鏈表要快得多。數組與指針語句具有十分密切的關系,一般來說,指針比較靈活簡潔,而數組則比較直觀,容易理解。對于大部分的編譯器,使用指針比使用數組生成的代碼更短,執行效率更高。
2020-09-21 11:55:261329 的優化器,最終生成二進制文件,二進制文件與編譯器運行時庫文件鏈接生成可執行文件,在方舟的運行環境中就可執行該文件。方舟編譯器 IR 是支持程序編譯和運行的中間程序表示。程序源代碼中的任何信息對于程序分
2020-10-14 14:56:111 對于程序員來說編譯器是非常熟悉的,每天都在用,但是當你在點擊“Run”這個按鈕或者執行編譯命令時你知道編譯器是怎樣工作的嗎?
2021-03-09 15:20:302533 由于早期的 Lisp 編譯器生成的代碼效率普遍低下,成為了 Lisp 失敗的主要原因之一。而現在的高性能 Lisp 編譯器(比
2021-03-30 10:45:291840 EE-147:調整TigerSHARC?DSP編譯器的C源代碼
2021-04-16 12:39:276 對 Compcert編譯器目標代碼生成機制進行剖析,主要介紹其設計邏輯、翻譯過程、語義保持性以及代碼結構,并給出了 Compcert編譯器重定向設計的要點。文中工作有助于實現 Compcert重定向,比如實現面向重要國產處理器的后端。
2021-05-07 10:17:284 1 設置環境變量包括gcc工具path,編譯器,linker,匯編工具名字,linker選項等2處理boot code3 編譯c代碼生成目標文件4準備elf文件用編譯器,linker生成最終可執行代碼
2021-11-02 17:30:4810 2021年11月6日MCC版本過高,低版本的XC8編譯器會導致警告?。代碼能夠編譯通過,但是在實際執行中會導致MCC配置的代碼出現問題,導致不能達到MCC配置預設的效果。例如:在用較高版本的MCC
2021-11-16 20:06:0412 編譯生成能在ARM架構上運行的程序。\qquad查看一個可執行程序,究竟屬于哪個架構,可以使用file命令。比如有.c文件hello.c。gcc hello.c -o hello #生成可執行文件hellofile hello\qquad運行結果:...
2021-11-30 15:21:1111 以前看過有的程序在可執行變量之后定義,當時就挺納悶,C語言不是只能在函數的可執行語句之前定義變量嗎。后來偶然發現KEIL5中設置一下編譯器就可以在可執行語句之后定義變量了。勾選下圖的“C99 Mode"選項即可...
2022-01-13 13:05:182 昨天有伙伴私信我,為什么我用C語言寫的hello world幾行代碼,在編譯器里面報錯了呢?
2022-03-16 08:38:144862 對于嵌入式系統,最終代碼的體積和效率取決于由編譯器生成的可執行代碼,而非開發人員編寫的源代碼;但是源代碼的優化,可以幫助編譯器生成更加優質的可執行代碼。
2022-03-29 15:58:071121 
22.0版本的Arm編譯器為Neoverse-V1提供了一個優化的成本模型,并提供了許多與SVE代碼生成相關的改進。這包括(1)優化使用SVE的Gather/Scatter功能(2)將循環(loop)填充對齊,以更好地利用指令緩存(3)在將向量的一個元素插入另一個元素時,優化使用SVE拼接操作。
2022-06-15 09:19:18965 在標準C語言中,編譯出來的可執行程序分為代碼區(text)、數據區(data)和未初始化數據區(bss)3個部分。如下代碼
2022-06-16 09:01:281488 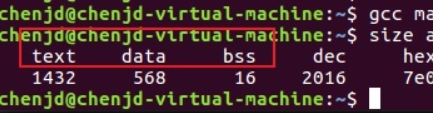
交叉編譯器中“交叉”的意思就是在一個架構上編譯另外一個架構的代碼,相當于兩種架構“交叉”起來了。Ubuntu 自帶的 gcc 編譯器是針對 X86 架構的,而我們現在要編譯的是 ARM 架構的代碼
2022-09-29 09:12:332468 在學習 Andorid 逆向的過程中,發現無論是哪種編譯器,生成哪個平臺的代碼,其優化思路在本質上如出一轍,在 Windwos 平臺所使用的技巧,在安卓平臺仍然適用,不外乎乘法除法計算的優化
2023-02-01 16:25:25596 在學習 Andorid 逆向的過程中,發現無論是哪種編譯器,生成哪個平臺的代碼,其優化思路在本質上如出一轍,在 Windwos 平臺所使用的技巧,在安卓平臺仍然適用,不外乎乘法除法計算的優化
2023-02-01 16:25:27599 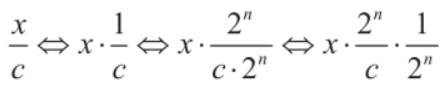
使用Keil MDK或者IAR等使用圖形界面的開發環境,可以在圖形界面環境下編譯源碼工程,并下載編譯生成的可執行文件到目標微控制器中。但若使用ARMGCC等命令行工具鏈,需要額外的下載工具,才能將編譯生成的可執行文件下載到目標微控制器中。
2023-02-17 09:32:37566 makefile文件最常用的作用是,告訴make程序,如何來編譯以及連接程序,最終生成可執行的二進制文件。
2023-05-18 15:27:582439 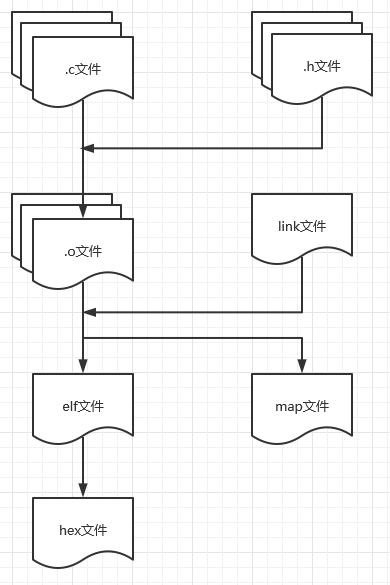
交叉編譯,也稱跨平臺編譯,就是在一個平臺上編譯源代碼,生成結果為另一個平臺上的可執行代碼。
2023-05-22 17:15:53379 一個程序首先要保證正確性,在保證正確性的基礎上,性能也是一個重要的考量。要編寫高性能的程序,第一,必須選擇合適的算法和數據結構;第二,應該編寫編譯器能夠有效優化以轉換成高效可執行代碼的源代碼,要做到
2023-11-24 15:37:18346 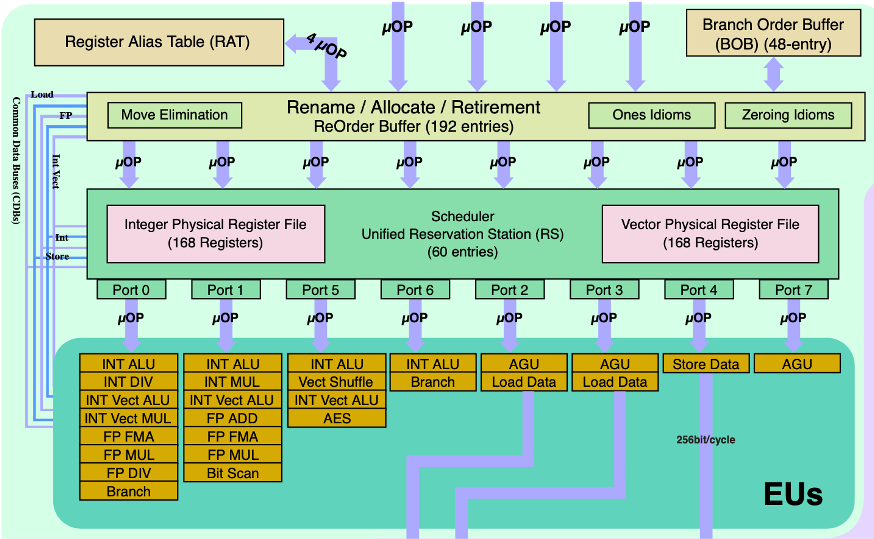
 電子發燒友App
電子發燒友App













 工商網監
工商網監
評論