 電子發(fā)燒友App
電子發(fā)燒友App


Linux - 基礎 IO
文件 IO 相關操作
stdin & stdout & stderr
系統(tǒng)文件 I/O
文件的宏觀理解:
狹義理解:
1.文件在磁盤里
2.磁盤是永久性存儲介質,因此文件在磁盤上的存儲是永久性的
3.磁盤是外設(即是輸出設備也是輸入設備)
4.磁盤上的文件 本質是對文件的所有操作,都是對外設的輸入和輸出 簡稱 IO
廣義理解:
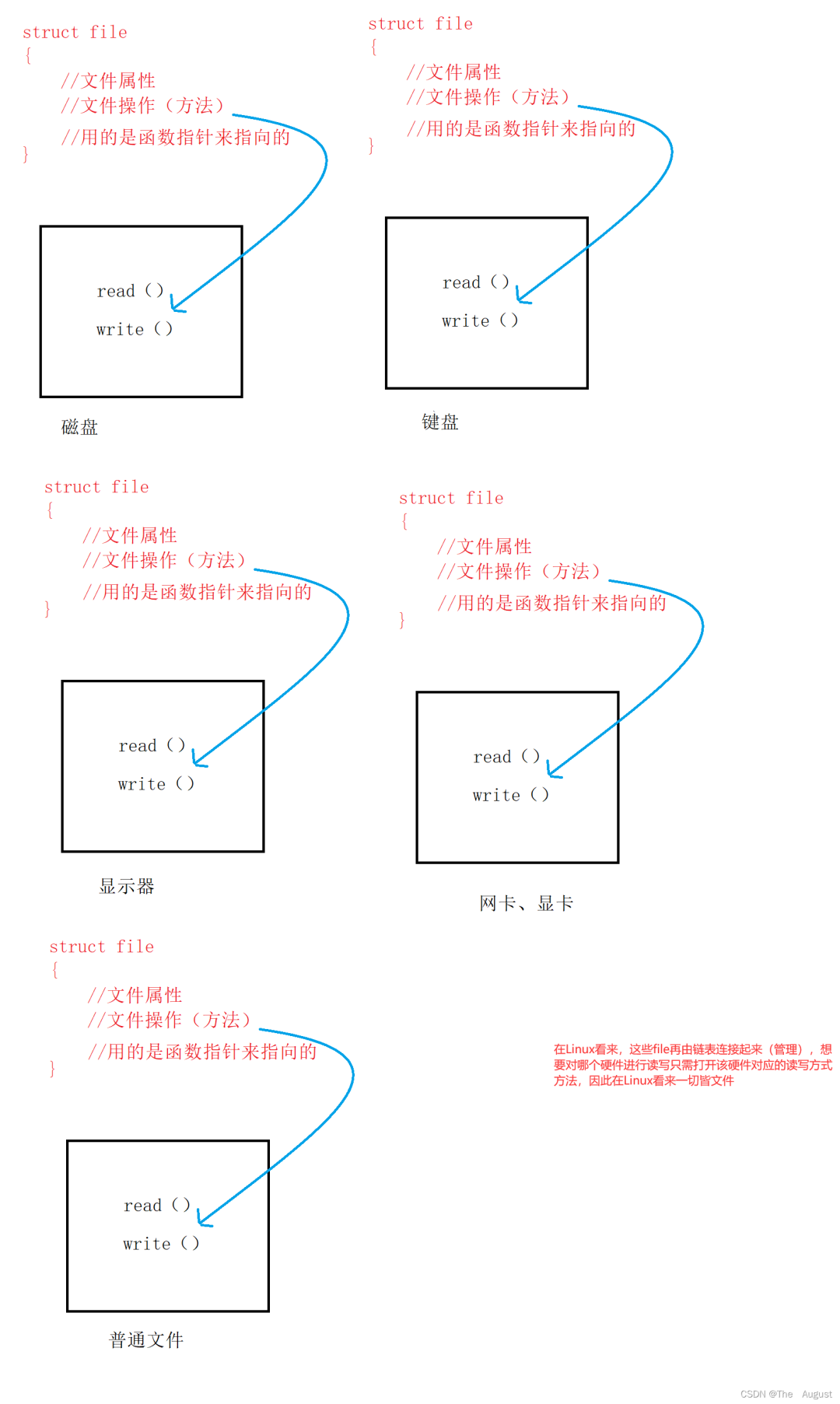
1.Linux 下一切皆文件(鍵盤、顯示器、網(wǎng)卡、磁盤…… 這些都是抽象化的過程)
文件操作的歸類認知:
1.對于 0KB 的空文件是占用磁盤空間的
2.文件是文件屬性(元數(shù)據(jù))和文件內(nèi)容的集合(文件 = 屬性(元數(shù)據(jù))+ 內(nèi)容)
3.所有的文件操作本質是文件內(nèi)容操作和文件屬性操作
系統(tǒng)角度:
1.對文件的操作本質是進程對文件的操作
2.磁盤的管理者是操作系統(tǒng)
3.文件的讀寫本質不是通過 C 語言 / C++ 的庫函數(shù)來操作的(這些庫函數(shù)只是為用戶提供方便),而是通過文件相關的系統(tǒng)調用接口來實現(xiàn)的
文件 IO 相關操作
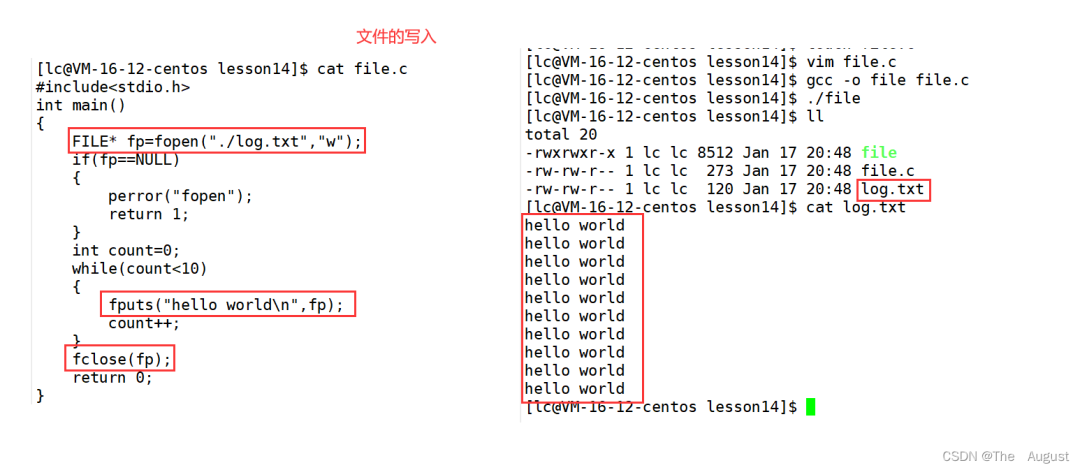
int?fputs(const?char?*s,?FILE?*stream);
?
fputs 函數(shù)是將 s 所指向的數(shù)據(jù)往 stream 中所指向的文件中寫
?
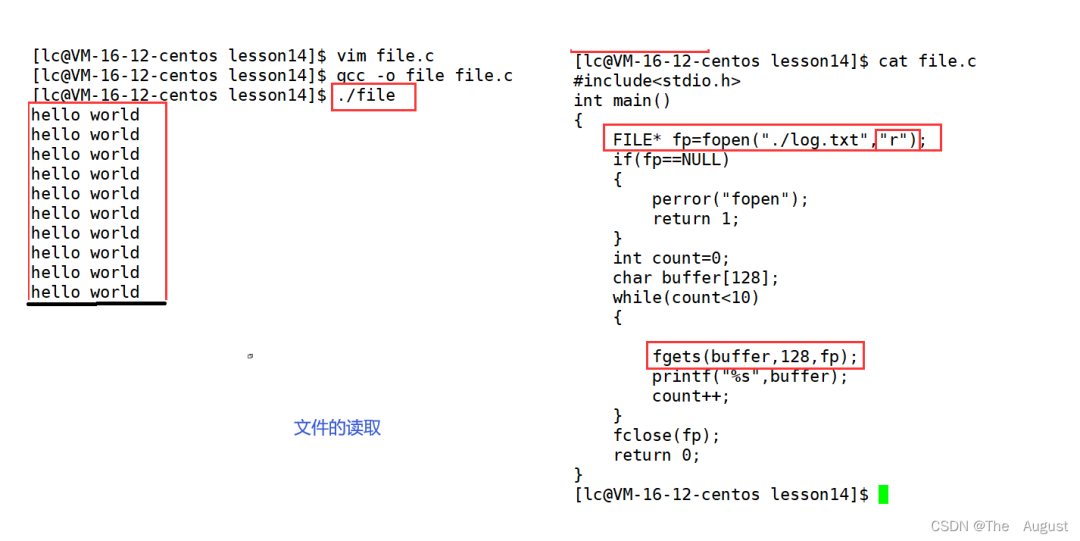
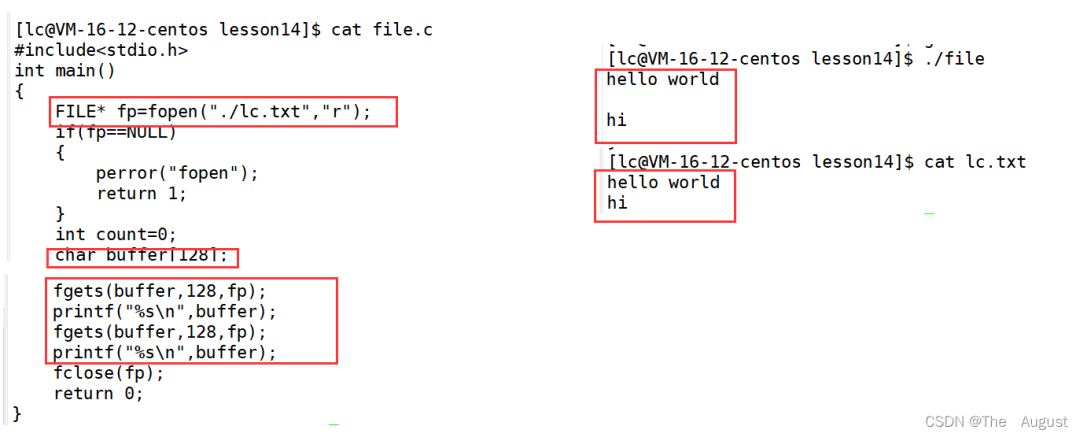
char?*?fgets?(?char?*?str,?int?num,?FILE?*?stream?)
?
注:
從流中讀取字符并將它們作為 C 字符串存儲到 str 中,直到讀取 (num-1) 個字符或到達換行符或文件結尾,以先發(fā)生者為準。
換行符使 fgets 停止讀取,但它被函數(shù)視為有效字符并包含在復制到 str 的字符串中。
在復制到 str 的字符之后會自動附加一個終止空字符。
fgets 與 get 完全不同:fgets 不僅接受流參數(shù),還允許指定 str 的最大大小并在字符串中包含任何結束的換行符。
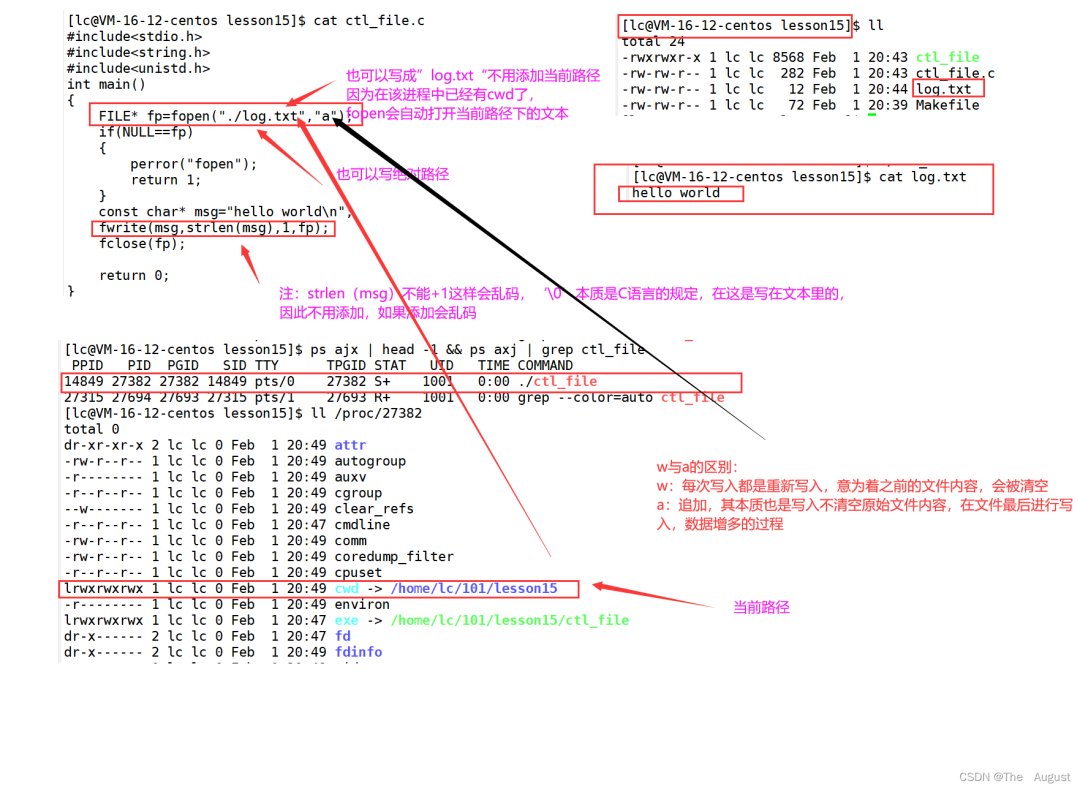
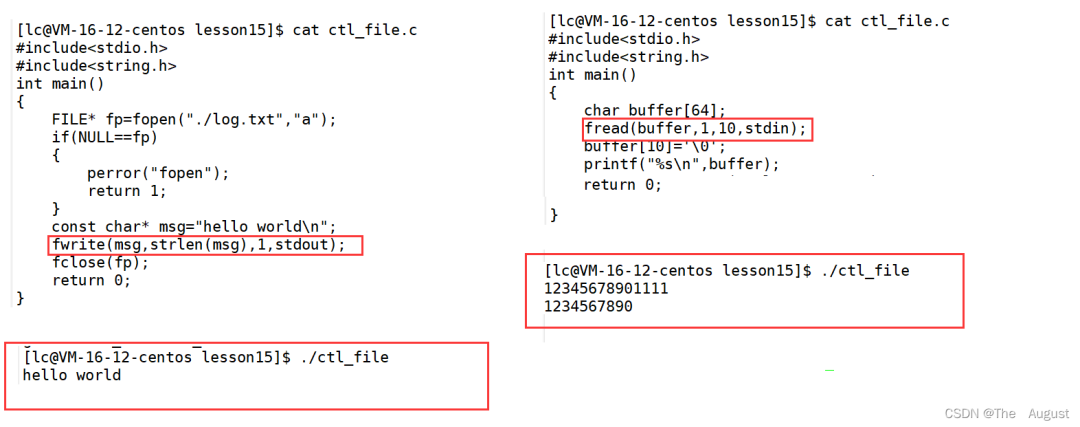
fwrite 的使用方法
當前路徑指的是每個進程,都有一個內(nèi)置的屬性 cwd
fwrite 函數(shù)如果 size_t count 傳入的數(shù)正好將字符串內(nèi)容全部傳入到指定文本中則返回 count,否則返回與 count 不同的數(shù)
fwrite 函數(shù)傳入內(nèi)容的大小正好是 size_t size, 和 size_t count 的乘積
stdin & stdout & stderr

任何 C 程序,都默認打開三個文件分別叫做標準輸入(stdin)、標準輸出(stdout)、標準錯誤(stderr)
標準輸入(stdin)——鍵盤文件——讀方法(read)
標準輸出(stdout)、標準錯誤(stderr)——顯示器文件——寫方法(write)
Linux 下一切皆文件
所有的外設硬件,本質是對應的核心操作無外乎是 read 和 write(不同的硬件對應的讀寫方式是不一樣的)
 注:
注:
可以通過 C 接口,直接對 stdin、stdout、stderr 進行讀寫
C 默認會打開三個輸入輸出流,分別是 stdin, stdout, stderr, 這樣做便于語言進行上手使用,都有輸入輸出的需求
幾乎所有的編程語言都會默認會打開三個輸入輸出流 stdin, stdout, stderr,
任何一種編程語言的文件操作相關的函數(shù)(庫函數(shù))底層都會調用系統(tǒng)調用接口(open、close、write、read,這些在 Linux 系統(tǒng)下有,但這些接口不具備可移植性)
語言上相關文件操作的庫函數(shù)兼容自身語法特征,系統(tǒng)調用使用成本較高,而且不具備可移植性
系統(tǒng)文件 I/O
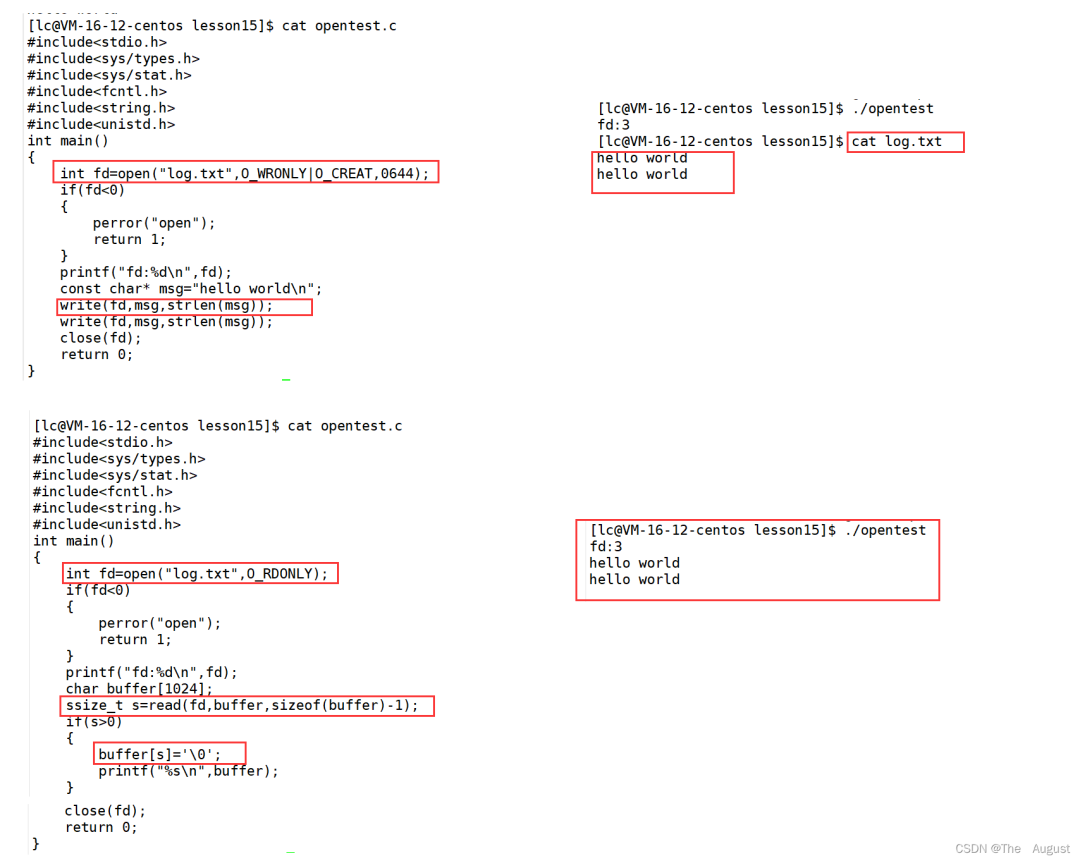
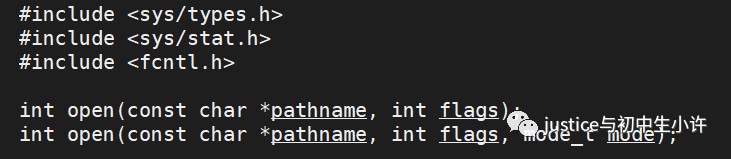
open
?
#include?#include? #include? int?open(const?char?*pathname,?int?flags); int?open(const?char?*pathname,?int?flags,?mode_t?mode); pathname:?要打開或創(chuàng)建的目標文件 flags:?打開文件時,可以傳入多個參數(shù)選項,用下面的一個或者多個常量進行“或”運算,構成flags。 參數(shù): ???O_RDONLY:?只讀打開 ???O_WRONLY:?只寫打開 ???O_RDWR?:?讀,寫打開 ?????這三個常量,必須指定一個且只能指定一個 ?? O_CREAT :?若文件不存在,則創(chuàng)建它。需要使用mode選項,來指明新文件的訪問權限 ???O_APPEND:?追加寫 ?返回值: ?????成功:新打開的文件描述符 ????失敗:-1
?
注:
open 函數(shù)具體使用哪個,和具體應用場景相關,如目標文件不存在,需要 open 創(chuàng)建,則第三個參數(shù)表示創(chuàng)建文件的默認權限, 否則,使用兩個參數(shù)的 open。
O_RDONLY、O_WRONLY、O_RDWR…… 這些都是系統(tǒng)定義的宏,這些參數(shù)只占一個 int 整形中的一個比特位
注:write read close lseek…… 與 C 語言文件相關接口用法類似
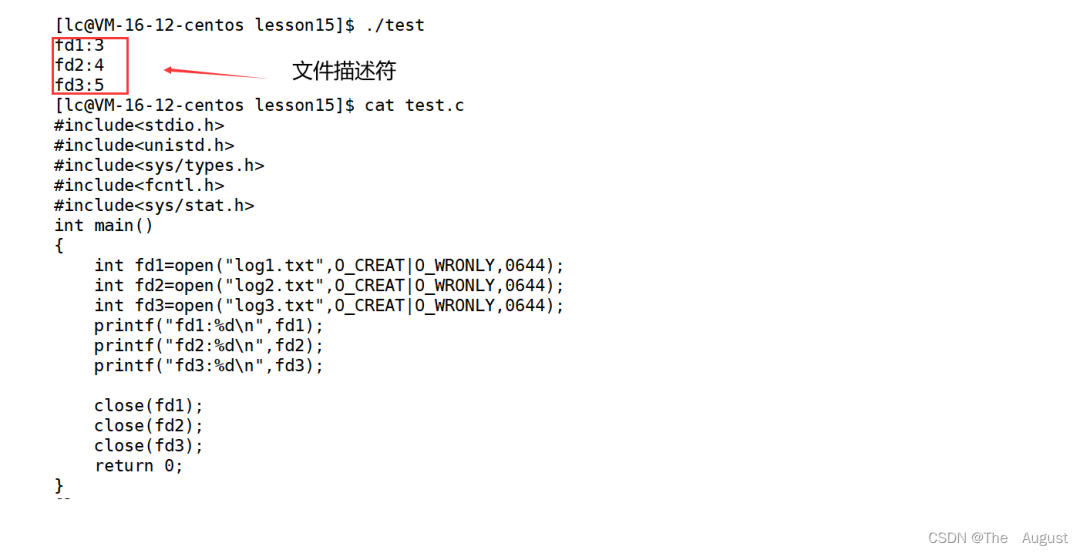
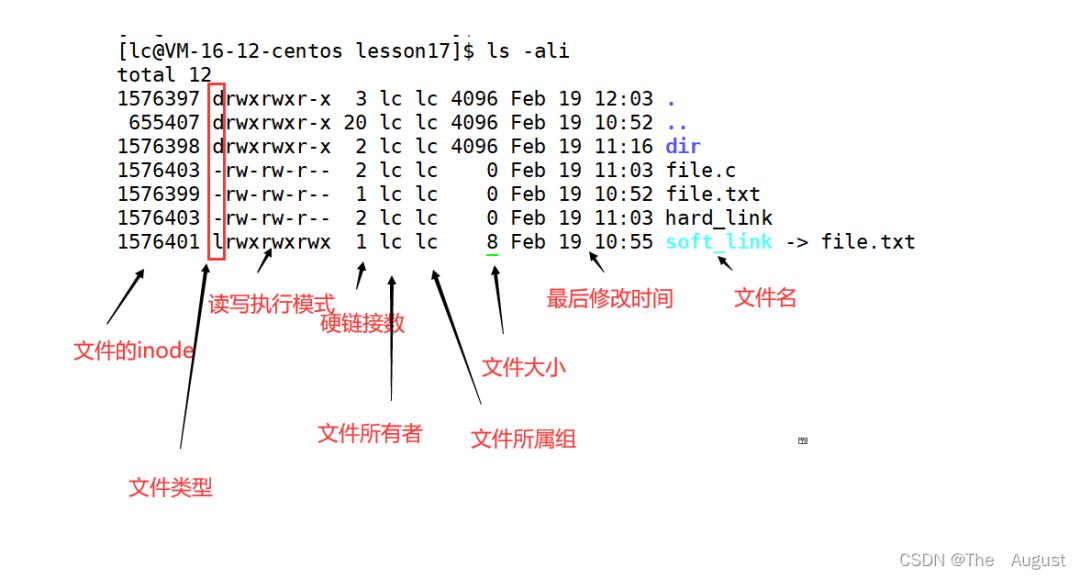
文件描述符 fd
 注:
注:
用戶層看到的 fd 本質是系統(tǒng)中維護進程和文件對應關系的數(shù)組的下標
所謂的默認打開文件,標準輸入,標準輸出,標準錯誤,其實是由底層系統(tǒng)支持的,默認一個進程在運行的時候,就打開了 0,1,2
對于進程來講,對所有的文件進行操作,統(tǒng)一使用一套接口(一組函數(shù)指針),因此在 OS 看來一切皆文件
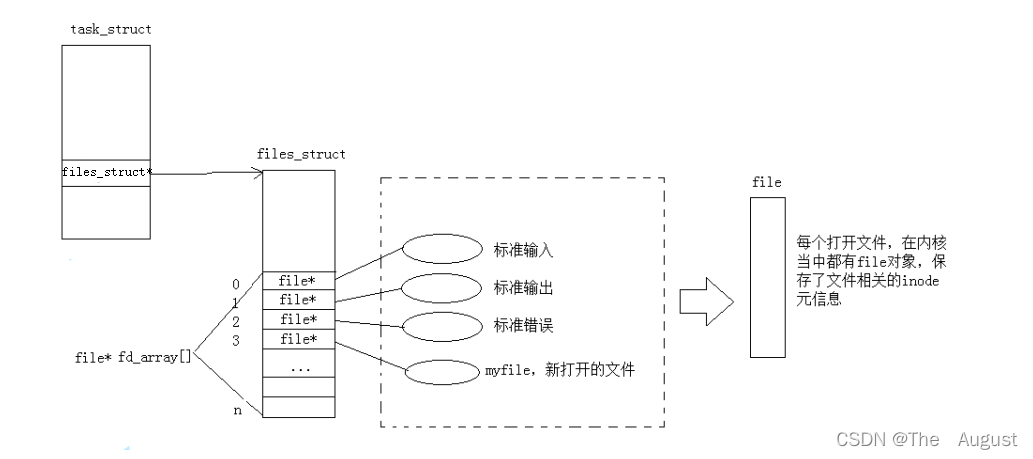
文件描述符就是從 0 開始的小整數(shù)。當打開文件時,操作系統(tǒng)在內(nèi)存中要創(chuàng)建相應的數(shù)據(jù)結構來描述目標文件。于是就有了 file 結構體。表示一個已經(jīng)打開的文件對象。而進程執(zhí)行 open 系統(tǒng)調用,所以必須讓進程和文件關聯(lián)起來。每個進程都有一個指針 files_struct*, 指向一張表 files_struct, 該表最重要的部分就是包涵一個指針數(shù)組,每個元素都是一個指向打開文件的指針!所以,本質上,文件描述符就是該數(shù)組的下標。只要拿著文件描述符,就可以找到對應的文件
補充:
標準輸入、標準輸出、標準錯誤在對應的文件描述符為 0,1,2,對應 C 語言層上的是 stdin、stdout、stderr
所有文件,如果要被使用時,首先必須被打開
一個進程可以打開多個文件,系統(tǒng)中被打開的文件一定有多個,多個被打開的文件,一定要被操作系統(tǒng)管理起來的(先描述(struct file(包含了目標文件的基本操作和部分屬性)),再組織(雙鏈表))
打開文件的過程:先在 fd_array 數(shù)組中找一個最小的沒有被使用的數(shù)組下標位置,然后把新 open 出的文件的結構體地址填入到數(shù)組中去,對應該地址的下標返回給對應的進程
fd:本質是進程和文件之間對應關系的數(shù)組的下標,有了 fd 就可以找到打開文件的所有細節(jié)
文件描述符的分配規(guī)則

總結:
文件描述符的分配規(guī)則:在 files_struct 數(shù)組當中,找到當前沒有被使用的
最小的一個下標,作為新的文件描述符
Linux 進程默認情況下會有 3 個缺省打開的文件描述符,分別是標準輸入 0, 標準輸出 1, 標準錯誤 2
重定向

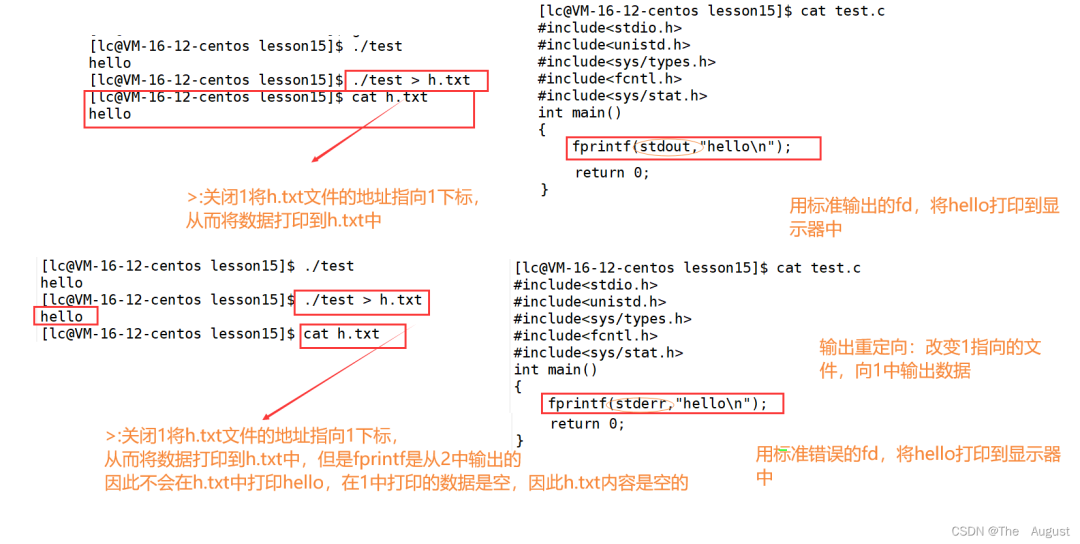
 補充:程序替換的時候不會影響重定向對應的數(shù)據(jù)結構的數(shù)據(jù)(程序替換影響的是進程虛擬地址空間部分,而重定向影響的是 files_struct 部分)
補充:程序替換的時候不會影響重定向對應的數(shù)據(jù)結構的數(shù)據(jù)(程序替換影響的是進程虛擬地址空間部分,而重定向影響的是 files_struct 部分)
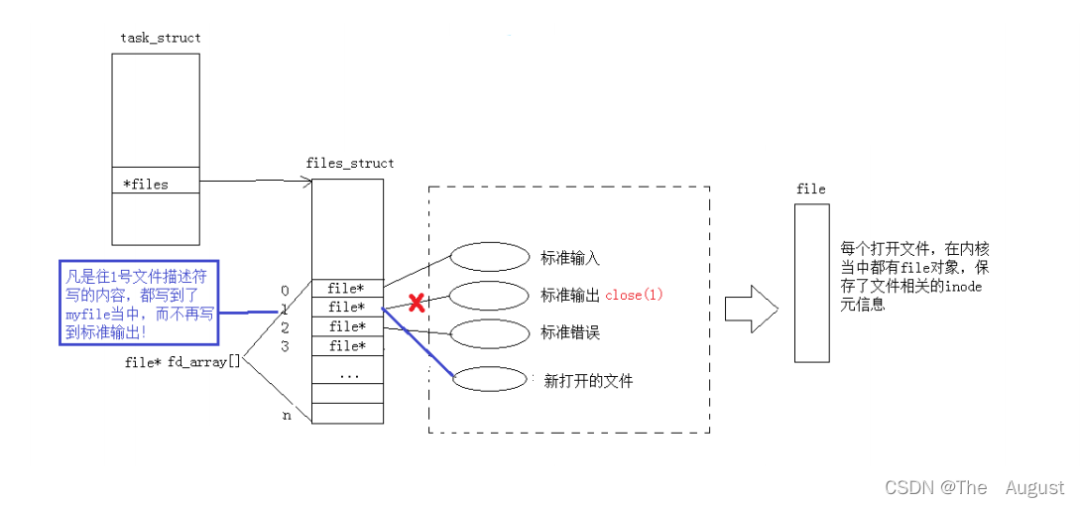
使用 dup2 系統(tǒng)調用
?
#include?int?dup2(int?oldfd,?int?newfd);
?
注:
newfd 使 oldfd 的一份拷貝,不是拷貝 fd 而是拷貝 fd 對應的 fd_array 數(shù)組中的內(nèi)容

FILE
因為 IO 相關函數(shù)與系統(tǒng)調用接口對應,并且?guī)旌瘮?shù)封裝系統(tǒng)調用,所以本質上,訪問文件都是通過 fd 訪問的。因此 C 庫當中的 FILE 結構體內(nèi)部,必定封裝了 fd
?
typedef?struct?_IO_FILE?FILE;?在/usr/include/stdio.h
在/usr/include/libio.h
struct?_IO_FILE?{
?int?_flags;?/*?High-order?word?is?_IO_MAGIC;?rest?is?flags.?*/
#define?_IO_file_flags?_flags
?//緩沖區(qū)相關
?/*?The?following?pointers?correspond?to?the?C++?streambuf?protocol.?*/
?/*?Note:?Tk?uses?the?_IO_read_ptr?and?_IO_read_end?fields?directly.?*/
?char*?_IO_read_ptr;?/*?Current?read?pointer?*/
?char*?_IO_read_end;?/*?End?of?get?area.?*/
?char*?_IO_read_base;?/*?Start?of?putback+get?area.?*/
?char*?_IO_write_base;?/*?Start?of?put?area.?*/
??char*?_IO_write_ptr;?/*?Current?put?pointer.?*/
?char*?_IO_write_end;?/*?End?of?put?area.?*/
?char*?_IO_buf_base;?/*?Start?of?reserve?area.?*/
?char*?_IO_buf_end;?/*?End?of?reserve?area.?*/
?/*?The?following?fields?are?used?to?support?backing?up?and?undo.?*/
?char?*_IO_save_base;?/*?Pointer?to?start?of?non-current?get?area.?*/
?char?*_IO_backup_base;?/*?Pointer?to?first?valid?character?of?backup?area?*/
?char?*_IO_save_end;?/*?Pointer?to?end?of?non-current?get?area.?*/
?struct?_IO_marker?*_markers;
?struct?_IO_FILE?*_chain;
?int?_fileno;?//封裝的文件描述符
#if?0
?int?_blksize;
#else
?int?_flags2;
#endif
?_IO_off_t?_old_offset;?/*?This?used?to?be?_offset?but?it's?too?small.?*/
#define?__HAVE_COLUMN?/*?temporary?*/
?/*?1+column?number?of?pbase();?0?is?unknown.?*/
?unsigned?short?_cur_column;
?signed?char?_vtable_offset;
?char?_shortbuf[1];
?/*?char*?_save_gptr;?char*?_save_egptr;?*/
?_IO_lock_t?*_lock;
#ifdef?_IO_USE_OLD_IO_FILE
};

?
總結:
FILE 結構體中包含了 int fileno 的成員(也就是系統(tǒng)上的 fd 文件描述符)
fopen、fwrite、fread、fclose 等 f 系列的庫函數(shù)都是由底層 open、write 、read、close 實現(xiàn)的,通過 open 的返回值傳給 fileno,從而對系統(tǒng)調用函數(shù)進行封裝
struct FILE 內(nèi)部包含:
底層對應的文件描述符下標
應用層 C 語言提供的緩沖區(qū)數(shù)據(jù)
所謂的默認打開文件,標準輸入、標準輸出、標準錯誤其實是由底層系統(tǒng)支持的,默認一個進程在運行的時候,就打開了 0,1,2
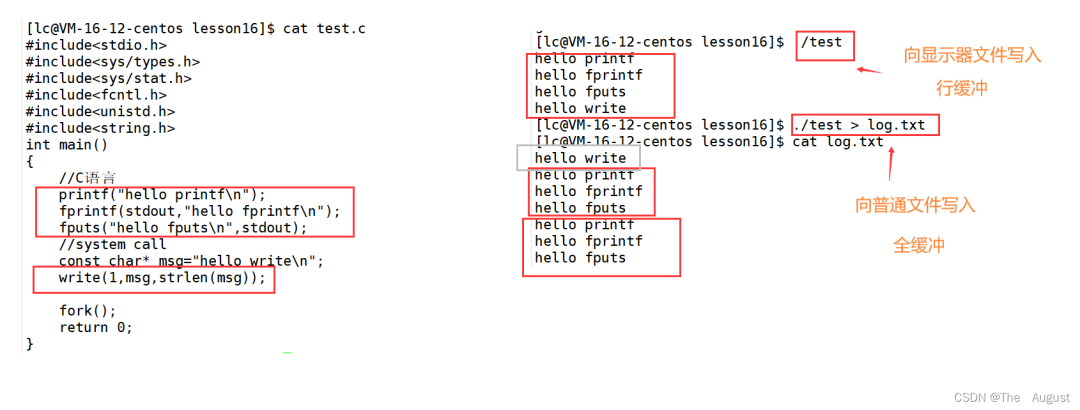
一般 C 庫函數(shù)寫入文件時是全緩沖的,而寫入顯示器是行緩沖。printf fprintf 等庫函數(shù)會自帶緩沖區(qū),當發(fā)生重定向到普通文件時,數(shù)據(jù)的緩沖方式由行緩沖變成了全緩沖。而我們放在緩沖區(qū)中的數(shù)據(jù),就不會被立即刷新,甚至 fork 之后但是進程退出之后,會統(tǒng)一刷新,寫入文件當中。但是 fork 的時候,父子數(shù)據(jù)會發(fā)生寫時拷貝,所以當你父進程準備刷新的時候,子進程也就有了同樣的一份數(shù)據(jù),隨即產(chǎn)生兩份數(shù)據(jù)。write 沒有變化,說明沒有所謂的緩沖
printf fputs 等 庫函數(shù)會自帶緩沖區(qū),而 write 系統(tǒng)調用沒有帶緩沖區(qū)。另外,我們這里所說的緩沖區(qū),都是用戶級緩沖區(qū)。其實為了提升整機性能,OS 也會提供相關內(nèi)核級緩沖區(qū)。printf fprintf 是庫函數(shù), write 是系統(tǒng)調用,庫函數(shù)在系統(tǒng)調用的 “上層”, 是對系統(tǒng)調用的 “封裝”,但是 write 有內(nèi)核級緩沖區(qū),而 printf fwrite fputs 等緩沖區(qū)是用戶級緩沖區(qū),由 C 標準庫提供
注:系統(tǒng)調用函數(shù)與庫函數(shù)盡量不要混在一起使用,可能會與統(tǒng)一使用的函數(shù)的運行結果有所差異
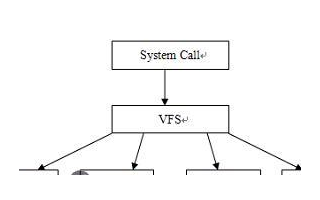
文件系統(tǒng)
文件:打開的文件、普通未打開的文件
打開的文件:屬性與操作方法的表現(xiàn)就是 struct file{} 屬于內(nèi)存級文件
普通未打開的文件:磁盤上面未被加載到內(nèi)存的
文件系統(tǒng)功能:將上述的這些文件管理起來
磁盤
磁盤是計算機主要的存儲介質,可以存儲大量的二進制數(shù)據(jù),并且斷電后也能保持數(shù)據(jù)不丟失。早期計算機使用的磁盤是軟磁盤(Floppy Disk,簡稱軟盤),如今常用的磁盤是硬磁盤(Hard disk,簡稱硬盤)。
 補充:
補充:
內(nèi)存在操作系統(tǒng)的角度使用的時候,基本單位是 4KB,但在使用角度是 1 字節(jié)
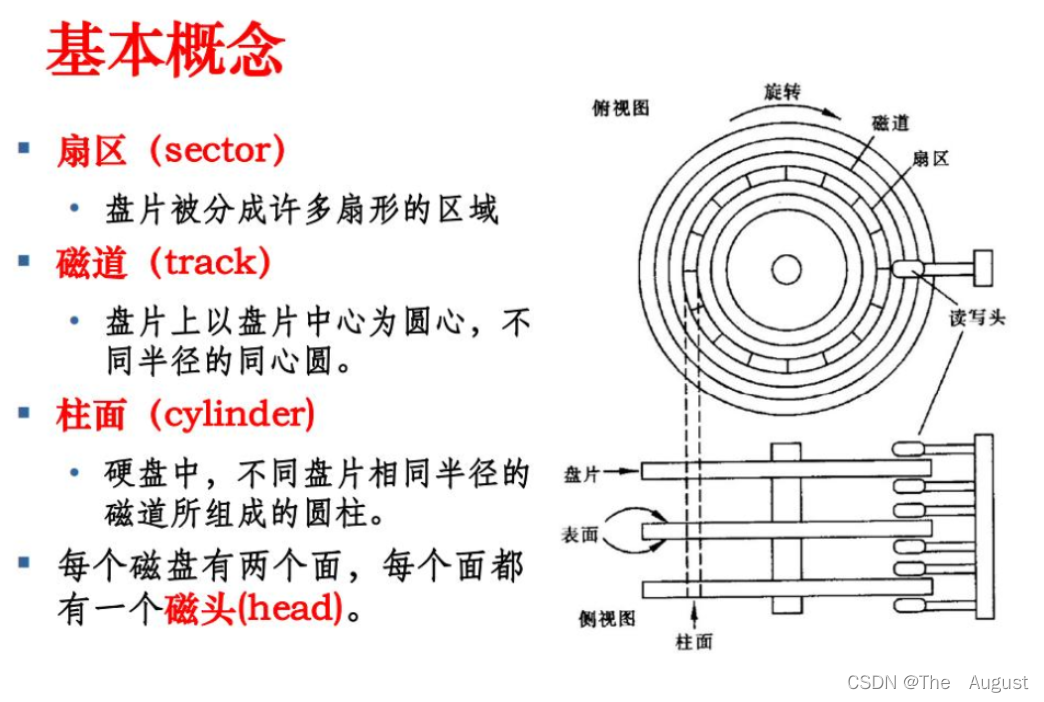
磁盤存儲的基本單位是扇區(qū)(512 字節(jié))(磁盤讀取的最小單元)
內(nèi)存與磁盤間 IO 時,基本單位是 4KB,是通過文件系統(tǒng)來完成的
磁盤的劃分
我們可以將磁盤想象成磁帶(線性結構),將磁盤看成一個線性空間(數(shù)組),類型為扇區(qū)的數(shù)組、數(shù)組個數(shù)為 10 億多

這樣劃分就不用讓 OS 讀取數(shù)據(jù)時在哪個盤面、哪個磁道、哪個扇區(qū)找了,OS 與磁盤映射關系可以通過磁盤驅動來完成,這樣也就做到強解耦性。無論換機械硬盤還是固態(tài)硬盤,OS 都不用改變讀取磁盤數(shù)據(jù)的數(shù)據(jù)結構,只需改變磁盤的驅動程序即可
注:操作系統(tǒng)讀取磁盤數(shù)據(jù)時的下標——LBA
磁盤經(jīng)過在 OS 中的虛擬化成數(shù)組,但是所占空間太大,因此需要進行分區(qū)化管理,并對該區(qū)域進行格式化(寫入文件系統(tǒng)(數(shù)據(jù)和方法))。eg:Windows 中的 C 盤、D 盤……
每個分區(qū)再進行分組——塊組
Linux 系統(tǒng)下支持多種文件系統(tǒng):Ext2、Ext3、fs、usb-fs、sysfs、proc
inode
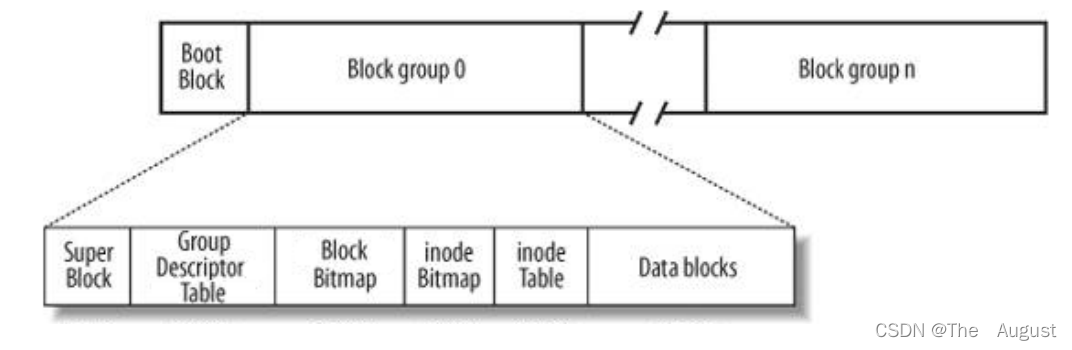
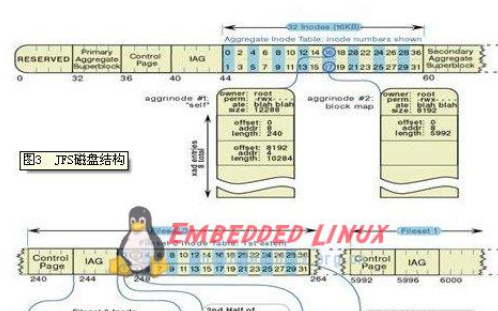
Linux ext2 文件系統(tǒng),上圖為磁盤文件系統(tǒng)圖(內(nèi)核內(nèi)存映像肯定有所不同),磁盤是典型的塊設備,硬盤分區(qū)被劃分為一個個的 block。一個 block 的大小是由格式化的時候確定的,并且不可以更改。例如 mke2fs 的 - b 選項可以設 定 block 大小為 1024、2048 或 4096 字節(jié)。而啟動塊(Boot Block)的大小是確定的,
Block Group:ext2 文件系統(tǒng)會根據(jù)分區(qū)的大小劃分為數(shù)個 Block Group。而每個 Block Group 都有著相同的結構組成。
超級塊(Super Block):存放文件系統(tǒng)本身的結構信息。記錄的信息主要有:bolck 和 inode 的總量,未使用的 block 和 inode 的數(shù)量,一個 block 和 inode 的大小,最近一次掛載的時間,最近一次寫入數(shù)據(jù)的時間,最近一次檢驗磁盤的時間等其他文件系統(tǒng)的相關信息。Super Block 的信息被破壞,可以說整個文件系統(tǒng)結構就被破壞了
GDT,Group Descriptor Table:塊組描述符,描述塊組屬性信息
塊位圖(Block Bitmap):Block Bitmap 中記錄著 Data Block 中哪個數(shù)據(jù)塊已經(jīng)被占用,哪個數(shù)據(jù)塊沒有被占用
inode 位圖(inode Bitmap):每個 bit 表示一個 inode 是否空閑可用。
i 節(jié)點表: 存放文件屬性 如 文件大小,所有者,最近修改時間等
數(shù)據(jù)區(qū):存放文件內(nèi)容
注:
Block Group 每個塊組中都有,但是 Super Block 并不是每個塊組中都有
每一個文件都對應一個 inode 節(jié)點
總結:
基本上,一個文件一個 inode(包括文件)
inode 是一個文件的所有的屬性集合(不包含文件名)(空文件也是占據(jù)空間的,所有的屬性也是數(shù)據(jù)也要占據(jù)空間)
真正表示文件的不是文件名,而是文件的 inode 編號
inode 是可以和特定的數(shù)據(jù)塊產(chǎn)生關聯(lián)的
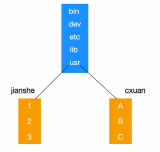
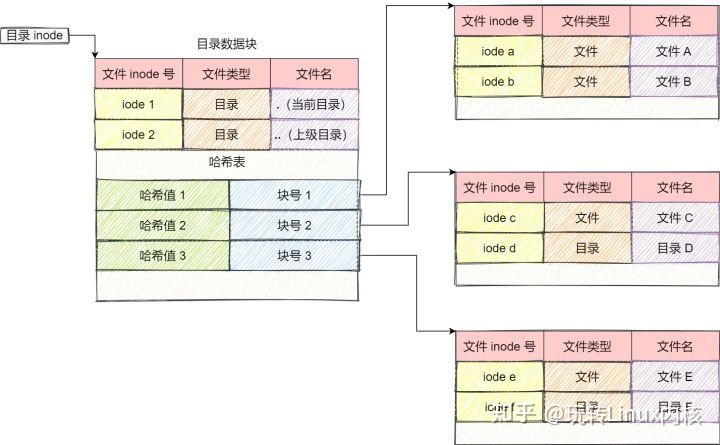
程序員是通過路徑定位的(目錄)來定位一個文件,而操作系統(tǒng)是通過目錄的 Data blocks 來確定文件名和 inode 的映射關系
目錄是文件,有獨立的 inode 和數(shù)據(jù)塊
創(chuàng)建一個新文件主要有一下 4 個操作:
1.存儲屬性 ——內(nèi)核先找到一個空閑的 i 節(jié)點。內(nèi)核把文件信息記錄到其中。
2.存儲數(shù)據(jù) ——該文件需要存儲在三個磁盤塊,內(nèi)核找到了三個空閑塊。將內(nèi)核緩沖區(qū)數(shù)據(jù)緩沖到磁盤的數(shù)據(jù)區(qū)中
3.記錄分配情況——文件內(nèi)容按順序存放(數(shù)據(jù)塊)。內(nèi)核在 inode 上的磁盤分布區(qū)記錄了上述塊列表。
4.添加文件名到目錄——內(nèi)核將入口添加到目錄文件。文件名和 inode 之間的對應關系將文件名和文件的內(nèi)容及屬性連接起來。
大多是操作系統(tǒng)在同一個目錄下是不允許存在同名文件的 刪除文件不需要清空該文件占據(jù)的所有的空間數(shù)據(jù)(只需將該文件的 inode 和對應的數(shù)據(jù)塊無效化即可(文件對應 inode 和 Block 位圖中的數(shù)字 1 設置為 0,并將該文件所對應的目錄中的數(shù)據(jù)塊的關于該文件內(nèi)容清空即可) Linux 下屬性和內(nèi)容是分離的,屬性 inode 保存的(在同一塊塊組 inode 編號是不同的,但是跨組的 inode 編號可能相同),內(nèi)容 Data blocks 保存的
補充:
inode 描述了文件大小和指向數(shù)據(jù)塊的指針
通過 inode 可獲得文件占用的塊數(shù)
通過 inode 可實現(xiàn)文件的邏輯結構和物理結構的轉換
軟硬連接
硬鏈接: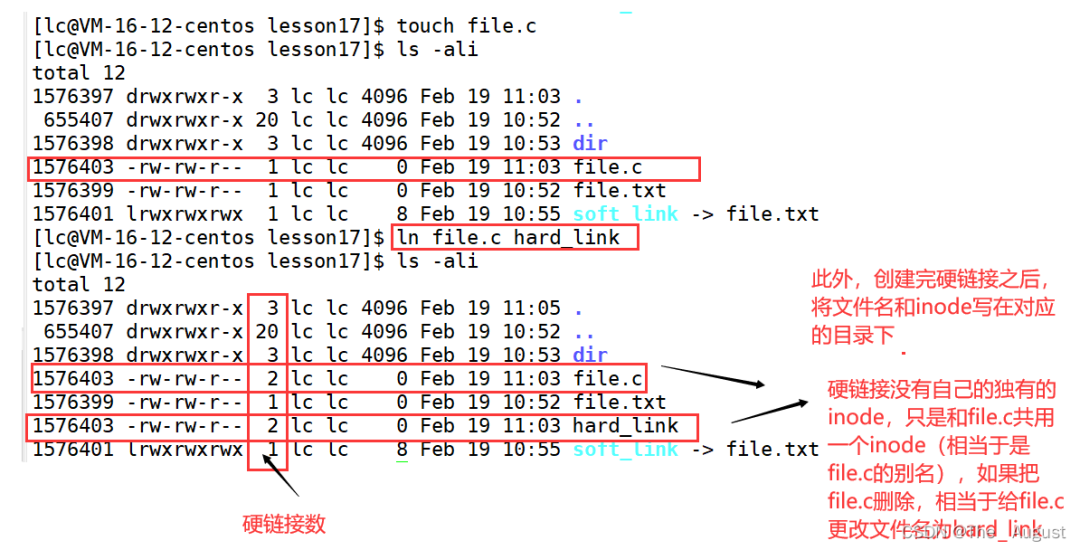 硬鏈接的應用場景:方便進行相對路徑的路徑的設置
硬鏈接的應用場景:方便進行相對路徑的路徑的設置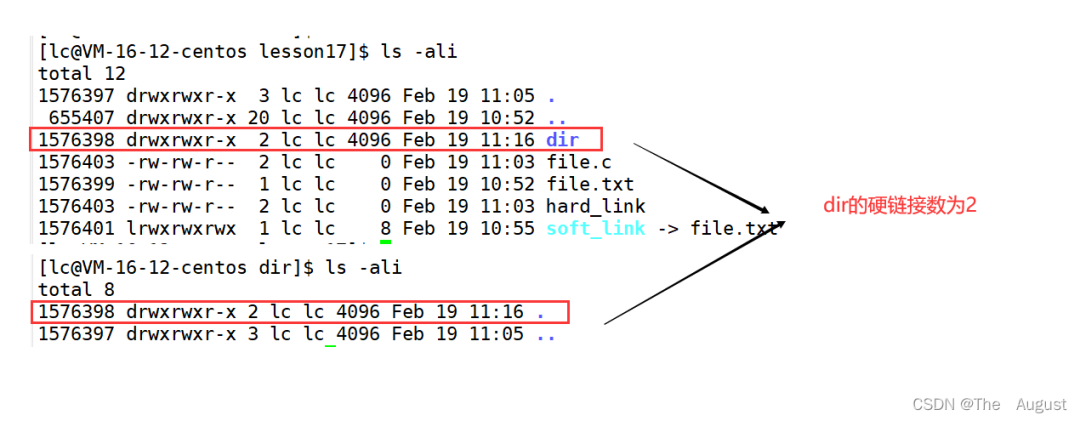
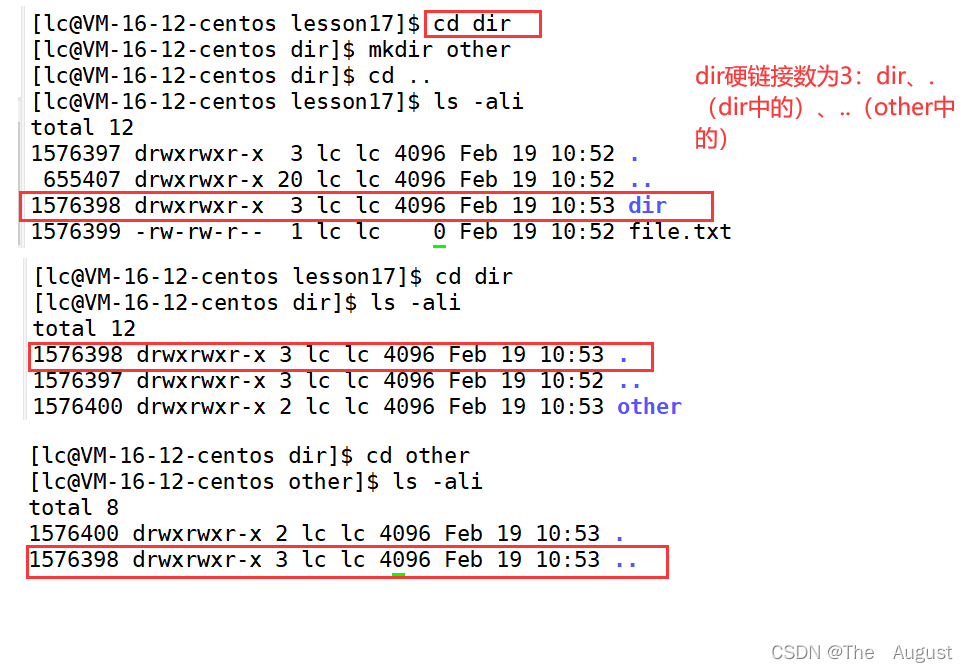 因此,可以看出.、… 的底層實現(xiàn)是通過硬鏈接的方式來實現(xiàn)的
因此,可以看出.、… 的底層實現(xiàn)是通過硬鏈接的方式來實現(xiàn)的
注:
真正找到磁盤上文件的并不是文件名,而是 inode。其實在 linux 中可以讓多個文件名對應于同一個 inode
在刪除文件時干了兩件事情:1. 在目錄中將對應的記錄刪除,2. 將硬連接數(shù) - 1,如果為 0,則將對應的磁盤釋放。
軟鏈接: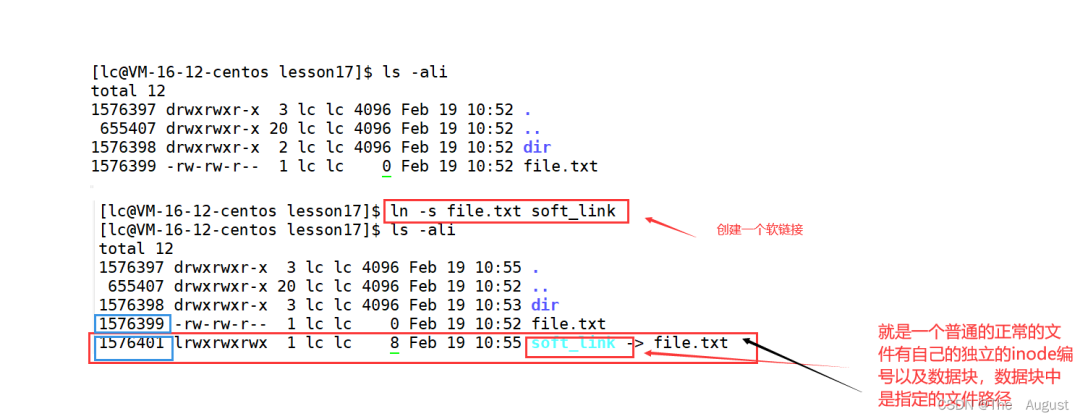 注:硬鏈接是通過 inode 引用另外一個文件,軟鏈接是通過名字引用另外一個文件
注:硬鏈接是通過 inode 引用另外一個文件,軟鏈接是通過名字引用另外一個文件
總結:軟硬鏈接的區(qū)別:本質是是否是獨立文件,有無獨立 inode;用途:軟鏈接可以指向特定的文件方便進行快速索引,硬鏈接是能進行相對路徑設置
補充:
軟鏈接文件是一個獨立的文件有自己的 inode 節(jié)點,通過數(shù)據(jù)中保存的源文件路徑訪問源文件
硬鏈接是文件的一個目錄項,與源文件共用同一個 inode 節(jié)點,直接通過自己的 inode 節(jié)點訪問源文件
不同分區(qū)有可能有不同文件系統(tǒng),因此硬鏈接不能跨分區(qū)建立;軟連接可以跨文件系統(tǒng)進行連接,硬鏈接不可以
當刪除源文件時,軟鏈接文件失效
ln 生成符號鏈接文件指的是 ln -s 生成軟鏈接文件
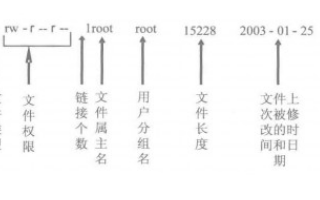
文件的 ACM
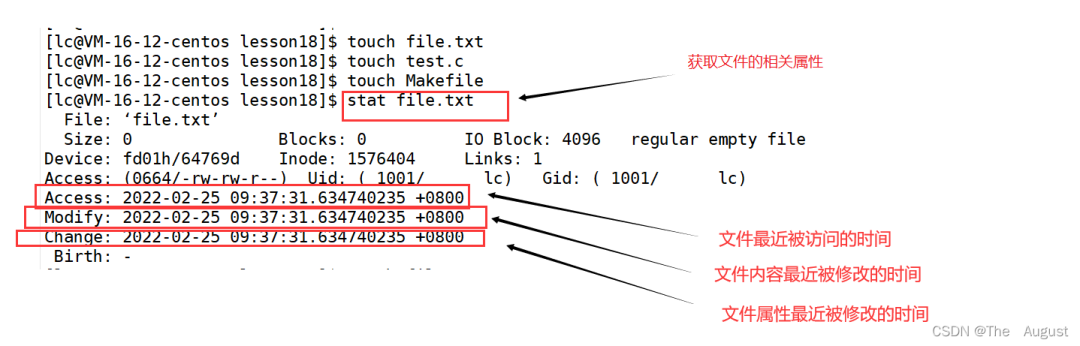

總結:
Access 最后訪問時間
Modify 文件內(nèi)容最后修改時間
Change 屬性最后修改時間
文件的 ACM 的應用場景: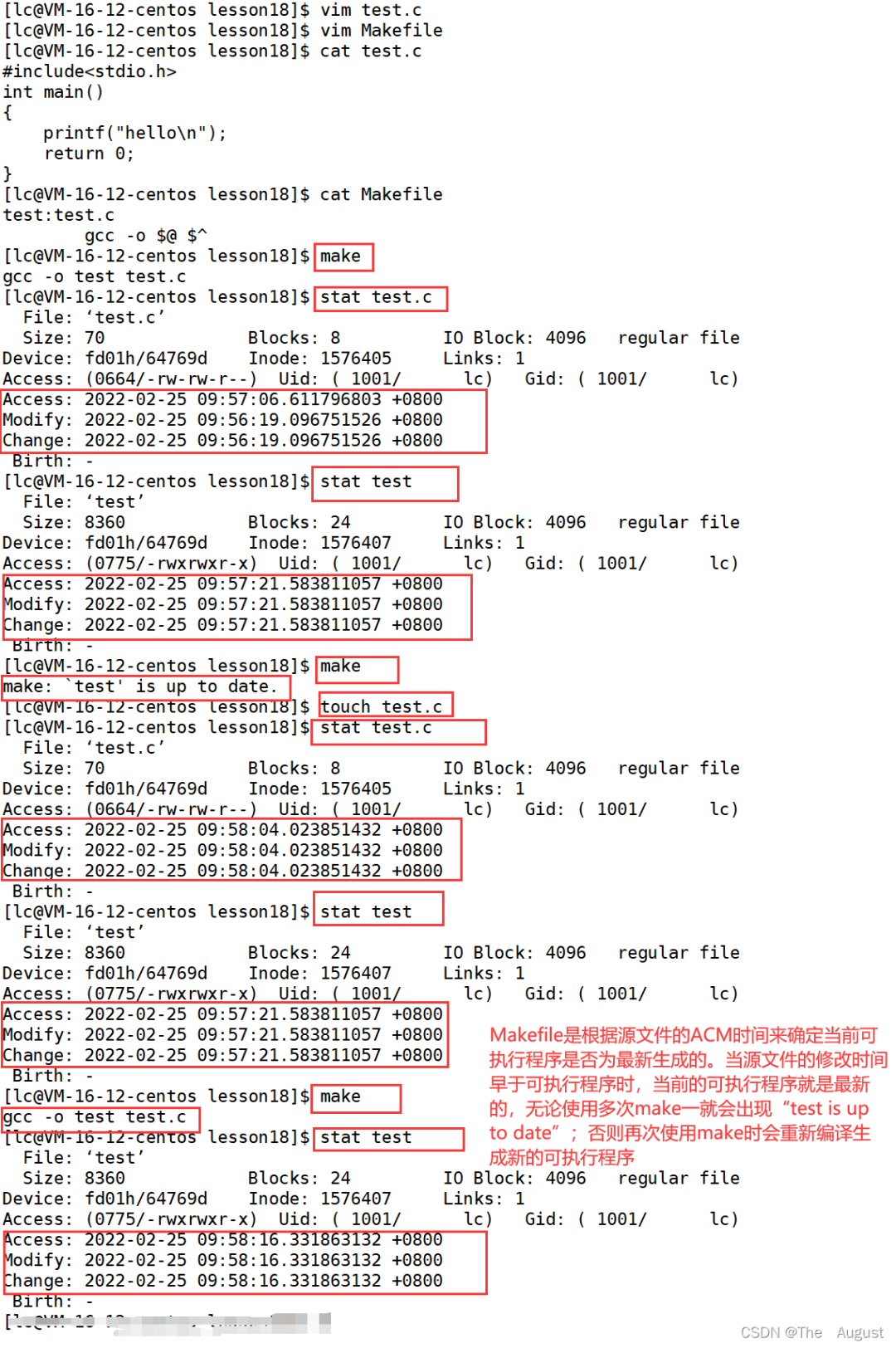
動態(tài)庫和靜態(tài)庫
靜態(tài)庫與動態(tài)庫
使用頂尖的工程師寫的代碼是為了開發(fā)效率和魯棒性(健壯性)
使用頂尖的工程師寫的功能一般通過庫、開源代碼、基本的網(wǎng)絡功能調用(各種網(wǎng)絡接口、語音識別)
庫分為動態(tài)庫和靜態(tài)庫
庫的命名:取消前綴 lib,去掉. 之后的內(nèi)容,剩下的就是庫的名字
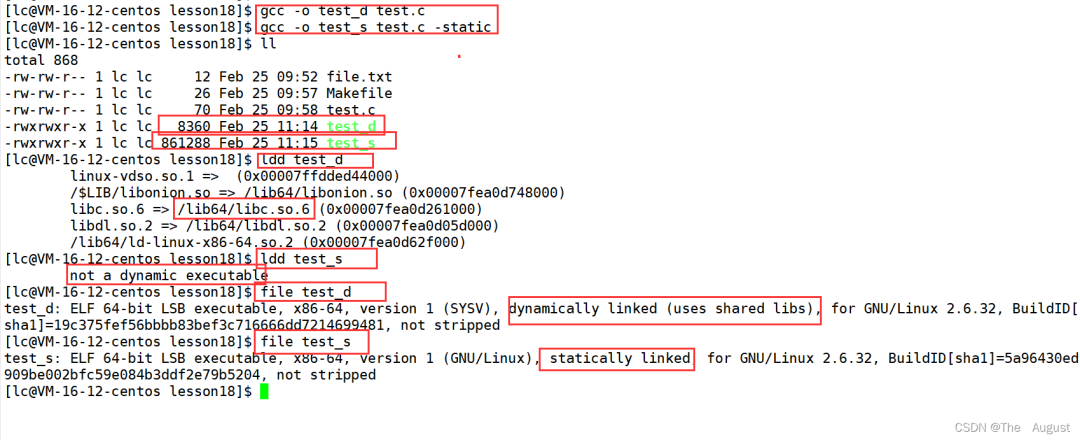
生成可執(zhí)行程序的方式有兩種:動態(tài)鏈接、靜態(tài)鏈接
 注:
注:
ldd 可以列出一個程序所需要得動態(tài)鏈接庫;file 命令用于辨識文件類型
Linux 中,默認情況下形成的可執(zhí)行程序是動態(tài)鏈接的
將庫中的我的可執(zhí)行程序中使用的二進制代碼,拷貝進我的可執(zhí)行程序中——靜態(tài)鏈接
一般為了更好的支持開發(fā),第三方庫或者語言庫都必須提供兩個庫,一個叫做靜態(tài)庫,一個叫做動態(tài)庫,方便程序員根據(jù)需要進行可執(zhí)行程序的生成
動態(tài)鏈接的特點:體積小、節(jié)省資源(磁盤、內(nèi)存),依賴庫,一旦丟失可執(zhí)行程序不可執(zhí)行
靜態(tài)鏈接的特點:體積大、浪費資源(磁盤、內(nèi)存),不依賴庫,庫丟失,可執(zhí)行程序不受影響
總結:
靜態(tài)庫(.a):程序在編譯鏈接的時候把庫的代碼鏈接到可執(zhí)行文件中。程序運行的時候將不再需要靜態(tài)庫
動態(tài)庫(.so):程序在運行的時候才去鏈接動態(tài)庫的代碼,多個程序共享使用庫的代碼。
一個與動態(tài)庫鏈接的可執(zhí)行文件僅僅包含它用到的函數(shù)入口地址的一個表,而不是外部函數(shù)所在目標文件的整個機器碼
在可執(zhí)行文件開始運行以前,外部函數(shù)的機器碼由操作系統(tǒng)從磁盤上的該動態(tài)庫中復制到內(nèi)存中,這個過程稱為動態(tài)鏈接(dynamic linking)
動態(tài)庫可以在多個程序間共享,所以動態(tài)鏈接使得可執(zhí)行文件更小,節(jié)省了磁盤空間。操作系統(tǒng)采用虛擬內(nèi)存機制允許物理內(nèi)存中的一份動態(tài)庫被要用到該庫的所有進程共用,節(jié)省了內(nèi)存和磁盤空間
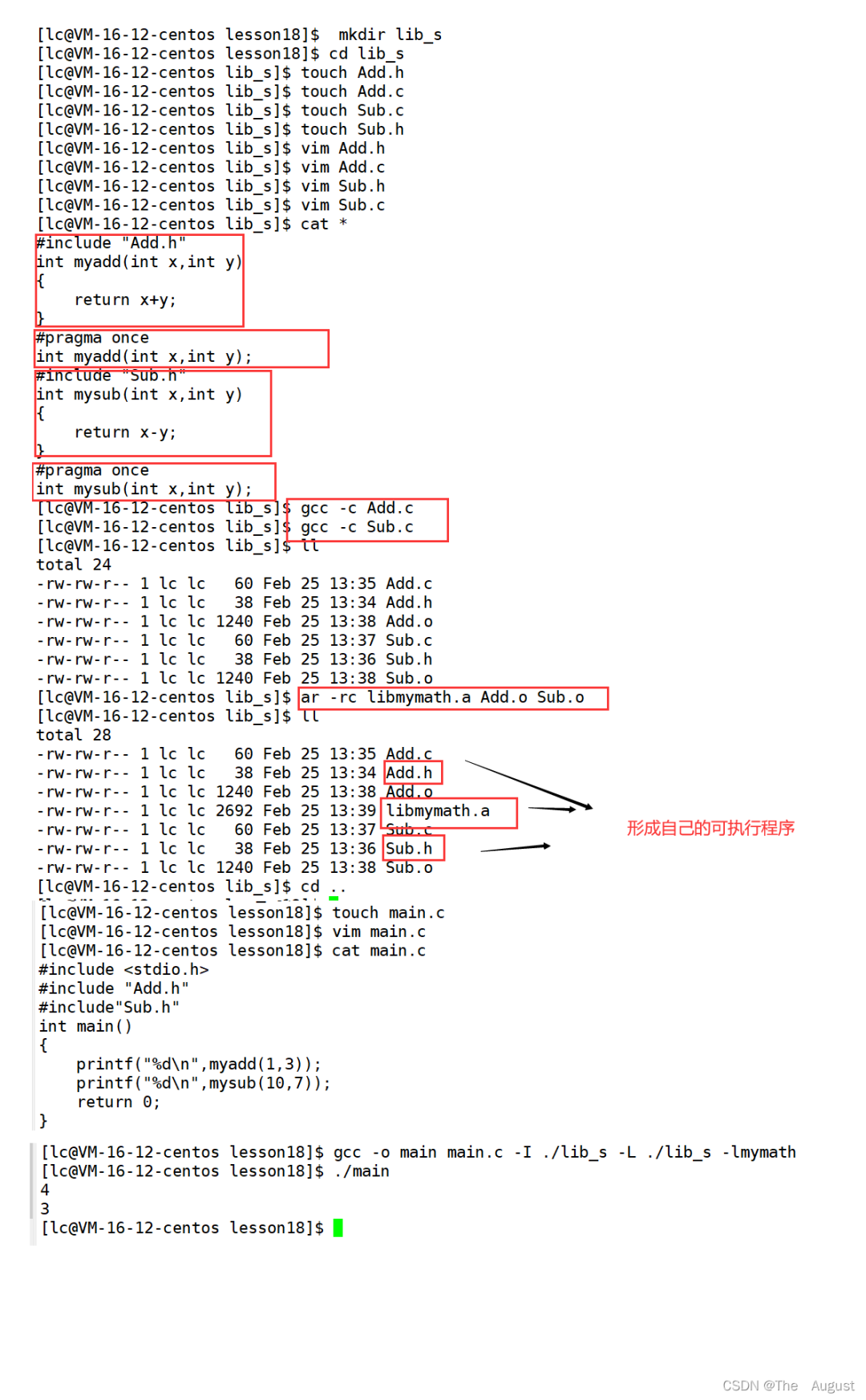
生成靜態(tài)庫
?
[root@localhost?linux]#?ls add.c?add.h?main.c?sub.c?sub.h [root@localhost?linux]#?gcc?-c?add.c?-o?add.o [root@localhost?linux]#?gcc?-c?sub.c?-o?sub.o 生成靜態(tài)庫 [root@localhost?linux]#?ar?-rc?libmymath.a?add.o?sub.o? ar是gnu歸檔工具,rc表示(replace?and?create) 查看靜態(tài)庫中的目錄列表 [root@localhost?linux]#?ar?-tv?libmymath.a? rw-r--r--?0/0?1240?Sep?15?16:53?2017?add.o rw-r--r--?0/0?1240?Sep?15?16:53?2017?sub.o t:列出靜態(tài)庫中的文件 v:verbose?詳細信息 [root@localhost?linux]#?gcc?main.c?-I?-L.?-lmymath -L?指定庫路徑 -I?指定頭文件路徑 -l?指定庫名 測試目標文件生成后,靜態(tài)庫刪掉,程序照樣可以運行
?
注:
-I:告訴 gcc 除了默認路徑(/usr/include)以及當前路徑之外,在指定路徑下也找一下頭文件
-L:告訴 gcc 除了默認路徑 (/lib/ 、/lib64 、/lib64/libc*) 以及當前路徑之外,在指定路徑下也找一下庫文件
-l?庫名稱:具體鏈接哪個庫
C 語言編譯時直接編譯不用任何選項:
1.庫文件和頭文件在默認路徑下 gcc 能找到
2.gcc 編譯 C 語言代碼默認應該鏈接 libc
當自己的可執(zhí)行程序編譯時不想用這些選項:將頭文件和庫文件分別拷貝到默認路徑下——庫的安裝(第三方庫)(使用時必須帶上 - l 庫名稱) 當只有靜態(tài)庫時,沒有動態(tài)庫,用 gcc 編譯(不加 - static)會直接用靜態(tài)鏈接生成可執(zhí)行程序
補充:
庫搜索路徑:
從左到右搜索 - L 指定的目錄。
由環(huán)境變量指定的目錄 (LIBRARY_PATH)
由系統(tǒng)指定的目錄
/usr/lib
/usr/local/lib
生成動態(tài)庫
shared: 表示生成共享庫格式
fPIC:產(chǎn)生位置無關碼 (position independent code)
庫名規(guī)則:libxxx.so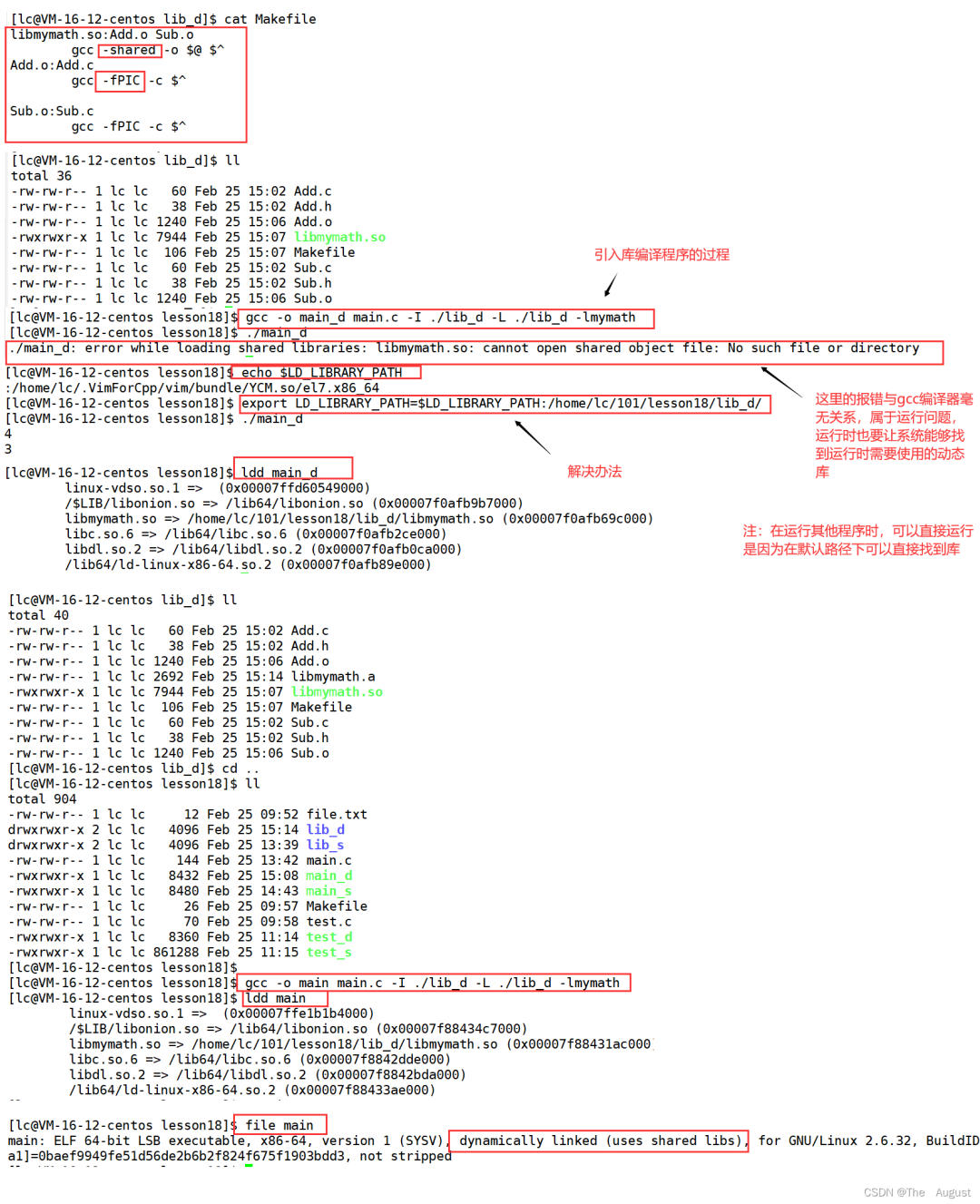
補充:
動態(tài)庫被加載在內(nèi)存中,可以供多個使用庫的程序共享映射到自己的虛擬地址空間使用,因此可以減少頁面交換以及降低內(nèi)存中代碼冗余,并且因為與源程序模塊分離,因此開發(fā)模式比較好
加載動態(tài)庫的程序運行速度相對較慢,因為動態(tài)庫運行時加載,映射到虛擬地址空間后需要重新根據(jù)映射起始地址計算函數(shù) / 變量地址
靜態(tài)庫會被添加為程序的一部分進行使用
動態(tài)庫可用節(jié)省內(nèi)存和磁盤空間
靜態(tài)庫重新編譯,需要將應用程序重新編譯
運行動態(tài)庫
1.拷貝. so 文件到系統(tǒng)共享庫路徑下, 一般指 / usr/lib?
2.更改 LD_LIBRARY_PATH(當系統(tǒng)重啟時使用之前添加的是無效的,應重新添加)
?
export?LD_LIBRARY_PATH=$LD_LIBRARY_PATH:路徑
?
3.ldconfig 配置 / etc/ld.so.conf.d/,ldconfig 更新
 ?
?
?















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論