 電子發燒友App
電子發燒友App


背景
Linux 具有功能豐富的網絡協議棧,并且兼顧了非常優秀的性能。但是,這是相對的。單純從網絡協議棧各個子系統的角度來說,確實做到了功能與性能的平衡。不過,當把多個子系統組合起來,去滿足實際的業務需求,功能與性能的天平就會傾斜。
容器網絡就是非常典型的例子,早期的容器網絡,利用 bridge、netfilter + iptables (或lvs)、veth等子系統的組合,實現了基本的網絡轉發;然而,性能卻不盡如人意。原因也比較明確:受限于當時的技術發展情況,為了滿足數據包在不同網絡 namespace 之間的轉發,當時可以選擇的方案只有 bridge + veth 組合;為了實現 POD 提供服務、訪問 NODE 之外的網絡等需求,可以選擇的方案只有 netfilter + iptables(或 lvs)。這些組合的技術方案增加了更多的網絡轉發耗時,故而在性能上有了更多的損耗。
然而,eBPF 技術的出現,徹底改變了這一切。eBPF 技術帶來的內核可編程能力,可以在原有漫長轉發路徑上,制造一些“蟲洞”,讓報文快速到達目的地。針對容器網絡的場景,我們可以利用 eBPF,略過 bridge、netfilter 等子系統,加速報文轉發。
下面我們以容器網絡為場景,用實際數據做支撐,深入分析 eBPF 加速容器網絡轉發的原理。
網絡拓撲
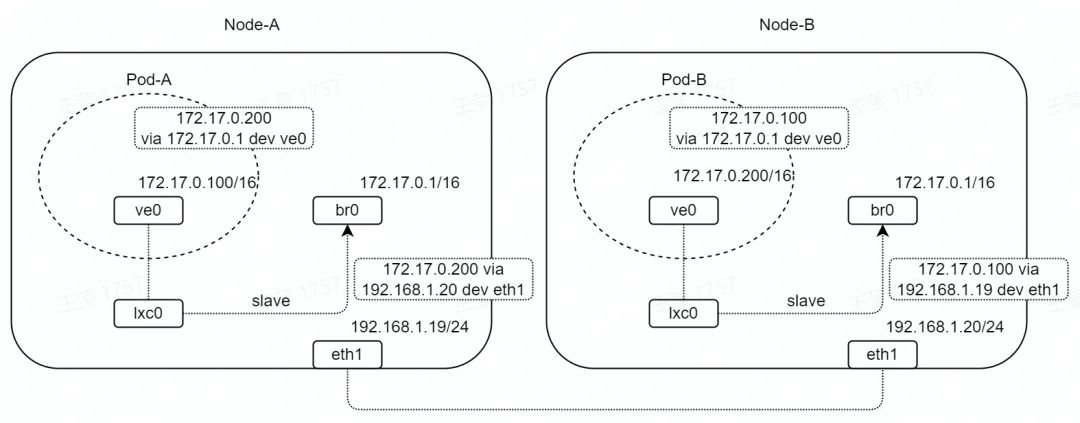
如圖,兩臺設備 Node-A/B 通過 eth1 直連,網段為 192.168.1.0/24。
Node-A/B 中分別創建容器 Pod-A/B,容器網卡名為 ve0,是 veth 設備,網段為172.17.0.0/16。
Node-A/B 中分別創建橋接口 br0,網段為 172.17.0.0/16,通過 lxc0(veth 設備)與 Pod-A/B 連通。
在 Node、Pod 網絡 namespace 中,分別設置靜態路由;其中,Pod 中靜態路由網關為 br0,Node 中靜態路由網關為對端 Node 接口地址。
為了方便測試與分析,我們將 eth1 的網卡隊列設置為 1,并且將網卡中斷綁定到 CPU0。
# ethtool -L eth1 combined 1
# echo 0 > /proc/irq/$(cat /proc/interrupts | awk -F ':' '/eth1/ {gsub(/ /,""); print $1}')/smp_affinity_list
bridge
bridge + veth 是容器網絡最早的轉發模式,我們結合上面的網絡拓撲,分析一下網絡數據包的轉發路徑。
在上面網絡拓撲中,eth1 收到目的地址為 172.17.0.0/16 網段的報文,會經過路由查找,走到 br0 的發包流程。
br0 的發包流程,會根據 FDB 表查找目的 MAC 地址歸屬的子接口,如果沒有查找到,就洪泛(遍歷所有子接口,發送報文);否則,選擇特定子接口,發送報文。在本例中,會選擇 lxc0 接口,發送報文。
lxc0 口是 veth 口,內核的實現是 veth 口發包,對端(peer)的 veth 口就會收包。在本例中,Pod-A/B 中的 ve0 口會收到報文。
至此,完成收包方向的主要流程。
當報文從 Pod-A/B 中發出,會先在 Pod 的網絡 namespace 中查找路由,假設流量從 Pod-A 發往 Pod-B,那么會命中我們之前設置的靜態路由:172.17.0.200 via 172.17.0.1 dev ve0,最終報文會從 ve0 口發出,目的 MAC 地址為 Node-A 上面 br0 的地址。
ve0 口是 veth 口,和收包方向類似,對端的 veth 口 lxc0 會收到報文。
lxc0 口是 br0 的子接口,由于報文目的 MAC 地址為 br0 的接口地址,報文會經過br0 口上送到 3 層協議棧處理。
3 層協議棧會查找路由,命中我們之前設置的靜態路由:172.17.0.200 via 192.168.1.20 dev eth1,最終報文會從 eth1 口發出,發給 Node-B。
至此,完成發包方向的主要流程。
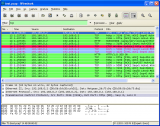
上面的流程比較抽象,我們用 perf ftrace 可以非常直觀地看到報文都經過了哪些內核協議棧路徑。
收包路徑
# perf ftrace -C0 -G '__netif_receive_skb_list_core' -g 'smp_*'
?
?
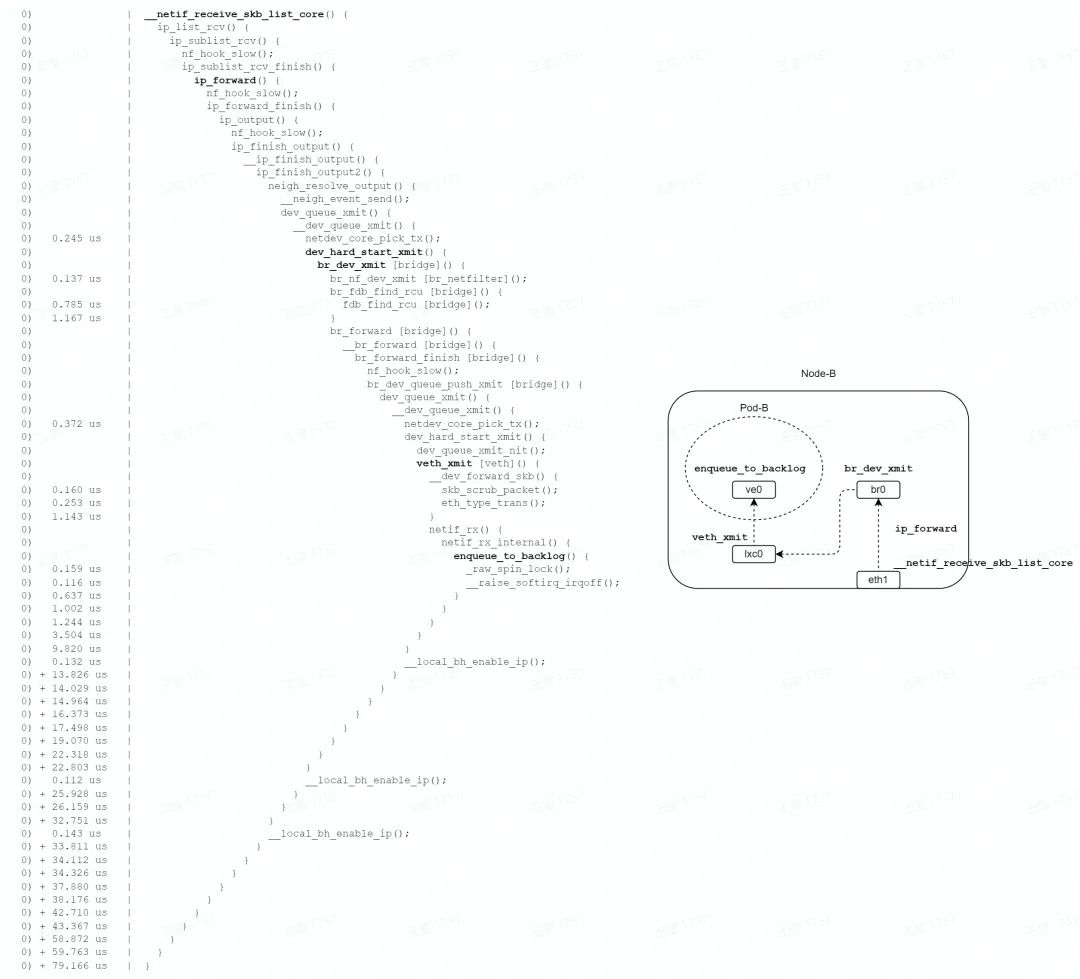
如圖,收包路徑主要經歷路由查找、橋轉發、veth 轉發、veth 收包等階段,中間多次經過 netfilter 的 hook 點。
最終調用 enqueue_to_backlog 函數,數據包暫存到每個 ?CPU 私有的 input_pkt_queue中,一次軟中斷結束,總耗時 79us。
但是報文并沒有到達終點,后續軟中斷到來時,會有機會調用 process_backlog,處理每個 CPU 私有的 input_pkt_queue,將報文丟入 Pod 網絡 namespace 的協議棧繼續處理,直到將報文送往 socket 的隊列,才算是到達了終點。
綜上,收包路徑要消耗2個軟中斷,才能將報文送達終點。
發包路徑
# perf ftrace -C0 -G '__netif_receive_skb_core' -g 'smp_*'
?
?
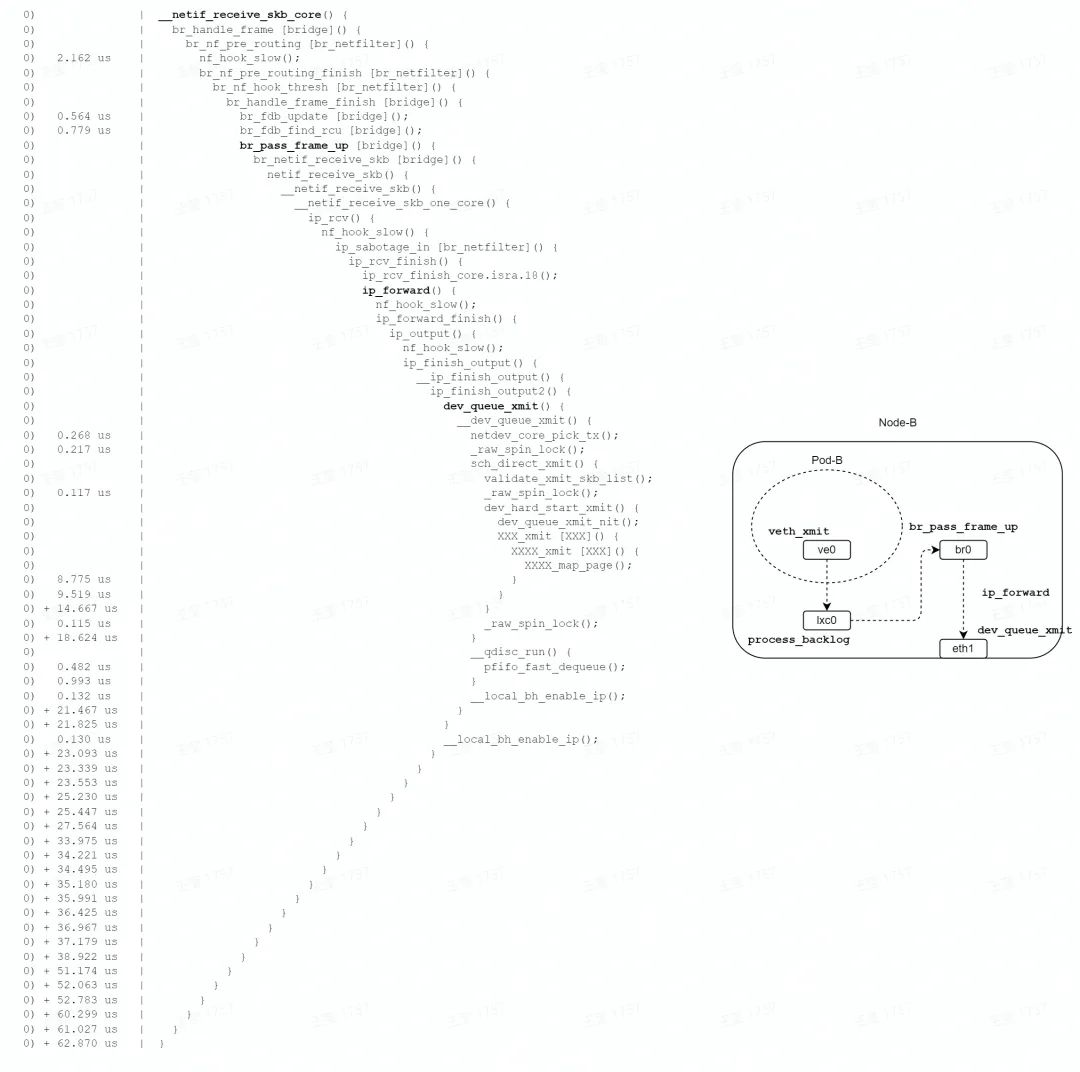
如圖,發包路徑主要經歷 veth 收包、橋上送、路由查找、物理網卡轉發等階段,中間多次經過 netfilter 的 hook點 。
最終調用網卡驅動發包函數,一次軟中斷結束,總耗時 62us。
分析
由 perf ftrace 的結果可以看出,利用 bridge + veth 的轉發模式,會多次經歷netfilter、路由等子系統,過程非常冗長,導致了轉發性能的下降。
我們接下來看一下,如何用eBPF跳過非必須的流程,加速網絡轉發。
TC redirect
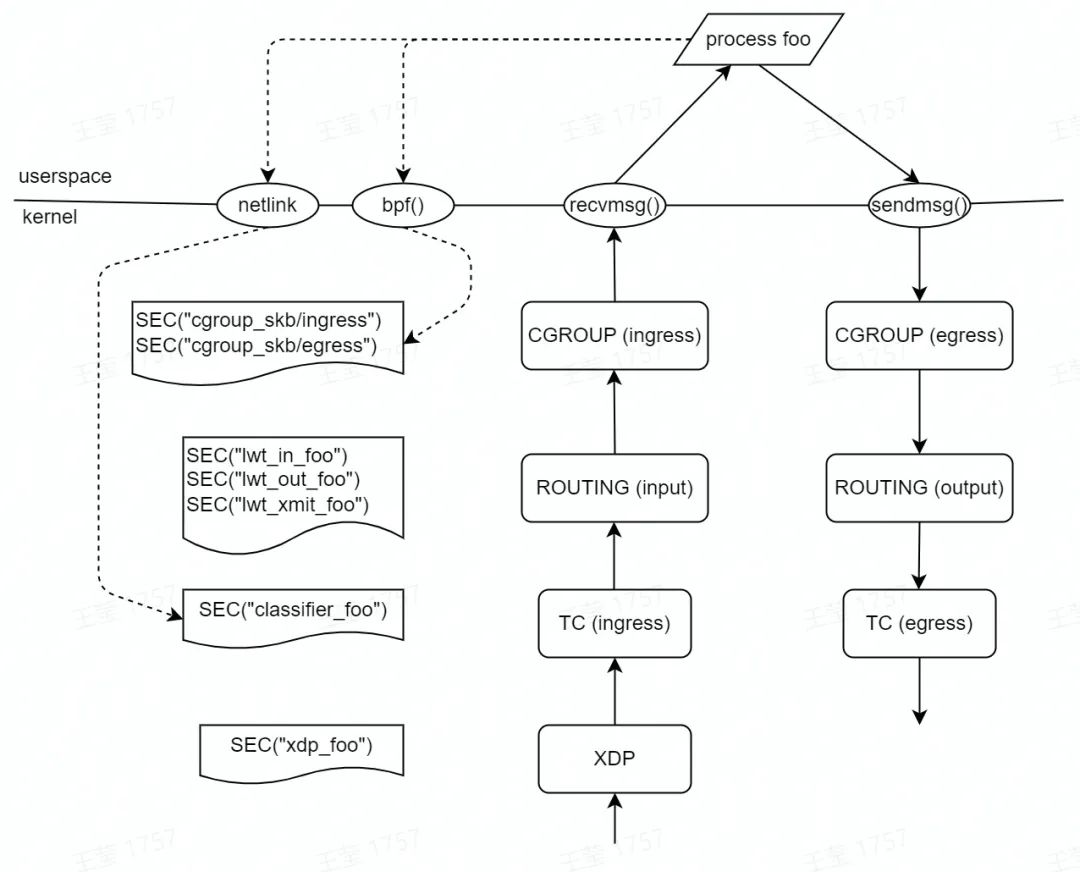
首先,我們先看一下內核協議棧主要支持的 eBPF hook 點,在這些 hook 點我們可以注入 eBPF 程序,實現具體的業務需求。
我們可以看到,與網絡轉發相關的 hook 點主要有 XDP(eXpress Data Path)、TC(Traffic Control)、LWT(Light Weight Tunnel)等。
針對于容器網絡轉發的場景,比較合適的 hook 點是 TC。因為 TC hook 點是協議棧的入口和出口,比較底層,eBPF 程序能夠獲取非常全面的上下文(如:socket、cgroup 信息等),這點是 XDP 沒有辦法做到的。而 LWT 則比較靠上層,報文到達這個 hook 點,會經過很多子系統(如:netfilter)。
加速收包路徑
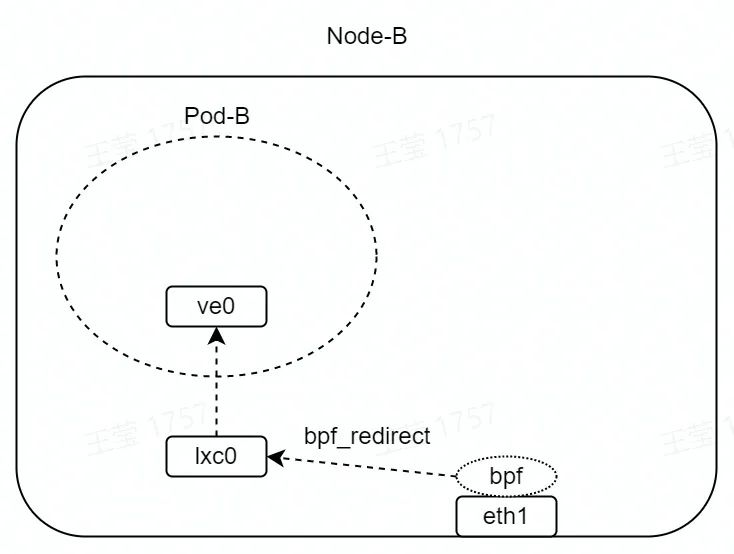
如圖,在 eth1 的 TC hook 點(收包方向)掛載 eBPF 程序。
# tc qdisc add dev eth1 clsact #?tc?filter?add?dev?eth1?ingress?bpf?da?obj?ingress_redirect.o?sec?classifier-redirect
eBPF 程序如下所示,其中 lxc0 接口的 index 為 2。bpf_redirect 函數為內核提供的 helper 函數,該函數會將 eth1 收到的數據包,直接轉發至 lxc0 接口。
SEC("classifier-redirect")
int cls_redirect(struct __sk_buff *skb) {
/* The ifindex of lxc0 is 2 */
return bpf_redirect(2, 0);
}
加速發包路徑
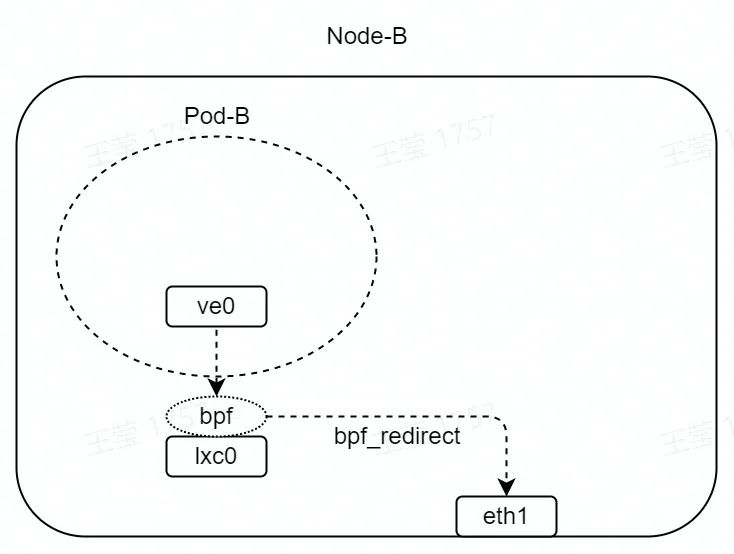
如圖,在 lxc0 的 TC hook 點(收包方向)掛載 eBPF 程序。
# tc qdisc add dev lxc0 clsact # tc filter add dev lxc0 ingress bpf da obj egress_redirect.o sec classifier-redirect
eBPF 程序如下所示,其中 eth1 接口的 index 為 1。bpf_redirect 函數會將 lxc0 收到的數據包,直接轉發至 eth1 接口。
SEC("classifier-redirect")
int cls_redirect(struct __sk_buff *skb) {
/* The ifindex of eth1 is 1 */
return bpf_redirect(1, 0);
}
分析
由上面的操作可以看到,我們直接跳過了 bridge 的轉發,利用 eBPF 程序,將 eth1 與 lxc0 之間建立了一個快速轉發通路。下面我們用 perf ftrace 看一下加速效果。
收包路徑
# perf ftrace -C0 -G '__netif_receive_skb_list_core' -g 'smp_*'
?
?
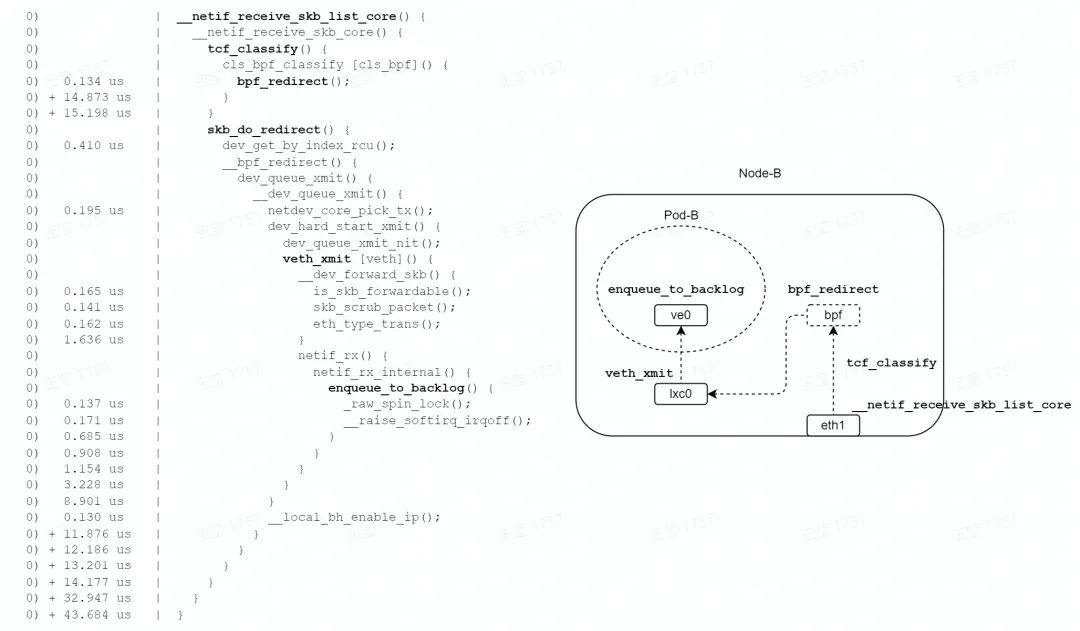
如圖,在收包路徑的 TC 子系統中,由 bpf_redirect 函數設置轉發信息( lxc0 接口 index),由 skb_do_redirect 函數直接調用了 lxc0 接口的 veth_xmit 函數;略過了路由、bridge、netfilter 等子系統。
最終調用 enqueue_to_backlog 函數,數據包暫存到每個 CPU 私有的input_pkt_queue 中,一次軟中斷結束,總耗時 43us;比 bridge 轉發模式的 79us,耗時減少約 45%。
但是,收包路徑仍然要消耗 2 個軟中斷,才能將報文送達終點。
發包路徑
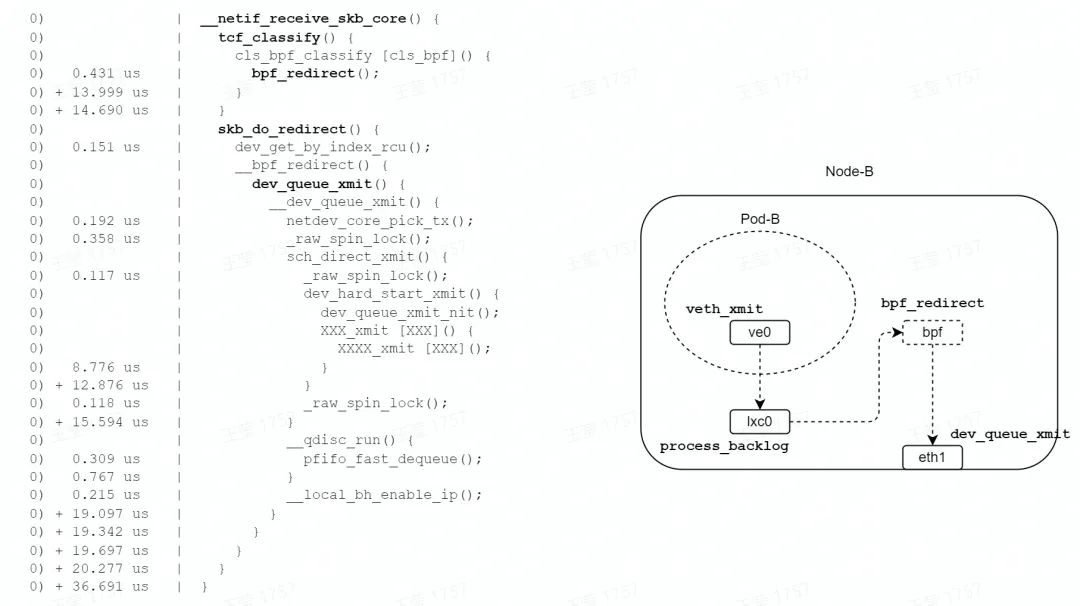
如圖,在發包路徑的 TC 子系統中,由 bpf_redirect 函數設置轉發信息( eth1 接口 index ),由 skb_do_redirect 函數直接調用了 eth1 接口的 xmit 函數;略過了路由、bridge、netfilter 等子系統。
最終調用網卡驅動發包函數,一次軟中斷結束,總耗時 36us,相比 bridge 模式 62us,耗時減少了約 42%。
小結
由 perf ftrace 的結果可以看出,利用 eBPF 在 TC 子系統注入轉發邏輯,可以跳過內核協議棧非必須的流程,實現加速轉發。收發兩個方向的耗時分別減少40%左右,性能提升非常可觀。
但是,我們在收包路徑上面仍然需要消耗 2 個軟中斷,才能將報文送往目的地。接下來我們看,如何利用 redirect peer 技術來優化這個流程。
TC redirect peer
加速收包路徑
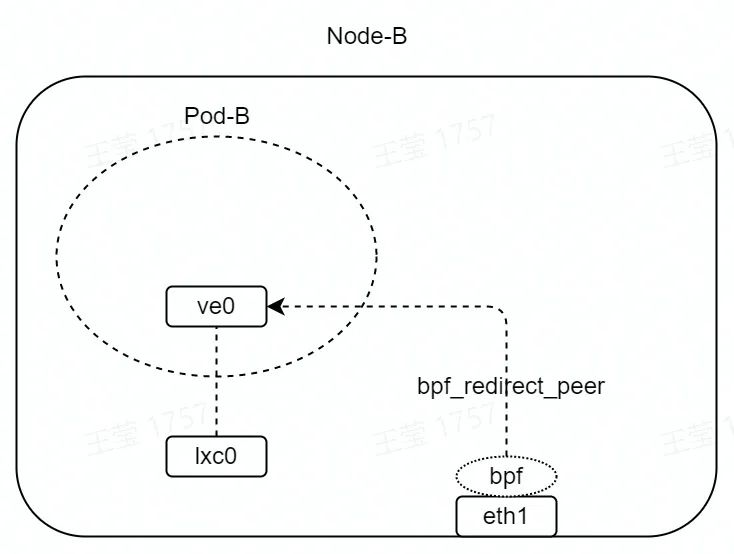
如圖,在 eth1 的 TC hook 點(收包方向)掛載 eBPF 程序。
# tc qdisc add dev eth1 clsact # tc filter add dev eth1 ingress bpf da obj ingress_redirect_peer.o sec classifier-redirect
eBPF 程序如下所示,其中 lxc0 接口的 index 為 2。bpf_redirect_peer 函數為內核提供的 helper 函數,該函數會將 eth1 收到的數據包,直接轉發至 lxc0 接口的 peer 接口,即 ve0 接口。
SEC("classifier-redirect")
int cls_redirect(struct __sk_buff *skb) {
/* The ifindex of lxc0 is 2 */
return bpf_redirect_peer(2, 0);
}
分析
由于 bpf_redirect_peer 會直接將數據包轉發到 Pod 網絡 namespace 中,避免了enqueue_to_backlog 操作,節省了一次軟中斷,性能理論上會有提升。我們用 perf ftrace 驗證一下。
# perf ftrace -C0 -G '__netif_receive_skb_list_core' -g 'smp_*
?
?
'
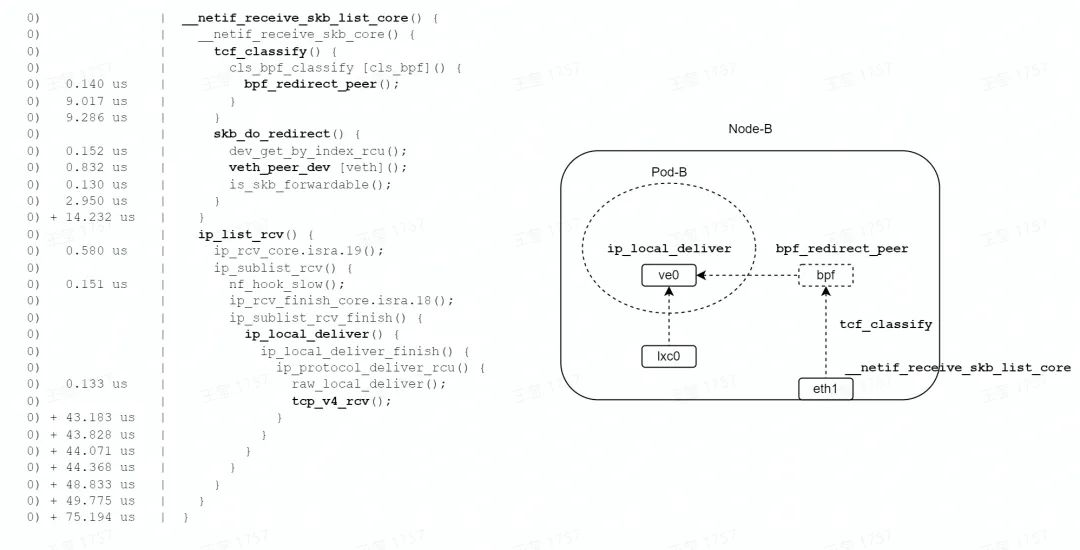
如圖,在收包路徑的 TC 子系統中,由 bpf_redirect_peer 函數設置轉發信息( lxc0 接口 index),由 skb_do_redirect 函數調用 veth_peer_dev 查找 lxc0 的 peer 接口,設置 skb->dev = ve0,返回 EAGAIN 給 tcf_classify 函數。
tcf_classify 函數會判斷 skb_do_redirect 的返回值,如果是 EAGAIN,則觸發 __netif_receive_skb_core 函數偽遞歸調用(通過 goto ?實現)。這樣,就非常巧妙地實現了網絡 namespace 的切換(在一次軟中斷上下文中)。
最終,通過 tcp_v4_rcv 函數到達報文的終點,整個轉發流程耗時 75us。從上面的函數耗時可以看到,ip_list_rcv 函數相當于 Pod 網絡 namespace 的耗時,本文描述的 3 種轉發模式,這段轉發路徑是相同的。所以,將 ip_list_rcv 函數耗時減去,轉發耗時約為 14us(這里還忽略了2次軟中斷調度的時間)。比 TC redirect 模式的 43us、bridge 模式的 79us,轉發耗時分別減少為 67%、82%。
總結
本文以容器網絡為例,對比了 3 種容器網絡轉發模式的性能差異。通過 perf ftrace 的函數調用關系以及耗時情況,詳細分析了導致性能差異的原因。我們演示了僅僅通過幾行 eBPF 代碼,就可以大大縮短報文轉發路徑,加速內核網絡轉發的效率,網絡轉發耗時最多可減少82%。
目前 eBPF 技術在開源社區非常流行,在 tracing、安全、網絡等領域有廣泛應用,我們可以利用這項技術做很多有意思的事情。感興趣的朋友可以加入我們,一起討論交流。
作者:王棟棟,字節跳動系統技術與工程團隊內核工程師,10年系統工程師工作經驗,關注Linux networking、eBPF等領域。目前在字節跳動,主要負責eBPF、內核網絡協議棧相關的開發工作。
編輯:黃飛
?



















 工商網監
工商網監
評論