 電子發(fā)燒友App
電子發(fā)燒友App


一、前言
操作系統上運作著各種應用、服務來滿足用戶需求,這些應用、服務實現的功能,通常都會依托一個個具體的線程來完成。在2022年的今天,無論是手機用戶還是平臺廠商,都不會容忍一臺手機的功能僅限于單一的通信功能。手機設備不比服務器,其多核架構體系上只存在8個cpu core,而執(zhí)行線程的數量卻輕而易舉超過8個。
每個cpu上該執(zhí)行什么線程,是由linux線程調度器來進行決策的,關于這一部分,網上已經有相當多的文章進行描述,因此本文在講解一些概念的基礎上,會分析為何當前的調度器仍滿足不了android系統的業(yè)務需求,我們?yōu)楹芜€需要做調度優(yōu)化。先拋出一張圖(圖1),大家感受下高負載下的cpu,是不是像極了正在工作的你,忙的不可開交!
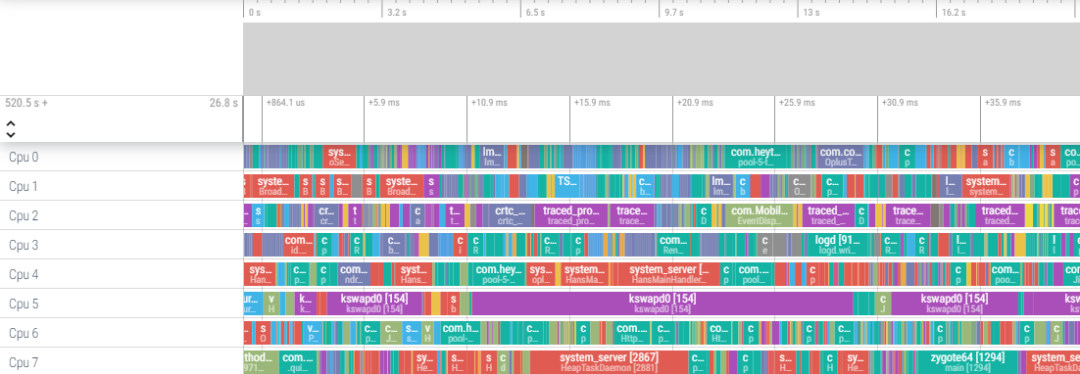
圖1 高負載系統運行狀態(tài)
擁有android開發(fā)經驗的伙伴,都清楚上面是通過google perfetto工具抓取的系統運行狀態(tài)圖示,8個核心全部跑滿,要達到這樣的現象并不困難,多啟動幾個應用,抓取下啟動時的狀態(tài)即可。那么問題來了,高負載的系統中,每個核心都不止運行一個線程,這必然導致線程執(zhí)行存在先后順序,每次執(zhí)行的時間也存在差異,那么,影響用戶體驗的線程能否及時執(zhí)行起來,能否得到足夠長的執(zhí)行時間,就顯得尤為重要,這也是調度團隊需要解決的問題。
二、線程調度器如何運作
實際的開發(fā)過程中,我們發(fā)現CFS調度類線程更容易出現調度問題,因此目前調度的優(yōu)化圍繞該調度類展開。下文的主要分析對象為CFS調度類,我們先從幾個基礎概念入手。
2.1 基礎調度概念
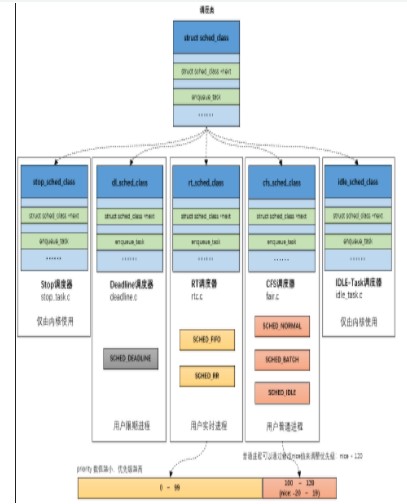
調度類(sched class):linux內核支持的調度類如圖2所示,每個線程歸屬于其中一種調度類,并遵循一種調度策略。android系統中,覆蓋面最廣的是CFS調度類fair_sched_class,其次是實時調度類中的rt_sched_class,我們喜歡將它們的線程分別成為cfs線程和rt線程。調度類存在優(yōu)先級,圖2從上到下羅列的調度類,優(yōu)先級從高至底。調度器總是從最高優(yōu)先級的調度類中開始檢索需要執(zhí)行的線程,同個調度類存在多個線程,則按具體的調度策略進行檢索。

圖2 linux支持調度類
調度類提供的實現接口用于定制具體的調度策略,開發(fā)人員也可按照相應的規(guī)則實現自己的調度類和調度策略。
運行隊列(runqueue):線程需要執(zhí)行時,會選取某個核,并放置到該核對應的運行隊列上,這個過程我們稱為入隊;當線程由于某種原因不再需要執(zhí)行時,將從運行隊列上摘除,對應的過程即出隊。不同調度策略,運行隊列的維護方式不同,如cfs線程的隊列維護是通過紅黑樹完成,而rt線程的隊列維護則是通過優(yōu)先級鏈表完成。
注:圖3為CFS調度類的實現,對應的接口作用如表1所示。

圖3 cfs調度策略實現接口
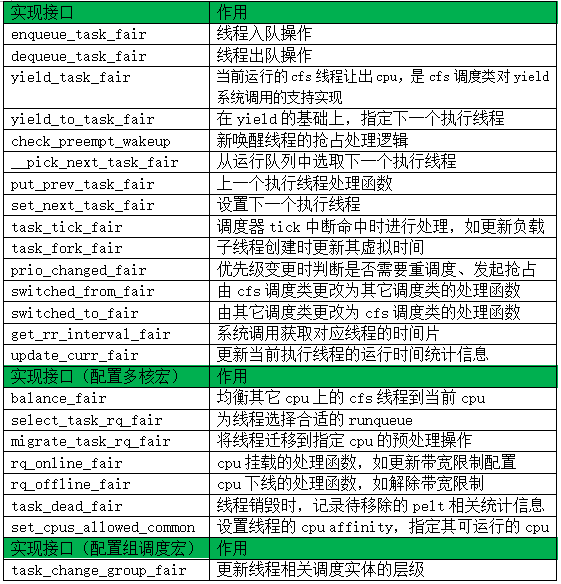
表1 cfs調度策略接口作用
調度延遲(sched latency):線程在運行隊列中的等待時間,這主要來自三個方面:從idle cpu喚醒需要等待器件做好準備;等待更高優(yōu)先級調度類線程執(zhí)行完成;等待同調度類的線程時間片耗盡。
時間片(sched slice):線程單次執(zhí)行的時長。CFS調度策略存在調度周期,理想情況下,調度周期內運行隊列的每個線程都將執(zhí)行一次,當運行隊列中只有一個線程時,將總是由該線程分得全部時間片。
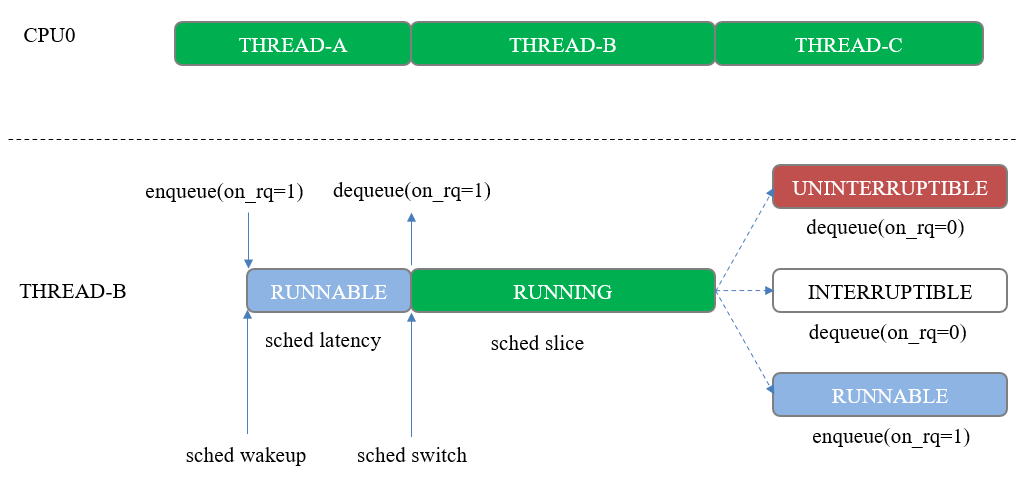
圖4 調度延遲與時間片
2.2 權重的作用
CFS調度策略就是青天大老爺,它來到linux內核,只做三件事:公平!公平!還是公平!其公平規(guī)則緊緊圍繞權重展開,理解了權重的作用,也就掌握了該調度策略的核心。
我們知道,每個線程都存在優(yōu)先級priority,記錄在其抽象結構體struct task_struct中,并提供相應的系統調用供用戶修改。實際上,android通過這些系統調用指定的是nice值,如表2所示。
文件路徑:system/core/libsystem/include/system/thread_defs.h
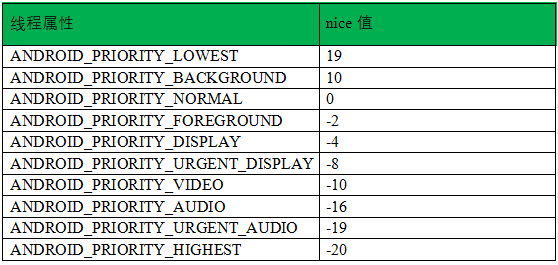
表2 android系統指定線程屬性值
nice值與priority之間存在一個轉換關系,如下:

nice值在一定程度上定義了該線程的重要程度,它是一個存在很久的概念。在CFS調度策略誕生之前,普通線程指定nice值后,調度器會賦予固定大小的時間片。nice值越小,優(yōu)先級越高,時間片越大。調度器總是讓高優(yōu)先級的線程優(yōu)先執(zhí)行完分配的時間片。這樣的做法存在兩個問題:
(1)低優(yōu)先級的調度延遲無法得到有效控制。由于總是讓高優(yōu)先級先執(zhí)行,那么調度延遲很大程度上取決于高優(yōu)先級線程的數量。
(2)固定時間片會導致低優(yōu)先級線程的執(zhí)行變得異常艱難。低優(yōu)先級線程本身時間片是非常小的,如果長時間的等待換來的是幾個ms的執(zhí)行,那它的任務將很難執(zhí)行完。
因此,內核引入CFS調度策略,保證公平調度。為此,調度器特地給nice值建立一一對應的權重值,如圖5所示,注意到,一共有40個權重等級,代表CFS調度類線程的nice范圍[-20, 19]:
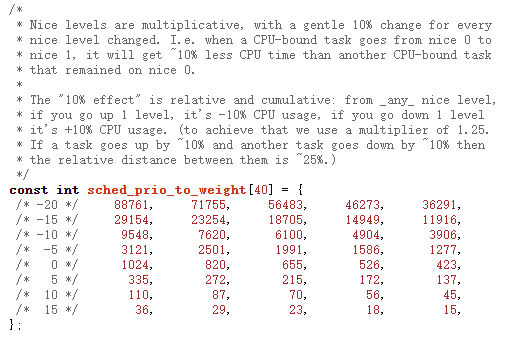
圖5 權重映射表
權重與nice值的計算關系如下:
weight = 1024 / (1.25 ^ nice)
權重的作用主要體現在兩個方面:
(1)時間片分配大小
時間片是按線程權重占比進行分配。如果兩個權重為1024(nice值為0)的線程放在同個核上,在沒有其它線程干擾的情況下,這兩個線程將平分整個調度周期。我們將掛在運行隊列的線程看做一個調度實體se(sched entity),則該se的時間片為:
slice = se->load.weight / cfs_rq->load
其中,se->load.weight代表該se的權重值,即圖5中nice值對應的數值(如果該se代表一個具體線程)。cfs_rq->load則代表當前運行隊列上所有調度實體的權重總和。注意,以上描述僅適用于未開啟組調度的情況,當開啟組調度后,情況會有些微不同,另有章節(jié)涉及。
(2)虛擬時間增長
調度實體的執(zhí)行時間,將按照權重反饋到虛擬時間的增長上。我們之前說過,CFS調度策略是通過一棵紅黑樹來進行維護的,虛擬時間越小的線程,將掛在紅黑樹的越左端,而最左端是普遍情況下調度器選取的下一個執(zhí)行對象。
對于一個權重為1024的線程,執(zhí)行2ms時,會原封不動地將這2個ms累加到虛擬時間上,但是,當它的權重增加到9548時(對應nice值為-10),虛擬時間只增加0.2ms。它們之間存在以下關系:
vruntime = exectime * (1024 / se->load.weight)
虛擬時間除了會影響調度實體在紅黑樹中的位置外,還影響喚醒搶占能否成功。如下:

傳遞的參數中,*curr代表當前正在執(zhí)行的調度實體,*se代表準備發(fā)起搶占的調度實體。此次搶占能否成功,取決于*curr的虛擬時間是否大于*se,當差值超過gran值時,則成功發(fā)起一次搶占。這樣設計的邏輯是,*curr通常是上一次調度器選擇時,紅黑樹中最左端的調度實體(即虛擬時間最小),在周期tick到來之前,它理應獲得的時間片可能還沒耗盡,此時如果直接允許喚醒的*se發(fā)起搶占,那對*curr是不公平的,那么,如果不發(fā)生搶占是否可行呢?這里運行隊列已經發(fā)生變化(一個新的task掛入隊列),需要盡快重新核算調度周期和時間片,如果等到周期tick命中當前任務再核算可能黃花菜都涼了,一個簡單的例子(圖6):
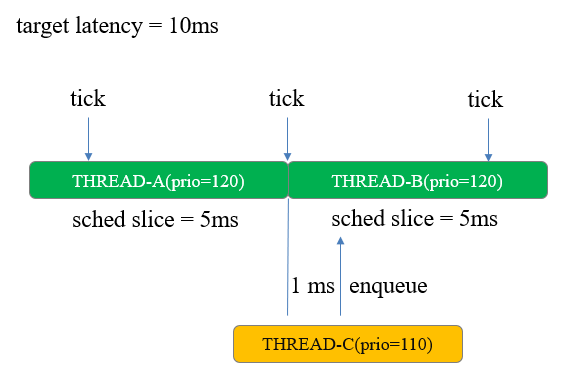
圖6 喚醒搶占
調度周期是10ms,任務A和B由于權重相同各分5ms,圖中第二個tick到來后, A時間片耗盡切換到B。1ms后,任務C喚醒。如果發(fā)生搶占,那么在喚醒之前的調度周期中,任務B就太可憐了,沒有跟A一樣耗盡時間片。如果不發(fā)生搶占,那么喚醒的C需要等待下一次tick到來,基于新的系統狀況來核算任務B的時間片(由于新增高優(yōu)先級任務,大概率會耗盡其時間片),對于C這個高優(yōu)先級任務而言,調度延遲又長了點。
總之,交給虛擬時間吧!值得注意的是,gran值依然是受權重值影響,*se的權重越大,gran值越小,其潛在含義是,如果喚醒線程優(yōu)先級高,那么gran值就小,從而更容易發(fā)生喚醒搶占)。如下:
gran = sysctl_sched_wakeup_granularity * (1024 / se->load.weight)
其中,sysctl_sched_wakeup_granularity是內核提供給用戶空間的一個可設置的數值。
三、如何進行優(yōu)化
3.1 存在的問題
在了解調度的基礎概念以及權重的作用后,我們應該明白調度器是如何運作的。CFS調度策略最讓人驚嘆的就是其基于虛擬時間的公平調度。假定調度周期為10ms,并且只有兩個線程位于同個運行隊列上,則:
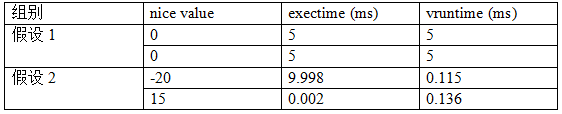
對于假設1,兩個線程的權重相同,平分10ms的調度周期,時間片均為5ms,對應的虛擬時間也相同;對于假設2,兩個線程的權重存在差異,時間片也產生很大的差別,但是將時間片轉換為虛擬時間,依然基本一致。注意,以上計算僅存在于理論中,實際上,由于存在調度時機,線程并不會在0.002ms后立刻發(fā)生切換。
這樣的“公平”設計很巧妙,但是依然不滿足手機這種強交互設備對及時性的需求。首先,執(zhí)行時間會不斷累積到虛擬時間上,這意味著,一個長時間執(zhí)行的線程,即便權重很高,它依然逃脫不了虛擬時間的不停增加,也就存在被其它長時間睡眠的喚醒線程搶占的可能性。其次,實際運行情況下,即便一個線程的權重很高,它始終不能分到一個周期內全部的時間片,并且分到的時間片也是有限的,當時鐘周期tick命中后,cpu使用權交給另一個線程,往往需要到下一個周期tick的調度點才能交換回來。
3.2 調度優(yōu)化點
從2.2節(jié)表2可以發(fā)現,原生android對系統中一些關鍵線程會進行優(yōu)化,比如將負責圖形顯示合成的surfaceflinger線程、hw-composer線程更改為實時調度類,能有效降低調度延遲,確保任務執(zhí)行完再調度出去。但系統中如果存在較多的實時線程是不合適的,實時線程并不講究“公平”,很可能會導致關鍵線程執(zhí)行互相受到影響,或者影響其它普通線程。因此,android主要還是通過提高CFS調度類線程的優(yōu)先級來進行改善,如音頻普通線程使用的nice值為-16,前臺交互應用的UI、Render線程使用的nice值為-10,system_server下一些關鍵持鎖線程nice值為-2或者-4。
從3.1節(jié)我們也可以知道,這樣的優(yōu)化在高負載下仍然會存在問題,現在系統中CFS調度類的線程對時延要求越來越高,比如120刷新率的界面,一幀合成時間就要求在8ms以內,也就兩個周期tick的時間長度(250HZ)。因此,我們可以從更底層的角度去對這些關鍵的CFS調度類線程做改善,比如做以下嘗試:
(1)喚醒搶占維度:關鍵線程喚醒時,我們是不是可以不考慮虛擬時間的評估,直接對當前非關鍵線程發(fā)起搶占呢;反之,非關鍵線程在喚醒時,則不允許對關鍵線程進行搶占。
(2)避開高優(yōu)先級調度類:關鍵線程在選核時,如果能避開更高優(yōu)先級調度類所在的核心,那么這一部分的調度延遲就可以避免。
(3)虛擬時間補償:原生內核其實已經存在此類做法,當線程長時間休眠時,并不會累加運行時間到其虛擬時間,線程喚醒后,將遠小于當前運行隊列的虛擬時間最小值。試想一下,如果我們不做任何改動,那該線程將長期霸占紅黑樹最左端的位置,這顯然是不合理的。因此在喚醒時,內核對其進行修正,使虛擬時間對齊到最小虛擬時間的基礎上,僅減少半個或1個調度周期時長作為補償。對于短時間休眠呢?短休眠的線程有可能其虛擬時間大于補償后的時間,那就仍維持現狀掛入。
對于關鍵線程,我們依然可以采用這個思路,喚醒時削減一定的虛擬時間作為補償,使其在接下來的幾次調度中占據優(yōu)勢。

圖7 原生內核對休眠線程的vruntime補償
四、組調度的引入
4.1 認識調度組
谷歌這兩年在推行通用內核鏡像(GKI),使用android系統的手機廠商,都必須確保設備能直接使用GKI鏡像,因此,廠商在內核修改這一塊存在許多限制。在kernel-5.4內核引入GKI1.0之后,我們發(fā)現谷歌使能組調度功能, CONFIG_FAIR_GROUP_SCHED配置為true,分組的情況如圖8所示,關鍵組別如下:
dev/cpuctl/tasks ---- root組
dev/cpuctl/top-app/tasks ---- top-app組(用戶交互組)
dev/cpuctl/foreground/tasks ---- 前臺組
dev/cpuctl/background/tasks ---- 后臺組
...
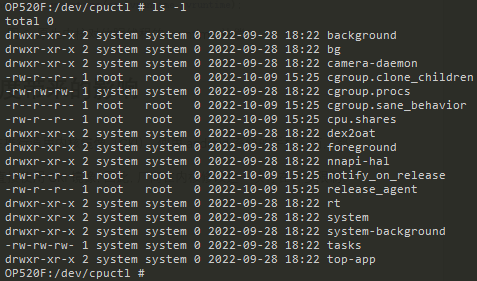
圖8 android使用組調度
組調度對CFS調度策略的影響是顯著的,原生內核提供這套機制,是為了將各類線程按group的形式進行資源分配,也就是將同一屬性的線程歸納到同一個group下,而android系統也順勢將各類應用進程、服務進程放入相應的組中,內核線程則默認放在root組(這一點很重要)。
4.2 公平分配規(guī)則的變動
我們在2.2節(jié)提到過調度實體的概念,當時是將每個線程看做一個調度實體,而調度實體是掛在運行隊列上的,引入調度組之后,調度實體就不一定是代表一個待執(zhí)行線程了,組調度為其建立起層級結構,如圖9所示。
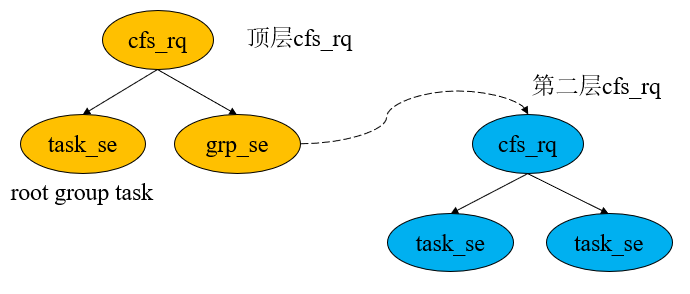
圖9 組調度建立起層級結構
在頂層的cfs_rq上,掛載兩個調度實體,其中一個為task級別的se,屬于root group,你可以把它當成某個內核線程,它的pid號記錄在“dev/cpuctl/tasks”中,另一個為group級別的se,代表某個調度組在當前cpu上的調度實體,比如前臺組“foreground”。聰明的你已經發(fā)現,group的se擁有自己的運行隊列,屬于第二層的cfs_rq,其上掛載該組在當前cpu上的線程,記錄在“dev/cpuctl/foreground/tasks”中。
層級結構引入后,時間片的分配規(guī)則也隨之產生變化。我們之前提到,一個調度周期會按當前運行隊列各個調度實體的權重占比進行分配,但層級結構需要注意的分配規(guī)則變動有兩個:
(1)調度周期的分配自上而下。假如我們給定調度周期為10ms,那么,這10個ms將從頂層的cfs_rq開始分配,分配依然是按se的權重占比劃分。我們假定頂層cfs_rq底下的兩個se(task級別和group級別)各自分得5ms,那么group se的5個ms,將繼續(xù)往下一層分配給其維護的第二層cfs_rq的task se們。
(2)group級別se的權重不再與nice值掛鉤。我們之前提到,task級別的se,即具體某一個線程,可以通過調節(jié)nice值更改其權重,進而影響時間片的分配、虛擬時間的累加。然而,group se下面維護的cfs_rq,可能存在多個task se,難道是將這些task se的權重累加嗎?顯然不是這樣的,linux的設計總是統一而優(yōu)雅,對于一個group se,也有其與權重掛鉤的“nice”值。
我們注意到,圖8中存在一個參數“cpu.shares”。share值即代表當前group級別se的權重,它并不受其子task se的影響,這個值在android平臺默認是1024。你也可以在其他group目錄如“dev/cpuctl/foreground/”中發(fā)現它的存在。
4.3 帶來的問題
受到4.2節(jié)(1)的影響,我們對某個task se進行虛擬時間上的補償優(yōu)化,意義已經不大,因為如果你的task se是掛在某個group的cfs_rq下,那么這個做法只會讓task在group所屬的cfs_rq中存在優(yōu)勢,而要讓它優(yōu)先得到執(zhí)行,調度器必須得先在頂層的cfs_rq中選中這個group se才行。那對group se做虛擬時間補償如何?這樣也不行,相當于group底下的所有子task se都會受益,并且你還不能確保目標task能優(yōu)先得到執(zhí)行。
受4.2節(jié)(2)的影響,nice值的作用在不同層級的cfs_rq中表現就不一樣了。我們之前說到group se的權重即share值,這樣的說法也不太準確,實際上,同個組的線程們極有可能運行在不同的cpu,所以內核同樣采取占比的方式來計算對應cpu上的group se的權重,公式如下:
ge->load.weight = tg->weight * grq->load.weight / SUM(grq->load.weight)
其中,ge->load.weight是當前cpu掛載的group se的權重;tg->weight就是我們提到的share值;grq->load.weight就是當前cpu掛載的group se,其維護的cfs_rq的權重,這個值是其上掛載的所有task se的權重總和;SUM(grq->load.weight)自然是group se在所有cpu的cfs_rq的權重總和。
感興趣的伙伴可以看下內核函數calc_group_shares(struct cfs_rq *cfs_rq),上面擁有非常詳細的注釋,這個函數用來更新group se的權重,它在線程入隊、出隊、周期tick命中以及用戶修改share值時,都會調用更新。
下面通過2個實驗來看下組調度帶來的影響。我們首先創(chuàng)建4個循環(huán)執(zhí)行的線程,命名為“root_0”、“root_1”、“top_0”、“top_1”。其中,“root_0”、“root_1”維持默認分組,也就是在root group中,它們入隊時,會直接掛在頂層的cfs_rq。“top_0”、“top_1”則放入新創(chuàng)建的tmp group中,避免收到其它線程的干擾,它們位于所在cpu的group se維護的cfs_rq。之后,我們將“root_0”、“top_0”綁定在cpu4,“root_1”、“top_1”綁定在cpu5。則調度實體的分布如圖10所示。
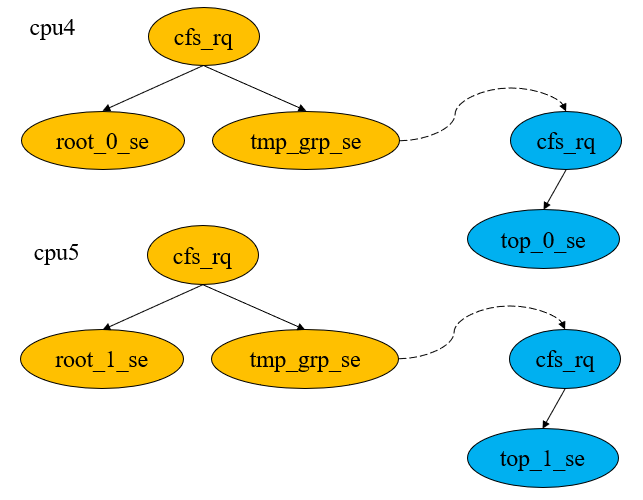
圖10 調度實體的分布
實驗一:4個線程nice值均為默認值0(對應權重為1024),root group和tmp group的share值均為默認值1024,調度周期target latency為10ms。“top_0”和“top_1”雖然處于不同的cpu,但它們都屬于tmp group。cpu4上“top_0”的時間片分配規(guī)則為:
(1)計算其所在group即tmp_grp_se的權重
tmp_grp_se.weight = tmp_grp.share * top_0_se.weight / (top_0_se.weight + top_1_se.weight) = 512
(2)頂層cfs_rq目前掛載兩個se,它們的時間片分別為:
root_0_se_slice = target_latency * root_0_se.weight / (root_0_se.weight + tmp_grp_se.weight) = 6.7 ms
tmp_grp_se_slice = target_latency * tmp_grp_se.weight / (root_0_se.weight + tmp_grp_se.weight) = 3.3 ms
(3)tmp_grp再將其配額分給其擁有的task se。由于其所屬的cfs_rq上只掛著“top_0”,因此top_0_se_slice為3.3 ms。
可以看到,雖然所有線程的nice值都是0,但是處于root group下的“root_0”卻拿到多出一倍的時間配額。
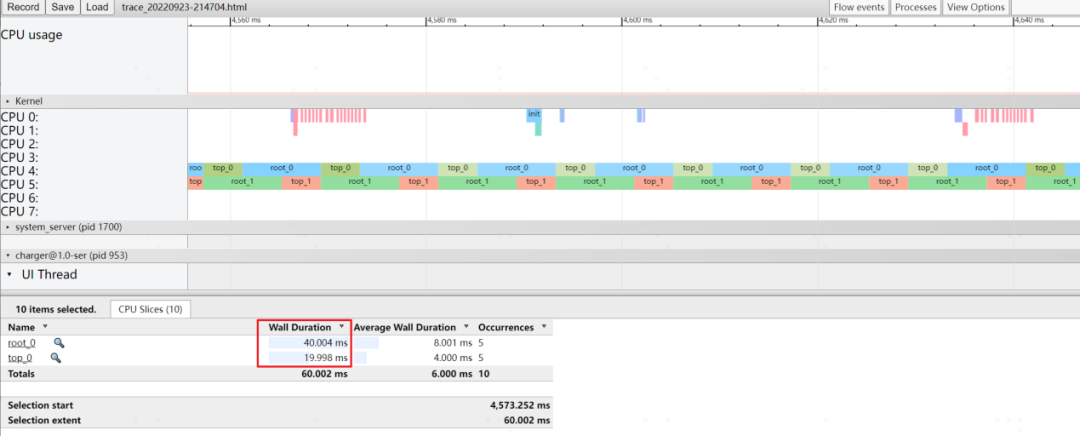
圖 11 實驗一運行結果
實驗二:在實驗一的基礎上,我們將“top_0”的nice值調整為-10,讓它成為高優(yōu)先級線程,其余條件不變。按照之前的處理步驟,在cpu4上,“root_0”拿到的時間片為5.3 ms,“top_0”拿到的時間片為4.7 ms,一個高優(yōu)先級的線程居然跟低優(yōu)先級的線程旗鼓相當!
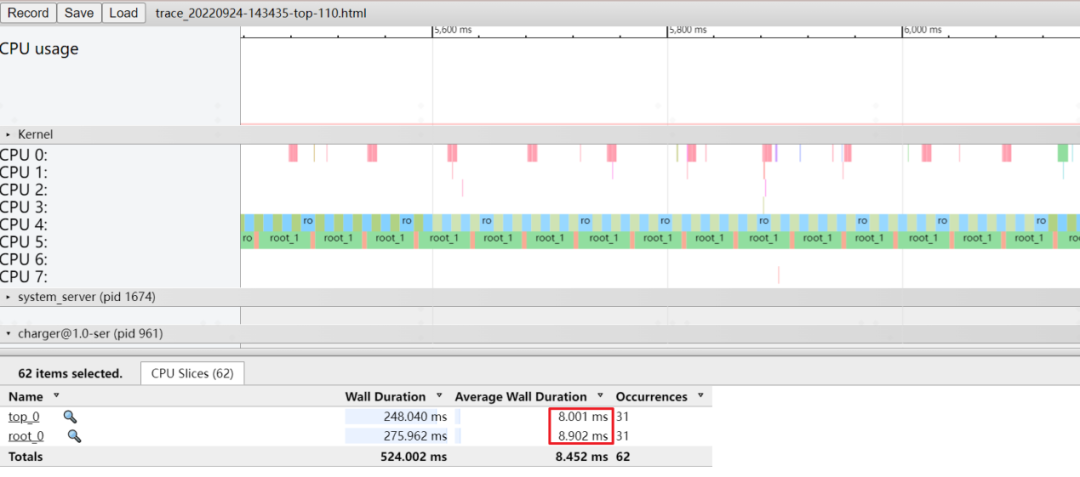
圖 12 實驗二運行結果
我們也可以通過調整share值來影響結果,在此不再演示。現在我們再回過來看下,CFS調度策略還公平嗎?其實從調度組的維度來看,還是公平的。這里我們難受的一點在于,root group的線程各自獨立,在計算權重時擁有很大優(yōu)勢,但實際上這些線程很少直接參與用戶圖形繪制、音頻輸入等業(yè)務。具體的業(yè)務線程又被android推入諸如top-app、foreground組,組內還包含其它不影響用戶體驗的線程,同個組的線程分散在不同的核上,引起組權重的重新分配,也就是說,一些關鍵業(yè)務線程的時間片分配會受到同組內其他不相關線程的影響;另一個點,android的業(yè)務設計上,不同組之間的線程可能會建立聯系,如app層對框架層的依賴,內核層的公共資源爭奪等,也就是說,一些關鍵業(yè)務線程也會在某些特定場景下依賴其他組的線程,這些線程理論上在這個時刻更應該看做是同個組。總之,目前調度組這樣的使用方式會帶來問題,僅從share值和nice值去調整,是很難達到目的。
五、結語
我們今天了解到權重在CFS調度策略中的重要地位,也了解到CFS調度策略存在的一些問題,包括引入組調度后產生的弊端。基于權重的“公平”,看起來并不能滿足手機場景對于關鍵線程的調度需求。如何保證關鍵線程的及時調度,同時又不餓死其它線程,或許還需要一種新的機制引入,至少目前來看,權重對這一塊的調節(jié)很有限。
參考文獻:
1、https://github.com/oppo-source/android_kernel_5.10_oppo_mt6983/
2、http://www.wowotech.net/sort/process_management
編輯:黃飛
?













 工商網監(jiān)
工商網監(jiān)
評論