 電子發燒友App
電子發燒友App


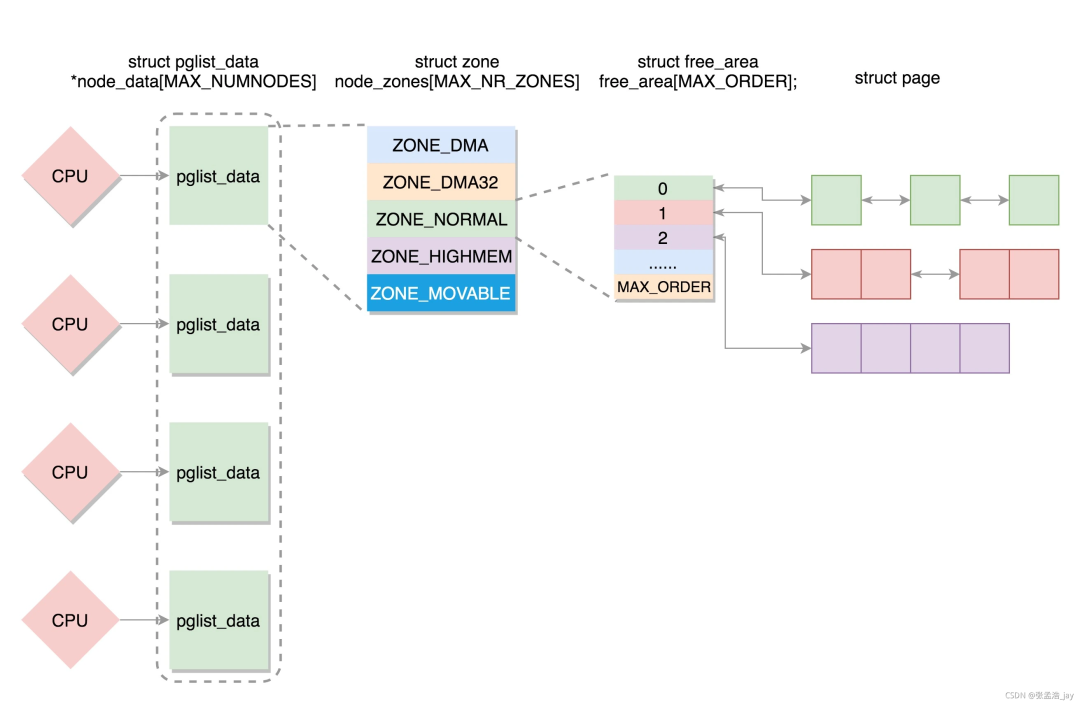
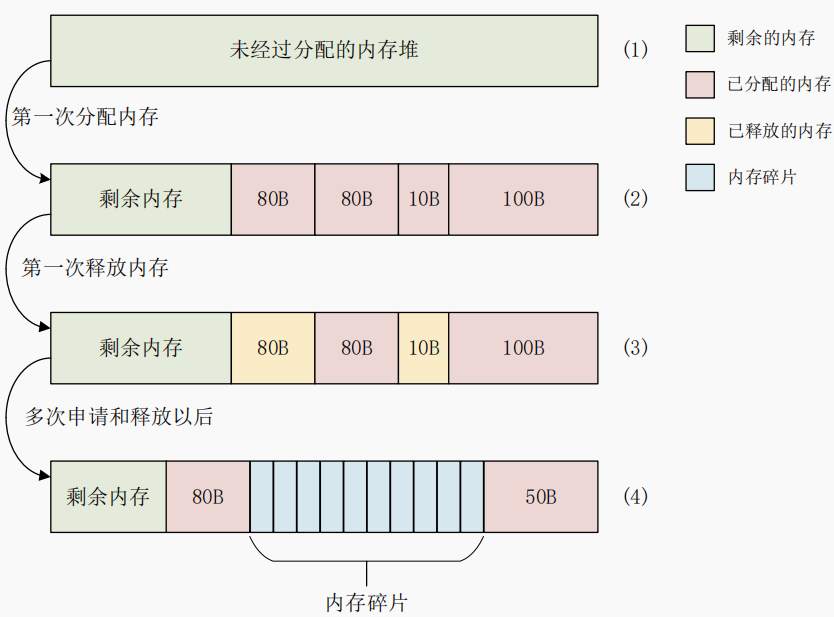
我們知道物理內存是以頁為單位進行管理的,每個內存頁大小默認是4K(大頁除外)。申請物理內存時,一般都是按順序分配的,但釋放內存的行為是隨機的。隨著系統運行時間變長后,將會出現以下情況:
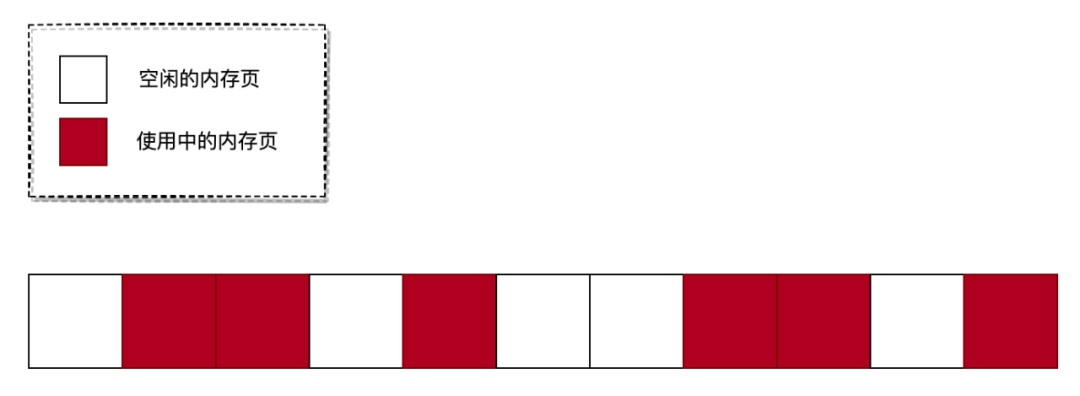
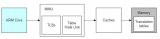
如上圖所示,當用戶需要申請地址連續的 3 個內存頁時,雖然系統中空閑的內存頁數量足夠,但由于空閑的內存頁相對分散,從而導致分配失敗。這些地址不連續的內存頁被稱為:內存碎片。
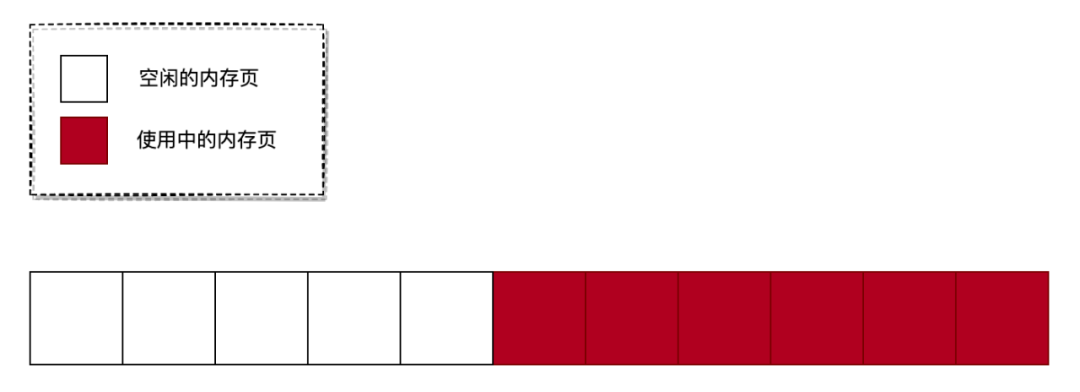
要解決這個問題也比較簡單,只需要把空閑的內存塊移動到一起即可。如下圖所示:
網絡上有句很有名的話:理想很美好,現實很骨感。
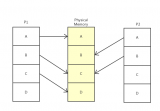
內存整理也是這樣,看起來很簡單,但實現起來就不那么簡單了。因為在內存整理后,需要修正進程的虛擬內存與物理內存之間的映射關系。如下圖所示:
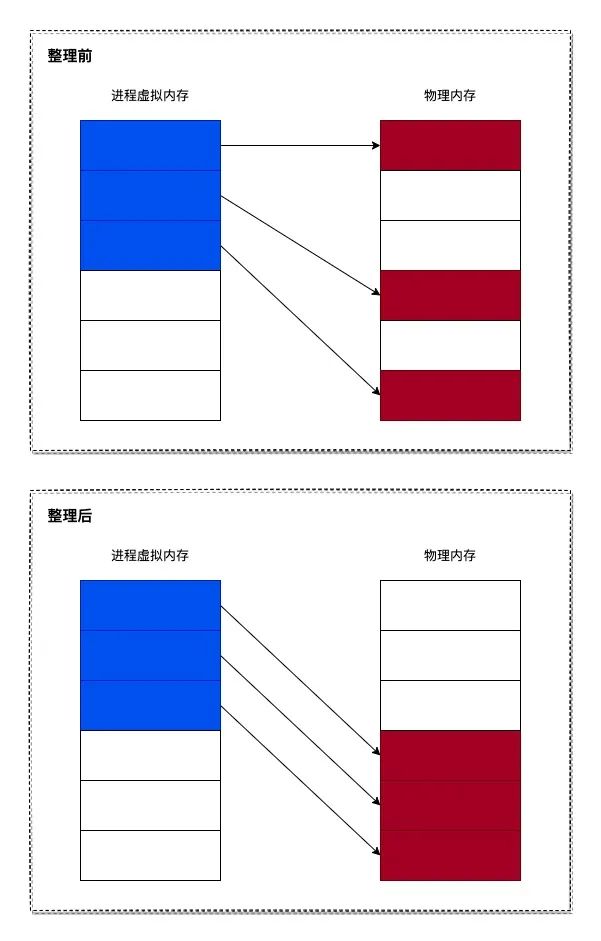
但由于 Linux 內核有個名為?內存頁反向映射?的功能,所以內存整理就變得簡單起來。
接下來,我們將會分析內存碎片整理的原理與實現。
內存碎片整理原理
內存碎片整理的原理比較簡單:在內存碎片整理開始前,會在內存區的頭和尾各設置一個指針,頭指針從頭向尾掃描可移動的頁,而尾指針從尾向頭掃描空閑的頁,當他們相遇時終止整理。下面說說內存隨便整理的過程(原理參考了內核文檔):
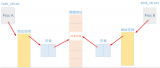
初始時內存狀態:
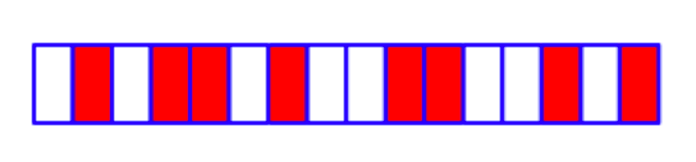
在上圖中,白色塊表示空閑的內存頁,而紅色塊表示已分配出去的內存頁。在初始狀態時,內存中存在多個碎片。如果此時要申請 3 個地址連續的內存頁,那么將會申請失敗。
內存碎片整理掃描開始:
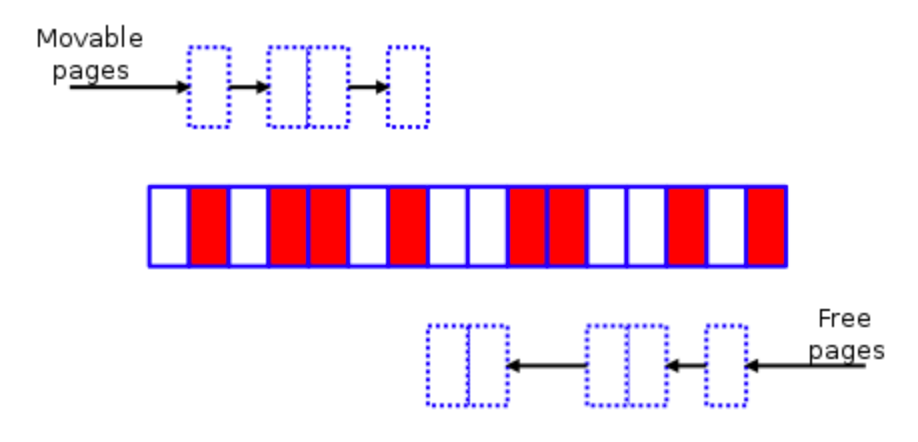
頭部指針從頭掃描可移動頁,而尾部指針從從尾掃描空閑頁。在整理時,將可移動頁的內容復制到空閑頁中。復制完成后,將可移動內存頁釋放即可。
最后結果:

經過內存碎片整理后,如果現在要申請 3 個地址連續的內存頁,就能申請成功了。
內存碎片整理實現
接下來,我們將會分析內存碎片整理的實現過程。
注:本文使用的是 Linux-2.6.36 版本的內存
1. 內存碎片整理時機
當要申請多個地址聯系的內存頁時,如果申請失敗,將會進行內存碎片整理。其調用鏈如下:
alloc_pages_node() └→?__alloc_pages() ???└→?__alloc_pages_nodemask() ??????└→?__alloc_pages_slowpath() ?????????└→?__alloc_pages_direct_compact()
當調用?alloc_pages_node()?函數申請多個地址連續的內存頁失敗時,將會觸發調用?__alloc_pages_direct_compact()?函數來進行內存碎片整理。我們來看看?__alloc_pages_direct_compact()?函數的實現:
static?struct?page?* __alloc_pages_direct_compact(gfp_t?gfp_mask,? ?????????????????????????????unsigned?int?order,? ?????????????????????????????struct?zonelist?*zonelist,? ?????????????????????????????enum?zone_type?high_zoneidx,? ?????????????????????????????nodemask_t?*nodemask,? ?????????????????????????????int?alloc_flags, ?????????????????????????????struct?zone?*preferred_zone, ?????????????????????????????int?migratetype,? ?????????????????????????????unsigned?long?*did_some_progress) { ????struct?page?*page; ????//?1.?如果申請一個內存頁,那么就沒有整理碎片的必要(這說明是內存不足,而不是內存碎片導致) ????if?(!order?||?compaction_deferred(preferred_zone)) ????????return?NULL; ????//?2.?開始進行內存碎片整理 ????*did_some_progress?=?try_to_compact_pages(zonelist,?order,?gfp_mask,?nodemask); ????if?(*did_some_progress?!=?COMPACT_SKIPPED)?{ ????????... ????????//?3.?整理完內存碎片后,繼續嘗試申請內存塊 ????????page?=?get_page_from_freelist(gfp_mask,?nodemask,?order,?zonelist,? ??????????????????????????????????????high_zoneidx,?alloc_flags,?preferred_zone,? ??????????????????????????????????????migratetype); ????????if?(page)?{ ????????????... ????????????return?page; ????????} ????????... ????} ????return?NULL; }
__alloc_pages_direct_compact()?函數是內存碎片整理的入口,其主要完成 3 個步驟:
先判斷申請的內存塊是否只有一個內存頁,如果是,那么就沒有整理碎片的必要(這說明是內存不足,而不是內存碎片導致)。
如果需要進行內存碎片整理,那么調用?try_to_compact_pages()?函數進行內存碎片整理。
整理完內存碎片后,調用?get_page_from_freelist()?函數繼續嘗試申請內存塊。
2. 內存碎片整理過程
由于內存碎片整理的具體實現在?try_to_compact_pages()?函數中進行,所以我們繼續來看看?try_to_compact_pages()?函數的實現:
unsigned?long try_to_compact_pages(struct?zonelist?*zonelist,?int?order,?gfp_t?gfp_mask, ?????????????????????nodemask_t?*nodemask) { ????... ????//?1.?遍歷所有內存區(由于內核會把物理內存分成多個內存區進行管理) ????for_each_zone_zonelist_nodemask(zone,?z,?zonelist,?high_zoneidx,?nodemask)?{ ????????... ????????//?2.?對內存區進行內存碎片整理 ????????status?=?compact_zone_order(zone,?order,?gfp_mask); ????????... ????} ????return?rc; }
可以看出,try_to_compact_pages()?函數最終會調用?compact_zone_order()?函數來進行內存碎片整理。我們只能進行來分析?compact_zone_order()?函數:
static?unsigned?long
compact_zone_order(struct?zone?*zone,?int?order,?gfp_t?gfp_mask)
{
????struct?compact_control?cc?=?{
????????.nr_freepages?=?0,
????????.nr_migratepages?=?0,
????????.order?=?order,
????????.migratetype?=?allocflags_to_migratetype(gfp_mask),
????????.zone?=?zone,
????};
????INIT_LIST_HEAD(&cc.freepages);
????INIT_LIST_HEAD(&cc.migratepages);
????return?compact_zone(zone,?&cc);
}
到這里,我們還沒有看到內存碎片整理的具體實現(調用鏈可真深啊 ^_^!),compact_zone_order()?函數也是構造了一些參數,然后繼續調用?compact_zone()?來進行內存碎片整理:
static?int?compact_zone(struct?zone?*zone,?struct?compact_control?*cc)
{
????...
????while?((ret?=?compact_finished(zone,?cc))?==?COMPACT_CONTINUE)?{
????????...
????????//?1.?收集可移動的內存頁列表
????????if?(!isolate_migratepages(zone,?cc))
????????????continue;
????????...
????????//?2.?將可移動的內存頁列表遷移到空閑列表中
????????migrate_pages(&cc->migratepages,?compaction_alloc,?(unsigned?long)cc,?0);
????????...
????}
????...
????return?ret;
}
在?compact_zone()?函數里,我們終于看到內存碎片整理的邏輯了。compact_zone()?函數主要完成 2 個步驟:
調用?isolate_migratepages()?函數收集可移動的內存頁列表。
調用?migrate_pages()?函數將可移動的內存頁列表遷移到空閑列表中。
這兩個函數非常重要,我們分別來分析它們是怎么實現的。
isolate_migratepages() 函數
isolate_migratepages()?函數用于收集可移動的內存頁列表,我們來看看其實現:
static?unsigned?long
isolate_migratepages(struct?zone?*zone,?struct?compact_control?*cc)
{
????unsigned?long?low_pfn,?end_pfn;
????struct?list_head?*migratelist?=?&cc->migratepages;
????...
????//?1.?掃描內存區所有的內存頁
????for?(;?low_pfn?lru,?migratelist);?
????????...
????????cc->nr_migratepages++;
????????...
????}
????...
????return?cc->nr_migratepages;
}
isolate_migratepages()?函數主要完成 5 個步驟,分別是:
掃描內存區所有的內存頁(與內存碎片整理原理一致)。
通過內存頁的編號獲取內存頁對象。
判斷內存頁是否可移動內存頁,如果不是可移動內存頁,那么就跳過。
將內存頁從 LRU 隊列中刪除,這樣可避免被其他進程回收這個內存頁。
添加到可移動內存頁列表中。
當完成這 5 個步驟后,內核就收集到可移動的內存頁列表。
migrate_pages() 函數
migrate_pages()?函數負責將可移動的內存頁列表遷移到空閑列表中,我們來分析一下其實現過程:
int?migrate_pages(struct?list_head?*from,?new_page_t?get_new_page,
??????????????????unsigned?long?private,?int?offlining)
{
????...
????for?(pass?=?0;?pass??2,?offlining);
????????????switch(rc)?{
????????????case?-ENOMEM:
????????????????goto?out;
????????????case?-EAGAIN:
????????????????retry++;
????????????????break;
????????????case?0:
????????????????break;
????????????default:
????????????????nr_failed++;
????????????????break;
????????????}
????????}
????}
????...
????return?nr_failed?+?retry;
}
migrate_pages()?函數的邏輯很簡單,主要完成 2 個步驟:
遍歷可移動內存頁列表,這個列表就是通過?isolate_migratepages()?函數收集的可移動內存頁列表。
調用?unmap_and_move()?函數將可移動內存頁遷移到空閑內存頁中。
可以看出,具體的內存遷移過程在?unmap_and_move()?函數中實現。我們來看看?unmap_and_move()?函數的實現:
static?int
unmap_and_move(new_page_t?get_new_page,?unsigned?long?private,
???????????????struct?page?*page,?int?force,?int?offlining)
{
????...
????//?1.?從內存區中找到一個空閑的內存頁
????struct?page?*newpage?=?get_new_page(page,?private,?&result);
????...
????//?2.?解開所有使用了當前可移動內存頁的進程的虛擬內存映射(涉及到內存頁反向映射)
????try_to_unmap(page,?TTU_MIGRATION|TTU_IGNORE_MLOCK|TTU_IGNORE_ACCESS);
skip_unmap:
????//?3.?將可移動內存頁的數據復制到空閑內存頁中
????if?(!page_mapped(page))
????????rc?=?move_to_new_page(newpage,?page,?remap_swapcache);
????...
????return?rc;
}
由于?unmap_and_move()?函數的實現比較復雜,所以我們對其進行了簡化。可以看出,unmap_and_move()?函數主要完成 3 個工作:
從內存區中找到一個空閑的內存頁。根據內存碎片整理算法,會從內存區最后開始掃描,找到合適的空閑內存頁。
由于將可移動內存頁遷移到空閑內存頁后,進程的虛擬內存映射將會發生變化。所以,這里要調用?try_to_unmap()?函數來解開所有使用了當前可移動內存頁的映射。
調用?move_to_new_page()?函數將可移動內存頁的數據復制到空閑內存頁中。在?move_to_new_page()?函數中,還會重新建立進程的虛擬內存映射,這樣使用了當前可移動內存頁的進程就能夠正常運行。
至此,內存碎片整理的過程已經分析完畢。
不過細心的讀者可能發現,在文中并沒有分析重新構建虛擬內存映射的過程。是的,因為重新構建虛擬內存映射要涉及到?內存頁反向映射?的知識點,后續的文章會介紹這個知識點,所以這里就不作詳細分析了。
總結
從上面的分析可知,內存碎片整理?是為了解決:在申請多個地址連續的內存頁時,空閑內存頁數量充足,但還是分配失敗的情況。
但由于內存碎片整理需要消耗大量的 CPU 時間,所以我們在申請內存時,可以通過指定?__GFP_WAIT?標志位(不等待)來避免內存碎片整理過程。
編輯:黃飛
?















 工商網監
工商網監
評論