 電子發燒友App
電子發燒友App


結構體的定義
結構體(struct)是由一系列具有相同類型或不同類型的數據構成的數據集合,也叫結構。
結構體和其他類型基礎數據類型一樣,例如 int 類型,char類型;只不過結構體可以做成你想要的數據類型,以方便日后的使用。
在實際項目中,結構體是大量存在的。研發人員常使用結構體來封裝一些屬性來組成新的類型。由于C語言無法操作數據庫,所以在項目中通過對結構體內部變量的操作將大量的數據存儲在內存中,以完成對數據的存儲和操作。
在實際問題中有時候我們需要幾種數據類型一起來修飾某個變量。
例如一個學生的信息就需要學號(字符串),姓名(字符串),年齡(整型)等等。
這些數據類型都不同但是他們又是表示一個整體,要存在聯系,那么我們就需要一個新的數據類型——結構體,它就將不同類型的數據存放在一起,作為一個整體進行處理。
結構體在函數中的作用不是簡便,其最主要的作用就是封裝。封裝的好處就是可以再次利用。讓使用者不必關心這個是什么,只要根據定義使用就可以了。
結構體的大小不是結構體元素單純相加就行的,因為我們現在主流的計算機使用的都是 32Bit 字長的 CPU,對這類型的 CPU 取 4 個字節的數要比取一個字節要高效,也更方便。所以在結構體中每個成員的首地址都是4的整數倍的話,取數據元素時就會相對更高效,這就是內存對齊的由來。
每個特定平臺上的編譯器都有自己的默認“對齊系數”(也叫對齊模數)。程序員可以通過預編譯命令 #pragma pack(n),n=1,2,4,8,16 來改變這一系數,其中的 n 就是你要指定的“對齊系數”。
規則
1、數據成員對齊規則:結構(struct)(或聯合(union))的數據成員,第一個數據成員放在 offset 為 0 的地方,以后每個數據成員的對齊按照 #pragma pack 指定的數值和這個數據成員自身長度中,比較小的那個進行。
2、結構(或聯合)的整體對齊規則:在數據成員完成各自對齊之后,結構(或聯合)本身也要進行對齊,對齊將按照#pragma pack指定的數值和結構(或聯合)最大數據成員長度中,比較小的那個進行。
3、結合1、2可推斷:當#pragma pack的n值等于或超過所有數據成員長度的時候,這個n值的大小將不產生任何效果。
在C語言中,可以定義結構體類型,將多個相關的變量包裝成為一個整體使用。在結構體中的變量,可以是相同、部分相同,或完全不同的數據類型。結構體不能包含函數。
在面向對象的程序設計中,對象具有狀態(屬性)和行為,狀態保存在成員變量中,行為通過成員方法(函數)來實現。C語言中的結構體只能描述一個對象的狀態,不能描述一個對象的行為。在C++中,考慮到 C 語言到 C++ 語言過渡的連續性,對結構體進行了擴展,C++的結構體可以包含函數,這樣,C++的結構體也具有類的功能,與 class 不同的是,結構體包含的函數默認為 public,而不是 private。
結構體聲明
?
//聲明一個結構體?
struct book
{
char title[MAXTITL];//一個字符串表示的titile 題目 ;
char author[MAXAUTL];//一個字符串表示的author作者 ;
float value;//一個浮點型表示的value價格;
}; //注意分號不能少,這也相當于一條語句;
?
這個聲明描述了一個由兩個字符數組和一個float變量組成的結構體。
但是注意,它并沒有創建一個實際的數據對象,而是描述了一個組成這類對象的元素。
因此,我們有時候也將結構體聲明叫做模板,因為它勾勒出數據該如何存儲,并沒有實例化數據對象。
下面介紹一下上面的結構體聲明;
1、首先使用關鍵字struct,它表示接下來是一個結構體。
2、后面是一個可選的標志(book),它是用來引用該結構體的快速標記。
因此我們以后就可以這樣創建數據對象
struct book library;//把library設為一個可以使用book結構體的結構體變量,則library這個變量就包含了其book結構體中的所有元素
3、接下來就是一個花括號,括起了結構體成員列表,及每個成員變量,使用的都是其自己的聲明方式來描述,用分號來結束描述;
例如:char title[MAXTITL]; 字符數組就是這樣聲明的,用分號結束;
注意?:其中每個成員可以使用任何一種C數據結構甚至是其他的結構體,也是可以的;
4、在結束花括號后的分號表示結構體設計定義的結束。
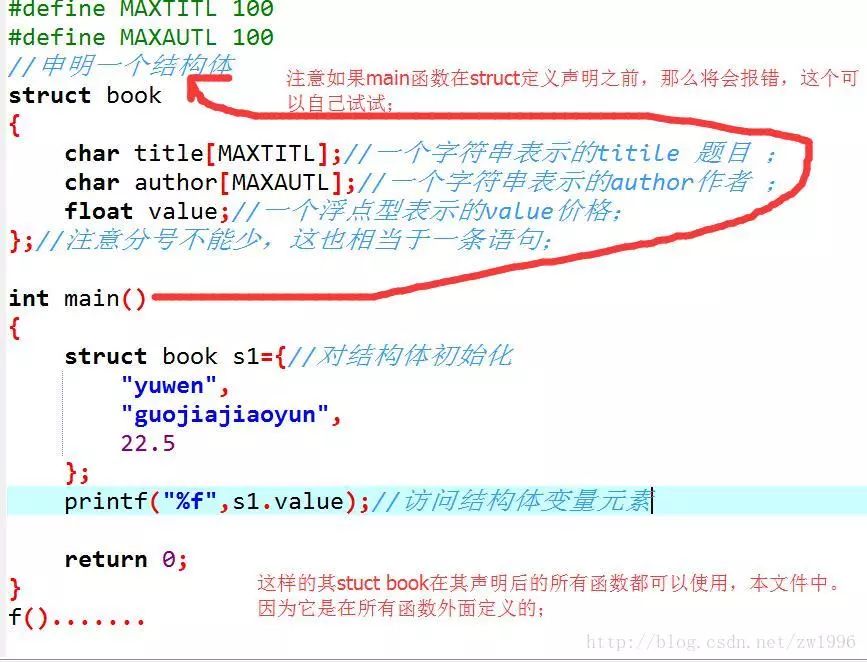
關于其struct聲明的位置,也就是這段代碼要放到哪里。?同樣這也是具有作用域的。
這種聲明如果放在任何函數的外面,那么則標記可以在在本文件中,該聲明后面的所有函數都可以使用。
如果這種聲明在某個函數的內部,則它的標記只能在內部使用,并且在其聲明之后;
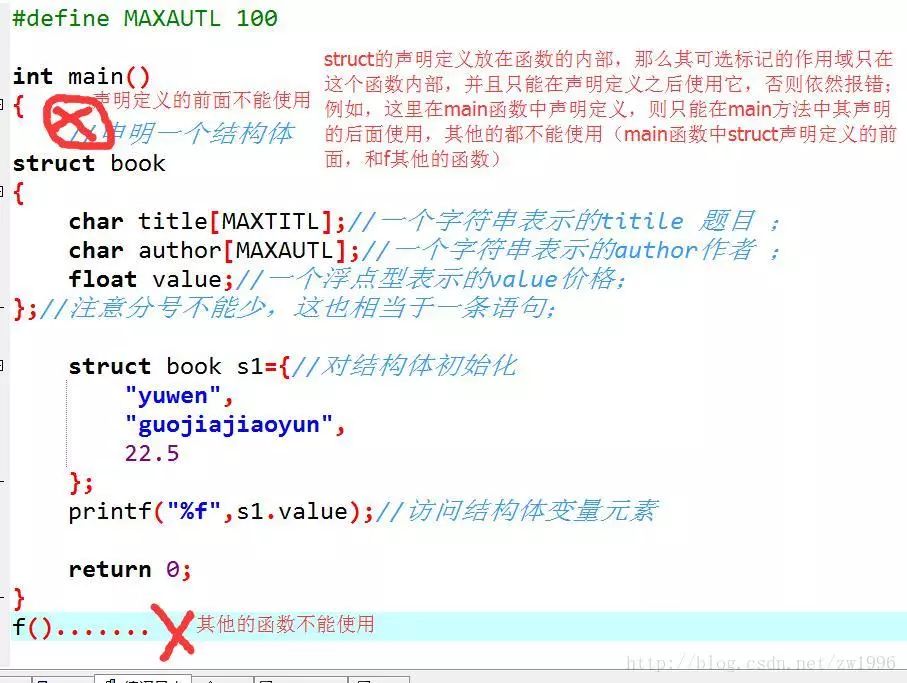
關于我們不斷說的,標記名是可選的,那么我們什么時候可以省略,什么時候一定不能省略呢?
如果是上面那種聲明定義的方法,并且想在一個地方定義結構體設計,而在其他地方定義實際的結構體變量,那么就必須使用標記;
可以省略,設計的同時就創建該結構體變量,但是這種設計是一次性的。
一般格式就是:
struct 結構體名(也就是可選標記名){ 成員變量;};//使用分號表示定義結束。
C 語言結構體定義的三種方式
1、最標準的方式:
?
#include?struct student //結構體類型的說明與定義分開。聲明 { int age; /*年齡*/ float score; /*分數*/ char sex; /*性別*/ }; int main () { struct student a={ 20,79,'f'}; //定義 printf("年齡:%d 分數:%.2f 性別:%c ", a.age, a.score, a.sex ); return 0; }
?
2、不環保的方式
?
#includestruct student /*聲明時直接定義*/ { int age; /*年齡*/ float score; /*分數*/ char sex; /*性別*/ /*這種方式不環保,只能用一次*/ } a={21,80,'n'}; int main () { printf("年齡:%d 分數:%.2f 性別:%c ", a.age, a.score, a.sex ); }
?
3、最奈何人的方式
?
#include?struct //直接定義結構體變量,沒有結構體類型名。這種方式最爛 { int age; float score; char sex; } t={21,79,'f'}; int main () { printf("年齡:%d 分數:%f 性別:%c ", t.age, t.score, t.sex); return 0; }
?
定義結構體變量
之前我們結構體類型的定義(結構體的聲明)只是告訴編譯器該如何表示數據,但是它沒有讓計算機為其分配空間。
我們要使用結構體,那么就需要創建變量,也就是結構體變量;
創建一個結構體變量;
?
struct book library;
?
看到這條指令,編譯器才會創建一個結構體變量library,此時編譯器才會按照book模板為該變量分配內存空間,并且這里存儲空間都是以這個變量結合在一起的。
這也是后面訪問結構體變量成員的時候,我們就要用到結構體變量名來訪問。
分析:
struct book的作用:
在結構體聲明中,struct book所起到的作用就像 int 等基礎數據類型名作用一樣。
?
struct book s1,s2,*ss;
?
定義兩個 struct book 結構體類型的結構體變量,還定義了一個指向該結構體的指針,其 ss 指針可以指向 s1,s2,或者任何其他的book結構體變量。
?
struct book library;等效于:
struct book{
char …
….
…..
}library;
這兩種是等效的,只是第一種可以減少代碼的編寫量; 現在還是回到剛才提及的那個問題,可選標志符什么時候可以省略;其一:
struct
{
char title[MAXTITL];
char author[MAXAUTL];
float value;
}library;
?
注意,這里不再是定義聲明結構體類型,而是直接創建結構體變量了,這個編譯器會分配內存的;
這樣的確可以省略標識符也就是結構體名,但是只能使用一次;因為這時,聲明結構體的過程和定義結構體變量的過程和在了一起,并且各成員變量沒有初始化。
如果你想多次使用一個結構體模塊,這樣子是行不通的。
其二,
用 typedef 定義新類型名來代替已有類型名,即給已有類型重新命名;
一般格式為;typedef 已有類型 新類型名;
?
typedef int Elem;
typedef struct{
int date;
.....
.....
}STUDENT;
STUDENT stu1,stu2;
?

總結一下關于結構體變量的定義:
1、先定義結構體類型后再定義結構體變量;
格式為:struct 結構體名 變量名列表;
?
//注意這種之前要先定義結構體類型后再定義變量; struct book s1,s2,*ss;
?
2、在定義結構體類型的同時定義結構體變量;
格式為:
struct 結構體名
{
成員列表;
}變量名列表;//這里結構體名是可以省的,但盡量別省;
struct book
{
char title[MAXTITL];//一個字符串表示的titile 題目 ;
char author[MAXAUTL];//一個字符串表示的author作者 ;
float value;//一個浮點型表示的value價格;
}s1,s2
?
直接定義結構體類型變量,就是第二種中省略結構體名的情況;
這種方式不能指明結構體類型名而是直接定義結構體變量,并且在只定義一次結構體變量時適用,無結構體名的結構體類型是無法重復使用的。
也就是說,后面程序不能再定義此類型變量了,除非再寫一次重復的 struct。對于結構體變量的初始化
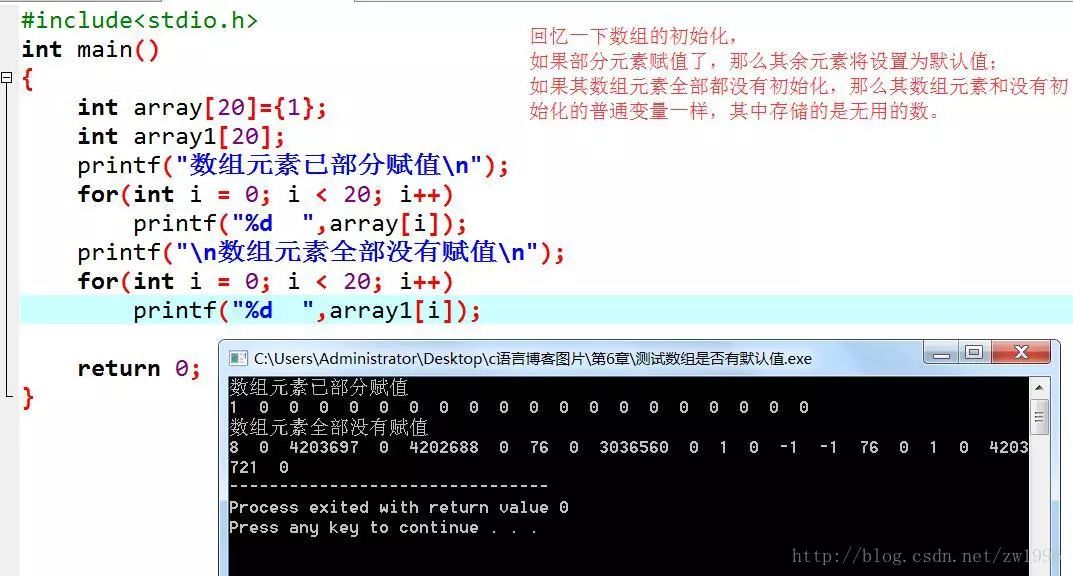
先回憶一下關于基本數據類型和數組類型的初始化:
?
int a =?0;
int array[4] = {1,2,3,4};//每個元素用逗號隔開
?
回憶一下數組初始化問題:
再回到結構體變量的初始化吧
關于結構體變量的初始化與初始化數組類似;
也是使用花括號括起來,用逗號分隔的初始化好項目列表。注意,每個初始化項目必須要和要初始化的結構體成員類型相匹配。
?
struct book s1=
{ //對結構體初始化
"yuwen", //title為字符串
"guojiajiaoyun", //author為字符數組
22.5 //value為flaot型
};
//要對應起來,用逗號分隔開來,與數組初始化一樣;
?
加入一點小知識,關于結構體初始化和存儲類時期的問題:如果要初始化一個具有靜態存儲時期的結構體,初始化項目列表中的值必須是常量表達式;
注意,如果在定義結構體變量的時候沒有初始化,那么后面就不能全部一起初始化了;意思就是:
?
/////////這樣是可以的,在定義變量的時候就初始化了;
struct book s1=
{ //對結構體初始化
"guojiajiaoyun",//author為字符數組
"yuwen",//title為字符串
22.5
};
/////////這種就不行了,在定義變量之后,若再要對變量的成員賦值,那么只能單個賦值了;
struct book s1;
s1={
"guojiajiaoyun",//author為字符數組
"yuwen",//title為字符串
22.5
};//這樣就是不行的,只能在定義的時候初始化才能全部賦值,之后就不能再全體賦值了,只能單個賦值;
只能:
s1.title = "yuwen";........//單個賦值;
?
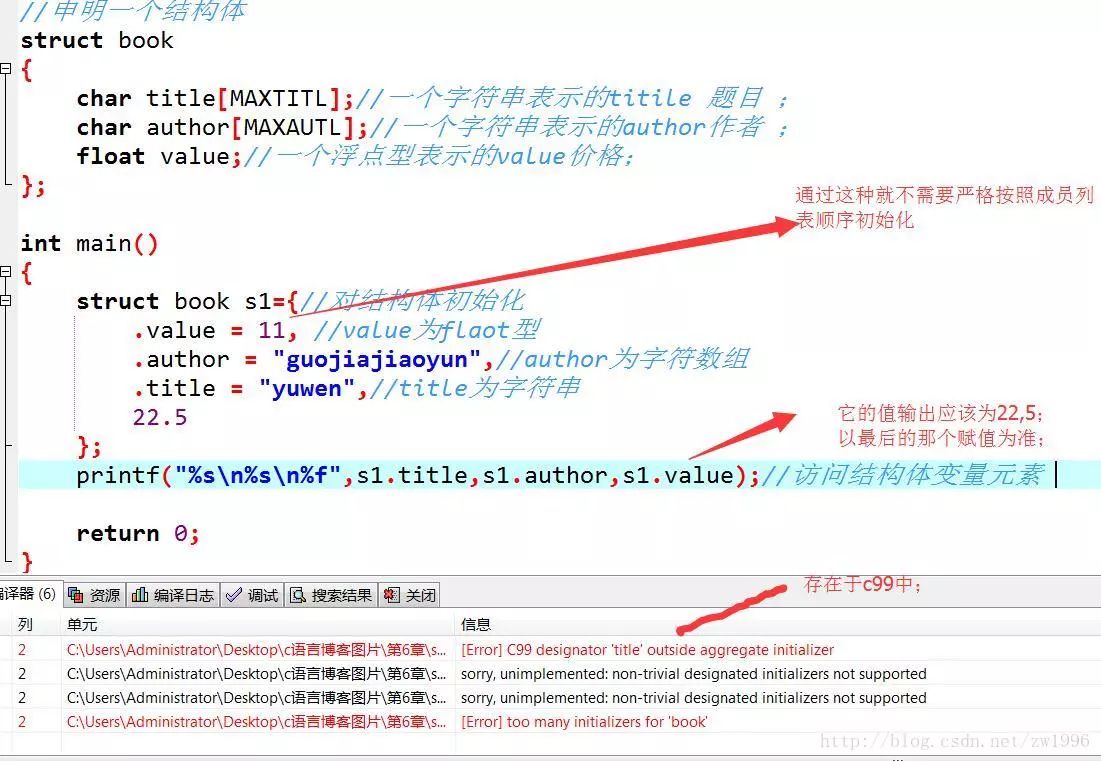
對于結構體的指定初始化:
訪問結構體成員
結構體就像一個超級數組,在這個超級數組內,一個元素可以是char類型,下個元素就可以是flaot類型,再下個還可以是int數組型,這些都是存在的。
在數組里面我們通過下標可以訪問一個數組的各個元素,那么如何訪問結構體中的各個成員呢?
用結構成員運算符點(.)就可以了;
結構體變量名.成員名;
注意,點其結合性是自左至右的,它在所有的運算符中優先級是最高的;
例如,s1.title指的就是s1的title部分;s1.author指的就是s1的author部分;s1.value指的就是s1的value部分。
然后就可以像字符數組那樣使用s1.title,像使用float數據類型一樣使用s1.value;
注意,s1 雖然是個結構體,但是 s1.value 卻是 float 型的。
因此 s1.value 就相當于 float 類型的變量名一樣,按照 float 類型來使用;
例如:
printf(“%s %s %f”,s1.title,s1.author,s1.value); //訪問結構體變量元素
注意 scanf(“%d”,&s1.value); 這語句存在兩個運算符,&和結構成員運算符點。
按照道理我們應該將(s1.value括起來,因為他們是整體,表示s1的value部分)但是我們不括起來也是一樣的,因為點的優先級要高于&。
如果其成員本身又是一種結構體類型,那么可以通過若干個成員運算符,一級一級的找到最低一級成員再對其進行操作;
結構體變量名.成員.子成員………最低一級子成員;
?
struct date
{
int year;
int month;
int day;
};
struct student
{
char name[10];
struct date birthday;
}student1;
//若想引用student的出生年月日,可表示為;student.brithday.year;
brithday是student的成員;year是brithday的成員;
?
整體與分開
可以將一個結構體變量作為一個整體賦值給另一相同類型的結構體變量,可以到達整體賦值的效果;這個成員變量的值都將全部整體賦值給另外一個變量;
不能將一個結構體變量作為一個整體進行輸入和輸出;在輸入輸出結構體數據時,必須分別指明結構體變量的各成員;
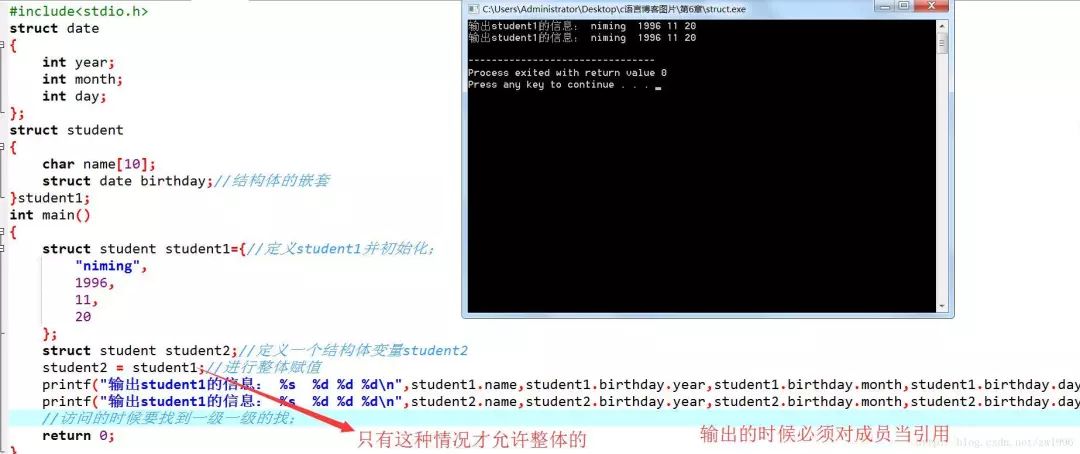
小結?:除去“相同類型的結構體變量可以相互整體賦值”外,其他情況下,不能整體引用,只能對各個成員分別引用;
結構體長度
數據類型的字節數:
16位編譯器char :1個字節
char*(即指針變量): 2個字節
short int : 2個字節
int: 2個字節
unsigned int : 2個字節
float: 4個字節
double: 8個字節
long: 4個字節
long long: 8個字節
unsigned long: 4個字節32位編譯器
char :1個字節
char*(即指針變量): 4個字節(32位的尋址空間是2^32, 即32個bit,也就是4個字節。同理64位編譯器)
short int : 2個字節
int: 4個字節
unsigned int : 4個字節
float: 4個字節
double: 8個字節
long: 4個字節long long: 8個字節
unsigned long: 4個字節
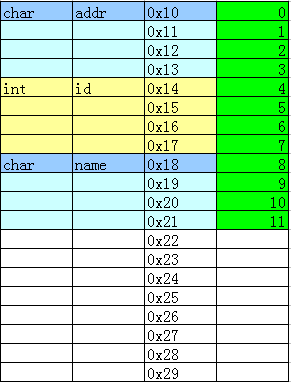
那么,下面這個結構體類型占幾個字節呢?
?
typedef?struct
{
char addr;
char name;
int id;
}PERSON;
通過printf("PERSON長度=%d字節 ",sizeof(PERSON));可以看到結果:
?
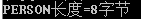
?
結構體字節對齊
通過下面的方式,可以清楚知道為什么是8字節。
1、定義20個char元素的數組
char ss[20]={0x10,0x11,0x12,0x13,0x14,0x15,0x16,0x17,0x18,0x19,0x20,0x21,0x22,0x23,0x24,0x25,0x26,0x27,0x28,0x29};
2、定義結構體類型的指針ps指向ss數組
PERSON *ps=(PERSON *)ss;3、打印輸出各個成員
printf("0x%02x,0x%02x,0x%02x
",ps->addr,ps->name,ps->id);printf("PERSON長度=%d字節
",sizeof(PERSON));
?
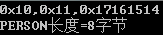
可以看到addr和name都只占一個字節,但是未滿4字節,跳過2字節后才是id的值,這就是4字節對齊。結構體成員有int型,會自動按照4字節對齊。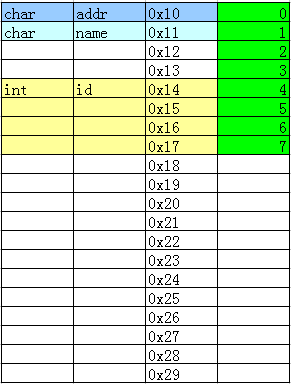 把結構體成員順序調換位置
把結構體成員順序調換位置
typedef struct
{
char addr;
int id;
char name;
}PERSON;
輸出: 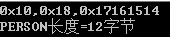
 按照下面的順序排列:
按照下面的順序排列:
typedef struct
{
int id;
char addr;
char name;
}PERSON;
輸出: 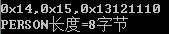
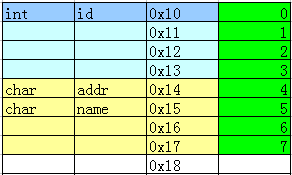 可見,結構體成員順序優化,可節省空間。
可見,結構體成員順序優化,可節省空間。如果全部成員都是 char 型,會按照 1 字節對齊,即
typedef struct
{
char addr;
char name;
char id;
}PERSON;
輸出結果:
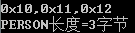

?
結構體嵌套
結構體嵌套結構體方式:
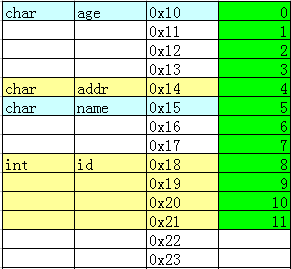
typedef struct
{
char addr;
char name;
int id;
}PERSON;
typedef struct
{
char age;
??PERSON??ps1;
}STUDENT;
先定義結構體類型PERSON,再定義結構體STUDENT,PERSON作為它的一個成員。
按照前面的方法,打印各成員的值。
1、定義STUDENT?指針變量指向數組 ss
STUDENT *stu=(STUDENT *)ss;
2、打印輸出各成員和長度
printf("0x%02x,0x%02x,0x%02x,0x%02x
",stu->ps1.addr,stu->ps1.name,stu->ps1.id,stu->age);
printf("STUDENT長度=%d字節
",sizeof(STUDENT));
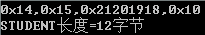
 調換STUDENT成員順序,
調換STUDENT成員順序,
typedef struct
{
PERSON ps1;
char age;
}STUDENT;
輸出結果: 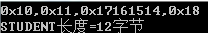
結構體嵌套其實沒有太意外的東西,只要遵循一定規律即可:
//對于“一錘子買賣”,只對最終的結構體變量感興趣,其中A、B也可刪,不過最好帶著
struct A{
struct B{
int c;
}b;
}a;??
//使用如下方式訪問:
a.b.c = 10;
特別的,可以一邊定義結構體B,一邊就使用上:
struct A{
struct B{
int c;
????????}b;
struct?B?sb;
}a;??
?
使用方法與測試:
?
a.b.c = 11;
printf("%d
",a.b.c);
a.sb.c = 22;
printf("%d
",a.sb.c);
?
結果無誤。
但是如果嵌套的結構體B是在A內部才聲明的,并且沒定義一個對應的對象實體b,這個結構體B的大小還是不算進結構體A中。
占用內存空間 struct結構體,在結構體定義的時候不能申請內存空間,不過如果是結構體變量,聲明的時候就可以分配——兩者關系就像C++的類與對象,對象才分配內存(不過嚴格講,作為代碼段,結構體定義部分“.text”真的就不占空間了么?當然,這是另外一個范疇的話題)。 結構體的大小通常(只是通常)是結構體所含變量大小的總和,下面打印輸出上述結構體的size:
printf("size of struct man:%d
",sizeof(struct man));
printf("size:%d
",sizeof(Huqinwei));
結果毫無懸念,都是28:分別是char數組20,int變量4,浮點變量4。
下邊說說不通常的情況
對于結構體中比較小的成員,可能會被強行對齊,造成空間的空置,這和讀取內存的機制有關。
為了效率,通常32位機按4字節對齊,小于的都當4字節,有連續小于4字節的,可以不著急對齊,等到湊夠了整,加上下一個元素超出一個對齊位置,才開始調整,比如3+2或者1+4,后者都需要另起(下邊的結構體大小是8bytes),相關例子就多了,不贅述。
struct s
{
char a;
short b;
int c;
};
?
相應的,64 位機按 8 字節對齊。不過對齊不是絕對的,用#pragma pack()可以修改對齊,如果改成1,結構體大小就是實實在在的成員變量大小的總和了。
和C++的類不一樣,結構體不可以給結構體內部變量初始化,。
如下,為錯誤示范:
#include//直接帶變量名 struct stuff{ // char job[20] = "Programmer"; // char job[]; // int age = 27; // float height = 185; };
?
PS:結構體的聲明也要注意位置的,作用域不一樣。
C++的結構體變量的聲明定義和C有略微不同,說白了就是更“面向對象”風格化,要求更低。
?
為什么有些函數的參數是結構體指針型 如果函數的參數比較多,很容易產生“重復C語言代碼”,例如:
int get_video(char **name, long *address, int *size, time_t *time, int *alg)
{
...
}
int handle_video(char *name, long address, int size, time_t time, int alg)
{
...
}
int send_video(char *name, long address, int size, time_t time, int alg)
{
...
}
上述C語言代碼定義了三個函數:get_video() 用于獲取一段視頻信息,包括:視頻的名稱,地址,大小,時間,編碼算法。然后 handle_video() 函數根據視頻的這些參數處理視頻,之后 send_video() 負責將處理后的視頻發送出去。下面是一次調用:
char *name = NULL; long address; int size, alg; time_t time; get_video(&name, &address, &size, &time, &alg); handle_video(name, address, size, time, alg); send_video(name, address, size, time, alg);從上面這段C語言代碼來看,為了完成視頻的一次“獲取”——“處理”——“發送”操作,C語言程序不得不定義多個變量,并且這些變量需要重復寫至少三遍。
雖說C語言程序的代碼風格因人而異,但是“重復的代碼”永遠是應盡力避免的,不管怎么說,每次使用這幾個函數,都需要定義很多臨時變量,總是非常麻煩的。所以,這種情況下,完全可以使用C語言的結構體語法:
struct video_info
{
char *name;
long address;
int size;
int alg;
time_t time;
};
定義好 video_info 結構體后,上述三個C語言函數的參數可以如下寫,請看:
int get_video(struct video_info *vinfo)
{
...
}
int handle_video(struct video_info *vinfo)
{
...
}
int send_video(struct video_info *vinfo)
{
...
}
修改后的C語言代碼明顯精簡多了,在函數內部,視頻的各個信息可以通過結構體指針 vinfo 訪問,例如:
printf("video name: %s
", vinfo->name);
long addr = vinfo->address;
int size = vinfo->size;
事實上,使用結構體 video_info 封裝視頻信息的各個參數后,調用這幾個修改后的函數也是非常簡潔的:
struct video_info vinfo = {0};
get_video(&vinfo);
handle_video(&vinfo);
send_video(&vinfo);
從上述C語言代碼可以看出,使用修改后的函數只需定義一個臨時變量,整個代碼變得非常精簡。讀者應該注意到了,修改之前的 handle_video() 和 send_video() 函數原型如下:
int handle_video(char *name, long address, int size, time_t time, int alg); int send_video(char *name, long address, int size, time_t time, int alg);根據這段C語言代碼,我們知道 handle_video() 和 send_video() 函數只需要讀取參數信息,并不再修改參數,那為什么使用結構體 video_info 封裝數據,修改后的 handle_video() 和 send_video() 函數參數是 struct video_info ?*指針型呢?
int handle_video(struct video_info *vinfo); int send_video(struct video_info *vinfo);既然 handle_video() 和 send_video() 函數只需要讀取參數信息,那我們就無需再使用指針型了呀?的確如此,這兩個函數的參數直接使用 struct video_info 型也是可以的:
int handle_video(struct video_info vinfo)
{
...
}
int send_video(struct video_info vinfo)
{
...
}
似乎這種寫法和使用 ?struct video_info ?*指針型 參數的區別,無非就是函數內部訪問數據的方式改變了而已。但是,如果讀者能夠想到我們之前討論過的 C語言函數的“棧幀”概念,應該能夠發現,使用指針型參數的 handle_video() 和 send_video() 函數效率更好,開銷更小。
?
嵌入式開發中,C語言位結構體用途詳解
在嵌入式開發中,經常需要表示各種系統狀態,位結構體的出現大大方便了我們,尤其是在進行一些硬件層操作和數據通信時。但是在使用位結構體的過程中,是否深入思考一下它的相關屬性?是否真正用到它的便利性,來提高系統效率?
下面將進行一些相關實驗(這里以項目開發中的實際代碼為例):
1. 位結構體類型設計
//data?structure?except?for?number?structure?? typedef struct symbol_struct {?? ??uint_32?SYMBOL_TYPE???:5;??//data?type,have?the?affect?on?"data?display?type"?? ??uint_32?reserved_1????:4;?? uint_32 SYMBOL_NUMBER :7; //effective data number in one element uint_32 SYMBOL_ACTIVE :1;//symbol active status ??? uint_32 SYMBOL_INDEX :8; //data index in norflash,result is related to "xxx_BASE_ADDR" uint_32?reserved_2?????:8;?? }SYMBOL_STRUCT, _PTR_?SYMBOL_STRUCT_PTR;
分析:這里定義了一個位結構體類型 SYMBOL_STRUCT,那么用該類型定義的變量都哪些屬性呢?
?
看下面運行結果:?
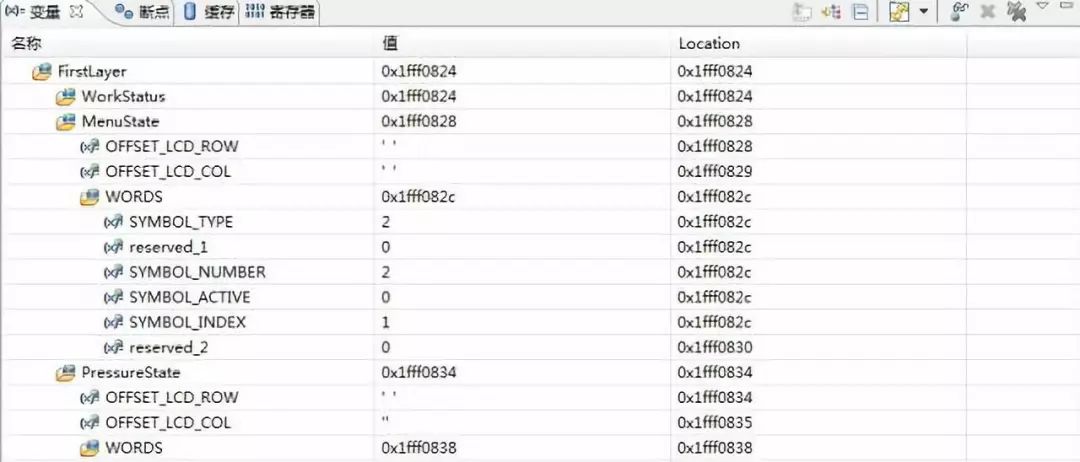
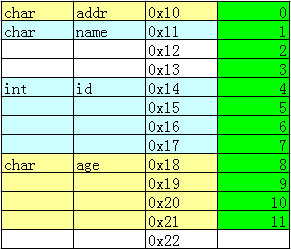
WORDS是定義的另一個外層類型定義封裝,可以把它當作變量來看待。WORDS變量里前5個數據域的地址都是0x1ffff082c,而reserved_2的地址0x1fff0830,緊接著的PressureState變量是0x1fff0834。
開始以為:reserved_1 和 SYMBOL_TYPE 不在一個地址上,因為他們 5+4 共9位,超過了1個字節地址,但實際他們共用首地址了;而且reserved_2只定義了8位,竟然實際占用了4個字節(0x1fff0834 - 0x1fff0830),我本來是想讓他占用1個字節的。
WORDS整體占了8個字節(0x1fff0834 - 0x1fff082c),設計時分析占用5個字節:
SYMBOL_TYPE 1個;reserved_1 1個;
SYMBOL_NUMBER+SYMBOL_ACTIVE 1個;
SYMBOL_INDEX 1個;reserved_2 1個;
uint_32 reserved_2 : 8;占用4個字節,估計是uint_32在起作用,而這里寫的8位,只是我使用的有效位數,另外24位空閑,如果在下面再定義一個uint_32 reserved_3 : 8,地址也是一樣的,都是以uint_32為單位取地址。
同理,上面的5個變量,共用一個地址就不足為奇了。而且有效位的分配不是連續進行的,例如 SYMBOL_TYPE+reserved_1 共9位,超過了一個字節,索性系統就分配兩個字節給他們,每人一個;SYMBOL_NUMBER+SYMBOL_ACTIVE 共8位,一個字節就能搞定。
2、修改數據結構,驗證上述猜想
?
//data?structure?except?for?number?structure??
typedef struct symbol_struct
{
??uint_8?SYMBOL_TYPE????:5;?//data?type,have?the?affect?on?"data?display?type"
uint_8 reserved_1 :4;
??uint_8?SYMBOL_NUMBER???:7;?//effective?data?number?in?one?element??
??uint_8?SYMBOL_ACTIVE???:1; //symbol?active?status??
??uint_8?SYMBOL_INDEX????:8;?//data?index?in?norflash,result?is?related?to?"xxx_BASE_ADDR"
??uint_8?reserved_2??????:8;??
}SYMBOL_STRUCT,_PTR_ SYMBOL_STRUCT_PTR;
?
地址數據如下:
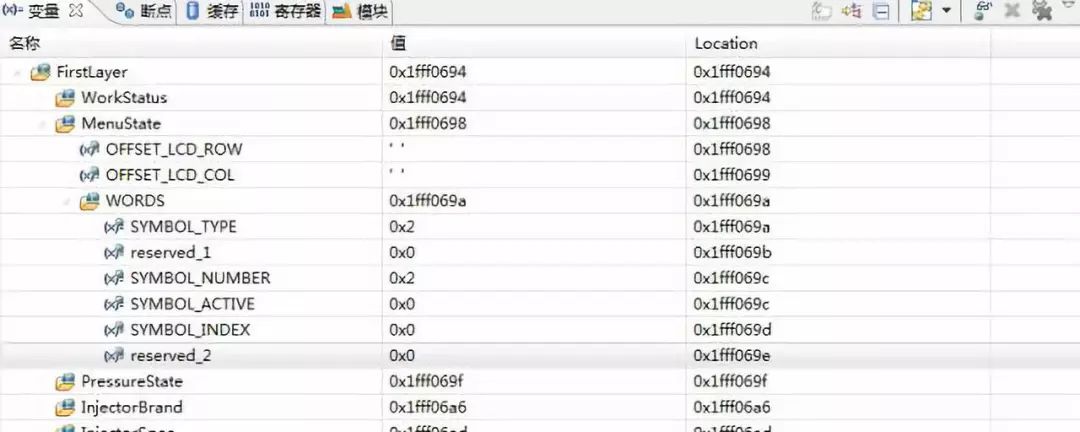
當換成uint_8后,可以看到地址空間占用大大減小,reserved_2 只占用1個字節(0x1fff069f - 0x1fff069e),其他變量也都符合上面的結論猜想。但是,注意看上面黃色和紅色的語句,總感覺有些勉強,那么我又會想,前兩個變量數據域是 9 位,那么他們實際上是不是真正的獨立呢?雖然在 uint_8 上面他們是不同的地址,在uint_32 的時候是不是也是不同的地址空間呢?
3、分析結構體內部的數據域是否連續,看下圖及結果
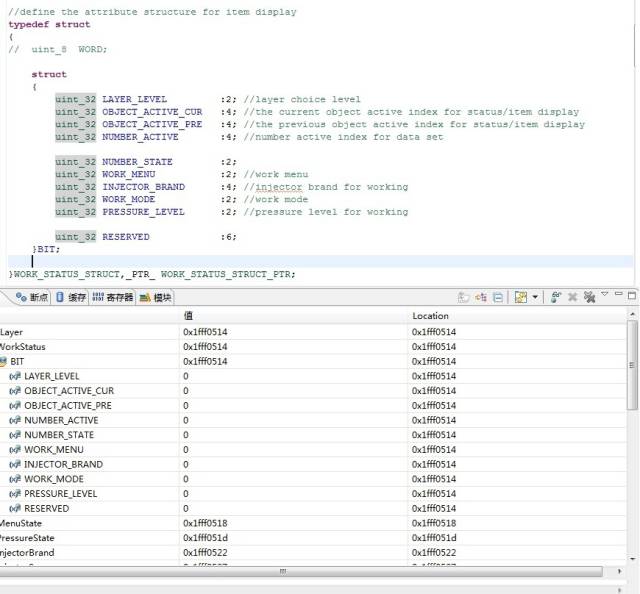
本來假設: 由前 2 次試驗的結論,一共占用 8 個字節,節空間占用:(2+4)+(4+4)+(2+2+4)+(2+2)+(6)。可是,實際效果并不是想的那樣。實際只占用了 4 個字節,系統并沒有按照預想的方式,為 RESERVED 變量分配 4 個字節。
分析:
這些數據域,整體相加一共32位,占用4個字節(不考慮數據對齊問題)。而實際確實是占用了4個字節,唯一的原因就是:這些數據域以緊湊的方式鏈接,沒有任何空閑位。實際是不是這樣呢?
看下圖和結果:
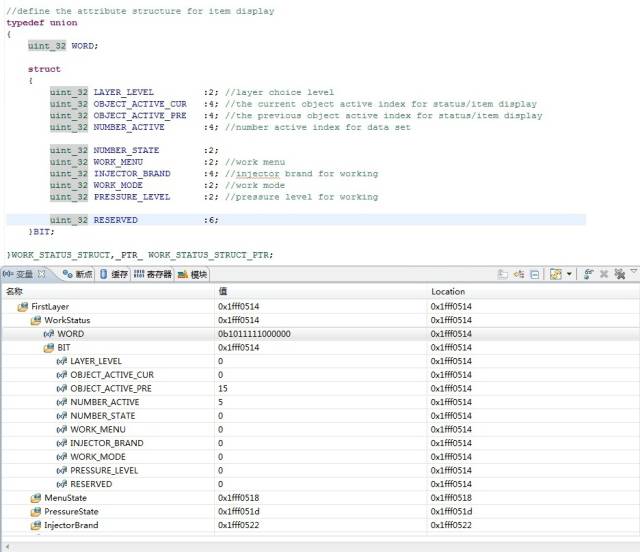
這里為了驗證是否緊湊鏈接,用到了一個union數據,后面會講到用union不會對數據組織方式有任何影響,看實際與上次的一樣,也能分析出來。
主要是分析第2和第3個數據域是否緊密鏈接的。OBJECT_ACTIVE_PRE賦值0b00001111,NUMBER_ACTIVE賦值0b00000101,其他變量都是0,看到WORD數值0b1011111000000。分析WORD數據,可以看到這款MCU還是小端格式(高位數據在高端,低位數據在低端,這里不對大小端進行討論),斷開數據變成(0)10111 11000000,正好是0101+1111,OBJECT_ACTIVE_PRE數據域,跨越了兩個字節,并不是剛開始設想的那樣。這就印證了上面的緊密鏈接的結論,也符合數據結果輸出。
4、再次實驗,分析數據是否緊密鏈接,看下圖和結果
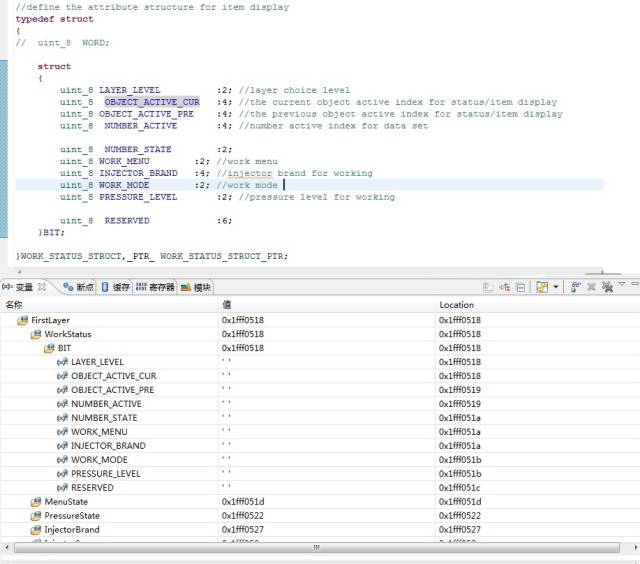
可以看到,RESERVED數據域已經不再屬于4個地址空間內了(0x1fff0518 - 0x1fff051b),但是他們整體加起來還是32個位域。這說明數據中間肯定有“空隙”存在了,空隙在哪?看一下NUMBER_STATE,如果緊密的話它應該跟NUMBER_ACTIVE在同一個字節地址上,可是他們并不在一塊,“空隙”就存在這里。
這兩個結構體有什么不一樣?數據類型不一致,一個是uint_32,一個是uint_8。
綜上所述?:數據類型影響的是編譯器在分配物理空間時的大小單位,uint_32 是以 4個字節為單位,而后面的位域則是指在已經分配好的物理空間內部再緊湊的方式分配數據位,當物理空間不能滿足位域時,那么系統就再次以一定大小單位進行物理空間分配,這個單位就是上面提到的 uint_8 或者 uint_32。
舉例:上面 uint_32 時,這些位域不管是不是在一個字節地址上,如果能夠緊湊的分配在一個4字節空間大小上,就直接緊湊分配。如果不能則繼續分配(總空間超過4字節),則再次以4字節空間分配,并把新的位域建立在新的地址空間上(條目1上的就是)。當 uint_8 時,很明顯如果位域不能緊湊的放在一個字節空間上,那么就從新分配新的1字節空間大小,道理是一樣的。
**5、結構體組合、共用體組合是否影響上述結論 **
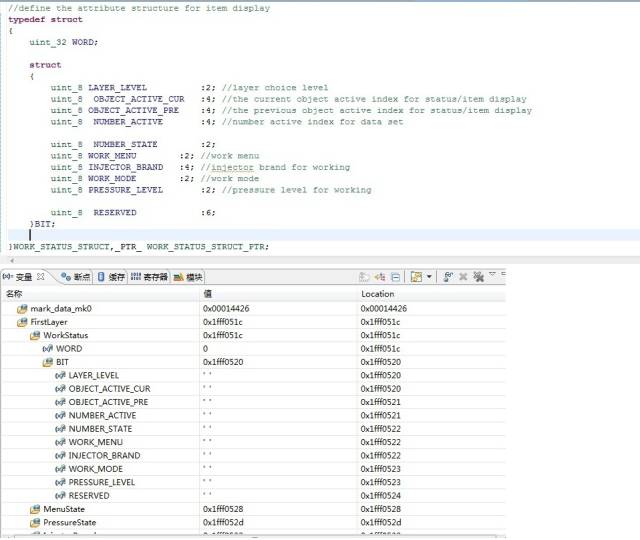
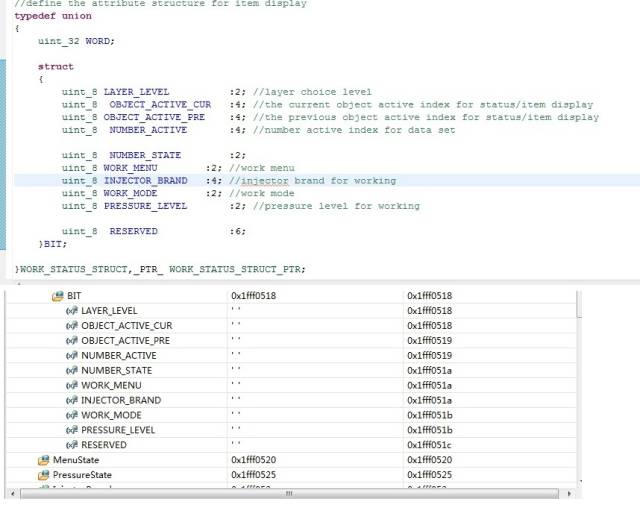
可以看到,系統并沒有因為位結構體上面有uint_4的4字節變量或者共用體類型,就改變分配策略把位域都擠到4字節之內,看來他們是沒有什么實質性聯系的。這里把uint_32改成uint_8,或者把位結構體也替換掉,經我試驗證明,都是沒有任何影響的。
總結:
1、在操作位結構體時,要關注變量的位域是否在一個變量類型(uint_32或者uint_8)上,判斷占用空間大小。
2、除了位域,還要關注變量定義類型,因為編譯器空間分配始終是按類型分配的,位域只是指出了有效位(小于類型占用空間),而且如果位域大于類型空間,編譯器直接報錯(如 uint_8 test :15,可自行實驗)。
3、這兩個因素都影響變量占用空間大小,具體可以結合調試窗口,通過地址分配分析判斷。
4、?最重要的一點?:上面的所有結果,都是基于我自己的 CodeWarrior10.2 和MQX3.8 分析出來的,不同的編譯環境和操作系統,都可能會有不同的結果;而且即便是環境相同,編譯器的配置和優化選項都有可能影響系統處理結果。結論并不重要,主要想告訴大家這一塊隱藏陷阱,在以后處理類似問題時,要注意分析避讓并掌握方法。
審核編輯:湯梓紅
?








 工商網監
工商網監
評論