 電子發燒友App
電子發燒友App


?一、程序結構優化
1、程序的書寫結構?
雖然書寫格式并不會影響生成的代碼質量,但是在實際編寫程序時還是應該遵循一定的書寫規則,一個書寫清晰、明了的程序,有利于以后的維護。在書寫程序時,特別是對于While、for、do…while、if…else、switch…case 等語句或這些語句嵌套組合時,應采用“縮格”的書寫形式。
2、標識符?
程序中使用的用戶標識符除要遵循標識符的命名規則以外,一般不要用代數符號(如a、b、x1、y1)作為變量名,應選取具有相關含義的英文單詞(或縮寫)或漢語拼音作為標識符,以增加程序的可讀性,如:count、number1、red、work 等。
3、程序結構?
C 語言是一種高級程序設計語言,提供了十分完備的規范化流程控制結構。因此在采用C 語言設計單片機應用系統程序時,首先要注意盡可能采用結構化的程序設計方法,這樣可使整個應用系統程序結構清晰,便于調試和維護。
對于一個較大的應用程序,通常將整個程序按功能分成若干個模塊,不同模塊完成不同的功能。各個模塊可以分別編寫,甚至還可以由不同的程序員編寫,一般單個模塊完成的功能較為簡單,設計和調試也相對容易一些。在C 語言中,一個函數就可以認為是一個模塊。
?
所謂程序模塊化,不僅是要將整個程序劃分成若干個功能模塊,更重要的是,還應該注意保持各個模塊之間變量的相對獨立性,即保持模塊的獨立性,盡量少使用全局變量等。對于一些常用的功能模塊,還可以封裝為一個應用程序庫,以便需要時可以直接調用。但是在使用模塊化時,如果將模塊分成太細太小,又會導致程序的執行效率變低(進入和退出一個函數時保護和恢復寄存器占用了一些時間)。
4、定義常數?
在程序化設計過程中,對于經常使用的一些常數,如果將它直接寫到程序中去,一旦常數的數值發生變化,就必須逐個找出程序中所有的常數,并逐一進行修改,這樣必然會降低程序的可維護性。因此,應盡量當采用預處理命令方式來定義常數,而且還可以避免輸入錯誤。
5、減少判斷語句?
能夠使用條件編譯(ifdef)的地方就使用條件編譯而不使用if 語句,有利于減少編譯生成的代碼的長度。
6、表達式?
對于一個表達式中各種運算執行的優先順序不太明確或容易混淆的地方,應當采用圓括號明確指定它們的優先順序。一個表達式通常不能寫得太復雜,如果表達式太復雜,時間久了以后,自己也不容易看得懂,不利于以后的維護。
7、函數?
對于程序中的函數,在使用之前,應對函數的類型進行說明,對函數類型的說明必須保證它與原來定義的函數類型一致,對于沒有參數和沒有返回值類型的函數應加上“void”說明。如果果需要縮短代碼的長度,可以將程序中一些公共的程序段定義為函數。如果需要縮短程序的執行時間,在程序調試結束后,將部分函數用宏定義來代替。注意,應該在程序調試結束后再定義宏,因為大多數編譯系統在宏展開之后才會報錯,這樣會增加排錯的難度。
8、盡量少用全局變量,多用局部變量?
因為全局變量是放在數據存儲器中,定義一個全局變量,MCU 就少一個可以利用的數據存儲器空間,如果定義了太多的全局變量,會導致編譯器無足夠的內存可以分配;而局部變量大多定位于MCU 內部的寄存器中,在絕大多數MCU 中,使用寄存器操作速度比數據存儲器快,指令也更多更靈活,有利于生成質量更高的代碼,而且局部變量所能占用的寄存器和數據存儲器在不同的模塊中可以重復利用。
9、設定合適的編譯程序選項?
許多編譯程序有幾種不同的優化選項,在使用前應理解各優化選項的含義,然后選用最合適的一種優化方式。通常情況下一旦選用最高級優化,編譯程序會近乎病態地追求代碼優化,可能會影響程序的正確性,導致程序運行出錯。因此應熟悉所使用的編譯器,應知道哪些參數在優化時會受到影響,哪些參數不會受到影響。 ?
二、代碼的優化
1、選擇合適的算法和數據結構?
應熟悉算法語言。將比較慢的順序查找法用較快的二分查找法或亂序查找法代替,插入排序或冒泡排序法用快速排序、合并排序或根排序代替,這樣可以大大提高程序執行的效率。
選擇一種合適的數據結構也很重要,比如在一堆隨機存放的數據中使用了大量的插入和刪除指令,比使用鏈表要快得多。數組與指針具有十分密切的關系,一般來說指針比較靈活簡潔,而數組則比較直觀,容易理解。對于大部分分的編譯器,使用指針比使用數組生成的代碼更短,執行效率更高。
但是在Keil 中則相反,使用數組比使用的指針生成的代碼更短。
2、使用盡量小的數據類型?
能夠使用字符型(char)定義的變量,就不要使用整型(int)變量來定義;能夠使用整型變量定義的變量就不要用長整型(long int),能不使用浮點型(float)變量就不要使用浮點型變量。當然,在定義變量后不要超過變量的作用范圍,如果超過變量的范圍賦值,C 編譯器并不報錯,但程序運行結果卻錯了,而且這樣的錯誤很難發現。
3、使用自加、自減指令?
通常使用自加、自減指令和復合賦值表達式(如a-=1 及a+=1 等)都能夠生成高質量的程序代碼,編譯器通常都能夠生成inc 和dec 之類的指令,而使用a=a+1 或a=a-1之類的指令,有很多C 編譯器都會生成2~3個字節的指令。
4、減少運算的強度?
可以使用運算量小但功能相同的表達式替換原來復雜的的表達式。如下:
(1)求余運算
a=a%8;
可以改為:
a=a&7;
說明:位操作只需一個指令周期即可完成,而大部分的C 編譯器的“%”運算均是調用子程序來完成,代碼長、執行速度慢。通常,只要求是求2n 方的余數,均可使用位操作的方法來代替。
(2)平方運算
? a=pow(a,2.0);
可以改為:
a=a*a; ? 說明:在有內置硬件乘法器的單片機中(如51 系列),乘法運算比求平方運算快得多,因為浮點數的求平方是通過調用子程序來實現的,在自帶硬件乘法器的AVR 單片機中,如ATMega163 中,乘法運算只需2 個時鐘周期就可以完成。即使是在沒有內置硬件乘法器的AVR單片機中,乘法運算的子程序比平方運算的子程序代碼短,執行速度快。如果是求3 次方,如: ? a=pow(a,3.0);
更改為:
a=a*a*a; ? 則效率的改善更明顯。
(3)用移位實現乘除法運算
a=a*4;
b=b/4;
可以改為:
a=a<<2;
b=b>>2; 說明:通常如果需要乘以或除以2n,都可以用移位的方法代替。在ICCAVR 中,如果乘以2n,都可以生成左移的代碼,而乘以其它的整數或除以任何數,均調用乘除法子程序。用移位的方法得到代碼比調用乘除法子程序生成的代碼效率高。實際上,只要是乘以或除以一個整數,均可以用移位的方法得到結果,如:
a=a*9
可以改為:
a=(a<<3)+a
5、循環?
(1)循環語
對于一些不需要循環變量參加運算的任務可以把它們放到循環外面,這里的任務包括表達式、函數的調用、指針運算、數組訪問等,應該將沒有必要執行多次的操作全部集合在一起,放到一個init 的初始化程序中進行。
(2)延時函數?
通常使用的延時函數均采用自加的形式:
?
void delay (void){unsigned int i;for (i=0;i<1000;i++); }將其改為自減延時函數:void delay (void){unsigned int i;for (i=1000;i>0;i--); }
? 兩個函數的延時效果相似,但幾乎所有的C 編譯對后一種函數生成的代碼均比前一種代碼少1~3 個字節,因為幾乎所有的MCU 均有為0轉移的指令,采用后一種方式能夠生成這類指令。在使用while 循環時也一樣,使用自減指令控制循環會比使用自加指令控制循環生成的代碼更少1~3 個字母。但是在循環中有通過循環變量“i”讀寫數組的指令時,使用預減循環時有可能使數組超界,要引起注意。
?
(3)while 循環和do…while 循環?
用while 循環時有以下兩種循環形式:
?
unsigned int i;i=0;while (i<1000){i++; //用戶程序}或:unsigned int i;i=1000;do{i--; //用戶程序}while (i>0);
? 在這兩種循環中,使用do…while循環編譯后生成的代碼的長度短于while循環。
?
6、查表?
在程序中一般不進行非常復雜的運算,如浮點數的乘除及開方等,以及一些復雜的數學模型的插補運算,對這些即消耗時間又消費資源的運算,應盡量使用查表的方式,并且將數據表置于程序存儲區。如果直接生成所需的表比較困難,也盡量在啟動時先計算,然后在數據存儲器中生成所需的表,后面在程序運行直接查表就可以了,減少了程序執行過程中重復計算的工作量。
7、其它?
比如使用在線匯編及將字符串和一些常量保存在程序存儲器中,均有利于優化。
三、乘除法優化
目前單片機的市場競爭很激烈,許多應用出于性價比的考慮,選擇使用程序存儲空間較小(如1K,2K)的小資源8位MCU芯片進行開發。一般情況下,這類MCU沒有硬件乘法、除法指令,在程序必須使用乘除法運算時,如果單純依靠編譯器調用內部函數庫來實現,常常會有代碼量偏大、執行效率偏低的缺點。
上海晟矽微電子推出的MC30、MC32系列MCU,采用了RISC架構,在小資源8位MCU領域有廣大的用戶群和廣泛的應用,本文就以晟矽微電的這兩個系列產品的指令集為例,結合匯編與C編譯平臺,給大家介紹一種即省時又節約資源的乘除法算法。
1、乘法篇?
單片機中的乘法是二進制的乘法,也就是把乘數的各個位與被乘數相乘,然后再相加得出,因為乘數和被乘數都是二進制,所以實際編程時每一步的乘法可以用移位實現。
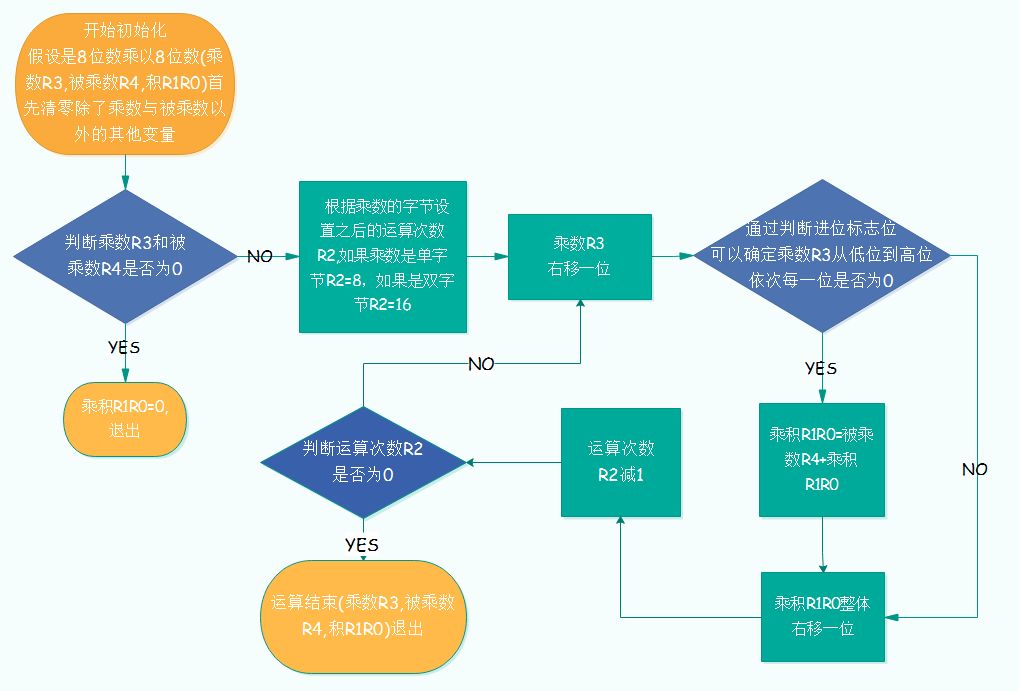
例如:乘數R3=01101101,被乘數R4=11000101,乘積R1R0。步驟如下:
1、清空乘積R1R0;
2、乘數的第0位是1,那被乘數R4需要乘上二進制數1,也就是左移0位,加到R1R0里;
3、乘數的第1位是0,忽略;
4、乘數的第2位是1,那被乘數R4需要乘上二進制數100,也就是左移2位,加到R1R0里;
5、乘數的第3位是1,那被乘數R4需要乘上二進制數1000,也就是左移3位,加到R1R0里;
6、乘數的第4位是0,忽略;
7、乘數的第5位是1,那被乘數R4需要乘上二進制數100000,也就是左移5位,加到R1R0里;
8、乘數的第6位是1,那被乘數R4需要乘上二進制數1000000,也就是左移6位,加到R1R0里;
9、乘數的第7位是0,忽略;
10、這時候R1R0里的值就是最后的乘積,至此算法完成。
以上例子運算結果:
R1R0 = R3 * R4= (R4<<6)+(R4<<5)+(R4<<3)+(R4<<2)+R4 = 101001111100001
實際運算流程圖見下圖:
? 
在實際的程序設計過程中,程序優化有兩個目標,提高程序運行效率,和減少代碼量。我們來看下本文提供的匯編算法和普通C語言編程的效率和代碼量對比。
表1.1是程序運行效率的對比數據(可能會有小的偏差),很明顯匯編編譯出來的運行時間要比C語言減少很多。
| ? |
匯編(時鐘周期) |
C語言(時鐘周期) |
8*8位乘法 |
79-87 |
184-190 |
16*8位乘法 |
201-210 |
362-388 |
16*16位乘法 |
234-379 |
396-468 |
表1.1? 乘法運算時鐘周期對比表 ?
表1.2是程序代碼量的對比數據(可能會有小的偏差),匯編占用的程序空間也要比C語言小很多。 ?
| ? |
匯編(Byte) |
C語言(Byte) |
8*8位乘法 |
15 |
34 |
16*8位乘法 |
19 |
96 |
16*16位乘法 |
31 |
96 |
表1.2? 乘法運算ROM空間使用情況對比表 ?
綜上兩點,本文介紹的乘法算法各方面使用情況都要比C編譯好很多。如果大家在使用過程中,原有的程序不能滿足應用需求,例如遇到程序空間不夠或者運行時間太久等問題,都可以按照以上方式進行優化。 匯編語言最接近機器語言的。在匯編語言中可以直接操作寄存器,調整指令執行順序。由于匯編語言直接面對硬件平臺,而不同的硬件平臺的指令集及指令周期均有較大差異,這樣會對程序的移植和維護造成一定的不便,所以我們針對精簡指令集做了乘法運算的例程,便于大家的移植和理解。 ? 


 ?
?
2、除法篇?
單片機中的除法也是二進制的除法,和現實中數學的除法類似,是從被除數的高位開始,按位對除數進行相除取余的運算,得出的余數再和之后的被除數一起再進行新的相除取余的運算,直到除不盡為止,因為單片機中的除法是二進制的,每個步驟除出來的商最大只有1,所以我們實際編程時可以把每一步的除法看作減法運算。 ? 例如:被除數R3R4=1100110001101101,除數R5=11000101,商R1R0,余數R2。步驟如下:
1、清空商R1R0,余數R2; 2、被除數放開最高位,第15位,為1,1比除數小,商為0,余數R2為1; 3、上一步余數并上被除數次高位,第14位,得11,11仍然比除數小,商為0,余數R2為11 4、直到放開第8位后,得11001100,比除數大,商得1,余數R2為111; 5、上一步余數并上被除數第7位,得1110,沒有除數大,商為0,余數R2為1110; 6、上一步余數并上被除數第6位,得11101,沒有除數大,商為0,余數R2為11101; 7、按照以上步驟,直到放開了被除數得第3位,得11101101,比除數大,商為1,余數R2為101000; 8、上一步余數并上被除數第2位,得1010001,沒有除數大,商為0,余數R2為1010001; 9、上一步余數并上被除數第1位,得10100010,沒有除數大,商為0,余數R2為10100010; 10、上一步余數并上被除數第0位,得101000101,比除數大,商為1,余數R2為10000000; 11、然后把以上所有步驟中得商從左至右依次排列就是最后的商100001001,余數為最后算得的余數10000000。 以上例子運算結果:R1R0 = R3R4 / R5 = 100001001 ;R2 = R3R4 % R5 = 10000000 ? 實際運算流程圖見下圖: ?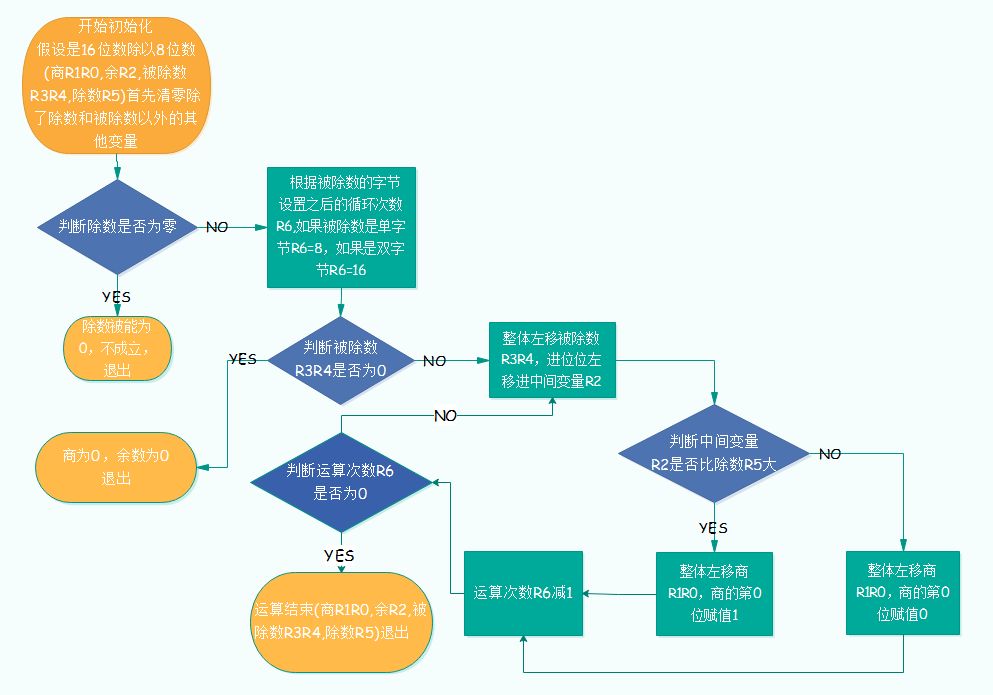 ? ?
? ?
除法運算的效率,代碼量見以下表格 ? 表2.1是程序運行效率和代碼量的對比數據(可能會有小的偏差),很明顯本文提供的匯編算法要優化的很多。 ?
16/8位除法 |
匯編 |
C語言 |
時鐘周期 |
287-321 |
740-804 |
使用空間(Byte) |
35 |
142 |
表2.1? 除法運算時鐘周期對比表 ? 所以對于除法運算,本文提供的方法也是相對較優的。 ? 以下是針對精簡指令集做的除法運算,16/8位的例程,便于大家的移植和理解。
? ? 











 工商網監
工商網監
評論