 電子發燒友App
電子發燒友App


大家好,今天我們來介紹一個用于億級實時數據分析架構Lambda架構。
Lambda架構
Lambda架構(Lambda Architecture)是由Twitter工程師南森·馬茨(Nathan Marz)提出的大數據處理架構。這一架構的提出基于馬茨在BackType和Twitter上的分布式數據處理系統的經驗。
Lambda架構使開發人員能夠構建大規模分布式數據處理系統。它具有很好的靈活性和可擴展性,也對硬件故障和人為失誤有很好的容錯性。
Lambda架構總共由三層系統組成:批處理層 (Batch Layer), 速度處理層 (Speed Layer),以及用于響應查詢的 服務層 (Serving Layer)。
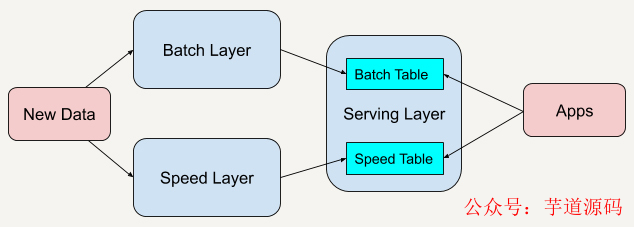
在Lambda架構中,每層都有自己所肩負的任務。
批處理層存儲管理主數據集(不可變的數據集)和預先批處理計算好的視圖。
批處理層使用可處理大量數據的分布式處理系統預先計算結果。它通過處理所有的已有歷史數據來實現數據的準確性。這意味著它是基于完整的數據集來重新計算的,能夠修復任何錯誤,然后更新現有的數據視圖。輸出通常存儲在只讀數據庫中,更新則完全取代現有的預先計算好的視圖。
速度處理層會實時處理新來的大數據。
速度層通過提供最新數據的實時視圖來最小化延遲。速度層所生成的數據視圖可能不如批處理層最終生成的視圖那樣準確或完整,但它們幾乎在收到數據后立即可用。而當同樣的數據在批處理層處理完成后,在速度層的數據就可以被替代掉了。
本質上,速度層彌補了批處理層所導致的數據視圖滯后。比如說,批處理層的每個任務都需要1個小時才能完成,而在這1個小時里,我們是無法獲取批處理層中最新任務給出的數據視圖的。而速度層因為能夠實時處理數據給出結果,就彌補了這1個小時的滯后。
所有在批處理層和速度層處理完的結果都輸出存儲在服務層中,服務層通過返回預先計算的數據視圖或從速度層處理構建好數據視圖來響應查詢。
我們舉個這樣的例子:假如用戶A的電腦暫時借給用戶B使用了一下,而用戶B瀏覽了一些新的網站類型(與用戶A不同)。這種情況下,我們無法判斷用戶A實際上是否對這類型的廣告感興趣,所以不能根據這些新的瀏覽記錄給用戶A推送廣告。那么我們如何做到既能實時分析用戶新的網站瀏覽行為又能兼顧到用戶的網站瀏覽行為歷史呢?這就可以利用Lambda架構。
所有的新用戶行為數據都可以同時流入批處理層和速度層。批處理層會永久保存數據并且對數據進行預處理,得到我們想要的用戶行為模型并寫入服務層。而速度層也同時對新用戶行為數據進行處理,得到實時的用戶行為模型。
而當“應該對用戶投放什么樣的廣告”作為一個查詢(Query)來到時,我們從服務層既查詢服務層中保存好的批處理輸出模型,也對速度層中處理的實時行為進行查詢,這樣我們就可以得到一個完整的用戶行為歷史了。
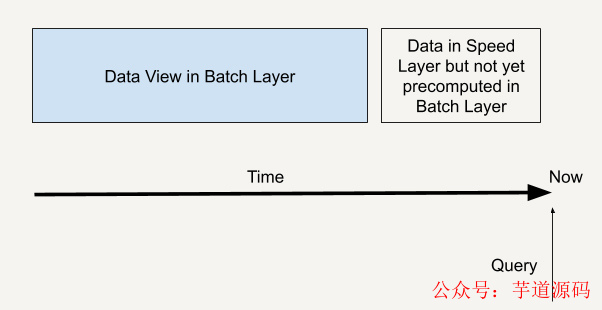
一個查詢就如下圖所示,既通過批處理層兼顧了數據的完整性,也可以通過速度層彌補批處理層的高延時性,讓整個查詢具有實時性。
Lambda架構在硅谷一線大公司的應用已經十分廣泛,我來帶你一起看看一些實際的應用場景。
Twitter的數據分析案例
Twitter在歐美十分受歡迎,而Twitter中人們所發Tweet里面的Hashtag也常常能引爆一些熱搜詞匯,也就是Most Popular Hashtags。下面我來給你講述一下如何利用Lambda架構來實時分析這些Hashtags。
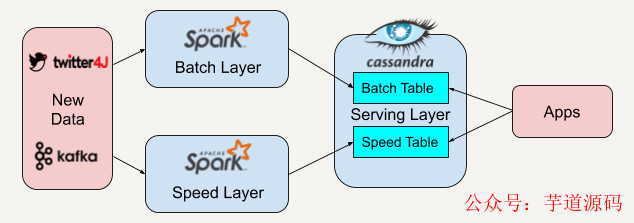
在這個實際案例里,我們先用twitter4J的流處理API抓取實時的Twitter推文,同時利用Apache Kafka將抓取到的數據保存并實時推送給批處理層和速度層。
因為Apache Spark平臺中既有批處理架構也兼容了流處理架構,所以我們選擇在批處理層和速度層都采用Apache Spark來讀取來自Apache Kafka的數據。
批處理層和速度層在分析處理好數據后會將數據視圖輸出存儲在服務層中,我們將使用Apache Cassandra平臺來存儲他們的數據視圖。Apache Cassandra將批處理層的視圖數據和速度層的實時視圖數據結合起來,就可以得到一系列有趣的數據。
例如,我們根據每一條Tweet中元數據(Metadata)里的location field,可以得知發推文的人的所在地。而服務層中的邏輯可以根據這個地址信息進行分組,然后統計在不同地區的人所關心的Hashtag是什么。
時間長達幾周或者的幾個月的數據,我們可以結合批處理層和速度層的數據視圖來得出,而快至幾個小時的數據我們又可以根據速度層的數據視圖來獲知,怎么樣?這個架構是不是十分靈活?
看到這里,你可能會問,我在上面所講的例子都是來自些科技巨頭公司,如果我在開發中面對的數據場景沒有這么巨大,又或者說我的公司還在創業起步階段,我是否可以用到Lambda架構呢?
答案是肯定的!我們一起來看一個在硅谷舊金山創業公司的App后臺架構。
Smart Parking案例分析
在硅谷地區上班生活,找停車位是一大難題。這里地少車多,每次出行,特別是周末,找停車位都要繞個好幾十分鐘才能找得到。
智能停車App就是在這樣的背景下誕生的。這個App可以根據大規模數據所構建的視圖推薦最近的車位給用戶。
看到這里,我想先請你結合之前所講到的廣告精準投放案例,思考一下Lambda架構是如何應用在這個App里的,然后再聽我娓娓道來。
好,我們來梳理一下各種可以利用到的大數據。
首先是可以拿到各類停車場的數據。這類數據的實時性雖然不一定高,但是數據的準確性高。那我們能不能只通過這類大數據來推薦停車位呢?
我舉個極端的例子。假設在一個區域有三個停車場,停車場A現在只剩下1個停車位了。
停車場B和C還有非常多的空位。而在這時候距離停車場比A較近的位置有10位車主在使用這個App尋求推薦停車位。如果只通過車主和停車場的距離和停車場剩余停車位來判斷的話,App很有可能會將這個只剩下一個停車位的停車場A同時推薦給這10位用戶。
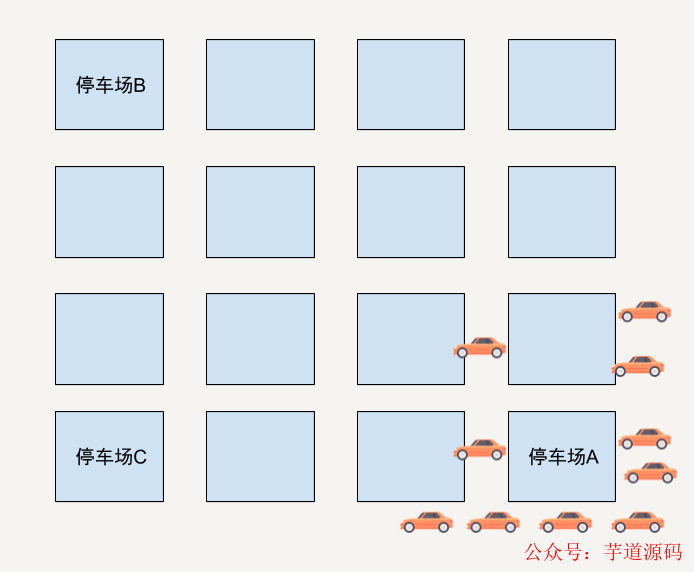
結果可想而知,只有一位幸運兒能找到停車位,剩下的9位車主需要重新尋找停車位。
如果附近又出現了只有一個停車位的停車場呢?同理,這個App又會推薦這個停車場給剩下的9位用戶。這時又只能有一位幸運兒找到停車位。
如此反復循環,用戶體驗會非常差,甚至會導致用戶放棄這個App。
那我們有沒有辦法可以改進推薦的準確度呢?
你可能會想到我們可以利用這些停車場的歷史數據,建立一個人工智能的預測模型,在推薦停車位的時候,不單單考慮到附近停車場的剩余停車位和用戶與停車場的相鄰距離,還能將預測模型應用在推薦里,看看未來的一段時間內這個停車場是否有可能會被停滿了。
這時候我們的停車位推薦系統就變成了一個基于分數(Score)來推薦停車位的系統了。
好了,這個時候的系統架構是否已經達到最優了呢?你有想到應用Lambda架構嗎?
沒錯,這些停車場的歷史數據或者每隔半小時拿到的停車位數據,我們可以把它作為批處理層的數據。
那速度層的數據呢?我們可以將所有用戶的GPS數據聚集起來,這些需要每秒收集的GPS數據剛好又是速度層所擅長的實時流處理數據。從這些用戶的實時GPS數據中,我們可以再建立一套預測模型來預測附近停車場位置的擁擠程度。
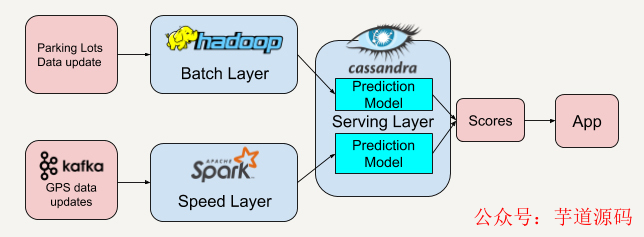
服務層將從批處理層和速度層得到的分數結合后將得到最高分數的停車場推薦給用戶。這樣利用了歷史數據(停車場數據)和實時數據(用戶GPS數據)能大大提升推薦的準確率。
總結
在了解Lambda架構后,我們知道Lambda架構具有很好的靈活性和可擴展性。我們可以很方便地將現有的開源平臺套用入這個架構中,如下圖所示。
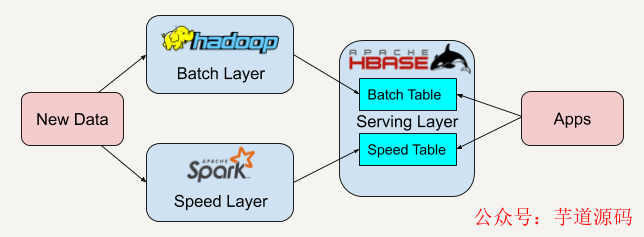
當開發者需要遷移平臺時,整體的架構不需要改變,只需要將邏輯遷移到新平臺中。
例如,可以將Apache Spark替換成Apache Storm。而因為我們有批處理層這一概念,又有了很好的容錯性。
假如某天開發者發現邏輯出現了錯誤,只需要調整算法對永久保存好的數據重新進行處理寫入服務層,經過多次迭代后整體的邏輯便可以被糾正過來。現在有很多的開發項目可能已經有了比較成熟的架構或者算法了。
但是如果我們平時能多思考一下現有架構的瓶頸,又或者想一想現在的架構能不能改善得更好,有了這樣的思考,在學習到這些經典優秀架構之后,說不定真的能讓現有的架構變得更好。
編輯:黃飛
?













 工商網監
工商網監
評論