 電子發燒友App
電子發燒友App


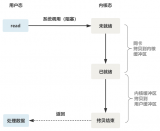
通常我們寫一個linux的client和server如下圖:
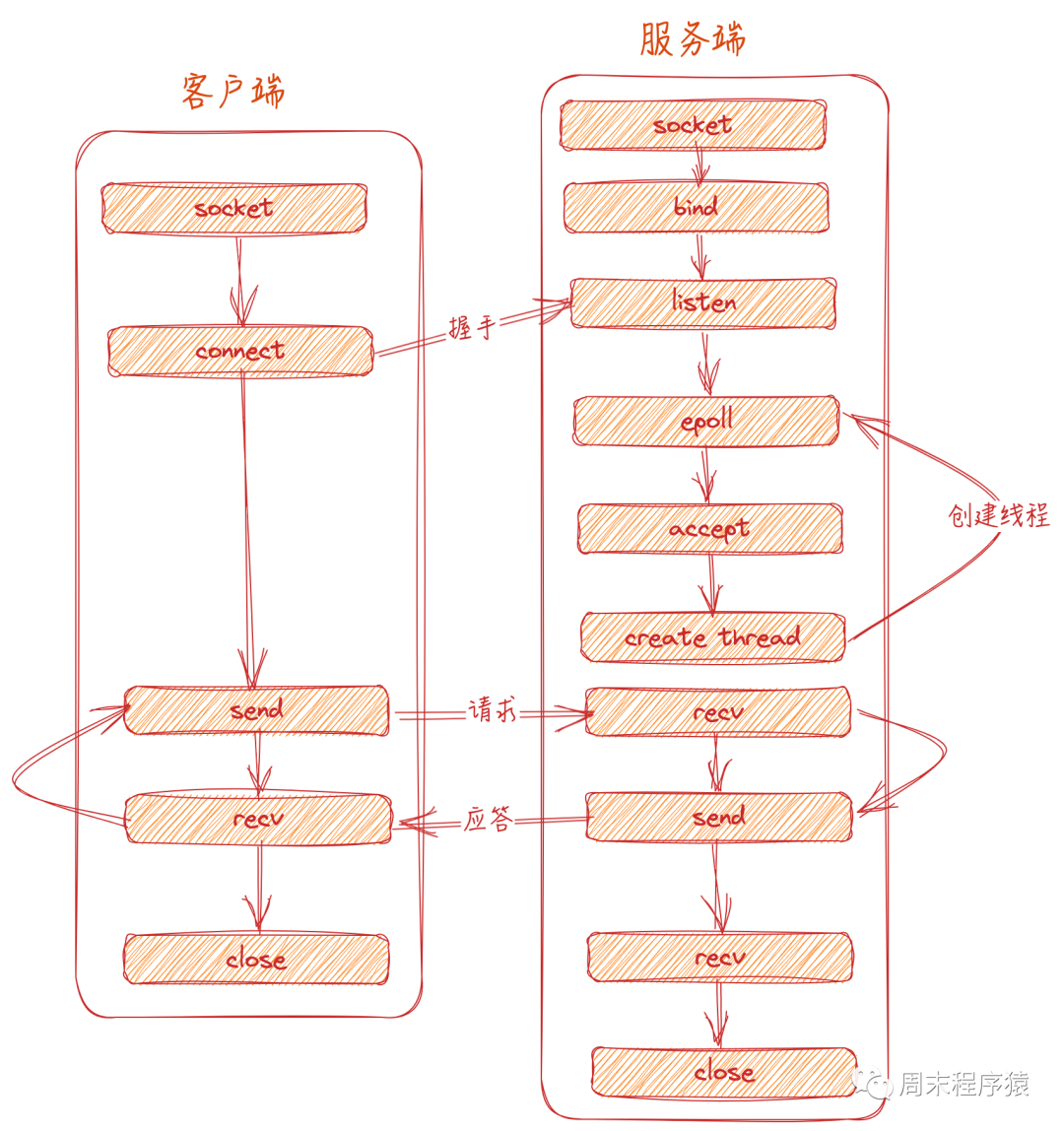
網絡圖
但是怎么提升性能?系統是如何快速處理網絡事件?因此本文就來談談IO復用和模式。
第一部分:模式
我們都知道socket分為阻塞和非阻塞,阻塞情況就是卡住流程,必須等事件發生;而非阻塞是立即返回,不管事件是否有沒有準備好,需要上層代碼通過EAGAIN,EWOULDBLOCK和EINPROGRESS等errno返回值來判斷,基于非阻塞有兩種網絡編程模式:Reactor和Proactor事件處理。
1、Reactor
同步IO模型一般使用Reactor,如果使用線程模式,Reactor是遇到事件就通知工作線程處理,然后主線程繼續循環等待事件的發生:

reactor
(1)對于網絡讀寫,先將socket注冊到epoll內核事件表中;
(2)使用epoll_wait等待句柄的讀寫事件;
(3)當句柄的可讀可寫事件發生,通知工作線程執行對應的讀寫動作;
(4)當工作線程處理完讀寫動作,如果還有后續讀寫,工作線程可以將句柄繼續注冊到epoll內核事件表中;
(5)主線程繼續用epoll_wait等待事件發生,然后繼續告知工作線程處理;
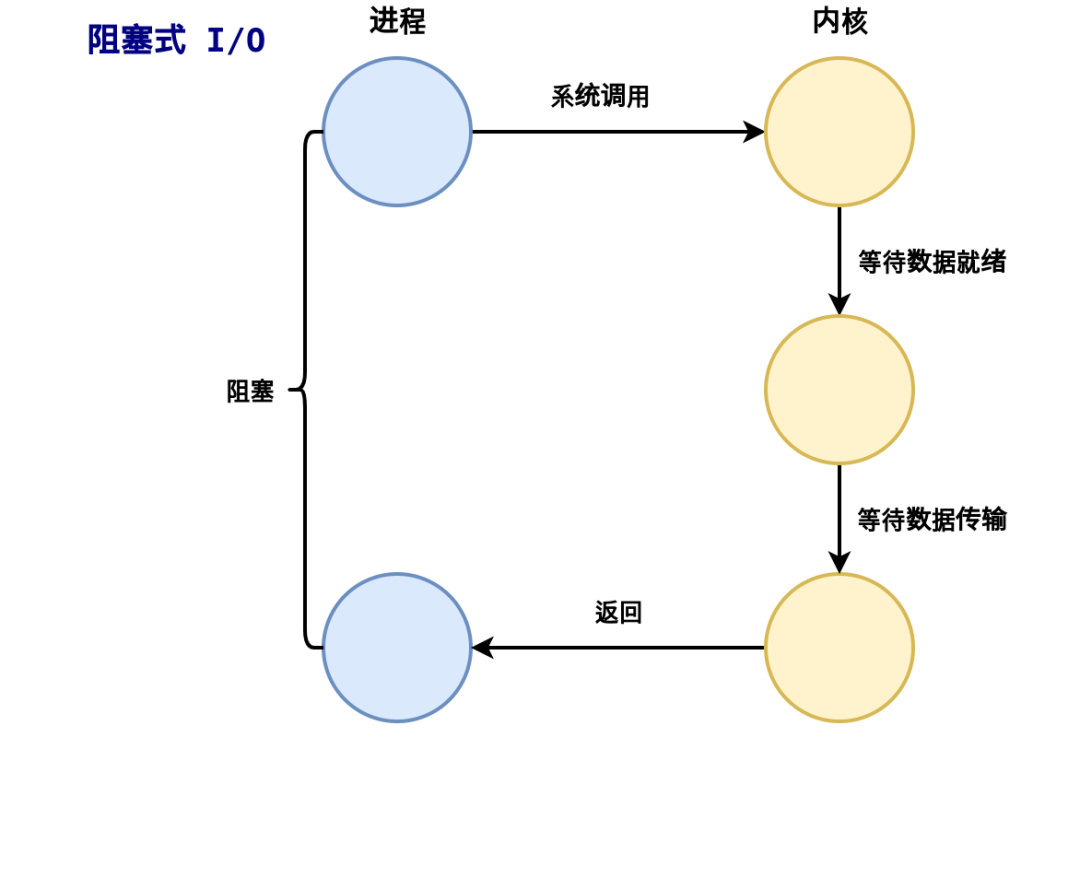
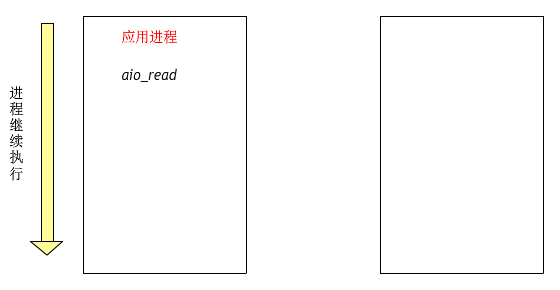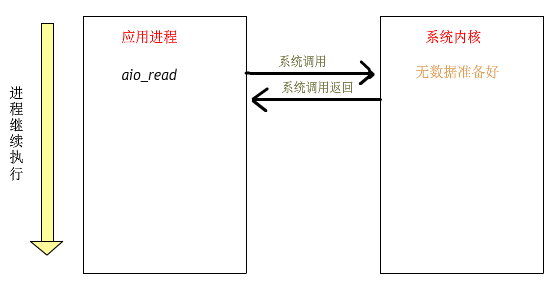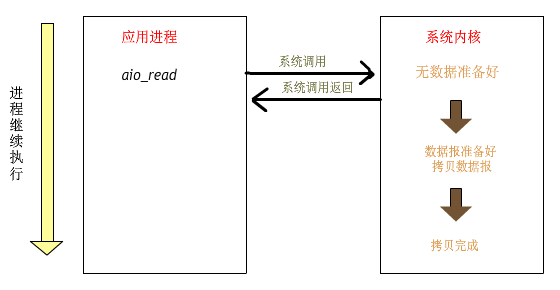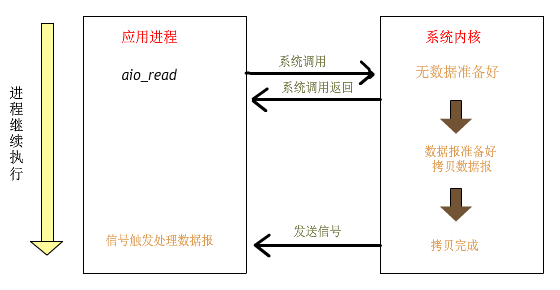
2、Proactor
在講Proactor之前我們先說說一個例子:
...
#include < libaio.h >
int main() {
io_context_t context;
struct iocb io[1], *p[1] = {&io[0]};
struct io_event e[1];
...
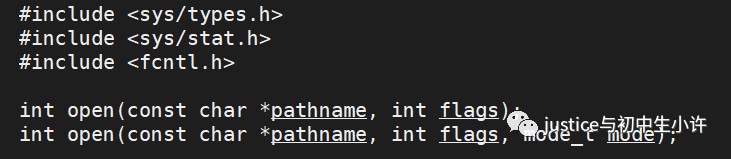
// 1. 打開要進行異步IO的文件
int fd = open("xxx", O_CREAT|O_RDWR|O_DIRECT, 0644);
if (fd < 0) {
printf("open error: %dn", errno);
return 0;
}
// 2. 創建一個異步IO上下文
if (0 != io_setup(nr_events, &context)) {
printf("io_setup error: %dn", errno);
return 0;
}
// 3. 創建一個異步IO任務
io_prep_pwrite(&io[0], fd, wbuf, wbuflen, 0);
// 4. 提交異步IO任務
if ((ret = io_submit(context, 1, p)) != 1) {
printf("io_submit error: %dn", ret);
io_destroy(context);
return -1;
}
while (1) {
// 5. 獲取異步IO的結果
ret = io_getevents(context, 1, 1, e, &timeout);
if (ret < 0) {
printf("io_getevents error: %dn", ret);
break;
}
...
}
...
}
以上就是linux的aio處理一個讀寫文件的流程,可以看到整個流程不需要工作線程處理,而是由內核直接處理后,主線程只需要等待處理結果即可。

proactor
3、Half-Reactor
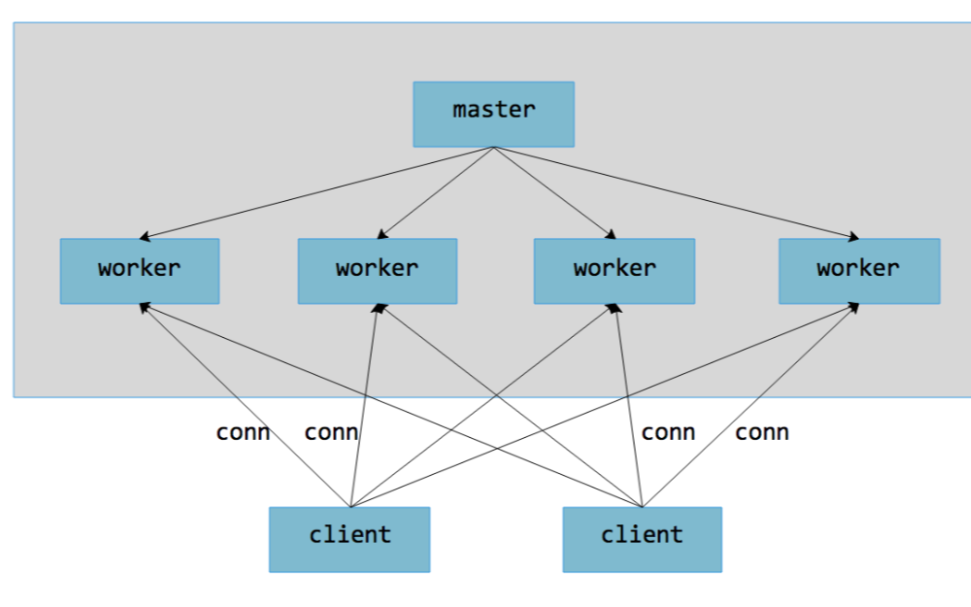
前面提到Reactor大家從圖中看出,都是主線程等待事件,分發事件,然后工作線程爭搶事件后處理,這里會有幾個缺點:
(1)工作線程需要加鎖取出自己的工作任務,浪費CPU;
(2)工作線程取出隊列一次只能處理一個,對于CPU密集型的任務可以跑滿CPU,但是如果是IO密集型任務,這個工作線程又會切換到休眠或者等待其他任務,不能充分利用CPU;
為了解決以上缺點,于是提出了Half-Reactor半反應堆模式:

Half-Reactor
第二部分:IO復用
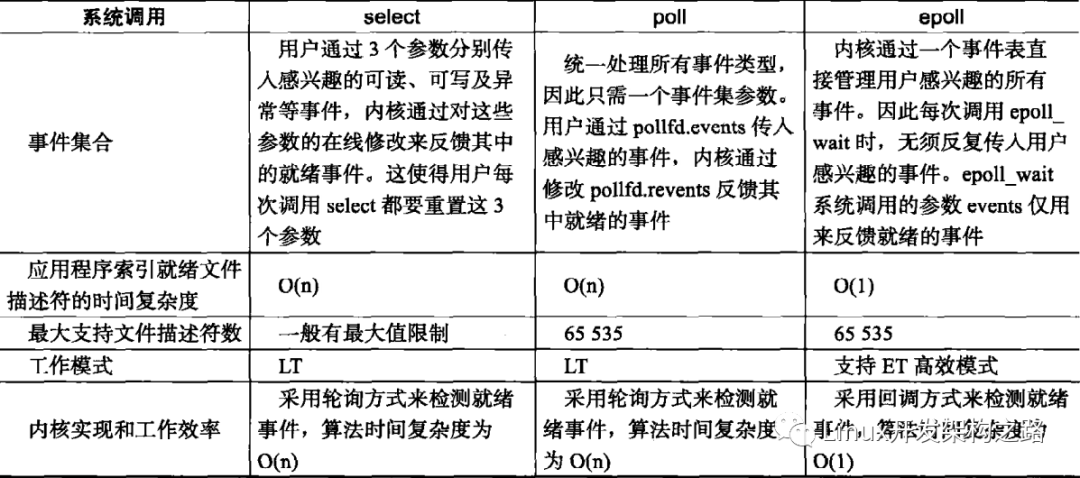
在開發一些業務面前,我們可能會面對C10K,C100K或者C10M等問題,只是靠堆服務器可能不能完全解決,所以我們就需要從IO復用來處理服務的并發能力,這里我們就直接講epoll(對于select,poll和epoll的大概區別應該都知道了,所以就不詳細說了,如果有疑問可以留言給我),同時找了一張libevent的幾個事件處理性能對比:

libevent
1、epoll的使用
#include < sys/epoll.h >
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
(1)epoll_create創建一個內核事件表,size可以指定大小,但是并沒有作用;
(2)epoll_ctl操作事件,epfd就是epoll事件表,op指定操作類型(EPOLL_CTL_ADD往事件表添加fd,EPOLL_CTL_MOD往事件表修改fd,EPOLL_CTL_DEL往事件表刪除fd);
(3)struct epoll_event其結構體:
sturct epoll_event
{
_uint32_t events; // EPOLLIN(數據可讀),EPOLLOUT(數據可寫)...
epoll_data_t data; // 用于存儲用戶監聽事件句柄需要在上下文攜帶的用戶數據
}
(4)epoll_wait等待事件發生,events返回發生事件的列表,timeout等待一定的超時時間,如果沒有事件發生依舊返回,maxevents最多一次監聽集合的大小;
2、LT和ET
(1)LT是epoll對文件操作符的模式,表示電平觸發(Level Trigger),當epoll_wait監聽了事件,上層可以不處理該事件,下一次epoll_wait依舊會觸發;
(2)ET是epoll對文件描述符的高效模式,表示邊緣觸發(Edge Trigger),當epoll_wait監聽了事件,如果不處理下一次不會再觸發,需要應用層一次就處理完,這樣可以減少觸發的次數,從而提升性能。
所以要注意對于read使用將套接口設置為非阻塞,再用while循環包住read一直讀到產生EAGAIN錯誤,采用非阻塞套接口的原因在于防止read被阻塞住。
3、樣例
詳細代碼由于篇幅原因,就不寫了,大概流程如下:
...
listen_fd = bind(...);
listen(listen_fd, LISTENQ);
int epoll_fd;
struct epoll_event events[10];
int nfds, i, fd;
...
// 創建一個描述符
epoll_fd = epoll_create(...);
// 添加監聽描述符事件
epoll_ctl(epoll_fd, ... listen_fd, ... EPOLLIN);
for ( ; ; )
{
nfds = epoll_wait(epoll_fd, events, sizeof(events)/sizeof(events[0]), 1000);
for (i = 0; i < nfds; i++)
{
fd = events[i].data.fd;
if (fd == listen_fd)
{
// 創建新連接
...
}
else if (events[i].events & EPOLLIN)
{
// 讀取socket數據
....
}
else if(events[i].events & EPOLLOUT)
{
// 寫入socket數據
...
}
}
}
close(epoll_fd);
4、epoll的實現
epoll底層數據結構是紅黑樹和鏈表組成,通過epoll_ctrl增加、減少事件,其中epoll結構體如下:
struct eventpoll
{
wait_queue_head_t wq;
struct list_head rdlist;
struct rb_root rbr;
...
}

epoll
(1)wq是等待隊列,用于epoll_wait;
(2)rdlist是就緒隊列,當有事件觸發時候,內核會將句柄等信息放入rdlist,方便快速獲取,不需要遍歷紅黑樹;
(3)rbr是一顆紅黑樹,支持增加,刪除和查找,管理用戶添加的socket信息;
第三部分:提升網絡編程中服務器性能的建議
在網絡編程中我們會遇到各種各樣的處理任務,比如純轉發的proxy,需要處理https的server,需要處理任務的業務邏輯server等等,而且在微服務時代和云原生時代可能這些問題更加復雜,比如我們需要在server前加上斷路器,在容器服務中我們都適用多線程模式等等。雖然面臨很多問題,但是網絡編程中服務器性能還是最基礎的那些問題,于是基于我的一些經驗,我整理了一些。
1、復用
(1)線程復用 :前面提到的工作線程,我們不應該對于每個客戶端都開一個線程,而是構建一個線程pool,當某些線程空閑就可以從隊列中取事件或者數據進行處理,畢竟linux中的線程和進程調度方式一樣,線程太多必然加劇內核的負載;
(2)內存復用 :在網絡狀態流轉和工作線程流轉過程中,我們需要盡可能考慮內存復用,而不是在每一層中都拷貝,比如一個請求從內核讀到數據以后,盡可能在當前請求的什么周期內,一直使用相同的內存塊(包括在業務層,盡量使用指針偏移量操作),減少拷貝;
當然減少內存拷貝以外,還需要做的就是同一塊內存用完不是讓系統回收,而是自己放到內存pool中,等待下一次請求需要再復用;
2、減少內存拷貝
這里上一篇文章提到的零拷貝,就是減少內存拷貝的一種方式,比如在文件讀寫方面能提升性能(可以參考nginx的sendfile),另一種可以使用共享內存,通過一寫多讀的方式解決一些場景下的內存拷貝;
3、減少上下文切換和競爭
上下文切換是阻礙性能提升的一個問題,比如頻繁的事件觸發會導致主線程和工作線程之間切換,其CPU時間會被浪費;小量的數據包多次觸發讀處理等。因此我們在寫server過程中對于能在同一個上下文處理的,就不必要再丟該其他線程處理,對于多個小塊數據可以等待一段超時時間一起處理(當然具體問題可以分析);
競爭也是阻礙性能提升的一個問題,掙搶共享資源會一段CPU時間片內阻塞操作,減少鎖的使用或者將鎖拆分更加細粒度的鎖,減少鎖住臨界區的范圍,是我們需要注意的;
4、利用CPU親和性
這里以nginx為例,提供了一個worker_cpu_affinity,cpu的親和性能使nginx對于不同的work工作進程綁定到不同的cpu上面去。就能夠減少在work間不斷切換cpu,進程通常不會在處理器之間頻繁遷移,進程遷移的頻率小,來減少性能損耗。
這種可以參考CPU性能提升方式,比如在NUMA下,處理器訪問它自己的本地存儲器的速度比非本地存儲器(存儲器的地方到另一個處理器之間共享的處理器或存儲器)快一些,所以針對NUMA架構系統的特點,可以通過將進程/線程綁定指定CPU(一個或多個)的方式,提高CPU CACHE的命中率,減少進程/線程遷移CPU造成的內存訪問的時間消耗,從而提高程序的運行效率。
5、協程
協程是一種用戶態線程,在現在主流的server框架,協程已經成為一個提升性能的銀彈(比如golang寫server又快又方便),后續文章會專門介紹協程(在此埋一個坑),但是協程也不是萬能的,需要定位本身業務特點,比如IO密集型就適合(當然這里也需要情況而定,比如純轉發類型的面對長尾延時,可能協程也不合適),CPU密集型自己調度協程還是比較麻煩的,所以在做優化的適合可以拷貝業務的特性和后續的擴展而定,畢竟沒有一個框架是萬能的。
















 工商網監
工商網監
評論