 電子發(fā)燒友App
電子發(fā)燒友App


虛擬內(nèi)存技術(shù)
虛擬內(nèi)存技術(shù)是操作系統(tǒng)實(shí)現(xiàn)的一種高效的物理內(nèi)存管理方式,具有以下作用:
- 使得進(jìn)程間彼此隔離 :通過將物理內(nèi)存和虛擬地址空間聯(lián)系起來,并將虛擬地址空間與進(jìn)程一一對應(yīng),每個(gè)進(jìn)程都認(rèn)為自己擁有了整個(gè)物理內(nèi)存,使得進(jìn)程之間彼此隔離。這讓操作系統(tǒng)在運(yùn)行多個(gè)進(jìn)程的同時(shí)也保障了內(nèi)存訪問的安全。
- 使得進(jìn)程共享物理內(nèi)存 :將物理內(nèi)存進(jìn)行虛擬化后,多個(gè)進(jìn)程可以同時(shí)共享同一塊物理內(nèi)存。
- 提升物理內(nèi)存利用率 :有了虛擬地址空間后,操作系統(tǒng)只需要將進(jìn)程當(dāng)前正在使用的部分?jǐn)?shù)據(jù)或指令加載入物理內(nèi)存,沒有在使用的部分?jǐn)?shù)據(jù)或指令則可以存儲(chǔ)在外存中,而不需要將整個(gè)進(jìn)程的數(shù)據(jù)或指令全部載入物理內(nèi)存。這使得操作系統(tǒng)可以在相對較小的物理內(nèi)存下運(yùn)行更多的進(jìn)程,從而提升了物理內(nèi)存的利用率。
- 方便內(nèi)存管理 :虛擬內(nèi)存技術(shù)將物理內(nèi)存分割成若干塊,每塊都可以分配給不同的進(jìn)程使用,這使得操作系統(tǒng)可以更加靈活地管理內(nèi)存。如物理內(nèi)存分配、回收等。
頁式內(nèi)存管理技術(shù)
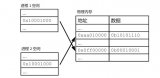
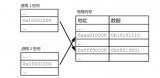
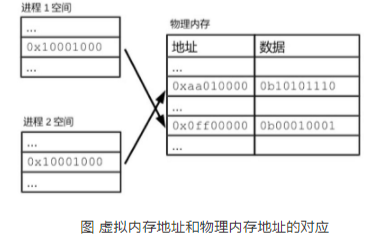
頁式內(nèi)存管理技術(shù)是 Linux 實(shí)現(xiàn)的一種虛擬內(nèi)存技術(shù),其基本思想是將物理內(nèi)存和虛擬內(nèi)存都分割成多個(gè)固定大小的 Page(頁),然后對這些 Pages 進(jìn)行編址,并通過 Page Table(頁表)將它們一一映射起來。當(dāng) CPU 訪問虛擬地址空間時(shí),Linux 會(huì)通過 Page Table 將虛擬地址轉(zhuǎn)換為物理地址。
- Virtual Address(虛擬地址) :操作系統(tǒng)和應(yīng)用程序使用的虛擬內(nèi)存地址。
- Physical Address(物理地址) :實(shí)際的物理內(nèi)存地址。
Linux 通過頁式內(nèi)存管理技術(shù),除了能夠高效地管理物理內(nèi)存之外,還提供了許多額外的虛擬內(nèi)存功能,例如:進(jìn)程隔離、內(nèi)存保護(hù)、共享物理內(nèi)存等。
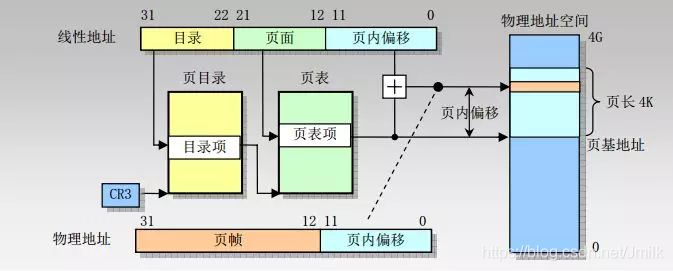
虛擬地址格式與頁表(32bit 系統(tǒng))
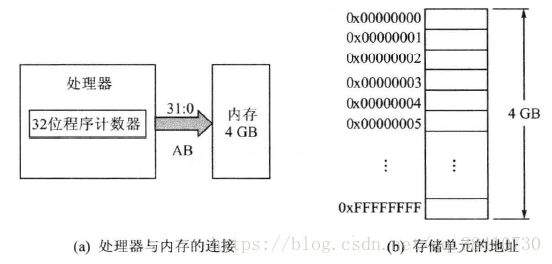
在 x86 32bit Linux 系統(tǒng)中,虛擬地址(也稱為線性地址,Linear Address)的格式由 3 部分組成,總長度為 32bit,尋址范圍為 2^32,最大可描述空間為 4G。
- Page Table Directory(10bit)
- Page Table Entry(10bit)
- Offset(12bit)
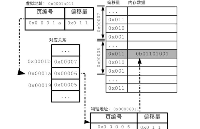
在 Kernel 中用于對虛擬地址進(jìn)行尋址的數(shù)據(jù)結(jié)構(gòu)稱為 Kernel Page Table(內(nèi)核頁表),包括:
- 頁表目錄(Page Directory):可包含 1024 個(gè)目錄項(xiàng)。
- 目錄項(xiàng)(Directory Entry):每個(gè)目錄項(xiàng)指向一個(gè)頁表,即有 1024 個(gè)頁表。
- 頁表(Page Table):大小為 4KB,頁表項(xiàng)的大小為 4B,即一個(gè)頁表可包含 1024 個(gè)頁表項(xiàng)。
- 頁表項(xiàng)(Page Table Entry):每個(gè)頁表項(xiàng)指向一個(gè)頁。
- 屬性標(biāo)記:用于將每個(gè)頁表項(xiàng)標(biāo)記為只讀、可寫、只執(zhí)行等,以控制內(nèi)存的訪問權(quán)限和緩存行為。
可見,32bit 系統(tǒng)中的 2 級頁表結(jié)構(gòu),最多可以映射 1024*1024 個(gè) Pages。而對于大于 4GB 的物理地址空間,則需要使用多級級頁表結(jié)構(gòu),以支持更大的物理內(nèi)存空間。
虛擬地址格式與頁表(64bit 系統(tǒng))
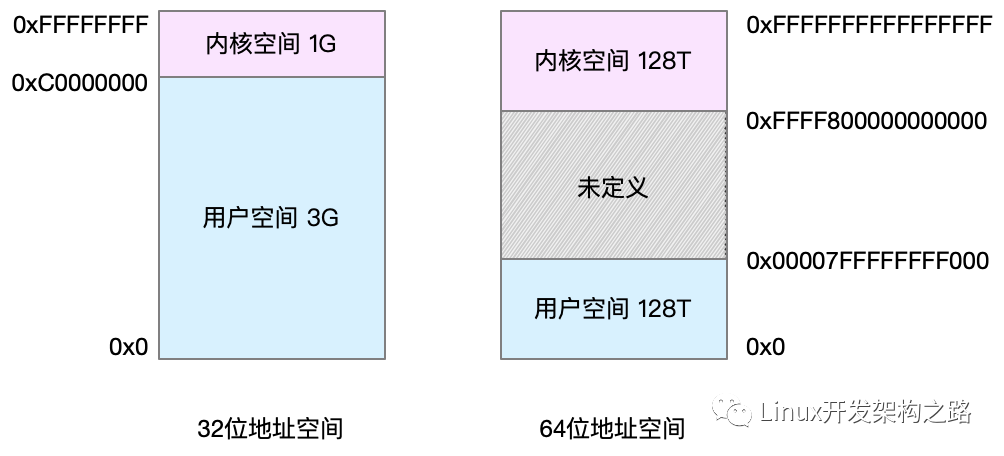
在 x86 64bit 系統(tǒng)中,可以描述的最長地址空間為 2^64(16EB),遠(yuǎn)遠(yuǎn)超過了目前主流內(nèi)存卡的規(guī)格,所以在 Linux 中只使用了 48bit 長度,尋址空間為 2^48(256TB),User Space 和 Kernel Space 各占 128T。尋址空間分別為:
- User Space :0x0000 0000 0000 0000~0x0000 7FFF FFFF F000,高 16bit 全 0。
- Canonical Address Space :0x0000 7FFF FFFF F000 - 0xFFFF 8000 0000 0000,無效地址空間。
- Kernel Space :0xFFFF 8000 0000 0000~0xFFFF FFFF FFFF FFFF,高 16bit 全 1。
由于內(nèi)存空間的擴(kuò)大,x86 64bit 系統(tǒng)中的虛擬地址格式由 5 部分組成,占 64bit 中的 48bit。相應(yīng)的,Linux Kernel 在 v2.6.10 中實(shí)現(xiàn)了四級頁表,后來又在 v4.11 中引入了五級的頁表結(jié)構(gòu)。
就四級頁表而言,虛擬內(nèi)存空間被劃分成了 4 個(gè)層次結(jié)構(gòu),每一級都有一個(gè)頁表來記錄該層次的映射關(guān)系。
- PGD(Page Global Directory,全局頁目錄)
- PUD(Page Upper Directory,上級頁目錄)
- PMD(Page Middle Directory,中間頁目錄)
- PTE(Page Table Entry,頁表項(xiàng))
當(dāng) CPU 需要訪問一個(gè)虛擬地址時(shí),會(huì)執(zhí)行以下頁表遍歷流程:
- 首先根據(jù)虛擬地址的 GLOBAL DIR(9bit) ,確定在 PGD 中的頁表項(xiàng),開始尋址 PUD。
- 再根據(jù)虛擬地址中的 UPPER DIR(9bit) ,確定 PUD 中的頁表項(xiàng),開始尋址 PMD。
- 再根據(jù)虛擬地址中的 MIDDLE DIR(9bit) ,確定 PMD 中的頁表項(xiàng),開始尋址 PTE。
- 再根據(jù)虛擬地址中的 TABLE ID(9bit) ,確定 PTE 中的頁表項(xiàng),開始尋址 Physical Page(物理內(nèi)存頁框)。
- 最后根據(jù)虛擬地址中的 OFFSET(12bit) ,確定 Physical Page 中的 Page Lane(頁條)。
在頁表遍歷的過程中,如果找到對應(yīng)的物理頁框,則可以進(jìn)行對應(yīng)的內(nèi)存讀寫操作。反之,如果遇到了尋址失敗的情況,則說明對應(yīng)的物理頁框沒有被分配或者被換出到外存了,此時(shí)需要進(jìn)行相應(yīng)的頁表調(diào)度和頁表交換操作。

四級頁表的優(yōu)點(diǎn)是它可以映射非常大的虛擬內(nèi)存空間,并且每個(gè)進(jìn)程的頁表都是獨(dú)立的,相互干擾。缺點(diǎn)是每次訪問內(nèi)存都需要遍歷四級頁表,這會(huì)導(dǎo)致一定的性能損失。并且,當(dāng) Linux 設(shè)定的虛擬頁大小越小時(shí),單個(gè)進(jìn)程中的頁表項(xiàng)和虛擬頁也就越多,頁表的層級也可能越多,查詢性能就越低。同時(shí)也需要注意,頁面并非是越大越好,因?yàn)檫^大的頁面會(huì)造成內(nèi)存碎片,降低了內(nèi)存的利用率。
因此,Linux 采用了一些優(yōu)化措施,如 TLB(Translation Look-aside Buffer)緩存等,來加速頁表遍歷的過程。

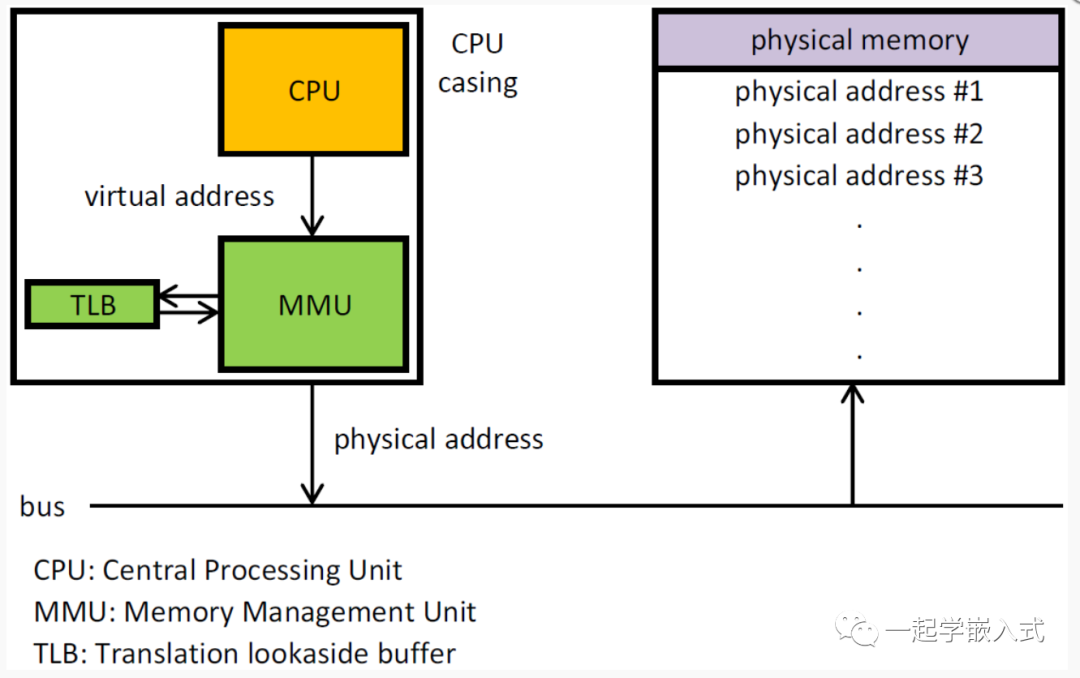
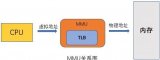
CPU MMU 虛實(shí)地址轉(zhuǎn)換
Linux 虛實(shí)地址轉(zhuǎn)換功能,除了需要由 Kernel 實(shí)現(xiàn)的內(nèi)核頁表(Page Table)數(shù)據(jù)結(jié)構(gòu)之外,還需要硬件層面的 CPU MMU(Memory Management Unit,存儲(chǔ)管理單元)支持。
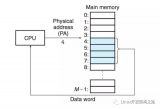
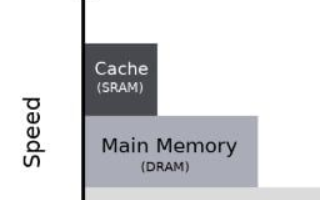
MMU(Memory Management Unit,內(nèi)存管理單元)內(nèi)嵌在 CPU 芯片上,它是一個(gè)專用的硬件,利用存放在 Main Memory 中的 Page Table 來輔助完成虛實(shí)地址之間的動(dòng)態(tài)翻譯,而 Page Table 的內(nèi)容就交由 Kernel 來統(tǒng)一管理。
當(dāng) CPU 訪問虛擬地址時(shí),MMU 首先將虛擬地址的高位部分作為頁表的索引,查找對應(yīng)的頁表項(xiàng)。頁表項(xiàng)中存儲(chǔ)了與虛擬頁對應(yīng)的物理頁的起始地址以及一些標(biāo)志位,如是否可讀、可寫等。然后,MMU 將虛擬地址的低位部分作為偏移量,加上物理頁的起始地址,得到實(shí)際的物理地址。

TLS 快表轉(zhuǎn)換
TLB(Translation Look-aside Buffer,翻譯旁路緩沖器)同樣是內(nèi)嵌在 CPU 芯片上的一個(gè)專用硬件,作為緩存,旁掛在 MMU 上,緩存了最近訪問過的虛擬地址與物理地址之間的映射關(guān)系,以便在下次訪問時(shí)快速地進(jìn)行翻譯。TLB 的空間非常有限,一般只可緩存幾十個(gè)到數(shù)百個(gè)條目。
通過 TLB,操作系統(tǒng)可以旁路掉多級頁表遍歷的流程,只需要在 TLB 中執(zhí)行一次高速訪問即可,前提是沒有 TLB Miss(緩存失效)。如果 Miss 的話,就會(huì)回到常規(guī)的頁表遍歷流程,然后再利用局部性原理去更新 TLB。

虛擬地址空間與 CPU 運(yùn)行模式

為了保障多任務(wù)實(shí)時(shí)操作系統(tǒng)運(yùn)行的安全性和穩(wěn)定性,Intel x86 CPU 提供了 Ring0-3 這 4 種不同的運(yùn)行模式,而 Linux 只使用了其中的 Ring0(特權(quán)指令模式)和 Ring3(非特權(quán)指令模式),為虛擬地址空間提供了 2 級保護(hù)機(jī)制。

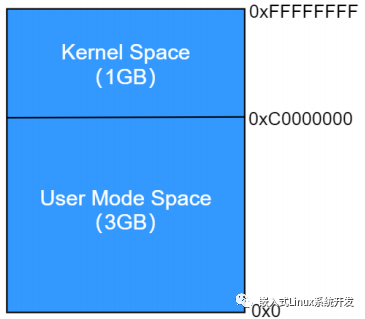
相應(yīng)的,在 32bit Linux 系統(tǒng)中,大小為 4G 的虛擬地址空間,被分成了 2 個(gè)部分:
- User Space(0x0~0xBFFF FFFF,0~3G) :每個(gè) User Process 都有自己的 User Space 且互相隔離。運(yùn)行在 CPU Ring3(用戶模式)模式,User Process 的代碼被限制了可以執(zhí)行的操作以及可以訪問的資源范圍;
- Kernel Space(0xC000 0000~0xFFF FFFF,3~4G) :屬于 Kernel 的 Kernel Space。運(yùn)行在 CPU Ring0(內(nèi)核模式)模式,Kernel 代碼沒有被限制,可以執(zhí)行任何操作并且可以訪問任何資源。
所以,Linux 中的 Page Table 也可以被分為 2 種:
- 內(nèi)核頁表區(qū) :用于 Kernel Space 高端內(nèi)存映射區(qū)與物理地址空間之間的映射。
- 進(jìn)程頁表區(qū) :每個(gè) User Process 擁有自己的頁表,用于進(jìn)程虛擬地址空間與物理地址空間之間的映射。

另外,User Space 可以通過 SCI(系統(tǒng)調(diào)用接口)來訪問或操作 Kernel Space 的代碼和數(shù)據(jù),同時(shí)也會(huì)觸發(fā) CPU 運(yùn)行模式的切換。例如:C 標(biāo)準(zhǔn)庫中的 malloc() 函數(shù)底層調(diào)用了 sbrk() 或 brk() SCI 來分配堆內(nèi)存;printf() 函數(shù)底層調(diào)用了 wirte() SCI 來輸出字符串等等。

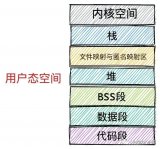
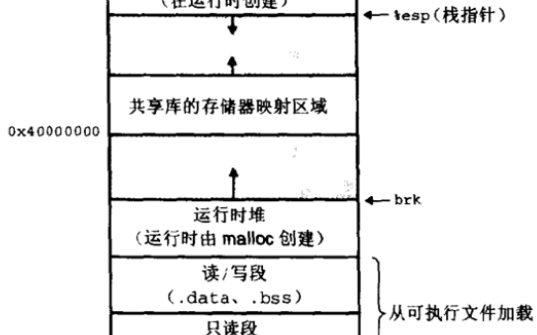
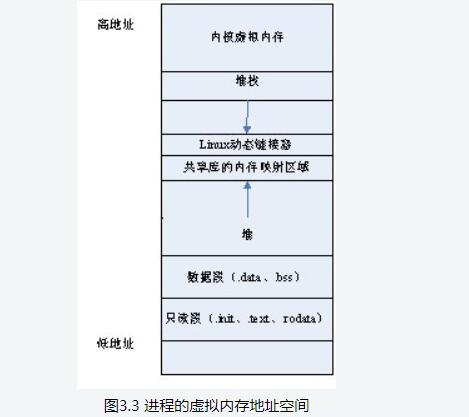
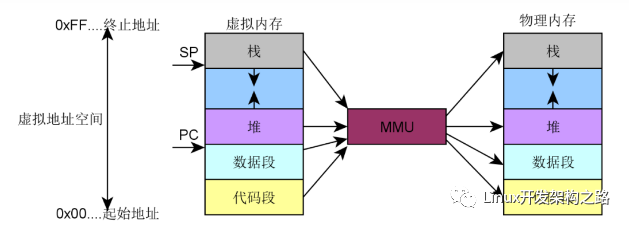
虛擬地址空間的布局(32bit 系統(tǒng))

從上圖可以看出 Linux 對虛擬地址空間作了復(fù)雜的分段布局,主要是為了實(shí)現(xiàn)更加高效的內(nèi)存管理和保護(hù)機(jī)制。
以 User Space 為例:
- 持久化的程序流代碼(順序程序流、條件程序流、循環(huán)程序流)存儲(chǔ)在 Test Segment 中。
- 持久化的、且初始化的常量、全局變量、靜態(tài)變量(包括靜態(tài)全局變量、靜態(tài)局部變量)存儲(chǔ)在 Data Segment 中。
- 持久化的、但未初始化的全局變量、靜態(tài)變量(包括靜態(tài)全局變量、靜態(tài)局部變量)存儲(chǔ)在 BSS Segment 中。
- 臨時(shí)的函數(shù)局部變量存儲(chǔ)在 Stack Segment 中。
- 臨時(shí)由用戶自主申請的數(shù)據(jù)存儲(chǔ) Heap Segment 或 MMAP Segment 中。
劃分不同的存儲(chǔ)空間更有助于針對不同的數(shù)據(jù)內(nèi)容進(jìn)行合理的訪問和存儲(chǔ)規(guī)劃。例如:
- 提高 CPU Cache 利用率 :將指令區(qū)、持久數(shù)據(jù)區(qū)、動(dòng)態(tài)數(shù)據(jù)區(qū)進(jìn)行分離,有利于應(yīng)用局部性原理來發(fā)揮出 CPU Instruction Cache(指令緩存)和 Data Cache(數(shù)據(jù)緩存)的優(yōu)勢。
- 節(jié)省內(nèi)存空間 :如果系統(tǒng)中運(yùn)行多個(gè)該程序的副本時(shí),指令區(qū)中的 Read Only 數(shù)據(jù)可被共享,物理內(nèi)存實(shí)際上只需要存儲(chǔ)一份。
User Space
在 User Space 中,每個(gè) User Process 都有一個(gè) task_struct(進(jìn)程描述符)。
struct task_struct {
pid_t pid; // User Process ID
pid_t tgid; // Kernel Thread ID
struct files_struct *files; // 文件描述符
struct mm_struct *mm; // 內(nèi)存映射描述符
...
}
其中,除了 Environment Variables(程序運(yùn)行時(shí)環(huán)境變量)和 Command-line arguments(程序運(yùn)行指令行參數(shù))之外,進(jìn)程虛擬地址空間的內(nèi)存布局都通過 mm_struct 結(jié)構(gòu)體來進(jìn)行描述。

Stack Segment(用戶棧)
User Process 下屬的每個(gè) User Thread 都有屬于自己的用戶線程棧。主要用于存儲(chǔ)以下信息:
- 存儲(chǔ)函數(shù)調(diào)用信息(Procedure Activation Record,過程活動(dòng)記錄)或棧幀(Stack Frame)。
- 存儲(chǔ)函數(shù)內(nèi)部的非靜態(tài)(Non-static)變量;
- 提供臨時(shí)存儲(chǔ)區(qū),使用 C 標(biāo)準(zhǔn)庫 alloca() 函數(shù)可動(dòng)態(tài)申請棧內(nèi)內(nèi)存。
Stack Segment 的空間具有 “靜態(tài)分配" 和 “動(dòng)態(tài)分配” 這 2 種使用形勢。其中,靜態(tài)分配由 C 編譯器自動(dòng)分配和管理,主要應(yīng)用在函數(shù)處理流程。而動(dòng)態(tài)分配則由程序通過 alloca() 函數(shù)主動(dòng)申請和釋放。
例如:在一次函數(shù)調(diào)用中,C 編譯器依次入棧的數(shù)據(jù)包括:
- 主調(diào)函數(shù)下一條語句(指令);
- 被調(diào)函數(shù)的返回值地址;
- 被調(diào)函數(shù)的實(shí)際參數(shù);
- 被調(diào)函數(shù)局部變量等。
通過先進(jìn)后出(FILO)的數(shù)據(jù)結(jié)構(gòu),使得被調(diào)函數(shù)退出后,可以繼續(xù)執(zhí)行主調(diào)函數(shù)的語句。
Stack Segment 是一塊連續(xù)的空間,運(yùn)行時(shí)大小可以由 Kernel 動(dòng)態(tài)調(diào)整(向下增長),且最大容量 RLIMIT_STACK(8M)由系統(tǒng)預(yù)先定義,用戶也可以通過 ulimit -s 指令來查看和設(shè)定棧的最大值。
$ ulimit -s
8192
當(dāng)程序入棧數(shù)據(jù)超出容量之后,就會(huì)觸發(fā) Stack Overflow(溢出)錯(cuò)誤,此時(shí)程序收到一個(gè) Segmentation Fault(段錯(cuò)誤)異常。
函數(shù)調(diào)用棧的工作原理
程序每執(zhí)行一次函數(shù)調(diào)用都會(huì)在 Stack 中生成一個(gè)棧幀(Stack Frame),對應(yīng)著一個(gè)未運(yùn)行完的主調(diào)函數(shù),用于存儲(chǔ)被調(diào)函數(shù)的執(zhí)行環(huán)境信息,包括:函數(shù)實(shí)際參數(shù)、函數(shù)局部變量、函數(shù)返回值地址等等。
棧幀主要通過兩個(gè)指針寄存器來實(shí)現(xiàn):
- ebp(幀指針) :指向幀底,作為基址指針,不會(huì)移動(dòng)。
- esp(棧指針) :指向棧頂,可以移動(dòng),通過移動(dòng) esp 來訪問棧幀中的數(shù)據(jù)。
ebp 到 esp 之間的地址空間就是用于存儲(chǔ)當(dāng)前被調(diào)函數(shù)執(zhí)行環(huán)境信息的空間。
另外,Stack Segment 很可能會(huì)同時(shí)存在多個(gè)棧幀(函數(shù)嵌套調(diào)用),此時(shí)多個(gè)棧幀會(huì)根據(jù)函數(shù)調(diào)用順序在 Stack Segment 中先入后出。
例如:雖然 esp 會(huì)隨著當(dāng)前函數(shù)的入棧和出棧而不斷移動(dòng),但由于 ebp 的存在,所以當(dāng)前函數(shù)棧幀的邊界始終是清晰的。當(dāng)被調(diào)函數(shù)退出后,ebp 就會(huì)跳到主函數(shù)棧幀的底部,esp 也會(huì)隨其自然的來到主函數(shù)棧幀的頭部。

Memory Mapping Segment(內(nèi)存映射段)
Memory Mapping Segment(內(nèi)存映射段)的空間通過 mmap() SCI(系統(tǒng)調(diào)用接口)來使用,用于將外存(e.g. 硬盤)中的一個(gè)文件、或一段物理內(nèi)存直接映射到 Memory Mapping Segment 中,而后 User Process 就可以采用指針的方式來訪問一段內(nèi)存,而不必再調(diào)用 read() / write() 等 SCI。mmap() 是一種高效的 I/O 方式。

Memory Mapping Segment 主要有 2 類應(yīng)用場景:
- File mappings(文件映射) :在程序裝載過程中,將程序所需要 #include 的 .so 動(dòng)態(tài)共享庫文件(Dynamic share libraries)加載到 Memory Mapping Segment 內(nèi)存空間。
- Anonymous mappings(匿名內(nèi)存映射) :C 標(biāo)準(zhǔn)庫 malloc() 函數(shù)的底層實(shí)現(xiàn)方式之一就是對大于 MMAP_THRESHOLD(默認(rèn)為 128KB)的空間申請,會(huì)調(diào)用 mmap() SCI 從 Memory Mapping Segment 中分配,而不是調(diào)用 sbrk() 或 brk() SCI 從 Heap 申請。
Memory Mapping Segment 的空間大小同樣可以由 Kernel 動(dòng)態(tài)調(diào)整(向上增長)。
Heap Segment(運(yùn)行時(shí)堆)
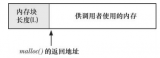
Heap Segment(運(yùn)行時(shí)堆)的空間由程序自行使用,包括分配和釋放。例如:開發(fā)者可通過 C 標(biāo)準(zhǔn)庫 malloc() 函數(shù)申請并返回 void*(無類型指針),且無名稱,只能通過指針訪問。
在 Kernel 層面通過堆管理器來管理 Heap Segment 的空間。堆管理器通過鏈表存儲(chǔ)結(jié)構(gòu)來記錄 Heap Segment 空間的使用情況,記錄了包括:空閑的內(nèi)存地址、已使用的內(nèi)存地址等。
當(dāng)程序申請一塊內(nèi)存時(shí),堆管理器會(huì)遍歷鏈表尋找第一個(gè)空間大于所申請空間的節(jié)點(diǎn),并返回地址給程序,然后將該節(jié)點(diǎn)從空閑鏈表中刪除。所以 Heap 空間中的多個(gè)內(nèi)存塊之間很可能是不連續(xù)的。
當(dāng)目前的 Heap Segment 已經(jīng)沒有足夠的空間時(shí)(可能由于內(nèi)存碎片太多導(dǎo)致的),那么堆管理器可能會(huì)通過 brk() 或 sbrk() SCI 進(jìn)行動(dòng)態(tài)調(diào)整(向上增長),實(shí)際上是通過調(diào)整 Heap Segment 末端的 break 指針來實(shí)現(xiàn)。
Heap Segment 的空間總大小受到 CPU 架構(gòu)和操作系統(tǒng)位數(shù)影響,例如:32bit 架構(gòu)的 Heap Segment 最大可達(dá) 2.9G 空間。
應(yīng)用程序裝載與數(shù)據(jù)段
當(dāng)開發(fā)者經(jīng)過編碼、編譯、匯編、鏈接一個(gè) C 程序后就得到了一個(gè)可執(zhí)行程序的文件。然后,就需要通過程序裝載器(Loader)將可執(zhí)行文件加載到 User Space 中并啟動(dòng)一個(gè) User Process。在 Linux 上,可執(zhí)行文件采用的是 ELF(Executable and Linkable File Format,可執(zhí)行與可鏈接文件格式)格式。
ELF 文件由 4 部分組成,分別是:
- ELF Header
- Program Header Table(程序頭表)
- Sections(節(jié))
- Section Header Table(節(jié)頭表)

其中,位于 Program Header Table 和 Section Header Table 之間的都是 Sections,這些 Sections 中的數(shù)據(jù)會(huì)在程序啟動(dòng)時(shí)被加載到相應(yīng)的進(jìn)程虛擬地址空間中。
關(guān)鍵的 Sections 包括以下幾個(gè):
- .bss :存儲(chǔ)未初始化的全局變量和靜態(tài)變量。
- .data :存儲(chǔ)已初始化的全局變量和靜態(tài)變量。
- .rodata :存儲(chǔ)只讀數(shù)據(jù)(e.g. 常量)。
- .text :存儲(chǔ)已編譯程序的機(jī)器指令代碼。
- .debug :調(diào)試符號(hào)表,調(diào)試器用此段的信息幫助調(diào)試。

數(shù)據(jù)段(BSS Segment 和 Data Segment)
BSS Segment 和 Data Segment 常被合并稱為 “數(shù)據(jù)段”,都用于存儲(chǔ)全局變量和靜態(tài)變量,區(qū)別于存儲(chǔ)在 Stack Segment 中的函數(shù)局部變量。
- BSS(Block Started by Symbol,未初始化的數(shù)據(jù)段) :可讀寫,主要存儲(chǔ)了從 ELF .bss section 中加載的數(shù)據(jù),包括:1)已定義,但未初始化的全局變量和靜態(tài)變量;2)已定義,且初始值為 0 的全局變量和靜態(tài)變量,例如 C 編譯器中的空指針。
- Data Segment(已初始化的數(shù)據(jù)段) :可讀寫,主要存儲(chǔ)了從 ELF .data section 中加載的數(shù)據(jù),包括:已定義、且已初始化、且初值不為 0 的全局變量、靜態(tài)變量和常量。所以,Data Segment 也被稱為 “靜態(tài)存儲(chǔ)區(qū)(Static data area)”。
ELF .bss section 的特別之處在于沒有具體的數(shù)值,所以只需要記錄下全局變量和靜態(tài)變量所需要的內(nèi)存空間大小即可,但并不會(huì)分配真實(shí)的內(nèi)存空間,即:只記錄了全局變量和靜態(tài)變量在虛擬地址空間中的開始和結(jié)束地址。
當(dāng)程序加載器(Loader) 將 ELF .bss section 加載到 BSS Segment 后,這些數(shù)據(jù)會(huì)被 C 編譯器自動(dòng)的初始化為 0 或 NULL。這樣可以有效的減少了 C object file 的體積。
例如:對于 int arr0[10000] = {1, 2, 3, …} 和 int ar1[10000] 這兩個(gè)數(shù)組而言:
- arr0 存儲(chǔ)在 Data Segment,記錄了每個(gè)數(shù)組元素的數(shù)值。
- arr1 存儲(chǔ)在 BSS Segment,只記錄了 arr1 的起始和結(jié)束地址,直到程序啟動(dòng)時(shí)才被編譯器在相應(yīng)的虛擬地址空間中刷 0。顯著的減少了可執(zhí)行文件的大小。
Text Segment(代碼段)
Text Segment(代碼段)主要存儲(chǔ)了從 ELF .text section 中加載的機(jī)器指令。
Text Segment 中的數(shù)據(jù)只能讀不能寫,但可以被執(zhí)行,即:Text Segment 中的數(shù)據(jù)是可共享的,可以被其他的進(jìn)程執(zhí)行。例如:機(jī)器中有數(shù)個(gè)進(jìn)程運(yùn)行相同的一個(gè)程序,那么它們就可以使用同一個(gè)代碼段。
可見,User Space 劃分了明確的 “數(shù)據(jù)區(qū)” 和 “指令區(qū)",且數(shù)據(jù)區(qū)對于進(jìn)程而言可讀寫,而指令區(qū)對于進(jìn)程只讀,以防止程序指令被誤改。
內(nèi)存缺頁中斷
基于 Linux 虛擬內(nèi)存管理技術(shù),每個(gè) User Process 都擁有自己獨(dú)立的虛擬地址空間,當(dāng)一個(gè) User Process 被 Kernel 加載并運(yùn)行時(shí),無需要一次性將 User Process 所有數(shù)據(jù)都加載到 Main Memory 中,而是當(dāng)通過 Page Table 缺頁中斷的方式來動(dòng)態(tài)加載。
虛擬地址的頁表遍歷過程中,當(dāng)訪問到某個(gè)頁面時(shí),通過頁表項(xiàng)中的有效位,可以得知此頁面是否在內(nèi)存中,如果不存在,則通過缺頁異常,將磁盤對應(yīng)的數(shù)據(jù)拷貝到內(nèi)存中,如果沒有空閑內(nèi)存,則選擇犧牲頁面,替換掉其他頁面。在這個(gè)時(shí)候,被內(nèi)存映射的文件實(shí)際上成了一個(gè)分頁交換文件。

Kernel Space

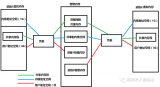
Kernel Space 與物理地址空間的映射關(guān)系
區(qū)別于 User Space 只擁有虛擬地址空間。Kernel Space 除了虛擬地址空間之外,還直接擁有一部分的物理地址空間。也就是說 Kernel Space 具有 2 種地址映射關(guān)系,如下圖所示。
- 直接映射(Linear Mapped) :Kernel Space 虛擬地址空間中的 3G~3G+896M 與物理地址空間的 0~896M 直接一對一映射,擁有最高的效率。
- 動(dòng)態(tài)映射(Dynamic Mapped) :Kernel Space 虛擬地址空間中的高端內(nèi)存映射區(qū)(0xF800 0000 ~ 0xFFFF FFFF)動(dòng)態(tài)的與物理地址空間 896M~4G 中的某塊物理頁面建立映射(通過 Page Table),即:在有需要的時(shí)候才建立映射,待使用完之后就釋放映射,以供其它物理頁面映射。

物理地址空間布局
基于不同的用途,Linux 將物理內(nèi)存劃分為 3 個(gè) ZONEs,從地址低到高為:
- ZONE_DMA(0~16M) :是 Kernel 直接映射的物理地址空間。
- ZONE_NORMAL(16M~896M) :是 Kernel 直接映射的物理地址空間,Kernel 將需要頻繁使用的數(shù)據(jù)存放于此。
- ZONE_HIGHMEM(896M~4G) :是 Kernel 動(dòng)態(tài)映射到物理地址空間,Kernel 將不常用數(shù)據(jù)存放于此,只在要訪問這些數(shù)據(jù)時(shí)才建立映射關(guān)系。

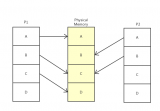
最終,通過結(jié)合兩種映射方式,Linux Kernel 可以完全接管整個(gè) 4G 物理內(nèi)存空間。如下圖所示,藍(lán)色區(qū)域?yàn)橹苯佑成淇臻g,綠色區(qū)域?yàn)閯?dòng)態(tài)映射空間,棕色區(qū)域?yàn)閯?dòng)態(tài)映射頁面。

物理直接映射區(qū)
根據(jù) User Process 對 Kernel Space 訪問權(quán)限的不同,還可以將 Kernel Space 分為 “進(jìn)程私有” 和 “進(jìn)程共享” 這 2 塊區(qū)域。
- 進(jìn)程私有區(qū)域 :每個(gè)進(jìn)程都有單獨(dú)的內(nèi)核棧、頁表、task 結(jié)構(gòu)以及 mem_map 結(jié)構(gòu)等。
- 進(jìn)程共享區(qū)域 :屬于所有進(jìn)程共享的內(nèi)存區(qū)域,包括:物理存儲(chǔ)器、內(nèi)核數(shù)據(jù)和內(nèi)核代碼區(qū)域。

Kernel Space 中的物理直接映射區(qū),屬于 “進(jìn)程共享區(qū)域",是為了讓 Kernel Space 或者 User Space 可以直接訪問某些特殊的物理內(nèi)存區(qū)域。這些物理內(nèi)存區(qū)域包括:
- ZONE_DMA :NIC、GPU 此類 I/O 外設(shè)所提供的 DMA Controller 只能對內(nèi)存的前 16M 進(jìn)行尋址。為了方便設(shè)備驅(qū)動(dòng)程序的實(shí)現(xiàn),Linux 通過物理直接映射區(qū),使得 Kernel 和 User Process 可以直接訪問這些外設(shè)的存儲(chǔ)器。此外,在 ZONE_DMA 中還劃分了用于 BIOS ROM 和 VGA 適配器的區(qū)域,地址為 640K~1M 。
- ZONE_NORMAL :常規(guī)內(nèi)存區(qū)域,沒有特殊的使用限制,主要用于 User Process 和 Kernel 之間的交互,以及作為文件緩存加快文件系統(tǒng)的訪問速度,避免頻繁地讀寫磁盤。例如:存放 Kernel Image(內(nèi)核代碼)、mem_map 數(shù)組等數(shù)據(jù)。
可見,物理直接映射區(qū)使得 Kernel 和 User Process 得以更方便地訪問一些特殊的物理內(nèi)存區(qū)域,從而簡化了操作系統(tǒng)和設(shè)備驅(qū)動(dòng)程序的編寫。
DMA 直接內(nèi)存訪問
DMA(Direct Memory Access,直接內(nèi)存訪問)指的是主機(jī)的 I/O 外設(shè)對 Main Memory 的直接訪問。有了 DMA 機(jī)制之后,外設(shè)跟主存之間的數(shù)據(jù)交互主要由 DMA Controller 來完成的,從而避免了 CPU(包括 MMU)的參與。

高端內(nèi)存映射區(qū)
物理內(nèi)存中的 ZONE_NORMAL(高端內(nèi)存區(qū)域)大小為 4G - 896M = 3200M,遠(yuǎn)遠(yuǎn)大于 Kernel Space 剩余的 1G - 896M = 128M 虛擬地址空間。所以 Kernel 對 ZONE_NORMAL 的訪問需要采用動(dòng)態(tài)映射的方式。
Kernel Space 中的 128M 統(tǒng)稱為 “高端內(nèi)存映射區(qū)”,主要有以下 3 個(gè)部分組成:
- Fixing Kernel Mapping(固定映射區(qū))/ Temporary Kernel Mapping(臨時(shí)映射區(qū))
- Persistent Kernel Mapping(持久映射區(qū))
- Vmalloc Area / Loremap Area(動(dòng)態(tài)映射區(qū))

Fixing Kernel Mapping(固定映射區(qū))/ Temporary Kernel Mapping(臨時(shí)映射區(qū))
Fixing Kernel Mapping(固定映射區(qū))通常用于靜態(tài)分配內(nèi)存,例如:驅(qū)動(dòng)程序需要一段固定大小的內(nèi)存來存儲(chǔ)數(shù)據(jù)結(jié)構(gòu)或緩沖區(qū),它可以使用 Fixing Kernel Mapping 將一段物理內(nèi)存空間映射到內(nèi)核虛擬地址空間中,并在整個(gè)生命周期中保持映射關(guān)系。
Temporary Kernel Mapping(臨時(shí)映射區(qū))通常用于動(dòng)態(tài)分配內(nèi)存,例如:驅(qū)動(dòng)程序需要在運(yùn)行時(shí)創(chuàng)建一個(gè)臨時(shí)緩沖區(qū)來存儲(chǔ)數(shù)據(jù),它可以使用 Temporary Kernel Mapping 來創(chuàng)建一個(gè)臨時(shí)的虛擬內(nèi)存區(qū)域,映射到物理內(nèi)存空間中,并在使用完畢后釋放虛擬內(nèi)存空間。
Persistent Kernel Mapping(持久映射區(qū))
Persistent Kernel Mapping(持久映射區(qū))用于在 Kernel Space 中維護(hù)一組持久性的映射關(guān)系。這些映射通常是針對硬件設(shè)備或驅(qū)動(dòng)程序的,允許 Kernel 直接訪問這些設(shè)備或驅(qū)動(dòng)程序的存儲(chǔ)器區(qū)域。例如:用于 PCI I/O 外設(shè)進(jìn)行內(nèi)存映射的區(qū)域,大小由 PCI 規(guī)范決定。
Vmalloc Area(動(dòng)態(tài)映射區(qū))
Vmalloc Area(動(dòng)態(tài)映射區(qū))用于 Kernel 動(dòng)態(tài)分配內(nèi)存,例如:當(dāng) Kernel 需要訪問 I/O 外設(shè)的存儲(chǔ)空間時(shí),就會(huì)使用 ioremap() SCI 將位于物理地址空間中的 MMIO 內(nèi)存映射到 Kernel Space 的 vmalloc area 中,并在使用完之后釋放映射關(guān)系。
vmalloc() 和 kmalloc() 內(nèi)存分配函數(shù)
vmalloc() 和 kmalloc() 函數(shù)都用于從 Kernel Space 中申請內(nèi)存,但兩者有很大的不同:
- vmalloc() 用于從動(dòng)態(tài)內(nèi)存映射區(qū)申請非連續(xù)的物理內(nèi)存(通過內(nèi)核頁表映射),可以最大限度的使用高端物理內(nèi)存空間。通常應(yīng)用于為活動(dòng)的 Swap 交換分區(qū)分配數(shù)據(jù)結(jié)構(gòu)、或?yàn)槟承?I/O 驅(qū)動(dòng)程序分配緩沖區(qū)、或?yàn)閮?nèi)核模塊分配空間。
- kmalloc() 用于從直接內(nèi)存映射區(qū)申請連續(xù)的物理內(nèi)存(通過 Slab 分配器分配)。
與 User Space 中的 malloc() 不同,在 Kernel Space 進(jìn)行內(nèi)存申請是直接分配的,區(qū)別于 User Space 的延遲分配(通過缺頁機(jī)制來反饋)方式。一旦 vmalloc() 和 kmalloc() 申請內(nèi)存,那么 Kernel 就必須立刻滿足。













 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論