 電子發燒友App
電子發燒友App


摘要——1988年的互聯網蠕蟲病毒奪走了雛形網絡的十分之一,并嚴重地減慢了剩余網絡的速度[1]。30多年過去了,用類C語言編寫的代碼中最重要的兩類安全漏洞仍然是對內存安全的侵犯。
根據2019年的BlueHat演示文稿,微軟產品中解決的所有安全問題中,有70%是由違反內存安全造成的[2]。Google也報告了Android的類似數據,超過75%的漏洞是違反內存安全的【3】。雖然這些違規中的許多在較新的語言中是不可能的,但用C和C++編寫的在用代碼的基礎是龐大的。僅Debian Linux就包含了超過5億行。
本文介紹了Armv8.5-A內存標記擴展(MTE)。MTE的目標是提高用不安全語言編寫的代碼的內存安全性,而不需要更改源代碼,在某些情況下,也不需要重新編譯。對內存安全違規的可輕松部署的檢測和緩解措施可以防止一大類安全漏洞被利用。
簡介
內存安全的破壞分為兩大類:空間安全和時間安全。
可利用的違規行為是攻擊的第一階段,旨在傳送惡意負載或與其他類型的漏洞鏈接,以獲得系統控制權或泄漏特權信息。
當訪問對象超出其真實邊界時,空間安全就會受到侵犯。例如,當棧上的緩沖區溢出時。這可能會被利用來覆蓋函數的返回地址,這可能會成為幾種類型攻擊的基礎。
當對對象的引用超出范圍使用時,通常是在對象的內存被重新分配之后,就違反了時間安全性。例如,當包含某種類型的函數指針的類型被惡意數據覆蓋時,惡意數據也可以構成多種攻擊的基礎。
MTE提供了一種機制來檢測兩類主要的內存安全違規。MTE通過提高測試和Fuzzing的有效性來幫助在部署之前檢測潛在的漏洞。MTE還可以在部署后幫助大規模檢測漏洞。
Fuzzing是一種軟件測試技術,也稱為模糊測試。它通過向軟件系統輸入大量隨機、無效或異常的數據,來檢測系統在處理這些數據時是否會出現異常或崩潰。Fuzzing可以幫助發現軟件系統中的漏洞和安全問題,從而提高軟件系統的穩定性和安全性。
通過仔細的軟件設計,可以始終檢測到在真正邊界之前或之后立即訪問內存的順序安全違規。可以概率地檢測到地址空間中任意位置的“野生”違規。
在部署之前定位和修復漏洞,減少了部署代碼的攻擊面。在部署后大規模檢測漏洞,支持在漏洞被廣泛利用之前被動地修復漏洞。對網絡犯罪經濟學的研究【5】表明它對規模非常敏感。及時的檢測和被動的修補可能在大規模打擊網絡犯罪方面非常有效。
威脅模型
MTE旨在提供魯棒性,以抵御試圖破壞代碼處理攻擊者提供的惡意數據的攻擊。它不解決算法漏洞或惡意軟件。
MTE旨在檢測內存安全違規,并提高針對違規所導致的攻擊的魯棒性。在動態鏈接系統中,遺留代碼受益于MTE的堆分配,而無需重新編譯。
將MTE應用到堆棧需要重新編譯。MTE架構設計時,假設堆棧指針是可信的。因此,在為堆棧分配部署MTE時,將MTE與其他功能(例如分支目標識別(BTI)和指針驗證碼(PAC))結合使用非常重要,以降低存在允許攻擊者控制的小工具的可能性的堆棧指針。
MTE的內存安全
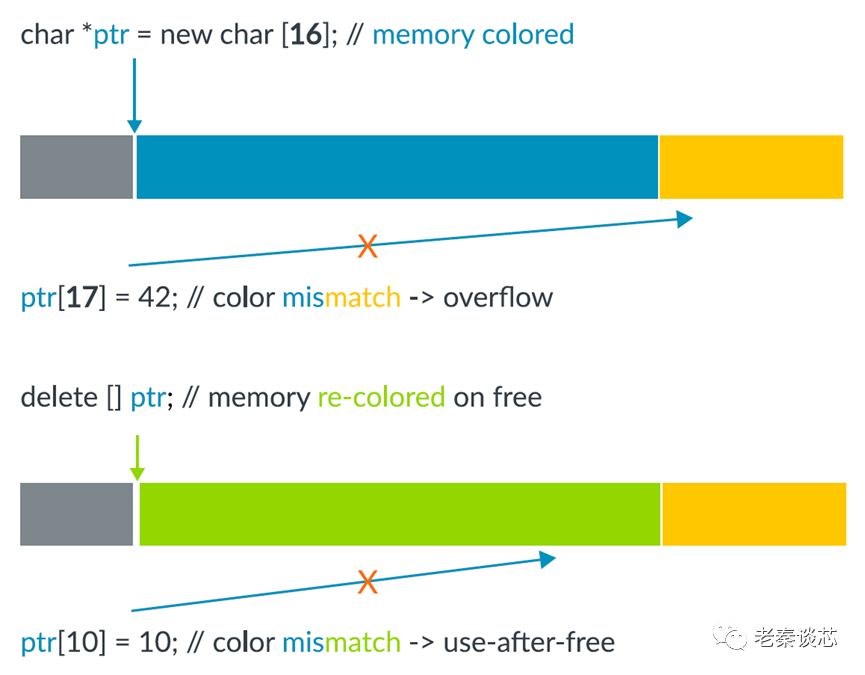
Arm內存標記擴展實現了對內存的鎖定和鍵訪問。可以在內存上設置鎖,在內存訪問時提供鍵。如果密鑰與鎖匹配,則允許訪問。如果不匹配,則會報錯。
通過在物理內存的每16字節中添加4位元數據來標記內存位置。這就是標簽顆粒。標記內存實現了鎖。
指針和虛擬地址都被修改為包含鍵。
為了在不需要更大指針的情況下實現密鑰位,MTE使用了Armv8-A架構的Top Byte Ignore (TBI)特性。當啟用TBI時,當將虛擬地址的最高字節用作地址轉換的輸入時,將忽略它。這允許頂部字節存儲元數據。在MTE中,最高字節的4位用于提供密鑰。
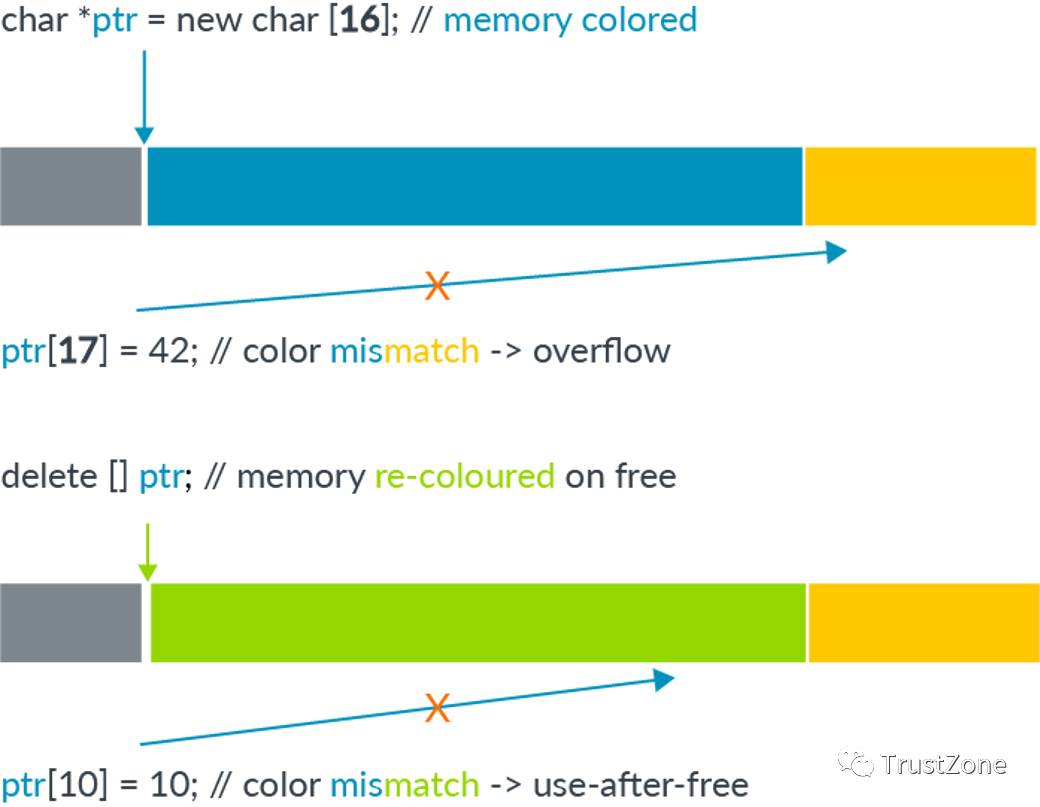
MTE依賴于鎖和密鑰的不同來檢測內存安全違規。
由于可用的標記位數有限,因此不能保證兩次內存分配對于任何特定的執行都具有不同的標記。但是,內存分配器可以確保順序分配的標記總是不同的,從而確保總是檢測到最常見的安全違規類型。
更普遍的是,MTE支持隨機標簽生成和基于種子的偽隨機標簽生成。在一個程序的執行次數足夠多的情況下,其中至少一個程序檢測到違規的概率趨于100%。
架構細節
MTE在Arm架構中增加了一種新的內存類型,即Normal Tagged Memory。
除了一些例外,如果可以靜態地確定訪問的安全性,加載和存儲到這個新的存儲器類型執行訪問,其中地址寄存器頂部字節中的標記與存儲在存儲器中的標記進行比較。
當不匹配配置為異步上報時,詳細信息將累積在系統寄存器中。提供了一個控制,以確保在進入以更高的異常級別運行的軟件時更新此寄存器。這使得操作系統內核能夠將不匹配的情況隔離到特定的執行線程,并基于這些信息做出決策。
同步異常的精確性在于,可以精確地確定是哪個加載或存儲指令導致了標記不匹配。相反,異步報告是不精確的,因為它只能將不匹配隔離到特定的執行線程。
MTE為Armv8-A架構添加了以下概述的說明,并將其分為三個不同的類別【6】:
適用于棧和堆標記的標記操作說明。
?IRG 為了使MTE的統計基礎有效,需要一個隨機標簽的來源。IRG被定義為在硬件中提供此標記,并將這樣的標記插入到寄存器中,以供其他指令使用。?GMI 此指令用于操作排除的標記集,以便與IRG指令一起使用。這適用于軟件為特殊目的使用特定標記值,同時為正常分配保留隨機標記行為的情況。?LDG、STG、STZG 這些指令允許在內存中獲取或設置標記。它們的目的是在不修改數據或將數據歸零的情況下更改內存中的標記。?ST2G和STZ2G 這些是STG和STZG的更密集的替代方案,它們在分配大小允許的情況下在兩個內存顆粒上運行。?STGP 該指令將標記和數據都存儲到內存中。
用于指針算術和堆棧標記的指令:
?ADDG和SUBG 這些是ADD和SUB指令的變體,旨在對地址進行算術運算。它們允許標記和地址都被一個立即值單獨修改。這些指令用于創建堆棧上對象的地址。?SUBP(S) 此指令提供了一個56位減法,帶有可選的標志設置,這是指針運算所必需的,忽略頂部字節中的標記。
系統使用說明:
?LDGM、STGM和STZGM 這些是在EL0處未定義的批量標簽操作指令。它們旨在供系統軟件為了初始化和序列化的目的來操作標記。例如,它們可以用于實現將標記的內存交換到不識別標記的介質。清零形式可以用于高效的內存初始化。此外,MTE還提供了一組設計用于標簽的緩存維護操作。這些提供了在整個緩存行上運行的高效機制。
MTE規模部署
Arm預計,在產品開發和部署的不同階段,MTE將部署在不同的配置中。
精確的檢查旨在提供有關故障位置的最多信息。不精確的檢查旨在實現更高的性能。
操作系統內核可以選擇是否終止由于標記不匹配而導致異常的進程,或者記錄該異常的發生并允許進程繼續進行。
在啟用MTE的情況下測試產品可以發現它的許多潛在問題。在這個階段,檢測和記錄盡可能多的問題的信息是合適的。
不需要保護系統免受攻擊者的攻擊。可能需要將系統配置為:
?進行精準檢查。?累積標記不匹配的數據,而不是終止進程。這種配置允許收集最多信息,以支持通過定向測試和Fuzzing找到最大數量的缺陷。
發布產品后,可能需要將MTE配置為:
?執行不精確的檢查。?在標記不匹配時終止進程。
此配置在性能和檢測可能啟動針對軟件的漏洞的內存安全違規之間提供了一種平衡。
在發布后,配置對黑客具有高價值的進程(例如加密密鑰存儲)可能是合適的,以執行精確的檢查,以便有關檢查失敗位置的準確信息可以通過錯誤報告和遙測系統傳回其開發人員。
系統自適應地改變其MTE配置也可能是合適的。
例如,如果使用不精確檢查運行的進程因為標記檢查失敗而終止,那么下次啟動該進程時,它可能會從啟用精確檢查開始,以便為其開發人員收集更好的診斷信息。這種部署模型融合了不精確檢查的性能優勢和精確檢查的優勢,以提供更好的質量反饋。
MTE硬件部署
為了支持實現MTE的未來Arm產品,正在開發一個新版本的AMBA 5相干集線器接口(CHI)規范,該規范支持MTE的傳輸和相干性要求【7】。
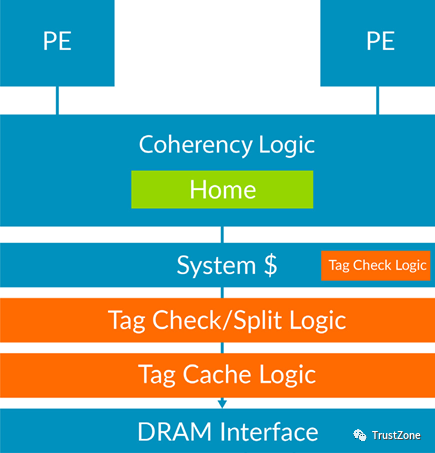
堆標記
在動態鏈接系統中,可以在不改變現有二進制文件的情況下部署標記堆。只需要修改操作系統內核和C庫代碼。
Arm通過添加對Linux內核的支持,對MTE進行原型化。需要修改的區域如下:
?能夠在使用用戶空間指針時將標記從它們中刪除用于地址空間管理。?使虛擬內存系統中的clear_page和copy_page函數感知標簽。?增加標簽不匹配導致的故障處理。類似于SIGSEGV處理翻譯故障的方式。?轉換可能暴露給用戶空間的內存映射進程來使用普通標記內存。?增加擴展檢測和系統寄存器配置以啟用擴展。
Arm正在向上游貢獻Linux內核支持。
在C庫中,Arm修改了這些與內存相關的函數:
?malloc?free?calloc?realloc
此外,還修改了內存拷貝和字符串相關函數,以防止它們過度讀取源緩沖區。
堆棧標記
在運行時堆棧上分配的內存需要編譯器支持和內核支持。二進制文件必須重新編譯。可以使用許多不同的堆棧標記策略。
我們的合作伙伴利用IRG設計了一個隨機選擇標簽的策略指令,在函數進入期間,分配一個新的棧幀。然后,編譯器使用ADDG和SUBG指令為函數內的每個棧槽創建標記地址,其中標記從初始隨機標記偏移。堆棧分配可以使用適當的標記存儲指令進行批量初始化,但編譯器不需要在函數體代碼使用之前初始化任何插槽。
此策略確保MTE的統計屬性對于每個函數調用都有效,并確保堆棧上相鄰的對象具有不同的標記,從而導致順序上溢和下溢。
保護堆棧上的相鄰對象需要增加這些對象與標記顆粒的對齊,即16字節。在某些程序中,MTE會因為這個效應而導致堆棧使用率增加。我們的基準分析表明,漲幅通常不大。
為了提高性能,在MTE下取消檢查使用堆棧指針尋址模式的立即偏移量的內存訪問。這是因為編譯器可以靜態地證明它們是正確的,或者在編譯時發出診斷。
MTE優化
MTE的設計使得它不需要修改源代碼就可以糾正代碼。但是,MTE必然會帶來開銷,因為標記必須從內存系統中獲取并存儲到內存系統中。這種開銷與內存分配的大小和生存期以及標記和數據是一起操作還是分開操作有關。可以通過以下方式最大限度地減少開銷:
?同時寫標簽和初始化內存。在許多情況下,內存必須初始化為零,并設置標記。例如,在將頁面交給用戶空間之前,清除操作系統內核中的頁面。Arm基于Linux的原型機為此使用了STZGM指令。?避免過度分配從未向其寫入數據的地址空間。在某些情況下,軟件分配的地址空間遠比它所需的多,并且在解除分配之前只接觸其中的一小部分。使用MTE,這更昂貴,因為即使數據永遠不會寫入內存,標記也可能需要。?避免過度的去分配和再分配。避免過多的去分配和再分配通常是一個好的實踐,無論是否部署了MTE。但是,由于使用MTE分配和解除分配的固定成本會增加,現有的性能問題可能會被放大。?避免在堆棧上進行大的固定大小分配。堆棧上的大的、固定大小的分配往往會被使用不足,例如,PATH_MAX等固定大小的緩沖區通常包含相對較短的字符串。避免這樣的分配,通過減少必須寫入的未使用的內存標記的數量,減少了保護堆棧的開銷。
參考文獻
?[1] F. B. I. [Online]。 Available: https://www.fbi.gov/news/stories/morris worm-30- years-since-first-major-attack-on-internet-110218
?[2] M. Miller, “Bluehat Abstracts,” [Online]。 Available: https://msrnd-cdn-stor. azureedge.net/bluehat/bluehatil/2019/assets/doc/Trends%2C%20 Challenges%2C%20and%20Strategic%20Shifts%20in%20the%20Software%20 Vulnerability%20Mitigation%20Landscape.pdf
?[3] “Google Queue Hardening,” [Online]。 Available: https://security.googleblog. com/2019/05/queue-hardening-enhancements.html
?[4] Debian, “Stretch Statistics,” [Online]。 Available: https://sources.debian.org/stats/ stretch
?[5] “ACM,” [Online]。 Available: https://dl.acm.org/citation.cfm?id=2654847
?[6] “AArch64 Instructions,” [Online]。 Available: https://developer.arm.com/docs/ ddi0596/latest/base-instructions-alphabetic-order
?[7] “Architecture Reference Manual,” [Online]。 Available: https://developer.arm.com/ docs/ddi0487/lates
編輯:黃飛









 工商網監
工商網監
評論