 電子發燒友App
電子發燒友App


1、什么是數據類型?
計算機編程語言是用來控制計算機的行為及操作,協助人們解決現實中的問題,其能表達的數據類型也是從實際中提取并抽象出來形成的數據結構描述。
例如:數學中數的基礎分類有正整數、負整數、小數等類別,數學中所有關于數的運算都是在基礎分類上進行的。計算機出現之前,數學家們用稿紙進行大量的數學運算以求證數學問題和科學計算,這耗費了數學家們太多的精力。隨著計算機科技的發展,大量復雜的數學運算交給計算機來執行,極大提高了計算效率,也讓數學家們從復雜的數學運算中擺脫出來。
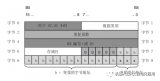
數學運算包含大量的計算表達式,計算機程序需要有連續處理算式和計算數據的能力,下面是一個簡單的四則運算算式:
15.8+20*31.5-30
計算機程序要處理上述算式,就需要具備存儲小數、整數、運算符的能力。C語言提供了存儲小數、整數、運算符的基本數據類型。下圖是算式中數據類型到C數據類型的映射圖。
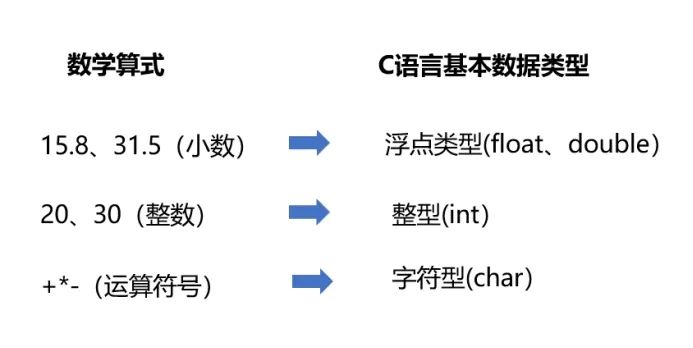
圖 2-1數學算式數據類型到C語言數據類型的映射
2、變量與數據類型
使用變量可以將數學算式中的數存儲起來,下面討論如何聲明或定義一個變量。在C語言中聲明一個變量和定義一個變量存在區別:聲明變量是通知編譯器變量的類型和名字,編譯解析聲明變量時,不會為該變量分配存儲空間,直至該變量被賦值時,才會為變量分配存儲空間;定義變量是在聲明變量的同時,為變量賦一個初始化值,編譯器解析定義變量時,將為該變量分配存儲空間。
聲明一個變量
語法規則: 數據類型 變量名;
其中,數據類型可以是C語言支持的任何數據類型;變量名為聲明的變量名稱。
示例:聲明整型變量
int number;
示例:聲明字符型變量
char op;
定義一個變量
聲明變量的同時并對變量直接賦值,稱為定義一個變量。如果在聲明變量時沒有對變量進行賦值,則應在后面的程序語句中為變量賦值。
示例:定義整型變量
int number= 30;
示例:為已聲明的變量賦值
op=’+’;
下面簡要說明一個解析數學算式并存儲運算符和運算數的示例,為說明問題起見,給出一個簡單數學算式:8.25+30。
聲明三個變量用來存儲運算數和運算符
float floatNum;
int intNum;
char op;
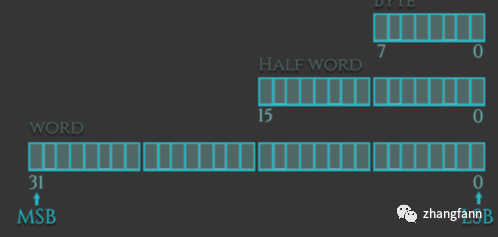
程序在計算上述數學算式時,首先從左到右掃描數學算式。假設本次掃描不考慮優先級運算,只是完成提取運算數和運算符的功能。掃描過程如下:如果是運算數,判斷是整數還是小數,整數賦值給intNum,如果是小數賦值給floatNum,如果是運算符賦值給op。下圖是掃描完成后,變量在內存儲器的存儲情況。

圖 2-2 不同數據類型的變量在存儲器的存儲情況
從圖2-2可以看出,不同數據類型的變量在存儲器占用的空間也不相同。數據類型為字符型的變量在存儲器占用一個字節的空間。C語言對整數類型并沒有嚴格規定其長度(占用存儲空間的字節數),只做了寬泛的限制。圖2-4整數類型占用4個字節的存儲空間,是指在32位操作系統下,整數類型占用4個字節的存儲空間。
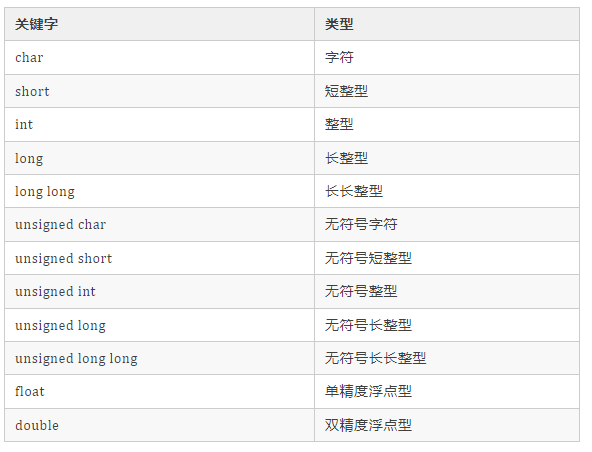
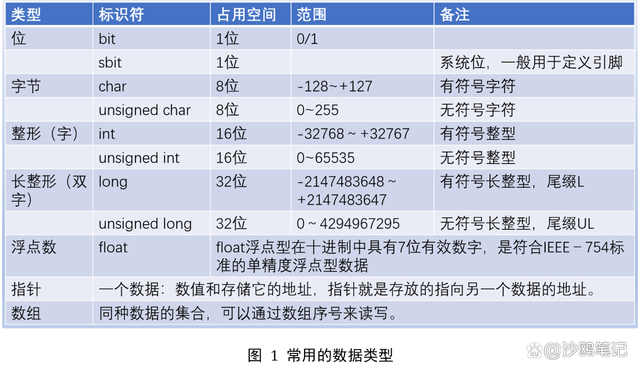
3、基礎數據類型
C語言基本數據類型見圖2-3。

圖 2-3 C語言基本數據類型
C語言基本數據類型包括數值、非數值兩種類型。數值類型又分為整數類型和非整數類型,整數類型包括整型、短整型和長整型,非整數類型包括單精度浮點和雙精度浮點。非數值包括字符類型。
4、整數類型
C語言的整數類型可以說是復雜多樣,根據存儲空間和數值范圍可分short(短整型,占用2個字節)、int(整型,機器字長)、long(長整型,32位環境占用4個字節,64位環境占用8個字節)、long long(加長整型,占用8個字節),根據整數分類又可分為有符號整數和無符號整數。
對整數而言,C語言為什么要定義這么多不同的類型呢?
在發明C語言的年代,計算機的存儲資源是非常珍貴的,程序員設計和編寫程序對存儲資源要精打細算,否則存儲資源就不夠用了。在存儲資源緊張的情況下,程序員優先選用占用存儲空間小且能夠滿足數據處理要求的整數類型。即使在當前存儲資源較為寬松的環境下,程序員在編寫代碼時,通常能預想到需要使用到的數據范圍的大小,這樣在處理一個數據時,可以從語言所提供的類型中選用最合適的類型來存儲數據。
實際上,C語言對short、int、long 并沒有嚴格規定其長度(占用存儲空間的字節數),只做了寬泛的限制:short 至少占用 2 個字節;int 建議為一個機器字長。32 位環境下機器字長為 4 字節,64 位環境下機器字長為 8 字節;short 的長度不能大于 int,long 的長度不能小于 int。
由此可見,short 并不一定真的”短“,long 也并不一定真的”長“,它們有可能和 int 占用相同的字節數。在 16 位系統下,short 的長度為 2 個字節,int 也為 2 個字節,long 為 4 個字節。在32位和64位操作系統下,short 的長度為 2 個字節,int 為 4 個字節,long 也為 4 個字節,long long類型為8個字節。
那么問題來了,在實際編程中如何確定一個整型占用的存儲空間大小呢?
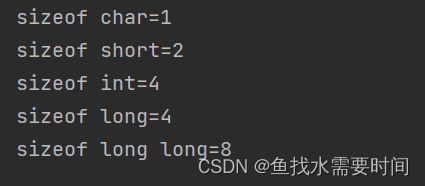
C語言提供了sizeof運算符來獲取數據類型占用的字節數,sizeof運算符傳入的參數可以是數據類型,也可以是變量名稱。例如下面的代碼分別輸出了不同數據類型的字節數:
#include
void main()
{
char ch = 'a';
printf("short:%d字節n",sizeof(short));
printf("int:%d字節n",sizeof(int));
printf("long:%d字節n",sizeof(long));
printf("long:%d字節n",sizeof(long long));
printf("ch:%d字節n",sizeof(ch));
}
執行上述代碼,輸出結果為:

整數類型有正整數和負整數之分,在C語言中,規定整型的最高位為符號位,最高位為“0”表示正數,最高位為“1”表示負數,其它位表示數值。因此整型類型的數據能夠表示的最小值為:-2n-1 —2n-1-1(n為該類型所占存儲空間的二進制位數)。
一個數在計算機中的二進制表示形式, 叫做這個數的機器數。例如:十進制數+3,使用8個二進制位表示,轉換成二進制就是00000011。如果是 -3 ,就是10000011 。00000011和10000011就是機器數。
因為最高位是符號位,因此機器數的形式值不一定等于真正的數值。例如上面的有符號數 10000011,其最高位1代表負,其真正數值是 -3 而不是形式值131(10000011轉換成十進制等于131)。為區別起見,后面的內容將帶符號位的機器數對應的真正數值稱為機器數的真值。
下面我們編寫一個簡單的程序,分別輸出+3和-3的機器數,查看機器數的形式值是否為機器數的真值。
#include
void printf_binary(char n);
void main()
{
char positive = 3;
char negative = -3;
printf_binary(positive);
printf_binary(negative);
}
// 輸出二進制數
void printf_binary(unsigned char n)
{
char i=0;
for(i=0; i< 8; i++ ){
if(n&(0x80 >?>i)){
printf("1");
}else{
printf("0");
}
}
printf("n");
}
char為字符類型,占用一個字節的存儲空間,值范圍為-128~127。printf_binary(unsigned char n)函數將十進制數轉換為二進制數輸出,函數及函數內的語句同學們先不要急于了解,后面的課程都會講到,重點關注程序的輸出結果

從輸出結果可以看出,+3的機器數為0000011,其形式值為3,機器數的形式值和真值相同。-3的機器數為11111101,其形式值為253,真值為-3,機器數的形式值和真值不相同,若把+3和-3的機器數相加,結果為0,運算結果正確。實際上,計算機是以補碼的方式來存儲數值的。
計算機為什么以補碼方式來存儲數值呢?對于一個數,計算機要使用一定的編碼方式進行存儲,原碼、反碼、補碼是機器存儲一個具體數字的編碼方式。
原碼就是符號位加上真值的絕對值,即最高位是符號位,其余位用來表示值。例如1個8位的二進制數:
[+3] 原碼:0000 0011
[-3] 原碼:1000 0011
原碼比較容易理解,但不利于計算機的加減計算,因為原碼帶符號位,若對兩個原碼表示的機器數直接進行加減運算,運算結果并不正確。若讓計算機能夠識別符號位,計算機的運算電路設計就會非常復雜。因此計算機一般不采用原碼的方式來存儲數值。
既要讓符號位參與運算,又要讓運算電路設計簡單,使用補碼存儲數值就會解決這個問題。
補碼應用了數學中同余的概念,同余的兩個數具有互補關系。給定一個正整數m,如果兩個整數a和b滿足a-b能夠被m整除,即(a-b)/m得到一個整數,那么就稱整數a與b對模m同余,a和b具有互補關系。
回到整數類型, 補碼的計算規則為最高位是符號位,0表示正數,1表示負數,正數的補碼等于本身,負數的補碼等于反碼(正數的反碼等于本身,負數的反碼除符號位外,各位取反)+1。
例如:
[-3] 原碼:1000 0011 反碼:1111 1100 補碼:1111 1101
前面討論的都是有符號整數,可以表示正負數。若只需要處理正整數,可以在上述類型關鍵字前面添加unsigned關鍵字表示無符號整數,兩個關鍵字用空格隔開,因為不需要符號位,因此無符號整數表示的范圍為:0 —2n-1。下表列出了符號整數的類型。

整型變量可按如下方式聲明:
int pageNumber;
long int size;
short age;
unsigned short readCount;
在一條語句中,可以聲明多個同一類型的整型變量,每個變量之間用逗號分隔:
int pageNumber, likeNumber,readCount;
整型變量可按如下方式定義:
int pageNumber=230;
short age = 21;
unsigned short readCount=1260;
在定義變量或為變量賦值時,常常會用到一些數值,這些值通常稱為字面值。字面值有三種不同的表示形式:十進制、八進制和十六進制。
八進制表示:在八進制數值前面加前綴數字0,其數碼取值為0—7,例如:023、0457、01329等;
十六進制表示:前綴為“0X”或“0x”,數碼取值0—9、A—F、或a—f。例如:0X2A、0XA0、0Xffff等;
十進制表示:既無前綴也無后綴。例如:236、56、7890等。
在字面值后面可以添加u或U(unsigned)、l或L(long)、u/U與l/L的組合(如:ul、lu、Lu等),表示該字面值的類型。例:100u; 123u; 0x123L;
5、浮點類型
浮點類型用來存儲實數,為什么在C中把實數稱為浮點數呢?在C語言中實數是以指數形式存放在存儲單元中,類似于科學計數法形式,如:2.1E5、3.7e-2等,其中e或E之前必須有數字,且e或E后面的指數必須為整數。
一個大于0的實數可以用下面指數的方式來表示:
a * 10n (1<=a<10,n為整數)
其中,a是該數值的有效位數,有效位數從左邊第一個不是0的數起,到末尾數字為止,所有的數字(包括0,科學計數法不計10的n次方),稱為有效數字。例如:光速是3E8,其有效數字是1位,值是3;世界人口數大約是6.1E9,其有效數字是2位,值是6.1。
n是該數值的整數部分減1的正整數。
一個小于0的實數可以用下面指數的方式來表示:
a * 10-n (1<=a<10,n為整數)
a的取值同上面相同,n的取值為原數中左邊第一個不為0的數字前面所有的0的個數(包括小數點前面的0)。
一個實數表示為指數形式,通過移動小數點可以有多種表示方法。例如:實數3.14159可以表示為以下的指數形式:
3.14159E0
0.314159E1
314.159E-2
上面的指數形式因為小數點所在位置不同,指數也不同,但實際表示的數值都是3.14159。因此只要在小數點位置浮動的同時改變指數的值,就可以保證它的值不會改變。由于小數點位置可以浮動,所以實數的指數形式稱為浮點數。
在C語言中,浮點類型有float和double兩種,分別表示單精度浮點數和雙精度浮點數。精度是指描述一個數值的準確程度,在數學運算中,經常會用到近似數,近似數與原數值非常相近,但又不完全符合原數值,只能說在某種程度上近似。精度與近似數相似,也是用一個與原數值非常相近的數代替原來的數值。
前面說過存儲一個數值所用的字節越多,其精度越高,數值范圍也越大。由此看來,精度與存儲字節數密切相關,float類型的存儲空間是4個字節,其表示的值范圍約為10-38到1038,double類型的存儲空間是8個字節,其表示的值范圍約為10-308到10308,float存儲數值的精度和范圍要小于double存儲數值的精度和范圍。因此,float是單精度數值,double是雙精度數值。

圖 2-4浮點型變量占用的存儲空間
實數的指數形式有多種表示方法,計算機在存儲實數時,一般采用標準化的指數形式,即小數點前的數字為0,小數點后第1為數字不為0。例如:0.314159E1就是3.14159的標準化的指數形式。
float類型的變量占用4個字節的存儲空間,系統存儲float類型的實數時,將實數分為小數部分和指數部分。最高位為符號位,小數部分占23位,剩余的8位存儲實數的指數部分(包括指數的符號)。由于用二進制形式表示一個實數以及存儲單元的長度是有限的,因此不可能得到完全精確的值,只能存儲成有限的近似值。小數部分占的位數愈多,數的有效數字愈多,精度也就愈高。指數部分占的位數愈多,則能表示的數值范圍越大。
double類型的變量占用8個字節的存儲空間,最高位為符號位,小數部分占52位,剩余的11位存儲實數的指數部分(包括指數的符號)。
float變量可按如下方式定義:
float price = 12.35f;
float average = 89.2f;
double變量可按如下方式定義:
double pi = 3.14159265;
public double average = 89.2987017;
字面值賦值給float變量時,數值尾部要加上小寫“f”或大寫“F”聲明為float類型的數值,不然編譯器會給出從“double”到“float”截斷的警告。因為在C語言中,帶小數的字面值默認為是double類型,double類型轉換為float類型,自然要損失精度,位數被截斷了。
C語言還提供了long double類型,表示長雙精度浮點數,但C語言并沒有long double的確切精度,對于不同系統平臺可能有不同的實現,有的是8字節,有的是10字節,有的是12字節或16字節,C語言函數sizeof(long double)可以輸出當前系統平臺下long double占用的字節數。
浮點類型字面值的后綴有:f或F(單精度浮點數)、l或L(長雙精度浮點數),因為浮點型常數總是有符號的,所以沒有u或U后綴。例:1.23e5f; 1.23L; -123.45f。
6、字符類型
在編寫程序時,我們還經常會遇到需要存儲并操縱字符型數據的情況。例如:計算數學算式時,需要存儲運算符,這時就需要一種可以存儲單個字符數據(字符包括字母、數字、運算符號、標點符號和其他符號,以及一些功能性符號)的數據類型。C語言提供了一種char數據類型,可以滿足存儲單個字符的需要。
計算機中的字符一般采用ASCII碼表示,ASCII碼是一種標準的字符編碼方式,規定每個字符對應一個數,例如:十進制數65對應大寫字母A,97對應小寫字母a。ASCII編碼最后一次更新是在1986年,到目前為止共定義了128個字符。
ASCII字符與編碼映射范圍表:

標準ASCII碼使用7位二進制數來表示所有的大寫和小寫字母,數字0 到9、標點符號,以及在美式英語中使用的特殊控制字符。char數據類型占用一個字節的存儲空間,可以表示8位二進制數,完全可以存儲ASCII碼。
char變量可按如下方式定義:
char code=’a’, op=’*’,digit=’0’;
任意單個字符,加單引號。
char code =97
可以直接把ASCII碼十進制數97賦值給char型變量code。
上面例句中的‘a’, ’*’, ‘0’為字符字面值,字符字面值需要使用一對單引號括起來,括號內只能包含一個字符。除了字符常量可以賦值給char型變量外,0~255的整數常量也可以賦值給char型變量。char型變量通常用來存儲字符,若存儲的數值超過ASCII碼范圍,變量的值沒有實際意義。
標準C語言沒有提供byte數據類型,byte占1個字節的存儲空間,表示的數值范圍是0~255。若需要使用byte數據類型,可以使用unsinged char來表示byte數據類型。
7、類型轉換
C語言是強類型語言,變量的數據類型被指定后,會一直保持該數據類型。同時C語言對參與賦值運算和算術運算的操作數數據類型要求必須一致,當參與運算的操作數數據類型不一致時,就需要對操作數的數據類型進行類型轉換,把參與運算的操作數轉換為同一數據類型后,再進行運算。
隱式類型轉換
例如:
double PI = 3.14;
int radius = 5;
double s;
s = PI * PI * radius;
在上面的例句中,表達式PI * PI * radius有二個操作數,PI是double類型,radius是整數類型。因為操作數的數據類型不一致,C語言編譯器會對數據類型做強制轉換,將radius的整數類型強制轉換為double類型。
這種轉換是C編譯器自動進行的,開發者不需要進行任何操作,由C編譯器自動完成,這種類型的轉換也稱為隱式轉換。
由于不同的數據類型存儲空間和表示的數值精度是不同的,因此在數據類型的轉換過程中,就會存在數值精度丟失和數值溢出的問題。例如:double類型轉換為float類型,數值精度就會丟失;long類型轉換為int類型時,如果long類型變量存儲的數值超過了int類型能夠存儲的數值范圍,就會發生數值溢出。
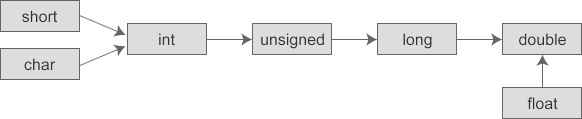
為了避免在轉換過程中發生數值精度丟失和溢出的問題,隱式轉換都會遵循從低級數據類型到高級類型的轉換規則,也可以說是從數值存儲精度小的類型到存儲數值精度高的類型轉換。這些數據類型按數值存儲范圍大小依次為:
short->int->long->float->double
下表列出了數據類型隱式轉換的一般規則。

【例】類型的隱式轉換練習
程序清單 sample.c
#include
int main()
{
// 聲明char類型的變量
char chTemp = 65;
// 聲明int類型的變量
int nTemp = 34;
// 聲明float類型的變量
float fTemp = 29.6f;
// 聲明double類型的變量
double dTemp = 86.69;
printf("char類型的數據與float類型的進行相加運算,運算結果為:%.2fn",(chTemp+fTemp));
printf("float類型的數據與double類型的進行相加運算,運算結果為:%.2fn",(fTemp+dTemp));
printf("char類型的數據與int類型的進行相加運算,運算結果為:%dn",(chTemp+nTemp));
}
7、顯示類型轉換
顯示類型轉換是相對隱式轉換來說的,隱式轉換由C編譯器自動進行,不需要開發者做任何操作。顯示類型轉換需要開發者在代碼中對數據類型進行顯示類型轉換。
當進行數據類型的顯示轉換時,程序員需要自身判斷類型轉換過程中是否會發生數值溢出或精度丟失,當由精度高的類型轉換為精度低的類型時,會發生精度丟失。
顯示轉換的一般形式為:
(類型名)要轉換的變量或常量
例如:
// 將數值36.9強制轉換為int,精度丟失
int nTemp = (int)36.9;
// 聲明double類型的變量
double dTemp = 12.15;
// 將double類型強制轉換為int,精度丟失
int nV = (int)dTemp;
在上面的例句中,36.9是數值常量,默認為double類型,顯示轉換為int類型并賦值給nTemp,此時nTemp的值為36,精度丟失。
dTemp是double類型的變量,將dTemp的值賦值給int變量時,需要進行顯示轉換,int變量只存儲double變量的整數部分,小數部分丟失。
















 工商網監
工商網監
評論