 電子發(fā)燒友App
電子發(fā)燒友App


# 前言 #
在很多編程語(yǔ)言中,經(jīng)常用 String 類型來(lái)表示字符串,用 Char 來(lái)表示字符類型;在以往的觀念中,String 與 Char 數(shù)組 (字符數(shù)組) 是等價(jià)的,但隨著計(jì)算機(jī)的發(fā)展以及編程語(yǔ)言的演進(jìn),這兩者之間好像出現(xiàn)了一些細(xì)微的不同。這篇文章將向讀者展示,Char 數(shù)組與 String 是如何從統(tǒng)一走向分離的。
# 從數(shù)數(shù)開(kāi)始 #
先從一個(gè)簡(jiǎn)單的 Python 程序講起,返回一個(gè)字符串的長(zhǎng)度。
輸入數(shù)據(jù)如下:
?
hello?world 你好,世界 cafe?
?
在筆者的環(huán)境中結(jié)果如下:
?
Python?3.8.0?(default,?Dec??9?2021,?17:53:27) [GCC?8.4.0]?on?linux Type?"help",?"copyright",?"credits"?or?"license"?for?more?information. >>>?len("hello?world") 11 >>>?len("你好,世界") 5 >>>?len("cafe?") 5 >>>?len("") 5 >>>?len("") 7按理說(shuō),len() 函數(shù)應(yīng)該返回字符串包含的 “字符” 的個(gè)數(shù),但是這里的 “字符” 與直覺(jué)上好像有一些出入。
?
| ? | 直覺(jué)上的長(zhǎng)度 | py3 輸出的長(zhǎng)度 | 相等與否 |
|---|---|---|---|
| hello world | 11 | 11 | ? |
| 你好,世界 | 5 | 5 | ? |
| cafe? | 4 | 5 | ? |
| ? | 3 | 5 | ? |
| ? | 1 | 7 | ? |
發(fā)生什么事了
到底是誰(shuí)錯(cuò)了?人還是機(jī)器?
機(jī)器永遠(yuǎn)是對(duì)的。——jyy
py3 輸出的長(zhǎng)度表示的是什么意思呢?
# 字符類型 #
為了回答前面的問(wèn)題,我們需要了解一下字符類型,雖然在 Python 中沒(méi)有獨(dú)立的字符類型,但其他大多數(shù)編程語(yǔ)言中都有單獨(dú)的字符類型,如 C#,Java,Rust,Julia 中的 Char,以及 Go 中的 rune 和 Swift 中的 Character;雖然都叫字符類型,但是由于一些原因,這些字符類型的實(shí)現(xiàn)并不一樣,有的是 16 位有的是 32 位 (其原因會(huì)在后面說(shuō)明) 。在比較現(xiàn)代的編程語(yǔ)言中,字符類型的實(shí)現(xiàn)多數(shù)為 32 位,我們就從 32 位字符類型開(kāi)始講起吧。
注: 在后文中出現(xiàn)的 Char 或者是 Char 類型,均指代編程語(yǔ)言中的字符類型,由于 “字符” 一詞存在歧義,故選擇了 Char 這個(gè)詞來(lái)指代。至于“字符”一詞的歧義,也會(huì)在后文中展開(kāi)說(shuō)明。
32 位字符類型基本都是用來(lái)表示 Unicode Scalar Value(Unicode 標(biāo)量值), 或者說(shuō) Unicode 中的 Code Point。
首先, Unicode 是什么呢?——Unicode 標(biāo)準(zhǔn) (The Unicode Standard) [1],簡(jiǎn)單說(shuō)就是一個(gè) “字符表”,一種規(guī)則,給每個(gè)字符一個(gè)編號(hào)。
可以類比于 ASCII 碼,大寫(xiě)字母 “A” 的編號(hào)是十進(jìn)制的 65。
下方的截圖來(lái)自于 Unicode 官網(wǎng)?[2],可以看到圖中列出了幾個(gè)字符,每個(gè)字符的下方會(huì)有一個(gè)編號(hào) (如 U+0669,十六進(jìn)制) ,這個(gè)編號(hào)就稱為 Code Point。
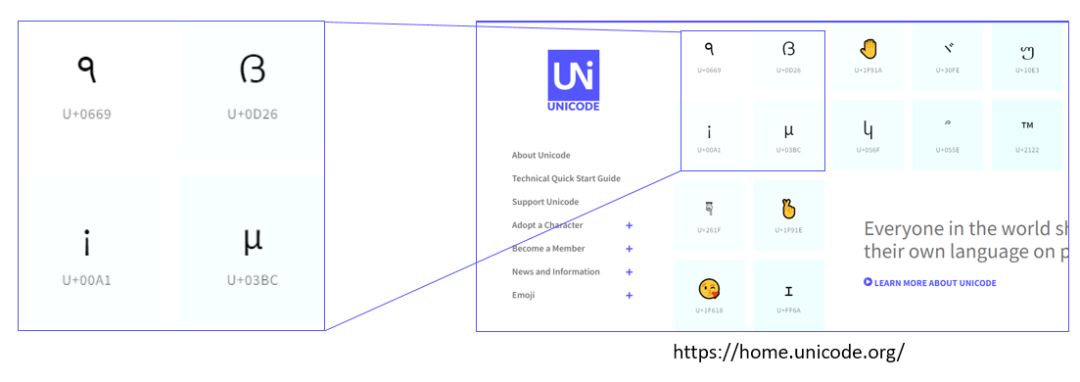
目前 Unicode Code Point 編號(hào)達(dá)到了 21 位 (二進(jìn)制) ,所以用 32?位來(lái)存儲(chǔ)是完全夠用的。
32 位字符類型表示的就是這個(gè)編號(hào),比如上圖中的 U+0669。
# Char == 字符?#
| ? | 直覺(jué)上的長(zhǎng)度 | py3 輸出的長(zhǎng)度 | 相等與否 |
|---|---|---|---|
| hello world | 11 | 11 | ? |
| 你好,世界 | 5 | 5 | ? |
| cafe? | 4 | 5 | ? |
| ? | 3 | 5 | ? |
| ? | 1 | 7 | ? |
回到前面字符串長(zhǎng)度的表格,現(xiàn)在我們可以回答之前提出的問(wèn)題了,py3 輸出的字符串長(zhǎng)度,其含義是字符串中 Unicode Code Point 的個(gè)數(shù) (感興趣的讀者可以自己驗(yàn)證,這里就忽略了) 。
再來(lái)看左側(cè)的 “直覺(jué)上的長(zhǎng)度”,為了更準(zhǔn)確地講解,我們引入一個(gè)新概念,用戶視角的字符 (User-perceived character) ,指符合人類直覺(jué)的字符,因?yàn)槭菑闹庇X(jué)的角度出發(fā),沒(méi)有明確的定義,比如一個(gè)“塊塊”,一個(gè) emoji 表情 。“直覺(jué)上的長(zhǎng)度” 含義就是 用戶視角的字符 的個(gè)數(shù)。
從這個(gè)表格中可以看到,有一些 “字符”,在人類視角是一個(gè) (一個(gè) 用戶視角的字符) ,但是在計(jì)算機(jī)的角度是由多個(gè) Unicode Code Point 組成。
很顯然,一個(gè)用戶視角的字符,可能需要多個(gè) Unicode 字符 (Code Point) 來(lái)表示。比如這個(gè)表示家庭的 emoji,,實(shí)際上由七個(gè) Unicode Code Point 組成,但是由前端渲染成了一個(gè) “用戶視角的字符”;或者這個(gè) ,由兩個(gè) Code Point 組成 (一個(gè) ,外加一個(gè)表示膚色的 Code Point) 。
更一般地講,32 位 Char 類型無(wú)法表示全部的用戶視角的字符,能表示的有英文、漢字、日語(yǔ)等;不能表示的有法語(yǔ)等小語(yǔ)種、部分組合而成的 emoji 。
不少編程語(yǔ)言中都是用 Char 作為字符類型,久而久之便形成了 “Char == 字符” 這樣的假設(shè),潛意識(shí)地認(rèn)為字符類型可以表示任何用戶角度的字符,但現(xiàn)在通過(guò)上面的幾個(gè)例子,可以看到 Char 類型與用戶視角的字符并不相同。
這里建議讀者把 32 位 Char 類型當(dāng)作表示 Unicode Code Point 的類型,不再使用 “字符” 類型這個(gè)詞。因?yàn)椴徽?“字符” 還是 “Character”,在計(jì)算機(jī)中都是含有歧義的詞語(yǔ);比如一個(gè) “字符” 是指 8 位?16 位?還是 32 位?更或是“用戶角度的字符”?而這些概念都有對(duì)應(yīng)的指代更為明確的詞語(yǔ)。
“Char == 字符” 的時(shí)代已經(jīng)過(guò)去了,雖然 Char 依然表示字符類型,但卻無(wú)法表示很多 “用戶視角的字符”,歡迎來(lái)到全新的 Unicode 時(shí)代~
類比計(jì)算機(jī)發(fā)展早期,比如在 C 語(yǔ)言中,一個(gè) char (8 位) 可以表示 ASCII 字符;但在當(dāng)今的時(shí)代,即使是 32 位的 Char,依然有很多用戶視角的字符超出了其表示能力。
小結(jié)
很多用戶角度的字符已經(jīng)超出了 Unicode 字符的表示范圍,即 32 位 Char 類型的表達(dá)能力。
“Char == 字符” 假設(shè),不再成立,或者在一定范圍內(nèi)成立。
字符是一個(gè)很容易產(chǎn)生歧義的詞,當(dāng)談及字符時(shí)候一定要小心 (指代不夠明確,是用戶角度的字符?Char 類型?32 位?16 位?8 位?)。
Char 類型有可能誤導(dǎo)使用者,其在部分場(chǎng)景夠用,但是更復(fù)雜的場(chǎng)景會(huì)暴露其不足 (在后面的 Code Point Unaware String 章節(jié)會(huì)有進(jìn)一步的討論) 。
# 走進(jìn)字符串 #
可以看到,即使是一個(gè)用戶視角的字符,我們也可能需要一個(gè)字符串 (多個(gè) Char 類型) 來(lái)表示。
我們對(duì)字符串最直觀的認(rèn)識(shí) —— Char 數(shù)組,這個(gè)直觀認(rèn)識(shí)不管從人類直覺(jué)還是從計(jì)算機(jī)發(fā)展都是很理所當(dāng)然的。
從人類直覺(jué)來(lái)說(shuō),字符串,字面意思,“字符” 的 “串”,使用代碼來(lái)表示,自然而然會(huì)想到用 Char 數(shù)組。
從筆者個(gè)人學(xué)習(xí)經(jīng)歷來(lái)說(shuō),筆者學(xué)的第一門(mén)編程語(yǔ)言是 C 語(yǔ)言,C 語(yǔ)言里面并沒(méi)有單獨(dú)的 String 類型,在 C 里面,字符串與 char 數(shù)組是等價(jià)的。
在一些語(yǔ)言的 String 設(shè)計(jì)中,這種直覺(jué)也是 “行得通” 的,比如 Java、C#、Swift,其字符串的長(zhǎng)度都表示 (該語(yǔ)言中) 字符類型的個(gè)數(shù),對(duì) String 索引操作得到的也是字符類型。
但如果我們?cè)贁U(kuò)大一下視角,來(lái)橫向看一下各個(gè)編程語(yǔ)言中的 String 類型,我們會(huì)發(fā)現(xiàn),“字符串是 Char 數(shù)組” 這個(gè)概念,好像并不統(tǒng)一。
我們通過(guò)各個(gè)語(yǔ)言中 String 類型索引和長(zhǎng)度的含義,以此來(lái)判斷其 String 是否為 Char 數(shù)組。
索引和長(zhǎng)度的含義可能是語(yǔ)言中內(nèi)置 Char 類型,此時(shí) String 與 Char 數(shù)組無(wú)異,我們可以像操作數(shù)組一樣操作 String;
除此之外,索引和長(zhǎng)度還可能是指 “字節(jié)”,二者的關(guān)系 —— 一個(gè) Char 可以由一個(gè)多個(gè)字節(jié)組成 (更具體的關(guān)系在后面的編碼章節(jié)會(huì)繼續(xù)深入),比較的語(yǔ)言和結(jié)果如下:
| ? | Swift | Go | Rust | Julia | Java | C# |
|---|---|---|---|---|---|---|
| String 索引含義 | Character 類型 | byte | byte | byte | Char 類型 | Char 類型 |
| String 是 Char 數(shù)組? | ? | ? | ? | ? | ? | ? |
注:這里并不考察 String 與 Char 數(shù)組的轉(zhuǎn)換,因?yàn)樗姓Z(yǔ)言都支持這種操作。
可以看到,這些語(yǔ)言都做出了不同的選擇 (設(shè)計(jì)) ,設(shè)計(jì)者到底為什么做出決定,各個(gè)語(yǔ)言為何在 string 的概念上不盡相同。
這一切的背后到底是道德的淪喪,還是人性的扭曲。
仔細(xì)思考一下這個(gè)分類,其實(shí)是很粗糙的,同時(shí)也存在一些問(wèn)題的,比如:
不同語(yǔ)言中字符類型相同嗎?C 語(yǔ)言中 char 是 8 位,Java 中是 16 位,Rust 中是 32 位,其他語(yǔ)言呢?基于不同的 char 類型比較得出的結(jié)論有意義嗎?
String 類型的屬性依賴于另一個(gè)類型?假如改變某一個(gè)語(yǔ)言中字符類型的實(shí)現(xiàn),那 String 的屬性也跟著變了
為了解釋這些疑問(wèn),同時(shí)為了看到各語(yǔ)言中 String 類型更本質(zhì)的區(qū)別,我們?cè)龠M(jìn)一步來(lái)看看 String 類型的實(shí)現(xiàn)。
# 深入實(shí)現(xiàn)之前 —— Unicode 編碼?#
在討論 String 的實(shí)現(xiàn)之前,我們先簡(jiǎn)單講解一下 Unicode 編碼,讀者可能之前聽(tīng)到過(guò) UTF-8、UTF-16、UTF-32,這里會(huì)盡可能地從 high-level 進(jìn)行講解。
首先我們從編碼說(shuō)起,一句話解釋,編碼就是將 Code Points 轉(zhuǎn)化成二進(jìn)制字節(jié)的過(guò)程;
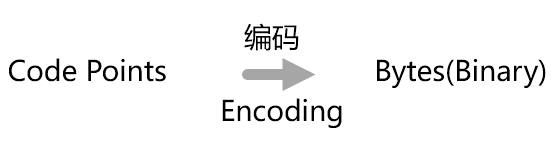
依然從老朋友 ASCII 碼講起,對(duì)于 ASCII 碼而言,編碼只有一種,直接將編號(hào)換算 (進(jìn)制轉(zhuǎn)換) 成二進(jìn)制 (或者十六進(jìn)制) 即可;
如:大寫(xiě)字母 “A” 的編號(hào) 65,編碼后就是 0x41。
基于這種直接進(jìn)制轉(zhuǎn)換的思想,我們便得到了名為 UTF-32 的編碼方式 —— 直接將 Unicode Code Point 轉(zhuǎn)換成 32 位的二進(jìn)制字節(jié)即可;
如下圖中的 A 和 ,分別換算成 00 00 00 41 和 00 01 F6 00,
這種編碼方式的缺點(diǎn)很明顯 —— 浪費(fèi)空間,對(duì)于常用的小編號(hào) Code Point (字母和數(shù)字,在 ASCII 字符集內(nèi)的字符) ,會(huì)存在前導(dǎo)零,這些前導(dǎo)零會(huì)浪費(fèi)空間。
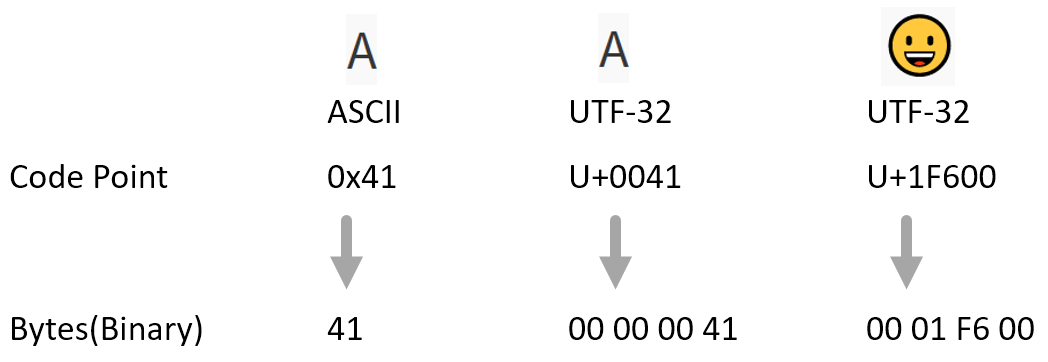
為了解決 UTF-32 浪費(fèi)空間的前導(dǎo)零,便有了變長(zhǎng)編碼 —— UTF-8。
讀者只需要理解兩種編碼的由來(lái)和特點(diǎn)即可,至于如何具體編碼,這篇文章不會(huì)包含這部分內(nèi)容。
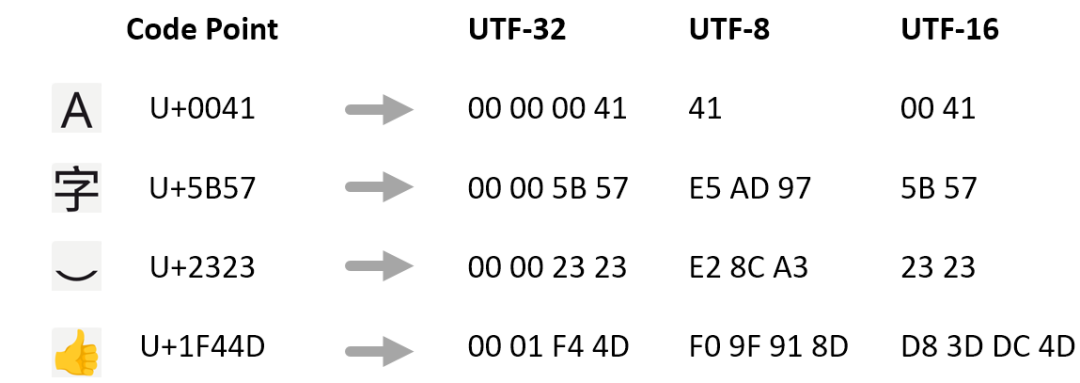
在上圖中可以看到,Code Point 經(jīng)過(guò) UTF-8 編碼得到的字節(jié)從一個(gè)到四個(gè)不等。
再引入一個(gè)概念——Code Unit ?(編碼單元) ,指的是編碼后的基本單元的長(zhǎng)度,UTF-32 的編碼單元是 32 位,4 個(gè)字節(jié),編碼名稱中的 32 指的就是編碼單元的長(zhǎng)度;
UTF-8 同理,編碼后的基本單元長(zhǎng)度是 8 位,一個(gè)字節(jié)。
關(guān)于 UTF-16,從現(xiàn)在的角度來(lái)看,既有前導(dǎo)零浪費(fèi)空間的問(wèn)題 (下圖中的 A 字符) ,又是變長(zhǎng)編碼 (變長(zhǎng)編碼的缺點(diǎn)在后面會(huì)討論到) ,
這東西可以說(shuō)完全是 “時(shí)代的眼淚”,UTF-16 的設(shè)計(jì)初衷是 “定長(zhǎng)編碼”,因?yàn)樵缙诘?Unicode 標(biāo)準(zhǔn)犯了一個(gè)歷史錯(cuò)誤——過(guò)早承諾了 Code Point 可以用 16 位存下。
但隨著 Unicode 標(biāo)準(zhǔn)的演進(jìn),最初的設(shè)計(jì)優(yōu)點(diǎn) (定長(zhǎng)編碼) 不復(fù)存在,成了只留下了缺點(diǎn) (浪費(fèi)空間和變長(zhǎng)) 的編碼方案。
雖然不在本文的關(guān)注范圍內(nèi),但是如果遇到文本亂碼,那基本上是編碼問(wèn)題了。
你無(wú)法在不知道編碼的情況下解決亂碼的問(wèn)題。
沒(méi)有編碼的字符串,毫無(wú)意義!——馬主任
在了解了 Unicode 和相關(guān)編碼之后,再來(lái)回頭看一下各種語(yǔ)言的 Char 和 String 類型的實(shí)現(xiàn):
| ? | Swift | Go | Rust | Julia | Java | C# |
|---|---|---|---|---|---|---|
| String 實(shí)現(xiàn)編碼 | UTF-16 -> UTF-8 | UTF-8 | UTF-8 | UTF-8 | UTF-16 | UTF-16 |
| String 索引含義 | Character 類型 | byte | byte | byte | Char 類型 | Char 類型 |
| 字符類型 | User-perceived character | 32 位 | 32 位 | 32 位 | 16 位 | 16 位 |
| 字符類型是用戶角度的字符? | ? | ? | ? | ? | ? | ? |
| String 是編碼單元數(shù)組? | ? | ? | ? | ? | ? | ? |
可以很明顯的看到,首先是 String 類型實(shí)現(xiàn)上的不同——有的語(yǔ)言采用了 UTF-8 編碼,有的采用了 UTF-16。
其次,連 Char 類型的實(shí)現(xiàn)也不一樣,Swift 中的 Character 類型,其抽象程度是最高的,可以直接用來(lái)表示用戶角度的字符;比如需要 7 個(gè) Code Point 才能表示的一家子 ,在 Swift 中完全可以用一個(gè) Character 類型的變量存下。
其它語(yǔ)言中的 Char 類型有 32 位的也有 16 位的,這兩種實(shí)現(xiàn)中只有 32 位的 Char 可以表示 Unicode Code Point,而 16 位 Char 甚至連一個(gè) Code Point 都無(wú)法表示,要知道,Code Point 可是 Unicode 標(biāo)準(zhǔn)中最小的帶有語(yǔ)義的單元。
編程語(yǔ)言中各不相同的 String 和 Char 類型的設(shè)計(jì),是否存在統(tǒng)一的視角進(jìn)行解讀?
# String 類型的歷史變遷 #
下面,從計(jì)算機(jī)發(fā)展的角度來(lái)理解一下各語(yǔ)言的設(shè)計(jì)初衷。
# ASCII 碼, C 語(yǔ)言
計(jì)算機(jī)早期處理的自然語(yǔ)言字符很有限,使用 ASCII 編碼就能裝下,對(duì)于字符串和字符的概念也沒(méi)有明確的區(qū)分。
比如在 C 語(yǔ)言中,使用 8 位的 Char 類型表示 ASCII 字符,而字符串也自然而然地使用了 char 數(shù)組。
從這里開(kāi)始慢慢誕生了一個(gè)假設(shè)或者說(shuō)是潛意識(shí)的習(xí)慣 —— “一個(gè) Char 表示一個(gè)字符”,很顯然,這里需要限定是 8 位 Char 和 ASCII 碼字符。
# Unicode, UTF-16,Java 和 C#
隨著計(jì)算機(jī)的發(fā)展,出現(xiàn)了 Unicode 來(lái)統(tǒng)一人類的語(yǔ)言的編碼,但是早期的 Unicode 犯了一個(gè) 歷史性錯(cuò)誤——承諾 Unicode 字符可以用 16 位存下。
與此同時(shí)第一批支持 Unicode 的 Java 和 windows 都成了受害者——選擇了 UTF-16 編碼,但這個(gè)編碼延續(xù)了以前的“習(xí)慣” —— “一個(gè) Char 依然能表示一個(gè)字符”,只不過(guò)這里的 Char 變成了 16 位,字符變成了早期 Unicode 字符集里的字符。
這個(gè)時(shí)期的編程語(yǔ)言里也出現(xiàn)了獨(dú)立的數(shù)據(jù)類型 String 來(lái)表示字符串,幸運(yùn)的是,在 UTF-16 編碼下,String 依然可以視作 Char 數(shù)組,因?yàn)?UTF-16 編碼中每個(gè)編碼單元都是 16 位,這些語(yǔ)言中的 Char 也從以前語(yǔ)言中的 8 位變成了 16 位。
# Unicode,UTF-8 和最近的編程語(yǔ)言
隨著 Unicode 的進(jìn)一步發(fā)展,標(biāo)準(zhǔn)內(nèi)的字符集已經(jīng)無(wú)法用 16 位裝下了,需要 32 位才能表示一個(gè) Unicode 編碼的字符。
甚至還出現(xiàn)了一些組合字符或者修飾字符,甚至有些自然語(yǔ)言里無(wú)法清晰地定義 “字符” 這個(gè)概念。
這時(shí)候即使是能夠表示 Unicode 編碼字符的 32 位 Char,也不能表示用戶角度的字符了。
此時(shí)上述“習(xí)慣” —— “Char == 字符”已經(jīng)不成立了,與此同時(shí)出現(xiàn)了 UTF-8 的編碼方式,該編碼方式被大量的網(wǎng)站和協(xié)議,工具等采用,采用 UTF-16 實(shí)現(xiàn) String 的編程語(yǔ)言開(kāi)始產(chǎn)生新的問(wèn)題:
雖然 String 依然是 Char 數(shù)組,但這里的 16 位 Char 表示能力已經(jīng)遠(yuǎn)低于后面語(yǔ)言中的 32 位 Char 了,甚至一些漢字和 emoji 需要兩個(gè) 16 位 Char 才可以表示。
丟棄假設(shè)“Char == 字符”,String 不再視作 Char 數(shù)組,如 Go、Rust、Julia。這些語(yǔ)言中,不存在 String 到 Char 的抽象開(kāi)銷(xiāo),由此帶來(lái)了高效的字符串處理效率,但是需要用戶先打破自己對(duì)字符串的傳統(tǒng)認(rèn)知
# String 類型的設(shè)計(jì)與性能 #
說(shuō)完了比較 high-level,比較抽象的設(shè)計(jì)層面,我們?cè)賮?lái)關(guān)注一下更具體的東西——性能,看看 String 的設(shè)計(jì)與性能會(huì)存在什么樣的聯(lián)系。
首先補(bǔ)充兩個(gè)背景知識(shí):
UTF-8 已成為事實(shí)上的標(biāo)準(zhǔn)。
變長(zhǎng)編碼帶來(lái)的 Code Point 抽象層開(kāi)銷(xiāo)。
這兩條背景知識(shí)剛好對(duì)應(yīng)著 String 性能的兩個(gè)維度——外部和內(nèi)部:
String 外部的性能 (與其他庫(kù)或者接口操作) ,String 實(shí)現(xiàn)采用非 UTF-8 編碼時(shí),會(huì)在 String 編解碼時(shí)產(chǎn)生開(kāi)銷(xiāo) (如 Java 和 C#) 。
String 內(nèi)部的性能 (自身操作) ,比如查找,切片等操作,String 抽象成非 “編碼單元” 數(shù)組時(shí),由于多了一層抽象層 (編碼索引和字符索引之間的轉(zhuǎn)換) ,在 String 自身操作時(shí)會(huì)產(chǎn)生性能問(wèn)題 (如 Swift) 。
舉例說(shuō)明 UTF-8 變長(zhǎng)編碼索引 Code Point 時(shí)的性能開(kāi)銷(xiāo):

比如,如果我們想得到漢字“陽(yáng)”的字符類型索引,由于前面的字符 (字母標(biāo)點(diǎn)和漢字) 對(duì)應(yīng)的編碼字節(jié)都是不確定的,所以需要從頭開(kāi)始計(jì)算,這樣一個(gè) O(N) 的操作對(duì)于字符串這種準(zhǔn)基本類型代價(jià)是很高的。
再來(lái)定性分析一下各語(yǔ)言 String 類型的性能:
| ? | Swift | Go | Rust | Julia | Java | C# |
|---|---|---|---|---|---|---|
| String 是編碼單元數(shù)組? | ? | ? | ? | ? | ? | ? |
| 字符串操作開(kāi)銷(xiāo) | 有 | 無(wú) | 無(wú) | 無(wú) | 無(wú) | 無(wú) |
| String 實(shí)現(xiàn)編碼 | UTF-8 | UTF-8 | UTF-8 | UTF-8 | UTF-16 | UTF-16 |
| API 間編解碼開(kāi)銷(xiāo) | 無(wú) | 無(wú) | 無(wú) | 無(wú) | 有 | 有 |
繼續(xù)具體地看一下各個(gè)語(yǔ)言的 String 類型:
Swift
該語(yǔ)言中的 Character 抽象能力最強(qiáng),可以表示用戶角度的字符,其 String 類型的長(zhǎng)度也是符合人類直覺(jué)的 “字符串” 的長(zhǎng)度;但是由于 Character 這層抽象層,不僅在使用上帶來(lái)不便,為什么 Swift 的 String 這么難用?[3],性能也會(huì)受影響,Swift String 性能問(wèn)題)?[4]。
Java
在 Java 18 中,各種 API 已經(jīng)默認(rèn)使用了 UTF-8 編碼,但是使用 UTF-16 實(shí)現(xiàn)的 String 不可避免的會(huì)產(chǎn)生編解碼的開(kāi)銷(xiāo);與此同時(shí),由于 16 位 Char 表達(dá)能力的缺陷,在 String 類型的 API 中除了 Char 相關(guān)的,也有 Code Point 相關(guān)的,如 CharAt (int index)?[5] 和 codePointAt (int index)?[6]。
C#
不光有 16 位的 Char 類型,還有 32 位的 Rune 類型。
(一點(diǎn)吐槽,Java 設(shè)計(jì) UTF-16 String 是由于 Unicode 標(biāo)準(zhǔn)的歷史錯(cuò)誤,但是 C# 的時(shí)期是可以避免這點(diǎn)的,為什么也栽了跟頭呢?)
雖然 C# String 實(shí)現(xiàn)和微軟自家生態(tài)都是基于 UTF-16,但微軟官方也在提倡采用 UTF-8 編碼,Use the Windows UTF-8 code page?[7]。
Go,Rust,Julia
基于 UTF-8 編碼,無(wú)額外抽象層的 String 類型,在性能上看不到明顯短板,唯一可能讓人感到違背直覺(jué)的——無(wú)法按照 char 來(lái)操作,接下來(lái)我們就來(lái)講解一下。
# Code Point Unaware String?#
比較現(xiàn)代的語(yǔ)言都選擇了 UTF-8 實(shí)現(xiàn)的 string,性能上可以看到兩方面都沒(méi)有劣勢(shì),唯一可能讓人感到違背直覺(jué)的——無(wú)法按照 char 來(lái)操作,更準(zhǔn)確的說(shuō)法是,Code Point Unaware String,在網(wǎng)上也可以經(jīng)常看到一些討論,如 what if strings were Code Point aware??[8]?on Rust,Indexing strings by Unicode code point instead of code unit??[9]?on Julia。
那么這個(gè)設(shè)計(jì)的初衷是什么呢,即使不去設(shè)計(jì)編程語(yǔ)言,作為語(yǔ)言 (庫(kù)) 的使用者又該如何理解呢?
首先,從實(shí)現(xiàn)的角度來(lái)說(shuō),變長(zhǎng)的 UTF-8 編碼不適合 “直接” 抽象成 Code Point 數(shù)組 (可以參考 Swift 的抽象層導(dǎo)致的性能問(wèn)題) ;
其次,在當(dāng)今的軟件中,索引 Code Point 并不像大家直覺(jué)中那么重要,絕大部分場(chǎng)景 Code Point 都不能滿足需求。
從實(shí)際的應(yīng)用軟件角度來(lái)考慮:
鼠標(biāo)移動(dòng)和選定——從上面的例子可以發(fā)現(xiàn),用戶角度的字符并不是由 Char 一一對(duì)應(yīng)的,在這種情況下,使用到的基本單位是字素 (grapheme)
文本查找和替換的場(chǎng)景——類似下方背景中性能問(wèn)題提到的例子,需要先通過(guò)遍歷或者搜索得到字符串的位置,再通過(guò)這個(gè)位置來(lái)操作,而這個(gè)位置是字節(jié)還是 Code Point 的并不會(huì)影響功能,但是會(huì)影響性能 (后者需要額外的計(jì)算)
限制長(zhǎng)度的場(chǎng)景——如輸入字符串,協(xié)議傳輸,數(shù)據(jù)庫(kù)等;更關(guān)心字符串編碼后的長(zhǎng)度,即字節(jié)數(shù),使用到的基本單位是 (code unit)
在屏幕上渲染 “字符”——同樣地,與 Char 無(wú)關(guān),一個(gè) Char 占據(jù)多少列是不確定的,需要由渲染引擎決
最后一點(diǎn),不是那么明顯但是影響深遠(yuǎn),Code Point 這層抽象不是一個(gè) “正確” 的抽象。 Code Point 在簡(jiǎn)單的場(chǎng)景中使用看起來(lái)不會(huì)有問(wèn)題,但一旦問(wèn)題變復(fù)雜,程序員可能意識(shí)不到是編程語(yǔ)言的數(shù)據(jù)類型的問(wèn)題;Code Point 作為一個(gè)不準(zhǔn)確的抽象,如果僅指望通過(guò)它來(lái)進(jìn)行簡(jiǎn)化,無(wú)異于掩蓋 Unicode 的復(fù)雜性,而這種行為反倒會(huì)埋下潛在的隱患。
由此可見(jiàn),該抽象層可能會(huì)誤導(dǎo)程序員,掩蓋了所處理問(wèn)題的復(fù)雜性。 # 總結(jié) # 從編程語(yǔ)言的歷史演進(jìn)中可以看到,String 可以說(shuō)是始于 Char 數(shù)組,但隨著處理問(wèn)題越來(lái)越復(fù)雜 (源于人類語(yǔ)言的復(fù)雜性) ,在一些現(xiàn)代語(yǔ)言中,String 已經(jīng)不再作為 Char 數(shù)組,而是獨(dú)立成單獨(dú)的類型;出于不同的目的或者是原因,各個(gè)編程語(yǔ)言中的字符類型和 String 類型也存在著這樣或那樣的差異。
審核編輯:劉清












 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論