 電子發(fā)燒友App
電子發(fā)燒友App


01 What is High-Cardinality
基數(Cardinality) 在數學中定義是用來代表集合元素個數的標量,比如對于有限集合 A = {a, b, c} 的基數就是 3,對于無限集合也有一個基數概念,但是今天主要談論的是計算機領域,就不在這里展開。
在數據庫的上下文里面,基數并沒有嚴格的定義,但大家對基數的共識可借鑒數學中的定義:用來衡量數據列包含的不同數值的個數多少。比如說一個記錄用戶的數據表,通常有 UID, Name 和 Gender 這幾個列,很顯然,UID 的基數最高,因為每個用戶都會被分配一個唯一的 ID, Name 也算高的,但由于會遇到重名的用戶,就不如 UID 那么高,而 Gender 一列可能數值相對較少。所以在用戶表這個例子里面,就可以稱 UID 列屬于高基,而 Gender 則屬于低基。
如果再細分到時序數據庫的領域,基數往往是特指時間線的個數,我們就以時序數據庫在可觀測領域的應用舉例:一個典型場景是記錄 API 服務的請求時間。舉一個最簡單的例子,針對不同 instance 的 API 服務各個接口的響應時間,就有兩個 label: API Routes 和 Instance, 如果有 20 個接口,5 個 Instance,時間線的基數就是 (20+1)x(5+1)-1 = 125(+1 是考慮到可以單獨看某個 Instance 所有接口響應時間或某個接口在所有 Instances 的響應時間), 看上去數值不大,但要注意算子是乘積,所以只要某個 label 基數高,或者新增加一個 label,就會導致時間線的基數暴增。
02 Why it matters
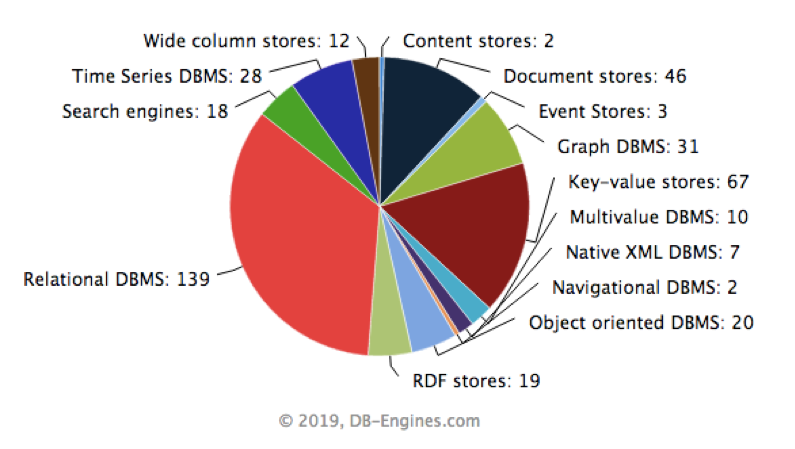
眾所周知,對于大家最熟悉的 MySQL 這類關系型數據庫而言,一般都有 ID 列,還有比如像 email, order-number 等等常見的列,這些都是 high-cardinality 的列,很少聽說因為這樣的數據建模而引起某些問題。事實也是這樣,在我們熟悉的 OLTP 領域,往往 high-cardinality 并不是一個問題,但在時序領域,因為數據模型的原因,往往會帶來問題,在進到時序領域之前,我們還是先來討論一下高基的數據集到底意味著什么。
在我看來,高基的數據集換個通俗的說法就是數據量大,那對于數據庫而言,數據量的增加必然會對寫入、查詢和存儲三個方面都帶來影響。特別注意,在寫入時影響最大的還是索引。
2.1 傳統(tǒng)數據庫的高基數
以關系型數據庫中采用的最常見的用來建立索引的數據結構 B-tree 為例,通常情況下,插入、查詢的復雜度是 O(logN),空間的復雜度一般來講是 O(N), 其中的 N 是元素個數,也就是我們談到的基數。自然 N 越大會有一定影響,但因為插入和查詢的復雜度是自然對數,所以數據量級不是特別大的情況下,影響并沒那么大。
所以看起來高基數據并沒有帶來什么不可忽視的影響,反而在很多情況下,高基數據的索引比低基數據的索引選擇性更強,高基索引通過一個查詢條件就可以過濾掉大部分不滿足條件的數據,從而減少磁盤 I/O 開銷,在數據庫應用方面,需要避免過多磁盤和網絡的 I/O 開銷。比如 select * from users where gender = "male";,得到的數據集就非常多,磁盤 I/O 和網絡 I/O 都會很大,實踐中,單獨使用這個低基數索引的意義也并不大。
2.2 時序數據庫的高基數
那么時序數據庫究竟有什么不同的地方,使得高基的數據列會引起問題?在時序數據領域,無論是數據建模還是引擎設計,核心會圍繞時間線進行。正如前面談到的,時序數據庫里面的高基問題,指的是時間線的數量大小,這個大小不僅僅是一個列的基數,而是所有 label 列的基數乘積,這樣的擴散性就會非常大,可以理解成在常見的關系型數據庫中,高基是隔離在某個列中,即數據規(guī)模是線性增長,而時序數據庫中的高基是多列的乘積,是非線性增長。讓我們具體來看看在時序數據庫中的高基時間線是如何產生的,我們先看第一種場景:
2.2.1 Time-series 數量
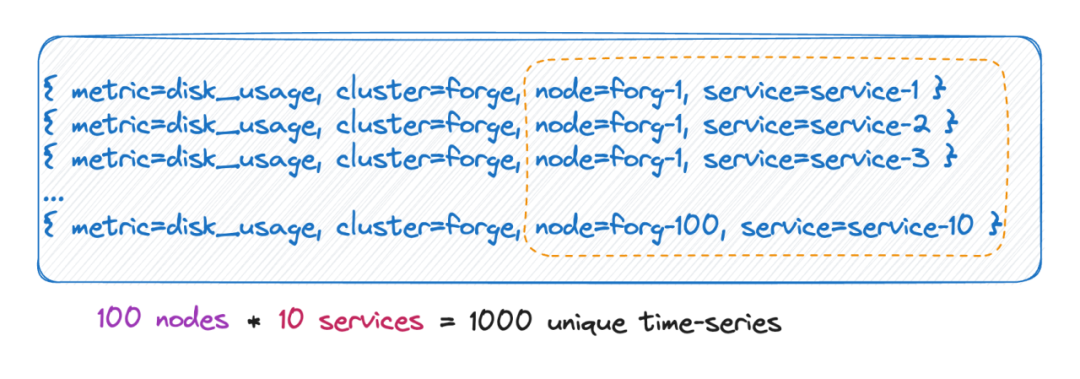
我們知道,時間線數量實際上就等于所有 label 基數的笛卡爾積。
如上圖,時間線數量就是 100 * 10 = 1000 條時間線,如果給這個 metric 再加上 6 個 tag,每個 tag value 的取值有 10 種,時間線數量就是 10^9 ,也就是一億條時間線,可以想象這個量級了。
2.3 Tag 擁有無限多的值
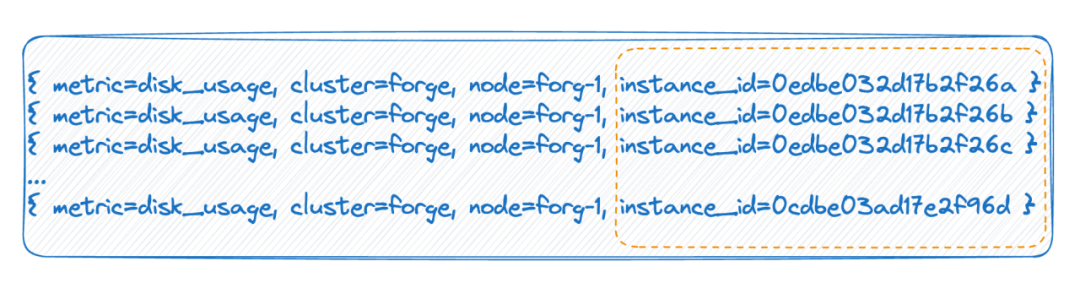
第二種情況,比如在云原生環(huán)境里,每個 pod 都有一個 ID,每次重啟時實際上 pod 是刪除再重建,它會生成一個新的 ID,這就導致這個 tag value 的值會非常的多,每次全量重啟會導致時間線數量翻一倍。
以上兩種情況,就是時序數據庫所說的高基數產生的主要原因。
2.4 時序數據庫如何組織數據
我們知道高基數是怎么產生的了,要理解它會導致什么問題,還要了解主流的時序數據庫是怎么組織數據的。
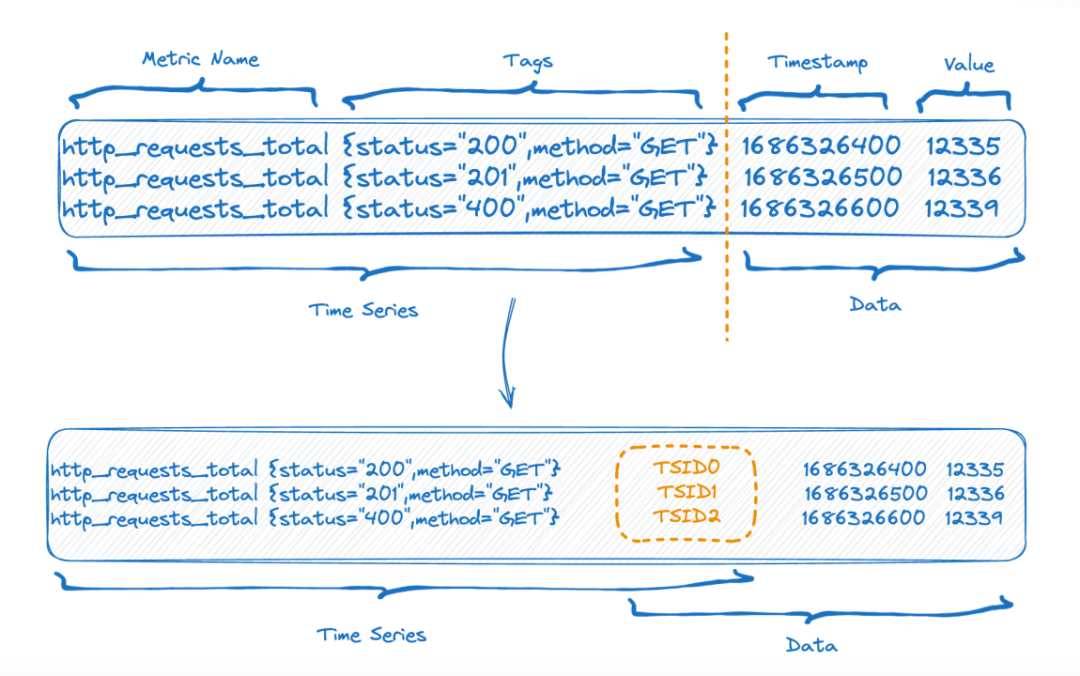
圖中上半部分是數據寫入前的表現形式,下半部分的圖則是數據存儲后的邏輯上的表現形式,左側也就是 time-series 部分的索引數據,右側則是數據部分。
每個 time-series 可以生成一個唯一的 TSID,索引和數據就是通過 TSID 關聯(lián)起來的,這個索引,熟悉的朋友可能已經看出來了,它就是倒排索引。
再來看下圖,是倒排索引在內存中的一個表現形式:
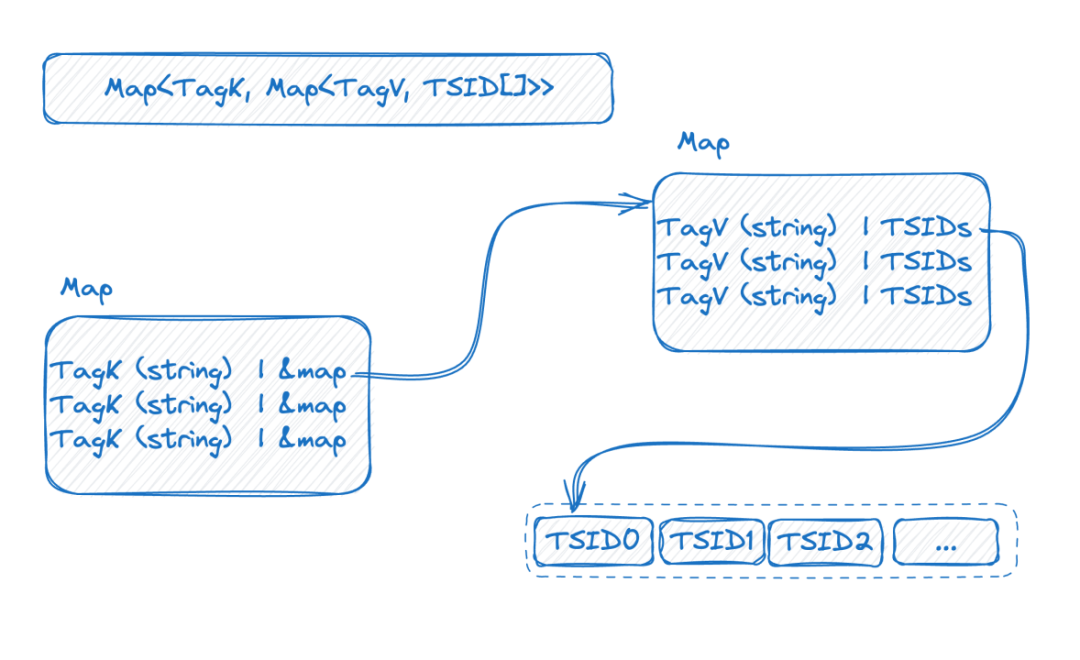
這是一個雙層的 map,外層先通過 tag name 找到內層 map,內層 map 的 K 是 tag value, V 是包含相應 tag value 的 TSID 的集合。
到這里再結合前面的介紹,我們可以看出來了,時序數據的基數越高,這個雙層 map 就會越大。
明白了索引結構以后我們就可以試圖去理解高基問題是如何產生的:
為了實現高吞吐的寫入,這個索引最好能保留在內存中,高基數則會導致索引膨脹從而讓你的內存中放不下索引。內存放不下就要交換到磁盤,交換到磁盤后就會因為大量的隨機磁盤 IO 影響寫入速度。
再來看查詢,從索引結構我們是可以猜到查詢的過程,比如查詢條件 where status = 200 and method="get",流程是先去找 key 為 status 的 map,拿到內層的 map 再根據 "200" 獲取所有 TSID 集合,同樣的方式再去查下一個條件,然后兩個 TSID 集合做交集后得到的新的 TSID 集合再去一個一個的按照 TSID 去撈數據。
可以看出,問題就核心在于數據是按照時間線來組織的,所以先要拿到時間線,再按照時間線去找數據。一次查詢涉及到的時間線越多,查詢就會越慢。
03 How to solve it
如果我們分析的是對的,知道了在時序數據領域下引起高基問題的原因,那也就好解決了,再來看一下引起問題的原因:
- 數據層面:C(L1) * C(L2) * C(L3) * ... * C(Ln) 引起的索引維護,查詢挑戰(zhàn)。
- 技術層面:數據是按照時間線來組織的,所以你先要拿到時間線,再按照時間線去找數據,時間線多就查詢變慢。
那小編拋磚引玉一下分別從兩個方面來探討解法:
3.1 數據建模上的優(yōu)化
#1 去掉不必要的 labels
我們經常會不小心將一些不必要字段設定成 label,從而導致時間線膨脹。比如說我們在監(jiān)控服務器狀態(tài)時,經常會有 instance_name, ip, 其實這兩個字段沒有必要都成為 label, 有其中一個很可能就可以了,另外一個可以設定成屬性。
#2 根據實際的查詢來做數據建模
- 10w 個設備
- 100 個地區(qū)
- 10 種設備
如果建模到一個 metric 里面,在 Prometheus 里面,就會導致有 10w * 100 * 10 = 1 億的時間線。(非嚴謹計算)
思考一下,查詢會按照這種方式進行么?比如說查詢某個某種類型設備在某個地區(qū)的時間線?這個似乎不太合理,因為一旦指定了設備,那種類也就確定了,所以這兩個 label 之間其實是不需要做在一起,那可能就變成:
metric_one: 10w 個設備
metric_two: 100 個地區(qū);10 種設備
metric_three: (假設某個設備可能會換到不同的地區(qū)采集數據)10w 個設備;100 個地區(qū)
這樣總計也就是 10w + 100*10 + 10w*100 ~ 1010w 的時間線,比起上述要少了 10倍。
#3 將有價值的高基時間線數據單獨管理
當然如果發(fā)現你的數據建模已經和查詢非常符合了,由于數據規(guī)模太大,依然無法將時間線減少,那就把和這個核心指標有關的服務都單獨放到一個更好的機器上吧。
3.2 時序數據庫技術上的優(yōu)化
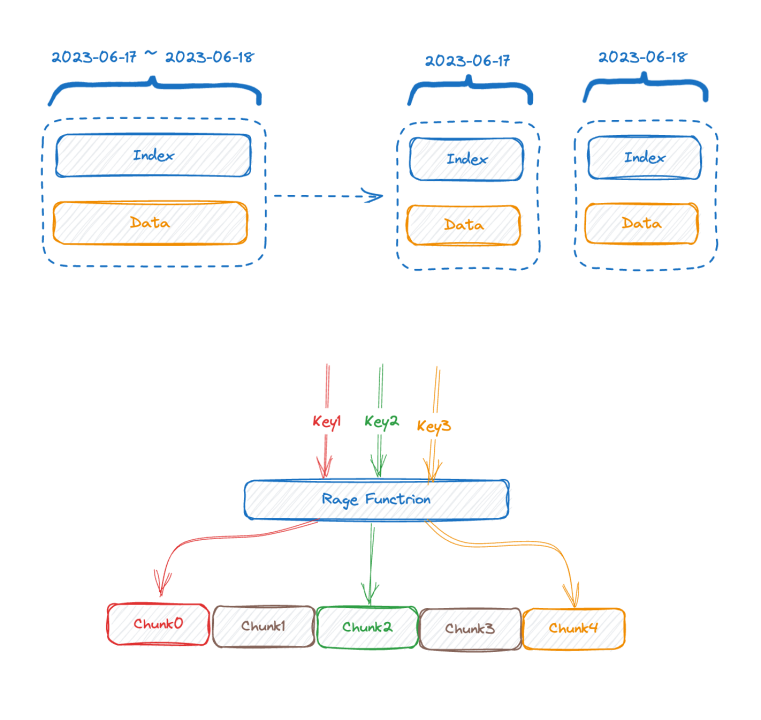
- 第一個有效的解法是垂直切分,大部分業(yè)界主流時序數據庫或多或少都采用了類似方法,按照時間來切分索引,因為如果不做這個切分的話,隨著時間的推進,索引會越來越膨脹,最后到內存放不下,如果按照時間切分,可以把舊的 index chunk 交換到磁盤甚至遠程存儲,起碼寫入是不會被影響到了。
- 與垂直切分相對的,就是水平切分,用一個 sharding key,一般可以是查詢謂詞使用頻率最高的一個或者幾個 tag,按照這些 tag 的 value 來進行 range 或者 hash 切分,這樣就相當于使用分布式的分而治之思想解決了單機上的瓶頸,代價就是如果查詢條件不帶 sharding key 的話通常是無法將算子下推,只能把數據撈到最上層去計算。
上面兩個辦法,屬于傳統(tǒng)的解決辦法,只能一定程度緩解問題,并不能從根本上解決問題。
接下來兩個方案不算是常規(guī)方案,是 GreptimeDB 在嘗試探索的方向,這里只稍微提下不做深入的分析,僅供大家參考:
- 我們可能要思考一下,時序數據庫是不是真的都需要倒排索引,TimescaleDB 采用 B-tree 索引, InfluxDB_IOx 也沒有倒排,對高基數的查詢,我們使用 OLAP 數據庫常用的分區(qū)掃描結合 min-max 索引進行一些剪枝優(yōu)化,效果會不會更好?
- 異步的智能索引了,要智能,就得先采集和分析行為,在用戶的一次次查詢中分析并異步構建最合適的索引來加速查詢,比如對用戶查詢條件中出現頻率非常低的 tag 我們選擇不為它創(chuàng)建倒排。
上面兩個方案結合起來看,在寫入的時候,因為倒排異步構建了,所以完全不影響寫入速度。
再來看查詢,因為時序數據有時間屬性,所以數據是可以按照 timestamp 來分桶,在最近的 time bucket 上我們不做索引,解決辦法就是硬掃,結合一些 min-max 類索引進行剪枝優(yōu)化,秒級掃描千萬行上億行還是可以做到的。
一個查詢來了,先去預估會涉及多少時間線,涉及少的走倒排,多的不走倒排直接走 scan + filter 的方式。
以上這些想法,我們還在不斷的探索當中,還不完善。
04 Conclusion 高基并不總是問題,有時候高基是必要的,我們需要做的是結合自身的業(yè)務情況以及所使用的工具性質,來構建自己的數據模型。當然有時候工具有一定場景局限性,比如 Prometheus 默認是為每個 metric 下的 label 建立索引,在單機場景下問題不大,同時還能方便用戶使用,但放到了大規(guī)模數據下就會捉襟見肘。GreptimeDB 是致力打造在單機和規(guī)模化場景下的統(tǒng)一解決方案,對于高基問題的技術嘗試,我們也在探索,也歡迎大家一起討論。
編輯:黃飛
?












 工商網監(jiān)
工商網監(jiān)
評論