 電子發燒友App
電子發燒友App


最近有同學面試字節三面的時候,被問到:“MySQL 分頁有什么性能問題?怎么優化?”
小林哥,MySQL分頁怎么優化?,面字節的時候被問到了,一二面考,算法撐過去了,但是MySQL優化的問題沒怎么準備過。
今天就主要圍繞這個問題跟大家說一下 MySQL 分頁問題和優化的思路。
我們刷網站的時候,我們經常會遇到需要分頁查詢的場景。
比如下圖紅框里的翻頁功能。

我們很容易能聯想到可以用mysql實現。
假設我們的建表sql是這樣的
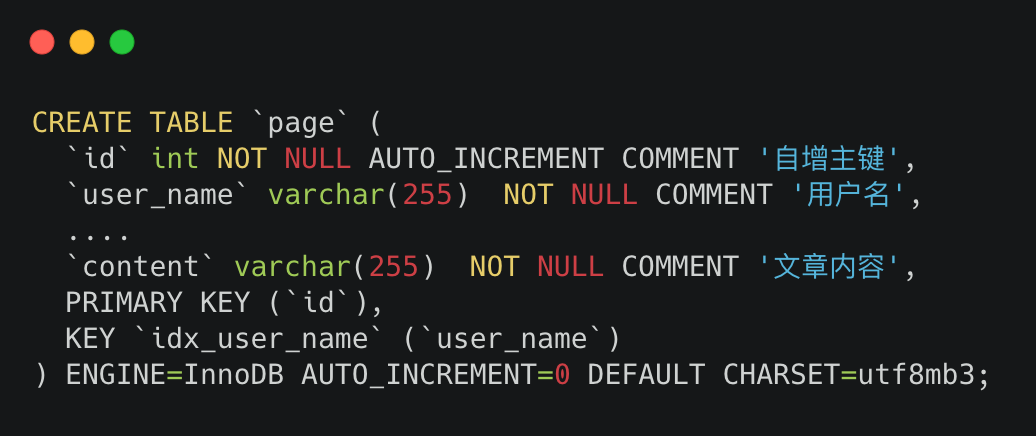
mysql建表sql
建表sql大家也不用扣細節,只需要知道id是主鍵,并且在user_name建了個非主鍵索引就夠了,其他都不重要。
為了實現分頁。
很容易聯想到下面這樣的sql語句。
select?*?from?page?order?by?id?limit?offset,?size;
比如一頁有10條數據。
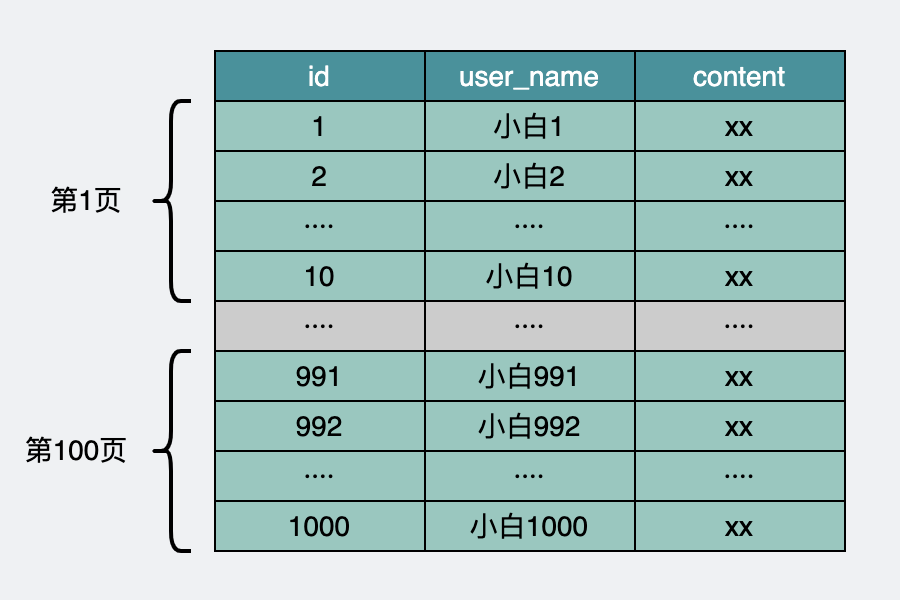
user表數據庫原始狀態
第一頁就是下面這樣的sql語句。
select?*?from?page?order?by?id?limit?0,?10;
第一百頁就是
select?*?from?page?order?by?id?limit?990,?10;
那么問題來了。
用這種方式,同樣都是拿10條數據,查第一頁和第一百頁的查詢速度是一樣的嗎?為什么?
兩種limit的執行過程
上面的兩種查詢方式。對應 limit offset, size 和 limit size 兩種方式。
而其實 limit size ,相當于 ?limit 0, size。也就是從0開始取size條數據。
也就是說,兩種方式的區別在于offset是否為0。
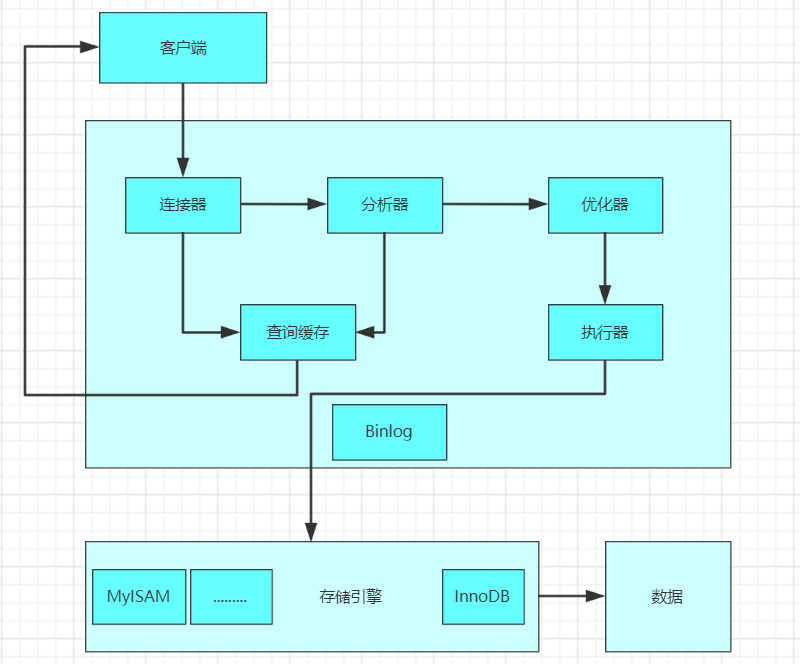
我們先來看下limit sql的內部執行邏輯。
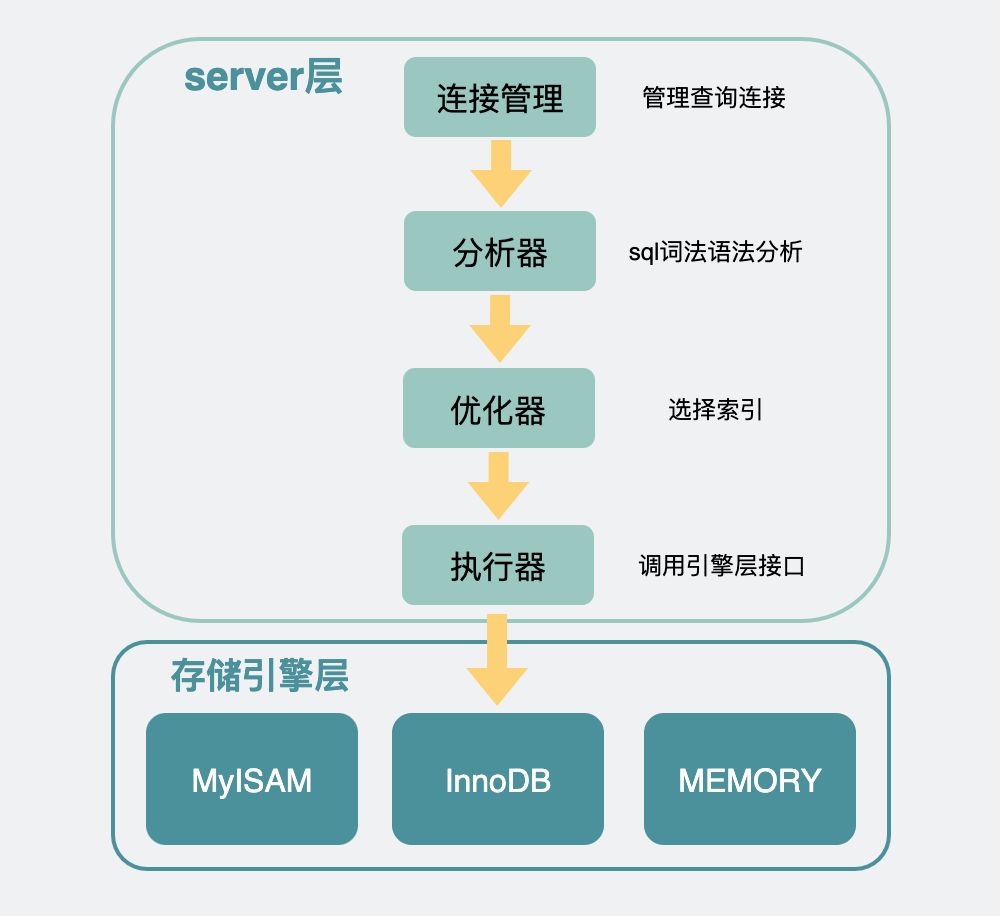
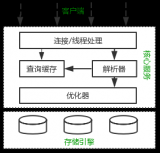
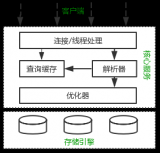
Mysql架構
mysql內部分為server層和存儲引擎層。一般情況下存儲引擎都用innodb。
server層有很多模塊,其中需要關注的是執行器是用于跟存儲引擎打交道的組件。
執行器可以通過調用存儲引擎提供的接口,將一行行數據取出,當這些數據完全符合要求(比如滿足其他where條件),則會放到結果集中,最后返回給調用mysql的客戶端(go、java寫的應用程序)。
我們可以對下面的sql先執行下 explain。
explain?select?*?from?page?order?by?id?limit?0,?10;
可以看到,explain中提示 key 那里,執行的是PRIMARY,也就是走的主鍵索引。
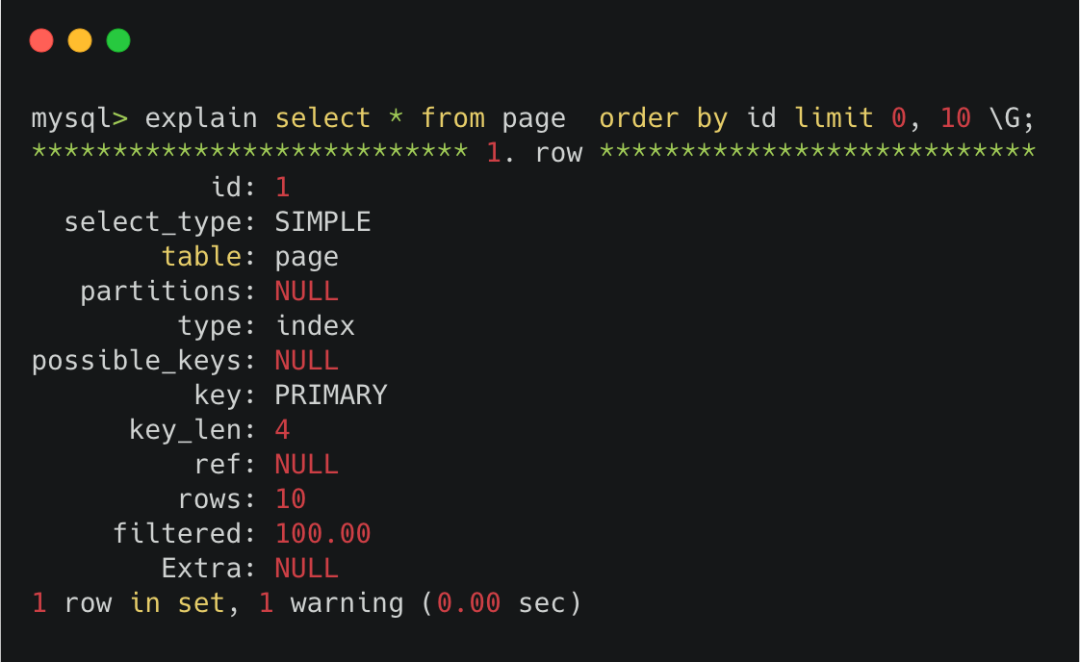
分頁查詢offset=0
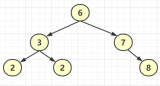
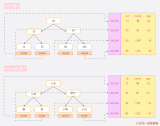
主鍵索引本質是一棵B+樹,它是放在innodb中的一個數據結構。
我們可以回憶下,B+樹大概長這樣。
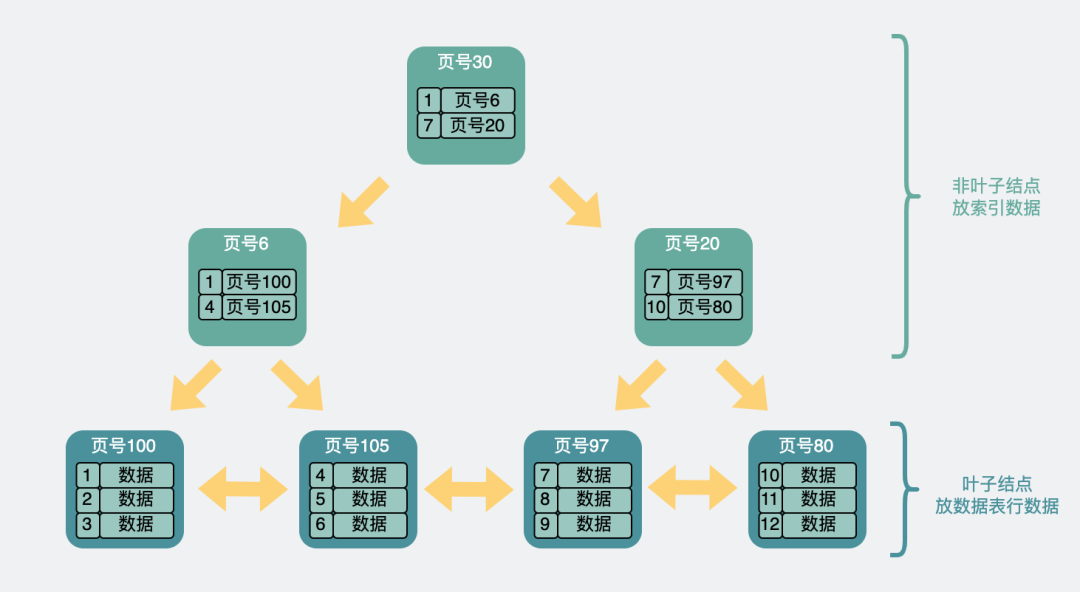
B+樹結構
在這個樹狀結構里,我們需要關注的是,最下面一層節點,也就是葉子結點。而這個葉子結點里放的信息會根據當前的索引是主鍵還是非主鍵有所不同。
如果是主鍵索引,它的葉子節點會存放完整的行數據信息。
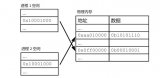
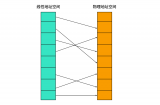
如果是非主鍵索引,那它的葉子節點則會存放主鍵,如果想獲得行數據信息,則需要再跑到主鍵索引去拿一次數據,這叫回表。
比如執行
select?*?from?page?where?user_name?=?"小白10";
會通過非主鍵索引去查詢user_name為"小白10"的數據,然后在葉子結點里找到"小白10"的數據對應的主鍵為10。
此時回表到主鍵索引中做查詢,最后定位到主鍵為10的行數據。
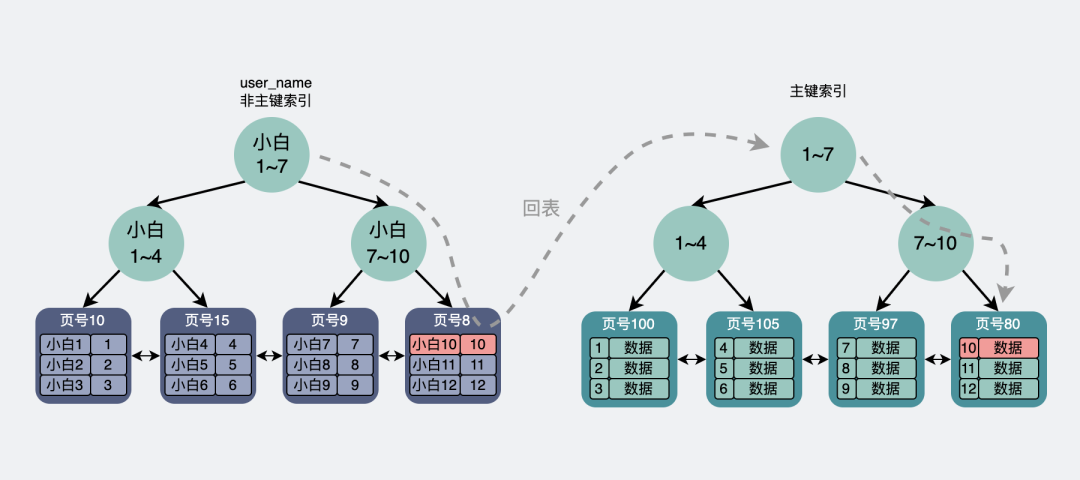
回表
但不管是主鍵還是非主鍵索引,他們的葉子結點數據都是有序的。比如在主鍵索引中,這些數據是根據主鍵id的大小,從小到大,進行排序的。
基于主鍵索引的limit執行過程
那么回到文章開頭的問題里。
當我們去掉explain,執行這條sql。
select?*?from?page?order?by?id?limit?0,?10;
上面select后面帶的是星號,也就是要求獲得行數據的所有字段信息。*
server層會調用innodb的接口,在innodb里的主鍵索引中獲取到第0到10條完整行數據,依次返回給server層,并放到server層的結果集中,返回給客戶端。
而當我們把offset搞離譜點,比如執行的是
select?*?from?page?order?by?id?limit?6000000,?10;
server層會調用innodb的接口,由于這次的offset=6000000,會在innodb里的主鍵索引中獲取到第0到(6000000 + 10)條完整行數據,返回給server層之后根據offset的值挨個拋棄,最后只留下最后面的size條,也就是10條數據,放到server層的結果集中,返回給客戶端。
可以看出,當offset非0時,server層會從引擎層獲取到很多無用的數據,而獲取的這些無用數據都是要耗時的。
因此,我們就知道了文章開頭的問題的答案,mysql查詢中 limit 1000,10 會比 limit 10 更慢。原因是 limit 1000,10 會取出1000+10條數據,并拋棄前1000條,這部分耗時更大
那這種case有辦法優化嗎?
可以看出,當offset非0時,server層會從引擎層獲取到很多無用的數據,而當select后面是*號時,就需要拷貝完整的行信息,拷貝完整數據跟只拷貝行數據里的其中一兩個列字段耗時是不同的,這就讓原本就耗時的操作變得更加離譜。
因為前面的offset條數據最后都是不要的,就算將完整字段都拷貝來了又有什么用呢,所以我們可以將sql語句修改成下面這樣。
select?*?from?page??where?id?>=(select?id?from?page??order?by?id?limit?6000000,?1)?order?by?id?limit?10;
上面這條sql語句,里面先執行子查詢 select id from page order by id limit 6000000, 1, 這個操作,其實也是將在innodb中的主鍵索引中獲取到6000000+1條數據,然后server層會拋棄前6000000條,只保留最后一條數據的id。
但不同的地方在于,在返回server層的過程中,只會拷貝數據行內的id這一列,而不會拷貝數據行的所有列,當數據量較大時,這部分的耗時還是比較明顯的。
在拿到了上面的id之后,假設這個id正好等于6000000,那sql就變成了
select?*?from?page??where?id?>=(6000000)?order?by?id?limit?10;
這樣innodb再走一次主鍵索引,通過B+樹快速定位到id=6000000的行數據,時間復雜度是lg(n),然后向后取10條數據。
這樣性能確實是提升了,親測能快一倍左右,屬于那種耗時從3s變成1.5s的操作。
這······
屬實有些杯水車薪,有點搓,屬于沒辦法中的辦法。
基于非主鍵索引的limit執行過程
上面提到的是主鍵索引的執行過程,我們再來看下基于非主鍵索引的limit執行過程。
比如下面的sql語句
select?*?from?page?order?by?user_name??limit?0,?10;
server層會調用innodb的接口,在innodb里的非主鍵索引中獲取到第0條數據對應的主鍵id后,回表到主鍵索引中找到對應的完整行數據,然后返回給server層,server層將其放到結果集中,返回給客戶端。
而當offset>0時,且offset的值較小時,邏輯也類似,區別在于,offset>0時會丟棄前面的offset條數據。
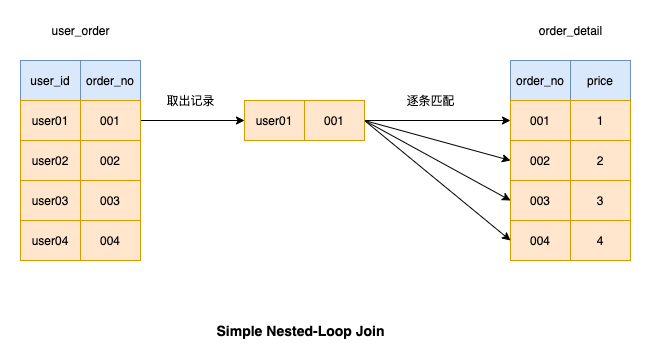
也就是說非主鍵索引的limit過程,比主鍵索引的limit過程,多了個回表的消耗。
但當offset變得非常大時,比如600萬,此時執行explain。
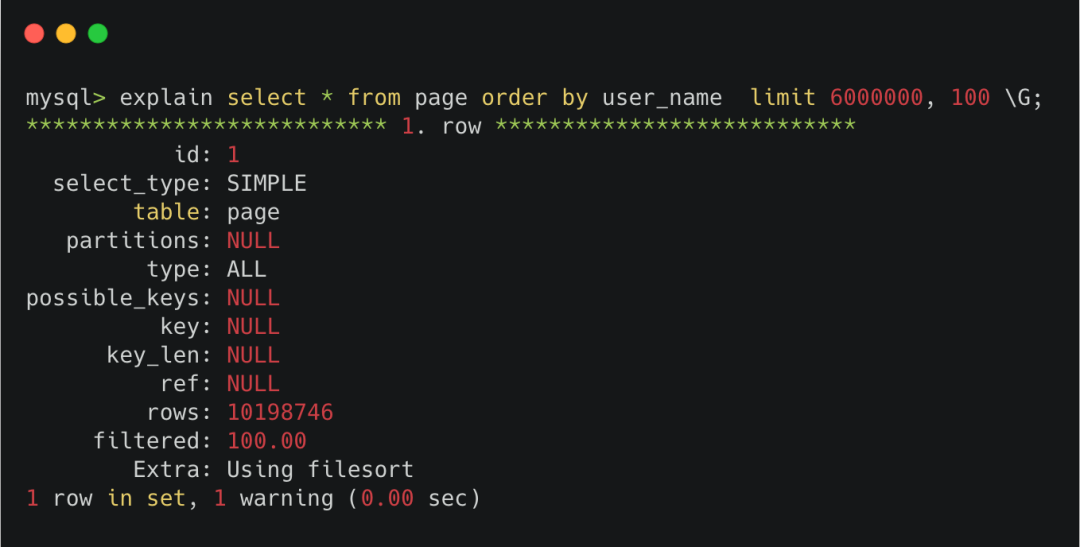
非主鍵索引offset值超大時走全表掃描
可以看到type那一欄顯示的是ALL,也就是全表掃描。
這是因為server層的優化器,會在執行器執行sql語句前,判斷下哪種執行計劃的代價更小。
很明顯,優化器在看到非主鍵索引的600w次回表之后,搖了搖頭,還不如全表一條條記錄去判斷算了,于是選擇了全表掃描。
因此,當limit offset過大時,非主鍵索引查詢非常容易變成全表掃描。是真·性能殺手。
這種情況也能通過一些方式去優化。比如
select?*?from?page?t1,?(select?id?from?page?order?by?user_name?limit?6000000,?100)?t2??WHERE?t1.id?=?t2.id;
通過select id from page order by user_name limit 6000000, 100。先走innodb層的user_name非主鍵索引取出id,因為只拿主鍵id,不需要回表,所以這塊性能會稍微快點,在返回server層之后,同樣拋棄前600w條數據,保留最后的100個id。然后再用這100個id去跟t1表做id匹配,此時走的是主鍵索引,將匹配到的100條行數據返回。這樣就繞開了之前的600w條數據的回表。
當然,跟上面的case一樣,還是沒有解決要白拿600w條數據然后拋棄的問題,這也是非常挫的優化。
像這種,當offset變得超大時,比如到了百萬千萬的量級,問題就突然變得嚴肅了。
這里就產生了個專門的術語,叫深度分頁。
深度分頁問題
深度分頁問題,是個很惡心的問題,惡心就惡心在,這個問題,它其實無解。
不管你是用mysql還是es,你都只能通過一些手段去"減緩"問題的嚴重性。
遇到這個問題,我們就該回過頭來想想。
為什么我們的代碼會產生深度分頁問題?
它背后的原始需求是什么,我們可以根據這個做一些規避。
如果你是想取出全表的數據
有些需求是這樣的,我們有一張數據庫表,但我們希望將這個數據庫表里的所有數據取出,異構到es,或者hive里,這時候如果直接執行
select?*?from?page;
這個sql一執行,狗看了都搖頭。
因為數據量較大,mysql根本沒辦法一次性獲取到全部數據,妥妥超時報錯。
于是不少mysql小白會通過limit offset size分頁的形式去分批獲取,剛開始都是好的,等慢慢地,哪天數據表變得奇大無比,就有可能出現前面提到的深度分頁問題。
這種場景是最好解決的。
我們可以將所有的數據根據id主鍵進行排序,然后分批次取,將當前批次的最大id作為下次篩選的條件進行查詢。
可以看下偽代碼
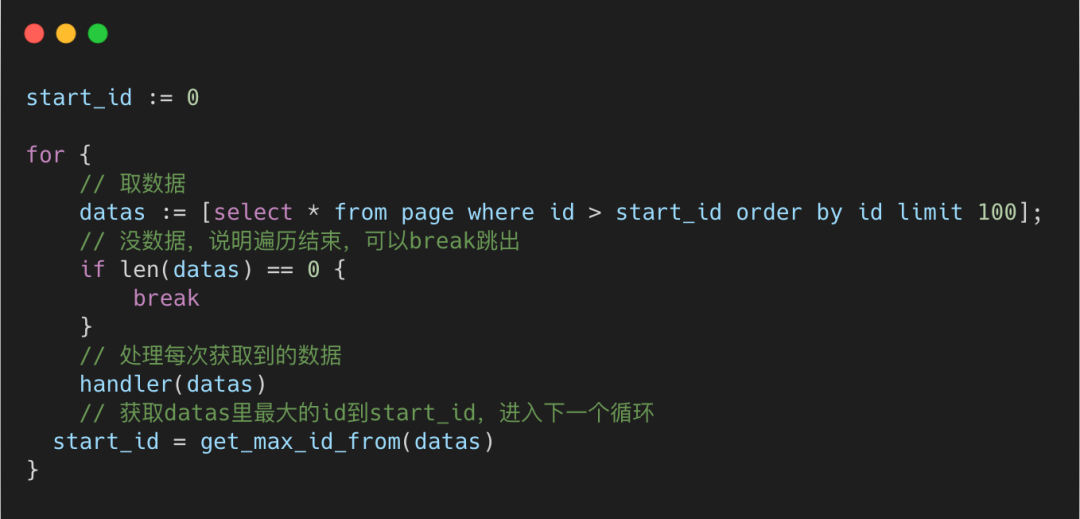
batch獲取數據
這個操作,可以通過主鍵索引,每次定位到id在哪,然后往后遍歷100個數據,這樣不管是多少萬的數據,查詢性能都很穩定。
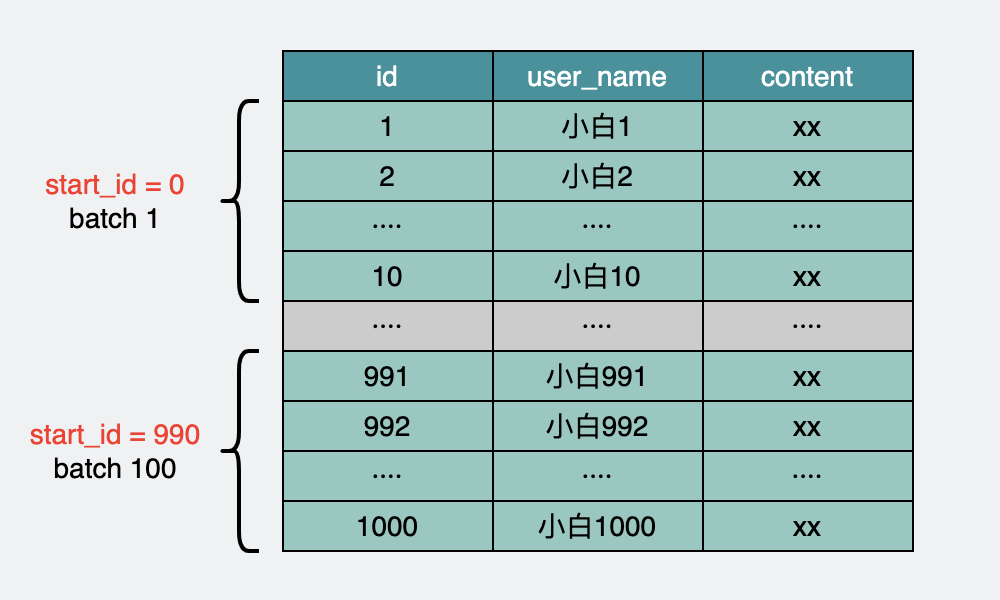
batch分批獲取user表
如果是給用戶做分頁展示
如果深度分頁背后的原始需求只是產品經理希望做一個展示頁的功能,比如商品展示頁,那么我們就應該好好跟產品經理battle一下了。
什么樣的翻頁,需要翻到10多萬以后,這明顯是不合理的需求。
是不是可以改一下需求,讓它更接近用戶的使用行為?
比如,我們在使用谷歌搜索時看到的翻頁功能。

一般來說,谷歌搜索基本上都在20頁以內,作為一個用戶,我就很少會翻到第10頁之后。
作為參考。
如果我們要做搜索或篩選類的頁面的話,就別用mysql了,用es,并且也需要控制展示的結果數,比如一萬以內,這樣不至于讓分頁過深。
如果因為各種原因,必須使用mysql。那同樣,也需要控制下返回結果數量,比如數量1k以內。
這樣就能勉強支持各種翻頁,跳頁(比如突然跳到第6頁然后再跳到第106頁)。
但如果能從產品的形式上就做成不支持跳頁會更好,比如只支持上一頁或下一頁。

上下頁的形式
這樣我們就可以使用上面提到的start_id方式,采用分批獲取,每批數據以start_id為起始位置。這個解法最大的好處是不管翻到多少頁,查詢速度永遠穩定。
總結
limit offset, size 比 limit size 要慢,且offset的值越大,sql的執行速度越慢。
當offset過大,會引發深度分頁問題,目前不管是mysql還是es都沒有很好的方法去解決這個問題。只能通過限制查詢數量或分批獲取的方式進行規避。
遇到深度分頁的問題,多思考其原始需求,大部分時候是不應該出現深度分頁的場景的,必要時多去影響產品經理。
如果數據量很少,比如1k的量級,且長期不太可能有巨大的增長,還是用limit offset, size 的方案吧,整挺好,能用就行。
編輯:黃飛















 工商網監
工商網監
評論