 電子發燒友App
電子發燒友App


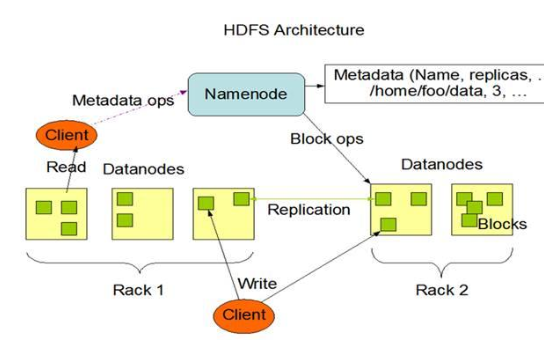
HDFS全稱是Hadoop Distributed File System,是Hadoop項目中常見的一種 分布式文件系統,在Hadoop項目中,HDFS解決了文件分布式存儲的問題。
HDFS有很多特點:
① 保存多個副本,且提供容錯機制,副本丟失或宕機自動恢復。默認存3份。
② 運行在廉價的機器上。
③ 適合大數據的處理。多大?多小?HDFS默認會將文件分割成block,64M為1個block,不足一64M的就以實際文件大小為block存在DataNode中。然后將block按鍵值對(形如:Block1: host2,host1,host3)存儲在HDFS上,并將鍵值對的映射存到NameNode的內存中。一個鍵值對的映射大約為150個字節(如果存儲1億個文件,則NameNode需要20G空間),如果小文件太多,則會在NameNode中產生相應多的鍵值對映射,那NameNode內存的負擔會很重。而且處理大量小文件速度遠遠小于處理同等大小的大文件的速度。每一個小文件要占用一個slot,而task啟動將耗費大量時間甚至大部分時間都耗費在啟動task和釋放task上。
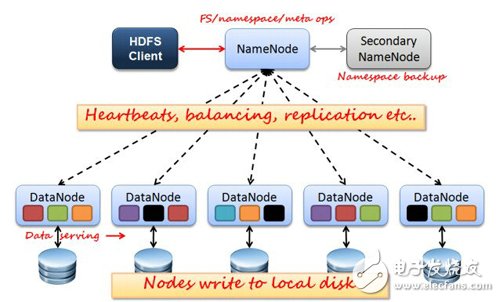
如上圖所示,HDFS也是按照Master和Slave的結構。分NameNode、SecondaryNameNode、DataNode這幾個角色。
NameNode:是Master節點,是HDFS的管理員。管理數據塊映射;處理客戶端的讀寫請求;負責維護元信息;配置副本策略;管理HDFS的名稱空間等
SecondaryNameNode:負責元信息和日志的合并;合并fsimage和fsedits然后再發給namenode。
PS:NameNode和SecondaryNameNode兩者沒有關系,更加不是備份,NameNode掛掉的時候SecondaryNameNode并不能頂替他的工作。
然而,由于NameNode單點問題,在Hadoop2中NameNode以集群的方式部署主要表現為HDFS Feration和HA,從而省去了SecondaryNode的存在,關于Hadoop2.x的改進移步hadoop1.x 與hadoop2.x 架構變化分析
DataNode:Slave節點,奴隸,干活的。負責存儲client發來的數據塊block;執行數據塊的讀寫操作。
熱備份:b是a的熱備份,如果a壞掉。那么b馬上運行代替a的工作。
冷備份:b是a的冷備份,如果a壞掉。那么b不能馬上代替a工作。但是b上存儲a的一些信息,減少a壞掉之后的損失。
fsimage:元數據鏡像文件(文件系統的目錄樹。)是在NameNode啟動時對整個文件系統的快照
edits:啟動后NameNode對元數據的操作日志(針對文件系統做的修改操作記錄)
namenode內存中存儲的是=fsimage+edits。
只有在NameNode重啟時,edit logs才會合并到fsimage文件中,從而得到一個文件系統的最新快照。但是在產品集群中NameNode是很少重啟的,這也意味著當NameNode運行了很長時間后,edit logs文件會變得很大。在這種情況下就會出現下面一些問題:
edit logs文件會變的很大,怎么去管理這個文件是一個挑戰。
NameNode的重啟會花費很長時間,因為有很多在edit logs中的改動要合并到fsimage文件上。
如果NameNode掛掉了,那我們就丟失了很多改動因為此時的fsimage文件非常舊。[筆者認為在這個情況下丟失的改動不會很多, 因為丟失的改動應該是還在內存中但是沒有寫到edit logs的這部分。]
那么其實可以在NameNode中起一個程序定時進行新的fsimage=edits+fsimage的更新,但是有一個更好的方法是SecondaryNameNode。
SecondaryNameNode的職責是合并NameNode的edit logs到fsimage文件中,減少NameNode下一次重啟過程
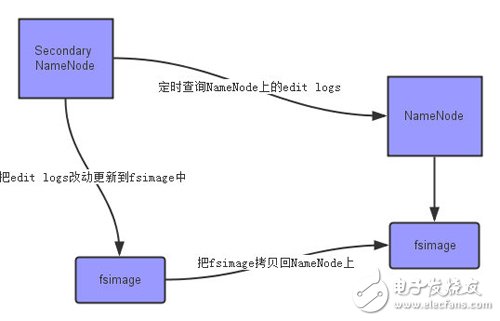
上面的圖片展示了Secondary NameNode是怎么工作的。
首先,它定時到NameNode去獲取edit logs,并更新到自己的fsimage上。
一旦它有了新的fsimage文件,它將其拷貝回NameNode中。
NameNode在下次重啟時會使用這個新的fsimage文件,從而減少重啟的時間。
Secondary NameNode的整個目的是在HDFS中提供一個檢查點。它只是NameNode的一個助手節點。這也是它在社區內被認為是檢查點節點的原因。SecondaryNameNode負責定時默認1小時,從namenode上,獲取fsimage和edits來進行合并,然后再發送給namenode。減少namenode的工作量和下一次重啟過程。
工作原理
寫操作:
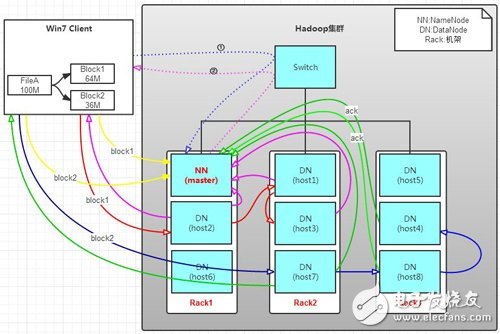
有一個文件FileA,100M大小。Client將FileA寫入到HDFS上。
HDFS按默認配置。
HDFS分布在三個機架上Rack1,Rack2,Rack3。
a. Client將FileA按64M分塊。分成兩塊,block1和Block2;
b. Client向nameNode發送寫數據請求,如圖藍色虛線①------》。
c. NameNode節點,記錄block信息(即鍵值對的映射)。并返回可用的DataNode,如粉色虛線②------》。
Block1: host2,host1,host3
Block2: host7,host8,host4
原理:
NameNode具有RackAware機架感知功能,這個可以配置。
若client為DataNode節點,那存儲block時,規則為:副本1,同client的節點上;副本2,不同機架節點上;副本3,同第二個副本機架的另一個節點上;其他副本隨機挑選。
若client不為DataNode節點,那存儲block時,規則為:副本1,隨機選擇一個節點上;副本2,不同副本1,機架上;副本3,同副本2相同的另一個節點上;其他副本隨機挑選。
d. client向DataNode發送block1;發送過程是以流式寫入。
流式寫入過程,
1》將64M的block1按64k的package劃分;
2》然后將第一個package發送給host2;
3》host2接收完后,將第一個package發送給host1,同時client想host2發送第二個package;
4》host1接收完第一個package后,發送給host3,同時接收host2發來的第二個package。
5》以此類推,如圖紅線實線所示,直到將block1發送完畢。
6》host2,host1,host3向NameNode,host2向Client發送通知,說“消息發送完了”。如圖粉紅顏色實線所示。
7》client收到host2發來的消息后,向namenode發送消息,說我寫完了。這樣就真完成了。如圖黃色粗實線
8》發送完block1后,再向host7,host8,host4發送block2,如圖藍色實線所示。
9》發送完block2后,host7,host8,host4向NameNode,host7向Client發送通知,如圖淺綠色實線所示。
10》client向NameNode發送消息,說我寫完了,如圖黃色粗實線。。。這樣就完畢了。
分析,通過寫過程,我們可以了解到:
①寫1T文件,我們需要3T的存儲,3T的網絡流量帶寬。
②在執行讀或寫的過程中,NameNode和DataNode通過HeartBeat進行保存通信,確定DataNode活著。如果發現DataNode死掉了,就將死掉的DataNode上的數據,放到其他節點去。讀取時,要讀其他節點去。
③掛掉一個節點,沒關系,還有其他節點可以備份;甚至,掛掉某一個機架,也沒關系;其他機架上,也有備份。
讀操作:
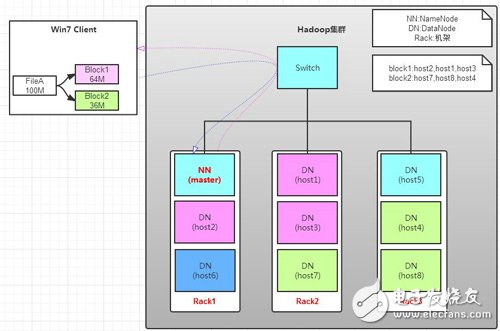
讀操作就簡單一些了,如圖所示,client要從datanode上,讀取FileA。而FileA由block1和block2組成。
那么,讀操作流程為:
a. client向namenode發送讀請求。
b. namenode查看Metadata信息(鍵值對的映射),返回fileA的block的位置。
block1:host2,host1,host3
block2:host7,host8,host4
c. block的位置是有先后順序的,先讀block1,再讀block2。而且block1去host2上讀取;然后block2,去host7上讀取;
上面例子中,client位于機架外,那么如果client位于機架內某個DataNode上,例如,client是host6。那么讀取的時候,遵循的規律是:
優先讀取本機架上的數據。
HDFS中常用到的命令
![HDFS全稱是Hadoop Distributed File System,是Hadoop項目中常見的一種 分布式文件系統,在Hadoop項目中,HDFS解決了文件分布式存儲的問題。 HDFS有很多特點: ① 保存多個副本,且提供容錯機制,副本丟失或宕機自動恢復。默認存3份。 ② 運行在廉價的機器上。 ③ 適合大數據的處理。多大?多小?HDFS默認會將文件分割成block,64M為1個block,不足一64M的就以實際文件大小為block存在DataNode中。然后將block按鍵值對(形如:Block1: host2,host1,host3)存儲在HDFS上,并將鍵值對的映射存到NameNode的內存中。一個鍵值對的映射大約為150個字節(如果存儲1億個文件,則NameNode需要20G空間),如果小文件太多,則會在NameNode中產生相應多的鍵值對映射,那NameNode內存的負擔會很重。而且處理大量小文件速度遠遠小于處理同等大小的大文件的速度。每一個小文件要占用一個slot,而task啟動將耗費大量時間甚至大部分時間都耗費在啟動task和釋放task上。 如上圖所示,HDFS也是按照Master和Slave的結構。分NameNode、SecondaryNameNode、DataNode這幾個角色。 NameNode:是Master節點,是HDFS的管理員。管理數據塊映射;處理客戶端的讀寫請求;負責維護元信息;配置副本策略;管理HDFS的名稱空間等 SecondaryNameNode:負責元信息和日志的合并;合并fsimage和fsedits然后再發給namenode。 PS:NameNode和SecondaryNameNode兩者沒有關系,更加不是備份,NameNode掛掉的時候SecondaryNameNode并不能頂替他的工作。 然而,由于NameNode單點問題,在Hadoop2中NameNode以集群的方式部署主要表現為HDFS Feration和HA,從而省去了SecondaryNode的存在,關于Hadoop2.x的改進移步hadoop1.x 與hadoop2.x 架構變化分析 DataNode:Slave節點,奴隸,干活的。負責存儲client發來的數據塊block;執行數據塊的讀寫操作。 熱備份:b是a的熱備份,如果a壞掉。那么b馬上運行代替a的工作。 冷備份:b是a的冷備份,如果a壞掉。那么b不能馬上代替a工作。但是b上存儲a的一些信息,減少a壞掉之后的損失。 fsimage:元數據鏡像文件(文件系統的目錄樹。)是在NameNode啟動時對整個文件系統的快照 edits:啟動后NameNode對元數據的操作日志(針對文件系統做的修改操作記錄) namenode內存中存儲的是=fsimage+edits。 只有在NameNode重啟時,edit logs才會合并到fsimage文件中,從而得到一個文件系統的最新快照。但是在產品集群中NameNode是很少重啟的,這也意味著當NameNode運行了很長時間后,edit logs文件會變得很大。在這種情況下就會出現下面一些問題: edit logs文件會變的很大,怎么去管理這個文件是一個挑戰。 NameNode的重啟會花費很長時間,因為有很多在edit logs中的改動要合并到fsimage文件上。 如果NameNode掛掉了,那我們就丟失了很多改動因為此時的fsimage文件非常舊。[筆者認為在這個情況下丟失的改動不會很多, 因為丟失的改動應該是還在內存中但是沒有寫到edit logs的這部分。] 那么其實可以在NameNode中起一個程序定時進行新的fsimage=edits+fsimage的更新,但是有一個更好的方法是SecondaryNameNode。 SecondaryNameNode的職責是合并NameNode的edit logs到fsimage文件中,減少NameNode下一次重啟過程 上面的圖片展示了Secondary NameNode是怎么工作的。 首先,它定時到NameNode去獲取edit logs,并更新到自己的fsimage上。 一旦它有了新的fsimage文件,它將其拷貝回NameNode中。 NameNode在下次重啟時會使用這個新的fsimage文件,從而減少重啟的時間。 Secondary NameNode的整個目的是在HDFS中提供一個檢查點。它只是NameNode的一個助手節點。這也是它在社區內被認為是檢查點節點的原因。SecondaryNameNode負責定時默認1小時,從namenode上,獲取fsimage和edits來進行合并,然后再發送給namenode。減少namenode的工作量和下一次重啟過程。 工作原理 寫操作: 有一個文件FileA,100M大小。Client將FileA寫入到HDFS上。 HDFS按默認配置。 HDFS分布在三個機架上Rack1,Rack2,Rack3。 a. Client將FileA按64M分塊。分成兩塊,block1和Block2; b. Client向nameNode發送寫數據請求,如圖藍色虛線①------》。 c. NameNode節點,記錄block信息(即鍵值對的映射)。并返回可用的DataNode,如粉色虛線②------》。 Block1: host2,host1,host3 Block2: host7,host8,host4 原理: NameNode具有RackAware機架感知功能,這個可以配置。 若client為DataNode節點,那存儲block時,規則為:副本1,同client的節點上;副本2,不同機架節點上;副本3,同第二個副本機架的另一個節點上;其他副本隨機挑選。 若client不為DataNode節點,那存儲block時,規則為:副本1,隨機選擇一個節點上;副本2,不同副本1,機架上;副本3,同副本2相同的另一個節點上;其他副本隨機挑選。 d. client向DataNode發送block1;發送過程是以流式寫入。 流式寫入過程, 1》將64M的block1按64k的package劃分; 2》然后將第一個package發送給host2; 3》host2接收完后,將第一個package發送給host1,同時client想host2發送第二個package; 4》host1接收完第一個package后,發送給host3,同時接收host2發來的第二個package。 5》以此類推,如圖紅線實線所示,直到將block1發送完畢。 6》host2,host1,host3向NameNode,host2向Client發送通知,說“消息發送完了”。如圖粉紅顏色實線所示。 7》client收到host2發來的消息后,向namenode發送消息,說我寫完了。這樣就真完成了。如圖黃色粗實線 8》發送完block1后,再向host7,host8,host4發送block2,如圖藍色實線所示。 9》發送完block2后,host7,host8,host4向NameNode,host7向Client發送通知,如圖淺綠色實線所示。 10》client向NameNode發送消息,說我寫完了,如圖黃色粗實線。。。這樣就完畢了。 分析,通過寫過程,我們可以了解到: ①寫1T文件,我們需要3T的存儲,3T的網絡流量帶寬。 ②在執行讀或寫的過程中,NameNode和DataNode通過HeartBeat進行保存通信,確定DataNode活著。如果發現DataNode死掉了,就將死掉的DataNode上的數據,放到其他節點去。讀取時,要讀其他節點去。 ③掛掉一個節點,沒關系,還有其他節點可以備份;甚至,掛掉某一個機架,也沒關系;其他機架上,也有備份。 讀操作: 讀操作就簡單一些了,如圖所示,client要從datanode上,讀取FileA。而FileA由block1和block2組成。 那么,讀操作流程為: a. client向namenode發送讀請求。 b. namenode查看Metadata信息(鍵值對的映射),返回fileA的block的位置。 block1:host2,host1,host3 block2:host7,host8,host4 c. block的位置是有先后順序的,先讀block1,再讀block2。而且block1去host2上讀取;然后block2,去host7上讀取; 上面例子中,client位于機架外,那么如果client位于機架內某個DataNode上,例如,client是host6。那么讀取的時候,遵循的規律是: 優先讀取本機架上的數據。 HDFS中常用到的命令 1 3、hadoop fsck 4、start-balancer.sh 注意,看了hdfs的布局,以及作用,這里需要考慮幾個問題: 1、既然NameNode,存儲小文件不太合適,那小文件如何處理? 至少有兩種場景下會產生大量的小文件: (1)這些小文件都是一個大邏輯文件的一部分。由于HDFS在2.x版本開始支持對文件的append,所以在此之前保存無邊界文件(例如,log文件)(譯者注:持續產生的文件,例如日志每天都會生成)一種常用的方式就是將這些數據以塊的形式寫入HDFS中(a very common pattern for saving unbounded files (e.g. log files) is to write them in chunks into HDFS)。 (2)文件本身就是很小。設想一下,我們有一個很大的圖片語料庫,每一個圖片都是一個獨一的文件,并且沒有一種很好的方法來將這些文件合并為一個大的文件。 (1)第一種情況 對于第一種情況,文件是許多記錄(Records)組成的,那么可以通過調用HDFS的sync()方法(和append方法結合使用),每隔一定時間生成一個大文件。或者,可以通過寫一個程序來來合并這些小文件(可以看一下Nathan Marz關于Consolidator一種小工具的文章)。 (2)第二種情況 對于第二種情況,就需要某種形式的容器通過某種方式來對這些文件進行分組。Hadoop提供了一些選擇: HAR File Hadoop Archives (HAR files)是在0.18.0版本中引入到HDFS中的,它的出現就是為了緩解大量小文件消耗NameNode內存的問題。HAR文件是通過在HDFS上構建一個分層文件系統來工作。HAR文件通過hadoop archive命令來創建,而這個命令實 際上是運行了一個MapReduce作業來將小文件打包成少量的HDFS文件(譯者注:將小文件進行合并幾個大文件)。對于client端來說,使用HAR文件沒有任何的改變:所有的原始文件都可見以及可訪問(只是使用har://URL,而不是hdfs://URL),但是在HDFS中中文件數卻減少了。 讀取HAR中的文件不如讀取HDFS中的文件更有效,并且實際上可能較慢,因為每個HAR文件訪問需要讀取兩個索引文件以及還要讀取數據文件本身(如下圖)。盡管HAR文件可以用作MapReduce的輸入,但是沒有特殊的魔法允許MapReduce直接操作HAR在HDFS塊上的所有文件(although HAR files can be used as input to MapReduce, there is no special magic that allows maps to operate over all the files in the HAR co-resident on a HDFS block)。 可以考慮通過創建一種input format,充分利用HAR文件的局部性優勢,但是目前還沒有這種input format。需要注意的是:MultiFileInputSplit,即使在HADOOP-4565的改進,但始終還是需要每個小文件的尋找。我們非常有興趣看到這個與SequenceFile進行對比。 在目前看來,HARs可能最好僅用于存儲文檔(At the current time HARs are probably best used purely for archival purposes.)](/uploads/allimg/171023/2474215-1G023104611Q7.png)
3、hadoop fsck
4、start-balancer.sh
注意,看了hdfs的布局,以及作用,這里需要考慮幾個問題:
1、既然NameNode,存儲小文件不太合適,那小文件如何處理?
至少有兩種場景下會產生大量的小文件:
(1)這些小文件都是一個大邏輯文件的一部分。由于HDFS在2.x版本開始支持對文件的append,所以在此之前保存無邊界文件(例如,log文件)(譯者注:持續產生的文件,例如日志每天都會生成)一種常用的方式就是將這些數據以塊的形式寫入HDFS中(a very common pattern for saving unbounded files (e.g. log files) is to write them in chunks into HDFS)。
(2)文件本身就是很小。設想一下,我們有一個很大的圖片語料庫,每一個圖片都是一個獨一的文件,并且沒有一種很好的方法來將這些文件合并為一個大的文件。
(1)第一種情況
對于第一種情況,文件是許多記錄(Records)組成的,那么可以通過調用HDFS的sync()方法(和append方法結合使用),每隔一定時間生成一個大文件。或者,可以通過寫一個程序來來合并這些小文件(可以看一下Nathan Marz關于Consolidator一種小工具的文章)。
(2)第二種情況
對于第二種情況,就需要某種形式的容器通過某種方式來對這些文件進行分組。Hadoop提供了一些選擇:
HAR File
Hadoop Archives (HAR files)是在0.18.0版本中引入到HDFS中的,它的出現就是為了緩解大量小文件消耗NameNode內存的問題。HAR文件是通過在HDFS上構建一個分層文件系統來工作。HAR文件通過hadoop archive命令來創建,而這個命令實 際上是運行了一個MapReduce作業來將小文件打包成少量的HDFS文件(譯者注:將小文件進行合并幾個大文件)。對于client端來說,使用HAR文件沒有任何的改變:所有的原始文件都可見以及可訪問(只是使用har://URL,而不是hdfs://URL),但是在HDFS中中文件數卻減少了。
讀取HAR中的文件不如讀取HDFS中的文件更有效,并且實際上可能較慢,因為每個HAR文件訪問需要讀取兩個索引文件以及還要讀取數據文件本身(如下圖)。盡管HAR文件可以用作MapReduce的輸入,但是沒有特殊的魔法允許MapReduce直接操作HAR在HDFS塊上的所有文件(although HAR files can be used as input to MapReduce, there is no special magic that allows maps to operate over all the files in the HAR co-resident on a HDFS block)。 可以考慮通過創建一種input format,充分利用HAR文件的局部性優勢,但是目前還沒有這種input format。需要注意的是:MultiFileInputSplit,即使在HADOOP-4565的改進,但始終還是需要每個小文件的尋找。我們非常有興趣看到這個與SequenceFile進行對比。 在目前看來,HARs可能最好僅用于存儲文檔(At the current time HARs are probably best used purely for archival purposes.)














 工商網監
工商網監
評論