 電子發(fā)燒友App
電子發(fā)燒友App


SDSoC 讓編程人員能夠構建完整的硬件— 軟件系統(tǒng),且不犧牲性能。
當今的醫(yī)療、工業(yè)及越來越多其他應用領域的“標準”圖像處理系統(tǒng)變得越來越先進。很多情況下,圖像處理復雜性已經超出了帶 GPU 加速功能的 PC的處理能力范圍。設計團隊在提高圖像處理質量標準,增加產品特性的同時,他們還必須滿足客戶對最終產品的更小型化、移動性、電池供電等要求。眾多現(xiàn)有平臺都在努力滿足如此復雜的要求。
?
幸運的是,設計團隊可利用賽靈思 Zynq?-7000 All Programmable SoC 和最新賽靈思 SDSoC ? 開發(fā)環(huán)境創(chuàng)建出小型、低功耗、特性豐富并帶有基于 C/C++ 語言的高級成像系統(tǒng)的產品。我們來了解一下如何使用 SDSoC環(huán)境對圖像流水線處理系統(tǒng)進行加速,以實現(xiàn)上述目標。我用不到一周時間就完成了這個項目,且實現(xiàn)了大幅度的系統(tǒng)加速。
我們的圖像批量處理系統(tǒng)將讀取存儲在SD 卡中的圖像,并利用不同的噪聲級參數(shù)和結構元素形狀的參數(shù)來處理這些圖像。
圖像批處理
我們的實例系統(tǒng)使用專門的相機獲取圖像,然后以批量模式處理圖像。圖像尺寸達 3,000 x 2,000像素(600 萬像素)。盡管處理后的圖像不是實時視頻,但目的是通過圖像流水線盡可能快地發(fā)送圖像。這里所用的流水線相當簡單:將 RGB 圖像轉換為灰度圖像;添加椒鹽噪聲;以及用三個濾波器(膨脹、中值和腐蝕)對噪聲圖像進行濾波。膨脹、中值和腐蝕濾波器均屬于中值濾波器系列,這類濾波器主要用來(但并非專門用于)消除脈沖噪聲以實現(xiàn)圖像增強。這些都是非線性濾波器,不涉及任何算術運算,而且功能僅限于數(shù)據(jù)排序和采集。盡管算法不是太復雜,但是當處理大圖像時會耗用相當多的處理時間,原因在于處理器的有序性,在給定時間內只處理 1 個像素。
中值濾波器是非線性濾波器,需要逐像素地計算輸出圖像。方法是取特定形狀(稱為結構元素)內輸入像素的臨近像素,將它們進行排序,并選
出位于 pth rank 上的像素。腐蝕濾波器選擇最小值(p=1)。膨脹濾波器選擇最大值(p=N,其中 N 是結構元素的像素數(shù)量)。中值濾波器選擇中間值(p =[N/2])。通常,結構元素是正方形、菱形或十字形(圖 1)。
圖 1 — 7x7 邊界框中的結構元素
我們的圖像批處理系統(tǒng)會讀取存儲在 SD 卡中的圖像,并利用不同的噪聲級參數(shù)和結構元素形狀的參數(shù)來處理這些圖像。運行頻率為 667MHz 的Zynq-7000 SoC 的雙核 ARM? Cortex ? -A9 處理器負責執(zhí)行計算任務。
軟件實現(xiàn)
首先,我們用 C++ 編寫完整的應用程序,這樣就可估算 Cortex-A9 的計算性能。應用程序包含一系列函數(shù),用以讀寫 SD 卡上的 BMP 圖像,計算亮度,添加噪聲,并執(zhí)行各種濾波器功能。采用 SDSoC開發(fā)環(huán)境的 SDDebug 配置,能夠通過賽靈思ZC702 評估平臺在 Linux 操作系統(tǒng)下快速進行軟件實現(xiàn)。
為生成真正可使用的可執(zhí)行文件,我們選擇選項 O3 啟動所有編譯器優(yōu)化。結構元素的形狀是應用程序的一個參數(shù),這樣我們可以采用任何適合放在7 x 7 像素邊界框中的結構元素。對流水線時延(圖 2)有影響的參數(shù)是圖像尺寸(#Size),結構元素中有效像素的數(shù)量(#Shape)。最小化時延能改善系統(tǒng)性能。FPGA 對涉及很多加法和乘法運算的信號處理算法執(zhí)行得非常好。我們的系統(tǒng)實例將展示可編程邏輯不僅善于強力計算,而且還善于執(zhí)行更標準的數(shù)據(jù)處理。

圖 2 - Zynq 處理系統(tǒng)的運行時間
基本特性分析(圖 3)顯示,通過 RGB 值計算亮度 (0.13%),以及為像素添加噪聲 (0.34%),這些操作在軟件中運行得非常快。中值濾波器占用了總時間中的大部分時間( 達 92.33%)。文件讀取和保存也會占用時間。

圖 3 — 初始軟件的特征分析結果
將函數(shù)轉移到硬件
加速的首要目的是在每個時鐘周期內處理一個新樣本。重寫部分代碼重寫以及重新設計接口可實現(xiàn)大幅加速。即使片上可編程邏輯 (PL) 的時鐘速率遠低于處理系統(tǒng) (PS) 的時鐘速率,但是能夠在每個時鐘周期內處理一個輸入像素也可以實現(xiàn)大幅加速。
中值濾波器是唯一被轉移到硬件的函數(shù)。在SDSoC 環(huán)境中將功能轉移到 PL 是一件非常容易的事情,只需在 Project Explorer 中右鍵點擊即可,而且不會添加任何指令(除了在接口位置添加外),也不用修改任何一行代碼來提高性能。這些修改由嵌入式編程人員負責,這就說明了為何初始加速通常不那么明顯。
以上指定的函數(shù)包含兩個貫穿整個圖像的嵌套循環(huán)。它還包含多個貫穿結構元素的子回路,可對所有元素進行排序。在本例中,我們使用標準氣泡排序算法。其他復雜度低的算法適合通過微處理器實現(xiàn),而這種算法的規(guī)則性更適合硬件實現(xiàn):
?
for ( i=0; ifor ( j=0; j{
Some Code
for ( s=0; sfor ( k=0; kk++)
for ( l=0; ll++)
{
Swap pixels if not correctly ordered
}
}
由于我們想在每個時鐘周期內處理一個 1 個輸出圖像像素,因此必須添加一條指令以便針對每個時鐘周期啟動像素矢量排序。我們利用值為 1 的啟動間距 (II) 對經過圖像縱列的第二個循環(huán)進行流水線化處理。(II 是指新的循環(huán)迭代啟動之前所需經過的時鐘周期數(shù)量。)通過使用這條指令,SDSoC 環(huán)境將自動展開剩下的內循環(huán),讓硬件能夠并行處理所有迭代。
加速的首要目的是能夠在每個時鐘周期中處理一個新樣本。重寫部分代碼以及重新設計接口可實現(xiàn)大幅加速。
在單核處理器中實現(xiàn)的圖像處理算法很容易用代碼編寫,因為各種處理器功能使數(shù)據(jù)可以在外部存儲器和處理器本身之間平穩(wěn)傳輸。存儲器高速緩存 L1 和 L2 會暫時存儲以后可能復用的數(shù)據(jù),從而縮短數(shù)據(jù)存取時延。
這種機制在 FPGA 中不是默認存在。盡管這樣我們就無法使用同一 C/C++ 源代碼創(chuàng)建硬件加速器,但我們可以設計一個性能和尺寸完全適合我們應用的存儲器高速緩存。這是一個很好的例子,這種情況下我們修改 C/C++ 源代碼的目的不是保持相同的功能,而是將性能提升到一定程度以便滿足我們的要求。賽靈思的 Vivado? 高層次綜合 (HLS) 是一種 SDSoC 引擎,能夠從 C/C++ 代碼生成寄存器傳輸級 (RTL) IP ;HLS 會考慮到我們的指令,生成一種適用于我們代碼的硬件架構。這就是為什么分析圖像處理代碼時不會自動生成線緩沖器和分析窗口;Vivado HLS 忠于原來的代碼,這樣能防止工具在未經開發(fā)者同意的情況下采取并隱藏優(yōu)化措施。
熟悉硬件圖像處理的設計人員對線緩沖器和分析窗口了如指掌。為避免從外部存儲器中多次讀取同一像素,像素會臨時存儲在內存 (Block RAM)中,如果剩下的執(zhí)行過程再也用不到這些像素,那么這些像素會被覆蓋。Block RAM 有兩個端口,這兩個端口可用作存儲器讀取、存儲器寫入或二者存儲器讀寫。當加速器接受了與 L 行和 C 列對應的像素,就會從線緩沖器中讀取所有與 C 列和 (L-1 …L-6) 行對應的像素,并重新寫入另一個位置,如圖4 所示。為了實現(xiàn)每個時鐘周期內處理 1 個像素這一目標,必須以一個時鐘周期的吞吐量執(zhí)行所有數(shù)據(jù)移動。
?

此外,像素鄰域中的所有像素以及結構元素也必須在一個時鐘周期內訪問。為此,我們還需要定義一個分析窗口,其中包含需要處理的特定像
素(隨像素不同而不同)。在 SDSoC 環(huán)境和 VHLS中,代碼不以任何形式進行時控; 工具會針對所用的資源和我們的指令將任何可以并行處理的任務均并行化。在我們的圖像樣本批處理系統(tǒng)代碼中,我們通過使用正確的分區(qū)指令(圖 5) 聲明兩個數(shù)組,從而為代碼添加線緩沖器和分析窗口。然后,我們將數(shù)據(jù)運動描述為對這些數(shù)組的讀/ 寫訪問(圖 6)。
?

由于依賴數(shù)組中的數(shù)據(jù)訪問,因此像素值排序過程在硬件架構中實現(xiàn)起來會比較復雜。軟件實現(xiàn)方法所使用的 C 代碼需要取得像素(已通過結構元素對像素進行了驗證)的向量,并使用標準冒泡排序法對向量排序。還有一些效率更高的算法,但是這些算法只有對較大向量才能發(fā)揮顯著優(yōu)勢。算法的復雜程度與結構元素的像素數(shù)量平方成正比,我們這個實例設計是 (7 x 7)2。
在硬件中,架構必須針對最壞情況來進行設計。如果我們要實現(xiàn)每個時鐘周期內處理 1 個像素這個目標,需要實現(xiàn)非常規(guī)則的結構。為此,我們規(guī)定輸入向量總是具有最大尺寸(7 x 7),而且所有未驗證的像素都具有數(shù)值 0,這樣它們會處于排序向量底部。我們還要針對最差情況設計級數(shù),即使對于具有較少有效像素的結構元素來說級數(shù)可能更低。只有相同向量不在每級重用時,才會發(fā)生不同級的并行化。結果得到一個數(shù)組,在這個數(shù)組中初始向量從列索引 0 入,從列索引 7 x 7 = 49 出(如圖7 和 8 所示)。
?
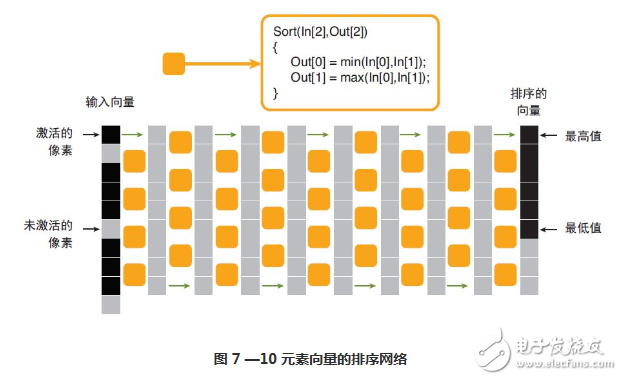
?

SDSOC 系統(tǒng)編譯器
SDSoC 并非簡單的全系統(tǒng)編譯器。它進行大量代碼分析,以決定要求在硬件中實現(xiàn)的函數(shù)最適合使用哪種數(shù)據(jù)移動器,并決定將數(shù)據(jù)移動器連接到哪個端口。對于函數(shù)的每個參數(shù),我們必須確定最適合使用 ARM? AMBA? AXI4-Lite、AXI4-Fullmemory-mapped 還是 AXI4-Stream 數(shù)據(jù)移動器。
我們還需要確定使用哪個連接器:AXI4 高性能 (HP) 端口、通用 (GP) 端口或加速器一致性端口(ACP),甚至是來自其他加速器的端口,可在 SDSoC環(huán)境中構建或者包含在板支持包 (BSP) 中。
然后,SDSoC 環(huán)境創(chuàng)建一個設計,添加所有必要的 IP 以構成功能完整的系統(tǒng),例如 AXI4 Stream 數(shù)據(jù)移動器的直接存儲器訪問 (DMA) ; 并修改 C 語言源代碼(而非初始的C++ 代碼),以調用硬件。本例中,接口非常簡單:通過 AXI4-Stream 和 DMA 訪問兩個輸入數(shù)組和三個輸出數(shù)組,通過 AXI4-Lite 設置幾個標量。我們不必考慮 DMA 的設置,也不必檢查標量寄存器的訪問地址;SDSoC 環(huán)境可自動管理所有事情。
在構建樣本系統(tǒng)時,我首先確認源代碼是否兼Vivado HLS,然后添加 VHLS 指令。我使用特定的 SDSoC 指令來指定數(shù)據(jù)在物理空間內連續(xù)存儲(通過函數(shù) sds_alloc 分配的存儲器) ,并指定通過DMA 來訪問數(shù)據(jù)(圖 9)。
?

然后,我把構建配置切換至 SDEstimate,以粗略估算所能實現(xiàn)的加速(圖 10)。我不必為這個步驟等候很長時間,因為此時尚未構建硬件。SDSoC環(huán)境可通過處理器運行時間(使用針對硬件修改的代碼計算出的(這比使用初始針對處理器修改的代碼計算得出的慢)并將編譯器優(yōu)化參數(shù)設定為–O0)和時鐘周期數(shù)量(采用 VHLS 計算得出的,作為硬件加速器的時延)計算出加速估算值。 該時延是硬件加速器的最大時延,因此這個估算值應該作為粗略估算。
?

就硬件加速器本身而言加速效果幾乎達 700倍。“main”級有很多文件訪問需要花費不少時間;這就是為什么總體加速“僅為”5 倍。實際上,我們可以選擇計算全局加速所涉及的頂層函數(shù),這樣就可獲得更有意義的加速值。
流程的最后一步是構建整個系統(tǒng)。這個階段,構建所有加速器都并連接到處理器。然后,修改C++ 源代碼以啟動和控制這些加速器(而非調用初始 C 函數(shù))。在這個階段,我們可以得到使用硬件加速器實現(xiàn)的準確加速值,其中考慮了所有進出DDR 的數(shù)據(jù)。這個加速值還考慮了清除緩存的時間,因為我們的數(shù)據(jù)位于存儲器的可緩存部分。
硬件加速器占用的時間與圖像的大小(而非結構元素的大小)成正比這就是為什么結構元素中的有效像素數(shù)量越多,加速比就會越高。圖 11 中的時延是整個圖像流水線的時延,包含軟件和硬件元素。開發(fā)這個項目時,構建軟件應用是時間最長的一個階段。在此之后,修改代碼的時間不足 2 小時,這樣就可得到完全兼容的 Vivado HLS 代碼,并具備正確的指令來優(yōu)化吞吐量。考慮到該設計的硬件部分較大(芯片的半個查找表),完成最后階段—— 綜合、布局布線、比特流、SD 卡—— 耗用2 個多小時。
?
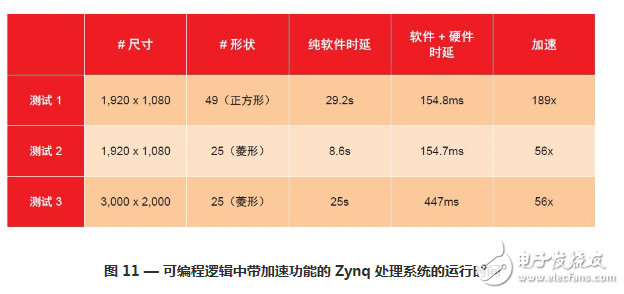
SDSoC 環(huán)境的系統(tǒng)級特性分析集成工具、可編程邏輯中的自動軟件加速功能以及全系統(tǒng)優(yōu)化編譯—— 自動生成正確的連接以最小化存儲器訪問瓶頸—— 使我能夠在不到一周的時間里完成這個實例項目。
如果使用標準的RTL 流程創(chuàng)建加速器,并憑借我自己的編程能力來利用不同驅動程序以修改C 代碼,那么根本無法在這么短的時間內完成。















 工商網監(jiān)
工商網監(jiān)
評論