 電子發(fā)燒友App
電子發(fā)燒友App


學(xué)過(guò)編譯原理課程的同學(xué)應(yīng)該有體會(huì),各種文法、各種詞法語(yǔ)法分析算法,非常消磨人的耐心和興致;中間代碼生成和優(yōu)化,其實(shí)在很多應(yīng)用場(chǎng)景下并不重要(當(dāng)然這一塊對(duì)于“編譯原理”很重要);語(yǔ)義分析要處理很多很多細(xì)節(jié),特別對(duì)于比較復(fù)雜的語(yǔ)言;最后的指令生成,可能需要讀各種手冊(cè),也比較枯燥。
我覺(jué)得對(duì)普通的程序員來(lái)說(shuō),編譯原理里面有實(shí)際用途的,是parser和codegen,但是因?yàn)檫@兩個(gè)領(lǐng)域,到了2016年都沒(méi)什么好研究的了,而且也被搞PLT的人所鄙視,所以你們看到的那些經(jīng)典的教材,都沒(méi)有好好講。
一、 編譯程序
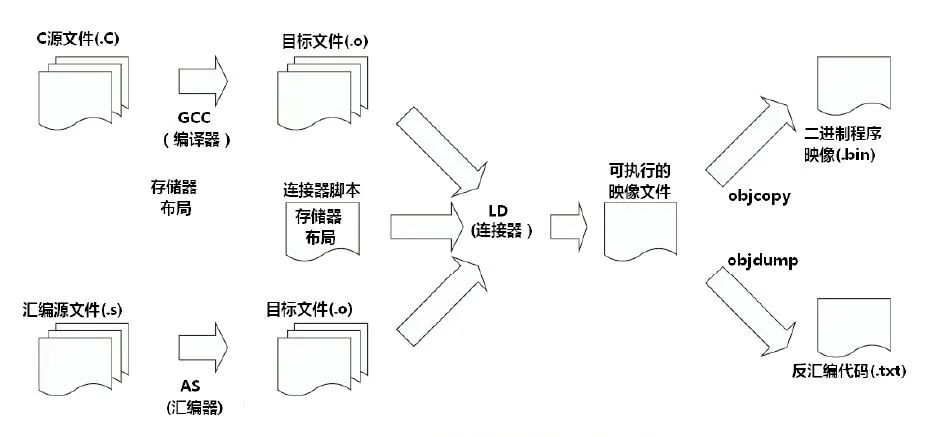
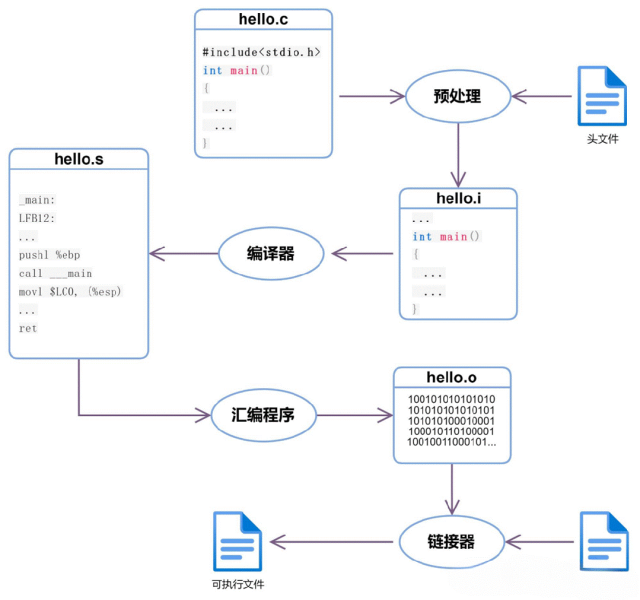
1、 編譯器是一種翻譯程序,它用于將源語(yǔ)言(即用某種程序設(shè)計(jì)語(yǔ)言寫成的)程序翻譯為目標(biāo)語(yǔ)言(即用二進(jìn)制數(shù)表示的偽機(jī)器代碼寫成的)程序。后者在windows操作系統(tǒng)平臺(tái)下,其文件的擴(kuò)展名通常為.obj。該文件通常還要經(jīng)過(guò)進(jìn)一步的連接,生成可執(zhí)行文件(機(jī)器代碼寫成的程序,文件擴(kuò)展名為.exe)。通常有兩種方式進(jìn)行這種翻譯,一種是編譯,另一種是解釋。后者并不生成可執(zhí)行文件,只是翻譯一條語(yǔ)句、執(zhí)行一條語(yǔ)句。這兩種方式相編譯比解釋運(yùn)行的速度要快得多。
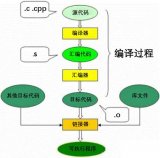
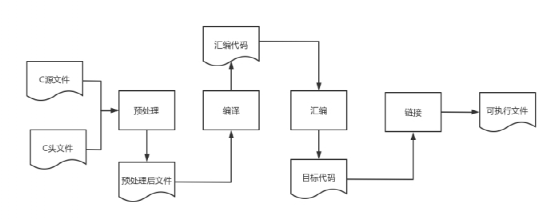
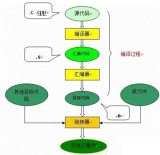
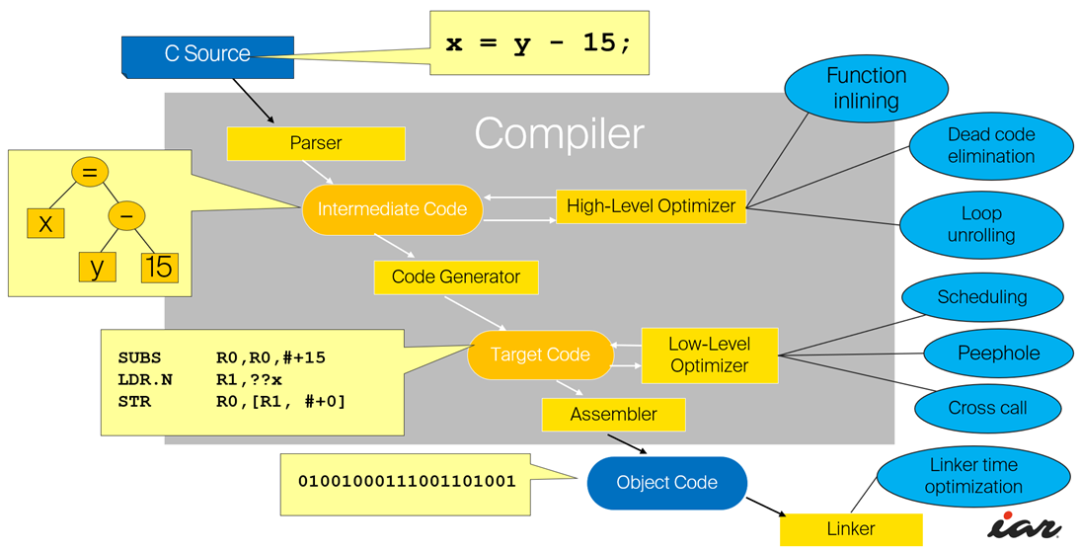
2、 編譯過(guò)程的5個(gè)階段:詞法分析;語(yǔ)法分析;語(yǔ)義分析與中間代碼產(chǎn)生;優(yōu)化;目標(biāo)代碼生成。
3、 在這五個(gè)階段中,詞法分析的任務(wù)是識(shí)別源程序中的單詞是否有誤,編譯程序中實(shí)現(xiàn)這種功能的部分一般稱為詞法分析器。在編譯器中,詞法分析器通常僅作為語(yǔ)法分析程序的一個(gè)子程序以便在它需要單詞符號(hào)時(shí)調(diào)用。在這一編譯階段中發(fā)現(xiàn)的源程序錯(cuò)誤,稱為詞法錯(cuò)誤。
4、 語(yǔ)法分析階段的目的是識(shí)別出源程序的語(yǔ)法結(jié)構(gòu)(即語(yǔ)句或句子)是否錯(cuò)誤,所以有時(shí)又常為句子分析。編譯程序中負(fù)責(zé)這一功能的程序稱為語(yǔ)法分析器或語(yǔ)法分析程序。在這一階段中發(fā)現(xiàn)的錯(cuò)誤稱為語(yǔ)法錯(cuò)誤。
5、 C語(yǔ)言的(源)程序必須經(jīng)過(guò)編譯才能生成目標(biāo)代碼,再經(jīng)過(guò)鏈接才能運(yùn)行。PASCAL語(yǔ)言、FORTRAN語(yǔ)言的源程序也要經(jīng)過(guò)這樣的過(guò)程。通常將C、PASCAL、FORTRAN這樣的語(yǔ)言統(tǒng)稱為高級(jí)語(yǔ)言。而將最終的可執(zhí)行程序稱為機(jī)器語(yǔ)言程序。
6、 在編譯C語(yǔ)言程序的過(guò)程中,發(fā)現(xiàn)源程序中的一個(gè)標(biāo)識(shí)符過(guò)長(zhǎng),超過(guò)了編譯程序允許的范圍,這個(gè)錯(cuò)誤應(yīng)在詞法分析階段發(fā)現(xiàn),這種錯(cuò)誤通常被稱作詞法錯(cuò)誤。
6.1. 詞法分析器的任務(wù)是以詞法規(guī)則為依據(jù)對(duì)輸入的源程序進(jìn)行單詞及其屬性的識(shí)別,識(shí)別出一個(gè)個(gè)單詞符號(hào)。
6.2. 詞法分析的輸入是源程序,輸出是一個(gè)個(gè)單詞的特殊符號(hào),稱為Token(標(biāo)記或符號(hào))。
6.3.語(yǔ)法分析器的類型有:自下而上、自上而下。常用的語(yǔ)法分析器有:遞歸下降分析方法是一種自上而下分析方法, 算符優(yōu)先分析法屬于自下而上分析方法,LR分析法屬于自下而上分析方法等等。
6.4.通常用正規(guī)文法或正規(guī)式來(lái)描述程序設(shè)計(jì)語(yǔ)言的詞法規(guī)則,而使用上下文無(wú)關(guān)文法來(lái)描述程序設(shè)計(jì)語(yǔ)言的語(yǔ)法規(guī)則。
6.5.語(yǔ)法分析階段中,處理的輸入數(shù)據(jù)是來(lái)自詞法分析階段的單詞符號(hào)。它們是詞法分析階段的終結(jié)符。
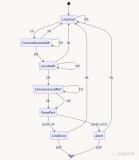
7、 編譯程序總框
8、 在計(jì)算機(jī)發(fā)展的早期階段,內(nèi)存較小的不能一次完成程序的編譯。這時(shí)通常將編譯過(guò)程分成若干遍來(lái)完成。每一遍完成一部分功能,稱為多遍編譯。
與采用高級(jí)程序設(shè)計(jì)語(yǔ)言寫的詞法分析器相比,用匯編語(yǔ)言寫的詞法分析通常分析速度要快些。
二。 詞法與語(yǔ)法
1、 程序語(yǔ)言主要由語(yǔ)法和語(yǔ)義兩個(gè)方面來(lái)定義。
2、 任何語(yǔ)言的程序都可看成是某字符集上的一個(gè)長(zhǎng)字符串。
3、 語(yǔ)言的語(yǔ)法:是指這樣的一組規(guī)則(即產(chǎn)生式),用它可以生成和產(chǎn)生一個(gè)良定的程序。這些規(guī)則的一部分稱為詞法規(guī)則,另一部分稱為語(yǔ)法規(guī)則。
4、 詞法規(guī)則:?jiǎn)卧~符號(hào)的形成規(guī)則;語(yǔ)法規(guī)則:語(yǔ)法單位(句子)的形成規(guī)則。語(yǔ)義規(guī)則:定義程序句子的意義。
5、 一個(gè)程序語(yǔ)言的基本功能是描述數(shù)據(jù)和對(duì)數(shù)據(jù)的運(yùn)算。
6、 高級(jí)語(yǔ)言的分類:強(qiáng)制式語(yǔ)言;應(yīng)用式語(yǔ)言;基于規(guī)則的語(yǔ)言;面向?qū)ο蟮恼Z(yǔ)言。
7、 一個(gè)語(yǔ)言的字母表為{a,b},則字符串a(chǎn)b的前綴有a、ε,其中ε不是真前綴。
8、 字符串的連接運(yùn)算一般不滿足交換率。
9、 文法G是一個(gè)四元組,或者說(shuō)由四個(gè)元素構(gòu)成,即非終結(jié)符集合VN、非終結(jié)符號(hào)集合VT 、開始符號(hào)S、產(chǎn)生式集合P,它可以形式化地表示成G =(VN,VT,S,P)。
按照文法的定義,這4個(gè)元素中終結(jié)符號(hào)集合是這個(gè)文法所規(guī)定的語(yǔ)言的字母表,產(chǎn)生式集合代表文法所規(guī)定的語(yǔ)言語(yǔ)法實(shí)體的集合。對(duì)上下文無(wú)關(guān)文法,通常我們只需要寫出這個(gè)文法的產(chǎn)生式集合就可以確定這個(gè)文法的其他所有元素。其中,第一條產(chǎn)生式的左部符號(hào)為開始符號(hào),而所有產(chǎn)生式的左部符號(hào)構(gòu)成的集合就是該文法的非終結(jié)符集合。
文法的例子:
設(shè)文法G=(VN,VT, S,P),其中P為產(chǎn)生式集合,它的每個(gè)元素的形式為產(chǎn)生式。
10、如果文法G的一個(gè)句子存在兩棵不同的最左語(yǔ)法分析樹,則這個(gè)文法是無(wú)二義的。
11、如果文法G的一個(gè)句子存在兩棵不同的最右語(yǔ)法分析樹,則這個(gè)文法是無(wú)二義的。
12、如果文法G的一個(gè)句子存在兩棵不同的語(yǔ)法分析樹,則這個(gè)文法是無(wú)法判斷是否是二義的。
13、A為非終結(jié)符,如果文法存在產(chǎn)生式 ,則稱 可以推導(dǎo)出 ;反之,稱 可歸約為 。
14、喬姆斯基(Chomsky)將文法分為四類,即0型文法、1文法、2文法、3文法。
按照喬姆斯基對(duì)方法的分類,上下文無(wú)關(guān)文法是2型文法,2型文法的描述能力最強(qiáng),3型文法又稱為正規(guī)文法。
15、產(chǎn)生式S→Sa | a產(chǎn)生的語(yǔ)言為L(zhǎng)(G) = {an | n ≥ 1}。
16、確定有限自動(dòng)機(jī)DFA是非確定有限自動(dòng)機(jī)NFA的特例;對(duì)任一非確定有限自動(dòng)機(jī)能找到一個(gè)與之等價(jià)的確定有限自動(dòng)機(jī)。
17、DFA和NFA的主要區(qū)別有三點(diǎn):一、DFA初態(tài)唯一,NFA初態(tài)不唯一;二、DFA弧標(biāo)記為Σ上的元素,NFA弧標(biāo)記為Σ*上的元素;三、DFA的函數(shù)為單射,NFA函數(shù)不是單射。
18、有限自動(dòng)機(jī)中兩個(gè)狀態(tài)S1和S2是等價(jià)的是指,無(wú)論是從S1還是S2出發(fā),停于終態(tài)時(shí),所識(shí)別的輸入字的集合相同。
19、自下而上的分析方法,是一個(gè)不斷歸約的過(guò)程。
20、遞歸下降分析器:當(dāng)一個(gè)文法滿足LL(1)條件時(shí),我們就可以為它構(gòu)造一個(gè)不帶回溯的自上而下分析程序。這個(gè)分析程序是由一組遞歸過(guò)程組成的,每個(gè)過(guò)程對(duì)應(yīng)文法的一個(gè)非終結(jié)符。
這個(gè)產(chǎn)生式中含有的左遞歸是直接左遞歸。遞歸下降分析法中,必須要消除所有的左遞歸。遞歸下降分析法中的試探分析法之所以要不斷用一個(gè)產(chǎn)生式的多個(gè)候選式進(jìn)行逐個(gè)試探,最根本的原因是這些候選式有公共左因子。
21、算符優(yōu)先分析法是一種自下而上的分析方法,它適合分析各種程序設(shè)計(jì)語(yǔ)中的表達(dá)式,并宜于手工實(shí)現(xiàn)。目前最廣泛的無(wú)回溯的“移進(jìn)—?dú)w約”方法是自下而上分析方法。
22、在表驅(qū)動(dòng)預(yù)測(cè)分析器中,
1)讀入一個(gè)終結(jié)符a,若該終結(jié)符與棧項(xiàng)的終結(jié)符相同,并且不是結(jié)束標(biāo)志$,則此時(shí)棧頂符號(hào)出棧;
2)若此時(shí)棧項(xiàng)符號(hào)是終結(jié)符并且是,并且讀入的終結(jié)符不是,說(shuō)明源程序有語(yǔ)法錯(cuò)誤;
3)若此時(shí)棧頂符號(hào)為,并且讀入的終結(jié)符也是,則分析成功。
23、算符優(yōu)先分析方法不存在使用形如 這樣的產(chǎn)生式進(jìn)行的歸約,即只要求終結(jié)符的位置與產(chǎn)生式結(jié)構(gòu)一致,從而使得分析速度比LR分析法更快。
24、LR(0)的例子:
產(chǎn)生式E→ E+T對(duì)應(yīng)的LR(0)項(xiàng)目中,待歸約的項(xiàng)目是E→ E+?T,移進(jìn)項(xiàng)目是E→ E?+T,還有兩個(gè)項(xiàng)目為E→ ?E+T和E→ E+T?。
當(dāng)一個(gè)LR(0)項(xiàng)目集中含有兩個(gè)歸約項(xiàng)目時(shí),稱這個(gè)項(xiàng)目集中含有歸約-歸約沖突。
25、LL(1)文法的產(chǎn)生式中一定沒(méi)有公共左因子,即LL(1)文法中一定沒(méi)有左遞歸。為了避免回溯,在LL(1)文法的預(yù)測(cè)分析表中,一個(gè)表項(xiàng)中至多只有一個(gè)產(chǎn)生式。
預(yù)測(cè)分析方法(即LL(1)方法),由一個(gè)棧,一個(gè)總控程序和一個(gè)預(yù)測(cè)分析表組成。其中構(gòu)造出預(yù)測(cè)分析表是該分析方法的關(guān)鍵。
26、LR(0)與SLR(1)兩種分析方法相比,SLR(1)的能力更強(qiáng)。
27、靜態(tài)語(yǔ)義檢查一般包括以下四個(gè)部分,即類型檢查、控制流檢查、名字匹配檢查、一致性檢查。
C語(yǔ)言編譯過(guò)程中下述常見(jiàn)的錯(cuò)誤都屬于檢查的范圍:
a) 將字符型指針的值賦給結(jié)構(gòu)體類型的指針變量:類型檢查。
b)switch語(yǔ)句中,有兩個(gè)case語(yǔ)句中出現(xiàn)了相同的常量:一致性檢查。
c)break語(yǔ)句在既不是循環(huán)體內(nèi)、又不是break語(yǔ)句出現(xiàn)的地方出現(xiàn):控制流檢查。
d)goto語(yǔ)句中的標(biāo)號(hào)在程序的函數(shù)中沒(méi)有找到:一致性檢查。
e)同一個(gè)枚舉常量出現(xiàn)在兩個(gè)枚舉類型的定義當(dāng)中:相關(guān)名字檢查。
28、循環(huán)優(yōu)化中代碼外提是指對(duì)循環(huán)中的有些代碼,如果它產(chǎn)生的結(jié)果在循環(huán)過(guò)程中是不變的,就把它提到循環(huán)體外來(lái);而強(qiáng)度削弱是指把程序中執(zhí)行時(shí)間較長(zhǎng)的運(yùn)算替換為執(zhí)行時(shí)間較短的運(yùn)算。
解析編譯原理主要過(guò)程
第一個(gè)編譯器由機(jī)器語(yǔ)言開發(fā) 然后就有了后來(lái)的各種語(yǔ)言寫出來(lái)的編譯器
1 編譯過(guò)程包括如下圖所示:。
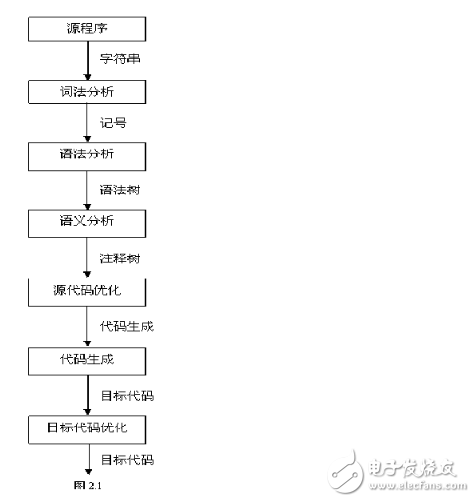
2 詞法分析作用:找出單詞 。如int a=b+c; 結(jié)果為: int,a,=,b,+,c和;
3語(yǔ)法分析作用:找出表達(dá)式,程序段,語(yǔ)句等。如int a=b=c;的語(yǔ)法分析結(jié)果為int a=b+c這條語(yǔ)句。
4語(yǔ)義分析作用:查看類型是否匹配等。
5注意點(diǎn):詞法分析器實(shí)現(xiàn)步驟:正規(guī)式-》NFA-》簡(jiǎn)化后的DFA-》對(duì)應(yīng)程序;語(yǔ)法分析要用到語(yǔ)法樹;語(yǔ)義分析要用到語(yǔ)法制導(dǎo)。
編譯原理一般分為詞法分析,語(yǔ)法分析,語(yǔ)義分析和代碼優(yōu)化及目標(biāo)代碼生成等一系列過(guò)程。下面我們結(jié)合來(lái)了解一下:
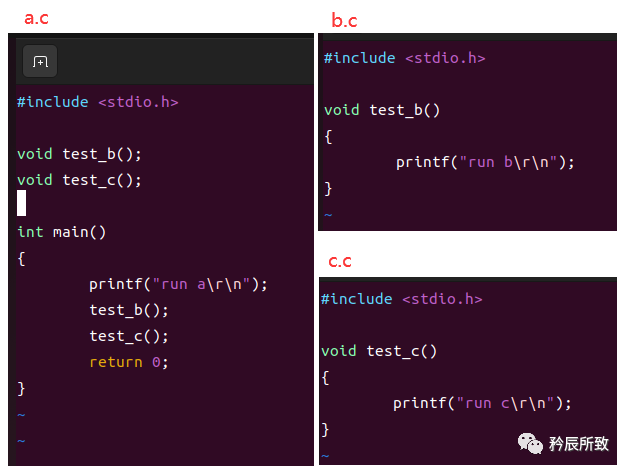
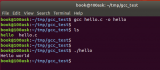
本程序可以同時(shí)在BC和Visual C++下運(yùn)行。我測(cè)試過(guò)了的。下面先將代碼貼給大家。其中如果你只想先了解詞法分析部分,你可以將其余的注釋就可以。我建議大家學(xué)習(xí)時(shí)一步一步來(lái),從詞法分析學(xué),然后學(xué)語(yǔ)法分析。其他的就類似了。
如果你在DOS下運(yùn)行,由于使用了漢字,請(qǐng)將其自行換成英文方便您的識(shí)別。
程序中的解釋就是編譯的基本原理。如果還不清楚建議大家看孫悅紅的編譯原理及實(shí)現(xiàn)清華的。




















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論