! 為什么百度不用SQL支持數(shù)據(jù)處理,還在寫一堆 Hadoop 腳本! Java 開發(fā)需要對大數(shù)據(jù)了解多少,Hbase、Hive、Spark 這些嗎? 不
2020-09-17 13:17:00 4018
4018 Hadoop 是 Apache 軟件基金會下一個開源分布式計算平臺,以 HDFS(Hadoop Distributed File System)、MapReduce(Hadoop2.0 加入
2022-09-27 09:40:011162 大數(shù)據(jù)基礎(chǔ)Hadoop311 的高可用HA安裝~踩坑記錄
2019-09-20 08:23:27
一、前言 以微博為例,每個用戶會發(fā)很多微博,其中包含了很多關(guān)鍵詞信息。而這些關(guān)鍵詞就是用戶可能感興趣的事物。我們需要用Hadoop MapperReduce計算出來。折舊引出了文檔加權(quán)算法。其含義
2021-09-17 06:51:49
當你在學習和使用hadoop時,也許會遇到這樣的一個問題,運行bin/start-all.sh時發(fā)現(xiàn)namenode沒有啟動,可以通過以下方法進行排查解決:翻看日志,尋找錯誤提示,并進行內(nèi)容的改進
2018-01-04 14:27:08
和Facebook的thrift。avro用來做以后hadoop的RPC,使hadoop的RPC模塊通信速度更快、數(shù)據(jù)結(jié)構(gòu)更緊湊。5.Hive :類似CloudBase,也是基于hadoop分布式計算平臺
2018-05-16 16:04:57
Hadoop教程:命令手冊
2020-03-18 11:28:02
Hadoop單機環(huán)境搭建
2019-06-06 06:42:20
,便捷性得到大大提升。對于初學者來說,不妨可以使用DKhadoop的發(fā)行版作為大數(shù)據(jù)學習的入門平臺。 DKhadoop是大快搜索推出的,純國產(chǎn)的原生態(tài)開發(fā)的。對于初學者來說DKhadoop還是比較友好
2018-11-28 13:25:46
Hadoop安裝(偽集群)
2019-10-16 10:39:41
!分享的這些內(nèi)容只能說是適合hadoop新手入門以及hadoop愛好者吧!而且可能由于使用的hadoop發(fā)行版不同的原因,如果你直接按照分享的步驟操作可能也會有“驚喜”!畢竟所有的文章也是我個人操作時的步驟
2019-01-09 15:39:39
Hadoop中Join多種應(yīng)用
2020-03-31 11:32:58
Hadoop任務(wù)調(diào)度策略
2019-05-10 17:01:21
?): 分布式文件系統(tǒng),提供對應(yīng)用程序數(shù)據(jù)的高吞吐量訪問。HadoopMapReduce:這是基于YARN的用于并行處理大數(shù)據(jù)集的系統(tǒng)。除了以上四個模塊,Hadoop還包括指向可以安裝在Hadoop
2018-05-11 16:00:10
Hadoop集群環(huán)境搭建是很多學習hadoop學習者或者是使用者都必然要面對的一個問題,網(wǎng)上關(guān)于hadoop集群環(huán)境搭建的博文教程也蠻多的。對于玩hadoop的高手來說肯定沒有什么問題,甚至可以說
2018-10-12 15:51:49
Elasticsearch集成Hadoop最佳實踐 PDF 下載,Hadoop權(quán)威指南 大數(shù)據(jù)的存儲與分析PDF 下載
2019-05-08 17:01:00
Hadoop計數(shù)器的應(yīng)用以及數(shù)據(jù)清洗
2019-11-04 09:19:29
hadoop 27集群搭建
2020-04-02 06:28:23
應(yīng)用一般都是批量處理,而不是用戶交互式處理,應(yīng)用程序能以流的形式訪問數(shù)據(jù)集。Hadoop已經(jīng)迅速成長為首選的、適用于非結(jié)構(gòu)化數(shù)據(jù)的大數(shù)據(jù)分析解決方案,HDFS分布式文件系統(tǒng)是Hadoop的核心組件之一
2018-03-23 14:22:23
的DKhaoop, 是目前已知的國產(chǎn)發(fā)行版中唯一一個純原生態(tài)的開發(fā),集成了整個HADOOP生態(tài)系統(tǒng)的全部組件,并深度優(yōu)化,重新編譯為一個完整的更高性能的大數(shù)據(jù)通用計算平臺,實現(xiàn)了各部件的有機協(xié)調(diào)。因此DKH相比開源的大數(shù)據(jù)平臺,在計算性能上有了高達5倍(最大)的性能提升。
2018-09-18 11:58:18
了整個HADOOP生態(tài)系統(tǒng)的全部組件,并深度優(yōu)化,重新編譯為一個完整的更高性能的大數(shù)據(jù)通用計算平臺,實現(xiàn)了各部件的有機協(xié)調(diào)。因此DKH相比開源的大數(shù)據(jù)平臺,在計算性能上有了高達5倍(最大)的性能提升
2018-09-18 16:30:32
什么大的區(qū)別。我記得剛開始接觸大數(shù)據(jù)這方面內(nèi)容的時候,也就這個問題查閱了一些資料,在《FreeRCH大數(shù)據(jù)一體化開發(fā)框架》的這篇說明文檔中有就Hadoop和spark的區(qū)別進行了簡單的說明,但我覺得解釋的也
2018-11-30 15:51:36
Hadoop主要是分布式計算和存儲的框架,其工作過程主要依賴于HDFS分布式存儲系統(tǒng)和Mapreduce分布式計算框架,以下是其工作過程:階段 1用戶/應(yīng)用程序可以通過指定以下項目來向Hadoop
2018-05-11 16:02:03
Hadoop50070是hdfs的web管理頁面,在搭建Hadoop集群環(huán)境時,有些大數(shù)據(jù)開發(fā)技術(shù)人員會遇到Hadoop 50070端口打不開的情況,引起該問題的原因很多,想要解決這個問題需要從以下
2018-04-10 16:02:13
hadoop。比如:阿里云在做大數(shù)據(jù)、華為云、以及騰訊云等。 但今天想要給hadoop新手入門推薦的最新發(fā)行穩(wěn)定版hadoop則是dkhadoop。Dkhadoop是大快推出的商業(yè)發(fā)行版,集成了整個
2018-12-28 16:08:44
火爆的hadoop、Maperduce和許多Nosql系統(tǒng)。這三大技術(shù)也是整個大數(shù)據(jù)技術(shù)的核心基礎(chǔ)。目前國內(nèi)的hadoop商業(yè)發(fā)行版也是比較多,這些hadoop商業(yè)版大部分都是由國外發(fā)行的,純國產(chǎn)
2018-10-15 15:59:43
hadoop集群搭建系列(step01:集群搭建準備)
2020-03-31 09:47:17
hadoop集群部署
2019-08-20 14:33:13
hadoop集群配置
2019-09-30 14:16:14
此類大規(guī)模攻擊,阿里云平臺已可默認攔截,降低漏洞對用戶的直接影響;如果企業(yè)希望徹底解決Hadoop安全漏洞,推薦企業(yè)使用阿里云MaxCompute (8年以上“零”安全漏洞)存儲、加工企業(yè)數(shù)據(jù);阿里云
2018-05-08 16:52:39
` 大數(shù)據(jù)這個詞也許幾年前你聽著還會覺得陌生,但我相信你現(xiàn)在聽到hadoop這個詞的時候你應(yīng)該都會覺得“熟悉”!越來越發(fā)現(xiàn)身邊從事hadoop開發(fā)或者是正在學習hadoop的人變多了。作為一個
2018-12-26 15:02:33
隨著互聯(lián)網(wǎng)的發(fā)展,大數(shù)據(jù)也在逐漸彰顯出自己的優(yōu)勢特點,那么關(guān)于大數(shù)據(jù)的處理流程,你是否了解?第一,數(shù)據(jù)采集定義:利用多種輕型數(shù)據(jù)庫來接收發(fā)自客戶端的數(shù)據(jù),并且用戶可以通過這些數(shù)據(jù)庫來進行簡單的查詢
2018-06-11 16:41:53
大數(shù)據(jù)工具可以幫助大數(shù)據(jù)工作人員進行日常的大數(shù)據(jù)工作,以下是大數(shù)據(jù)工作中常用的工具:1.HivemallHivemall結(jié)合了面向Hive的多種機器學習算法。它包括諸多高度擴展性算法,可用于數(shù)據(jù)分類
2018-04-24 15:24:01
Hadoop教程:大數(shù)據(jù)概述
2019-08-27 10:52:24
處理、集群、實時性計算等,匯集了當前IT領(lǐng)域熱門流行的IT技術(shù)。想要學好大數(shù)據(jù)需掌握以下技術(shù):1. Java編程技術(shù)Java編程技術(shù)是大數(shù)據(jù)學習的基礎(chǔ),Java是一種強類型語言,擁有極高的跨平臺能力
2018-04-08 16:50:41
了hadoop商業(yè)版的發(fā)行。這里就通過大快DKhadoop為大家詳細介紹一下hadoop大數(shù)據(jù)平臺架構(gòu)內(nèi)容。目前國內(nèi)的商業(yè)發(fā)行版hadoop除了大快DKhadoop以外還有像華為云等。雖然發(fā)行方
2018-10-17 15:12:09
大數(shù)據(jù)的應(yīng)用開發(fā)太過偏向于底層,學習的難度不是一般的大,所涉及到的技術(shù)面廣太大,不是一般人所能夠駕馭得了的。市場上大部分打著hadoop國產(chǎn)發(fā)行版,也只是把國外的拿過來重新修改了一下而已。大快
2018-10-19 15:12:26
、如果你對原生hadoop較為熟悉的,你就會發(fā)現(xiàn)dkhadoop是集成了整個hadoop生態(tài)系統(tǒng)的全部組建,當然不僅僅是集成這么簡單,而是做了深度的優(yōu)化,重新編寫成的一個完整的更高性能的大數(shù)據(jù)通過計算平臺
2018-10-31 13:58:17
【Spark系列】:Spark為什么比Hadoop快
2020-04-06 09:11:41
1.上傳文件 1)hadoop fs -put words.txt /path/to/input/ 2)hdfs dfs -put words.txt /path/wc/input/2.獲取hdfs
2019-07-08 08:10:31
Hadoop是在分布式服務(wù)器集群上存儲海量數(shù)據(jù)并運行分布式分析應(yīng)用的一個平臺,其核心部件是HDFS與MapReduce。HDFS是一個分布式文件系統(tǒng),可對數(shù)據(jù)系統(tǒng)進行分布式儲存讀取
2018-03-13 15:21:18
Mac編譯Hadoop源碼
2019-08-29 08:47:59
時期內(nèi)關(guān)于大數(shù)據(jù)應(yīng)用開發(fā)又將進入到一個新的階段。現(xiàn)在市面上圍繞大數(shù)據(jù)的應(yīng)用開發(fā)如火如荼,比如,企業(yè)級大數(shù)據(jù)處理平臺開發(fā)、政務(wù)大數(shù)據(jù)平臺的開發(fā)、智慧交通大數(shù)據(jù)平臺開發(fā)等。這些大數(shù)據(jù)處理平臺的開發(fā)從技術(shù)角度
2018-11-07 14:10:20
linux下編譯hadoop的272的源碼
2020-04-02 11:48:38
→ Kafka → Sqoop → Pig學習目標:掌握大數(shù)據(jù)學習基石Hadoop、數(shù)據(jù)串行化系統(tǒng)與技術(shù)、數(shù)據(jù)的統(tǒng)計分析、分布式集群、流行的隊列、數(shù)據(jù)遷移、大數(shù)據(jù)平臺分析等第三階段:Storm
2018-03-01 15:41:13
分享給大家,供參考之用。關(guān)于學習hadoop需要具備什么基礎(chǔ)知識,首先應(yīng)該從整體了解hadoop,包括hadoop是什么,能夠幫助我們解決什么問題,以及hadoop的使用場景等。在有了整體上的了解后
2018-09-20 16:00:57
你現(xiàn)在的基礎(chǔ)之上的。假定你連基礎(chǔ)的計算機基礎(chǔ)都沒有,那可能真的就是“難不會”了。如果你是有一個良好的計算機基礎(chǔ)的,比如,虛擬機的配置你會、擁有JAVA基礎(chǔ)和Linux操作基礎(chǔ),那學習hadoop對你來
2018-09-13 13:37:51
安裝。一次性安裝成功這種事情是不存在的,折騰到崩潰卻是事實。我讓他們?nèi)ハ螺dDKHadoop安裝試一下,至于后來試沒試就不得而知了。下面就切入正題,看完整個安裝步驟你會發(fā)現(xiàn)hadoop安裝原來也可以這么
2019-01-25 14:50:28
上次我們分享了Spark與Hadoop計算模型的內(nèi)存問題,今天山西思軟嵌入式學員為大家分享Spark與Hadoop計算模型的Spark比Hadoop更通用的問題。 Spark提供的數(shù)據(jù)集操作類型
2012-11-17 16:44:30
大數(shù)據(jù)初學者的福利——Hadoop快速入門教程
2020-04-15 11:38:59
Hadoop源碼解析之Partitioner類
2020-03-27 09:41:52
Hadoop源碼分析——JobClient
2019-09-30 10:47:07
最全hadoop架構(gòu)總結(jié)
2019-05-29 16:08:16
Hadoop各成員源代碼下載地址:http://svn.apache.org/repos/asf/hadoop,請使用SVN下載,在SVN瀏覽器中將trunk目錄下的源代碼check-out出來即可:
2011-04-03 22:15:08 54
54 用Linux和Apache Hadoop進行云計算使用Linux 和 Hadoop 進行分布式計算介紹Hadoop 框架.
2012-03-31 15:23:3412 一種多層次Hadoop平臺設(shè)計_李兆興
2017-01-03 18:03:200 Hadoop環(huán)境的搭建與管理--謝志明.pptx
2017-02-14 17:17:230 Hadoop平臺下改進的推測任務(wù)調(diào)度算法_陳明麗
2017-03-19 11:41:510 hadoop大數(shù)據(jù)windows搭建環(huán)境
2017-09-08 08:52:444 基于Ubuntu的Hadoop集群安裝與配置
2017-09-08 14:20:598 如何高效排序是在對大數(shù)據(jù)進行快速有效的分析與處理時的一個重要問題。首先對基于Hadoop平臺的幾種高效的排序算法(Quicksort,Heapsort和Mergesort算法)進行了研究。再通過
2017-11-08 17:25:2815 Hadoop遠遠不止HDFS和MapReduce/Spark,它是一個全面的數(shù)據(jù)平臺。CDH平臺包含了很多Hadoop生態(tài)圈的其他組件。我們在做群集規(guī)劃的時候往往還需要考慮HBase,Impala和Solr等。它們都會運行在DataNode上運行,從而保證數(shù)據(jù)的本地性。
2017-11-09 11:59:011535 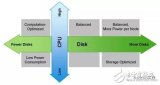
隨著大數(shù)據(jù)的發(fā)展,Hadoop系統(tǒng)成為了大數(shù)據(jù)處理中的重要工具之一。在實際應(yīng)用中,Hadoop的I/O作制約系統(tǒng)性能的提升。通常Hadoop系統(tǒng)通過軟件壓縮數(shù)據(jù)來減少I/O操作,但是軟件壓縮速度較慢
2017-11-27 10:49:050 Hadoop學習筆記(一)—-概念命令操作java操作1. Hadoop概述 HADOOP是apache旗下的一套開源軟件平臺,利用服務(wù)器集群,根據(jù)用戶的自定義業(yè)務(wù)邏輯,對海量數(shù)據(jù)進行分布式處理
2017-11-27 20:03:02920 隨著信息技術(shù)的發(fā)展,互聯(lián)網(wǎng)信息資源變得越來越豐富,大數(shù)據(jù)技術(shù)的發(fā)展使得我們能夠從互聯(lián)網(wǎng)復雜的信息數(shù)據(jù)中獲得相應(yīng)的知識。這其中最基本的技術(shù)就是大數(shù)據(jù)采集技術(shù),它使我們能夠黹互聯(lián)網(wǎng)數(shù)據(jù)快速采集下來
2017-12-05 14:51:290 根據(jù)2ICMA相關(guān)器的算法特點,在對比基于CPU并行的MPI集群、MPI+CUDA異構(gòu)并行集群和Hadoop+ CUDA異構(gòu)并行集群的架構(gòu)特點的基礎(chǔ)上,提出了一種基于Hadoop+ CUDA平臺實現(xiàn)
2017-12-06 10:12:260 針對海量web日志數(shù)據(jù)在存儲和計算方面存在的問題,結(jié)合當前的大數(shù)據(jù)技術(shù),提出一種基于Hadoop與聚類分析的網(wǎng)絡(luò)日志分析模型。利用Hadoop中的MapReduce編程模型對海量Web日志進行處理
2017-12-07 15:40:170 ,優(yōu)化存儲空間利用率。利用Hadoop大數(shù)據(jù)處理平臺下的分布式文件系統(tǒng)(HDFS)和非關(guān)系型數(shù)據(jù)庫HBase兩種數(shù)據(jù)管理模式,設(shè)計并實現(xiàn)一種可擴展分布式重刪存儲系統(tǒng)。其中,MapReduce并行編程框架實現(xiàn)分布式并行重刪處理,HDFS負責重刪后的數(shù)據(jù)存儲
2017-12-22 14:19:500 Hadoop是一個由Apache基金會所開發(fā)的分布式系統(tǒng)基礎(chǔ)架構(gòu)。用戶可以在不了解分布式底層細節(jié)的情況下,開發(fā)分布式程序。充分利用集群的威力進行高速運算和存儲。Hadoop實現(xiàn)了一個分布式文件系統(tǒng),簡稱HDFS。
2017-12-25 15:28:5216583 Hadoop是一個能夠?qū)Υ罅?b class="flag-6" style="color: red">數(shù)據(jù)進行分布式處理的軟件框架。 Hadoop 以一種可靠、高效、可伸縮的方式進行數(shù)據(jù)處理。Hadoop 是可靠的,因為它假設(shè)計算元素和存儲會失敗,因此它維護多個工作數(shù)據(jù)副本,確保能夠針對失敗的節(jié)點重新分布處理。
2017-12-25 15:55:552664 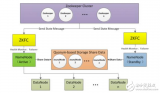
Hadoop 由許多元素構(gòu)成。其最底部是 Hadoop Distributed File System(HDFS),它存儲 Hadoop 集群中所有存儲節(jié)點上的文件。HDFS(對于本文)的上一層是MapReduce 引擎,該引擎由 JobTrackers 和 TaskTrackers 組成。
2017-12-25 16:19:474002 
一、 hadoop是什么? (1)Hadoop是一個開發(fā)和運行處理大規(guī)模數(shù)據(jù)的軟件平臺,可編寫和運行分布式應(yīng)用處理大規(guī)模數(shù)據(jù),是Appach的一個用java語言實現(xiàn)開源軟件框架,實現(xiàn)在大量
2017-12-29 16:32:4039568 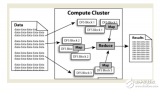
大數(shù)據(jù)就是Hadoop嗎?當然不是,但是很多人一提到大數(shù)據(jù)就會立刻想到Hadoop。大數(shù)據(jù)技術(shù)一旦進入超級計算時代,很快便可應(yīng)用于普通企業(yè),在遍地開花的過程中,它將改變許多行業(yè)業(yè)務(wù)經(jīng)營的模式。但是很多人對大數(shù)據(jù)存在誤解,下面就來縷一縷大數(shù)據(jù)與Hadoop之間的關(guān)系。
2018-01-02 09:21:184512 如何搭建hadoop平臺如下所示,一、虛擬機及系統(tǒng)安裝二、在虛擬機中配置JAVA環(huán)境三、修改hosts...
2018-01-02 09:29:268864 本文比較全面的向大家介紹一下Hadoop命令,歡迎大家一起來學習,希望通過本節(jié)的介紹大家能夠掌握一些常見Hadoop命令的使用方法。Hadoop命令以及常見Hadoop命令使用方法詳解如下
2018-01-02 10:17:278081 
的Hadoop,因其在大規(guī)模、分布式數(shù)據(jù)集上強大的并行處理能力,目前已成為大數(shù)據(jù)并行計算現(xiàn)實中的標準。Hadoop是一個實現(xiàn)了MapReduce計算模型的開源分布式并行編程框架,可以在同一時間內(nèi)處理來自多個用戶的不同類型的多個作業(yè)。而Hadoop的虛擬
2018-01-10 14:34:350 為解決Hadoop云平臺無法動態(tài)控制用戶訪問請求的問題,提出一種基于用戶行為評估的Hadoop云平臺動態(tài)訪問控制( DACUBA,dynamic access control based
2018-01-10 16:37:000 問題,提出了基于Hadoop的負載均衡數(shù)據(jù)分割FP-Growth并行算法。在Hadoop平臺下,使用負載均衡和數(shù)據(jù)分割相結(jié)合的方式對原始事務(wù)數(shù)據(jù)集分片實現(xiàn)并行化。實驗證明,基于Hadoop的負載均衡數(shù)據(jù)分割FP-Crowth并行算法在處理數(shù)據(jù)量和效率上有所提高。
2018-01-14 16:41:141 Hadoop是一個由Apache基金會所開發(fā)的分布式系統(tǒng)基礎(chǔ)架構(gòu)。用戶可以在不了解分布式底層細節(jié)的情況下,開發(fā)分布式程序。充分利用集群的威力進行高速運算和存儲。Hadoop實現(xiàn)了一個分布式文件系統(tǒng)
2018-02-12 10:03:336255 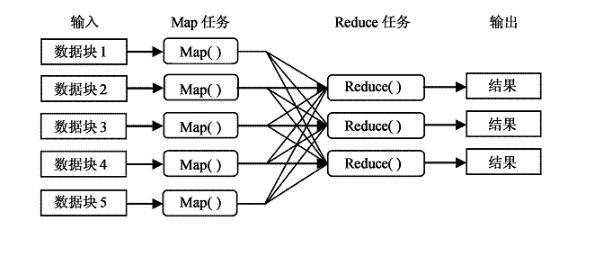
Apache Spark 是專為大規(guī)模數(shù)據(jù)處理而設(shè)計的快速通用的計算引擎。Hadoop是一個由Apache基金會所開發(fā)的分布式系統(tǒng)基礎(chǔ)架構(gòu)。用戶可以在不了解分布式底層細節(jié)的情況下,開發(fā)分布式程序。
2018-02-12 14:41:3214450 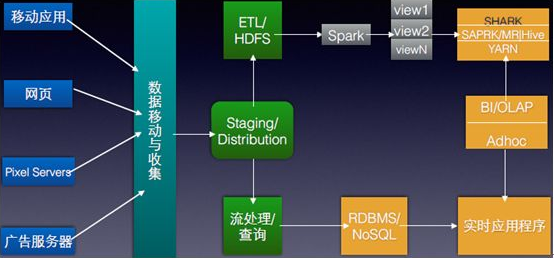
Hadoop在2006年開始成為雅虎項目,隨后成為頂級的Apache開源項目。它是一種通用的分布式處理形式,具有多個組件:
HDFS(分布式文件系統(tǒng)),它將文件以Hadoop本機格式存儲,并在集群中并行化;
YARN,協(xié)調(diào)應(yīng)用程序運行時的調(diào)度程序.
2018-06-04 12:48:006565 針對空間科學大數(shù)據(jù)的快速檢索需求,提出了分布式區(qū)域檢索算法。算法主要包括四維空間科學數(shù)據(jù)的索引方法和分布式四維空間科學數(shù)據(jù)的索引架構(gòu)兩部分。在KTS存儲結(jié)構(gòu)下,通過基于立方體的Block-Grid
2018-04-03 14:54:400 Hadoop 由 Apache Software Foundation 公司于 2005 年秋天作為 Lucene 的子項目 Nutch 的一部分正式引入。它受到最先由 Google Lab 開發(fā)
2018-04-09 11:10:354 企業(yè)版集群,解決8~12個場景下的任務(wù) 2、CCA Spark and Hadoop Developer (CCA175) 開發(fā)者認證 認證準備建議:Spark and Hadoop開發(fā)者培訓 考試形式
2018-09-06 12:55:02564 在工作崗位上,大數(shù)據(jù)工程師需要基于Hadoop,Spark等構(gòu)建數(shù)據(jù)分析平臺,進行設(shè)計、開發(fā)分布式計算業(yè)務(wù)。負責大數(shù)據(jù)平臺(Hadoop,HBase,Spark等)集群環(huán)境的搭建,性能調(diào)優(yōu)和日常維護。負責數(shù)據(jù)倉庫設(shè)計,數(shù)據(jù)ETL的設(shè)計、開發(fā)和性能優(yōu)化。參與構(gòu)建大數(shù)據(jù)平臺,依托大數(shù)據(jù)技術(shù)建設(shè)用戶畫像。
2019-05-30 15:52:095339 Hadoop的優(yōu)點
(1)Hadoop具有按位存儲和處理數(shù)據(jù)能力的高可靠性。
(2)Hadoop通過可用的計算機集群分配數(shù)據(jù),完成存儲和計算任務(wù),這些集群可以方便地擴展到數(shù)以千計的節(jié)點中,具有
2019-10-04 12:16:006476 毫無疑問,為專家設(shè)計的產(chǎn)品一般都會停留在原來的軌道上,在其他方面不會有所涉及。但Spark在各個行業(yè)都存在一些有意義的分布,這可能要歸功于各種市場上的大數(shù)據(jù)的泛濫。所以,雖然Spark可能有更廣泛的應(yīng)用,但Hadoop仍然支配著原本預期的用戶群。
2020-03-20 14:12:232224 
Hadoop 是一個分布式系統(tǒng)基礎(chǔ)架構(gòu),在大數(shù)據(jù)領(lǐng)域被廣泛的使用,它將大數(shù)據(jù)處理引擎盡可能的靠近存儲,Hadoop 最核心的設(shè)計就是 HDFS 和 MapReduce,HDFS 為海量的數(shù)據(jù)提供
2020-04-02 08:00:0012 虛擬機:Hadoop集群的搭建
2020-07-01 13:03:262938 
虛擬機:Hadoop集群的配置
2020-07-01 14:14:182519 如今,開源分析已牢固地成為企業(yè)軟件堆棧的一部分,“大數(shù)據(jù)”一詞似乎已經(jīng)過時,并且Hadoop已成為死法已成為人們公認的民間傳說。不過,這太夸張了;盡管Hadoop不再炙手可熱,但它仍然是一個重要因素
2020-08-17 17:58:432339 最新的OBSA-HDFS組件版本,快速在華為云完成大數(shù)據(jù)平臺的部署和使用。 OBSA-HDFS組件全稱為HuaweiCloud OBS Adapter for Hadoop Support,利用
2021-01-22 16:52:532070 希望實現(xiàn)數(shù)據(jù)基礎(chǔ)設(shè)施的現(xiàn)代化并將Hadoop遷移到云平臺中嗎?以下是組織在數(shù)據(jù)遷移之前需要問的五個問題:
2021-05-05 16:59:00742 數(shù)據(jù)湖的發(fā)展契機,來源于近年來的AI熱潮和云計算、5G的發(fā)展,在日益發(fā)展的海量數(shù)據(jù)時代,數(shù)據(jù)已成為企業(yè)發(fā)展的核心資產(chǎn),通過構(gòu)建適用于大數(shù)據(jù)的底層架構(gòu),圍繞Hadoop提供語義一致性、數(shù)據(jù)治理和安全性
2021-08-24 16:22:32562 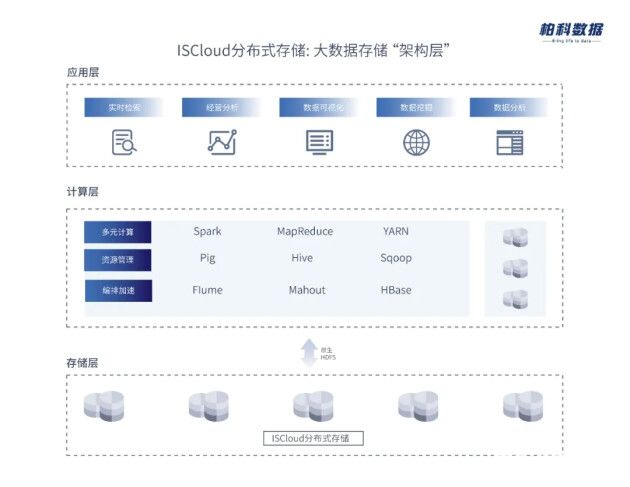
摘要: 研究產(chǎn)品相關(guān)大數(shù)據(jù)資源組織存儲與檢索查詢技術(shù),提出在Hadoop平臺基礎(chǔ)上對產(chǎn)品大數(shù)據(jù)資源進行分塊存儲。基于MapReduce并行架構(gòu)模型,提出多副本一致性Hash數(shù)據(jù)存儲算法,算法充分考慮
2022-03-22 11:09:40593 Hadoop的誕生改變了企業(yè)對數(shù)據(jù)的存儲、處理和分析的過程,加速了大數(shù)據(jù)的發(fā)展。隨著大數(shù)據(jù)系統(tǒng)建設(shè)的深入,企業(yè)的數(shù)據(jù)基礎(chǔ)設(shè)施易出現(xiàn)計算資源浪費、存儲性能低、管理成本過高等挑戰(zhàn)。相比存算一體架構(gòu)
2022-12-26 14:45:16772 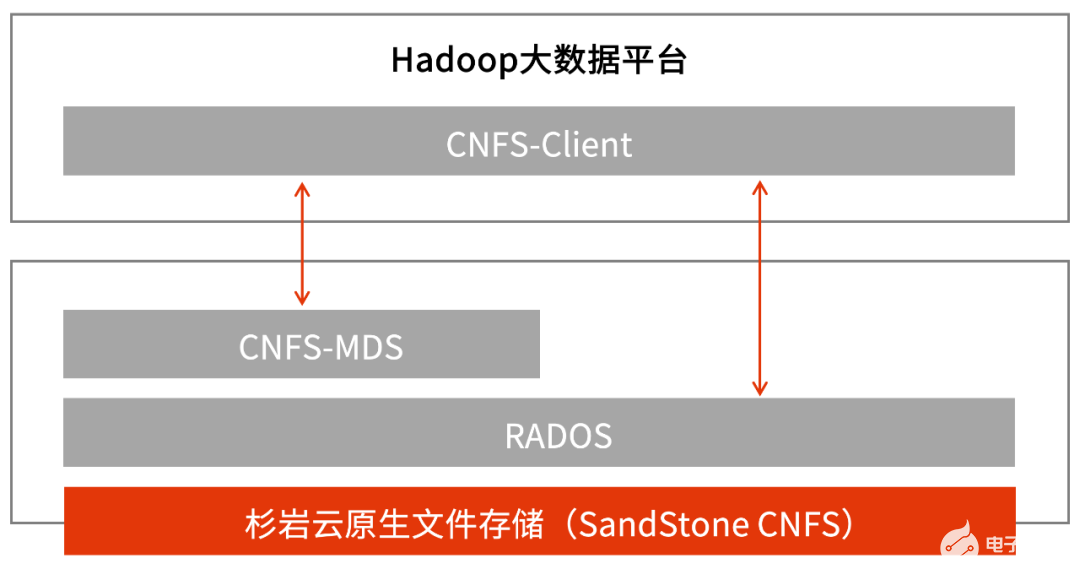
大數(shù)據(jù)平臺指的是具體的平臺比如某個商業(yè)公司用的某個基于大數(shù)據(jù)開發(fā)的平臺,大數(shù)據(jù)平臺主要有阿里巴巴、華為云、百度云、浪潮、騰訊等。
大數(shù)據(jù)平臺可以根據(jù)應(yīng)用場景和功能需求,分為多種類型。以下
2023-04-16 16:14:009850 電子發(fā)燒友網(wǎng)站提供《基于Hadoop云計算智能家居信息處理平臺.doc》資料免費下載
2023-10-30 11:06:340 Hadoop是一個開源的分布式計算框架,它可以處理大規(guī)模數(shù)據(jù)集并能夠在通常由計算機集群或者計算機網(wǎng)絡(luò)上的數(shù)千臺計算機上并行運行。Hadoop的設(shè)計初衷是為了解決大規(guī)模數(shù)據(jù)處理和分析的問題,它采用
2024-02-05 10:52:01301
 電子發(fā)燒友App
電子發(fā)燒友App











 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論